Machine Learning Linear Classification. Prof. Matteo Matteucci
|
|
|
- Kelly Gabriella Lynch
- 6 years ago
- Views:
Transcription

1 Machine Learning Linear Classification Prof. Matteo Matteucci
 Clustering")
2 Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X) Clustering Partitions

3 Example: Default dataset 3 Overall Default Rate 3%
4 Linear regression for classification? 4 o Suppose to predict the medical condition of a patient. How should this be encoded? We could use dummy variables in case of binary output but how to deal with multiple output? Different encodings could result in different models
5 Recall here the Bayesian Classifier 5 o For a classification problem we can use the error rate i.e. I Error y i yˆ ( i Rate ) n i 1 I( yi yˆ i ) / Where is an indicator function, which will give 1 if the condition y yˆ ) is correct, otherwise it gives a 0. ( i i The error rate represents the fraction of incorrect classifications, or misclassifications o The Bayes Classifier minimizes the Average Test Error Rate max j P( Y j X x0) o The Bayes error rate refers to the lowest possible Error Rate achievable knowing the true distribution of the data n The best classifier possible estimates the class posterior probability!!
6 Logistic Regression 6 o We want to model the probability of the class given the input but a linear model has some drawbacks
7 Example: Default data & Linear Regression 7 Overall Default Rate 3% Negative probability?
8 Logistic Regression 8 o We want to model the probability of the class given the input but a linear model has some drawbacks o Logistic regression solves the negative probability (ad other issues as well) by regressing the logistic function
9 Example: Default data & Logistic Regression 9
10 Logistic Regression 10 o We want to model the probability of the class given the input but a linear model has some drawbacks (see later slide) Linear Regression o Logistic regression solves the negative probability (ad other issues as well) by regressing the logistic function Logistic Regression from this we derive This is called odds and taking logarithms This is called log-odds or logit
11 Coefficient interpretation 11 o Interpreting what 1 means is not very easy with logistic regression, simply because we are predicting P(Y) and not Y. If 1 =0, this means that there is no relationship between Y and X If 1 >0, this means that when X gets larger so does the probability that Y = 1 If 1 <0, this means that when X gets larger, the probability that Y = 1 gets smaller. o But how much bigger or smaller depends on where we are on the slope, i.e., it is not linear
12 Training Logistic Regression (1/4) 12 o For the basic logistic regression wee need two parameters o In principle we could use (non linear) Least Squares fitting on the observed data the corresponding model o But a more principled approach for training in classification problems is based on Maximum Likelihood We want to find the parameters which maximize the likelihood function
13 Maximum Likelihood flash-back (1/6) 13 o Suppose we observe some i.i.d. samples coming from a Gaussian distribution with known variance: Which distribution do you prefer?

14 Maximum Likelihood flash-back (2/6) 14 o There is a simple recipe for Maximum Likelihood estimation o Let s try to apply it to our example
15 Maximum Likelihood flash-back (3/6) 15 o Let s try to apply it to our example 1. Write le likelihood for the data
16 Maximum Likelihood flash-back (4/6) 16 o Let s try to apply it to our example 2. (Take the logarithm of the likelihood -> log-likelihood)
17 Maximum Likelihood flash-back (5/6) 17 o Let s try to apply it to our example 3. Work out the derivatives using high-school calculus
18 Maximum Likelihood flash-back (6/6) 18 o Let s try to apply it to our example 4. Solve the unconstrained equations
19 Training Logistic Regression (1/4) 19 o For the basic logistic regression we need two parameters o In principle we could use (non linear) Least Squares fitting on the observed data the corresponding model o But a more principled approach for training in classification problems is based on Maximum Likelihood We want to find the parameters which maximize the likelihood function
20 Training Logistic Regression (2/4) 20 o Let s find the parameters which maximize the likelihood function o If we compute the log-likelihood for N observations Taken from ESL where o We obtain a log-likelihood in the form of Can you derive it?
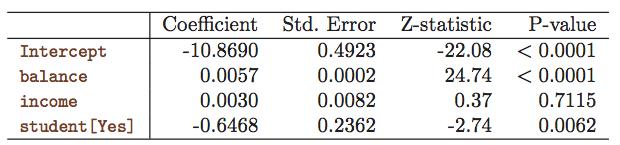
21 Training Logistic Regression (3/4) 21 o Let s find the parameters which maximize the likelihood function Z-statistics has the same role of the regression t-statistics, a large value means the parameter is not null Intercept does not have a particular meaning is used to adjust the probability to class proportions
22 Example: Default data & Logistic Regression 22
")
23 Training Logistic Regression (4/4) 23 o Let s find the parameters which maximize the likelihood function We can train the model using qualitative variables through the use of binary (dummy) variables
24 Making predictions with Logistic Regression 24 o Once we have the model parameters we can predict the class o The Default probability having 1000$ balance is <1% while with a balance of 2000$ this becomes 58.6% o With qualitative variables, i.e., dummy variables, we get that being a students results in

25 Multiple Logistic Regression 25 o So far we have considered only one predictor, but we can extend the approach to multiple regressors o By maximum likelihood we learn the corresponding parameters What about this?

26 An apparent contradiction 26 Positive Negative!!!
27 Example: Confounding in Default data set 27

28 Example: South African Heart Disease 28 Taken from ESL
29 Logistic Regression for Feature Selection 29 o If we fit the complete model on these data we get Taken from ESL o While if we use stepwise Logistic Regression Taken from ESL
30 Logistic Regression parameters meaning 30 o Regression parameters represent the increment on the logit of probability given by a unitary increment of a variable o Let consider the increase of tobacco consumption in life od 1Kg, this count for an increase in log-odds of exp(0.081)=1.084 which means an overall increase of 8.4% o With a 95% confidence interval Taken from ESL
31 Regularized Logistic Regression 31 o As for Linear Regression we can compute a Lasso version
32 Regularized Logistic Regression 32 o As for Linear Regression we can compute a Lasso version Taken from ESL
33 Multiclass Logistic Regression 33 o Logistic Regression extends naturally to multiclass problems by computing the log-odds w.r.t. the K th class Comes from ESL, but it s worth knowing!!! Notation different because it comes from ESL o This is equivalent to o Can you prove it?!?!?
34 Wrap-up on Logistic Regression 34 o We model the log-odds as a linear regression model o This means the posterior probability becomes o Parameters represent log-odds increase per variable unit increment keeping fixed the others o We can use it to perform feature selection using z-scores and forward stepwise selection o The class decision boundary is linear, but points close to the boundary count more this will be discussed later
35 Beyond Logistic Regression 35 o Logistic Regression models directly class posterior probability o Linear Discriminant Analysis uses the Bayes Theorem o What improvements come with this model? Parameter learning unstable in Logistic Regression for well separated classes With little data and normal predictor distribution LDA is more stable A very popular algorithm with more than 2 response classes
36 Linear Discriminant Analysis (1/3) 36 o Suppose we want to discriminate among K>2 classes o Each class has a prior probability o Given the class we model the density function of predictors as o Using the Bayes Theorem we obtain Prior probability is relatively simple to learn Likelihood might be more tricky and we need some assumptions to simplify it o If we correctly estimate the likelihood we obtain the Bayes Classifier, i.e., the one with the smallest error rate!
37 Linear Discriminant Analysis (2/3) 37 o Let assume p=1 and use a Gaussian distribution o Let assume all classes have the same covariance o The posteriors probability as computed by LDA becomes o The selected class is the one with the highest posterior which is equivalent to the highest discriminating function Can you derive this? Linear discriminant function in x
38 Linear Discriminant Analysis (3/3) 38 o With 2 classes having the same prior probability we decide the class according to the inequality o The Bayes decision boundary corresponds to o Training is as simple as estimating the model parameters
39 LDA Simple Example (with p=1) 39
 40 o In case p>1 we assume comes")
40 Linear Discriminant Analysis with p>1 (1/3) 40 o In case p>1 we assume comes from
41 Linear Discriminant Analysis with p>1 (2/3) 41 o In the case of p>1 the LDA classifier assumes Observations from the k-th class are drawn from The covariance structure is common to all classes o The Bayes discriminating function becomes Can you derive this? Still linear in x!!! o From this we can compute the boundary between each class (considering the two classes having the same prior probability) o Training formulas for the LDA parameters are similar to the case of p=1

42 Linear Discriminant Analysis Example 42
43 Example: LDA on the Default Dataset 43 o LDA on the Default dataset gets 2.75% training error rate Having records and p=3 we do not expect much overfitting by the way how many parameters we have? Being 3.33% the number of defaulters a dummy classifier would get a similar error rate
44 On the performance of LDA 44 o Errors in classification are often reported as a Confusion Matrix Sensitivity: percentage of true defaulters Specificity: percentage of non-defaulters correctly identified o The Bayes classifier optimize the overall error rate independently from the class they belong to an it does this by thresholding o Can we improve on this?
45 Example: Increasing LDA Sensitivity 45 o We might want to improve classifier sensitivity with respect to a given class because we consider it more critical Reduced Default error rate from 75.7% to 41.4% Increased overall error of 3.73% (but it is worth)
46 Tweaking LDA sensitivity 46 The right choice comes from domain knowledge
47 ROC Curve 47 o The ROC (Receiver Operating Characteristics) summarizes false positive and false negative errors o Obtained by testing all possible thresholds Overall performance given by Area Under the ROC Curve A classifier which randomly guesses (with two classes) has an AUC = 0.5 a perfect classifier has AUC = 1 o ROC curve considers true positive and false positive rates Sensitivity is equivalent to true positive rate Specificity is equivalent to 1 false positive rate
48 ROC Curve for LDA on Default data 48 All subjects are defaulters No subject is defaulter ROC Curve for Logistic Regression is ~ the same
49 Clearing out terminology 49 o When applying a classifier we can obtain o Out of this we can define the following
50 Quadratic Discriminant Analysis 50 o Linear Discriminant Analysis assumes all classes having a common covariance structure o Quadratic Discriminant Analysis assumes different covariances o Under this hypothesis the Bayes discriminant function becomes Can you derive this? Quadratic function o The decision LDA vs. QDA boils down to bias-variance trade-off QDA requires parameters while LDA only

51 QDA vs LDA Example 51
52 Which classifier is better? 52 o Let consider 2 classes and 1 predictor It can be seen that for LDA the log odds is given by While for Logistic Regression the log odds is Both linear functions but learning procedures are different o Linear Discriminant Analysis is the Optimal Bayes if its hypothesis holds otherwise Logistic Regression can outperforms it! o Quadratic Discriminant Analysis is to be preferred if the class covariances are different and we have a non linear boundary
53 Some scenarios tested 53 o Linear Boundary Scenarios 1. Samples from 2 uncorrelated normal distributions 2. Samples from 2 slightly correlated normal distributions 3. Samples from t-student distributed classes
54 Some other scenarios tested 54 o Non Linear Boundary Scenarios 4. Samples from 2 normal distribution with different correlation 5. Samples from 2 normals, predictors are quadratic functions 6. As previous but with a more complicated function
55 Overall conclusion on the comparison 55 o No method is better than all the others In the decision boundary is linear then LDA and Logistic Regression are those performing better When the decision boundary is moderately non linear QDA may give better results For much complex decision boundaries non parametric approaches such as KNN perform better, but the right level of smoothness has to be chosen
Introduction to Data Science
 Introduction to Data Science Winter Semester 2018/19 Oliver Ernst TU Chemnitz, Fakultät für Mathematik, Professur Numerische Mathematik Lecture Slides Contents I 1 What is Data Science? 2 Learning Theory
Introduction to Data Science Winter Semester 2018/19 Oliver Ernst TU Chemnitz, Fakultät für Mathematik, Professur Numerische Mathematik Lecture Slides Contents I 1 What is Data Science? 2 Learning Theory
Lecture 4 Discriminant Analysis, k-nearest Neighbors
 Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Lecture 9: Classification, LDA
 Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis October 13, 2017 1 / 21 Review: Main strategy in Chapter 4 Find an estimate ˆP (Y X). Then, given an input x 0, we
Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis October 13, 2017 1 / 21 Review: Main strategy in Chapter 4 Find an estimate ˆP (Y X). Then, given an input x 0, we
ECLT 5810 Linear Regression and Logistic Regression for Classification. Prof. Wai Lam
 ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
Lecture 9: Classification, LDA
 Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis Jonathan Taylor, 10/12 Slide credits: Sergio Bacallado 1 / 1 Review: Main strategy in Chapter 4 Find an estimate ˆP
Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis Jonathan Taylor, 10/12 Slide credits: Sergio Bacallado 1 / 1 Review: Main strategy in Chapter 4 Find an estimate ˆP
Lecture 9: Classification, LDA
 Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis October 13, 2017 1 / 21 Review: Main strategy in Chapter 4 Find an estimate ˆP (Y X). Then, given an input x 0, we
Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis October 13, 2017 1 / 21 Review: Main strategy in Chapter 4 Find an estimate ˆP (Y X). Then, given an input x 0, we
Introduction to Signal Detection and Classification. Phani Chavali
 Introduction to Signal Detection and Classification Phani Chavali Outline Detection Problem Performance Measures Receiver Operating Characteristics (ROC) F-Test - Test Linear Discriminant Analysis (LDA)
Introduction to Signal Detection and Classification Phani Chavali Outline Detection Problem Performance Measures Receiver Operating Characteristics (ROC) F-Test - Test Linear Discriminant Analysis (LDA)
Machine Learning Linear Regression. Prof. Matteo Matteucci
 Machine Learning Linear Regression Prof. Matteo Matteucci Outline 2 o Simple Linear Regression Model Least Squares Fit Measures of Fit Inference in Regression o Multi Variate Regession Model Least Squares
Machine Learning Linear Regression Prof. Matteo Matteucci Outline 2 o Simple Linear Regression Model Least Squares Fit Measures of Fit Inference in Regression o Multi Variate Regession Model Least Squares
Final Overview. Introduction to ML. Marek Petrik 4/25/2017
 Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Applied Machine Learning Annalisa Marsico
 Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 22 April, SoSe 2015 Goals Feature Selection rather than Feature
Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 22 April, SoSe 2015 Goals Feature Selection rather than Feature
Lecture 3 Classification, Logistic Regression
 Lecture 3 Classification, Logistic Regression Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se F. Lindsten Summary
Lecture 3 Classification, Logistic Regression Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se F. Lindsten Summary
Classification. Chapter Introduction. 6.2 The Bayes classifier
 Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Contents Lecture 4. Lecture 4 Linear Discriminant Analysis. Summary of Lecture 3 (II/II) Summary of Lecture 3 (I/II)
 Summary of Lecture 3 (I/II)") Contents Lecture Lecture Linear Discriminant Analysis Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University Email: fredriklindsten@ituuse Summary of lecture
Contents Lecture Lecture Linear Discriminant Analysis Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University Email: fredriklindsten@ituuse Summary of lecture
BANA 7046 Data Mining I Lecture 4. Logistic Regression and Classications 1
 BANA 7046 Data Mining I Lecture 4. Logistic Regression and Classications 1 Shaobo Li University of Cincinnati 1 Partially based on Hastie, et al. (2009) ESL, and James, et al. (2013) ISLR Data Mining I
BANA 7046 Data Mining I Lecture 4. Logistic Regression and Classications 1 Shaobo Li University of Cincinnati 1 Partially based on Hastie, et al. (2009) ESL, and James, et al. (2013) ISLR Data Mining I
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
ECLT 5810 Linear Regression and Logistic Regression for Classification. Prof. Wai Lam
 ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
SF2935: MODERN METHODS OF STATISTICAL LECTURE 3 SUPERVISED CLASSIFICATION, LINEAR DISCRIMINANT ANALYSIS LEARNING. Tatjana Pavlenko.
 SF2935: MODERN METHODS OF STATISTICAL LEARNING LECTURE 3 SUPERVISED CLASSIFICATION, LINEAR DISCRIMINANT ANALYSIS Tatjana Pavlenko 5 November 2015 SUPERVISED LEARNING (REP.) Starting point: we have an outcome
SF2935: MODERN METHODS OF STATISTICAL LEARNING LECTURE 3 SUPERVISED CLASSIFICATION, LINEAR DISCRIMINANT ANALYSIS Tatjana Pavlenko 5 November 2015 SUPERVISED LEARNING (REP.) Starting point: we have an outcome
LDA, QDA, Naive Bayes
 LDA, QDA, Naive Bayes Generative Classification Models Marek Petrik 2/16/2017 Last Class Logistic Regression Maximum Likelihood Principle Logistic Regression Predict probability of a class: p(x) Example:
LDA, QDA, Naive Bayes Generative Classification Models Marek Petrik 2/16/2017 Last Class Logistic Regression Maximum Likelihood Principle Logistic Regression Predict probability of a class: p(x) Example:
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Classification Methods II: Linear and Quadratic Discrimminant Analysis
 Classification Methods II: Linear and Quadratic Discrimminant Analysis Rebecca C. Steorts, Duke University STA 325, Chapter 4 ISL Agenda Linear Discrimminant Analysis (LDA) Classification Recall that linear
Classification Methods II: Linear and Quadratic Discrimminant Analysis Rebecca C. Steorts, Duke University STA 325, Chapter 4 ISL Agenda Linear Discrimminant Analysis (LDA) Classification Recall that linear
Machine Learning. Regression-Based Classification & Gaussian Discriminant Analysis. Manfred Huber
 Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
MS&E 226: Small Data
 MS&E 226: Small Data Lecture 12: Logistic regression (v1) Ramesh Johari ramesh.johari@stanford.edu Fall 2015 1 / 30 Regression methods for binary outcomes 2 / 30 Binary outcomes For the duration of this
MS&E 226: Small Data Lecture 12: Logistic regression (v1) Ramesh Johari ramesh.johari@stanford.edu Fall 2015 1 / 30 Regression methods for binary outcomes 2 / 30 Binary outcomes For the duration of this
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Bayesian Decision Theory
 Introduction to Pattern Recognition [ Part 4 ] Mahdi Vasighi Remarks It is quite common to assume that the data in each class are adequately described by a Gaussian distribution. Bayesian classifier is
Introduction to Pattern Recognition [ Part 4 ] Mahdi Vasighi Remarks It is quite common to assume that the data in each class are adequately described by a Gaussian distribution. Bayesian classifier is
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION
 SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
MS&E 226: Small Data
 MS&E 226: Small Data Lecture 9: Logistic regression (v2) Ramesh Johari ramesh.johari@stanford.edu 1 / 28 Regression methods for binary outcomes 2 / 28 Binary outcomes For the duration of this lecture suppose
MS&E 226: Small Data Lecture 9: Logistic regression (v2) Ramesh Johari ramesh.johari@stanford.edu 1 / 28 Regression methods for binary outcomes 2 / 28 Binary outcomes For the duration of this lecture suppose
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
ECE521 Lecture7. Logistic Regression
 ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
Applied Multivariate and Longitudinal Data Analysis
 Applied Multivariate and Longitudinal Data Analysis Discriminant analysis and classification Ana-Maria Staicu SAS Hall 5220; 919-515-0644; astaicu@ncsu.edu 1 Consider the examples: An online banking service
Applied Multivariate and Longitudinal Data Analysis Discriminant analysis and classification Ana-Maria Staicu SAS Hall 5220; 919-515-0644; astaicu@ncsu.edu 1 Consider the examples: An online banking service
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout 2:. The Multivariate Gaussian & Decision Boundaries
 University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
Sparse Linear Models (10/7/13)
") STA56: Probabilistic machine learning Sparse Linear Models (0/7/) Lecturer: Barbara Engelhardt Scribes: Jiaji Huang, Xin Jiang, Albert Oh Sparsity Sparsity has been a hot topic in statistics and machine
STA56: Probabilistic machine learning Sparse Linear Models (0/7/) Lecturer: Barbara Engelhardt Scribes: Jiaji Huang, Xin Jiang, Albert Oh Sparsity Sparsity has been a hot topic in statistics and machine
Evaluation. Andrea Passerini Machine Learning. Evaluation
 Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Evaluation requires to define performance measures to be optimized
 Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Problem #1 #2 #3 #4 #5 #6 Total Points /6 /8 /14 /10 /8 /10 /56
 STAT 391 - Spring Quarter 2017 - Midterm 1 - April 27, 2017 Name: Student ID Number: Problem #1 #2 #3 #4 #5 #6 Total Points /6 /8 /14 /10 /8 /10 /56 Directions. Read directions carefully and show all your
STAT 391 - Spring Quarter 2017 - Midterm 1 - April 27, 2017 Name: Student ID Number: Problem #1 #2 #3 #4 #5 #6 Total Points /6 /8 /14 /10 /8 /10 /56 Directions. Read directions carefully and show all your
Lecture 3. STAT161/261 Introduction to Pattern Recognition and Machine Learning Spring 2018 Prof. Allie Fletcher
 Lecture 3 STAT161/261 Introduction to Pattern Recognition and Machine Learning Spring 2018 Prof. Allie Fletcher Previous lectures What is machine learning? Objectives of machine learning Supervised and
Lecture 3 STAT161/261 Introduction to Pattern Recognition and Machine Learning Spring 2018 Prof. Allie Fletcher Previous lectures What is machine learning? Objectives of machine learning Supervised and
Lecture 2 Machine Learning Review
 Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Class 4: Classification. Quaid Morris February 11 th, 2011 ML4Bio
 Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers
 Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Linear and Logistic Regression. Dr. Xiaowei Huang
 Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet.
 or two-page (one side) crib sheet.") CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
LECTURE NOTE #3 PROF. ALAN YUILLE
 LECTURE NOTE #3 PROF. ALAN YUILLE 1. Three Topics (1) Precision and Recall Curves. Receiver Operating Characteristic Curves (ROC). What to do if we do not fix the loss function? (2) The Curse of Dimensionality.
LECTURE NOTE #3 PROF. ALAN YUILLE 1. Three Topics (1) Precision and Recall Curves. Receiver Operating Characteristic Curves (ROC). What to do if we do not fix the loss function? (2) The Curse of Dimensionality.
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Introduction to Machine Learning Spring 2018 Note 18
 CS 189 Introduction to Machine Learning Spring 2018 Note 18 1 Gaussian Discriminant Analysis Recall the idea of generative models: we classify an arbitrary datapoint x with the class label that maximizes
CS 189 Introduction to Machine Learning Spring 2018 Note 18 1 Gaussian Discriminant Analysis Recall the idea of generative models: we classify an arbitrary datapoint x with the class label that maximizes
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
Machine Learning for OR & FE
 Machine Learning for OR & FE Regression II: Regularization and Shrinkage Methods Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com
Machine Learning for OR & FE Regression II: Regularization and Shrinkage Methods Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com
Lecture 3. Linear Regression II Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Performance Evaluation and Comparison
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Cross Validation and Resampling 3 Interval Estimation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Cross Validation and Resampling 3 Interval Estimation
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Least Squares Regression
 CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
A simulation study of model fitting to high dimensional data using penalized logistic regression
 A simulation study of model fitting to high dimensional data using penalized logistic regression Ellinor Krona Kandidatuppsats i matematisk statistik Bachelor Thesis in Mathematical Statistics Kandidatuppsats
A simulation study of model fitting to high dimensional data using penalized logistic regression Ellinor Krona Kandidatuppsats i matematisk statistik Bachelor Thesis in Mathematical Statistics Kandidatuppsats
DEPARTMENT OF COMPUTER SCIENCE Autumn Semester MACHINE LEARNING AND ADAPTIVE INTELLIGENCE
 Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Outline. Supervised Learning. Hong Chang. Institute of Computing Technology, Chinese Academy of Sciences. Machine Learning Methods (Fall 2012)
") Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d)
") COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d) Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless
COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d) Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless
Introduction to Bayesian Learning. Machine Learning Fall 2018
 Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Modeling Data with Linear Combinations of Basis Functions. Read Chapter 3 in the text by Bishop
 Modeling Data with Linear Combinations of Basis Functions Read Chapter 3 in the text by Bishop A Type of Supervised Learning Problem We want to model data (x 1, t 1 ),..., (x N, t N ), where x i is a vector
Modeling Data with Linear Combinations of Basis Functions Read Chapter 3 in the text by Bishop A Type of Supervised Learning Problem We want to model data (x 1, t 1 ),..., (x N, t N ), where x i is a vector
COMS 4771 Regression. Nakul Verma
 COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
Midterm. Introduction to Machine Learning. CS 189 Spring Please do not open the exam before you are instructed to do so.
 CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
Assignment 3. Introduction to Machine Learning Prof. B. Ravindran
 Assignment 3 Introduction to Machine Learning Prof. B. Ravindran 1. In building a linear regression model for a particular data set, you observe the coefficient of one of the features having a relatively
Assignment 3 Introduction to Machine Learning Prof. B. Ravindran 1. In building a linear regression model for a particular data set, you observe the coefficient of one of the features having a relatively
Generative classifiers: The Gaussian classifier. Ata Kaban School of Computer Science University of Birmingham
 Generative classifiers: The Gaussian classifier Ata Kaban School of Computer Science University of Birmingham Outline We have already seen how Bayes rule can be turned into a classifier In all our examples
Generative classifiers: The Gaussian classifier Ata Kaban School of Computer Science University of Birmingham Outline We have already seen how Bayes rule can be turned into a classifier In all our examples
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Learning Classification with Auxiliary Probabilistic Information Quang Nguyen Hamed Valizadegan Milos Hauskrecht
 Learning Classification with Auxiliary Probabilistic Information Quang Nguyen Hamed Valizadegan Milos Hauskrecht Computer Science Department University of Pittsburgh Outline Introduction Learning with
Learning Classification with Auxiliary Probabilistic Information Quang Nguyen Hamed Valizadegan Milos Hauskrecht Computer Science Department University of Pittsburgh Outline Introduction Learning with
Gaussian discriminant analysis Naive Bayes
 DM825 Introduction to Machine Learning Lecture 7 Gaussian discriminant analysis Marco Chiarandini Department of Mathematics & Computer Science University of Southern Denmark Outline 1. is 2. Multi-variate
DM825 Introduction to Machine Learning Lecture 7 Gaussian discriminant analysis Marco Chiarandini Department of Mathematics & Computer Science University of Southern Denmark Outline 1. is 2. Multi-variate
Machine Learning Basics Lecture 7: Multiclass Classification. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Least Squares Regression
 E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
COMS 4771 Introduction to Machine Learning. James McInerney Adapted from slides by Nakul Verma
 COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
COMP 551 Applied Machine Learning Lecture 5: Generative models for linear classification
 COMP 55 Applied Machine Learning Lecture 5: Generative models for linear classification Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp55 Unless otherwise noted, all material
COMP 55 Applied Machine Learning Lecture 5: Generative models for linear classification Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp55 Unless otherwise noted, all material
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES. Supervised Learning
 LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
Machine Learning 2017
 Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
MODULE -4 BAYEIAN LEARNING
 MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
STATS216v Introduction to Statistical Learning Stanford University, Summer Midterm Exam (Solutions) Duration: 1 hours
 Duration: 1 hours") Instructions: STATS216v Introduction to Statistical Learning Stanford University, Summer 2017 Remember the university honor code. Midterm Exam (Solutions) Duration: 1 hours Write your name and SUNet ID
Instructions: STATS216v Introduction to Statistical Learning Stanford University, Summer 2017 Remember the university honor code. Midterm Exam (Solutions) Duration: 1 hours Write your name and SUNet ID
Notes on Discriminant Functions and Optimal Classification
 Notes on Discriminant Functions and Optimal Classification Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Discriminant Functions Consider a classification problem
Notes on Discriminant Functions and Optimal Classification Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Discriminant Functions Consider a classification problem
Machine Learning (CS 567) Lecture 5
 Lecture 5") Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Feature Engineering, Model Evaluations
 Feature Engineering, Model Evaluations Giri Iyengar Cornell University gi43@cornell.edu Feb 5, 2018 Giri Iyengar (Cornell Tech) Feature Engineering Feb 5, 2018 1 / 35 Overview 1 ETL 2 Feature Engineering
Feature Engineering, Model Evaluations Giri Iyengar Cornell University gi43@cornell.edu Feb 5, 2018 Giri Iyengar (Cornell Tech) Feature Engineering Feb 5, 2018 1 / 35 Overview 1 ETL 2 Feature Engineering
CMSC858P Supervised Learning Methods
 CMSC858P Supervised Learning Methods Hector Corrada Bravo March, 2010 Introduction Today we discuss the classification setting in detail. Our setting is that we observe for each subject i a set of p predictors
CMSC858P Supervised Learning Methods Hector Corrada Bravo March, 2010 Introduction Today we discuss the classification setting in detail. Our setting is that we observe for each subject i a set of p predictors
CSC 411: Lecture 04: Logistic Regression
 CSC 411: Lecture 04: Logistic Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 23, 2015 Urtasun & Zemel (UofT) CSC 411: 04-Prob Classif Sep 23, 2015 1 / 16 Today Key Concepts: Logistic
CSC 411: Lecture 04: Logistic Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 23, 2015 Urtasun & Zemel (UofT) CSC 411: 04-Prob Classif Sep 23, 2015 1 / 16 Today Key Concepts: Logistic
Generative Learning. INFO-4604, Applied Machine Learning University of Colorado Boulder. November 29, 2018 Prof. Michael Paul
 Generative Learning INFO-4604, Applied Machine Learning University of Colorado Boulder November 29, 2018 Prof. Michael Paul Generative vs Discriminative The classification algorithms we have seen so far
Generative Learning INFO-4604, Applied Machine Learning University of Colorado Boulder November 29, 2018 Prof. Michael Paul Generative vs Discriminative The classification algorithms we have seen so far
Classification: Linear Discriminant Analysis
 Classification: Linear Discriminant Analysis Discriminant analysis uses sample information about individuals that are known to belong to one of several populations for the purposes of classification. Based
Classification: Linear Discriminant Analysis Discriminant analysis uses sample information about individuals that are known to belong to one of several populations for the purposes of classification. Based
Biostatistics-Lecture 16 Model Selection. Ruibin Xi Peking University School of Mathematical Sciences
 Biostatistics-Lecture 16 Model Selection Ruibin Xi Peking University School of Mathematical Sciences Motivating example1 Interested in factors related to the life expectancy (50 US states,1969-71 ) Per
Biostatistics-Lecture 16 Model Selection Ruibin Xi Peking University School of Mathematical Sciences Motivating example1 Interested in factors related to the life expectancy (50 US states,1969-71 ) Per
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Lecture 5: LDA and Logistic Regression
 Lecture 5: and Logistic Regression Hao Helen Zhang Hao Helen Zhang Lecture 5: and Logistic Regression 1 / 39 Outline Linear Classification Methods Two Popular Linear Models for Classification Linear Discriminant
Lecture 5: and Logistic Regression Hao Helen Zhang Hao Helen Zhang Lecture 5: and Logistic Regression 1 / 39 Outline Linear Classification Methods Two Popular Linear Models for Classification Linear Discriminant
Machine Learning for OR & FE
 Machine Learning for OR & FE Introduction to Classification Algorithms Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com Some
Machine Learning for OR & FE Introduction to Classification Algorithms Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com Some
Classifier performance evaluation
 Classifier performance evaluation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics 166 36 Prague 6, Jugoslávských partyzánu 1580/3, Czech Republic
Classifier performance evaluation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics 166 36 Prague 6, Jugoslávských partyzánu 1580/3, Czech Republic
Introduction to Logistic Regression
 Introduction to Logistic Regression Problem & Data Overview Primary Research Questions: 1. What are the risk factors associated with CHD? Regression Questions: 1. What is Y? 2. What is X? Did player develop
Introduction to Logistic Regression Problem & Data Overview Primary Research Questions: 1. What are the risk factors associated with CHD? Regression Questions: 1. What is Y? 2. What is X? Did player develop
ESS2222. Lecture 4 Linear model
 ESS2222 Lecture 4 Linear model Hosein Shahnas University of Toronto, Department of Earth Sciences, 1 Outline Logistic Regression Predicting Continuous Target Variables Support Vector Machine (Some Details)
ESS2222 Lecture 4 Linear model Hosein Shahnas University of Toronto, Department of Earth Sciences, 1 Outline Logistic Regression Predicting Continuous Target Variables Support Vector Machine (Some Details)
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Linear Classifiers. Blaine Nelson, Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
The Naïve Bayes Classifier. Machine Learning Fall 2017
 The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning