BAYESIAN DECISION THEORY
|
|
|
- Hillary Simon
- 5 years ago
- Views:
Transcription
1 Last updated: September 17, 2012 BAYESIAN DECISION THEORY
2 Problems 2 The following problems from the textbook are relevant: , 2.11, 2.17 For this week, please at least solve Problem 2.3. We will go over this in class.
3 Credits 3 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis, University of Athens & Konstantinos Koutroumbas, National Observatory of Athens
4 Bayesian Decision Theory: Topics 4 1. Probability 2. The Univariate Normal Distribution 3. Bayesian Classifiers 4. Minimizing Risk 5. Nonparametric Density Estimation 6. Training and Evaluation Methods
5 Bayesian Decision Theory: Topics 5 1. Probability 2. The Univariate Normal Distribution 3. Bayesian Classifiers 4. Minimizing Risk 5. Nonparametric Density Estimation 6. Training and Evaluation Methods
6 Probability 6 Probability theory is nothing but common sense reduced to calculation - Pierre Laplace, 1812.
7 Random Variables 7 A random variable is a variable whose value is uncertain. For example, the height of a randomly selected person in this class is a random variable I won t know its value until the person is selected. Note that we are not completely uncertain about most random variables. For example, we know that height will probably be in the 5-6 range. In addition, 5 6 is more likely than 5 0 or 6 0. The function that describes the probability of each possible value of the random variable is called a probability distribution.


8 Probability Distributions 8 For a discrete distribution, the probabilities over all possible values of the random variable must sum to 1.
 = 0.50.")
9 Probability Distributions 9 For a discrete distribution, we can talk about the probability of a particular score occurring, e.g., p(province = Ontario) = We can also talk about the probability of any one of a subset of scores occurring, e.g., p(province = Ontario or Quebec) = In general, we refer to these occurrences as events.
10 Probability Distributions 10 For a continuous distribution, the probabilities over all possible values of the random variable must integrate to 1 (i.e., the area under the curve must be 1). Note that the height of a continuous distribution can exceed 1! S h a d e d a r e a = S h a d e d a r e a = S h a d e d a r e a =
11 Continuous Distributions 11 For continuous distributions, it does not make sense to talk about the probability of an exact score. e.g., what is the probability that your height is exactly inches? Normal Approximation to probability distribution for height of Canadian females (parameters from General Social Survey, 1991) Probability p µ = s = 5'3.8" 2.6" Height (in)?
12 Continuous Distributions 12 It does make sense to talk about the probability of observing a score that falls within a certain range e.g., what is the probability that you are between 5 3 and 5 7? e.g., what is the probability that you are less than 5 10? Valid events Normal Approximation to probability distribution for height of Canadian females (parameters from General Social Survey, 1991) Probability p µ = s = 5'3.8" 2.6" Height (in)
 Probability density")
13 Probability Densities 13 Cumulative distribution (CDF) Probability density (PDF)
. y is also a random variable.")
14 Transformed Densities 14 Consider a random variable x with probability density p x (x). Suppose you have another variable y that is defined to be a function of x: y = f(x). y is also a random variable. What is its probability density p y (y)? Caution: in general, p y (y) p x (f -1 (y)).
 is monotonic, and hence invertible.")
15 Transformed Densities 15 This is a difficult problem in general. However, it is tractable when f(x) is monotonic, and hence invertible. In this case, we can solve for the pdf p y (y) by differentiating the cdf P y (y). y y = f(x) x
16 Transformed Densities 16 Let s assume that y is monotonically increasing in x. Then we can write P y (y) = P ( f (x) y ) = P ( x f 1 (y)) = P ( x f 1 (y)) Taking derivatives, we get p y (y) d dy P y (y) = d dy P x where x = f 1 (y). Note that dx dy > 0 in this case. ( f 1 (y)) = dx dy d dx P x ( x) = dx dy p x ( x)
17 Transformed Densities 17 If y is monotonically decreasing in x, using the same method it is easy to show that p y (y) = dx dy p x where x = f 1 (y). Note that dx dy ( x) < 0 in this case. Thus a general expression that applies when y is monotonic on x is: p y (y) = dx dy p x ( x), where x = f 1 (y).
 δy p y (y ) p x (x) δx δy Note that in general, δy δx. Rather, δy δx dy dx as δx 0. Thus p y (y ) = p x (x) dx dy")
18 Transformed Densities: Intuition 18 f(x) Observations falling within ( x + δ x ) tranform to the range ( y + δy ) p x (x) δx = p y (y ) δy p y (y ) p x (x) δx δy Note that in general, δy δx. Rather, δy δx dy dx as δx 0. Thus p y (y ) = p x (x) dx dy



19 Joint Distributions 19 Marginal Probability Joint Probability Conditional Probability
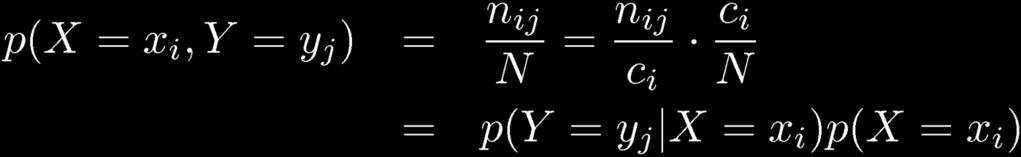
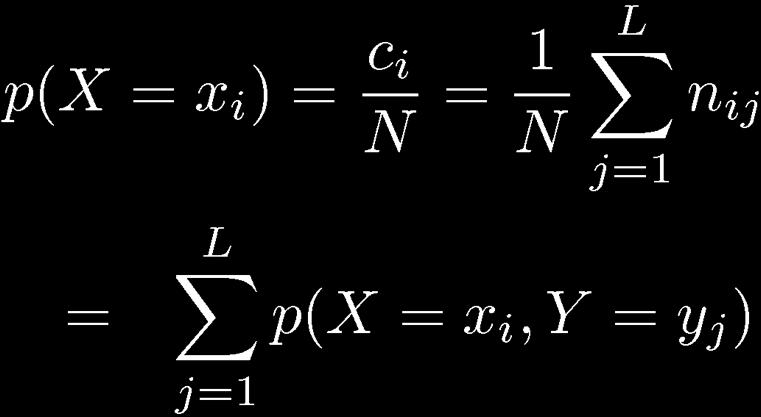
20 Joint Distributions 20 Sum Rule Product Rule


21 Joint Distributions: The Rules of Probability 21 Sum Rule Product Rule
 over the other")
22 Marginalization 22 We can recover probability distribution of any variable in a joint distribution by integrating (or summing) over the other variables
23 Conditional Probability 23 Conditional probability of X given that Y=y* is relative propensity of variable X to take different outcomes given that Y is fixed to be equal to y* Written as Pr(X Y=y*)
24 Conditional Probability 24 Conditional probability can be extracted from joint probability Extract appropriate slice and normalize
25 Conditional Probability 25 More usually written in compact form Can be re-arranged to give
26 Independence 26 If two variables X and Y are independent then variable X tells us nothing about variable Y (and vice-versa)
27 Independence 27 When variables are independent, the joint factorizes into a product of the marginals:

28 Bayes Rule 28 From before: Combining: Re-arranging:
29 Bayes Rule Terminology 29 Likelihood propensity for observing a certain value of X given a certain value of Y Prior what we know about y before seeing x Posterior what we know about y after seeing x Evidence a constant to ensure that the left hand side is a valid distribution
 be some")


")
30 Expectations 30 Let f(x) be some function of a random variable x. Then we define: Condi3onal Expecta3on (discrete) Approximate Expecta3on (discrete and con3nuous)

31 Variances and Covariances 31
32 End of Lecture Sept 10, 2012
33 Bayesian Decision Theory: Topics Probability 2. The Univariate Normal Distribution 3. Bayesian Classifiers 4. Minimizing Risk 5. Nonparametric Density Estimation 6. Training and Evaluation Methods

34 The Gaussian Distribution 34 MATLAB Statistics Toolbox Function: normpdf(x,mu,sigma)


35 Central Limit Theorem 35 The distribution of the mean of N i.i.d. random variables becomes increasingly Gaussian as N grows. Example: N uniform [0,1] random variables.

36 Gaussian Mean and Variance 36
37 Bayesian Decision Theory: Topics Probability 2. The Univariate Normal Distribution 3. Bayesian Classifiers 4. Minimizing Risk 5. Nonparametric Density Estimation 6. Training and Evaluation Methods
38 Bayesian Classification 38 Input feature vectors x = x 1,x 2,...,x l T Assign the pattern represented by feature vector x to the most probable of the available classes ω 1,ω 2,...,ω M That is, x ω i : P(ω i x) is maximum. Posterior
39 Bayesian Classification 39 Computation of posterior probabilities Assume known n Prior probabilities P(ω 1 ),P(ω 2 )...,P(ω M ) n Likelihoods p( x ω i ), i = 1,2,,M
40 Bayes Rule for Classification 40 ( ) = p ( x ω i )p( ω i ) p( x) p ω i x where M ( ) = p x ω i p x i=1 ( )p ω i ( ),
41 M=2 Classes Given x classify it according to the rule If P(ω 1 x) > P(ω 2 x) ω 1 If P(ω 2 x) > P(ω 1 x) ω 2 Equivalently: classify x according to the rule If p( x ω 1 )P ω 1 If p( x ω 2 )P ω 2 ( ) > p x ω 2 ( ) > p x ω 1 ( )P ω 2 ( )P ω 1 ( ) ω 1 ( ) ω 2 For equiprobable classes the test becomes ( ) > p( x ω 2 ) ω 1 ( ) > p( x ω 1 ) ω 2 If p x ω 1 If p x ω 2
42 Example: Equiprobable Classes 42 R ( ω ) and R ( ω )
43 Example: Equiprobable Classes Probability of error The black and red shaded areas represent Thus x 0 ( ) = p(x ω 2 )dx P error ω 2 and P error ω 1 ( ) = p(x ω 1 )dx x 0 P e P(error) = P ( ω 2 )P error ω 2 = 1 2 x 0 ( ) + P ω 1 1 p(x ω 2 )dx x 0 ( )P error ω 1 p(x ω 1 )dx ( ) Bayesian classifier is OPTIMAL: it minimizes the classification error probability
44 Example: Equiprobable Classes 44 To see this, observe that shifting the threshold increases the error rate for one class of patterns more than it decreases the error rate for the other class.
45 The General Case In general, for M classes and unequal priors, the decision rule P(ω i x) > P(ω j x) j i ω i minimizes the expected error rate.
46 Types of Error 46 Minimizing the expected error rate is a pretty reasonable goal. However, it is not always the best thing to do. Example: You are designing a pedestrian detection algorithm for an autonomous navigation system. Your algorithm must decide whether there is a pedestrian crossing the street. There are two possible types of error: n False positive: there is no pedestrian, but the system thinks there is. n Miss: there is a pedestrian, but the system thinks there is not. Should you give equal weight to these 2 types of error?
47 Bayesian Decision Theory: Topics Probability 2. The Univariate Normal Distribution 3. Bayesian Classifiers 4. Minimizing Risk 5. Nonparametric Density Estimation 6. Training and Evaluation Methods

48 Topic 4. Minimizing Risk
49 The Loss Matrix 49 To deal with this problem, instead of minimizing error rate, we minimize something called the risk. First, we define the loss matrix L, which quantifies the cost of making each type of error. Element λ ij of the loss matrix specifies the cost of deciding class j when in fact the input is of class i. Typically, we set λ ii =0 for all i. Thus a typical loss matrix for the M = 2 case would have the form L = 0 λ 12 λ 21 0

50 Risk 50 Given a loss function, we can now define the risk associated with each class k as: M i=1 r k = λ ki p( x ω k )dx R i Probability we will decide Class ω i given pattern from Class ω k where R i is the region of the input space where we will decide ω i.
51 Minimizing Risk 51 Now the goal is to minimize the expected risk r, given by r = M k=1 r k P ( ω ) k
52 Minimizing Risk 52 r = M r k P ( ω ) k where r k = λ ki p( x ω k )dx k=1 M i=1 R i We need to select the decision regions R i to minimize the risk r. Note that the set of R i are disjoint and exhaustive. Thus we can minimize the risk by ensuring that each input x falls in the region R i that minimizes the expected loss for that particular input, i.e., M Letting l i = λ ki p ( x ω k )P ( ω ) k, k =1 we select the partioning regions such that x R i if l i < l j j i
53 Example: M=2 53 For the 2-class case: l 1 = λ 11 p ( x ω 1 )P ω 1 and l 2 = λ 12 p ( x ω 1 )P ω 1 Thus we assign x to ω 1 if i.e., if ( ) + λ 21 p x ω 2 ( )P ω 2 ( ) + λ 22 p x ω 2 ( ) ( )P ω 2 ( ) ( λ 21 λ ) 22 p ( x ω 2 )P ( ω ) 2 < ( λ 12 λ ) 11 p ( x ω 1 )P ( ω ) 1 ( ) ( ) > P ( ω )( λ 2 21 λ ) 22 P ( ω )( 1 λ 12 λ ). 11 p x ω 1 p x ω 2 Likelihood Ratio Test
54 Likelihood Ratio Test 54 ( ) ( ) > P ( ω )( λ 2 21 λ )? 22 P ( ω )( 1 λ 12 λ ). 11 p x ω 1 p x ω 2 Typically, the loss for a correct decision is 0. Thus the likelihood ratio test becomes ( ) ( ) > P ( ω )? λ 2 ( ) 21. λ 12 p x ω 1 p x ω 2 P ω 1 In the case of equal priors and equal loss functions, the test reduces to ( )? ( ) > 1. p x ω 1 p x ω 2
55 Example 55 Consider a one-dimensional input space, with features generated by normal distributions with identical variance: ( ) ( ) p(x ω 1 ) N µ 1,σ 2 p(x ω 2 ) N µ 2,σ 2 where µ 1 = 0, µ 2 = 1, and σ 2 = 1 2 Let s assume equiprobable classes, and higher loss for errors on Class 2, specifically: λ 21 = 1, λ 12 = 1 2.

56 Results 56 The threshold has shifted to the left why?
57 End of Lecture Sept 12, 2012
58 Bayesian Decision Theory: Topics Probability 2. The Univariate Normal Distribution 3. Bayesian Classifiers 4. Minimizing Risk 5. Nonparametric Density Estimation 6. Training and Evaluation Methods
59 Nonparametric Methods 59 Parametric distribution models are restricted to specific forms, which may not always be suitable; for example, consider modelling a multimodal distribution with a single, unimodal model. You can use a mixture model, but then you have to decide on the number of components, and hope that your parameter estimation algorithm (e.g., EM) converges to a global optimum! Nonparametric approaches make few assumptions about the overall shape of the distribution being modelled, and in some cases may be simpler than using a mixture model.



60 Histogramming 60 Histogram methods partition the data space into distinct bins with widths Δ i and count the number of observations, n i, in each bin. Often, the same width is used for all bins, Δ i = Δ. Δ acts as a smoothing parameter. In a D-dimensional space, using M bins in each dimension will require M D bins! The curse of dimensionality
 is approximately constant over R and The expected number K out of N observations that will lie inside R is given by Thus")
61 Kernel Density Estimation 61 Assume observations drawn from a density p(x) and consider a small region R containing x such that If the volume V of R is sufficiently small, p(x) is approximately constant over R and The expected number K out of N observations that will lie inside R is given by Thus

 It follows that")
62 Kernel Density Estimation 62 Kernel Density Estimation: fix V, estimate K from the data. Let R be a hypercube centred on x and define the kernel function (Parzen window) It follows that and hence
, use a smooth")
 such that")
63 Kernel Density Estimation 63 To avoid discontinuities in p(x), use a smooth kernel, e.g. a Gaussian (Any kernel k(u) such that will work.) h acts as a smoother.

64 KDE Example 64
65 Kernel Density Estimation 65 Problem: if V is fixed, there may be too few points in some regions to get an accurate estimate.
66 Nearest Neighbour Density Estimation 66 Nearest Neighbour Density Estimation: fix K, estimate V from the data. Consider a hypersphere centred on x and let it grow to a volume V* that includes K of the given N data points. Then for j=1:np d=sort(abs(x(j)-xi)); V=2*d(K(i)); phat(j)=k(i)/(n*v); end
67 Nearest Neighbour Density Estimation 67 Nearest Neighbour Density Estimation: fix K, estimate V from the data. Consider a hypersphere centred on x and let it grow to a volume V* that includes K of the given N data points. Then K=5 K=10 K=100 True distribution Training data KNN Estimate
68 Nearest Neighbour Density Estimation 68 Problem: does not generate a proper density (for example, integral is unbounded on D ) In practice, on finite domains, can normalize. But makes strong assumption on tails 1 x
69 Nonparametric Methods 69 Nonparametric models (not histograms) require storing and computing with the entire data set. Parametric models, once fitted, are much more efficient in terms of storage and computation.



70 K-Nearest-Neighbours for Classification 70 Given a data set with N k data points from class C k and, we have and correspondingly Since, Bayes theorem gives
71 K-Nearest-Neighbours for Classification 71 K = 3 K = 1


72 K-Nearest-Neighbours for Classification 72 K acts as a smoother As, the error rate of the 1-nearestneighbour classifier is never more than twice the optimal error (obtained from the true conditional class distributions).

73 KNN Example 73
74 Naïve Bayes Classifiers 74 All of these nonparametric methods require lots of data to work. If O ( N ) training points are required for accurate estimation in 1 dimension, then O ( N D ) points are required for D-dimensional input vectors. It may sometimes be possible to assume that the individual dimensions of the feature vector are conditionally independent. Then we have ( ) = p x j ω i p x ω i D j =1 ( ) This reduces the data requirements to O ( DN ).
75 Bayesian Decision Theory: Topics Probability 2. The Univariate Normal Distribution 3. Bayesian Classifiers 4. Minimizing Risk 5. Nonparametric Density Estimation 6. Training and Evaluation Methods
76 Machine Learning System Design 76 The process of solving a particular classification or regression problem typically involves the following sequence of steps: 1. Design and code promising candidate systems 2. Train each of the candidate systems (i.e., learn the parameters) 3. Evaluate each of the candidate systems 4. Select and deploy the best of these candidate systems
77 Using Your Training Data 77 You will always have a finite amount of data on which to train and evaluate your systems. The performance of a classification system is often data-limited: if we only had more data, we could make the system better. Thus it is important to use your finite data set wisely.

78 Overfitting 78 Given that learning is often data-limited, it is tempting to use all of your data to estimate the parameters of your models, and then select the model with the lowest error on your training data. Unfortunately, this leads to a notorious problem called over-fitting.
79 Example: Polynomial Curve Fitting 79
80 Sum-of-Squares Error Function 80
81 How do we choose M, the order of the model? 81
82 1 st Order Polynomial 82
83 3 rd Order Polynomial 83
84 9 th Order Polynomial 84
85 Over-fitting 85 Root- Mean- Square (RMS) Error:
86 Overfitting and Sample Size 86 9 th Order Polynomial
87 Over-fitting and Sample Size 87 9 th Order Polynomial
88 Methods for Preventing Over-Fitting 88 Bayesian parameter estimation Application of prior knowledge regarding the probable values of unknown parameters can often limit over-fitting of a model Model selection criteria Methods exist for comparing models of differing complexity (i.e., with different types and numbers of parameters) n Bayesian Information Criterion (BIC) n Akaike Information Criterion (AIC) Cross-validation This is a very simple method that is universally applicable.
89 Cross-Validation 89 The available data are partitioned into disjoint training and test subsets. Parameters are learned on the training sets. Performance of the model is then evaluated on the test set. Since the test set is independent of the training set, the evaluation is fair: models that overlearn the noise in the training set will perform poorly on the test set.
90 Cross-Validation: Choosing the Partition 90 What is the best way to partition the data? A larger training set will lead to more accurate parameter estimation. However a small test set will lead to a noisy performance score. If you can afford the computation time, repeat the training/test cycle on complementary partitions and then average the results. This gives you the best of all worlds: accurate parameter estimation and accurate evaluation. In the limit: the leave-one-out method
91 A useful MATLAB function 91 randperm(n) Generates a random permutation of the integers from 1 to n The result can be used to select random subsets from your data
92 Bayesian Decision Theory: Topics Probability 2. The Univariate Normal Distribution 3. Bayesian Classifiers 4. Minimizing Risk 5. Nonparametric Density Estimation 6. Training and Evaluation Methods
BAYESIAN DECISION THEORY. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 BAYESIAN DECISION THEORY Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis, University of Athens
BAYESIAN DECISION THEORY Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis, University of Athens
COURSE INTRODUCTION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 COURSE INTRODUCTION COMPUTATIONAL MODELING OF VISUAL PERCEPTION 2 The goal of this course is to provide a framework and computational tools for modeling visual inference, motivated by interesting examples
COURSE INTRODUCTION COMPUTATIONAL MODELING OF VISUAL PERCEPTION 2 The goal of this course is to provide a framework and computational tools for modeling visual inference, motivated by interesting examples
Curve Fitting Re-visited, Bishop1.2.5
 Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Machine Learning. Nonparametric Methods. Space of ML Problems. Todo. Histograms. Instance-Based Learning (aka non-parametric methods)
") Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
MIXTURE MODELS AND EM
 Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
Computer vision: models, learning and inference
 Computer vision: models, learning and inference Chapter 2 Introduction to probability Please send errata to s.prince@cs.ucl.ac.uk Random variables A random variable x denotes a quantity that is uncertain
Computer vision: models, learning and inference Chapter 2 Introduction to probability Please send errata to s.prince@cs.ucl.ac.uk Random variables A random variable x denotes a quantity that is uncertain
Machine Learning Lecture 3
 Announcements Machine Learning Lecture 3 Eam dates We re in the process of fiing the first eam date Probability Density Estimation II 9.0.207 Eercises The first eercise sheet is available on L2P now First
Announcements Machine Learning Lecture 3 Eam dates We re in the process of fiing the first eam date Probability Density Estimation II 9.0.207 Eercises The first eercise sheet is available on L2P now First
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Supervised Learning: Non-parametric Estimation
 Supervised Learning: Non-parametric Estimation Edmondo Trentin March 18, 2018 Non-parametric Estimates No assumptions are made on the form of the pdfs 1. There are 3 major instances of non-parametric estimates:
Supervised Learning: Non-parametric Estimation Edmondo Trentin March 18, 2018 Non-parametric Estimates No assumptions are made on the form of the pdfs 1. There are 3 major instances of non-parametric estimates:
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Pattern Classification
 Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Probability Based Learning
 Probability Based Learning Lecture 7, DD2431 Machine Learning J. Sullivan, A. Maki September 2013 Advantages of Probability Based Methods Work with sparse training data. More powerful than deterministic
Probability Based Learning Lecture 7, DD2431 Machine Learning J. Sullivan, A. Maki September 2013 Advantages of Probability Based Methods Work with sparse training data. More powerful than deterministic
12 - Nonparametric Density Estimation
 ST 697 Fall 2017 1/49 12 - Nonparametric Density Estimation ST 697 Fall 2017 University of Alabama Density Review ST 697 Fall 2017 2/49 Continuous Random Variables ST 697 Fall 2017 3/49 1.0 0.8 F(x) 0.6
ST 697 Fall 2017 1/49 12 - Nonparametric Density Estimation ST 697 Fall 2017 University of Alabama Density Review ST 697 Fall 2017 2/49 Continuous Random Variables ST 697 Fall 2017 3/49 1.0 0.8 F(x) 0.6
EEL 851: Biometrics. An Overview of Statistical Pattern Recognition EEL 851 1
 EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Machine Learning Linear Classification. Prof. Matteo Matteucci
 Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Gaussian Processes. Le Song. Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012
 Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
probability of k samples out of J fall in R.
 Nonparametric Techniques for Density Estimation (DHS Ch. 4) n Introduction n Estimation Procedure n Parzen Window Estimation n Parzen Window Example n K n -Nearest Neighbor Estimation Introduction Suppose
Nonparametric Techniques for Density Estimation (DHS Ch. 4) n Introduction n Estimation Procedure n Parzen Window Estimation n Parzen Window Example n K n -Nearest Neighbor Estimation Introduction Suppose
Nonparametric Methods Lecture 5
 Nonparametric Methods Lecture 5 Jason Corso SUNY at Buffalo 17 Feb. 29 J. Corso (SUNY at Buffalo) Nonparametric Methods Lecture 5 17 Feb. 29 1 / 49 Nonparametric Methods Lecture 5 Overview Previously,
Nonparametric Methods Lecture 5 Jason Corso SUNY at Buffalo 17 Feb. 29 J. Corso (SUNY at Buffalo) Nonparametric Methods Lecture 5 17 Feb. 29 1 / 49 Nonparametric Methods Lecture 5 Overview Previously,
Gaussian processes. Chuong B. Do (updated by Honglak Lee) November 22, 2008
 November 22, 2008") Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Non-parametric Methods
 Non-parametric Methods Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 2 of Pattern Recognition and Machine Learning by Bishop (with an emphasis on section 2.5) Möller/Mori 2 Outline Last
Non-parametric Methods Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 2 of Pattern Recognition and Machine Learning by Bishop (with an emphasis on section 2.5) Möller/Mori 2 Outline Last
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
On Bias, Variance, 0/1-Loss, and the Curse-of-Dimensionality. Weiqiang Dong
 On Bias, Variance, 0/1-Loss, and the Curse-of-Dimensionality Weiqiang Dong 1 The goal of the work presented here is to illustrate that classification error responds to error in the target probability estimates
On Bias, Variance, 0/1-Loss, and the Curse-of-Dimensionality Weiqiang Dong 1 The goal of the work presented here is to illustrate that classification error responds to error in the target probability estimates
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probability Theory for Machine Learning. Chris Cremer September 2015
 Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Lecture 1: Bayesian Framework Basics
 Lecture 1: Bayesian Framework Basics Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de April 21, 2014 What is this course about? Building Bayesian machine learning models Performing the inference of
Lecture 1: Bayesian Framework Basics Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de April 21, 2014 What is this course about? Building Bayesian machine learning models Performing the inference of
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Machine Learning. Theory of Classification and Nonparametric Classifier. Lecture 2, January 16, What is theoretically the best classifier
 Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 89 Part II
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 89 Part II
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 3: Probability, Bayes Theorem, and Bayes Classification Peter Belhumeur Computer Science Columbia University Probability Should you play this game? Game: A fair
Deep Learning for Computer Vision Lecture 3: Probability, Bayes Theorem, and Bayes Classification Peter Belhumeur Computer Science Columbia University Probability Should you play this game? Game: A fair
INTRODUCTION TO PATTERN RECOGNITION
 INTRODUCTION TO PATTERN RECOGNITION INSTRUCTOR: WEI DING 1 Pattern Recognition Automatic discovery of regularities in data through the use of computer algorithms With the use of these regularities to take
INTRODUCTION TO PATTERN RECOGNITION INSTRUCTOR: WEI DING 1 Pattern Recognition Automatic discovery of regularities in data through the use of computer algorithms With the use of these regularities to take
Lecture 4: Probabilistic Learning
 DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
Day 5: Generative models, structured classification
 Day 5: Generative models, structured classification Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 22 June 2018 Linear regression
Day 5: Generative models, structured classification Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 22 June 2018 Linear regression
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Maximum Likelihood Estimation. only training data is available to design a classifier
 Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
Probability theory for Networks (Part 1) CS 249B: Science of Networks Week 02: Monday, 02/04/08 Daniel Bilar Wellesley College Spring 2008
 CS 249B: Science of Networks Week 02: Monday, 02/04/08 Daniel Bilar Wellesley College Spring 2008") Probability theory for Networks (Part 1) CS 249B: Science of Networks Week 02: Monday, 02/04/08 Daniel Bilar Wellesley College Spring 2008 1 Review We saw some basic metrics that helped us characterize
Probability theory for Networks (Part 1) CS 249B: Science of Networks Week 02: Monday, 02/04/08 Daniel Bilar Wellesley College Spring 2008 1 Review We saw some basic metrics that helped us characterize
Pattern Recognition. Parameter Estimation of Probability Density Functions
 Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
Computer Vision Group Prof. Daniel Cremers. 10a. Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Multivariate statistical methods and data mining in particle physics
 Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Introduction to Machine Learning
 Introduction to Machine Learning 3. Instance Based Learning Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Parzen Windows Kernels, algorithm Model selection
Introduction to Machine Learning 3. Instance Based Learning Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Parzen Windows Kernels, algorithm Model selection
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Preliminary Statistics Lecture 2: Probability Theory (Outline) prelimsoas.webs.com
 prelimsoas.webs.com") 1 School of Oriental and African Studies September 2015 Department of Economics Preliminary Statistics Lecture 2: Probability Theory (Outline) prelimsoas.webs.com Gujarati D. Basic Econometrics, Appendix
1 School of Oriental and African Studies September 2015 Department of Economics Preliminary Statistics Lecture 2: Probability Theory (Outline) prelimsoas.webs.com Gujarati D. Basic Econometrics, Appendix
Nonparametric probability density estimation
 A temporary version for the 2018-04-11 lecture. Nonparametric probability density estimation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics
A temporary version for the 2018-04-11 lecture. Nonparametric probability density estimation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Data Mining Prof. Pabitra Mitra Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur
 Data Mining Prof. Pabitra Mitra Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Lecture - 17 K - Nearest Neighbor I Welcome to our discussion on the classification
Data Mining Prof. Pabitra Mitra Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Lecture - 17 K - Nearest Neighbor I Welcome to our discussion on the classification
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Bayesian Decision Theory
 Bayesian Decision Theory Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Bayesian Decision Theory Bayesian classification for normal distributions Error Probabilities
Bayesian Decision Theory Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Bayesian Decision Theory Bayesian classification for normal distributions Error Probabilities
6.867 Machine Learning
 6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Bayesian decision theory Introduction to Pattern Recognition. Lectures 4 and 5: Bayesian decision theory
 Bayesian decision theory 8001652 Introduction to Pattern Recognition. Lectures 4 and 5: Bayesian decision theory Jussi Tohka jussi.tohka@tut.fi Institute of Signal Processing Tampere University of Technology
Bayesian decision theory 8001652 Introduction to Pattern Recognition. Lectures 4 and 5: Bayesian decision theory Jussi Tohka jussi.tohka@tut.fi Institute of Signal Processing Tampere University of Technology
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
Classification: The rest of the story
 U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
6.867 Machine Learning
 6.867 Machine Learning Problem set 1 Due Thursday, September 19, in class What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
6.867 Machine Learning Problem set 1 Due Thursday, September 19, in class What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
CSC2515 Assignment #2
 CSC2515 Assignment #2 Due: Nov.4, 2pm at the START of class Worth: 18% Late assignments not accepted. 1 Pseudo-Bayesian Linear Regression (3%) In this question you will dabble in Bayesian statistics and
CSC2515 Assignment #2 Due: Nov.4, 2pm at the START of class Worth: 18% Late assignments not accepted. 1 Pseudo-Bayesian Linear Regression (3%) In this question you will dabble in Bayesian statistics and
Statistical and Learning Techniques in Computer Vision Lecture 2: Maximum Likelihood and Bayesian Estimation Jens Rittscher and Chuck Stewart
 Statistical and Learning Techniques in Computer Vision Lecture 2: Maximum Likelihood and Bayesian Estimation Jens Rittscher and Chuck Stewart 1 Motivation and Problem In Lecture 1 we briefly saw how histograms
Statistical and Learning Techniques in Computer Vision Lecture 2: Maximum Likelihood and Bayesian Estimation Jens Rittscher and Chuck Stewart 1 Motivation and Problem In Lecture 1 we briefly saw how histograms
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Bayes Classifiers. CAP5610 Machine Learning Instructor: Guo-Jun QI
 Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 143 Part IV
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 143 Part IV
LECTURE NOTE #3 PROF. ALAN YUILLE
 LECTURE NOTE #3 PROF. ALAN YUILLE 1. Three Topics (1) Precision and Recall Curves. Receiver Operating Characteristic Curves (ROC). What to do if we do not fix the loss function? (2) The Curse of Dimensionality.
LECTURE NOTE #3 PROF. ALAN YUILLE 1. Three Topics (1) Precision and Recall Curves. Receiver Operating Characteristic Curves (ROC). What to do if we do not fix the loss function? (2) The Curse of Dimensionality.
Decision Trees. Nicholas Ruozzi University of Texas at Dallas. Based on the slides of Vibhav Gogate and David Sontag
 Decision Trees Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Supervised Learning Input: labelled training data i.e., data plus desired output Assumption:
Decision Trees Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Supervised Learning Input: labelled training data i.e., data plus desired output Assumption:
L2: Review of probability and statistics
 Probability L2: Review of probability and statistics Definition of probability Axioms and properties Conditional probability Bayes theorem Random variables Definition of a random variable Cumulative distribution
Probability L2: Review of probability and statistics Definition of probability Axioms and properties Conditional probability Bayes theorem Random variables Definition of a random variable Cumulative distribution
COMP 551 Applied Machine Learning Lecture 20: Gaussian processes
 COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
Lecture 11. Probability Theory: an Overveiw
 Math 408 - Mathematical Statistics Lecture 11. Probability Theory: an Overveiw February 11, 2013 Konstantin Zuev (USC) Math 408, Lecture 11 February 11, 2013 1 / 24 The starting point in developing the
Math 408 - Mathematical Statistics Lecture 11. Probability Theory: an Overveiw February 11, 2013 Konstantin Zuev (USC) Math 408, Lecture 11 February 11, 2013 1 / 24 The starting point in developing the
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout 2:. The Multivariate Gaussian & Decision Boundaries
 University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Error Rates. Error vs Threshold. ROC Curve. Biometrics: A Pattern Recognition System. Pattern classification. Biometrics CSE 190 Lecture 3
 Biometrics: A Pattern Recognition System Yes/No Pattern classification Biometrics CSE 190 Lecture 3 Authentication False accept rate (FAR): Proportion of imposters accepted False reject rate (FRR): Proportion
Biometrics: A Pattern Recognition System Yes/No Pattern classification Biometrics CSE 190 Lecture 3 Authentication False accept rate (FAR): Proportion of imposters accepted False reject rate (FRR): Proportion
DIFFERENT APPROACHES TO STATISTICAL INFERENCE: HYPOTHESIS TESTING VERSUS BAYESIAN ANALYSIS
 DIFFERENT APPROACHES TO STATISTICAL INFERENCE: HYPOTHESIS TESTING VERSUS BAYESIAN ANALYSIS THUY ANH NGO 1. Introduction Statistics are easily come across in our daily life. Statements such as the average
DIFFERENT APPROACHES TO STATISTICAL INFERENCE: HYPOTHESIS TESTING VERSUS BAYESIAN ANALYSIS THUY ANH NGO 1. Introduction Statistics are easily come across in our daily life. Statements such as the average
Reminders. Thought questions should be submitted on eclass. Please list the section related to the thought question
 Linear regression Reminders Thought questions should be submitted on eclass Please list the section related to the thought question If it is a more general, open-ended question not exactly related to a
Linear regression Reminders Thought questions should be submitted on eclass Please list the section related to the thought question If it is a more general, open-ended question not exactly related to a
Machine Learning Lecture 1
 Many slides adapted from B. Schiele Machine Learning Lecture 1 Introduction 18.04.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de Organization Lecturer Prof.
Many slides adapted from B. Schiele Machine Learning Lecture 1 Introduction 18.04.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de Organization Lecturer Prof.
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Human-Oriented Robotics. Probability Refresher. Kai Arras Social Robotics Lab, University of Freiburg Winter term 2014/2015
 Probability Refresher Kai Arras, University of Freiburg Winter term 2014/2015 Probability Refresher Introduction to Probability Random variables Joint distribution Marginalization Conditional probability
Probability Refresher Kai Arras, University of Freiburg Winter term 2014/2015 Probability Refresher Introduction to Probability Random variables Joint distribution Marginalization Conditional probability
Machine Learning, Fall 2009: Midterm
 10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Probability Models for Bayesian Recognition
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG / osig Second Semester 06/07 Lesson 9 0 arch 07 Probability odels for Bayesian Recognition Notation... Supervised Learning for Bayesian
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG / osig Second Semester 06/07 Lesson 9 0 arch 07 Probability odels for Bayesian Recognition Notation... Supervised Learning for Bayesian
Algorithm-Independent Learning Issues
 Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning
Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides
 Many thanks to Carlos Thomaz who authored the original version of these slides") Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides Intelligent Data Analysis and Probabilistic Inference Lecture
Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides Intelligent Data Analysis and Probabilistic Inference Lecture
Lecture 13: Data Modelling and Distributions. Intelligent Data Analysis and Probabilistic Inference Lecture 13 Slide No 1
 Lecture 13: Data Modelling and Distributions Intelligent Data Analysis and Probabilistic Inference Lecture 13 Slide No 1 Why data distributions? It is a well established fact that many naturally occurring
Lecture 13: Data Modelling and Distributions Intelligent Data Analysis and Probabilistic Inference Lecture 13 Slide No 1 Why data distributions? It is a well established fact that many naturally occurring
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Intensity Analysis of Spatial Point Patterns Geog 210C Introduction to Spatial Data Analysis
 Intensity Analysis of Spatial Point Patterns Geog 210C Introduction to Spatial Data Analysis Chris Funk Lecture 4 Spatial Point Patterns Definition Set of point locations with recorded events" within study
Intensity Analysis of Spatial Point Patterns Geog 210C Introduction to Spatial Data Analysis Chris Funk Lecture 4 Spatial Point Patterns Definition Set of point locations with recorded events" within study
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Machine Learning Lecture 2
 Announcements Machine Learning Lecture 2 Eceptional number of lecture participants this year Current count: 449 participants This is very nice, but it stretches our resources to their limits Probability
Announcements Machine Learning Lecture 2 Eceptional number of lecture participants this year Current count: 449 participants This is very nice, but it stretches our resources to their limits Probability
Bayesian Decision Theory
 Bayesian Decision Theory Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551, Fall 2017 c 2017, Selim Aksoy (Bilkent University) 1 / 46 Bayesian
Bayesian Decision Theory Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551, Fall 2017 c 2017, Selim Aksoy (Bilkent University) 1 / 46 Bayesian
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Nonparametric Methods
 Nonparametric Methods Michael R. Roberts Department of Finance The Wharton School University of Pennsylvania July 28, 2009 Michael R. Roberts Nonparametric Methods 1/42 Overview Great for data analysis
Nonparametric Methods Michael R. Roberts Department of Finance The Wharton School University of Pennsylvania July 28, 2009 Michael R. Roberts Nonparametric Methods 1/42 Overview Great for data analysis