Povratne neuronske mreže. Martin Tutek 6. Prosinac, 2017.
|
|
|
- Arleen Evans
- 5 years ago
- Views:
Transcription
1 Povratne neuronske mreže Martin Tutek 6. Prosinac, 2017.
2 Uvod


3 U prvom ciklusu Obradili smo: Modele za podatke s fiksnom dimenzionalnošću Modele za podatke s eksplicitnom međuovisnošću Primjeri slika iz CIFAR10 Multivarijatna normalna razdioba 1
4 U prvom ciklusu Obradili smo: Modele za podatke s fiksnom dimenzionalnošću Modele za podatke s eksplicitnom međuovisnošću Multivarijatna normalna razdioba Primjeri slika iz CIFAR10 2
5 U prvom ciklusu Fiksna dimenzionalnost ulaznih podataka: Dimenzionalnost multivarijatne normalne razdiobe je fiksna za svaki uzorak iz razdiobe x i R d Svaka slika iz CIFAR10 je dimenzija 32x32x3 (WxHxC) Nije eksplicitno: (random) crop, pad, max/avg pooling, interpolacija za skaliranje slika na iste dimenzije 3
6 U prvom ciklusu Fiksna dimenzionalnost ulaznih podataka: Dimenzionalnost multivarijatne normalne razdiobe je fiksna za svaki uzorak iz razdiobe x i R d Svaka slika iz CIFAR10 je dimenzija 32x32x3 (WxHxC) Nije eksplicitno: (random) crop, pad, max/avg pooling, interpolacija za skaliranje slika na iste dimenzije Eksplicitna međuovisnost: Normalna razdioba: Definirana vektorom µ i matricom Σ Slike: slični pikseli (po boji) imaju slični intenzitet Nije eksplicitno: lokalna korelacija pikseli blizu jedan drugog su vjerojatnije povezani ( riješeno konvolucijskim filtrima) 3
7 Obrada prirodnog jezika Prevedite iduću rečenicu na engleski jezik: Duboko učenje je super. 4
8 Obrada prirodnog jezika Prevedite iduću rečenicu na engleski jezik: Duboko učenje je super. Deep learning is great. Implicitno smo: Razdvojili rečenicu (sekvencu slova) na smislene komponente Razumjeli da izraz duboko učenje nije učenje na velikim dubinama već podvrsta strojnog učenja Shvatili značenje rečenice na ulaznom (source) jeziku bez specifikacije koji je to jezik Generirali rečenicu proizvoljne duljine na ciljnom jeziku Tekst: Nije fiksne dimenzije (duljina rečenice varira) Nema* eksplicitnu međuovisnost (donekle ima kroz sličnost slova) 4
9 Obrada prirodnog jezika Prevedite iduću rečenicu na vijetnamski jezik: 5
10 Obrada prirodnog jezika Prevedite iduću rečenicu na vijetnamski jezik: Chờ internet ở đâu 5
11 Obrada prirodnog jezika Prevedite iduću rečenicu na vijetnamski jezik: Chờ internet ở đâu (Where is the nearest internet shop) Jezik računalima izgleda otprilike kao što nama (koji ne znamo japanski) izgleda japanski Pojmovi značenja riječi, sličnosti riječi i jezičnih jedinica nisu definirani Najčešće, prije obrade teksta algoritmima strojnog učenja možemo barem inicijalizirati te pojmove pomoću vektorskih (distribuiranih) reprezentacija riječi 5
12 Reprezentacije podataka


13 Analiza teksta 6


14 Reprezentacije riječi - one-hot 7


15 Reprezentacije rečenica - bag-of-words Vreća riječi reprezentacija Svaku riječ reprezentiramo s rijetkim vektorom iz {0, 1} V, pri čemu je V veličina vokabulara koji koristimo. Niz riječi reprezentiramo s vektorom veličine V, pri čemu su elementi veltora na indeksima koji odgovaraju riječima u nizu 1 (upaljeni, hot) 8

16 Reprezentacije rečenica - bag-of-words 9
17 Reprezentacije rečenica - bag-of-words Problemi: 1. Veličina vokabulara V je obično jako velika U logističkoj regresiji, trebamo naučiti težinu za svaku riječ u vokabularu 2. Nemamo pojam sličnosti između riječi sim(avion, zrakoplov) = sim(avion, pas) Pri čemu je sim proizvoljna mjera sličnosti (npr. kosinusna sličnost) 3. Gubimo pojam redoslijeda riječi Pri reprezentaciji rečenice, imamo samo informaciju koje su se riječi pojavile u rečenici, ali ne i kojim redoslijedom bow( duboko ucenje je super ali ) = bow( super je ucenje ali duboko ) U nastavku ćemo se prvo baviti rješavanjem problema 1. i 2. kroz distribuirane reprezentacije riječi, a potom problemom 3. kroz povratne neuronske mreže 10
18 Distribuirane reprezentacije riječi Ideja: umjesto velikog i rijetkog vektora nula i jedinica, iskoristiti gusti d-dimenzionalni vekor realnih brojeva R d u kojemu će svaka riječ biti jedinstveno određena kao točka u prostoru Vizualizacija distribuiranih reprezentacija riječi iz [3] 11
.")
 Plus: imamo informaciju o sličnosti riječi (2.")
19 Model matrice susjedstva Matrica susjedstva Firth-ova hipoteza distribucijske semantike - poznavati ćete riječ po njenom društvu Svaka riječ će biti reprezentirana s vektorom w i, pri čemu su elementi vektora w ij = count 5 (w i, w j ). Count 5 je funkcija koja broji koliko puta se riječi w i i w j nalaze unutar udaljenosti od 5 jedna od druge u nekom skupu podataka (npr. engleska Wikipedija) Plus: imamo informaciju o sličnosti riječi (2.) Minus: koristimo matricu veličine V 2 12
20 Modeli redukcije dimenzionalnosti Dekompozicija matrice susjedstva (SVD, LSI, LSA, NMF) Ponovno računamo matricu susjedstva M, no sad joj smanjujemo dimenzionalnost Tražimo vektor v i R k za svaku riječ w i V N Pri čemu je N veličina vokabulara, a k << N dimenzija vektora koje učimo Minimiziramo npr. rekonstrukcijsku grešku Podsjetnik: SVD A = UΣV T A = velika matrica realnih brojeva (u našem slučaju, dimenzija NxN) U T U = I, V T V = I (I = matrica identiteta) Σ = dijagonalna matrica svojstvenih vrijednosti sortiranih po padajućim vrijednostima U, Σ, V - jedinstveni! 13
21 Modeli redukcije dimenzionalnosti - SVD Jesmo li zadovoljni s ovom dekompozicijom? 14

22 Modeli redukcije dimenzionalnosti - SVD Jesmo li zadovoljni s ovom dekompozicijom? Nismo! Ali, možemo odabrati najbitnijih k elemenata matrice svojstvenih vrijednosti (najbitnijih = najvećih) 14

23 Modeli redukcije dimenzionalnosti - SVD Zapravo želimo matricu U dimenzija Nxk koja transformira N-dimenzionalne rijetke vektore susjedstva za svaku riječ u k-dimenzionalan gusti vektor Kroz ovu projekciju interesantna svojstva postanu izraženija 15
 Plus: dimenzija k je mnogo manja od veličine vokabulara N (1.) Može li bolje?")
24 Modeli redukcije dimenzionalnosti - interesantna svojstva Kroz prisiljavanje na kompresiju podataka, algoritam je grupirao slične koncepte Plus: imamo informaciju o sličnosti riječi (2.) Plus: dimenzija k je mnogo manja od veličine vokabulara N (1.) Može li bolje? 16
25 Klasifikacijski modeli Može: Ideja: u dosadašnjim pristupima koristimo samo pozitivne primjere (nizove riječi koje stvarno vidimo u tekstu) klasifikacijski zadatak u kojem neki klasifikator (npr. logistička regresija) za zadanu centralnu riječ w i i njen kontekst c i (riječi udaljene za k od w i) predviđa da li je niz riječi ispravan Izvedba: Za svaku centralnu riječ učimo vektor težina w i Za svaki kontekst učimo vektor težina w c f(x) = σ(w i w c ) Problem - pripada li riječ u kontekst Logloss + trikovi (negative sampling, hierarchical softmax, subsampling,...) 17
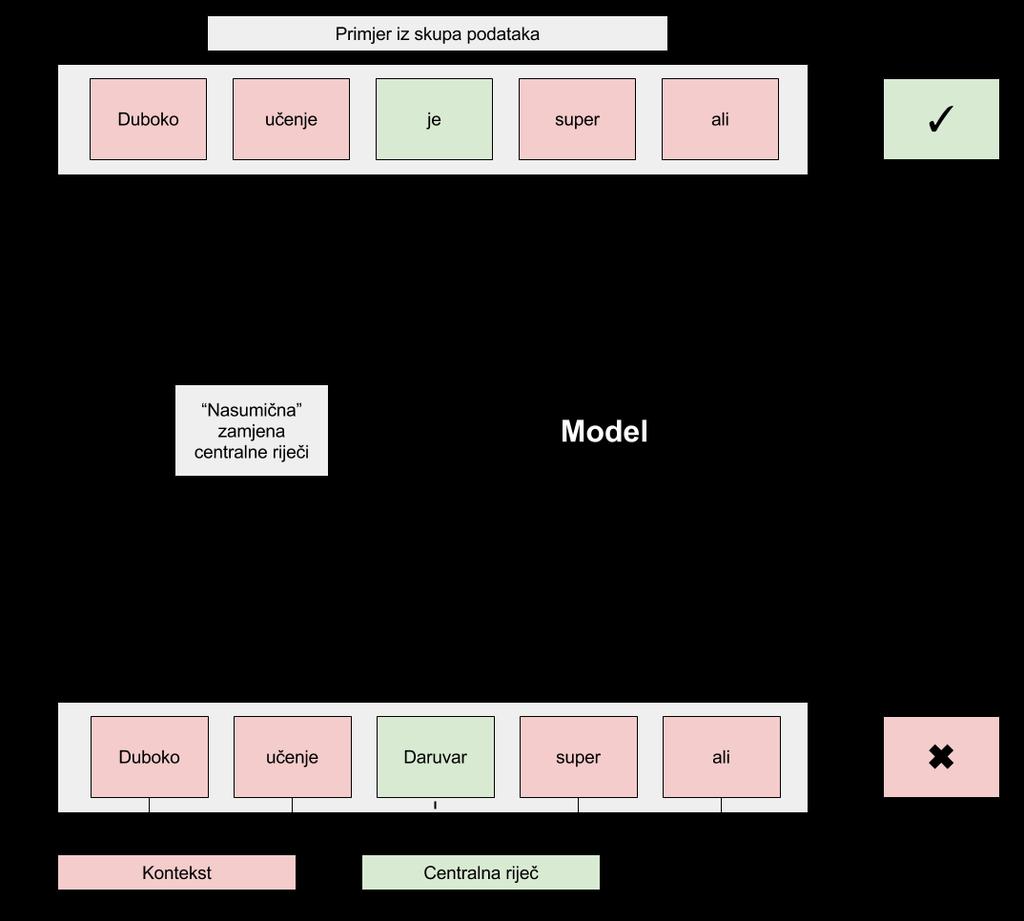
26 Klasifikacijski modeli 18
27 Klasifikacijski modeli Word2Vec Efficient Estimation of Word Representations in Vector Space T. Mikolov et al. [2] (a) Muško - žensko (b) Država - glavni grad Regularnosti u reprezentacijama riječi 19
28 Svojstva vektorskih reprezentacija riječi Mikolov et al. uvode tzv. igru analogija Man is to woman as king is to x x = vec(king) vec(man) + vec(woman) min abs(vec i x) = vec(queen) i O. Levy i Y. Goldberg [1] pokazuju da su ova svojstva prisutna i u tradicionalnim reprezentacijama pomoću matrica sličnosti, no da način treniranja izražava određene konceptualne veze 20
29 Sažetak Riješili smo probleme 1. i 2. Smanjili smo dimenzionalnost vektorskog zapisa riječi Uspješno smo uhvatili sličnost između riječi Sve sa plitkim modelima Opstaje problem 3. Ne koristimo redoslijed riječi Procesiranje slijedova varijabilne duljine - kako? U nastavku Problem strojnog prevođenja & povratne neuronske mreže 21
30 Problem strojnog prevođenja


31 Strojno prevođenje Strojno prevođenje je problem u kojemu dobivamo tekst (niz znakova w 1,..., w T ) u ulaznom jeziku, a cilj nam je smisleno reproducirati ulazni tekst u zadanom izlaznom jeziku. 22
32 Strojno prevođenje - pristup Problemu strojnog prevođenja možemo pristupiti modelom unaprijedne neuronske mreže, gdje na temelju ulaznog niza predviđamo svaku riječ izlaznog niza Sve riječi u svakom jeziku spremimo u mape vokabulara veličina V in te V out Na izlazu kao svaki element izlaznog niza predviđamo najvjerojatniju riječ iz V out P(W o,1,..., W ) = o,ˆt P(W o,1 W i,1,..., W i,t )... P(W o,2 W i,1,..., W i,t ) Tražimo W out,1,..., W out,ˆt koji maksimizira zadanu vjerojatnost. 23

33 Pretvorba ulaznog niza u vektore Probleme sličnosti riječi i dimenzionalnosti vokabulara smo već riješili pomoću distribuiranih reprezentacija riječi, te ćemo u prvom koraku mapirati riječi iz ulaznog niza na već naučene reprezentacije 24

34 Pretvorba izlaznih vjerojatnosti u riječi Ovisno o notaciji, u vektoru o su ponekad već vjerojatnosti, a ponekad log vjerojatnosti, koje se potom skaliraju preko softmax funkcije 25
35 Unaprijedna neuronska mreža za strojno prevođenje 26

36 27
37 Problemi? 28

38 Problem: Varijabilna duljina niza 29
39 Problemi... Broj parametara Prosječna duljina rečenice u engleskom jeziku je 15 riječi Prosječna duljina rečenice u hrvatskom jeziku je 12 riječi Pretpostavimo li da je veličina reprezentacije riječi 300, a veličina skrivenog sloja 1000, veličina ulaznog vokabulara 10000, te veličina izlaznog vokabulara Uz sve ovo, u pristupu s jednoslojnom neuronskom mrežom imamo: Ulazni sloj: x 300 = 3,000,000 realnih brojeva Skriveni sloj: 12 x 300 x 1000 = 3,600,000 realnih brojeva Izlazni sloj: 15 x 1000 x = 150,000,000 realnih brojeva Ogroman broj parametara za treniranje! (sama veličina na disku je 700MB u idealnim uvjetima, no teško je optimizirati ovoliki broj parametara) 30

40 Problemi... Težine su vezane za poziciju riječi u tekstu...što ne znači da učimo poredak riječi - samo da moramo naučiti isto ponašanje za svaku riječ na svakoj njenoj mogućoj poziciji u rečenici (u svakoj matrici težina) 31

41 Problemi... Zapravo i ne koristimo poredak riječi u rečenici Mreža može naučiti ignorira neke veze - no zašto taj postupak prepustiti mreži? 32
42 Rješenja? 33

43 Dijeljenje parametara Neovisno o broju (npr.) riječi na ulazu, koristimo istu matricu U Rješava: 1. Broj parametara 2. Varijabilnu duljinu nizova 3. Težine vezane za poziciju u rečenici Ne rješava: 1. Poredak riječi 34

44 Poredak riječi Dodajemo težinsku matricu W koja povezuje skriveni sloj iz prethodnog vremenskog koraka s trenutnim skrivenim slojem 35
 = f(wh (t 1) + Ux (t) + b) Pri čemu je f funkcija nelinearnosti, u ovom slučaju tangens hiperbolni, a b vektor pristranosti dimenzije H")
45 Novi neuron Naša nova verzija neurona u svakom koraku prima dva ulaza - vektor prethodnog stanja pomnoženog s matricom W, te vektor novog ulaza pomnožen s matricom U h (t) = f(wh (t 1) + Ux (t) + b) Pri čemu je f funkcija nelinearnosti, u ovom slučaju tangens hiperbolni, a b vektor pristranosti dimenzije H 36
46 Povratne neuronske mreže
47 Povratna ćelija Operacije koje radimo u svakom koraku možemo izolirati u ćeliju, koju u ovom slučaju zovemo (običnom) povratnom ćelijom 37

48 Povratna ćelija kao sloj neuronske mreže, vrijeme Povratnu ćeliju možemo interpretirati kao jedan sloj neuronske mreže kojoj je prijenosna funkcija tangens hiperbolni Vrijeme u povratnim neuronskim mrežama označava redoslijed kojim se podaci šalju na ulaz 38

49 Izlaz povratne ćelije 39
50 Izlaz povratne ćelije Pri računanju izlaza povratne neuronske mreže uvodimo novu težinsku matricu V te vektor pristranosti c. o (t) = Vh (t) + c Ovisno o problemu (regresija, klasifikacija), iz vektora o (t) se na drugačiji način računa predikcija (ŷ (t) ) U slučaju strojnog prevođenja, predviđamo koja riječ iz vokabulara ciljnog jezika ima najveću vjerojatnost kao idući element izlaza 40

51 Povratna neuronska mreža za strojno prevođenje 41
52 Povratna neuronska mreža za strojno prevođenje Povratna neuronska mreža u svakom koraku kao izlaz generira nenormalizirane vjerojatnosti u vektoru o (t) dimenzije Y Y je broj ciljnih klasa (u problemu strojnog prevođenja, veličina vokabulara ciljnog jezika). Vjerojatnosti normaliziramo funkcijom softmax te spremamo u vektor ŷ y ˆ (t) = softmax(o (t) ) Normalizirane vjerojatnosti uspoređujemo sa stvarnom distribucijom na izlazu (na izlazu imamo prijevod u ciljnom jeziku) te koristimo gubitak unakrsne entropije L = Y y i log(ŷ i ) i=1 Pri čemu je y i stvarna riječ prijevoda u koraku i. 42

53 Gubitak povratne neuronske mreže 43

54 Povratne neuronske mreže - formalizacija 44
55 Povratne neuronske mreže - Hiperparametri Veličina skrivenog sloja H određuje kolika je reprezentativna moć mreže Uobičajeno je pravilo - što više, to bolje Problem se može dogoditi ukoliko je veličina skrivenog sloja veća od dimenzionalnosti podataka, te mreža krene pamtiti ulazne podatke U praksi, ograničenje je količina dostupne memorije Broj vremenskih koraka odmatanja mreže T T je obično uvjetovan podacima, no u slučaju podataka varijabilne duljine (tekst, rečenice) možemo odrediti maksimalnu duljinu rečenice koju primamo U tom slučaju, podaci dulji od T se krate na T, a podaci kraći od T npr. nadopunjuju nulama (u praksi drugi pristupi) Algoritam optimizacije i stopa učenja Optimizacija: algoritmi s adaptivnim stopama učenja U praksi Adam, RMSProp (AdaGrad) 45
56 Povratne neuronske mreže - formalizacija Radi jednostavnosti, inicijaliziramo skriveno stanje na vektor nula: h (0) = 0 Projekcija ulaza u skriveno stanje i projekcija prošlog skrivenog stanja u skriveno stanje: h (t) = tanh(wh (t 1) + Ux t + b) (1) Projekcija u izlazni sloj: Vjerojatnosti izlaznog sloja (klasifikacija): o (t) = Vh (t) + c (2) ŷ (t) = softmax(o (t) ) (3) Gubitak unakrsne entropije: L (t) = C i y (t) i log(ŷ (t) i ) (4) 46

57 Povratne neuronske mreže - propagacija unaprijed 47

58 Povratne neuronske mreže - propagacija unaprijed 48

59 Povratne neuronske mreže - propagacija unaprijed 49

60 Povratne neuronske mreže - propagacija unaprijed 50

61 Povratne neuronske mreže - propagacija unaprijed 51

62 Povratne neuronske mreže - propagacija unaprijed 52

63 Povratne neuronske mreže - propagacija unaprijed 53
64 Treniranje povratnih neuronskih mreža

65 Propagacija unatrag kroz vrijeme 54

66 Propagacija unatrag kroz vrijeme 55
 = tanh(wh (t) + Ux (t+1) +")
67 Propagacija unatrag kroz vrijeme Podsjetnik - osnovna RNN ćelija je zapravo jednoslojna neuronska mreža: h (t+1) = tanh(wh (t) + Ux (t+1) + b) 56
68 Intermezzo: tangens hiperbolni Tangens hiperbolni je zapravo skalirana funkcija logističke sigmoide: σ(x) = ex 1 + e x = e x tanh(x) = 1 e 2x 1 + e 2x = ex e x e x + e x tanh(x) = 2σ(2x) 1 d dx tanh(x) = 1 tanh2 (x) 57
69 Intermezzo: tangens hiperbolni 58
70 Propagacija unatrag kroz vrijeme Stanja (i ulazi) povratne neuronske mreže utječu na svaki idući izlaz h (t) = f(h (t k 1), x (t k) ) 0 k < t T Svako stanje h (t) prima budući (engl. upstream) gradijent kroz h (t+1) L h L(t) L(t+) = + (t) h (t) h (t) Računanje gradijenta s obzirom na parametre radimo u suprotnom smjeru od smjera protoka vremena Backpropagation through time - BPTT Zapravo najobičniji backprop 59
71 Propagacija unatrag kroz vrijeme - zadnji vremenski korak U zadnjem vremenskom koraku propagiramo gradijent gubitka (npr.) unakrsne entropije s obzirom na funkciju softmax izlaza povratne mreže o (t) 60

 = softmax(o(t) ) y")
72 Propagacija unatrag kroz vrijeme - zadnji vremenski korak L (t) o (t) = softmax(o(t) ) y (t) (5) 61
73 Propagacija unatrag kroz vrijeme - gradijent izlaznog sloja Podsjetnik: projekcija u izlazni sloj: o (t) = Vh (t) + c (6) L (t) o (t) = softmax(o(t) ) y (t) (7) Tražimo gradijente na matricu V, pristranost c u zadnjem koraku i gradijent koji propagira dalje, s obzirom na h (t) L V = L o (t) o (t) V = (softmax(o(t) ) y (t) )h (t)t (8) L c = L o (t) o (t) c = softmax(o(t) ) y (t) (9) L L(t) o (t) = h (t) o (t) h L(t+) + (t) h (t) Za zadnji vremenski korak, L(t+) h (t) = 0 = V T ( L(t) L(t+) ) + (10) o (t) h (t) 62
, te sad trebamo odrediti gradijente s")
 i prošlo skriveno")
74 Propagacija unatrag kroz vrijeme - zadnji vremenski korak Poznat nam je gradijent koji propagira kroz izlaz o (t), te sad trebamo odrediti gradijente s obzirom na parametre projekcije u skriveni sloj - matrica W, U i vektora b, te gradijente koji propagiraju dalje s obzirom na ulaz x (t) i prošlo skriveno stanje h (t 1) 63
75 Propagacija unatrag kroz vrijeme - gradijent ćelije Podsjetnik: projekcija u ćeliju: h (t) = tanh(wh (t 1) + Ux (t) + b) Koristeći pravilo ulančavanja, izraz ćemo razdvojiti na način da ćemo prvo računati gradijent kroz funkciju tangens hiperbolni, a potom gradijent s obzirom na matrice W, U i vektor b Radi čitkosti, stavljamo a (t) = Wh (t 1) + Ux (t) + b Gradijent tangensa hiperbolnog: tanh(x) x = 1 tanh 2 (x) Preko pravila ulančavanja: tanh(a (t) ) x = 1 tanh(a (t)2 ) = 1 h (t)2 (11) L a (t) = L h (t) h (t) a = (t) L tanh h (t) = L a (t) h 2 (1 h(t) (t) ) (12) 64
76 Propagacija unatrag kroz vrijeme - gradijent parametara ćelije Podsjetnik: projekcija u ćeliju, gradijent kroz a (t) : h (t) = tanh(wh (t 1) + Ux (t) + b) = tanh(a (t) ) L a = L 2 (1 (t) h(t) ) h (t) Gradijenti na parametre (W, U, b): L W = L U = L a (t) a (t) W = L a (t) a (t) U = L a (t) h(t 1)T (13) L a (t) x(t)t (14) L b = L a (t) a (t) b = L (15) a (t) 65
77 Propagacija unatrag kroz vrijeme - gradijent ulaza ćelije Podsjetnik: projekcija u ćeliju, gradijent kroz a (t) : Gradijenti na ulaze (h (t 1), x (t) ): h (t) = tanh(wh (t 1) + Ux (t) + b) L h (t 1) = L a = L 2 (1 (t) h(t) ) h (t) L x (t) = L a (t) a (t) h = L WT (16) (t 1) a (t) L a (t) = L a (t) UT (17) x (t) a (t) 66
78 Propagacija unatrag kroz vrijeme - algoritam Gradijenti na parametre se akumuliraju L T W = t=1 Jednako za sve ostake parametre Implementacijski: L (t) W = T t=1 L (t) h(t 1)T a (t) Petlja od T prema 0 Cache podataka koji su nužni za idući korak backpropa (koji?) Pamćenje sume gradijenata Gradijenti na ulaze - zašto? Na ulazu su vektori dobiveni treniranjem na drugom zadatku (EN wiki, Google news) Fine tuning Na ulazu je... nešto drugo? Duboke povratne neuronske mreže 67
79 Pitanja? 67
80 Dodatni materijali Uz (odličnu) knjigu, preporuča se pročitati ovim redoslijedom (1.-3.) 1. Peter s notes: Implementing a NN / RNN from scratch 2. Andrej Karpathy: The Unreasonable Effectiveness of Recurrent Neural Networks http: //karpathy.github.io/2015/05/21/rnn-effectiveness/ 3. Cristopher Olah: Understanding LSTM s http: //colah.github.io/posts/ understanding-lstms/ Za one koji žele znati (puno) više CS224d: Deep Learning for Natural Language Processing 68
81 References I O. Levy, Y. Goldberg, and I. Ramat-Gan. Linguistic regularities in sparse and explicit word representations. In CoNLL, pages , T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space. arxiv preprint arxiv: , J. Turian, L. Ratinov, and Y. Bengio. Word representations: a simple and general method for semi-supervised learning. In Proceedings of the 48th annual meeting of the association for computational linguistics, pages Association for Computational Linguistics, 2010.
Algoritam za množenje ulančanih matrica. Alen Kosanović Prirodoslovno-matematički fakultet Matematički odsjek
 Algoritam za množenje ulančanih matrica Alen Kosanović Prirodoslovno-matematički fakultet Matematički odsjek O problemu (1) Neka je A 1, A 2,, A n niz ulančanih matrica duljine n N, gdje su dimenzije matrice
Algoritam za množenje ulančanih matrica Alen Kosanović Prirodoslovno-matematički fakultet Matematički odsjek O problemu (1) Neka je A 1, A 2,, A n niz ulančanih matrica duljine n N, gdje su dimenzije matrice
Strojno učenje 3 (II dio) Struktura metoda/algoritama strojnog učenja. Tomislav Šmuc
 Struktura metoda/algoritama strojnog učenja. Tomislav Šmuc") Strojno učenje 3 (II dio) Struktura metoda/algoritama strojnog učenja Tomislav Šmuc PMF, Zagreb, 2013 Sastavnice (nadziranog) problema učenja Osnovni pojmovi Ulazni vektor varijabli (engl. attributes,
Strojno učenje 3 (II dio) Struktura metoda/algoritama strojnog učenja Tomislav Šmuc PMF, Zagreb, 2013 Sastavnice (nadziranog) problema učenja Osnovni pojmovi Ulazni vektor varijabli (engl. attributes,
TEORIJA SKUPOVA Zadaci
 TEORIJA SKUPOVA Zadai LOGIKA 1 I. godina 1. Zapišite simbolima: ( x nije element skupa S (b) d je član skupa S () F je podskup slupa S (d) Skup S sadrži skup R 2. Neka je S { x;2x 6} = = i neka je b =
TEORIJA SKUPOVA Zadai LOGIKA 1 I. godina 1. Zapišite simbolima: ( x nije element skupa S (b) d je član skupa S () F je podskup slupa S (d) Skup S sadrži skup R 2. Neka je S { x;2x 6} = = i neka je b =
Metoda parcijalnih najmanjih kvadrata: Regresijski model
 Sveučilište u Zagrebu Prirodoslovno-matematički fakultet Matematički odsjek Tamara Sente Metoda parcijalnih najmanjih kvadrata: Regresijski model Diplomski rad Voditelj rada: Izv.prof.dr.sc. Miljenko Huzak
Sveučilište u Zagrebu Prirodoslovno-matematički fakultet Matematički odsjek Tamara Sente Metoda parcijalnih najmanjih kvadrata: Regresijski model Diplomski rad Voditelj rada: Izv.prof.dr.sc. Miljenko Huzak
Deep Learning. Ali Ghodsi. University of Waterloo
 University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
Slika 1. Slika 2. Da ne bismo stalno izbacivali elemente iz skupa, mi ćemo napraviti još jedan niz markirano, gde će
 Permutacije Zadatak. U vreći se nalazi n loptica različitih boja. Iz vreće izvlačimo redom jednu po jednu lopticu i stavljamo jednu pored druge. Koliko različitih redosleda boja možemo da dobijemo? Primer
Permutacije Zadatak. U vreći se nalazi n loptica različitih boja. Iz vreće izvlačimo redom jednu po jednu lopticu i stavljamo jednu pored druge. Koliko različitih redosleda boja možemo da dobijemo? Primer
NEURONSKE MREŽE 1. predavanje
 NEURONSKE MREŽE 1. predavanje dr Zoran Ševarac sevarac@gmail.com FON, 2014. CILJ PREDAVANJA I VEŽBI IZ NEURONSKIH MREŽA Upoznavanje sa tehnologijom - osnovni pojmovi i modeli NM Mogućnosti i primena NM
NEURONSKE MREŽE 1. predavanje dr Zoran Ševarac sevarac@gmail.com FON, 2014. CILJ PREDAVANJA I VEŽBI IZ NEURONSKIH MREŽA Upoznavanje sa tehnologijom - osnovni pojmovi i modeli NM Mogućnosti i primena NM
Fajl koji je korišćen može se naći na
 Machine learning Tumačenje matrice konfuzije i podataka Fajl koji je korišćen može se naći na http://www.technologyforge.net/datasets/. Fajl se odnosi na pečurke (Edible mushrooms). Svaka instanca je definisana
Machine learning Tumačenje matrice konfuzije i podataka Fajl koji je korišćen može se naći na http://www.technologyforge.net/datasets/. Fajl se odnosi na pečurke (Edible mushrooms). Svaka instanca je definisana
UMJETNE NEURONSKE MREŽE
 SVEUČILIŠTE U RIJECI FILOZOFSKI FAKULTET U RIJECI Odsjek za politehniku Stella Paris UMJETNE NEURONSKE MREŽE (završni rad) Rijeka, 207. godine SVEUČILIŠTE U RIJECI FILOZOFSKI FAKULTET U RIJECI Studijski
SVEUČILIŠTE U RIJECI FILOZOFSKI FAKULTET U RIJECI Odsjek za politehniku Stella Paris UMJETNE NEURONSKE MREŽE (završni rad) Rijeka, 207. godine SVEUČILIŠTE U RIJECI FILOZOFSKI FAKULTET U RIJECI Studijski
Strojno učenje. Metoda potpornih vektora (SVM Support Vector Machines) Tomislav Šmuc
 Tomislav Šmuc") Strojno učenje Metoda potpornih vektora (SVM Support Vector Machines) Tomislav Šmuc Generativni i diskriminativni modeli Diskriminativni Generativni (Učenje linije koja razdvaja klase) Učenje modela za
Strojno učenje Metoda potpornih vektora (SVM Support Vector Machines) Tomislav Šmuc Generativni i diskriminativni modeli Diskriminativni Generativni (Učenje linije koja razdvaja klase) Učenje modela za
Red veze za benzen. Slika 1.
 Red veze za benzen Benzen C 6 H 6 je aromatično ciklično jedinjenje. Njegove dve rezonantne forme (ili Kekuléove structure), prema teoriji valentne veze (VB) prikazuju se uobičajeno kao na slici 1 a),
Red veze za benzen Benzen C 6 H 6 je aromatično ciklično jedinjenje. Njegove dve rezonantne forme (ili Kekuléove structure), prema teoriji valentne veze (VB) prikazuju se uobičajeno kao na slici 1 a),
Word2Vec Embedding. Embedding. Word Embedding 1.1 BEDORE. Word Embedding. 1.2 Embedding. Word Embedding. Embedding.
 c Word Embedding Embedding Word2Vec Embedding Word EmbeddingWord2Vec 1. Embedding 1.1 BEDORE 0 1 BEDORE 113 0033 2 35 10 4F y katayama@bedore.jp Word Embedding Embedding 1.2 Embedding Embedding Word Embedding
c Word Embedding Embedding Word2Vec Embedding Word EmbeddingWord2Vec 1. Embedding 1.1 BEDORE 0 1 BEDORE 113 0033 2 35 10 4F y katayama@bedore.jp Word Embedding Embedding 1.2 Embedding Embedding Word Embedding
Raspoznavanje objekata dubokim neuronskim mrežama
 SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA DIPLOMSKI RAD br. 696 Raspoznavanje objekata dubokim neuronskim mrežama Vedran Vukotić Zagreb, lipanj 2014. Zahvala Zahvaljujem se svom mentoru,
SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA DIPLOMSKI RAD br. 696 Raspoznavanje objekata dubokim neuronskim mrežama Vedran Vukotić Zagreb, lipanj 2014. Zahvala Zahvaljujem se svom mentoru,
Šime Šuljić. Funkcije. Zadavanje funkcije i područje definicije. š2004š 1
 Šime Šuljić Funkcije Zadavanje funkcije i područje definicije š2004š 1 Iz povijesti Dvojica Francuza, Pierre de Fermat i Rene Descartes, posebno su zadužila matematiku unijevši ideju koordinatne metode
Šime Šuljić Funkcije Zadavanje funkcije i područje definicije š2004š 1 Iz povijesti Dvojica Francuza, Pierre de Fermat i Rene Descartes, posebno su zadužila matematiku unijevši ideju koordinatne metode
LINEARNI MODELI STATISTIČKI PRAKTIKUM 2 2. VJEŽBE
 LINEARNI MODELI STATISTIČKI PRAKTIKUM 2 2. VJEŽBE Linearni model Promatramo jednodimenzionalni linearni model. Y = β 0 + p β k x k + ε k=1 x 1, x 2,..., x p - varijable poticaja (kontrolirane) ε - sl.
LINEARNI MODELI STATISTIČKI PRAKTIKUM 2 2. VJEŽBE Linearni model Promatramo jednodimenzionalni linearni model. Y = β 0 + p β k x k + ε k=1 x 1, x 2,..., x p - varijable poticaja (kontrolirane) ε - sl.
KLASIFIKACIJA NAIVNI BAJES. NIKOLA MILIKIĆ URL:
 KLASIFIKACIJA NAIVNI BAJES NIKOLA MILIKIĆ EMAIL: nikola.milikic@fon.bg.ac.rs URL: http://nikola.milikic.info ŠTA JE KLASIFIKACIJA? Zadatak određivanja klase kojoj neka instanca pripada instanca je opisana
KLASIFIKACIJA NAIVNI BAJES NIKOLA MILIKIĆ EMAIL: nikola.milikic@fon.bg.ac.rs URL: http://nikola.milikic.info ŠTA JE KLASIFIKACIJA? Zadatak određivanja klase kojoj neka instanca pripada instanca je opisana
Mathcad sa algoritmima
 P R I M J E R I P R I M J E R I Mathcad sa algoritmima NAREDBE - elementarne obrade - sekvence Primjer 1 Napraviti algoritam za sabiranje dva broja. NAREDBE - elementarne obrade - sekvence Primjer 1 POČETAK
P R I M J E R I P R I M J E R I Mathcad sa algoritmima NAREDBE - elementarne obrade - sekvence Primjer 1 Napraviti algoritam za sabiranje dva broja. NAREDBE - elementarne obrade - sekvence Primjer 1 POČETAK
Strojno učenje. Metoda potpornih vektora (SVM Support Vector Machines) Tomislav Šmuc
 Tomislav Šmuc") Strojno učenje Metoda potpornih vektora (SVM Support Vector Machines) Tomislav Šmuc Generativni i diskriminativni modeli Diskriminativni Generativni (Učenje linije koja razdvaja klase) Učenje modela za
Strojno učenje Metoda potpornih vektora (SVM Support Vector Machines) Tomislav Šmuc Generativni i diskriminativni modeli Diskriminativni Generativni (Učenje linije koja razdvaja klase) Učenje modela za
Projektovanje paralelnih algoritama II
 Projektovanje paralelnih algoritama II Primeri paralelnih algoritama, I deo Paralelni algoritmi za množenje matrica 1 Algoritmi za množenje matrica Ovde su data tri paralelna algoritma: Direktan algoritam
Projektovanje paralelnih algoritama II Primeri paralelnih algoritama, I deo Paralelni algoritmi za množenje matrica 1 Algoritmi za množenje matrica Ovde su data tri paralelna algoritma: Direktan algoritam
ZANIMLJIV NAČIN IZRAČUNAVANJA NEKIH GRANIČNIH VRIJEDNOSTI FUNKCIJA. Šefket Arslanagić, Sarajevo, BiH
 MAT-KOL (Banja Luka) XXIII ()(7), -7 http://wwwimviblorg/dmbl/dmblhtm DOI: 75/МК7A ISSN 5-6969 (o) ISSN 986-588 (o) ZANIMLJIV NAČIN IZRAČUNAVANJA NEKIH GRANIČNIH VRIJEDNOSTI FUNKCIJA Šefket Arslanagić,
MAT-KOL (Banja Luka) XXIII ()(7), -7 http://wwwimviblorg/dmbl/dmblhtm DOI: 75/МК7A ISSN 5-6969 (o) ISSN 986-588 (o) ZANIMLJIV NAČIN IZRAČUNAVANJA NEKIH GRANIČNIH VRIJEDNOSTI FUNKCIJA Šefket Arslanagić,
Vrednovanje raspoznavanja znamenki i slova konvolucijskim neuronskim mrežama
 SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA ZAVRŠNI RAD br. 3945 Vrednovanje raspoznavanja znamenki i slova konvolucijskim neuronskim mrežama Mislav Larva Zagreb, lipanj 2015. Sadržaj
SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA ZAVRŠNI RAD br. 3945 Vrednovanje raspoznavanja znamenki i slova konvolucijskim neuronskim mrežama Mislav Larva Zagreb, lipanj 2015. Sadržaj
GloVe: Global Vectors for Word Representation 1
 GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
An overview of word2vec
 An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
Oracle Spatial Koordinatni sustavi, projekcije i transformacije. Dalibor Kušić, mag. ing. listopad 2010.
 Oracle Spatial Koordinatni sustavi, projekcije i transformacije Dalibor Kušić, mag. ing. listopad 2010. Pregled Uvod Koordinatni sustavi Transformacije Projekcije Modeliranje 00:25 Oracle Spatial 2 Uvod
Oracle Spatial Koordinatni sustavi, projekcije i transformacije Dalibor Kušić, mag. ing. listopad 2010. Pregled Uvod Koordinatni sustavi Transformacije Projekcije Modeliranje 00:25 Oracle Spatial 2 Uvod
Formule za udaljenost točke do pravca u ravnini, u smislu lp - udaljenosti math.e Vol 28.
 1 math.e Hrvatski matematički elektronički časopis Formule za udaljenost točke do pravca u ravnini, u smislu lp - udaljenosti Banachovi prostori Funkcija udaljenosti obrada podataka optimizacija Aleksandra
1 math.e Hrvatski matematički elektronički časopis Formule za udaljenost točke do pravca u ravnini, u smislu lp - udaljenosti Banachovi prostori Funkcija udaljenosti obrada podataka optimizacija Aleksandra
Odre divanje smjera gledanja konvolucijskim neuronskim mrežama
 SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA DIPLOMSKI RAD br. 1013 Odre divanje smjera gledanja konvolucijskim neuronskim mrežama Mirko Jurić-Kavelj Zagreb, veljača 2015. Želim se zahvaliti
SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA DIPLOMSKI RAD br. 1013 Odre divanje smjera gledanja konvolucijskim neuronskim mrežama Mirko Jurić-Kavelj Zagreb, veljača 2015. Želim se zahvaliti
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Modelling of Parameters of the Air Purifying Process With a Filter- Adsorber Type Puri er by Use of Neural Network
 Strojarstvo 53 (3) 165-170 (2011) M. RAOS et. al., Modelling of Parameters of the Air... 165 CODEN STJSAO ISSN 0562-1887 ZX470/1507 UDK 697.941:532.52:004.032.26 Modelling of Parameters of the Air Purifying
Strojarstvo 53 (3) 165-170 (2011) M. RAOS et. al., Modelling of Parameters of the Air... 165 CODEN STJSAO ISSN 0562-1887 ZX470/1507 UDK 697.941:532.52:004.032.26 Modelling of Parameters of the Air Purifying
Sequence Models. Ji Yang. Department of Computing Science, University of Alberta. February 14, 2018
 Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
PRIPADNOST RJEŠENJA KVADRATNE JEDNAČINE DANOM INTERVALU
 MAT KOL Banja Luka) ISSN 0354 6969 p) ISSN 1986 58 o) Vol. XXI )015) 105 115 http://www.imvibl.org/dmbl/dmbl.htm PRIPADNOST RJEŠENJA KVADRATNE JEDNAČINE DANOM INTERVALU Bernadin Ibrahimpašić 1 Senka Ibrahimpašić
MAT KOL Banja Luka) ISSN 0354 6969 p) ISSN 1986 58 o) Vol. XXI )015) 105 115 http://www.imvibl.org/dmbl/dmbl.htm PRIPADNOST RJEŠENJA KVADRATNE JEDNAČINE DANOM INTERVALU Bernadin Ibrahimpašić 1 Senka Ibrahimpašić
Matematika (PITUP) Prof.dr.sc. Blaženka Divjak. Matematika (PITUP) FOI, Varaždin
 Prof.dr.sc. Blaženka Divjak. Matematika (PITUP) FOI, Varaždin") Matematika (PITUP) FOI, Varaždin Dio II Bez obzira kako nam se neki teorem činio korektnim, ne možemo biti sigurni da ne krije neku nesavršenost sve dok se nam ne čini prekrasnim G. Boole The moving power
Matematika (PITUP) FOI, Varaždin Dio II Bez obzira kako nam se neki teorem činio korektnim, ne možemo biti sigurni da ne krije neku nesavršenost sve dok se nam ne čini prekrasnim G. Boole The moving power
pretraživanje teksta Knuth-Morris-Pratt algoritam
 pretraživanje teksta Knuth-Morris-Pratt algoritam Jelena Držaić Oblikovanje i analiza algoritama Mentor: Prof.dr.sc Saša Singer 18. siječnja 2016. 18. siječnja 2016. 1 / 48 Sadržaj 1 Uvod 2 Pretraživanje
pretraživanje teksta Knuth-Morris-Pratt algoritam Jelena Držaić Oblikovanje i analiza algoritama Mentor: Prof.dr.sc Saša Singer 18. siječnja 2016. 18. siječnja 2016. 1 / 48 Sadržaj 1 Uvod 2 Pretraživanje
Artificial Neural Networks
 Artificial Neural Networks Short introduction Bojana Dalbelo Bašić, Marko Čupić, Jan Šnajder Faculty of Electrical Engineering and Computing University of Zagreb Zagreb, June 6, 2018 Dalbelo Bašić, Čupić,
Artificial Neural Networks Short introduction Bojana Dalbelo Bašić, Marko Čupić, Jan Šnajder Faculty of Electrical Engineering and Computing University of Zagreb Zagreb, June 6, 2018 Dalbelo Bašić, Čupić,
Algoritam za odre divanje ukupnog poravnanja dva grafa poravnanja parcijalnog ure daja
 SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA ZAVRŠNI RAD br. 000 Algoritam za odre divanje ukupnog poravnanja dva grafa poravnanja parcijalnog ure daja Mislav Bradač Zagreb, lipanj 2017.
SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA ZAVRŠNI RAD br. 000 Algoritam za odre divanje ukupnog poravnanja dva grafa poravnanja parcijalnog ure daja Mislav Bradač Zagreb, lipanj 2017.
Vektori u ravnini i prostoru. Rudolf Scitovski, Ivan Vazler. 10. svibnja Uvod 1
 Ekonomski fakultet Sveučilište J. J. Strossmayera u Osijeku Vektori u ravnini i prostoru Rudolf Scitovski, Ivan Vazler 10. svibnja 2012. Sadržaj 1 Uvod 1 2 Operacije s vektorima 2 2.1 Zbrajanje vektora................................
Ekonomski fakultet Sveučilište J. J. Strossmayera u Osijeku Vektori u ravnini i prostoru Rudolf Scitovski, Ivan Vazler 10. svibnja 2012. Sadržaj 1 Uvod 1 2 Operacije s vektorima 2 2.1 Zbrajanje vektora................................
PARALELNI ALGORITMI ZA PROBLEM GRUPIRANJA PODATAKA
 SVEUČILIŠTE U ZAGREBU PRIRODOSLOVNO MATEMATIČKI FAKULTET MATEMATIČKI ODSJEK Anto Čabraja PARALELNI ALGORITMI ZA PROBLEM GRUPIRANJA PODATAKA Diplomski rad Voditelj rada: doc. dr. sc. Goranka Nogo Zagreb,
SVEUČILIŠTE U ZAGREBU PRIRODOSLOVNO MATEMATIČKI FAKULTET MATEMATIČKI ODSJEK Anto Čabraja PARALELNI ALGORITMI ZA PROBLEM GRUPIRANJA PODATAKA Diplomski rad Voditelj rada: doc. dr. sc. Goranka Nogo Zagreb,
Sortiranje podataka. Ključne riječi: algoritmi za sortiranje, merge-sort, rekurzivni algoritmi. Data sorting
 Osječki matematički list 5(2005), 21 28 21 STUDENTSKA RUBRIKA Sortiranje podataka Alfonzo Baumgartner Stjepan Poljak Sažetak. Ovaj rad prikazuje jedno od rješenja problema sortiranja podataka u jednodimenzionalnom
Osječki matematički list 5(2005), 21 28 21 STUDENTSKA RUBRIKA Sortiranje podataka Alfonzo Baumgartner Stjepan Poljak Sažetak. Ovaj rad prikazuje jedno od rješenja problema sortiranja podataka u jednodimenzionalnom
Strojno učenje 3 (I dio) Evaluacija modela. Tomislav Šmuc
 Evaluacija modela. Tomislav Šmuc") Strojno učenje 3 (I dio) Evaluacija modela Tomislav Šmuc Pregled i. Greške (stvarna; T - na osnovu uzorka primjera) ii. Resampling metode procjene greške iii. Usporedba modela ili algoritama (na istim
Strojno učenje 3 (I dio) Evaluacija modela Tomislav Šmuc Pregled i. Greške (stvarna; T - na osnovu uzorka primjera) ii. Resampling metode procjene greške iii. Usporedba modela ili algoritama (na istim
Metode izračunavanja determinanti matrica n-tog reda
 Osječki matematički list 10(2010), 31 42 31 STUDENTSKA RUBRIKA Metode izračunavanja determinanti matrica n-tog reda Damira Keček Sažetak U članku su opisane metode izračunavanja determinanti matrica n-tog
Osječki matematički list 10(2010), 31 42 31 STUDENTSKA RUBRIKA Metode izračunavanja determinanti matrica n-tog reda Damira Keček Sažetak U članku su opisane metode izračunavanja determinanti matrica n-tog
Quasi-Newtonove metode
 Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Milan Milinčević Quasi-Newtonove metode Završni rad Osijek, 2016. Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Milan Milinčević
Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Milan Milinčević Quasi-Newtonove metode Završni rad Osijek, 2016. Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Milan Milinčević
Sveučilišni studijski centar za stručne studije. Zavod za matematiku i fiziku. Uvod u Matlab. Verzija 1.1
 Sveučilišni studijski centar za stručne studije Zavod za matematiku i fiziku Uvod u Matlab Verzija 1.1 Karmen Rivier, Arijana Burazin Mišura 1.11.2008 Uvod Matlab je interaktivni sistem namijenjen izvođenju
Sveučilišni studijski centar za stručne studije Zavod za matematiku i fiziku Uvod u Matlab Verzija 1.1 Karmen Rivier, Arijana Burazin Mišura 1.11.2008 Uvod Matlab je interaktivni sistem namijenjen izvođenju
Strojno učenje. Ansambli modela. Tomislav Šmuc
 Strojno učenje Ansambli modela Tomislav Šmuc Literatura 2 Dekompozicija prediktivne pogreške: Pristranost i varijanca modela Skup za učenje je T slučajno uzorkovan => predikcija ŷ slučajna varijabla p
Strojno učenje Ansambli modela Tomislav Šmuc Literatura 2 Dekompozicija prediktivne pogreške: Pristranost i varijanca modela Skup za učenje je T slučajno uzorkovan => predikcija ŷ slučajna varijabla p
Šta je to mašinsko učenje?
 MAŠINSKO UČENJE Šta je to mašinsko učenje? Disciplina koja omogućava računarima da uče bez eksplicitnog programiranja (Arthur Samuel 1959). 1. Generalizacija znanja na osnovu prethodnog iskustva (podataka
MAŠINSKO UČENJE Šta je to mašinsko učenje? Disciplina koja omogućava računarima da uče bez eksplicitnog programiranja (Arthur Samuel 1959). 1. Generalizacija znanja na osnovu prethodnog iskustva (podataka
Vedska matematika. Marija Miloloža
 Osječki matematički list 8(2008), 19 28 19 Vedska matematika Marija Miloloža Sažetak. Ovimčlankom, koji je gradivom i pristupom prilagod en prvim razredima srednjih škola prikazuju se drugačiji načini
Osječki matematički list 8(2008), 19 28 19 Vedska matematika Marija Miloloža Sažetak. Ovimčlankom, koji je gradivom i pristupom prilagod en prvim razredima srednjih škola prikazuju se drugačiji načini
ANALYSIS OF THE RELIABILITY OF THE "ALTERNATOR- ALTERNATOR BELT" SYSTEM
 I. Mavrin, D. Kovacevic, B. Makovic: Analysis of the Reliability of the "Alternator- Alternator Belt" System IVAN MAVRIN, D.Sc. DRAZEN KOVACEVIC, B.Eng. BRANKO MAKOVIC, B.Eng. Fakultet prometnih znanosti,
I. Mavrin, D. Kovacevic, B. Makovic: Analysis of the Reliability of the "Alternator- Alternator Belt" System IVAN MAVRIN, D.Sc. DRAZEN KOVACEVIC, B.Eng. BRANKO MAKOVIC, B.Eng. Fakultet prometnih znanosti,
Konstekstno slobodne gramatike
 Konstekstno slobodne gramatike Vežbe 07 - PPJ Nemanja Mićović nemanja_micovic@matfbgacrs Matematički fakultet, Univerzitet u Beogradu 4 decembar 2017 Sadržaj Konstekstno slobodne gramatike Rečenična forma
Konstekstno slobodne gramatike Vežbe 07 - PPJ Nemanja Mićović nemanja_micovic@matfbgacrs Matematički fakultet, Univerzitet u Beogradu 4 decembar 2017 Sadržaj Konstekstno slobodne gramatike Rečenična forma
Neural Word Embeddings from Scratch
 Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
Uvod u relacione baze podataka
 Uvod u relacione baze podataka Ana Spasić 2. čas 1 Mala studentska baza dosije (indeks, ime, prezime, datum rodjenja, mesto rodjenja, datum upisa) predmet (id predmeta, sifra, naziv, bodovi) ispitni rok
Uvod u relacione baze podataka Ana Spasić 2. čas 1 Mala studentska baza dosije (indeks, ime, prezime, datum rodjenja, mesto rodjenja, datum upisa) predmet (id predmeta, sifra, naziv, bodovi) ispitni rok
IDENTIFIKACIJA STRUKTURE NEURONSKE MREŽE U MJERENJU OČEKIVANE INFLACIJE
 SVEUČILIŠTE U SPLITU EKONOMSKI FAKULTET TEA POKLEPOVIĆ IDENTIFIKACIJA STRUKTURE NEURONSKE MREŽE U MJERENJU OČEKIVANE INFLACIJE DOKTORSKA DISERTACIJA Split, listopad 2017. godine SVEUČILIŠTE U SPLITU EKONOMSKI
SVEUČILIŠTE U SPLITU EKONOMSKI FAKULTET TEA POKLEPOVIĆ IDENTIFIKACIJA STRUKTURE NEURONSKE MREŽE U MJERENJU OČEKIVANE INFLACIJE DOKTORSKA DISERTACIJA Split, listopad 2017. godine SVEUČILIŠTE U SPLITU EKONOMSKI
NIPP. Implementing rules for metadata. Ivica Skender NSDI Working group for technical standards.
 Implementing rules for metadata Ivica Skender NSDI Working group for technical standards ivica.skender@gisdata.com Content Working group for technical standards INSPIRE Metadata implementing rule Review
Implementing rules for metadata Ivica Skender NSDI Working group for technical standards ivica.skender@gisdata.com Content Working group for technical standards INSPIRE Metadata implementing rule Review
Metode praćenja planova
 Metode praćenja planova Klasična metoda praćenja Suvremene metode praćenja gantogram mrežni dijagram Metoda vrednovanja funkcionalnosti sustava Gantogram VREMENSKO TRAJANJE AKTIVNOSTI A K T I V N O S T
Metode praćenja planova Klasična metoda praćenja Suvremene metode praćenja gantogram mrežni dijagram Metoda vrednovanja funkcionalnosti sustava Gantogram VREMENSKO TRAJANJE AKTIVNOSTI A K T I V N O S T
Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Sveučilišni nastavnički studij matematike i informatike. Sortiranje u linearnom vremenu
 Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Sveučilišni nastavnički studij matematike i informatike Tibor Pejić Sortiranje u linearnom vremenu Diplomski rad Osijek, 2011. Sveučilište J.
Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Sveučilišni nastavnički studij matematike i informatike Tibor Pejić Sortiranje u linearnom vremenu Diplomski rad Osijek, 2011. Sveučilište J.
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Matrice u Maple-u. Upisivanje matrica
 Matrice u Maple-u Tvrtko Tadić U prošlom broju upoznali ste se s matricama, a u ovom broju vidjeli ste neke njihove primjene. Mnoge je vjerojatno prepalo računanje s matricama. Pa tko će raditi svo to
Matrice u Maple-u Tvrtko Tadić U prošlom broju upoznali ste se s matricama, a u ovom broju vidjeli ste neke njihove primjene. Mnoge je vjerojatno prepalo računanje s matricama. Pa tko će raditi svo to
Machine learning in solid-state physics and statistical physics
 UNIVERSITY OF ZAGREB FACULTY OF SCIENCE DEPARTMENT OF PHYSICS Lovro Vrček Machine learning in solid-state physics and statistical physics Master Thesis Zagreb, 2018. SVEUČILIŠTE U ZAGREBU PRIRODOSLOVNO-MATEMATIČKI
UNIVERSITY OF ZAGREB FACULTY OF SCIENCE DEPARTMENT OF PHYSICS Lovro Vrček Machine learning in solid-state physics and statistical physics Master Thesis Zagreb, 2018. SVEUČILIŠTE U ZAGREBU PRIRODOSLOVNO-MATEMATIČKI
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
L A T E X 1. predavanje
 L A T E X 1. predavanje Ivica Nakić PMF-MO Računarski praktikum 3 nakic@math.hr LAT E X- predavanje 1 - p. 1 Što je LAT E X? Mali primjer PDF dokument Zašto LAT E X? LAT E X- predavanje 1 - p. 2 Što je
L A T E X 1. predavanje Ivica Nakić PMF-MO Računarski praktikum 3 nakic@math.hr LAT E X- predavanje 1 - p. 1 Što je LAT E X? Mali primjer PDF dokument Zašto LAT E X? LAT E X- predavanje 1 - p. 2 Što je
Matrične dekompozicije i primjene
 Sveučilište JJ Strossmayera u Osijeku Odjel za matematiku Goran Pavić Matrične dekompozicije i primjene Diplomski rad Osijek, 2012 Sveučilište JJ Strossmayera u Osijeku Odjel za matematiku Goran Pavić
Sveučilište JJ Strossmayera u Osijeku Odjel za matematiku Goran Pavić Matrične dekompozicije i primjene Diplomski rad Osijek, 2012 Sveučilište JJ Strossmayera u Osijeku Odjel za matematiku Goran Pavić
word2vec Parameter Learning Explained
 word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
Numeričke metode u ekonomiji Dr. sc. Josip Matejaš, EFZG
 Numeričke metode u ekonomiji Dr. sc. Josip Matejaš, EFZG http://web.math.hr/~rogina/001096/num_anal.pdf Numerička analiza G R E Š K E Prvi uvodni primjer 50 50 1/ 5 33554 43 1.414 1356... 50 1.414 1356
Numeričke metode u ekonomiji Dr. sc. Josip Matejaš, EFZG http://web.math.hr/~rogina/001096/num_anal.pdf Numerička analiza G R E Š K E Prvi uvodni primjer 50 50 1/ 5 33554 43 1.414 1356... 50 1.414 1356
Summary Modeling of nonlinear reactive electronic circuits using artificial neural networks
 Summary Modeling of nonlinear reactive electronic circuits using artificial neural networks The problem of modeling of electronic components and circuits has been interesting since the first component
Summary Modeling of nonlinear reactive electronic circuits using artificial neural networks The problem of modeling of electronic components and circuits has been interesting since the first component
Lekcija 1: Osnove. Elektrotehnički fakultet Sarajevo 2012/2013
 Lekcija : Osnove multivarijabilnih sistema upravljanja Prof.dr.sc. Jasmin Velagić Elektrotehnički fakultet Sarajevo Kolegij: Multivarijabilni ij i sistemi i 0/03 Kolegij: Multivarijabilni sistemi Predmetni
Lekcija : Osnove multivarijabilnih sistema upravljanja Prof.dr.sc. Jasmin Velagić Elektrotehnički fakultet Sarajevo Kolegij: Multivarijabilni ij i sistemi i 0/03 Kolegij: Multivarijabilni sistemi Predmetni
Deep Learning for NLP Part 2
 Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
PRIMJENA METODE PCA NAD SKUPOM SLIKA ZNAKOVA
 SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA ZAVRŠNI RAD br. 81 PRIMJENA METODE PCA NAD SKUPOM SLIKA ZNAKOVA Ivana Sučić Zagreb, srpanj 009 Sadržaj 1. Uvod... 1. Normalizacija slika znakova....1.
SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA ZAVRŠNI RAD br. 81 PRIMJENA METODE PCA NAD SKUPOM SLIKA ZNAKOVA Ivana Sučić Zagreb, srpanj 009 Sadržaj 1. Uvod... 1. Normalizacija slika znakova....1.
PEARSONOV r koeficijent korelacije [ ]
![PEARSONOV r koeficijent korelacije [ ]](/thumbs/92/109804180.jpg "PEARSONOV r koeficijent korelacije [ ]") PEARSONOV r koeficijent korelacije U prošlim vježbama obradili smo Spearmanov Ro koeficijent korelacije, a sada nas čeka Pearsonov koeficijent korelacije ili Produkt-moment koeficijent korelacije. To je
PEARSONOV r koeficijent korelacije U prošlim vježbama obradili smo Spearmanov Ro koeficijent korelacije, a sada nas čeka Pearsonov koeficijent korelacije ili Produkt-moment koeficijent korelacije. To je
Primjena Fuzzy ARTMAP neuronske mreže za indeksiranje i klasifikaciju dokumenata
 SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA DIPLOMSKI RAD br. 568 Primjena Fuzzy ARTMAP neuronske mreže za indeksiranje i klasifikaciju dokumenata Stjepan Buljat Zagreb, studeni 2005. ...mojoj
SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA DIPLOMSKI RAD br. 568 Primjena Fuzzy ARTMAP neuronske mreže za indeksiranje i klasifikaciju dokumenata Stjepan Buljat Zagreb, studeni 2005. ...mojoj
KVADRATNE INTERPOLACIJSKE METODE ZA JEDNODIMENZIONALNU BEZUVJETNU LOKALNU OPTIMIZACIJU 1
 MAT KOL (Banja Luka) ISSN 0354 6969 (p), ISSN 1986 5228 (o) Vol. XXII (1)(2016), 5 19 http://www.imvibl.org/dmbl/dmbl.htm KVADRATNE INTERPOLACIJSKE METODE ZA JEDNODIMENZIONALNU BEZUVJETNU LOKALNU OPTIMIZACIJU
MAT KOL (Banja Luka) ISSN 0354 6969 (p), ISSN 1986 5228 (o) Vol. XXII (1)(2016), 5 19 http://www.imvibl.org/dmbl/dmbl.htm KVADRATNE INTERPOLACIJSKE METODE ZA JEDNODIMENZIONALNU BEZUVJETNU LOKALNU OPTIMIZACIJU
ANALIZA I IMPLEMENTACIJA ALGORITMA ZA SMANJENJE DIMENZIONALNOSTI DEKOMPOZICIJOM NA SINGULARNE VRIJEDNOSTI
 SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA DIPLOMSKI RAD br. 569 ANALIZA I IMPLEMENTACIJA ALGORITMA ZA SMANJENJE DIMENZIONALNOSTI DEKOMPOZICIJOM NA SINGULARNE VRIJEDNOSTI Zagreb, studeni
SVEUČILIŠTE U ZAGREBU FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA DIPLOMSKI RAD br. 569 ANALIZA I IMPLEMENTACIJA ALGORITMA ZA SMANJENJE DIMENZIONALNOSTI DEKOMPOZICIJOM NA SINGULARNE VRIJEDNOSTI Zagreb, studeni
Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku
 Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Mateja Dumić Cjelobrojno linearno programiranje i primjene Diplomski rad Osijek, 2014. Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku
Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Mateja Dumić Cjelobrojno linearno programiranje i primjene Diplomski rad Osijek, 2014. Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku
ALGORITMI PODIJELI PA VLADAJ
 SVEUČILIŠTE U ZAGREBU PRIRODOSLOVNO MATEMATIČKI FAKULTET MATEMATIČKI ODSJEK Petra Penzer ALGORITMI PODIJELI PA VLADAJ Diplomski rad Voditelj rada: izv.prof.dr.sc. Saša Singer Zagreb, rujan 2016. Ovaj diplomski
SVEUČILIŠTE U ZAGREBU PRIRODOSLOVNO MATEMATIČKI FAKULTET MATEMATIČKI ODSJEK Petra Penzer ALGORITMI PODIJELI PA VLADAJ Diplomski rad Voditelj rada: izv.prof.dr.sc. Saša Singer Zagreb, rujan 2016. Ovaj diplomski
Simetrične matrice, kvadratne forme i matrične norme
 Sveučilište JJStrossmayera u Osijeku Odjel za matematiku Sveučilišni preddiplomski studij matematike Martina Dorić Simetrične matrice, kvadratne forme i matrične norme Završni rad Osijek, 2014 Sveučilište
Sveučilište JJStrossmayera u Osijeku Odjel za matematiku Sveučilišni preddiplomski studij matematike Martina Dorić Simetrične matrice, kvadratne forme i matrične norme Završni rad Osijek, 2014 Sveučilište
Sveučilište u Zagrebu Fakultet prometnih znanosti Diplomski studij. Umjetna inteligencija - Genetski algoritmi 47895/47816 UMINTELI HG/
 Sveučilište u Zagrebu Fakultet prometnih znanosti Diplomski studij Umjetna inteligencija - Genetski algoritmi 47895/47816 UMINTELI HG/2008-2009 Genetski algoritam Postupak stohastičkog pretraživanja prostora
Sveučilište u Zagrebu Fakultet prometnih znanosti Diplomski studij Umjetna inteligencija - Genetski algoritmi 47895/47816 UMINTELI HG/2008-2009 Genetski algoritam Postupak stohastičkog pretraživanja prostora
Deep Learning. Recurrent Neural Network (RNNs) Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning
 Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning") Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
NAPREDNI FIZIČKI PRAKTIKUM 1 studij Matematika i fizika; smjer nastavnički MJERENJE MALIH OTPORA
 NAPREDNI FIZIČKI PRAKTIKUM 1 studij Matematika i fizika; smjer nastavnički MJERENJE MALIH OTPORA studij Matematika i fizika; smjer nastavnički NFP 1 1 ZADACI 1. Mjerenjem geometrijskih dimenzija i otpora
NAPREDNI FIZIČKI PRAKTIKUM 1 studij Matematika i fizika; smjer nastavnički MJERENJE MALIH OTPORA studij Matematika i fizika; smjer nastavnički NFP 1 1 ZADACI 1. Mjerenjem geometrijskih dimenzija i otpora
Neural Network Language Modeling
 Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Linearno programiranje i primjene
 Sveučilište J.J.Strossmayera u Osijeku Odjel za matematiku Rebeka Čordaš Linearno programiranje i primjene Diplomski rad Osijek, 2014. Sveučilište J.J.Strossmayera u Osijeku Odjel za matematiku Rebeka
Sveučilište J.J.Strossmayera u Osijeku Odjel za matematiku Rebeka Čordaš Linearno programiranje i primjene Diplomski rad Osijek, 2014. Sveučilište J.J.Strossmayera u Osijeku Odjel za matematiku Rebeka
1.1 Algoritmi. 2 Uvod
 GLAVA 1 Uvod Realizacija velikih računarskih sistema je vrlo složen zadatak iz mnogih razloga. Jedan od njih je da veliki programski projekti zahtevaju koordinisani trud timova stručnjaka različitog profila.
GLAVA 1 Uvod Realizacija velikih računarskih sistema je vrlo složen zadatak iz mnogih razloga. Jedan od njih je da veliki programski projekti zahtevaju koordinisani trud timova stručnjaka različitog profila.
UPUTE ZA OBLIKOVANJE DIPLOMSKOG RADA
 1 UPUTE ZA OBLIKOVANJE DIPLOMSKOG RADA Opseg je diplomskog rada ograničen na 30 stranica teksta (broje se i arapskim brojevima označavaju stranice od početka Uvoda do kraja rada). Veličina je stranice
1 UPUTE ZA OBLIKOVANJE DIPLOMSKOG RADA Opseg je diplomskog rada ograničen na 30 stranica teksta (broje se i arapskim brojevima označavaju stranice od početka Uvoda do kraja rada). Veličina je stranice
Nilpotentni operatori i matrice
 Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Sveučilišni preddiplomski studij matematike Nikolina Romić Nilpotentni operatori i matrice Završni rad Osijek, 2016. Sveučilište J. J. Strossmayera
Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Sveučilišni preddiplomski studij matematike Nikolina Romić Nilpotentni operatori i matrice Završni rad Osijek, 2016. Sveučilište J. J. Strossmayera
ATOMSKA APSORP SORPCIJSKA TROSKOP
 ATOMSKA APSORP SORPCIJSKA SPEKTROS TROSKOP OPIJA Written by Bette Kreuz Produced by Ruth Dusenbery University of Michigan-Dearborn 2000 Apsorpcija i emisija svjetlosti Fizika svjetlosti Spectroskopija
ATOMSKA APSORP SORPCIJSKA SPEKTROS TROSKOP OPIJA Written by Bette Kreuz Produced by Ruth Dusenbery University of Michigan-Dearborn 2000 Apsorpcija i emisija svjetlosti Fizika svjetlosti Spectroskopija
Sveučilište Josipa Jurja Strossmayera u Osijeku Odjel za matematiku
 Sveučilište Josipa Jurja Strossmayera u Osijeku Odjel za matematiku Valentina Volmut Ortogonalni polinomi Diplomski rad Osijek, 2016. Sveučilište Josipa Jurja Strossmayera u Osijeku Odjel za matematiku
Sveučilište Josipa Jurja Strossmayera u Osijeku Odjel za matematiku Valentina Volmut Ortogonalni polinomi Diplomski rad Osijek, 2016. Sveučilište Josipa Jurja Strossmayera u Osijeku Odjel za matematiku
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Rešenja zadataka za vežbu na relacionoj algebri i relacionom računu
 Rešenja zadataka za vežbu na relacionoj algebri i relacionom računu 1. Izdvojiti ime i prezime studenata koji su rođeni u Beogradu. (DOSIJE WHERE MESTO_RODJENJA='Beograd')[IME, PREZIME] where mesto_rodjenja='beograd'
Rešenja zadataka za vežbu na relacionoj algebri i relacionom računu 1. Izdvojiti ime i prezime studenata koji su rođeni u Beogradu. (DOSIJE WHERE MESTO_RODJENJA='Beograd')[IME, PREZIME] where mesto_rodjenja='beograd'
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Adaptation of Neural Networks Using Genetic Algorithms
 CROATICA CHEMICA ACTA CCACAA68 (1) 29-38 (1995) ISSN 0011-1643 CCA-2209 Conference Paper Adaptation of Neural Networks Using Genetic Algorithms Tin Ilakovac Ruđer Bošković Institute, POB 1016, HR-41001
CROATICA CHEMICA ACTA CCACAA68 (1) 29-38 (1995) ISSN 0011-1643 CCA-2209 Conference Paper Adaptation of Neural Networks Using Genetic Algorithms Tin Ilakovac Ruđer Bošković Institute, POB 1016, HR-41001
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Sparse representations of signals for information recovery from incomplete data
 Faculty of Science Department of Mathematics Marko Filipović Sparse representations of signals for information recovery from incomplete data Doctoral thesis Zagreb, 2013. Prirodoslovno-matematički fakultet
Faculty of Science Department of Mathematics Marko Filipović Sparse representations of signals for information recovery from incomplete data Doctoral thesis Zagreb, 2013. Prirodoslovno-matematički fakultet
Slide credit from Hung-Yi Lee & Richard Socher
 Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
APPROPRIATENESS OF GENETIC ALGORITHM USE FOR DISASSEMBLY SEQUENCE OPTIMIZATION
 JPE (2015) Vol.18 (2) Šebo, J. Original Scientific Paper APPROPRIATENESS OF GENETIC ALGORITHM USE FOR DISASSEMBLY SEQUENCE OPTIMIZATION Received: 17 July 2015 / Accepted: 25 Septembre 2015 Abstract: One
JPE (2015) Vol.18 (2) Šebo, J. Original Scientific Paper APPROPRIATENESS OF GENETIC ALGORITHM USE FOR DISASSEMBLY SEQUENCE OPTIMIZATION Received: 17 July 2015 / Accepted: 25 Septembre 2015 Abstract: One
Deep Learning Basics Lecture 10: Neural Language Models. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Funkcijske jednadºbe
 MEMO pripreme 2015. Marin Petkovi, 9. 6. 2015. Funkcijske jednadºbe Uvod i osnovne ideje U ovom predavanju obradit emo neke poznate funkcijske jednadºbe i osnovne ideje rje²avanja takvih jednadºbi. Uobi
MEMO pripreme 2015. Marin Petkovi, 9. 6. 2015. Funkcijske jednadºbe Uvod i osnovne ideje U ovom predavanju obradit emo neke poznate funkcijske jednadºbe i osnovne ideje rje²avanja takvih jednadºbi. Uobi
Improved Learning through Augmenting the Loss
 Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Rekurzivni algoritmi POGLAVLJE Algoritmi s rekurzijama
 POGLAVLJE 8 Rekurzivni algoritmi U prošlom dijelu upoznali smo kako rekurzije možemo implementirati preko stogova, u ovom dijelu promotriti ćemo probleme koje se mogu izraziti na rekurzivan način Vremenska
POGLAVLJE 8 Rekurzivni algoritmi U prošlom dijelu upoznali smo kako rekurzije možemo implementirati preko stogova, u ovom dijelu promotriti ćemo probleme koje se mogu izraziti na rekurzivan način Vremenska
Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku
 Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Marija Brnatović Blok šifre i DES-kriptosustav Diplomski rad Osijek, 2012. Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Marija
Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Marija Brnatović Blok šifre i DES-kriptosustav Diplomski rad Osijek, 2012. Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Marija
Karakteri konačnih Abelovih grupa
 Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Sveučilišni preddiplomski studij matematike Matija Klarić Karakteri konačnih Abelovih grupa Završni rad Osijek, 2015. Sveučilište J. J. Strossmayera
Sveučilište J. J. Strossmayera u Osijeku Odjel za matematiku Sveučilišni preddiplomski studij matematike Matija Klarić Karakteri konačnih Abelovih grupa Završni rad Osijek, 2015. Sveučilište J. J. Strossmayera
A Tutorial On Backward Propagation Through Time (BPTT) In The Gated Recurrent Unit (GRU) RNN
 In The Gated Recurrent Unit (GRU) RNN") A Tutorial On Backward Propagation Through Time (BPTT In The Gated Recurrent Unit (GRU RNN Minchen Li Department of Computer Science The University of British Columbia minchenl@cs.ubc.ca Abstract In this
A Tutorial On Backward Propagation Through Time (BPTT In The Gated Recurrent Unit (GRU RNN Minchen Li Department of Computer Science The University of British Columbia minchenl@cs.ubc.ca Abstract In this