Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
|
|
|
- Laureen Webb
- 5 years ago
- Views:
Transcription
1 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016
2 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest Neighbor Density Estimation Supervised: Instance-based learners Classification knn classification Weighted (or kernel) knn Regression knn regression Locally linear weighted regression 2
3 Introduction Estimation of arbitrary density functions Parametric density functions cannot usually fit the densities we encounter in practical problems. e.g., parametric densities are unimodal. Non-parametric methods don't assume that the model (from) of underlying densities is known in advance Non-parametric methods (for classification) can be categorized into Generative Estimate p(x C i ) from D i using non-parametric density estimation Discriminative Estimate p(c i x) from D 3
4 Parametric vs. nonparametric methods Parametric methods need to find parameters from data and then use the inferred parameters to decide on new data points Learning: finding parameters from data Nonparametric methods Training examples are explicitly used Training phase is not required Both supervised and unsupervised learning methods can be categorized into parametric and non-parametric methods. 4
5 Histogram approximation idea Histogram approximation of an unknown pdf P(b l ) k n (b l )/n l = 1,, L k n (b l ): number of samples (among n ones) lied in the bin b l k n The corresponding estimated pdf: p x = P(b l) h x x bl h 2 h Mid-point of the bin b l 5
6 Non-parametric density estimation Probability of falling in a region R: P = R p x dx (smoothed version of p x ) D = x i n i=1 : a set of samples drawn i.i.d. according to p x The probability that k of the n samples fall in R: P k = n k Pk 1 P n k E k = np This binomial distribution peaks sharply about the mean: k np k as an estimate for P n More accurate for larger n 6
7 Non-parametric density estimation We can estimate smoothed p x by estimating P: Assumptions: p x is continuous and the region R enclosing x is so small that p is near constant in it: P = R p x dx = p x V V = Vol R x R p x = P V k/n V Let V approach zero if we want to find p x averaged version. instead of the 7
8 Necessary conditions for converge p n x is the estimate of p x using n samples: 8 V n : the volume of region around x k n : the number of samples falling in the region p n x = k n/n V n Necessary conditions for converge of p n x to p(x): lim V n = 0 n lim k n = n lim k n /n = 0 n
9 Non-parametric density estimation: Main approaches Two approaches of satisfying conditions: k-nearest neighbor density estimator: fix K and determine the value ofv from the data Volume grows until it contains K neighbors of x Kernel density estimator (Parzen window): fix V and determine K from the data Number of points falling inside the volume can vary from point to point 9
10 Parzen window Extension of histogram idea: Hyper-cubes with length of side h (i.e., volume h d ) are located on the samples Hypercube as a simple window function: φ u = 1 ( u u d 1 2 ) 0 o. w. 1 1/2 1/2 1 1/2 1/2 p n x = k n nv n = 1 nv n i=1 n φ x x(i) h n k n = n i=1 V n = h n d φ x x(i) h n number of samples in the hypercube around x 10
11 Window function Necessary conditions for window function to find legitimate density function: φ(x) 0 φ x dx = 1 Windows are also called kernels or potential functions. 11
12 Density estimation: non-parametric p n x = 1 n n i=1 N(x x (i), h 2 ) 1 2πh e x x (i) 2 2h σ = h p x = 1 n = 1 n i=1 n i=1 n 1 N(x x (i), σ 2 ) 2πσ e x x (i) 2 2σ 2 12 Choice of σ is crucial.

13 Density estimation: non-parametric σ = 0.02 σ = 0.1 σ = 0.5 σ =
 converges to p(x)")
14 Window (or kernel) function: Width parameter n p n x = 1 n 1 h n d i=1 φ x x(i) h n Choosing h n : Too large: low resolution Too small: much variability [Duda, Hurt, and Stork] For unlimited n, by letting V n slowly approach zero as n increases p n (x) converges to p(x) 14
15 Width parameter For fixed n, a smaller h results in higher variance while a larger h leads to higher bias. For a fixed h, the variance decreases as the number of sample points n tends to infinity for a large enough number of samples, the smaller h the better the accuracy of the resulting estimate In practice, where only a finite number of samples is possible, a compromise between h and n must be made. h can be set using techniques like cross-validation where the density estimation used for learning tasks such as classification 15
16 Practical issues: Curse of dimensionality Large n is necessary to find an acceptable density estimation in high dimensional feature spaces n must grow exponentially with the dimensionality d. If n equidistant points are required to densely fill a one-dim interval, n d points are needed to fill the corresponding d-dim hypercube. We need an exponentially large quantity of training data to ensure that the cells are not empty Also complexity requirements 16 d = 1 d = 2 d = 3
17 k n -nearest neighbor estimation Cell volume is a function of the point location To estimate p(x), let the cell around x grow until it captures k n samples called k n nearest neighbors of x. k n is a function of n Two possibilities can occur: high density near x cell will be small which provides a good resolution low density near x cell will grow large and stop until higher density regions are reached 17
18 k n -nearest neighbor estimation Necessary and sufficient conditions of convergence: lim k n n lim k n /n 0 n A family of estimates by setting k n = k 1 different values for k 1 : n and choosing p n x = k n/n V n V n 1/p(x) n k 1 = 1 V n is a function of x 18

19 k n -Nearest Neighbor Estimation: Example Discontinuities in the slopes [Bishop] 19
20 Non-parametric density estimation: Summary Generality of distributions With enough samples, convergence to an arbitrarily complicated target density can be obtained. The number of required samples must be very large to assure convergence grows exponentially with the dimensionality of the feature space These methods are very sensitive to the choice of window width or number of nearest neighbors There may be severe requirements for computation time and storage (needed to save all training samples). training phase simply requires storage of the training set. computational cost of evaluating p(x) grows linearly with the size of the data set. 20
21 Nonparametric learners Memory-based or instance-based learners lazy learning: (almost) all the work is done at the test time. Generic description: Memorize training (x (1), y (1) ),..., (x (n), y (n) ). Given test x predict: y = f(x; x (1), y (1),..., x (n), y (n) ). f is typically expressed in terms of the similarity of the test sample x to the training samples x (1),..., x (n) 21
22 Parzen window & generative classification If 1 n1 1 h d 1 n2 1 h d x (i) D1 x (i) D2 φ x x(i) h φ x x(i) h > P(C 2) P(C 1 ) decide C 1 otherwise decide C 2 n j = D j (j = 1,2): number of training samples in class C j D j : set of training samples labels as C j For large n, it needs both high time and memory requirements 22


23 Parzen window & generative classification: Example Smaller h larger h 23 [Duda, Hurt, and Stork]
24 k n -nearest neighbor estimation & generative classification If kn 2V 2 kn 1 V 1 > P(C 2) P(C 1 ) decide C 1 otherwise decide C 2 n j = D j (j = 1,2): number of training samples in class C j D j : set of training samples labels as C j V j shows the hypersphere volumes r j : the radius of the hypersphere centered at x containing k samples of the class C j (j = 1,2) k may not necessarily be the same for all classes 24
25 k-nearest-neighbor (knn) rule k-nn classifier: k > 1 nearest neighbors Label for x predicted by majority voting among its k-nn. x 2 k = 5 1? x = [x 1, x 2 ] x 1 What is the effect of k? 25
26 knn classifier Given Training data {(x 1, y 1 ),..., (x n, y n )} are simply stored. Test sample: x To classify x: Find k nearest training samples to x Out of these k samples, identify the number of samples k j belonging to class C j (j = 1,, C). Assign x to the class C j where j = argmax k j j=1,,c It can be considered as a discriminative method. 26
27 Probabilistic perspective of knn knn as a discriminative nonparametric classifier Non-parametric density estimation for P(C j x) P C j x k j k where k j shows the number of training samples among k nearest neighbors of x that are labeled C j Bayes decision rule for assigning labels 27

28 Nearest-neighbor classifier: Example Voronoi tessellation: Each cell consists of all points closer to a given training point than to any other training points All points in a cell are labeled by the category of the corresponding training point. 28 [Duda, Hurt, and Strok s Book]
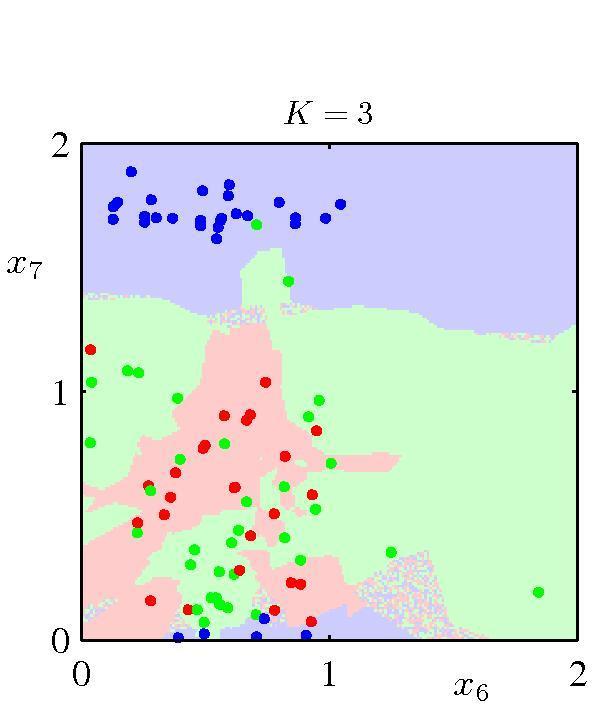
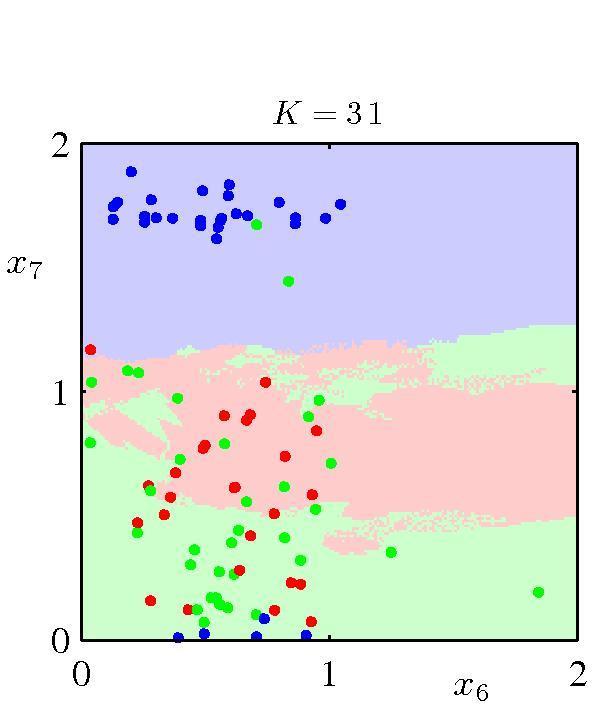
29 knn classifier: Effect of k [Bishop] 29
30 Nearest neighbor classifier: error bound Nearest-Neighbor: knn with k = 1 Decision rule: y = y NN(x) where NN(x) = argmin i=1,,n x x (i) Cover & Hart 67: asymptotic risk of NN classifier satisfies: R R NN 2R (1 R ) 2R R n : expected risk of NN classifier with n training examples drawn from p(x, y) R NN = lim n R n NN R : the optimal Bayes risk 30
31 k-nn classifier: error bound Devr 96: the asymptotic risk of the knn classifier R = lim n R n satisfies R R knn R + where R is the optimal Bayes risk. 2R NN k 31
32 Instance-based learner Main things to construct an instance-based learner: A distance metric Number of nearest neighbors of the test data that we look at A weighting function (optional) How to find the output based on neighbors? 33
33 Distance measures Euclidean distance d x, x = x x 2 2 = x 1 x x d x d 2 Distance learning methods for this purpose Weighted Euclidean distance d w x, x = w 1 x 1 x w d x d x d 2 Mahalanobis distance d A x, x = x 1 x 1 T A x 1 x 1 Other distances: Hamming, angle, Sensitive to irrelevant features L p x, x = p d i=1 x i x i p 34
34 Distance measure: example d x, x = x 1 x x 2 x 2 2 d x, x = x 1 x x 2 x
35 Weighted knn classification Weight nearer neighbors more heavily: y = f x = argmax c=1,,c j N k (x) w j (x) I(c = y j ) w j (x) = 1 x x (j) 2 An example of weighting function In the weighted knn, we can use all training examples instead of just k (Stepard s method): 36 y = f x = argmax c=1,,c n j=1 w j (x) I(c = y j ) Weights can be found using a kernel function w j (x) = K(x, x (j) ): e.g., K(x, x (j) ) = e d(x,x(j) ) σ 2
36 Weighting functions d = d(x, x ) 37 [Fig. has been adopted from Andrew Moore s tutorial on Instance-based learning ]
37 knn regression Simplest k-nn regression: Let x 1,, x k be the k nearest neighbors of x and y 1,, y k be their labels. y = 1 k k j=1 y j Problems of knn regression for fitting functions: Problem 1: Discontinuities in the estimated function Solution:Weighted (or kernel) regression 1NN: noise-fitting problem knn ( k > 1 ) smoothes away noise, but there are other deficiencies. flats the ends 38
38 knn regression: examples Dataset 1 Dataset 2 Dataset 3 k = 1 k = 9 39 [Figs. have been adopted from Andrew Moore s tutorial on Instance-based learning ]
39 Weighted (or kernel) knn regression Higher weights to nearer neighbors: y = f x = j N k (x) w j(x) y (j) j N k (x) w j(x) In the weighted knn regression, we can use all training examples instead of just k in the weighted form: y = f x = j=1 n w j (x) y (j) n w j (x) j=1 40
40 Kernel knn regression σ = 1 32 of x-axis width σ = 1 32 of x-axis width σ = 1 16 of x-axis width Choosing a good parameter (kernel width) is important. 41 [This slide has been adapted from Andrew Moore s tutorial on Instance-based learning ]
41 Kernel knn regression In these datasets, some regions are without samples Best kernel widths have been used Disadvantages: not capturing the simple structure of the data failure to extrapolate at edges 42 [Figs. have been adopted from Andrew Moore s tutorial on Instance-based learning ]
42 Locally weighted linear regression For each test sample, it produces linear approximation to the target function in a local region Instead of finding the output using weighted averaging (as in the kernel regression), we fit a parametric function locally: y = f x, x 1, y 1,..., x n, y n y = f x; w = w 0 + w 1 x w d x d J w = i N k (x) y i w T x i 2 Unweighted linear 43 w is found for each test sample
43 Locally weighted linear regression y = f x, x 1, y 1,..., x n, y n J w x = y i w T x i 2 i N k (x) J w x = K x, x i y i w T x i 2 i N k (x) unweighted e.g, K x,x i = e x x i 2σ 2 weighted 2 J w x = n i=1 K x, x i y i w T x i 2 Weighted on all training examples 44
44 Locally weighted linear regression: example σ = 1 16 of x-axis width σ = 1 32 of x-axis width σ = 1 8 of x-axis width More proper result than weighted knn regression 45 [Figs. have been adopted from Andrew Moore s tutorial on Instance-based learning ]
45 Locally weighted regression: summary Idea 1: weighted knn regression using the weighted average on the output of x s neighbors (or on the outputs of all training data): y = i=1 k y i K(x, x (i) ) k K(x, x (j) ) j=1 Idea 2: Locally weighted parametric regression Fit a parametric model (e.g. linear function) to the neighbors of x (or on all training data). Implicit assumption: the target function is reasonably smooth. y 46 x
46 Parametric vs. nonparametric methods Is SVM classifier parametric? y = sign(w 0 + α i y i K(x, x (i) )) α i >0 In general, we can not summarize it in a simple parametric form. Need to keep around support vectors (possibly all of the training data). However, α i are kind of parameters that are found in the training phase 47
47 Instance-based learning: summary Learning is just storing the training data prediction on a new data based on the training data themselves An instance-based learner does not rely on assumption concerning the structure of the underlying density function. With large datasets, instance-based methods are slow for prediction on the test data kd-tree, Locally Sensitive Hashing (LSH), and other knn approximations can help. 48
48 Reference T. Mitchell, Machine Learning, [Chapter 8] 49
Machine Learning. Nonparametric Methods. Space of ML Problems. Todo. Histograms. Instance-Based Learning (aka non-parametric methods)
") Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
probability of k samples out of J fall in R.
 Nonparametric Techniques for Density Estimation (DHS Ch. 4) n Introduction n Estimation Procedure n Parzen Window Estimation n Parzen Window Example n K n -Nearest Neighbor Estimation Introduction Suppose
Nonparametric Techniques for Density Estimation (DHS Ch. 4) n Introduction n Estimation Procedure n Parzen Window Estimation n Parzen Window Example n K n -Nearest Neighbor Estimation Introduction Suppose
Nonparametric Methods Lecture 5
 Nonparametric Methods Lecture 5 Jason Corso SUNY at Buffalo 17 Feb. 29 J. Corso (SUNY at Buffalo) Nonparametric Methods Lecture 5 17 Feb. 29 1 / 49 Nonparametric Methods Lecture 5 Overview Previously,
Nonparametric Methods Lecture 5 Jason Corso SUNY at Buffalo 17 Feb. 29 J. Corso (SUNY at Buffalo) Nonparametric Methods Lecture 5 17 Feb. 29 1 / 49 Nonparametric Methods Lecture 5 Overview Previously,
Machine Learning. Theory of Classification and Nonparametric Classifier. Lecture 2, January 16, What is theoretically the best classifier
 Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
Nonparametric probability density estimation
 A temporary version for the 2018-04-11 lecture. Nonparametric probability density estimation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics
A temporary version for the 2018-04-11 lecture. Nonparametric probability density estimation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics
Supervised Learning: Non-parametric Estimation
 Supervised Learning: Non-parametric Estimation Edmondo Trentin March 18, 2018 Non-parametric Estimates No assumptions are made on the form of the pdfs 1. There are 3 major instances of non-parametric estimates:
Supervised Learning: Non-parametric Estimation Edmondo Trentin March 18, 2018 Non-parametric Estimates No assumptions are made on the form of the pdfs 1. There are 3 major instances of non-parametric estimates:
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Nearest Neighbor. Machine Learning CSE546 Kevin Jamieson University of Washington. October 26, Kevin Jamieson 2
 Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
CSE446: non-parametric methods Spring 2017
 CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
CS4495/6495 Introduction to Computer Vision. 8C-L3 Support Vector Machines
 CS4495/6495 Introduction to Computer Vision 8C-L3 Support Vector Machines Discriminative classifiers Discriminative classifiers find a division (surface) in feature space that separates the classes Several
CS4495/6495 Introduction to Computer Vision 8C-L3 Support Vector Machines Discriminative classifiers Discriminative classifiers find a division (surface) in feature space that separates the classes Several
Non-parametric Methods
 Non-parametric Methods Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 2 of Pattern Recognition and Machine Learning by Bishop (with an emphasis on section 2.5) Möller/Mori 2 Outline Last
Non-parametric Methods Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 2 of Pattern Recognition and Machine Learning by Bishop (with an emphasis on section 2.5) Möller/Mori 2 Outline Last
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
BAYESIAN DECISION THEORY
 Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Probability Models for Bayesian Recognition
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG / osig Second Semester 06/07 Lesson 9 0 arch 07 Probability odels for Bayesian Recognition Notation... Supervised Learning for Bayesian
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG / osig Second Semester 06/07 Lesson 9 0 arch 07 Probability odels for Bayesian Recognition Notation... Supervised Learning for Bayesian
Probabilistic Methods in Bioinformatics. Pabitra Mitra
 Probabilistic Methods in Bioinformatics Pabitra Mitra pabitra@cse.iitkgp.ernet.in Probability in Bioinformatics Classification Categorize a new object into a known class Supervised learning/predictive
Probabilistic Methods in Bioinformatics Pabitra Mitra pabitra@cse.iitkgp.ernet.in Probability in Bioinformatics Classification Categorize a new object into a known class Supervised learning/predictive
Curve Fitting Re-visited, Bishop1.2.5
 Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
EEL 851: Biometrics. An Overview of Statistical Pattern Recognition EEL 851 1
 EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
Introduction to Machine Learning
 Introduction to Machine Learning 3. Instance Based Learning Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Parzen Windows Kernels, algorithm Model selection
Introduction to Machine Learning 3. Instance Based Learning Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Parzen Windows Kernels, algorithm Model selection
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Lecture 3: Statistical Decision Theory (Part II)
") Lecture 3: Statistical Decision Theory (Part II) Hao Helen Zhang Hao Helen Zhang Lecture 3: Statistical Decision Theory (Part II) 1 / 27 Outline of This Note Part I: Statistics Decision Theory (Classical
Lecture 3: Statistical Decision Theory (Part II) Hao Helen Zhang Hao Helen Zhang Lecture 3: Statistical Decision Theory (Part II) 1 / 27 Outline of This Note Part I: Statistics Decision Theory (Classical
Brief Introduction to Machine Learning
 Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Decision Trees. Machine Learning CSEP546 Carlos Guestrin University of Washington. February 3, 2014
 Decision Trees Machine Learning CSEP546 Carlos Guestrin University of Washington February 3, 2014 17 Linear separability n A dataset is linearly separable iff there exists a separating hyperplane: Exists
Decision Trees Machine Learning CSEP546 Carlos Guestrin University of Washington February 3, 2014 17 Linear separability n A dataset is linearly separable iff there exists a separating hyperplane: Exists
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
ECE662: Pattern Recognition and Decision Making Processes: HW TWO
 ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Machine Learning 2017
 Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Chapter 9. Non-Parametric Density Function Estimation
 9-1 Density Estimation Version 1.1 Chapter 9 Non-Parametric Density Function Estimation 9.1. Introduction We have discussed several estimation techniques: method of moments, maximum likelihood, and least
9-1 Density Estimation Version 1.1 Chapter 9 Non-Parametric Density Function Estimation 9.1. Introduction We have discussed several estimation techniques: method of moments, maximum likelihood, and least
Geometric View of Machine Learning Nearest Neighbor Classification. Slides adapted from Prof. Carpuat
 Geometric View of Machine Learning Nearest Neighbor Classification Slides adapted from Prof. Carpuat What we know so far Decision Trees What is a decision tree, and how to induce it from data Fundamental
Geometric View of Machine Learning Nearest Neighbor Classification Slides adapted from Prof. Carpuat What we know so far Decision Trees What is a decision tree, and how to induce it from data Fundamental
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
Classification: The rest of the story
 U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Recap from previous lecture
 Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors. Furong Huang /
 CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors Furong Huang / furongh@cs.umd.edu What we know so far Decision Trees What is a decision tree, and how to induce it from
CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors Furong Huang / furongh@cs.umd.edu What we know so far Decision Trees What is a decision tree, and how to induce it from
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION
 SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
GI01/M055: Supervised Learning
 GI01/M055: Supervised Learning 1. Introduction to Supervised Learning October 5, 2009 John Shawe-Taylor 1 Course information 1. When: Mondays, 14:00 17:00 Where: Room 1.20, Engineering Building, Malet
GI01/M055: Supervised Learning 1. Introduction to Supervised Learning October 5, 2009 John Shawe-Taylor 1 Course information 1. When: Mondays, 14:00 17:00 Where: Room 1.20, Engineering Building, Malet
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Chapter 9. Non-Parametric Density Function Estimation
 9-1 Density Estimation Version 1.2 Chapter 9 Non-Parametric Density Function Estimation 9.1. Introduction We have discussed several estimation techniques: method of moments, maximum likelihood, and least
9-1 Density Estimation Version 1.2 Chapter 9 Non-Parametric Density Function Estimation 9.1. Introduction We have discussed several estimation techniques: method of moments, maximum likelihood, and least
Multivariate statistical methods and data mining in particle physics
 Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
On Bias, Variance, 0/1-Loss, and the Curse-of-Dimensionality. Weiqiang Dong
 On Bias, Variance, 0/1-Loss, and the Curse-of-Dimensionality Weiqiang Dong 1 The goal of the work presented here is to illustrate that classification error responds to error in the target probability estimates
On Bias, Variance, 0/1-Loss, and the Curse-of-Dimensionality Weiqiang Dong 1 The goal of the work presented here is to illustrate that classification error responds to error in the target probability estimates
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Chap 1. Overview of Statistical Learning (HTF, , 2.9) Yongdai Kim Seoul National University
 Yongdai Kim Seoul National University") Chap 1. Overview of Statistical Learning (HTF, 2.1-2.6, 2.9) Yongdai Kim Seoul National University 0. Learning vs Statistical learning Learning procedure Construct a claim by observing data or using logics
Chap 1. Overview of Statistical Learning (HTF, 2.1-2.6, 2.9) Yongdai Kim Seoul National University 0. Learning vs Statistical learning Learning procedure Construct a claim by observing data or using logics
CENG 793. On Machine Learning and Optimization. Sinan Kalkan
 CENG 793 On Machine Learning and Optimization Sinan Kalkan 2 Now Introduction to ML Problem definition Classes of approaches K-NN Support Vector Machines Softmax classification / logistic regression Parzen
CENG 793 On Machine Learning and Optimization Sinan Kalkan 2 Now Introduction to ML Problem definition Classes of approaches K-NN Support Vector Machines Softmax classification / logistic regression Parzen
Chemometrics: Classification of spectra
 Chemometrics: Classification of spectra Vladimir Bochko Jarmo Alander University of Vaasa November 1, 2010 Vladimir Bochko Chemometrics: Classification 1/36 Contents Terminology Introduction Big picture
Chemometrics: Classification of spectra Vladimir Bochko Jarmo Alander University of Vaasa November 1, 2010 Vladimir Bochko Chemometrics: Classification 1/36 Contents Terminology Introduction Big picture
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
12 - Nonparametric Density Estimation
 ST 697 Fall 2017 1/49 12 - Nonparametric Density Estimation ST 697 Fall 2017 University of Alabama Density Review ST 697 Fall 2017 2/49 Continuous Random Variables ST 697 Fall 2017 3/49 1.0 0.8 F(x) 0.6
ST 697 Fall 2017 1/49 12 - Nonparametric Density Estimation ST 697 Fall 2017 University of Alabama Density Review ST 697 Fall 2017 2/49 Continuous Random Variables ST 697 Fall 2017 3/49 1.0 0.8 F(x) 0.6
CS 195-5: Machine Learning Problem Set 1
 CS 95-5: Machine Learning Problem Set Douglas Lanman dlanman@brown.edu 7 September Regression Problem Show that the prediction errors y f(x; ŵ) are necessarily uncorrelated with any linear function of
CS 95-5: Machine Learning Problem Set Douglas Lanman dlanman@brown.edu 7 September Regression Problem Show that the prediction errors y f(x; ŵ) are necessarily uncorrelated with any linear function of
Non-parametric Methods
 Non-parametric Methods Machine Learning Alireza Ghane Non-Parametric Methods Alireza Ghane / Torsten Möller 1 Outline Machine Learning: What, Why, and How? Curve Fitting: (e.g.) Regression and Model Selection
Non-parametric Methods Machine Learning Alireza Ghane Non-Parametric Methods Alireza Ghane / Torsten Möller 1 Outline Machine Learning: What, Why, and How? Curve Fitting: (e.g.) Regression and Model Selection
Data Mining. Linear & nonlinear classifiers. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Mining of Massive Datasets Jure Leskovec, AnandRajaraman, Jeff Ullman Stanford University
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Exploiting k-nearest Neighbor Information with Many Data
 Exploiting k-nearest Neighbor Information with Many Data 2017 TEST TECHNOLOGY WORKSHOP 2017. 10. 24 (Tue.) Yung-Kyun Noh Robotics Lab., Contents Nonparametric methods for estimating density functions Nearest
Exploiting k-nearest Neighbor Information with Many Data 2017 TEST TECHNOLOGY WORKSHOP 2017. 10. 24 (Tue.) Yung-Kyun Noh Robotics Lab., Contents Nonparametric methods for estimating density functions Nearest
Pattern Recognition 2
 Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Machine Learning Lecture 3
 Announcements Machine Learning Lecture 3 Eam dates We re in the process of fiing the first eam date Probability Density Estimation II 9.0.207 Eercises The first eercise sheet is available on L2P now First
Announcements Machine Learning Lecture 3 Eam dates We re in the process of fiing the first eam date Probability Density Estimation II 9.0.207 Eercises The first eercise sheet is available on L2P now First
Pattern Recognition and Machine Learning. Bishop Chapter 2: Probability Distributions
 Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Issues and Techniques in Pattern Classification
 Issues and Techniques in Pattern Classification Carlotta Domeniconi www.ise.gmu.edu/~carlotta Machine Learning Given a collection of data, a machine learner eplains the underlying process that generated
Issues and Techniques in Pattern Classification Carlotta Domeniconi www.ise.gmu.edu/~carlotta Machine Learning Given a collection of data, a machine learner eplains the underlying process that generated
Artificial Intelligence Roman Barták
 Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
Classification and Pattern Recognition
 Classification and Pattern Recognition Léon Bottou NEC Labs America COS 424 2/23/2010 The machine learning mix and match Goals Representation Capacity Control Operational Considerations Computational Considerations
Classification and Pattern Recognition Léon Bottou NEC Labs America COS 424 2/23/2010 The machine learning mix and match Goals Representation Capacity Control Operational Considerations Computational Considerations
The Gaussian distribution
 The Gaussian distribution Probability density function: A continuous probability density function, px), satisfies the following properties:. The probability that x is between two points a and b b P a
The Gaussian distribution Probability density function: A continuous probability density function, px), satisfies the following properties:. The probability that x is between two points a and b b P a
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Parametric Techniques
 Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
Consistency of Nearest Neighbor Methods
 E0 370 Statistical Learning Theory Lecture 16 Oct 25, 2011 Consistency of Nearest Neighbor Methods Lecturer: Shivani Agarwal Scribe: Arun Rajkumar 1 Introduction In this lecture we return to the study
E0 370 Statistical Learning Theory Lecture 16 Oct 25, 2011 Consistency of Nearest Neighbor Methods Lecturer: Shivani Agarwal Scribe: Arun Rajkumar 1 Introduction In this lecture we return to the study
Outline. Supervised Learning. Hong Chang. Institute of Computing Technology, Chinese Academy of Sciences. Machine Learning Methods (Fall 2012)
") Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Statistical Learning Reading Assignments
 Statistical Learning Reading Assignments S. Gong et al. Dynamic Vision: From Images to Face Recognition, Imperial College Press, 2001 (Chapt. 3, hard copy). T. Evgeniou, M. Pontil, and T. Poggio, "Statistical
Statistical Learning Reading Assignments S. Gong et al. Dynamic Vision: From Images to Face Recognition, Imperial College Press, 2001 (Chapt. 3, hard copy). T. Evgeniou, M. Pontil, and T. Poggio, "Statistical
Bayes Classifiers. CAP5610 Machine Learning Instructor: Guo-Jun QI
 Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
Machine Learning & SVM
 Machine Learning & SVM Shannon "Information is any difference that makes a difference. Bateman " It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible
Machine Learning & SVM Shannon "Information is any difference that makes a difference. Bateman " It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible
Metric-based classifiers. Nuno Vasconcelos UCSD
 Metric-based classifiers Nuno Vasconcelos UCSD Statistical learning goal: given a function f. y f and a collection of eample data-points, learn what the function f. is. this is called training. two major
Metric-based classifiers Nuno Vasconcelos UCSD Statistical learning goal: given a function f. y f and a collection of eample data-points, learn what the function f. is. this is called training. two major
LECTURE NOTE #3 PROF. ALAN YUILLE
 LECTURE NOTE #3 PROF. ALAN YUILLE 1. Three Topics (1) Precision and Recall Curves. Receiver Operating Characteristic Curves (ROC). What to do if we do not fix the loss function? (2) The Curse of Dimensionality.
LECTURE NOTE #3 PROF. ALAN YUILLE 1. Three Topics (1) Precision and Recall Curves. Receiver Operating Characteristic Curves (ROC). What to do if we do not fix the loss function? (2) The Curse of Dimensionality.
Pattern Recognition. Parameter Estimation of Probability Density Functions
 Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
Machine Learning. Kernels. Fall (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang. (Chap. 12 of CIML)
 Professor Liang Huang. (Chap. 12 of CIML)") Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Parametric Techniques Lecture 3
 Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Statistical learning. Chapter 20, Sections 1 4 1
 Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
DATA MINING LECTURE 10
 DATA MINING LECTURE 10 Classification Nearest Neighbor Classification Support Vector Machines Logistic Regression Naïve Bayes Classifier Supervised Learning 10 10 Illustrating Classification Task Tid Attrib1
DATA MINING LECTURE 10 Classification Nearest Neighbor Classification Support Vector Machines Logistic Regression Naïve Bayes Classifier Supervised Learning 10 10 Illustrating Classification Task Tid Attrib1
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Support Vector Machine & Its Applications
 Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
CS-E3210 Machine Learning: Basic Principles
 CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
Maximum Likelihood Estimation. only training data is available to design a classifier
 Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW2 due now! Project proposal due on tomorrow Midterm next lecture! HW3 posted Last time Linear Regression Parametric vs Nonparametric
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW2 due now! Project proposal due on tomorrow Midterm next lecture! HW3 posted Last time Linear Regression Parametric vs Nonparametric
Sparse Kernel Machines - SVM
 Sparse Kernel Machines - SVM Henrik I. Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I. Christensen (RIM@GT) Support
Sparse Kernel Machines - SVM Henrik I. Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I. Christensen (RIM@GT) Support