Reminders. Thought questions should be submitted on eclass. Please list the section related to the thought question
|
|
|
- Ginger Kennedy
- 5 years ago
- Views:
Transcription

1 Linear regression
2 Reminders Thought questions should be submitted on eclass Please list the section related to the thought question If it is a more general, open-ended question not exactly related to a section, label the question with a topic (e.g., Picking models) 2
3 Properties of distributions Mean is the expected value (E[X]) Mode is the most likely value (i.e., x with largest p(x)) Median m is the value such that X is equally likely to fall above or below m: P( X m ) = P( X m ) When we use a squared-error cost, obtain f(x) = E[Y x] If we use an absolute-error cost, obtain f(x) = median ( p (y x) ) 3
4 Summary of optimal models Expected cost introduced to formalize our objective 8 Bayes risk function indicates best we could do >< f(x) specified for each x, rather than having some simpler (continuous) function class >: can think of it as a table of values { ptimal solut For classification (with uniform cost) = arg max f (x) {z } y2y {p(y x)}. 4 ptimal solution ˆ f (x) = For regression (with squared-error cost) Y yp(y x)dy
5 Learning functions Hypothesize a functional form, e.g. f(x) = dx w j x j j=1 f(x 1,x 2 )=w 0 + w 1 x 1 + w 2 x 2 f(x 1,x 2 )=wx 1 x 2 Then need to find the best parameters for this function; we will find the parameters that best approximate E[y x]... 5
6 Exercise: Reducible error Can f(x) = dx w j x j always represent E[Y x]? j=1 No. Imagine y =wx 1 x 2 This is deterministic, so there is enough information in x to predict y i.e., the stochasticity is not the problem, have zero irreducible error Rather simplistic functional form means we cannot predict y 6
7 Linear versus polynomial function 5 f 3 (x) 4 3 f 1 (x) x 7
8 Linear Regression e.g., x_i = size of house y_i = cost of house y ( x, y ) 2 2 fx ( ) f(x) =w 0 + w 1 x ( x, y ) 1 1 e1 = f( x1) { y1 x Figure 4.1: An example of a linear regression fitting on data set D = {(1, 1.2), (2, 2.3), (3, 2.3), (4, 3.3)}. The task of the optimization process is to find the best linear function f(x) =w 0 + w 1 x so that the sum of squared errors e e2 2 + e2 3 + e2 4 is minimized. 8

9 (Multiple) Linear Regression e.g., x_{i1} = size of house x_{i2} = age of house y_i = cost of house 9
10 Linear regression importance Many other techniques will use linear weighting of features including neural networks Often, we will add non-linearity using non-linear transformations of linear weighting non-linear transformations of features Becoming comfortable will linear weightings, for multiple inputs and outputs, is important 10
11 Example: regression that it projects to the column space of. Example 11: Consider again data set D = {(1, 1.2), (2, 2.3), (3, 2.3), (4, 3.3)} from Figure 4.1. Wewanttofindtheoptimalcoefficients of the least-squares X = , w = apple w0 w 1, y = , j k f j d 2 T x i i x ij d y i = n ŷ i = x > i w n 11 X = wy
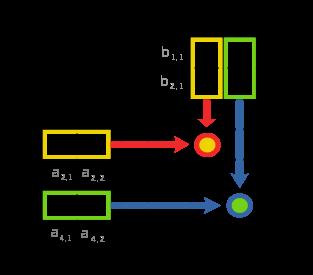
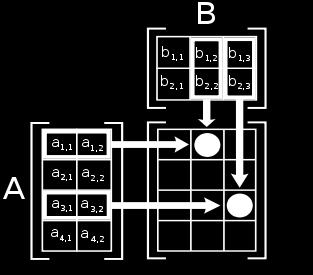
12 12 Matrix multiplication
13 Whiteboard Maximum likelihood formulation (and assumptions) Solving the optimization Weighted error functions, if certain data points matter more than others Predicting multiple outputs (multivariate y) 13
 Assignment 1 due")

14 Comments (Sep 26, 2017) Assignment 1 due on Thursday More review of linear algebra today 14
15 M = U V > SVD Mx = U V > x = U (V > x) 15
16 What we ve done so far Discussed linear regression goal: obtain weights w such that < x, w> approximates E[Y x] Discussed maximum likelihood formulation Solution: w =(X > X) 1 X > y ŷ = Xw > Starting discussing the properties of the solution When is it stable? Today: What does this mean for accuracy in predicting on new data? 16
17 Example: OLS that it projects to the column space of. Example 11: Consider again data set D = {(1, 1.2), (2, 2.3), (3, 2.3), (4, 3.3)} from Figure 4.1. Wewanttofindtheoptimalcoefficients of the least-squares X = In Matlab, can compute 1. X > X 2. (X > X) , w = apple w0 w 1, y = X > X = , apple (X > X) 1 X > y 17 What if we did not add the column of 1s?
18 Whiteboard More about inverses of matrices Refresh about stability of the solution Using regularization to fix the problem Properties of solution: Bias (and underfitting) Variance (and overfitting) 18
19 Overfitting 5 f 3 (x) 4 3 f 1 (x) x Figure 4.4: Example of a linear vs. polynomial fit on a data set shown in Figure 4.1. The linear fit, f 1 (x), isshownasasolidgreenline,whereasthe cubic polynomial fit, f 3 (x), isshownasasolidblueline.thedottedredline indicates the target linear concept. w 1 =(0.7, 0.63) w 3 =( 3.1, 6.6, 2.65, 0.35) 19
20 Comments (Sep 28, 2017) Assignment 1 due today Need matplotlib for simulate.py Today: finish-off bias-variance 20
21 Terminology clarification What is a parameter? Any coefficients (i.e., scalars, vectors or matrices) that define the function you care about e.g., a and b are both parameters for function f f(x) = a if x<0 b if x 0 Maximum likelihood solution: parameters for the pmf or pdf that make the data the most likely The following function is not the maximum likelihood solution f(x) = arg max y2y p(y x) 21
22 Linear regression for non-linear problems e.g. f(x) =w 0 + w 1 x, f(x) = px w j x j, j=0 e.g. f(x 1,x 2 )=w 0 + w 1 x 1 + w 2 x 2 + w 3 x 1 x 2 + w 4 x w 5 x 2 2 X 1 x 1 0 (x 1 )... p(x 1 ) x 2! n x n 0 (x n )... p(x n ) Figure 4.3: Transformation of an n 1 data matrix X into an n (p + 1) matrix using a set of basis functions j, j =0, 1,...,p. 22 w = > 1 > y.

23 Polynomial representations w 0 + w 1 x 1 + w 2 x w 9 x 9 23
24 Whiteboard Bias and variance of linear regression solutions 24

25 Bias-variance trade-off Low Variance High Variance Low Bias High Bias 25 *Nice images from:
26 Example: regularization and bias Picked a Gaussian prior and obtained l2 regularization We discussed the bias of this regularization no regularization was unbiased E[w] = true w with regularization meant E[w] was not equal to the true w Previously, however, mentioned that MAP and ML converge to the same estimate Does that happen here? w =(X > X + I) 1 X > y 26
27 How do we pick lambda? Discussed goal to minimize bias-variance trade-off i.e., minimizing MSE But, this involves knowing the true w! Recall our actual goal: learn w to get good prediction accuracy on new data Called generalization error Alternative to directly minimize MSE: use data to determine which choice of lambda provides good prediction accuracy 27
28 How can we tell if its a good model? What if you train many different models on a batch of data, check their accuracy on that data, and pick the best one? Imagine your are predicting how much energy your appliances will use today You train your models on all previous data for energy use in your home How well will this perform in the real world? What if the models you are testing are only different in terms of the regularization parameter lambda that they use? What will you find? 28

29 Simulating generalization error labeled data set training set test set learning method learned model accuracy estimate 29
30 Simulating generalization error Now we have one model, trained similarly to how it will be trained, and a measure of accuracy on new data (but distributed identically to trained data) What if we pick the model with the best test accuracy? Any issues? 30
31 Picking other priors Picked Gaussian prior on weights Encodes that we want the weights to stay near zero, varying with at most 1/lambda What if we had picked a different prior? e.g., the Laplace prior? 1 2b exp( x µ /b) 31

32 Regularization intuition Figure 4.5: A comparison between Gaussian and Laplace priors. The Gaussian prior prefers the values to be near zero, whereas the Laplace prior more strongly prefers the values to equal zero. 32

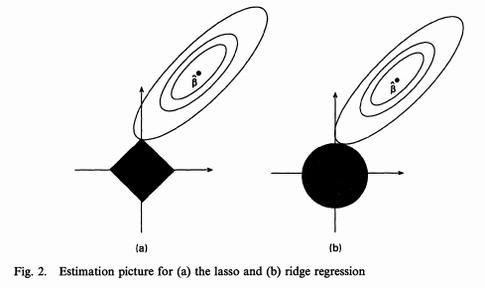

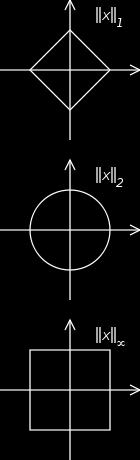
33 33 Regularization intuition
34 l1 regularization Feature selection, as well as preventing large weight t k = = = k = How do we solve this optimization? min w2r d kxw yk kwk 1 34
35 How do we solve with l1 regularizer? min w2r d kxw yk kwk 1 Is there a closed form solution? What approaches can we take? 35
36 Practically solving optimization In general, what are the advantages and disadvantages of the closed form linear regression solution? + Simple approach: no need to add additional requirements, like stopping rules - Is not usually possible - Must compute an expensive inverse - With a large number of features, inverting large matrix? What about a large number of samples? 36
Why should you care about the solution strategies?
 Optimization Why should you care about the solution strategies? Understanding the optimization approaches behind the algorithms makes you more effectively choose which algorithm to run Understanding the
Optimization Why should you care about the solution strategies? Understanding the optimization approaches behind the algorithms makes you more effectively choose which algorithm to run Understanding the
Probability and Statistical Decision Theory
 Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2019s/ Probability and Statistical Decision Theory Many slides attributable to: Erik Sudderth (UCI) Prof. Mike Hughes
Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2019s/ Probability and Statistical Decision Theory Many slides attributable to: Erik Sudderth (UCI) Prof. Mike Hughes
Comments. x > w = w > x. Clarification: this course is about getting you to be able to think as a machine learning expert
 Logistic regression Comments Mini-review and feedback These are equivalent: x > w = w > x Clarification: this course is about getting you to be able to think as a machine learning expert There has to be
Logistic regression Comments Mini-review and feedback These are equivalent: x > w = w > x Clarification: this course is about getting you to be able to think as a machine learning expert There has to be
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Lecture 2: Linear regression
 Lecture 2: Linear regression Roger Grosse 1 Introduction Let s ump right in and look at our first machine learning algorithm, linear regression. In regression, we are interested in predicting a scalar-valued
Lecture 2: Linear regression Roger Grosse 1 Introduction Let s ump right in and look at our first machine learning algorithm, linear regression. In regression, we are interested in predicting a scalar-valued
Parameter estimation Conditional risk
 Parameter estimation Conditional risk Formalizing the problem Specify random variables we care about e.g., Commute Time e.g., Heights of buildings in a city We might then pick a particular distribution
Parameter estimation Conditional risk Formalizing the problem Specify random variables we care about e.g., Commute Time e.g., Heights of buildings in a city We might then pick a particular distribution
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Mathematical Formulation of Our Example
 Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
CS 195-5: Machine Learning Problem Set 1
 CS 95-5: Machine Learning Problem Set Douglas Lanman dlanman@brown.edu 7 September Regression Problem Show that the prediction errors y f(x; ŵ) are necessarily uncorrelated with any linear function of
CS 95-5: Machine Learning Problem Set Douglas Lanman dlanman@brown.edu 7 September Regression Problem Show that the prediction errors y f(x; ŵ) are necessarily uncorrelated with any linear function of
Linear Regression and Its Applications
 Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Lecture 2 Machine Learning Review
 Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Lecture 4: Types of errors. Bayesian regression models. Logistic regression
 Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Lecture 13: Data Modelling and Distributions. Intelligent Data Analysis and Probabilistic Inference Lecture 13 Slide No 1
 Lecture 13: Data Modelling and Distributions Intelligent Data Analysis and Probabilistic Inference Lecture 13 Slide No 1 Why data distributions? It is a well established fact that many naturally occurring
Lecture 13: Data Modelling and Distributions Intelligent Data Analysis and Probabilistic Inference Lecture 13 Slide No 1 Why data distributions? It is a well established fact that many naturally occurring
PROBABILITY THEORY REVIEW
 PROBABILITY THEORY REVIEW CMPUT 466/551 Martha White Fall, 2017 REMINDERS Assignment 1 is due on September 28 Thought questions 1 are due on September 21 Chapters 1-4, about 40 pages If you are printing,
PROBABILITY THEORY REVIEW CMPUT 466/551 Martha White Fall, 2017 REMINDERS Assignment 1 is due on September 28 Thought questions 1 are due on September 21 Chapters 1-4, about 40 pages If you are printing,
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Machine Learning Lecture Notes
 Machine Learning Lecture Notes Predrag Radivojac February 2, 205 Given a data set D = {(x i,y i )} n the objective is to learn the relationship between features and the target. We usually start by hypothesizing
Machine Learning Lecture Notes Predrag Radivojac February 2, 205 Given a data set D = {(x i,y i )} n the objective is to learn the relationship between features and the target. We usually start by hypothesizing
Introduction to the regression problem. Luca Martino
 Introduction to the regression problem Luca Martino 2017 2018 1 / 30 Approximated outline of the course 1. Very basic introduction to regression 2. Gaussian Processes (GPs) and Relevant Vector Machines
Introduction to the regression problem Luca Martino 2017 2018 1 / 30 Approximated outline of the course 1. Very basic introduction to regression 2. Gaussian Processes (GPs) and Relevant Vector Machines
Lecture 3: Introduction to Complexity Regularization
 ECE90 Spring 2007 Statistical Learning Theory Instructor: R. Nowak Lecture 3: Introduction to Complexity Regularization We ended the previous lecture with a brief discussion of overfitting. Recall that,
ECE90 Spring 2007 Statistical Learning Theory Instructor: R. Nowak Lecture 3: Introduction to Complexity Regularization We ended the previous lecture with a brief discussion of overfitting. Recall that,
Week 5: Logistic Regression & Neural Networks
 Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d)
") COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d) Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless
COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d) Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless
Introduction to Machine Learning
 Introduction to Machine Learning Linear Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Introduction to Machine Learning Linear Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
CSC321 Lecture 2: Linear Regression
 CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
Gaussian Process Regression
 Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
6.867 Machine Learning
 6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
Machine learning - HT Maximum Likelihood
 Machine learning - HT 2016 3. Maximum Likelihood Varun Kanade University of Oxford January 27, 2016 Outline Probabilistic Framework Formulate linear regression in the language of probability Introduce
Machine learning - HT 2016 3. Maximum Likelihood Varun Kanade University of Oxford January 27, 2016 Outline Probabilistic Framework Formulate linear regression in the language of probability Introduce
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
41903: Introduction to Nonparametrics
 41903: Notes 5 Introduction Nonparametrics fundamentally about fitting flexible models: want model that is flexible enough to accommodate important patterns but not so flexible it overspecializes to specific
41903: Notes 5 Introduction Nonparametrics fundamentally about fitting flexible models: want model that is flexible enough to accommodate important patterns but not so flexible it overspecializes to specific
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
12 Statistical Justifications; the Bias-Variance Decomposition
 Statistical Justifications; the Bias-Variance Decomposition 65 12 Statistical Justifications; the Bias-Variance Decomposition STATISTICAL JUSTIFICATIONS FOR REGRESSION [So far, I ve talked about regression
Statistical Justifications; the Bias-Variance Decomposition 65 12 Statistical Justifications; the Bias-Variance Decomposition STATISTICAL JUSTIFICATIONS FOR REGRESSION [So far, I ve talked about regression
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Linear Regression. CSL603 - Fall 2017 Narayanan C Krishnan
 Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Overview. Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation
 Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Linear Regression. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
cxx ab.ec Warm up OH 2 ax 16 0 axtb Fix any a, b, c > What is the x 2 R that minimizes ax 2 + bx + c
 Warm up D cai.yo.ie p IExrL9CxsYD Sglx.Ddl f E Luo fhlexi.si dbll Fix any a, b, c > 0. 1. What is the x 2 R that minimizes ax 2 + bx + c x a b Ta OH 2 ax 16 0 x 1 Za fhkxiiso3ii draulx.h dp.d 2. What is
Warm up D cai.yo.ie p IExrL9CxsYD Sglx.Ddl f E Luo fhlexi.si dbll Fix any a, b, c > 0. 1. What is the x 2 R that minimizes ax 2 + bx + c x a b Ta OH 2 ax 16 0 x 1 Za fhkxiiso3ii draulx.h dp.d 2. What is
Bayesian Linear Regression [DRAFT - In Progress]
![Bayesian Linear Regression [DRAFT - In Progress]](/thumbs/92/109828713.jpg "Bayesian Linear Regression [DRAFT - In Progress]") Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
11. Learning graphical models
 Learning graphical models 11-1 11. Learning graphical models Maximum likelihood Parameter learning Structural learning Learning partially observed graphical models Learning graphical models 11-2 statistical
Learning graphical models 11-1 11. Learning graphical models Maximum likelihood Parameter learning Structural learning Learning partially observed graphical models Learning graphical models 11-2 statistical
Machine Learning - MT & 5. Basis Expansion, Regularization, Validation
 Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Machine Learning CSE546 Sham Kakade University of Washington. Oct 4, What about continuous variables?
 Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Linear Models for Regression
 Linear Models for Regression CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 The Regression Problem Training data: A set of input-output
Linear Models for Regression CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 The Regression Problem Training data: A set of input-output
CSC 411: Lecture 09: Naive Bayes
 CSC 411: Lecture 09: Naive Bayes Class based on Raquel Urtasun & Rich Zemel s lectures Sanja Fidler University of Toronto Feb 8, 2015 Urtasun, Zemel, Fidler (UofT) CSC 411: 09-Naive Bayes Feb 8, 2015 1
CSC 411: Lecture 09: Naive Bayes Class based on Raquel Urtasun & Rich Zemel s lectures Sanja Fidler University of Toronto Feb 8, 2015 Urtasun, Zemel, Fidler (UofT) CSC 411: 09-Naive Bayes Feb 8, 2015 1
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, What about continuous variables?
 Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 89 Part II
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 89 Part II
Logistic Regression. Some slides adapted from Dan Jurfasky and Brendan O Connor
 Logistic Regression Some slides adapted from Dan Jurfasky and Brendan O Connor Naïve Bayes Recap Bag of words (order independent) Features are assumed independent given class P (x 1,...,x n c) =P (x 1
Logistic Regression Some slides adapted from Dan Jurfasky and Brendan O Connor Naïve Bayes Recap Bag of words (order independent) Features are assumed independent given class P (x 1,...,x n c) =P (x 1
Machine Learning! in just a few minutes. Jan Peters Gerhard Neumann
 Machine Learning! in just a few minutes Jan Peters Gerhard Neumann 1 Purpose of this Lecture Foundations of machine learning tools for robotics We focus on regression methods and general principles Often
Machine Learning! in just a few minutes Jan Peters Gerhard Neumann 1 Purpose of this Lecture Foundations of machine learning tools for robotics We focus on regression methods and general principles Often
Recap from previous lecture
 Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Computer Vision Group Prof. Daniel Cremers. 3. Regression
 Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Notes on Discriminant Functions and Optimal Classification
 Notes on Discriminant Functions and Optimal Classification Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Discriminant Functions Consider a classification problem
Notes on Discriminant Functions and Optimal Classification Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Discriminant Functions Consider a classification problem
Machine Learning and Data Mining. Linear regression. Kalev Kask
 Machine Learning and Data Mining Linear regression Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ Parameters q Learning algorithm Program ( Learner ) Change q Improve performance
Machine Learning and Data Mining Linear regression Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ Parameters q Learning algorithm Program ( Learner ) Change q Improve performance
Machine Learning for Large-Scale Data Analysis and Decision Making A. Week #1
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Week #1 Today Introduction to machine learning The course (syllabus) Math review (probability + linear algebra) The future
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Week #1 Today Introduction to machine learning The course (syllabus) Math review (probability + linear algebra) The future
The Kernel Trick, Gram Matrices, and Feature Extraction. CS6787 Lecture 4 Fall 2017
 The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, 2013
 Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review
CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review
Gaussian processes and bayesian optimization Stanisław Jastrzębski. kudkudak.github.io kudkudak
 Gaussian processes and bayesian optimization Stanisław Jastrzębski kudkudak.github.io kudkudak Plan Goal: talk about modern hyperparameter optimization algorithms Bayes reminder: equivalent linear regression
Gaussian processes and bayesian optimization Stanisław Jastrzębski kudkudak.github.io kudkudak Plan Goal: talk about modern hyperparameter optimization algorithms Bayes reminder: equivalent linear regression
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Probability and Information Theory. Sargur N. Srihari
 Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers
 Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
Lecture 4 Discriminant Analysis, k-nearest Neighbors
 Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
Summer School in Statistics for Astronomers V June 1 - June 6, Regression. Mosuk Chow Statistics Department Penn State University.
 Summer School in Statistics for Astronomers V June 1 - June 6, 2009 Regression Mosuk Chow Statistics Department Penn State University. Adapted from notes prepared by RL Karandikar Mean and variance Recall
Summer School in Statistics for Astronomers V June 1 - June 6, 2009 Regression Mosuk Chow Statistics Department Penn State University. Adapted from notes prepared by RL Karandikar Mean and variance Recall
Midterm. Introduction to Machine Learning. CS 189 Spring Please do not open the exam before you are instructed to do so.
 CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
BAYESIAN DECISION THEORY
 Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Association studies and regression
 Association studies and regression CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar Association studies and regression 1 / 104 Administration
Association studies and regression CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar Association studies and regression 1 / 104 Administration
Machine Learning Basics: Maximum Likelihood Estimation
 Machine Learning Basics: Maximum Likelihood Estimation Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics 1. Learning
Machine Learning Basics: Maximum Likelihood Estimation Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics 1. Learning
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Basics: Estimators, Bias and Variance
 Machine Learning Basics: Estiators, Bias and Variance Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Basics
Machine Learning Basics: Estiators, Bias and Variance Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Basics
Machine Learning. Regression-Based Classification & Gaussian Discriminant Analysis. Manfred Huber
 Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Least Squares Regression
 E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
Regression I: Mean Squared Error and Measuring Quality of Fit
 Regression I: Mean Squared Error and Measuring Quality of Fit -Applied Multivariate Analysis- Lecturer: Darren Homrighausen, PhD 1 The Setup Suppose there is a scientific problem we are interested in solving
Regression I: Mean Squared Error and Measuring Quality of Fit -Applied Multivariate Analysis- Lecturer: Darren Homrighausen, PhD 1 The Setup Suppose there is a scientific problem we are interested in solving
CMSC858P Supervised Learning Methods
 CMSC858P Supervised Learning Methods Hector Corrada Bravo March, 2010 Introduction Today we discuss the classification setting in detail. Our setting is that we observe for each subject i a set of p predictors
CMSC858P Supervised Learning Methods Hector Corrada Bravo March, 2010 Introduction Today we discuss the classification setting in detail. Our setting is that we observe for each subject i a set of p predictors
First Year Examination Department of Statistics, University of Florida
 First Year Examination Department of Statistics, University of Florida August 19, 010, 8:00 am - 1:00 noon Instructions: 1. You have four hours to answer questions in this examination.. You must show your
First Year Examination Department of Statistics, University of Florida August 19, 010, 8:00 am - 1:00 noon Instructions: 1. You have four hours to answer questions in this examination.. You must show your
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Linear Models for Regression CS534
 Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
CSE546 Machine Learning, Autumn 2016: Homework 1
 CSE546 Machine Learning, Autumn 2016: Homework 1 Due: Friday, October 14 th, 5pm 0 Policies Writing: Please submit your HW as a typed pdf document (not handwritten). It is encouraged you latex all your
CSE546 Machine Learning, Autumn 2016: Homework 1 Due: Friday, October 14 th, 5pm 0 Policies Writing: Please submit your HW as a typed pdf document (not handwritten). It is encouraged you latex all your
Least Squares Regression
 CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
Data Analysis and Machine Learning Lecture 12: Multicollinearity, Bias-Variance Trade-off, Cross-validation and Shrinkage Methods.
 TheThalesians Itiseasyforphilosopherstoberichiftheychoose Data Analysis and Machine Learning Lecture 12: Multicollinearity, Bias-Variance Trade-off, Cross-validation and Shrinkage Methods Ivan Zhdankin
TheThalesians Itiseasyforphilosopherstoberichiftheychoose Data Analysis and Machine Learning Lecture 12: Multicollinearity, Bias-Variance Trade-off, Cross-validation and Shrinkage Methods Ivan Zhdankin
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 254 Part V
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 254 Part V
CSC2515 Winter 2015 Introduction to Machine Learning. Lecture 2: Linear regression
 CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
Classification. Chapter Introduction. 6.2 The Bayes classifier
 Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
10-701/ Machine Learning, Fall
 0-70/5-78 Machine Learning, Fall 2003 Homework 2 Solution If you have questions, please contact Jiayong Zhang .. (Error Function) The sum-of-squares error is the most common training
0-70/5-78 Machine Learning, Fall 2003 Homework 2 Solution If you have questions, please contact Jiayong Zhang .. (Error Function) The sum-of-squares error is the most common training
COMP 551 Applied Machine Learning Lecture 20: Gaussian processes
 COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
Lecture 3. STAT161/261 Introduction to Pattern Recognition and Machine Learning Spring 2018 Prof. Allie Fletcher
 Lecture 3 STAT161/261 Introduction to Pattern Recognition and Machine Learning Spring 2018 Prof. Allie Fletcher Previous lectures What is machine learning? Objectives of machine learning Supervised and
Lecture 3 STAT161/261 Introduction to Pattern Recognition and Machine Learning Spring 2018 Prof. Allie Fletcher Previous lectures What is machine learning? Objectives of machine learning Supervised and
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak
 Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
ECE 541 Stochastic Signals and Systems Problem Set 9 Solutions
 ECE 541 Stochastic Signals and Systems Problem Set 9 Solutions Problem Solutions : Yates and Goodman, 9.5.3 9.1.4 9.2.2 9.2.6 9.3.2 9.4.2 9.4.6 9.4.7 and Problem 9.1.4 Solution The joint PDF of X and Y
ECE 541 Stochastic Signals and Systems Problem Set 9 Solutions Problem Solutions : Yates and Goodman, 9.5.3 9.1.4 9.2.2 9.2.6 9.3.2 9.4.2 9.4.6 9.4.7 and Problem 9.1.4 Solution The joint PDF of X and Y
Terminology. Experiment = Prior = Posterior =
 Review: probability RVs, events, sample space! Measures, distributions disjoint union property (law of total probability book calls this sum rule ) Sample v. population Law of large numbers Marginals,
Review: probability RVs, events, sample space! Measures, distributions disjoint union property (law of total probability book calls this sum rule ) Sample v. population Law of large numbers Marginals,
Tutorial on Machine Learning for Advanced Electronics
 Tutorial on Machine Learning for Advanced Electronics Maxim Raginsky March 2017 Part I (Some) Theory and Principles Machine Learning: estimation of dependencies from empirical data (V. Vapnik) enabling
Tutorial on Machine Learning for Advanced Electronics Maxim Raginsky March 2017 Part I (Some) Theory and Principles Machine Learning: estimation of dependencies from empirical data (V. Vapnik) enabling
Introduction to Bayesian Statistics
 School of Computing & Communication, UTS January, 207 Random variables Pre-university: A number is just a fixed value. When we talk about probabilities: When X is a continuous random variable, it has a
School of Computing & Communication, UTS January, 207 Random variables Pre-university: A number is just a fixed value. When we talk about probabilities: When X is a continuous random variable, it has a
Is the test error unbiased for these programs?
 Is the test error unbiased for these programs? Xtrain avg N o Preprocessing by de meaning using whole TEST set 2017 Kevin Jamieson 1 Is the test error unbiased for this program? e Stott see non for f x
Is the test error unbiased for these programs? Xtrain avg N o Preprocessing by de meaning using whole TEST set 2017 Kevin Jamieson 1 Is the test error unbiased for this program? e Stott see non for f x
6.867 Machine Learning
 6.867 Machine Learning Problem set 1 Due Thursday, September 19, in class What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
6.867 Machine Learning Problem set 1 Due Thursday, September 19, in class What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
Gaussian processes. Chuong B. Do (updated by Honglak Lee) November 22, 2008
 November 22, 2008") Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Machine Learning, Fall 2009: Midterm
 10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all