Natural Language Processing and Recurrent Neural Networks
|
|
|
- Jennifer Black
- 5 years ago
- Views:
Transcription
1 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018
2 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo
3 What is NLP? Natural Language? : Huge amount of information available pertaining to different languages in terms of text and speech. Processing? : The idea is to use computer to understand languages to do a bunch of stuff.
4 Uses of Natural Language Processing Spell checking, keyword search, synonyms Automated translation Sentiment analysis of movie reviews Speech recognition, complex question answering Language modelling
5 Why is language different? Language is essentially a signalling system by which we convey information. Interestingly language is mostly discrete/categorical in nature. These signals are communicated in different ways: Sound, Text, Image, Gesture. Huge vocabulary results in sparsity problem for encoding the symbolic/categorical signals. [We will talk about it later!]
6 Why is NLP difficult? Inherent ambiguity in human language. Here is an example of a real newspaper (Time Magazine) headline The pope s baby steps on gays. Efficiently representing word as a vector of numbers is challenging. Language conveys information in a sequential manner. [This is where RNN is going to help us!]
7 Word vector representation Batman will beat Superman with enough preparation time. One easy way to represent Batman is using one-hot vector. [ ] Step 1: Using a corpus of words, we can build a dictionary or vocabulary. [Which is essentially a vector of words arranged, not necessarily in alphabetic order.] Step 2: i th word in that dictionary will be represented by i th unit vector. (1)
8 Issues with one-hot representation If your dictionary consists of T words. Each word will be represented by T 1 dimensional vectors. T is usually very large! 20K(Speech)- 500K(Machine translation)- 13M(Google 1TB corpus). Localist representation. Doesn t give any inherent notion of association between words.
9 Hurricane in Tallahassee Hurricane in Florida If one searches one of these two sentences, search engine should return results for other sentence as well. In one-hot representation, vector representations of Tallahassee and Florida are orthogonal.
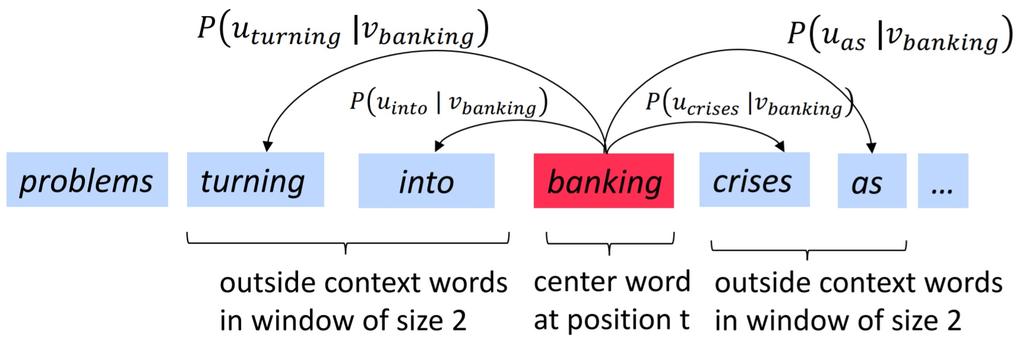
10 Distributional Similarity The idea of distributional similarity was first coined by linguist Z.S. Harris (1954). Later this idea has been used to represent words by means of its neighbors (Bengio et. al, 03, Mikolov et. al,13). Neighboring words will now represent banking....debt problems turning into banking crises as has......europe needs unified banking regulation to replace the...
11 word2vec The general idea is to define a model that predicts between a center word w t and neighboring context words in terms of word vectors and P(w t w t ) or P(w t w t ). Goal: Obtain a vector representation that maximizes P(w t w t ) or P(w t w t ). Skip-gram model: Predict context words given a center word. Continuous bag-of-words model: Predict center word from a bag of context words.
12 skip-gram For each position t = 1(1)T, predict context words within a window of fixed size m, given center word w j L(θ) = T t=1 m j m,j 0 The goal is to minimize J(θ) where P(w t+j w t ; θ) (2) J(θ) = 1 T log L(θ) = 1 T T log P(w t+j w t ) (3) t=1 m j m,j 0
13
14 Two different vectors are used to represent a word w. v w when w is a center word. u w when w is a context word. For any j 0, P(w t+j w t ) = exp(u T w t+j v wt ) V i=1 exp(ut w t+i v w t ) This is called softmax function.
15 Suppose we are using a d-dimensional vector to represent a word and we have V -many wordsθ = v aardvark v zyzzyva u aardvark u zyzzyva R 2dV
16 The gradient of J(θ) is calculated from Update equation v wt P(w t+j w t ) = u wt+j V P(w t+i w t )u wt+i i=1 θ new = θ old α θ J(θ) or elementwise it is θ new j = θ old j α θj old J(θ)
17 Stochastic Gradient Descent For a large corpus, updating entire gradient vector is extremely expensive. Calculate the gradient for one randomly selected center word J t (θ). Update equation θ new = θ old α θ J t (θ)
18
19 CBOW Unlike skip-gram, we predict center word w.r.t context words. Cost function J(θ) = 1 T T log P(w t w t m,, w t 1, w t+1,, w t+m ) t=1 Softmax function defined as P(v wt û) = exp(v T w t û) V i=1 exp(v T w t û) where û = u t m + + u t 1 + u t u t+m 2m
20 Recurrent Neural Networks
21 one-hot word vectors x (t) R V Word embedding e (t) = Ex (t) Hidden states h (t) = g(w h h (t 1) + W e e (t) + b) h (0) is the initial hidden state usually a vector of 0s where g is some activation function(sigmoid, tanh, ReLu). Output probability ŷ (t) = softmax(uh (t) + b 1 )
22 How to Train an RNN Language Model Get a Big corpus of text which is a sequence of words: x (1), x (2),, x (T ). Compute the output distribution ŷ (t) for every time step t. This is essentially the probability distribution of every word given the previously occured words. Loss function- cross entropy y (t) = x (t+1) J (t) (θ) = V t=1 y (t) j log ŷ (t) j
23 Overall cost function is J(θ) = T J (t) (θ) t=1 Updating parameters in NN architecture using J(θ) is called back-propagation.
24
25 Backpropagation through time We need to update the parameters using gradient descent. For example let us look at the update of U. We need to calculate the J U using J U = t J ŷ (t) ŷ (t) U b 1 can be updated in a similar way.
26 Next we are going to update W h. Notice that, at each time step t, J(θ) depends on W h through h (t) which itself depends on h (t 1). So we are going to backpropagate over time steps t = T, T 1,, 0 summing the gradients as we go. Update equation J (t) W h = J ŷ (t) ŷ (t) h (t) h (t) W h
27 Since h (t) depends on h (t 1), J (t) W h = J(t) ŷ (t) ŷ (t) h (t) h (t) W h J (t) W h = t k=1 J (t) ŷ (t) h (t) h (t 1) ŷ (t) h (t) h (t 1) W h J = W h t t k=1 J (t) ŷ (t) ŷ (t) h (t) h (t) h (k) h (k) W h
28 Calculating gradient of W e and b is comparatively easier. J = W e t J b = t J ŷ (t) h (t) ŷ (t) h (t) W e J ŷ (t) h (t) ŷ (t) h (t) b
29 Vanishing and Exploding gradient problem Derivatives through time can be very small or very large very quickly. (Bengio et al 1994) J = W h t t k=1 J (t) ŷ (t) ŷ (t) h (t) h (t) h (k) h (k) W h In NLP, vanishing gradient is an issue The cat, which already ate a plate full of fish, was full. One trick to deal with this problem- Gradient clipping. Not efficient.
30 Gated Recurrent Unit An efficient way to deal with vanishing gradient problem is to use more complicated hidden units!(cho et al 2014) Main idea is to keep around memories to capture long term dependencies. Essentially this is sort of a simpler version of LSTM which will be discussed later.
31 GRU first computes an update gate(another layer!) based on current input word vector and hidden state z (t) = σ(w z x (t) + U z h (t 1) ) And a reset gate similarly but with different parameters r (t) = σ(w r x (t) + U r h (t 1) ) Sigmoid activation is used because we want the values to be either close to 0 or close to 1. (Explained later!)
32 New memory content h (t) = g(wx (t) + r (t) Uh (t 1) ) If reset step is very close to 0, then this ignores previous memory and stores the new word information. Current time step update h (t) = z (t) h (t 1) + (1 z (t) ) h (t)
33 If reset is close to 0, ignore previous hidden state which allows model to drop information that is irrelevant in the future. Update gate controls how much of past state should matter now. If update gate is close to 1, then we can copy information in that unit through many time steps! Units with short-term dependencies often have reset gates very active.
34
35
36 Long short-term memory(hochreiter and Schmidhuber, 1997) Input gate Output gate Forget gate New memory cell i (t) = σ(w i x (t) + U i h (t 1) ) o (t) = σ(w o x (t) + U o h (t 1) ) f (t) = σ(w f x (t) + U f h (t 1) ) c (t) = g(w c x (t) + U c h (t 1) )
37 Final memory cell Final hidden state c (t) = f (t) c (t 1) + i (t) c (t) h t = o (t) g(c (t) ) Memory cells can keep information intact, unless input makes them forget it or overwrite it with new input. Cell can decide to output the information of just to store it.
38
39 Discussion All the RNN models discussed here can only take previous words into consideration. Solution- Bidirectional RNN. RNNs are a great way for language modelling, machine translation, speech recognition, name entity tagging.
40 Thank you
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Deep Learning. Recurrent Neural Network (RNNs) Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning
 Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning") Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Neural Networks Language Models
 Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Recurrent Neural Networks. deeplearning.ai. Why sequence models?
 Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
arxiv: v3 [cs.lg] 14 Jan 2018
![arxiv: v3 [cs.lg] 14 Jan 2018](/thumbs/92/109503708.jpg "arxiv: v3 [cs.lg] 14 Jan 2018") A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
Deep Learning and Lexical, Syntactic and Semantic Analysis. Wanxiang Che and Yue Zhang
 Deep Learning and Lexical, Syntactic and Semantic Analysis Wanxiang Che and Yue Zhang 2016-10 Part 2: Introduction to Deep Learning Part 2.1: Deep Learning Background What is Machine Learning? From Data
Deep Learning and Lexical, Syntactic and Semantic Analysis Wanxiang Che and Yue Zhang 2016-10 Part 2: Introduction to Deep Learning Part 2.1: Deep Learning Background What is Machine Learning? From Data
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Models. Ji Yang. Department of Computing Science, University of Alberta. February 14, 2018
 Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook
 Sumit Chopra Facebook") Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Improved Learning through Augmenting the Loss
 Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Recurrent and Recursive Networks
 Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
GloVe: Global Vectors for Word Representation 1
 GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
Slide credit from Hung-Yi Lee & Richard Socher
 Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
word2vec Parameter Learning Explained
 word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Lecture 15: Exploding and Vanishing Gradients
 Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
An overview of word2vec
 An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
Modelling Time Series with Neural Networks. Volker Tresp Summer 2017
 Modelling Time Series with Neural Networks Volker Tresp Summer 2017 1 Modelling of Time Series The next figure shows a time series (DAX) Other interesting time-series: energy prize, energy consumption,
Modelling Time Series with Neural Networks Volker Tresp Summer 2017 1 Modelling of Time Series The next figure shows a time series (DAX) Other interesting time-series: energy prize, energy consumption,
Recurrent Neural Networks Deep Learning Lecture 5. Efstratios Gavves
 Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
CS224n: Natural Language Processing with Deep Learning 1
 CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
Natural Language Processing with Deep Learning CS224N/Ling284. Richard Socher Lecture 2: Word Vectors
 Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Structured Neural Networks (I)
") Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
The representation of word and sentence
 2vec Jul 4, 2017 Presentation Outline 2vec 1 2 2vec 3 4 5 6 discrete representation taxonomy:wordnet Example:good 2vec Problems 2vec synonyms: adept,expert,good It can t keep up to date It can t accurate
2vec Jul 4, 2017 Presentation Outline 2vec 1 2 2vec 3 4 5 6 discrete representation taxonomy:wordnet Example:good 2vec Problems 2vec synonyms: adept,expert,good It can t keep up to date It can t accurate
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Neural Networks. Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016
 Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
 2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
Natural Language Understanding. Recap: probability, language models, and feedforward networks. Lecture 12: Recurrent Neural Networks and LSTMs
 Natural Language Understanding Lecture 12: Recurrent Neural Networks and LSTMs Recap: probability, language models, and feedforward networks Simple Recurrent Networks Adam Lopez Credits: Mirella Lapata
Natural Language Understanding Lecture 12: Recurrent Neural Networks and LSTMs Recap: probability, language models, and feedforward networks Simple Recurrent Networks Adam Lopez Credits: Mirella Lapata
Recurrent Neural Network
 Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
EE-559 Deep learning LSTM and GRU
 EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
arxiv: v3 [cs.cl] 30 Jan 2016
![arxiv: v3 [cs.cl] 30 Jan 2016](/thumbs/72/66377864.jpg "arxiv: v3 [cs.cl] 30 Jan 2016") word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
Lecture 6: Neural Networks for Representing Word Meaning
 Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
CSCI 315: Artificial Intelligence through Deep Learning
 CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
Introduction to RNNs!
 Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
CS224N: Natural Language Processing with Deep Learning Winter 2017 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2017 Midterm Exam This examination consists of 14 printed sides, 5 questions, and 100 points. The exam accounts for 17% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2017 Midterm Exam This examination consists of 14 printed sides, 5 questions, and 100 points. The exam accounts for 17% of your total grade.
Tracking the World State with Recurrent Entity Networks
 Tracking the World State with Recurrent Entity Networks Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, Yann LeCun Task At each timestep, get information (in the form of a sentence) about the
Tracking the World State with Recurrent Entity Networks Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, Yann LeCun Task At each timestep, get information (in the form of a sentence) about the
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Language Models. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Language Models Tobias Scheffer Stochastic Language Models A stochastic language model is a probability distribution over words.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Language Models Tobias Scheffer Stochastic Language Models A stochastic language model is a probability distribution over words.
Recurrent Neural Networks 2. CS 287 (Based on Yoav Goldberg s notes)
") Recurrent Neural Networks 2 CS 287 (Based on Yoav Goldberg s notes) Review: Representation of Sequence Many tasks in NLP involve sequences w 1,..., w n Representations as matrix dense vectors X (Following
Recurrent Neural Networks 2 CS 287 (Based on Yoav Goldberg s notes) Review: Representation of Sequence Many tasks in NLP involve sequences w 1,..., w n Representations as matrix dense vectors X (Following
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Neural Networks for NLP. COMP-599 Nov 30, 2016
 Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
RECURRENT NETWORKS I. Philipp Krähenbühl
 RECURRENT NETWORKS I Philipp Krähenbühl RECAP: CLASSIFICATION conv 1 conv 2 conv 3 conv 4 1 2 tu RECAP: SEGMENTATION conv 1 conv 2 conv 3 conv 4 RECAP: DETECTION conv 1 conv 2 conv 3 conv 4 RECAP: GENERATION
RECURRENT NETWORKS I Philipp Krähenbühl RECAP: CLASSIFICATION conv 1 conv 2 conv 3 conv 4 1 2 tu RECAP: SEGMENTATION conv 1 conv 2 conv 3 conv 4 RECAP: DETECTION conv 1 conv 2 conv 3 conv 4 RECAP: GENERATION
Natural Language Processing
 Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Deep Learning for NLP
 Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Homework 3 COMS 4705 Fall 2017 Prof. Kathleen McKeown
 Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Stephen Scott.
 1 / 35 (Adapted from Vinod Variyam and Ian Goodfellow) sscott@cse.unl.edu 2 / 35 All our architectures so far work on fixed-sized inputs neural networks work on sequences of inputs E.g., text, biological
1 / 35 (Adapted from Vinod Variyam and Ian Goodfellow) sscott@cse.unl.edu 2 / 35 All our architectures so far work on fixed-sized inputs neural networks work on sequences of inputs E.g., text, biological
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
arxiv: v1 [cs.cl] 21 May 2017
![arxiv: v1 [cs.cl] 21 May 2017](/thumbs/92/109535705.jpg "arxiv: v1 [cs.cl] 21 May 2017") Spelling Correction as a Foreign Language Yingbo Zhou yingbzhou@ebay.com Utkarsh Porwal uporwal@ebay.com Roberto Konow rkonow@ebay.com arxiv:1705.07371v1 [cs.cl] 21 May 2017 Abstract In this paper, we
Spelling Correction as a Foreign Language Yingbo Zhou yingbzhou@ebay.com Utkarsh Porwal uporwal@ebay.com Roberto Konow rkonow@ebay.com arxiv:1705.07371v1 [cs.cl] 21 May 2017 Abstract In this paper, we
Recurrent neural networks
 12-1: Recurrent neural networks Prof. J.C. Kao, UCLA Recurrent neural networks Motivation Network unrollwing Backpropagation through time Vanishing and exploding gradients LSTMs GRUs 12-2: Recurrent neural
12-1: Recurrent neural networks Prof. J.C. Kao, UCLA Recurrent neural networks Motivation Network unrollwing Backpropagation through time Vanishing and exploding gradients LSTMs GRUs 12-2: Recurrent neural
Neural Networks in Structured Prediction. November 17, 2015
 Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
Recurrent Neural Networks. COMP-550 Oct 5, 2017
 Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Deep Learning. Ali Ghodsi. University of Waterloo
 University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Generating Sequences with Recurrent Neural Networks
 Generating Sequences with Recurrent Neural Networks Alex Graves University of Toronto & Google DeepMind Presented by Zhe Gan, Duke University May 15, 2015 1 / 23 Outline Deep recurrent neural network based
Generating Sequences with Recurrent Neural Networks Alex Graves University of Toronto & Google DeepMind Presented by Zhe Gan, Duke University May 15, 2015 1 / 23 Outline Deep recurrent neural network based
Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials
 Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials Contents 1 Pseudo-code for the damped Gauss-Newton vector product 2 2 Details of the pathological synthetic problems
Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials Contents 1 Pseudo-code for the damped Gauss-Newton vector product 2 2 Details of the pathological synthetic problems
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
EE-559 Deep learning Recurrent Neural Networks
 EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
Neural Network Language Modeling
 Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Recurrent Neural Networks
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
(
 Class 15 - Long Short-Term Memory (LSTM) Study materials http://colah.github.io/posts/2015-08-understanding-lstms/ (http://colah.github.io/posts/2015-08-understanding-lstms/) http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Class 15 - Long Short-Term Memory (LSTM) Study materials http://colah.github.io/posts/2015-08-understanding-lstms/ (http://colah.github.io/posts/2015-08-understanding-lstms/) http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Contents. (75pts) COS495 Midterm. (15pts) Short answers
 COS495 Midterm. (15pts) Short answers") Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent
 Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent 1 Xi-Lin Li, lixilinx@gmail.com arxiv:1606.04449v2 [stat.ml] 8 Dec 2016 Abstract This paper studies the performance of
Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent 1 Xi-Lin Li, lixilinx@gmail.com arxiv:1606.04449v2 [stat.ml] 8 Dec 2016 Abstract This paper studies the performance of
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Neural Word Embeddings from Scratch
 Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
TTIC 31230, Fundamentals of Deep Learning David McAllester, April Vanishing and Exploding Gradients. ReLUs. Xavier Initialization
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
Long-Short Term Memory
 Long-Short Term Memory Sepp Hochreiter, Jürgen Schmidhuber Presented by Derek Jones Table of Contents 1. Introduction 2. Previous Work 3. Issues in Learning Long-Term Dependencies 4. Constant Error Flow
Long-Short Term Memory Sepp Hochreiter, Jürgen Schmidhuber Presented by Derek Jones Table of Contents 1. Introduction 2. Previous Work 3. Issues in Learning Long-Term Dependencies 4. Constant Error Flow
Lecture 7: Word Embeddings
 Lecture 7: Word Embeddings Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 6501 Natural Language Processing 1 This lecture v Learning word vectors
Lecture 7: Word Embeddings Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 6501 Natural Language Processing 1 This lecture v Learning word vectors
Implicitly-Defined Neural Networks for Sequence Labeling
 Implicitly-Defined Neural Networks for Sequence Labeling Michaeel Kazi MIT Lincoln Laboratory 244 Wood St, Lexington, MA, 02420, USA michaeel.kazi@ll.mit.edu Abstract We relax the causality assumption
Implicitly-Defined Neural Networks for Sequence Labeling Michaeel Kazi MIT Lincoln Laboratory 244 Wood St, Lexington, MA, 02420, USA michaeel.kazi@ll.mit.edu Abstract We relax the causality assumption
A Tutorial On Backward Propagation Through Time (BPTT) In The Gated Recurrent Unit (GRU) RNN
 In The Gated Recurrent Unit (GRU) RNN") A Tutorial On Backward Propagation Through Time (BPTT In The Gated Recurrent Unit (GRU RNN Minchen Li Department of Computer Science The University of British Columbia minchenl@cs.ubc.ca Abstract In this
A Tutorial On Backward Propagation Through Time (BPTT In The Gated Recurrent Unit (GRU RNN Minchen Li Department of Computer Science The University of British Columbia minchenl@cs.ubc.ca Abstract In this
CSC321 Lecture 10 Training RNNs
 CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
Long Short-Term Memory (LSTM)
") Long Short-Term Memory (LSTM) A brief introduction Daniel Renshaw 24th November 2014 1 / 15 Context and notation Just to give the LSTM something to do: neural network language modelling Vocabulary, size
Long Short-Term Memory (LSTM) A brief introduction Daniel Renshaw 24th November 2014 1 / 15 Context and notation Just to give the LSTM something to do: neural network language modelling Vocabulary, size
Faster Training of Very Deep Networks Via p-norm Gates
 Faster Training of Very Deep Networks Via p-norm Gates Trang Pham, Truyen Tran, Dinh Phung, Svetha Venkatesh Center for Pattern Recognition and Data Analytics Deakin University, Geelong Australia Email:
Faster Training of Very Deep Networks Via p-norm Gates Trang Pham, Truyen Tran, Dinh Phung, Svetha Venkatesh Center for Pattern Recognition and Data Analytics Deakin University, Geelong Australia Email:
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Feedforward Neural Networks. Michael Collins, Columbia University
 Feedforward Neural Networks Michael Collins, Columbia University Recap: Log-linear Models A log-linear model takes the following form: p(y x; v) = exp (v f(x, y)) y Y exp (v f(x, y )) f(x, y) is the representation
Feedforward Neural Networks Michael Collins, Columbia University Recap: Log-linear Models A log-linear model takes the following form: p(y x; v) = exp (v f(x, y)) y Y exp (v f(x, y )) f(x, y) is the representation
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
(2pts) What is the object being embedded (i.e. a vector representing this object is computed) when one uses
 What is the object being embedded (i.e. a vector representing this object is computed) when one uses") Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Feedforward Neural Networks
 Feedforward Neural Networks Michael Collins 1 Introduction In the previous notes, we introduced an important class of models, log-linear models. In this note, we describe feedforward neural networks, which
Feedforward Neural Networks Michael Collins 1 Introduction In the previous notes, we introduced an important class of models, log-linear models. In this note, we describe feedforward neural networks, which
Spatial Transformer. Ref: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transformer Networks, NIPS, 2015
 Spatial Transormer Re: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transormer Networks, NIPS, 2015 Spatial Transormer Layer CNN is not invariant to scaling and rotation
Spatial Transormer Re: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transormer Networks, NIPS, 2015 Spatial Transormer Layer CNN is not invariant to scaling and rotation
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function
 Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Conditional Language modeling with attention
 Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Deep learning for Natural Language Processing and Machine Translation
 Deep learning for Natural Language Processing and Machine Translation 2015.10.16 Seung-Hoon Na Contents Introduction: Neural network, deep learning Deep learning for Natural language processing Neural
Deep learning for Natural Language Processing and Machine Translation 2015.10.16 Seung-Hoon Na Contents Introduction: Neural network, deep learning Deep learning for Natural language processing Neural
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic