L11: Pattern recognition principles
|
|
|
- Ashlee Mills
- 6 years ago
- Views:
Transcription
1 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction to Speech Processing Ricardo Gutierrez-Osuna 1

2 Bayes decision rule Bayesian decision theory Consider the problem of making predictions for the stock market The goal is to predict whether the Dow Jones Industrial Average index will go UP, DOWN, or remain UNCHANGED Assume the only available information is the prior probability P ω i for each of the three outcomes, which we denote by ω 1, ω 2, ω 3 If we are to make predictions based only on the prior, the most sensitive decision would be to choose the class with largest prior However, this decision is unreasonable since it always makes the same prediction but we know that the DJIA does fluctuate up and down Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 2
3 To improve our predictions, we may make additional observations x, i.e., interest rates, unemployment rates, etc. These observations can be characterized by their likelihoods p x ω i, which tells how likely we are to observe x for each possible outcome With this information, and using Bayes rule we obtain P ω i x = p x ω i P ω i p x ω i P ω i = p x 3 k=1 p x ω k P ω k An intuitive decision rule would be to choose class ω k with greatest posterior k = arg max P ω i x = arg max p x ω i P ω i i i As we will see next, this rule yields the minimum decision error (on average) Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 3
4 Minimum-error-rate decision rules Let Ω = ω 1 ω s be a set of s possible categories to be predicted, and let Δ = δ 1 δ t be the finite set of t possible decisions Let l δ i ω j be the loss incurred for making decision δ i when the true class is ω j (in our market example, this loss would be financial) The expected loss associated with making δ i given observation x is s R δ i x = j=1 l δ i ω j P ω j x This expression is known as a conditional risk We then seek a decision rule δ x (a mapping from observations x into Δ = δ 1 δ t ) that minimizes the overall risk R = R δ x x p x dx which can be minimized by minimizing its integrand x, that is, by always choosing the class with lowest conditional risk k = arg min i R δ i x = arg min i l δ i ω j P ω j x Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 4 s j=1
5 Assume that all errors are equally costly, which we can model with a symmetric zero-one loss function 0 i = j l δ i ω j = 1 i j Can you think of situations where this loss function may not be advisable? Plugging this expression into that of the conditional risk yields s R δ i x = l δ i ω j P ω j x j=1 = P ω j x j i = 1 P ω i x In other words, in order to minimize classification rate, we should always choose the class with largest posterior = Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 5
6 Statistical classifiers What happens when the likelihood functions are unknown? The Bayes/MAP decision rule assumes that p x ω i are known, which is unlikely in most practical applications In this case, we have several options We can attempt to estimate p x ω i from data, by means of density estimation techniques This gives rise to methods such as Naïve Bayes and nearest-neighbors We can assume p x ω i follows a particular distribution (i.e. Normal) and estimate its parameters (see previous lecture) This gives rise to methods such as Quadratic classifiers Ignore the underlying distribution, and attempt to separate the data geometrically This gives rise to methods such as perceptrons or support vector machines Due to time constraints, here we will review two simple techniques Quadratic classifiers K nearest neighbors Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 6
7 Quadratic or Gaussian classifiers A Quadratic classifier results when we assume that the likelihood function follows a Gaussian distribution 1 1 p x ω i = 2π n/2 Σ 1/2 e 2 x μ i T 1 Σ i x μi i From which the posterior can be estimated as 1 1 P ω i x P ω i 2π n/2 Σ 1/2 e 2 x μ i T 1 Σ i x μi i Taking logs, we obtain log P ω i x = 1 2 x μ i T Σ 1 i x μ i + log P ω i 1 2 log Σ i d log 2π 2 Denoting d i x = log P ω i x, we then obtain the rule k = arg max d i x i In other words, assign example x with the class with largest d i x The function d i x is known as a discriminant function Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 7
8 To simplify the classification rule, we can eliminate terms in the discriminant function that are independent of the class d i x = 1 2 x μ i T Σ i 1 x μ i + log P ω i 1 2 log Σ i Assuming equiprobable classes, we can then drop log P ω i d i x = 1 2 x μ i T Σ i 1 x μ i 1 2 log Σ i By making additional assumptions, we can further simplify d i x Case 1: assume Σ i = Iσ 2 In this case, the discriminant function reduces to the Euclidean distance d i x = 1 2σ 2 x μ i 2 This rule is known as the minimum-distance nearest-mean classifier It can be shown that the resulting decision boundary is linear Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 8
9 Case 2: assume Σ i = Σ In this case, the discriminant function reduces to d i x = 1 2 x μ i T Σ 1 x μ i Which is also a nearest-mean classifier, but in this case uses the Mahalanobis distance instead of the Euclidean distance It can be shown that the resulting decision boundary is linear x 1 μ x 2 2 x i μ Σ 1 = C x i μ 2 = C Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 9



10 Case 1 Case 2 General case Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 10
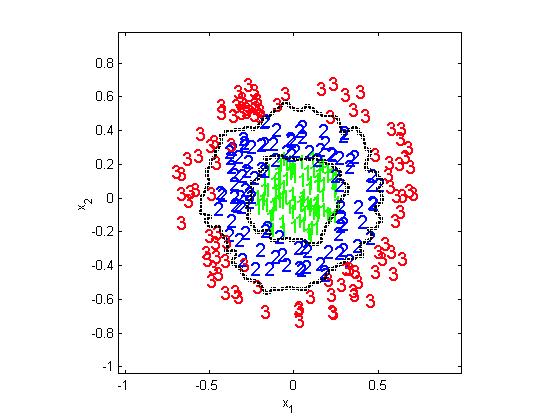
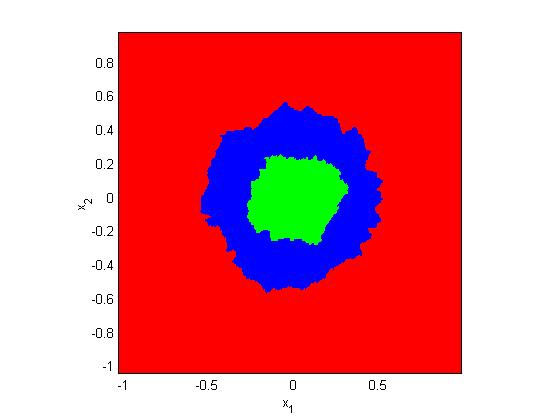
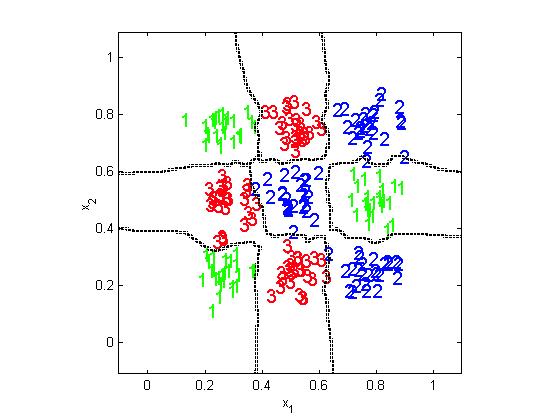
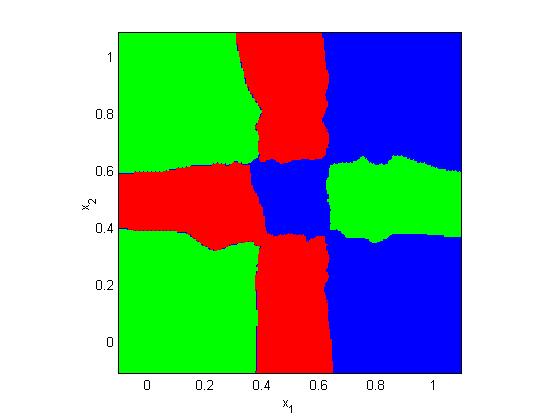
11 k nearest neighbors (knn) classifier knn is a very intuitive method that classifies unlabeled examples based on their similarity to examples in the training set Given unlabeled example x u, find the k closest examples in the training set and assign x u to the most represented class among the k-subset The knn classifier only requires: An integer k A set of labeled examples (training data) A closeness measure, generally Euclidean ω 1 x u ω 2 ω 3 Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 11
12 Advantages Analytically tractable Simple implementation Nearly optimal in the large sample limit (n ) P error Bayes < P error 1NN <2P error Bayes Uses local information, which can yield highly adaptive behavior Lends itself very easily to parallel implementations Disadvantages Large storage requirements Computationally intensive recall Highly susceptible to the curse of dimensionality 1NN versus knn The use of large values of k has two main advantages Yields smoother decision regions Provides probabilistic information However, too large a value of k is detrimental It destroys the locality of the estimation In addition, it increases the computational burden Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 12
13 Introduction to Speech Processing Ricardo Gutierrez-Osuna 13
14 Dimensionality reduction The curse of dimensionality The number of examples needed to accurately train a classifier grows exponentially with the dimensionality of the model In theory, information provided by additional features should help improve the model s accuracy In reality, however, additional features increase the risk of overfitting, i.e., memorizing noise in the data rather than its underlying structure The curse of dimensionality is an issue of trainability For a given sample size, there is a maximum number of features above which the classifier s performance degrades rather than improves In most cases, the additional information that is lost by discarding some features is (more than) compensated by a more accurate mapping in the lower-dimensional space Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 14
![[Hughes, 1968] Introduction to Speech](/docs-images/72/66820552/images/15-0.jpg "Processing Ricardo Gutierrez-Osuna")
15 [Hughes, 1968] Introduction to Speech Processing Ricardo Gutierrez-Osuna 15

16 Introduction to Speech Processing Ricardo Gutierrez-Osuna 16
17 Dimensionality reduction How do we beat the curse of dimensionality? By incorporating prior knowledge (e.g., parametric models) By enforcing smoothness in the target function (e.g., regularization) By reducing the dimensionality (e.g., feature selection/extraction) Here we focus on the last option Dimensionality reduction methods can be broadly grouped into Feature extraction methods: creating a subset of new features by combinations of the existing features y = f x Methods of this type include Principal Components Analysis (PCA) and Fisher s Linear Discriminant Analysis (LDA) Feature selection methods: choosing a subset of all the features Methods of this kind include sequential selection techniques (forward, backward), and won t be reviewed here Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 17
18 Feature 2 Feature extraction Two types of criteria are commonly used Signal representation: The goal of feature selection is to accurately represent the samples accurately in a lower-dimensional space Classification: The goal of feature selection is to enhance the classdiscriminatory information in the lower-dimensional space Within the realm of linear feature extraction y = f x = Ax, two techniques are generally used Principal Components Analysis, which we mentioned earlier in terms of the Karhunen-Loewe transform Fisher s Linear Discriminants Analysis, which shares strong connections with the quadratic classifiers we reviewed earlier Feature 1 Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 18
19 Principal Components Analysis Project the data onto the eigenvectors v i corresponding to the largest eigenvalues λ i of the data s covariance matrix Σ y = Ax A = v 1 v 2 v M λ i v i = Σv i PCA finds orthogonal directions of largest variance If data is Gaussian, PCA finds independent axes; otherwise, PCA simply de-correlates the features However, directions of high variance do not necessarily contain discriminatory information Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 19
20 Linear Discriminants Analysis Define scatter matrices Within class S W = C S i C = x μ i x μ i T i=1 Between class C i=1 x ω i S B = N i μ i μ μ i μ T x 2 S W1 i=1 Then maximize ratio J W = WT S B W W T S W W 1 S B1 S B2 S B3 3 S W3 2 S W2 x 1 Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 20
21 Solution Notes Optimal projections are the eigenvectors of the largest eigenvalues of the generalized eigenvalue problem S B λ i S W v i = 0 S B is the sum of C matrices of rank one or less, and the mean vectors are constrained by Σ i μ i = μ Therefore, S B will be at most of rank C 1, and LDA produces at most C 1 feature projections Limitations Overfitting Information not in the mean of the data Classes significantly non Gaussian Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 21
22 ex11p1.m Computing principal components analysis Computing linear discriminants analysis Introduction to Speech Processing Ricardo Gutierrez-Osuna 22
23 Clustering Supervised vs. unsupervised learning The methods discussed so far have focused on classification A pattern consisted of a pair of variables x, ω, where x was a feature vector, and ω was the concept behind the observation Such pattern recognition problems are called supervised (training with a teacher) since the system is given the correct answer Now we explore methods that operate on unlabeled data Given a collection of feature vectors X = X 1, X 2 X n without class labels ω i, the goal is build a model that captures the structure of the data These methods are called unsupervised (training without a teacher) since they are not provided the correct answer In particular, we will explore two methods that will later be reused when we discussed hidden Markov models Gaussian mixture models (and the EM algorithm), and K means clustering Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 23
24 Gaussian mixture models Consider the problem of modeling a pdf given a dataset of examples If the form of the underlying pdf is known (e.g. Gaussian), the problem can be solved through parameter estimation If the form of the pdf is unknown, the problem must to be solved with non-parametric density estimation methods such as Parzen windows We will now consider an alternative density estimation method: modeling the pdf with a mixture of parametric densities These methods are sometimes known as semi-parametric In particular, we will focus on mixture models of Gaussian densities C p x θ = p x θ c p θ c c=1 Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 24
25 The GMM can be framed in terms of the ML criterion Given a dataset of examples X = X 1, X 2 X n, we seek to find model parameters θ that maximize the log likelihood of the data θ ML = arg max θ p X θ n = arg max θ C n i=1 log p x i θ) = arg max log p x i θ c p θ c θ i=1 c=1 where θ c = μ c, Σ c and p θ c are the parameters and mixing coefficient of the c-th mixture component, respectively We could try to find the maximum of this function by differentiation For Σ i = Iσ i, the solution becomes [Bishop, 1995] n i=1 p θ c x i x i = 0 μ c = n μ c i=1 p θ c x i = 0 σ 2 σ c = 1 n i=1 p θ c x i x i μ c 2 n c d i=1 p θ c x i = 0 p θ p θ c = 1 n p θ c n c x i i=1 = Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 25
26 Notice that the previous equations are not a closed form solution Parameters μ c, Σ c, p θ c also appear on the RHS because of Bayes rule! Thus, this is a highly non-linear coupled system of equations These expressions, however, suggest that we may be able to use a fixed-point algorithm to find the maxima 1. Begin with some value of the model parameters (the old values) 2. Evaluate the RHS to obtain new values for the parameters 3. Let these new values become the old ones and repeat the process Surprisingly, an algorithm this simple can be found that is guaranteed to increase the log-likelihood with every iteration This example represents a particular case of a more general procedure known as the Expectation-Maximization algorithm Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 26
27 A derivation of the update equations for the full-covariance mixture model can be found in [Nabney, 2002] The final equations are provided here for those of you interested in experimenting with mixture models p (k θ c = 1 n n n i=1 p (k 1 θ c x i (k i=1 p (k 1 θ c x i x i μ c = n i=1 p (k 1 θ c x i n p (k 1 (k (k θ (i c x i x i μ c x i μ T i=1 c Σ c = n i=1 p (k 1 θ c x i Notice where the new parameters θ (k and old parameters θ (k 1 appear on the RHS and compare these expressions to those earlier for the univariate case Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 27
28 GMM example Training set: n = 900 examples from a uniform pdf inside an annulus Model: GMM with C = 30 Gaussian components Training procedure Gaussians centers initialized by choosing 30 arbitrary training examples Covariance matrices initialized to be diagonal, with large variance compared to that of the training data To avoid singularities, at every iteration the covariance matrices computed with EM were regularized with a small multiple of the identity matrix Components whose mixing coefficients fell below a threshold are removed Illustrative results are provided in the next slide Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 28
29 Iteration 0 Iteration 25 Iteration Iteration 75 Iteration 275 Iteration
30 k-means clustering The k-means algorithm is a simple procedure that attempts to group a collection of unlabeled examples X = x 1 x n into one of C clusters k-means seeks to find compact clusters, measured as C 2 J MSE = x μ c ; μ c = 1 x c=1 x ω c n c x ω c It can be shown that k-means is a special case of the GMM-EM algorithm Procedure 1. Define the number of clusters 2. Initialize clusters by a) an arbitrary assignment of examples to clusters or b) an arbitrary set of cluster centers (i.e., use some examples as centers) 3. Compute the sample mean of each cluster 4. Reassign each example to the cluster with the nearest mean 5. If the classification of all samples has not changed, stop, else go to step 3 Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 30
31 k-means is widely used in DSP for Vector Quantization Unidimensional signal values are usually quantized into a number of levels (typically a power of 2 so the signal can be transmitted in binary format) The same idea can be extended for multiple channels However, rather than quantizing each separate channel, we can obtain a more efficient signal coding by quantizing the overall multidimensional vector into a small number of multidimensional prototypes (cluster centers) Each cluster center is called a codeword and the collection of codewords is called a codebook 8 7 Q uantized 6 signal S ig nal C o n tin u o u s sig n al 2 Q uantization Codew ords V ecto rs 1 n o ise 0 V o ro n o i reg io n T im e (s) Introduction to Speech Processing Ricardo Gutierrez-Osuna CSE@TAMU 31
32 ex11p2.m k-means clustering Introduction to Speech Processing Ricardo Gutierrez-Osuna 32
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
L5: Quadratic classifiers
 L5: Quadratic classifiers Bayes classifiers for Normally distributed classes Case 1: Σ i = σ 2 I Case 2: Σ i = Σ (Σ diagonal) Case 3: Σ i = Σ (Σ non-diagonal) Case 4: Σ i = σ 2 i I Case 5: Σ i Σ j (general
L5: Quadratic classifiers Bayes classifiers for Normally distributed classes Case 1: Σ i = σ 2 I Case 2: Σ i = Σ (Σ diagonal) Case 3: Σ i = Σ (Σ non-diagonal) Case 4: Σ i = σ 2 i I Case 5: Σ i Σ j (general
Feature selection and extraction Spectral domain quality estimation Alternatives
 Feature selection and extraction Error estimation Maa-57.3210 Data Classification and Modelling in Remote Sensing Markus Törmä markus.torma@tkk.fi Measurements Preprocessing: Remove random and systematic
Feature selection and extraction Error estimation Maa-57.3210 Data Classification and Modelling in Remote Sensing Markus Törmä markus.torma@tkk.fi Measurements Preprocessing: Remove random and systematic
Dimensionality Reduction Using PCA/LDA. Hongyu Li School of Software Engineering TongJi University Fall, 2014
 Dimensionality Reduction Using PCA/LDA Hongyu Li School of Software Engineering TongJi University Fall, 2014 Dimensionality Reduction One approach to deal with high dimensional data is by reducing their
Dimensionality Reduction Using PCA/LDA Hongyu Li School of Software Engineering TongJi University Fall, 2014 Dimensionality Reduction One approach to deal with high dimensional data is by reducing their
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides
 Many thanks to Carlos Thomaz who authored the original version of these slides") Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides Intelligent Data Analysis and Probabilistic Inference Lecture
Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides Intelligent Data Analysis and Probabilistic Inference Lecture
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
EEL 851: Biometrics. An Overview of Statistical Pattern Recognition EEL 851 1
 EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
BAYESIAN DECISION THEORY
 Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
COM336: Neural Computing
 COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Bayesian Decision Theory
 Bayesian Decision Theory Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551, Fall 2017 c 2017, Selim Aksoy (Bilkent University) 1 / 46 Bayesian
Bayesian Decision Theory Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551, Fall 2017 c 2017, Selim Aksoy (Bilkent University) 1 / 46 Bayesian
SGN (4 cr) Chapter 5
 Chapter 5") SGN-41006 (4 cr) Chapter 5 Linear Discriminant Analysis Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology January 21, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
SGN-41006 (4 cr) Chapter 5 Linear Discriminant Analysis Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology January 21, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
Machine Learning 2017
 Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
5. Discriminant analysis
 5. Discriminant analysis We continue from Bayes s rule presented in Section 3 on p. 85 (5.1) where c i is a class, x isap-dimensional vector (data case) and we use class conditional probability (density
5. Discriminant analysis We continue from Bayes s rule presented in Section 3 on p. 85 (5.1) where c i is a class, x isap-dimensional vector (data case) and we use class conditional probability (density
Heeyoul (Henry) Choi. Dept. of Computer Science Texas A&M University
 Choi. Dept. of Computer Science Texas A&M University") Heeyoul (Henry) Choi Dept. of Computer Science Texas A&M University hchoi@cs.tamu.edu Introduction Speaker Adaptation Eigenvoice Comparison with others MAP, MLLR, EMAP, RMP, CAT, RSW Experiments Future
Heeyoul (Henry) Choi Dept. of Computer Science Texas A&M University hchoi@cs.tamu.edu Introduction Speaker Adaptation Eigenvoice Comparison with others MAP, MLLR, EMAP, RMP, CAT, RSW Experiments Future
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
L20: MLPs, RBFs and SPR Bayes discriminants and MLPs The role of MLP hidden units Bayes discriminants and RBFs Comparison between MLPs and RBFs
 L0: MLPs, RBFs and SPR Bayes discriminants and MLPs The role of MLP hidden units Bayes discriminants and RBFs Comparison between MLPs and RBFs CSCE 666 Pattern Analysis Ricardo Gutierrez-Osuna CSE@TAMU
L0: MLPs, RBFs and SPR Bayes discriminants and MLPs The role of MLP hidden units Bayes discriminants and RBFs Comparison between MLPs and RBFs CSCE 666 Pattern Analysis Ricardo Gutierrez-Osuna CSE@TAMU
Mathematical Formulation of Our Example
 Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Machine Learning 2nd Edition
 INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
Clustering VS Classification
 MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
L26: Advanced dimensionality reduction
 L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Pattern Recognition 2
 Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Classification: The rest of the story
 U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
Lecture 3: Pattern Classification
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
Machine Learning. Nonparametric Methods. Space of ML Problems. Todo. Histograms. Instance-Based Learning (aka non-parametric methods)
") Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Clustering by Mixture Models. General background on clustering Example method: k-means Mixture model based clustering Model estimation
 Clustering by Mixture Models General bacground on clustering Example method: -means Mixture model based clustering Model estimation 1 Clustering A basic tool in data mining/pattern recognition: Divide
Clustering by Mixture Models General bacground on clustering Example method: -means Mixture model based clustering Model estimation 1 Clustering A basic tool in data mining/pattern recognition: Divide
Introduction to Machine Learning
 Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Computer Vision Group Prof. Daniel Cremers. 3. Regression
 Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning. Theory of Classification and Nonparametric Classifier. Lecture 2, January 16, What is theoretically the best classifier
 Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout 2:. The Multivariate Gaussian & Decision Boundaries
 University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
ENG 8801/ Special Topics in Computer Engineering: Pattern Recognition. Memorial University of Newfoundland Pattern Recognition
 Memorial University of Newfoundland Pattern Recognition Lecture 6 May 18, 2006 http://www.engr.mun.ca/~charlesr Office Hours: Tuesdays & Thursdays 8:30-9:30 PM EN-3026 Review Distance-based Classification
Memorial University of Newfoundland Pattern Recognition Lecture 6 May 18, 2006 http://www.engr.mun.ca/~charlesr Office Hours: Tuesdays & Thursdays 8:30-9:30 PM EN-3026 Review Distance-based Classification
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Linear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Pattern Recognition. Parameter Estimation of Probability Density Functions
 Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
IN Pratical guidelines for classification Evaluation Feature selection Principal component transform Anne Solberg
 IN 5520 30.10.18 Pratical guidelines for classification Evaluation Feature selection Principal component transform Anne Solberg (anne@ifi.uio.no) 30.10.18 IN 5520 1 Literature Practical guidelines of classification
IN 5520 30.10.18 Pratical guidelines for classification Evaluation Feature selection Principal component transform Anne Solberg (anne@ifi.uio.no) 30.10.18 IN 5520 1 Literature Practical guidelines of classification
Clustering. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Clustering CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Supervised vs Unsupervised Learning Supervised learning Given x ", y " "%& ', learn a function f: X Y Categorical output classification
Clustering CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Supervised vs Unsupervised Learning Supervised learning Given x ", y " "%& ', learn a function f: X Y Categorical output classification
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Introduction to Graphical Models
 Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Introduction to Machine Learning. Introduction to ML - TAU 2016/7 1
 Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Data Mining. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Introduction to Machine Learning
 Introduction to Machine Learning Bayesian Classification Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Introduction to Machine Learning Bayesian Classification Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Pattern Classification
 Pattern Classification Introduction Parametric classifiers Semi-parametric classifiers Dimensionality reduction Significance testing 6345 Automatic Speech Recognition Semi-Parametric Classifiers 1 Semi-Parametric
Pattern Classification Introduction Parametric classifiers Semi-parametric classifiers Dimensionality reduction Significance testing 6345 Automatic Speech Recognition Semi-Parametric Classifiers 1 Semi-Parametric
University of Cambridge Engineering Part IIB Module 4F10: Statistical Pattern Processing Handout 2: Multivariate Gaussians
 Engineering Part IIB: Module F Statistical Pattern Processing University of Cambridge Engineering Part IIB Module F: Statistical Pattern Processing Handout : Multivariate Gaussians. Generative Model Decision
Engineering Part IIB: Module F Statistical Pattern Processing University of Cambridge Engineering Part IIB Module F: Statistical Pattern Processing Handout : Multivariate Gaussians. Generative Model Decision
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Gaussian Models
 Gaussian Models ddebarr@uw.edu 2016-04-28 Agenda Introduction Gaussian Discriminant Analysis Inference Linear Gaussian Systems The Wishart Distribution Inferring Parameters Introduction Gaussian Density
Gaussian Models ddebarr@uw.edu 2016-04-28 Agenda Introduction Gaussian Discriminant Analysis Inference Linear Gaussian Systems The Wishart Distribution Inferring Parameters Introduction Gaussian Density
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation)
") Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Computer Vision Group Prof. Daniel Cremers. 6. Mixture Models and Expectation-Maximization
 Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
Chemometrics: Classification of spectra
 Chemometrics: Classification of spectra Vladimir Bochko Jarmo Alander University of Vaasa November 1, 2010 Vladimir Bochko Chemometrics: Classification 1/36 Contents Terminology Introduction Big picture
Chemometrics: Classification of spectra Vladimir Bochko Jarmo Alander University of Vaasa November 1, 2010 Vladimir Bochko Chemometrics: Classification 1/36 Contents Terminology Introduction Big picture
Overview of Statistical Tools. Statistical Inference. Bayesian Framework. Modeling. Very simple case. Things are usually more complicated
 Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers
 Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Motivating the Covariance Matrix
 Motivating the Covariance Matrix Raúl Rojas Computer Science Department Freie Universität Berlin January 2009 Abstract This note reviews some interesting properties of the covariance matrix and its role
Motivating the Covariance Matrix Raúl Rojas Computer Science Department Freie Universität Berlin January 2009 Abstract This note reviews some interesting properties of the covariance matrix and its role
Machine Learning (Spring 2012) Principal Component Analysis
 Principal Component Analysis") 1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Machine Learning (CS 567) Lecture 5
 Lecture 5") Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Dimensionality Reduction and Principal Components
 Dimensionality Reduction and Principal Components Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,..., M} and observations of X
Dimensionality Reduction and Principal Components Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,..., M} and observations of X
ECE662: Pattern Recognition and Decision Making Processes: HW TWO
 ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
MACHINE LEARNING ADVANCED MACHINE LEARNING
 MACHINE LEARNING ADVANCED MACHINE LEARNING Recap of Important Notions on Estimation of Probability Density Functions 2 2 MACHINE LEARNING Overview Definition pdf Definition joint, condition, marginal,
MACHINE LEARNING ADVANCED MACHINE LEARNING Recap of Important Notions on Estimation of Probability Density Functions 2 2 MACHINE LEARNING Overview Definition pdf Definition joint, condition, marginal,
CSC411: Final Review. James Lucas & David Madras. December 3, 2018
 CSC411: Final Review James Lucas & David Madras December 3, 2018 Agenda 1. A brief overview 2. Some sample questions Basic ML Terminology The final exam will be on the entire course; however, it will be
CSC411: Final Review James Lucas & David Madras December 3, 2018 Agenda 1. A brief overview 2. Some sample questions Basic ML Terminology The final exam will be on the entire course; however, it will be
Discriminant analysis and supervised classification
 Discriminant analysis and supervised classification Angela Montanari 1 Linear discriminant analysis Linear discriminant analysis (LDA) also known as Fisher s linear discriminant analysis or as Canonical
Discriminant analysis and supervised classification Angela Montanari 1 Linear discriminant analysis Linear discriminant analysis (LDA) also known as Fisher s linear discriminant analysis or as Canonical
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar