Curve Fitting Re-visited, Bishop1.2.5
|
|
|
- Edward Hector Lynch
- 5 years ago
- Views:
Transcription
1 Curve Fitting Re-visited, Bishop1.2.5
2 Maximum Likelihood Bishop Model Likelihood differentiation
3 p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the simple Gaussian distribution earlier, it is convenient to maximize the logarithm of the likelihood function. Substituting for the form of the Gaussian distribution, given by (1.46), we obtain the log likelihood function in the form ln p(t x, w, β) = β N {y(x n, w) t n } 2 + N 2 2 ln β N ln(2π). (1.62) 2 n=1 Consider first the determination of the maximum likelihood solution for the polyno- 1 = 1 N {y(x n, w ML ) t n } 2. (1.63) β ML N n=1 Giving estimates of W and beta, we can predict p(t x, w ML, β ML )=N ( t y(x, w ML ), β 1 ML). (1.64) ke a step towards a more Bayesian approach and introduce a prior
4 Predictive Distribution


5 MAP: A Step towards Bayes Determine by minimizing regularized sum-of-squares error,. Regularized sum of squares

6 Important quantity in coding theory statistical physics machine learning Entropy 1.6



7 Differential Entropy Put bins of width along the real line For fixed differential entropy maximized when in which case


8 The Kullback-Leibler Divergence P true distribution, q is approximating distribution
9 Inference step Decision Theory Determine either or. Decision step For given x, determine optimal t.
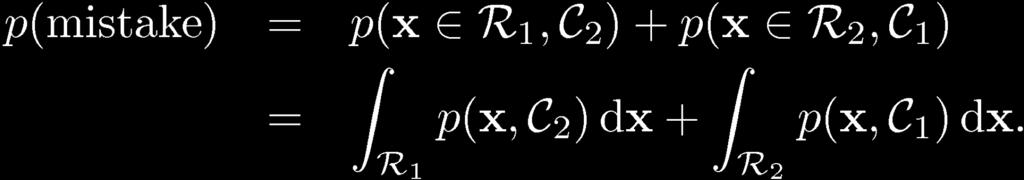
10 Minimum Misclassification Rate
11 Mixtures of Gaussians (Bishop 2.3.9) Old Faithful geyser: The time between eruptions has a bimodal distribution, with the mean interval being either 65 or 91 minutes, and is dependent on the length of the prior eruption. Within a margin of error of ±10 minutes, Old Faithful will erupt either 65 minutes after an eruption lasting less than minutes, or 91 minutes after an eruption lasting more than minutes. Single Gaussian Mixture of two Gaussians


12 Mixtures of Gaussians (Bishop 2.3.9) Combine simple models into a complex model: Component Mixing coefficient K=3

13 Mixtures of Gaussians (Bishop 2.3.9)
 Determining parameters p, µ, and S using maximum log likelihood Log of a sum; no closed form maximum.")
14 Mixtures of Gaussians (Bishop 2.3.9) Determining parameters p, µ, and S using maximum log likelihood Log of a sum; no closed form maximum. Solution: use standard, iterative, numeric optimization methods or the expectation maximization algorithm (Chapter 9).
15 Homework



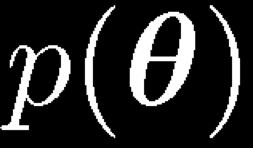

16 Basic building blocks: Need to determine given Representation: or? Parametric Distributions Recall Curve Fitting We focus on Gaussians!
17 The Gaussian Distribution


18 Central Limit Theorem The distribution of the sum of N i.i.d. random variables becomes increasingly Gaussian as N grows. Example: N uniform [0,1] random variables.

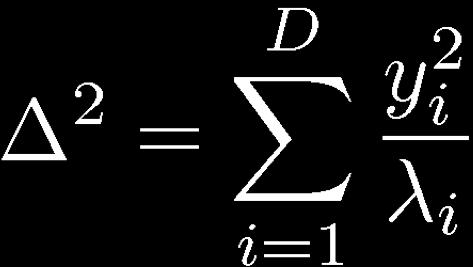
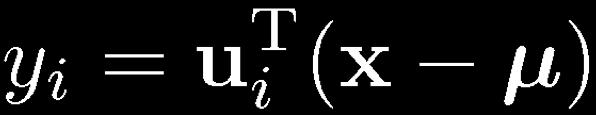
19 Geometry of the Multivariate Gaussian
20 Moments of the Multivariate Gaussian (2) A Gaussian requires D*(D-1)/2 +D parameters. Often we use D +D or Just D+1 parameters.
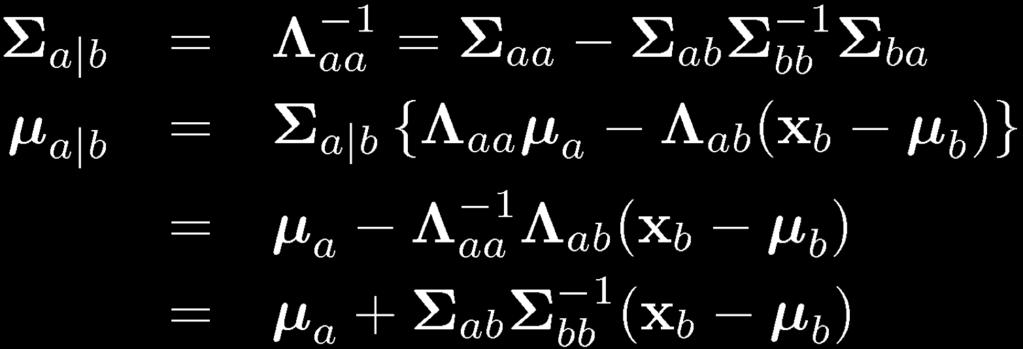
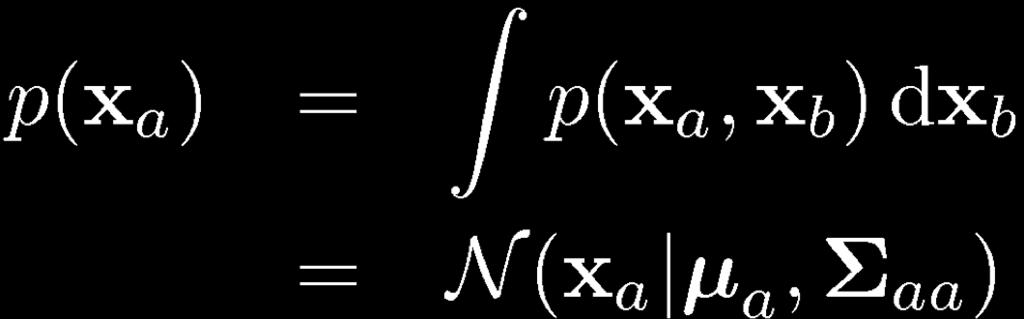
21 Partitioned Conditionals and Marginals, page 89
, the log likelihood function is given by ( ) ( ) A ln")
22 Given i.i.d. data Maximum Likelihood for the Gaussian (1), the log likelihood function is given by ( ) ( ) A ln A = ( A 1) T 2) and (C.26). A Tr (AB) =BT. ( ) A 1 1 A = A x x A 1 (C.28) (C.24) (C.21)
 Set the derivative")

23 Maximum Likelihood for the Gaussian (2) Set the derivative of the log likelihood function to zero, and solve to obtain Similarly

24 Bayes Theorem for Gaussian Variables Given we have where

25 Sequential Estimation Contribution of the N th data point, x N correction given x N correction weight old estimate

26 Bayesian Inference for the Gaussian (1) Assume s 2 is known. Given i.i.d. data the likelihood function for µ is given by This has a Gaussian shape as a function of µ (but it is not a distribution over µ).
 Combined with a Gaussian prior")

27 Bayesian Inference for the Gaussian (2) Combined with a Gaussian prior over µ, this gives the posterior Completing the square over µ, we see that
28 Bayesian Inference for the Gaussian (4) Example: for N = 0, 1, 2 and 10. Prior

29 Bayesian Inference for the Gaussian (5) Sequential Estimation The posterior obtained after observing N { 1 data points becomes the prior when we observe the N th data point.
30 NON PARAMETRIC
31 Nonparametric Methods (1) Parametric distribution models are restricted to specific forms, which may not always be suitable; for example, consider modelling a multimodal distribution with a single, unimodal model. Nonparametric approaches make few assumptions about the overall shape of the distribution being modelled parameter versus 10 parameter


32 Nonparametric Methods (2) Histogram methods partition the data space into distinct bins with widths i and count the number of observations, n i, in each bin. Often, the same width is used for all bins, D i = D. D acts as a smoothing parameter. In a D-dimensional space, using M bins in each dimension will require M D bins!
 and consider a small region R containing x")
 is approximately constant over R and Thus The")
 and if N is large V small, yet K>0, therefore")
33 Nonparametric Methods (3) Assume observations drawn from a density p(x) and consider a small region R containing x such that If the volume of R, V, is sufficiently small, p(x) is approximately constant over R and Thus The probability that K out of N observations lie inside R is Bin(KjN,P ) and if N is large V small, yet K>0, therefore N large?

 It follows")
34 Nonparametric Methods (4) Kernel Density Estimation: fix V, estimate K from the data. Let R be a hypercube centred on x and define the kernel function (Parzen window) It follows that and hence
, use a smooth")

35 Nonparametric Methods (5) To avoid discontinuities in p(x), use a smooth kernel, e.g. a Gaussian Any kernel such that will work. h acts as a smoother.


36 Nonparametric Methods (6) Nearest Neighbour Density Estimation: fix K, estimate V from the data. Consider a hypersphere centred on x and let it grow to a volume, V?, that includes K of the given N data points. Then K acts as a smoother.
37 Nonparametric Methods (7) Nonparametric models (not histograms) requires storing and computing with the entire data set. Parametric models, once fitted, are much more efficient in terms of storage and computation.
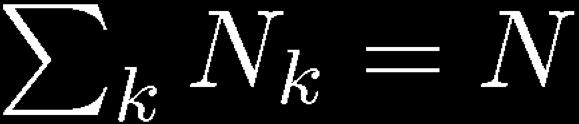
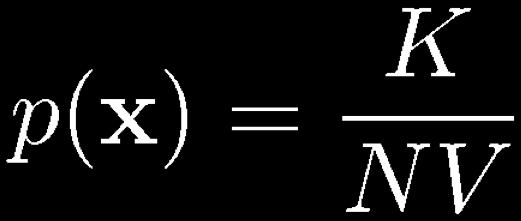
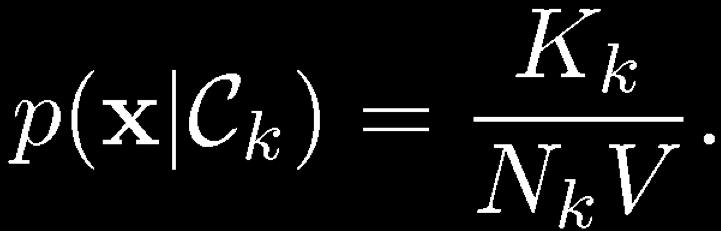
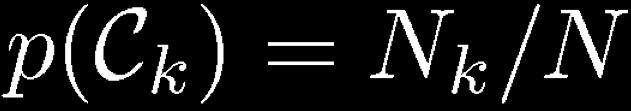
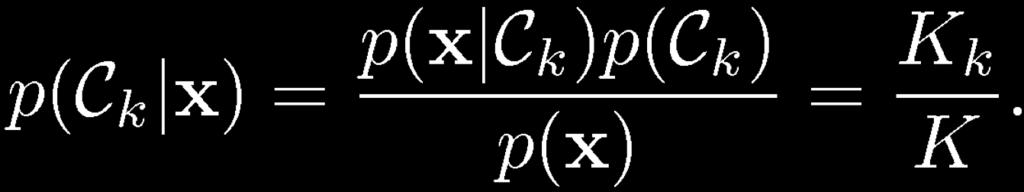
38 K-Nearest-Neighbours for Classification (1) Given a data set with N k data points from class C k and, we have and correspondingly Since, Bayes theorem gives
39 K-Nearest-Neighbours for Classification (2) K = 3 K = 1


40 K-Nearest-Neighbours for Classification (3) K acts as a smother For, the error rate of the 1-nearest-neighbour classifier is never more than twice the optimal error (obtained from the true conditional class distributions).
41 OLD

42 Bayesian Inference for the Gaussian (6) Now assume µ is known. The likelihood function for l=1/s 2 is given by This has a Gamma shape as a function of l. The Gamma distribution:
 Now we combine a Gamma prior,,")

43 Bayesian Inference for the Gaussian (8) Now we combine a Gamma prior,, with the likelihood function for l to obtain which we recognize as with

44 Bayesian Inference for the Gaussian (9) If both µ and l are unknown, the joint likelihood function is given by We need a prior with the same functional dependence on µ and l.

45 Bayesian Inference for the Gaussian (10) The Gaussian-gamma distribution Quadratic in µ. Linear in l. Gamma distribution over l. Independent of µ. µ 0 =0, b=2, a=5, b=6
46 Bayesian Inference for the Gaussian (12) Multivariate conjugate priors µ unknown, L known: p(µ) Gaussian. L unknown, µ known: p(l) Wishart, L and µ unknown: p(µ, L) Gaussian-Wishart,
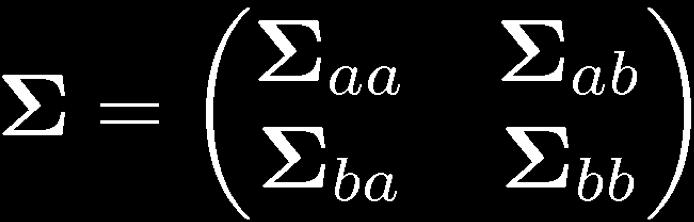
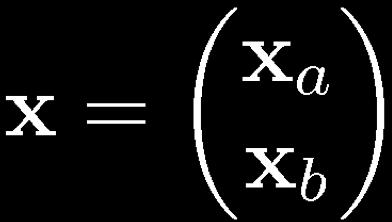
47 Partitioned Gaussian Distributions


48 Maximum Likelihood for the Gaussian (3) Under the true distribution Hence define


49 Moments of the Multivariate Gaussian (1) thanks to anti-symmetry of z
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
ECE285/SIO209, Machine learning for physical applications, Spring 2017
 ECE285/SIO209, Machine learning for physical applications, Spring 2017 Peter Gerstoft, 534-7768, gerstoft@ucsd.edu We meet Wednesday from 5 to 6:20pm in Spies Hall 330 Text Bishop Grading A or maybe S
ECE285/SIO209, Machine learning for physical applications, Spring 2017 Peter Gerstoft, 534-7768, gerstoft@ucsd.edu We meet Wednesday from 5 to 6:20pm in Spies Hall 330 Text Bishop Grading A or maybe S
PROBABILITY DISTRIBUTIONS. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
BAYESIAN DECISION THEORY
 Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Machine Learning. Nonparametric Methods. Space of ML Problems. Todo. Histograms. Instance-Based Learning (aka non-parametric methods)
") Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Machine Learning Lecture 3
 Announcements Machine Learning Lecture 3 Eam dates We re in the process of fiing the first eam date Probability Density Estimation II 9.0.207 Eercises The first eercise sheet is available on L2P now First
Announcements Machine Learning Lecture 3 Eam dates We re in the process of fiing the first eam date Probability Density Estimation II 9.0.207 Eercises The first eercise sheet is available on L2P now First
Maximum Likelihood Estimation. only training data is available to design a classifier
 Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Non-parametric Methods
 Non-parametric Methods Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 2 of Pattern Recognition and Machine Learning by Bishop (with an emphasis on section 2.5) Möller/Mori 2 Outline Last
Non-parametric Methods Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 2 of Pattern Recognition and Machine Learning by Bishop (with an emphasis on section 2.5) Möller/Mori 2 Outline Last
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
IEOR E4570: Machine Learning for OR&FE Spring 2015 c 2015 by Martin Haugh. The EM Algorithm
 IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Pattern Recognition and Machine Learning. Bishop Chapter 2: Probability Distributions
 Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Non-parametric Methods
 Non-parametric Methods Machine Learning Alireza Ghane Non-Parametric Methods Alireza Ghane / Torsten Möller 1 Outline Machine Learning: What, Why, and How? Curve Fitting: (e.g.) Regression and Model Selection
Non-parametric Methods Machine Learning Alireza Ghane Non-Parametric Methods Alireza Ghane / Torsten Möller 1 Outline Machine Learning: What, Why, and How? Curve Fitting: (e.g.) Regression and Model Selection
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Nonparametric Methods Lecture 5
 Nonparametric Methods Lecture 5 Jason Corso SUNY at Buffalo 17 Feb. 29 J. Corso (SUNY at Buffalo) Nonparametric Methods Lecture 5 17 Feb. 29 1 / 49 Nonparametric Methods Lecture 5 Overview Previously,
Nonparametric Methods Lecture 5 Jason Corso SUNY at Buffalo 17 Feb. 29 J. Corso (SUNY at Buffalo) Nonparametric Methods Lecture 5 17 Feb. 29 1 / 49 Nonparametric Methods Lecture 5 Overview Previously,
Variational Inference. Sargur Srihari
 Variational Inference Sargur srihari@cedar.buffalo.edu 1 Plan of Discussion Functionals Calculus of Variations Maximizing a Functional Finding Approximation to a Posterior Minimizing K-L divergence Factorized
Variational Inference Sargur srihari@cedar.buffalo.edu 1 Plan of Discussion Functionals Calculus of Variations Maximizing a Functional Finding Approximation to a Posterior Minimizing K-L divergence Factorized
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
BAYESIAN DECISION THEORY. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 BAYESIAN DECISION THEORY Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis, University of Athens
BAYESIAN DECISION THEORY Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis, University of Athens
Statistical and Learning Techniques in Computer Vision Lecture 2: Maximum Likelihood and Bayesian Estimation Jens Rittscher and Chuck Stewart
 Statistical and Learning Techniques in Computer Vision Lecture 2: Maximum Likelihood and Bayesian Estimation Jens Rittscher and Chuck Stewart 1 Motivation and Problem In Lecture 1 we briefly saw how histograms
Statistical and Learning Techniques in Computer Vision Lecture 2: Maximum Likelihood and Bayesian Estimation Jens Rittscher and Chuck Stewart 1 Motivation and Problem In Lecture 1 we briefly saw how histograms
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Machine Learning Overview
 Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Quantitative Biology II Lecture 4: Variational Methods
 10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
Density Estimation: ML, MAP, Bayesian estimation
 Density Estimation: ML, MAP, Bayesian estimation CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Maximum-Likelihood Estimation Maximum
Density Estimation: ML, MAP, Bayesian estimation CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Maximum-Likelihood Estimation Maximum
Expectation Propagation for Approximate Bayesian Inference
 Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
COM336: Neural Computing
 COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Variational Mixture of Gaussians. Sargur Srihari
 Variational Mixture of Gaussians Sargur srihari@cedar.buffalo.edu 1 Objective Apply variational inference machinery to Gaussian Mixture Models Demonstrates how Bayesian treatment elegantly resolves difficulties
Variational Mixture of Gaussians Sargur srihari@cedar.buffalo.edu 1 Objective Apply variational inference machinery to Gaussian Mixture Models Demonstrates how Bayesian treatment elegantly resolves difficulties
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Machine Learning Lecture Notes
 Machine Learning Lecture Notes Predrag Radivojac January 25, 205 Basic Principles of Parameter Estimation In probabilistic modeling, we are typically presented with a set of observations and the objective
Machine Learning Lecture Notes Predrag Radivojac January 25, 205 Basic Principles of Parameter Estimation In probabilistic modeling, we are typically presented with a set of observations and the objective
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Probability Models for Bayesian Recognition
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG / osig Second Semester 06/07 Lesson 9 0 arch 07 Probability odels for Bayesian Recognition Notation... Supervised Learning for Bayesian
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG / osig Second Semester 06/07 Lesson 9 0 arch 07 Probability odels for Bayesian Recognition Notation... Supervised Learning for Bayesian
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Lecture 4: Probabilistic Learning
 DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA. Sistemi di Elaborazione dell Informazione. Regressione. Ruggero Donida Labati
 SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA Sistemi di Elaborazione dell Informazione Regressione Ruggero Donida Labati Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy http://homes.di.unimi.it/donida
SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA Sistemi di Elaborazione dell Informazione Regressione Ruggero Donida Labati Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy http://homes.di.unimi.it/donida
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
Learning Bayesian network : Given structure and completely observed data
 Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Nonparametric probability density estimation
 A temporary version for the 2018-04-11 lecture. Nonparametric probability density estimation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics
A temporary version for the 2018-04-11 lecture. Nonparametric probability density estimation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Foundations of Nonparametric Bayesian Methods
 1 / 27 Foundations of Nonparametric Bayesian Methods Part II: Models on the Simplex Peter Orbanz http://mlg.eng.cam.ac.uk/porbanz/npb-tutorial.html 2 / 27 Tutorial Overview Part I: Basics Part II: Models
1 / 27 Foundations of Nonparametric Bayesian Methods Part II: Models on the Simplex Peter Orbanz http://mlg.eng.cam.ac.uk/porbanz/npb-tutorial.html 2 / 27 Tutorial Overview Part I: Basics Part II: Models
Hypothesis Testing with the Bootstrap. Noa Haas Statistics M.Sc. Seminar, Spring 2017 Bootstrap and Resampling Methods
 Hypothesis Testing with the Bootstrap Noa Haas Statistics M.Sc. Seminar, Spring 2017 Bootstrap and Resampling Methods Bootstrap Hypothesis Testing A bootstrap hypothesis test starts with a test statistic
Hypothesis Testing with the Bootstrap Noa Haas Statistics M.Sc. Seminar, Spring 2017 Bootstrap and Resampling Methods Bootstrap Hypothesis Testing A bootstrap hypothesis test starts with a test statistic
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Gaussian Processes. Le Song. Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012
 Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Linear Regression and Discrimination
 Linear Regression and Discrimination Kernel-based Learning Methods Christian Igel Institut für Neuroinformatik Ruhr-Universität Bochum, Germany http://www.neuroinformatik.rub.de July 16, 2009 Christian
Linear Regression and Discrimination Kernel-based Learning Methods Christian Igel Institut für Neuroinformatik Ruhr-Universität Bochum, Germany http://www.neuroinformatik.rub.de July 16, 2009 Christian
Computer Vision Group Prof. Daniel Cremers. 3. Regression
 Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Parametric Techniques Lecture 3
 Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
The classifier. Theorem. where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know
 The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The classifier. Linear discriminant analysis (LDA) Example. Challenges for LDA
 Example. Challenges for LDA") The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
Machine Learning Linear Classification. Prof. Matteo Matteucci
 Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Chapter 3: Maximum-Likelihood & Bayesian Parameter Estimation (part 1)
") HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
Machine Learning using Bayesian Approaches
 Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Parametric Techniques
 Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory
 Bayesian Inference Statistical Decison Theory") Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP
 INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP Personal Healthcare Revolution Electronic health records (CFH) Personal genomics (DeCode, Navigenics, 23andMe) X-prize: first $10k human genome technology
INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP Personal Healthcare Revolution Electronic health records (CFH) Personal genomics (DeCode, Navigenics, 23andMe) X-prize: first $10k human genome technology
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
probability of k samples out of J fall in R.
 Nonparametric Techniques for Density Estimation (DHS Ch. 4) n Introduction n Estimation Procedure n Parzen Window Estimation n Parzen Window Example n K n -Nearest Neighbor Estimation Introduction Suppose
Nonparametric Techniques for Density Estimation (DHS Ch. 4) n Introduction n Estimation Procedure n Parzen Window Estimation n Parzen Window Example n K n -Nearest Neighbor Estimation Introduction Suppose
Advanced statistical methods for data analysis Lecture 2
 Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
p L yi z n m x N n xi
 y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
Lecture 9: PGM Learning
 13 Oct 2014 Intro. to Stats. Machine Learning COMP SCI 4401/7401 Table of Contents I Learning parameters in MRFs 1 Learning parameters in MRFs Inference and Learning Given parameters (of potentials) and
13 Oct 2014 Intro. to Stats. Machine Learning COMP SCI 4401/7401 Table of Contents I Learning parameters in MRFs 1 Learning parameters in MRFs Inference and Learning Given parameters (of potentials) and
PROBABILITY DISTRIBUTIONS Nonparametric Methods
 120 2. PROBABILITY DISTRIBUTIONS An example of a scale parameter would be the standard deviation cr of a Gaussian distribution, after we have taken account of the location parameter J.L, because (2.240)
120 2. PROBABILITY DISTRIBUTIONS An example of a scale parameter would be the standard deviation cr of a Gaussian distribution, after we have taken account of the location parameter J.L, because (2.240)
Bayes Classifiers. CAP5610 Machine Learning Instructor: Guo-Jun QI
 Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
INTRODUCTION TO PATTERN RECOGNITION
 INTRODUCTION TO PATTERN RECOGNITION INSTRUCTOR: WEI DING 1 Pattern Recognition Automatic discovery of regularities in data through the use of computer algorithms With the use of these regularities to take
INTRODUCTION TO PATTERN RECOGNITION INSTRUCTOR: WEI DING 1 Pattern Recognition Automatic discovery of regularities in data through the use of computer algorithms With the use of these regularities to take
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 305 Part VII
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 305 Part VII
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Machine Learning for Signal Processing Bayes Classification
 Machine Learning for Signal Processing Bayes Classification Class 16. 24 Oct 2017 Instructor: Bhiksha Raj - Abelino Jimenez 11755/18797 1 Recap: KNN A very effective and simple way of performing classification
Machine Learning for Signal Processing Bayes Classification Class 16. 24 Oct 2017 Instructor: Bhiksha Raj - Abelino Jimenez 11755/18797 1 Recap: KNN A very effective and simple way of performing classification
Linear Models for Regression
 Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
Supervised Learning: Non-parametric Estimation
 Supervised Learning: Non-parametric Estimation Edmondo Trentin March 18, 2018 Non-parametric Estimates No assumptions are made on the form of the pdfs 1. There are 3 major instances of non-parametric estimates:
Supervised Learning: Non-parametric Estimation Edmondo Trentin March 18, 2018 Non-parametric Estimates No assumptions are made on the form of the pdfs 1. There are 3 major instances of non-parametric estimates: