PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
|
|
|
- Barnaby Clark
- 6 years ago
- Views:
Transcription
1 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS

2 Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting

3 Binary Variables (1) Coin flipping: heads=1, tails=0 Bernoulli Distribution
")

4 Binary Variables (2) N coin flips: Binomial Distribution
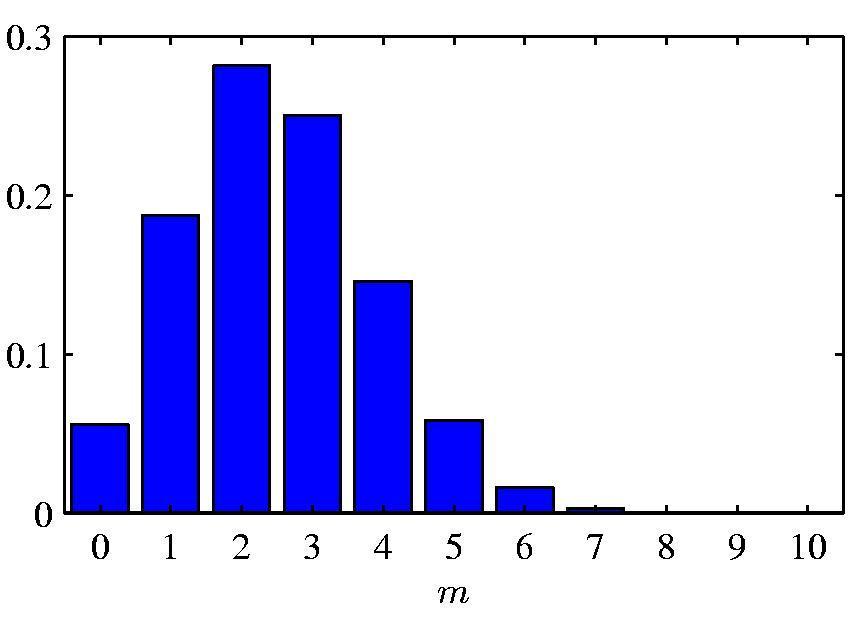
5 Binomial Distribution


6 Parameter Estimation (1) ML for Bernoulli Given:

7 Parameter Estimation (2) Example: Prediction: all future tosses will land heads up Overfitting to D

8 Beta Distribution Distribution over.

9 Bayesian Bernoulli The Beta distribution provides the conjugate prior for the Bernoulli distribution.
10 Beta Distribution
11 Prior Likelihood = Posterior

12 Properties of the Posterior As the size of the data set, N, increase

13 Prediction under the Posterior What is the probability that the next coin toss will land heads up?
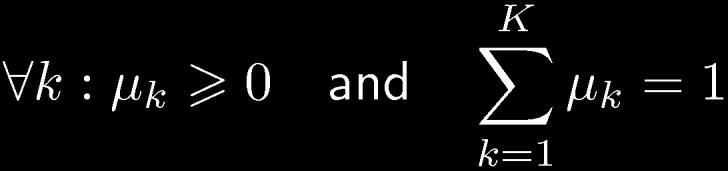
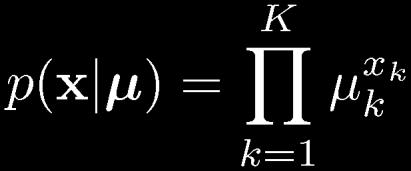
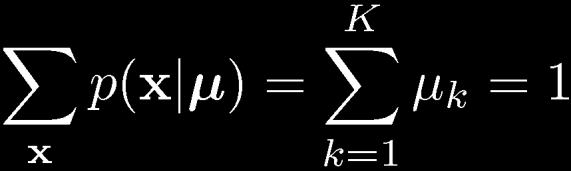
14 Multinomial Variables 1-of-K coding scheme:


15 ML Parameter estimation Given: Ensure, use a Lagrange multiplier,.

16 The Multinomial Distribution



17 The Dirichlet Distribution Conjugate prior for the multinomial distribution.
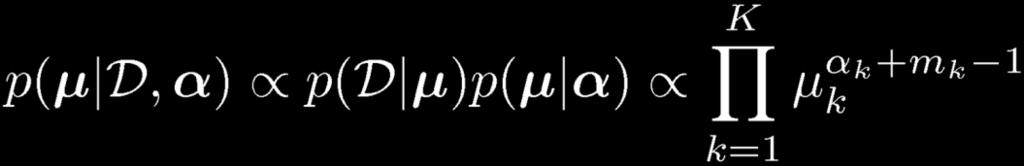
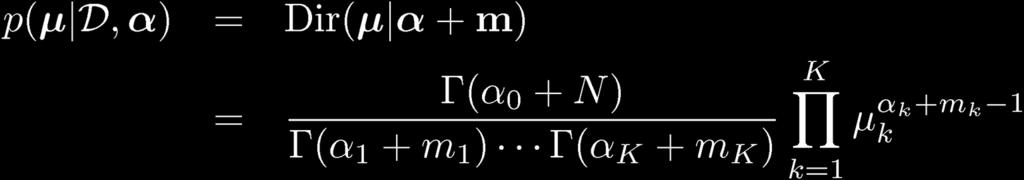
18 Bayesian Multinomial (1)
19 Bayesian Multinomial (2)
20 The Gaussian Distribution


21 Central Limit Theorem The distribution of the sum of N i.i.d. random variables becomes increasingly Gaussian as N grows. Example: N uniform [0,1] random variables.

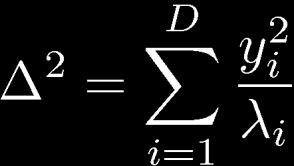
22 Geometry of the Multivariate Gaussian
 thanks to")
23 Moments of the Multivariate Gaussian (1) thanks to anti-symmetry of z
24 Moments of the Multivariate Gaussian (2)
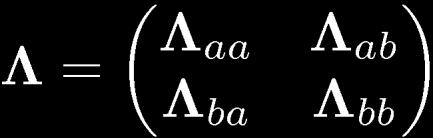
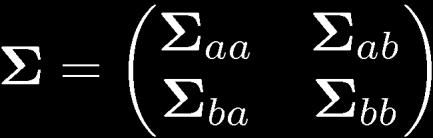
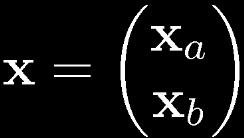
25 Partitioned Gaussian Distributions
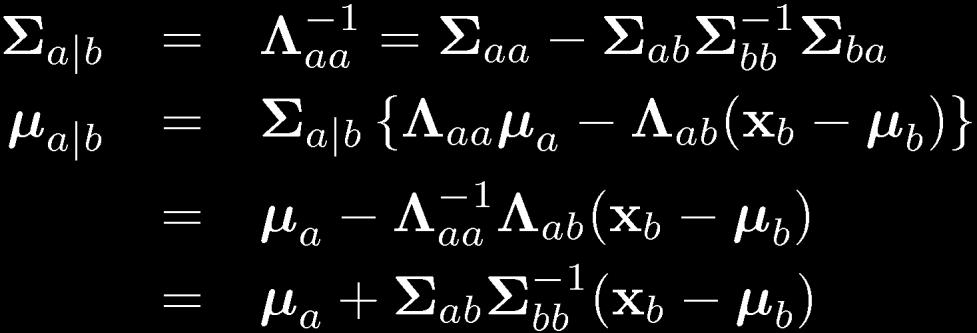
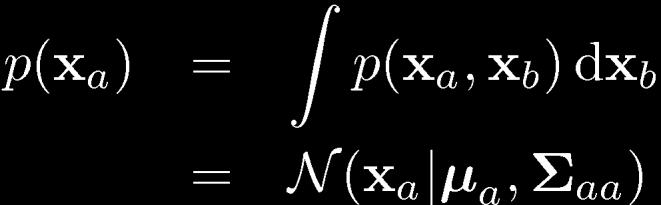
26 Partitioned Conditionals and Marginals
27 Partitioned Conditionals and Marginals

28 Bayes Theorem for Gaussian Variables Given we have where
29 Maximum Likelihood for the Gaussian (1), the log likeli- Given i.i.d. data hood function is given by Sufficient statistics
")


30 Maximum Likelihood for the Gaussian (2) Set the derivative of the log likelihood function to zero, and solve to obtain Similarly

31 Maximum Likelihood for the Gaussian (3) Under the true distribution Hence define

32 Sequential Estimation Contribution of the N th data point, x N correction given x N correction weight old estimate
 and define the regression function Seek µ? such that f(µ?")
33 The Robbins-Monro Algorithm (1) Consider µ and z governed by p(z,µ) and define the regression function Seek µ? such that f(µ? ) = 0.
34 The Robbins-Monro Algorithm (2) Assume we are given samples from p(z,µ), one at the time.
35 The Robbins-Monro Algorithm (3) Successive estimates of µ? are then given by Conditions on a N for convergence :
36 Robbins-Monro for Maximum Likelihood (1) Regarding as a regression function, finding its root is equivalent to finding the maximum likelihood solution µ ML. Thus

37 Robbins-Monro for Maximum Likelihood (2) Example: estimate the mean of a Gaussian. The distribution of z is Gaussian with mean ¹ { ¹ ML. For the Robbins-Monro update equation, a N = ¾ 2 =N.
38 Bayesian Inference for the Gaussian (1) Assume ¾ 2 is known. Given i.i.d. data, the likelihood function for ¹ is given by This has a Gaussian shape as a function of ¹ (but it is not a distribution over ¹).
39 Bayesian Inference for the Gaussian (2) Combined with a Gaussian prior over ¹, this gives the posterior Completing the square over ¹, we see that

")
40 Bayesian Inference for the Gaussian (3) where Note:
41 Bayesian Inference for the Gaussian (4) Example: for N = 0, 1, 2 and 10.

42 Bayesian Inference for the Gaussian (5) Sequential Estimation The posterior obtained after observing N { 1 data points becomes the prior when we observe the N th data point.
43 Bayesian Inference for the Gaussian (6) Now assume ¹ is known. The likelihood function for = 1/¾ 2 is given by This has a Gamma shape as a function of.
 The Gamma")
44 Bayesian Inference for the Gaussian (7) The Gamma distribution
45 Bayesian Inference for the Gaussian (8) Now we combine a Gamma prior,, with the likelihood function for to obtain which we recognize as with

46 Bayesian Inference for the Gaussian (9) If both ¹ and are unknown, the joint likelihood function is given by We need a prior with the same functional dependence on ¹ and.

47 Bayesian Inference for the Gaussian (10) The Gaussian-gamma distribution Quadratic in ¹. Linear in. Gamma distribution over. Independent of ¹.
48 Bayesian Inference for the Gaussian (11) The Gaussian-gamma distribution
49 Bayesian Inference for the Gaussian (12) Multivariate conjugate priors ¹ unknown, known: p(¹) Gaussian. unknown, ¹ known: p( ) Wishart, and ¹ unknown: p(¹, ) Gaussian- Wishart,

50 Student s t-distribution where Infinite mixture of Gaussians.

51 Student s t-distribution
52 Student s t-distribution Robustness to outliers: Gaussian vs t-distribution.


53 Student s t-distribution The D-variate case: where. Properties:

54 Periodic variables Examples: calendar time, direction, We require

55 von Mises Distribution (1) This requirement is satisfied by where is the 0 th order modified Bessel function of the 1 st kind.
56 von Mises Distribution (4)


57 Maximum Likelihood for von Mises Given a data set, is given by, the log likelihood function Maximizing with respect to µ 0 we directly obtain Similarly, maximizing with respect to m we get which can be solved numerically for m ML.
58 Mixtures of Gaussians (1) Old Faithful data set Single Gaussian Mixture of two Gaussians

59 Mixtures of Gaussians (2) Combine simple models into a complex model: Component Mixing coefficient K=3

60 Mixtures of Gaussians (3)

61 Mixtures of Gaussians (4) Determining parameters ¹,, and ¼ using maximum log likelihood Log of a sum; no closed form maximum. Solution: use standard, iterative, numeric optimization methods or the expectation maximization algorithm (Chapter 9).
 can be interpreted as a normalization")
62 The Exponential Family (1) where is the natural parameter and so g( ) can be interpreted as a normalization coefficient.



63 The Exponential Family (2.1) The Bernoulli Distribution Comparing with the general form we see that and so Logistic sigmoid
 The Bernoulli distribution can hence be")
64 The Exponential Family (2.2) The Bernoulli distribution can hence be written as where
 The Multinomial")


65 The Exponential Family (3.1) The Multinomial Distribution where,, and NOTE: The k parameters are not independent since the corresponding ¹ k must satisfy
 Let.")


66 The Exponential Family (3.2) Let. This leads to and Here the k parameters are independent. Note that and Softmax
 The Multinomial distribution can then")
67 The Exponential Family (3.3) The Multinomial distribution can then be written as where


68 The Exponential Family (4) The Gaussian Distribution where
69 ML for the Exponential Family (1) From the definition of g( ) we get Thus

70 ML for the Exponential Family (2) Give a data set, function is given by, the likelihood Thus we have Sufficient statistic
71 Conjugate priors For any member of the exponential family, there exists a prior Combining with the likelihood function, we get Prior corresponds to º pseudo-observations with value Â.

72 Noninformative Priors (1) With little or no information available a-priori, we might choose a non-informative prior. discrete, K-nomial : 2[a,b] real and bounded: real and unbounded: improper! A constant prior may no longer be constant after a change of variable; consider p( ) constant and = 2:
73 Noninformative Priors (2) Translation invariant priors. Consider For a corresponding prior over ¹, we have for any A and B. Thus p(¹) = p(¹ { c) and p(¹) must be constant.

74 Noninformative Priors (3) Example: The mean of a Gaussian, ¹ ; the conjugate prior is also a Gaussian, As, this will become constant over ¹.
75 Noninformative Priors (4) Scale invariant priors. Consider and make the change of variable For a corresponding prior over ¾, we have for any A and B. Thus p(¾) / 1/¾ and so this prior is improper too. Note that this corresponds to p(ln ¾) being constant.
76 Noninformative Priors (5) Example: For the variance of a Gaussian, ¾ 2, we have If = 1/¾ 2 and p(¾) / 1/¾, then p( ) / 1/. We know that the conjugate distribution for is the Gamma distribution, A noninformative prior is obtained when a 0 = 0 and b 0 = 0.
77 Nonparametric Methods (1) Parametric distribution models are restricted to specific forms, which may not always be suitable; for example, consider modelling a multimodal distribution with a single, unimodal model. Nonparametric approaches make few assumptions about the overall shape of the distribution being modelled.


78 Nonparametric Methods (2) Histogram methods partition the data space into distinct bins with widths i and count the number of observations, n i, in each bin. Often, the same width is used for all bins, i =. acts as a smoothing parameter. In a D-dimensional space, using M bins in each dimension will require M D bins!

 and if N is large Thus V small, yet K>0, therefore N large?")
79 Nonparametric Methods (3) Assume observations drawn from a density p(x) and consider a small region R containing x such that If the volume of R, V, is sufficiently small, p(x) is approximately constant over R and The probability that K out of N observations lie inside R is Bin(KjN,P ) and if N is large Thus V small, yet K>0, therefore N large?

 It follows")
80 Nonparametric Methods (4) Kernel Density Estimation: fix V, estimate K from the data. Let R be a hypercube centred on x and define the kernel function (Parzen window) It follows that and hence
, use a smooth")

81 Nonparametric Methods (5) To avoid discontinuities in p(x), use a smooth kernel, e.g. a Gaussian Any kernel such that will work. h acts as a smoother.

82 Nonparametric Methods (6) Nearest Neighbour Density Estimation: fix K, estimate V from the data. Consider a hypersphere centred on x and let it grow to a volume, V?, that includes K of the given N data points. Then K acts as a smoother.
83 Nonparametric Methods (7) Nonparametric models (not histograms) requires storing and computing with the entire data set. Parametric models, once fitted, are much more efficient in terms of storage and computation.
 Given")


84 K-Nearest-Neighbours for Classification (1) Given a data set with N k data points from class C k and, we have and correspondingly Since, Bayes theorem gives
85 K-Nearest-Neighbours for Classification (2) K = 3 K = 1


86 K-Nearest-Neighbours for Classification (3) K acts as a smother For, the error rate of the 1-nearest-neighbour classifier is never more than twice the optimal error (obtained from the true conditional class distributions).
Curve Fitting Re-visited, Bishop1.2.5
 Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
PROBABILITY DISTRIBUTIONS. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
Pattern Recognition and Machine Learning. Bishop Chapter 2: Probability Distributions
 Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
BAYESIAN DECISION THEORY
 Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
ECE285/SIO209, Machine learning for physical applications, Spring 2017
 ECE285/SIO209, Machine learning for physical applications, Spring 2017 Peter Gerstoft, 534-7768, gerstoft@ucsd.edu We meet Wednesday from 5 to 6:20pm in Spies Hall 330 Text Bishop Grading A or maybe S
ECE285/SIO209, Machine learning for physical applications, Spring 2017 Peter Gerstoft, 534-7768, gerstoft@ucsd.edu We meet Wednesday from 5 to 6:20pm in Spies Hall 330 Text Bishop Grading A or maybe S
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP
 INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP Personal Healthcare Revolution Electronic health records (CFH) Personal genomics (DeCode, Navigenics, 23andMe) X-prize: first $10k human genome technology
INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP Personal Healthcare Revolution Electronic health records (CFH) Personal genomics (DeCode, Navigenics, 23andMe) X-prize: first $10k human genome technology
Stat 5101 Lecture Notes
 Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2
 Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Machine Learning Overview
 Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Machine Learning. Nonparametric Methods. Space of ML Problems. Todo. Histograms. Instance-Based Learning (aka non-parametric methods)
") Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Machine Learning using Bayesian Approaches
 Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Machine Learning CMPT 726 Simon Fraser University. Binomial Parameter Estimation
 Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Learning Bayesian network : Given structure and completely observed data
 Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory
 Bayesian Inference Statistical Decison Theory") Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Machine Learning Lecture 3
 Announcements Machine Learning Lecture 3 Eam dates We re in the process of fiing the first eam date Probability Density Estimation II 9.0.207 Eercises The first eercise sheet is available on L2P now First
Announcements Machine Learning Lecture 3 Eam dates We re in the process of fiing the first eam date Probability Density Estimation II 9.0.207 Eercises The first eercise sheet is available on L2P now First
Lecture 2: Conjugate priors
 (Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
(Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Outline. Binomial, Multinomial, Normal, Beta, Dirichlet. Posterior mean, MAP, credible interval, posterior distribution
 Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Probability Theory for Machine Learning. Chris Cremer September 2015
 Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Classical and Bayesian inference
 Classical and Bayesian inference AMS 132 Claudia Wehrhahn (UCSC) Classical and Bayesian inference January 8 1 / 11 The Prior Distribution Definition Suppose that one has a statistical model with parameter
Classical and Bayesian inference AMS 132 Claudia Wehrhahn (UCSC) Classical and Bayesian inference January 8 1 / 11 The Prior Distribution Definition Suppose that one has a statistical model with parameter
Generative Models for Discrete Data
 Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
NPFL108 Bayesian inference. Introduction. Filip Jurčíček. Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic
 NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Bayesian Learning. Tobias Scheffer, Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Naïve Bayes Introduction to Machine Learning. Matt Gormley Lecture 18 Oct. 31, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Maximum Likelihood Estimation. only training data is available to design a classifier
 Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Non-parametric Methods
 Non-parametric Methods Machine Learning Alireza Ghane Non-Parametric Methods Alireza Ghane / Torsten Möller 1 Outline Machine Learning: What, Why, and How? Curve Fitting: (e.g.) Regression and Model Selection
Non-parametric Methods Machine Learning Alireza Ghane Non-Parametric Methods Alireza Ghane / Torsten Möller 1 Outline Machine Learning: What, Why, and How? Curve Fitting: (e.g.) Regression and Model Selection
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
CS 361: Probability & Statistics
 October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 2 Linear Least Squares From
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 2 Linear Least Squares From
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
Lecture 11: Probability Distributions and Parameter Estimation
 Intelligent Data Analysis and Probabilistic Inference Lecture 11: Probability Distributions and Parameter Estimation Recommended reading: Bishop: Chapters 1.2, 2.1 2.3.4, Appendix B Duncan Gillies and
Intelligent Data Analysis and Probabilistic Inference Lecture 11: Probability Distributions and Parameter Estimation Recommended reading: Bishop: Chapters 1.2, 2.1 2.3.4, Appendix B Duncan Gillies and
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Motivation Scale Mixutres of Normals Finite Gaussian Mixtures Skew-Normal Models. Mixture Models. Econ 690. Purdue University
 Econ 690 Purdue University In virtually all of the previous lectures, our models have made use of normality assumptions. From a computational point of view, the reason for this assumption is clear: combined
Econ 690 Purdue University In virtually all of the previous lectures, our models have made use of normality assumptions. From a computational point of view, the reason for this assumption is clear: combined
Fundamentals. CS 281A: Statistical Learning Theory. Yangqing Jia. August, Based on tutorial slides by Lester Mackey and Ariel Kleiner
 Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
DEPARTMENT OF COMPUTER SCIENCE Autumn Semester MACHINE LEARNING AND ADAPTIVE INTELLIGENCE
 Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Non-parametric Methods
 Non-parametric Methods Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 2 of Pattern Recognition and Machine Learning by Bishop (with an emphasis on section 2.5) Möller/Mori 2 Outline Last
Non-parametric Methods Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 2 of Pattern Recognition and Machine Learning by Bishop (with an emphasis on section 2.5) Möller/Mori 2 Outline Last
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Density Estimation: ML, MAP, Bayesian estimation
 Density Estimation: ML, MAP, Bayesian estimation CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Maximum-Likelihood Estimation Maximum
Density Estimation: ML, MAP, Bayesian estimation CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Maximum-Likelihood Estimation Maximum
Linear Classification
 Linear Classification Lili MOU moull12@sei.pku.edu.cn http://sei.pku.edu.cn/ moull12 23 April 2015 Outline Introduction Discriminant Functions Probabilistic Generative Models Probabilistic Discriminative
Linear Classification Lili MOU moull12@sei.pku.edu.cn http://sei.pku.edu.cn/ moull12 23 April 2015 Outline Introduction Discriminant Functions Probabilistic Generative Models Probabilistic Discriminative
Discrete Binary Distributions
 Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
Lecture 2: Priors and Conjugacy
 Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference
 COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
Outline. Supervised Learning. Hong Chang. Institute of Computing Technology, Chinese Academy of Sciences. Machine Learning Methods (Fall 2012)
") Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Bayesian Approach 2. CSC412 Probabilistic Learning & Reasoning
 CSC412 Probabilistic Learning & Reasoning Lecture 12: Bayesian Parameter Estimation February 27, 2006 Sam Roweis Bayesian Approach 2 The Bayesian programme (after Rev. Thomas Bayes) treats all unnown quantities
CSC412 Probabilistic Learning & Reasoning Lecture 12: Bayesian Parameter Estimation February 27, 2006 Sam Roweis Bayesian Approach 2 The Bayesian programme (after Rev. Thomas Bayes) treats all unnown quantities
CS839: Probabilistic Graphical Models. Lecture 7: Learning Fully Observed BNs. Theo Rekatsinas
 CS839: Probabilistic Graphical Models Lecture 7: Learning Fully Observed BNs Theo Rekatsinas 1 Exponential family: a basic building block For a numeric random variable X p(x ) =h(x)exp T T (x) A( ) = 1
CS839: Probabilistic Graphical Models Lecture 7: Learning Fully Observed BNs Theo Rekatsinas 1 Exponential family: a basic building block For a numeric random variable X p(x ) =h(x)exp T T (x) A( ) = 1
Probability. Machine Learning and Pattern Recognition. Chris Williams. School of Informatics, University of Edinburgh. August 2014
 Probability Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh August 2014 (All of the slides in this course have been adapted from previous versions
Probability Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh August 2014 (All of the slides in this course have been adapted from previous versions
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Pattern Recognition. Parameter Estimation of Probability Density Functions
 Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
Machine Learning. Probability Basics. Marc Toussaint University of Stuttgart Summer 2014
 Machine Learning Probability Basics Basic definitions: Random variables, joint, conditional, marginal distribution, Bayes theorem & examples; Probability distributions: Binomial, Beta, Multinomial, Dirichlet,
Machine Learning Probability Basics Basic definitions: Random variables, joint, conditional, marginal distribution, Bayes theorem & examples; Probability distributions: Binomial, Beta, Multinomial, Dirichlet,
CS 361: Probability & Statistics
 March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
p L yi z n m x N n xi
 y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
Gaussian Processes. Le Song. Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012
 Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
Introduction to Machine Learning. Lecture 2
 Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
COMS 4771 Regression. Nakul Verma
 COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Empirical Bayes, Hierarchical Bayes Mark Schmidt University of British Columbia Winter 2017 Admin Assignment 5: Due April 10. Project description on Piazza. Final details coming
CPSC 540: Machine Learning Empirical Bayes, Hierarchical Bayes Mark Schmidt University of British Columbia Winter 2017 Admin Assignment 5: Due April 10. Project description on Piazza. Final details coming
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Probability and Estimation. Alan Moses
 Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
6.867 Machine Learning
 6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.