Machine Learning Techniques for Computer Vision
|
|
|
- Ronald Newton
- 6 years ago
- Views:
Transcription
1 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x ECCV 2004, Prague x 2 x 1
2 Overview of Part 2 Mixture models EM Variational Inference Bayesian model complexity Continuous latent variables
3 The Gaussian Distribution Multivariate Gaussian mean covariance Maximum likelihood
4 Gaussian Mixtures Linear super-position of Gaussians Normalization and positivity require
 0 0 0.5 1 (b)")
5 Example: Mixture of 3 Gaussians (a) (b)
6 Maximum Likelihood for the GMM Log likelihood function Sum over components appears inside the log no closed form ML solution
7 EM Algorithm Informal Derivation
8 EM Algorithm Informal Derivation M step equations
9 EM Algorithm Informal Derivation E step equation
10 EM Algorithm Informal Derivation Can interpret the mixing coefficients as prior probabilities Corresponding posterior probabilities (responsibilities)
 Duration of eruption")
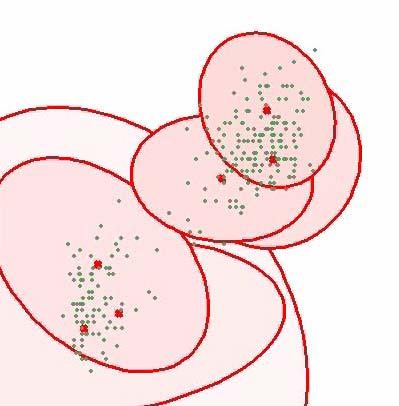
11 Old Faithful Data Set Time between eruptions (minutes) Duration of eruption (minutes)
12
13
14
15
16
17
18 Latent Variable View of EM To sample from a Gaussian mixture: first pick one of the components with probability then draw a sample from that component repeat these two steps for each new data point (a)
19 Latent Variable View of EM Goal: given a data set, find Suppose we knew the colours maximum likelihood would involve fitting each component to the corresponding cluster Problem: the colours are latent (hidden) variables
20 Incomplete and Complete Data (b) incomplete (a) complete
21 Latent Variable Viewpoint
22 Latent Variable Viewpoint Binary latent variables describing which component generated each data point Conditional distribution of observed variable Z Prior distribution of latent variables X Marginalizing over the latent variables we obtain
23 Graphical Representation of GMM z n x n N
24 Latent Variable View of EM Suppose we knew the values for the latent variables maximize the complete-data log likelihood trivial closed-form solution: fit each component to the corresponding set of data points We don t know the values of the latent variables however, for given parameter values we can compute the expected values of the latent variables
25 Posterior Probabilities (colour coded) (b) (a)
26 Over-fitting in Gaussian Mixture Models Infinities in likelihood function when a component collapses onto a data point: with Also, maximum likelihood cannot determine the number K of components
27 Cross Validation Can select model complexity using an independent validation data set If data is scarce use cross-validation: partition data into S subsets train on S 1 subsets test on remainder repeat and average Disadvantages computationally expensive can only determine one or two complexity parameters
28 Bayesian Mixture of Gaussians Parameters and latent variables appear on equal footing Conjugate priors z n x n N
29 Data Set Size Problem 1: learn the function for from 100 (slightly) noisy examples data set is computationally small but statistically large Problem 2: learn to recognize 1,000 everyday objects from 5,000,000 natural images data set is computationally large but statistically small Bayesian inference computationally more demanding than ML or MAP (but see discussion of Gaussian mixtures later) significant benefit for statistically small data sets
30 Variational Inference Exact Bayesian inference intractable Markov chain Monte Carlo computationally expensive issues of convergence Variational Inference broadly applicable deterministic approximation let denote all latent variables and parameters approximate true posterior using a simpler distribution minimize Kullback-Leibler divergence
31 General View of Variational Inference For arbitrary where Maximizing over would give the true posterior this is intractable by definition
32 Variational Lower Bound
33 Factorized Approximation Goal: choose a family of q distributions which are: sufficiently flexible to give good approximation sufficiently simple to remain tractable Here we consider factorized distributions No further assumptions are required! Optimal solution for one factor, keeping the remainder fixed coupled solutions so initialize then cyclically update message passing view (Winn and Bishop, 2004)
34 1 x x 1 (a) 1
35 Lower Bound Can also be evaluated Useful for maths/code verification Also useful for model comparison:
36 Illustration: Univariate Gaussian Likelihood function Conjugate prior Factorized variational distribution
37 Initial Configuration 2 (a) τ µ 1
38 After Updating 2 (b) τ µ 1
39 After Updating 2 (c) τ µ 1
40 Converged Solution 2 (d) τ µ 1
41 Variational Mixture of Gaussians Assume factorized posterior distribution No other approximations needed!
42 Variational Equations for GMM
43 Lower Bound for GMM

44 VIBES Bishop, Spiegelhalter and Winn (2002)
45 ML Limit If instead we choose we recover the maximum likelihood EM algorithm
46 Bound vs. K for Old Faithful Data
47 Bayesian Model Complexity
48 Sparse Bayes for Gaussian Mixture Corduneanu and Bishop (2001) Start with large value of K treat mixing coefficients as parameters maximize marginal likelihood prunes out excess components
49

50
51 Summary: Variational Gaussian Mixtures Simple modification of maximum likelihood EM code Small computational overhead compared to EM No singularities Automatic model order selection
52 Continuous Latent Variables Conventional PCA data covariance matrix eigenvector decomposition x 2 x n ~xn ~ xn u 1 Minimizes sum-of-squares projection not a probabilistic model how should we choose L? x 1
53 Probabilistic PCA Tipping and Bishop (1998) L dimensional continuous latent space D dimensional data space x 2 PCA factor analysis w { z x 1
54 Probabilistic PCA Marginal distribution z n Advantages x n N exact ML solution computationally efficient EM algorithm captures dominant correlations with few parameters mixtures of PPCA Bayesian PCA building block for more complex models W
55 EM for PCA 2 (a)
56 EM for PCA 2 (b)
57 EM for PCA 2 (c)
58 EM for PCA 2 (d)
59 EM for PCA 2 (e)
60 EM for PCA 2 (f)
61 EM for PCA 2 (g)

 z n N W x n")
62 Bayesian PCA Bishop (1998) Gaussian prior over columns of Automatic relevance determination (ARD) z n N W x n ML PCA Bayesian PCA

63 Non-linear Manifolds Example: images of a rigid object x 3 x 1 x 2
64 Bayesian Mixture of BPCA Models W m s n x n z nm N m M
65
66 Flexible Sprites Jojic and Frey (2001) Automatic decomposition of video sequence into background model ordered set of masks (one per object per frame) foreground model (one per object per frame)

67
68 Transformed Component Analysis Generative model Now include transformations (translations) Extend to L layers s l m l Inference intractable so use variational framework T nl L x n N

69

")


70 Bayesian Constellation Model Li, Fergus and Perona (2003) Object recognition from small training sets Variational treatment of fully Bayesian model
71 Bayesian Constellation Model
72 Summary of Part 2 Discrete and continuous latent variables EM algorithm Build complex models from simple components represented graphically incorporates prior knowledge Variational inference Bayesian model comparison
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
p L yi z n m x N n xi
 y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Variational Principal Components
 Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
VIBES: A Variational Inference Engine for Bayesian Networks
 VIBES: A Variational Inference Engine for Bayesian Networks Christopher M. Bishop Microsoft Research Cambridge, CB3 0FB, U.K. research.microsoft.com/ cmbishop David Spiegelhalter MRC Biostatistics Unit
VIBES: A Variational Inference Engine for Bayesian Networks Christopher M. Bishop Microsoft Research Cambridge, CB3 0FB, U.K. research.microsoft.com/ cmbishop David Spiegelhalter MRC Biostatistics Unit
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Variational Message Passing. By John Winn, Christopher M. Bishop Presented by Andy Miller
 Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
Lecture 10. Announcement. Mixture Models II. Topics of This Lecture. This Lecture: Advanced Machine Learning. Recap: GMMs as Latent Variable Models
 Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Curve Fitting Re-visited, Bishop1.2.5
 Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Variational Autoencoders
 Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Sparse Gaussian Markov Random Field Mixtures for Anomaly Detection
 Sparse Gaussian Markov Random Field Mixtures for Anomaly Detection Tsuyoshi Idé ( Ide-san ), Ankush Khandelwal*, Jayant Kalagnanam IBM Research, T. J. Watson Research Center (*Currently with University
Sparse Gaussian Markov Random Field Mixtures for Anomaly Detection Tsuyoshi Idé ( Ide-san ), Ankush Khandelwal*, Jayant Kalagnanam IBM Research, T. J. Watson Research Center (*Currently with University
K-Means and Gaussian Mixture Models
 K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
PROBABILITY DISTRIBUTIONS. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
The Expectation-Maximization Algorithm
 1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures
 17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Non-linear Bayesian Image Modelling
 Non-linear Bayesian Image Modelling Christopher M. Bishop 1 and John M. Winn 2 1 Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/
Non-linear Bayesian Image Modelling Christopher M. Bishop 1 and John M. Winn 2 1 Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA
, Factor Analysis, Mixtures of PPCA") Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
The Particle Filter. PD Dr. Rudolph Triebel Computer Vision Group. Machine Learning for Computer Vision
 The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
Machine Learning Overview
 Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Introduction to Graphical Models
 Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Chris Bishop s PRML Ch. 8: Graphical Models
 Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
COURSE INTRODUCTION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 COURSE INTRODUCTION COMPUTATIONAL MODELING OF VISUAL PERCEPTION 2 The goal of this course is to provide a framework and computational tools for modeling visual inference, motivated by interesting examples
COURSE INTRODUCTION COMPUTATIONAL MODELING OF VISUAL PERCEPTION 2 The goal of this course is to provide a framework and computational tools for modeling visual inference, motivated by interesting examples
Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis
 Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture
Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Kyle Reing University of Southern California April 18, 2018
 Renormalization Group and Information Theory Kyle Reing University of Southern California April 18, 2018 Overview Renormalization Group Overview Information Theoretic Preliminaries Real Space Mutual Information
Renormalization Group and Information Theory Kyle Reing University of Southern California April 18, 2018 Overview Renormalization Group Overview Information Theoretic Preliminaries Real Space Mutual Information
Latent Variable Models and EM Algorithm
 SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Neural networks: Unsupervised learning
 Neural networks: Unsupervised learning 1 Previously The supervised learning paradigm: given example inputs x and target outputs t learning the mapping between them the trained network is supposed to give
Neural networks: Unsupervised learning 1 Previously The supervised learning paradigm: given example inputs x and target outputs t learning the mapping between them the trained network is supposed to give
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Generative models for missing value completion
 Generative models for missing value completion Kousuke Ariga Department of Computer Science and Engineering University of Washington Seattle, WA 98105 koar8470@cs.washington.edu Abstract Deep generative
Generative models for missing value completion Kousuke Ariga Department of Computer Science and Engineering University of Washington Seattle, WA 98105 koar8470@cs.washington.edu Abstract Deep generative
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Course 495: Advanced Statistical Machine Learning/Pattern Recognition
 Course 495: Advanced Statistical Machine Learning/Pattern Recognition Goal (Lecture): To present Probabilistic Principal Component Analysis (PPCA) using both Maximum Likelihood (ML) and Expectation Maximization
Course 495: Advanced Statistical Machine Learning/Pattern Recognition Goal (Lecture): To present Probabilistic Principal Component Analysis (PPCA) using both Maximum Likelihood (ML) and Expectation Maximization
Deep Learning Srihari. Deep Belief Nets. Sargur N. Srihari
 Deep Belief Nets Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines for continuous
Deep Belief Nets Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines for continuous
Lecture 6: Gaussian Mixture Models (GMM)
") Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
Expectation Propagation for Approximate Bayesian Inference
 Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Independent Component Analysis and Unsupervised Learning. Jen-Tzung Chien
 Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent voices Nonparametric likelihood
Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent voices Nonparametric likelihood
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Probability and Information Theory. Sargur N. Srihari
 Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Efficient Variational Inference in Large-Scale Bayesian Compressed Sensing
 Efficient Variational Inference in Large-Scale Bayesian Compressed Sensing George Papandreou and Alan Yuille Department of Statistics University of California, Los Angeles ICCV Workshop on Information
Efficient Variational Inference in Large-Scale Bayesian Compressed Sensing George Papandreou and Alan Yuille Department of Statistics University of California, Los Angeles ICCV Workshop on Information
CSC 2541: Bayesian Methods for Machine Learning
 CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 10 Alternatives to Monte Carlo Computation Since about 1990, Markov chain Monte Carlo has been the dominant
CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 10 Alternatives to Monte Carlo Computation Since about 1990, Markov chain Monte Carlo has been the dominant
Gaussian Mixture Models
 Gaussian Mixture Models David Rosenberg, Brett Bernstein New York University April 26, 2017 David Rosenberg, Brett Bernstein (New York University) DS-GA 1003 April 26, 2017 1 / 42 Intro Question Intro
Gaussian Mixture Models David Rosenberg, Brett Bernstein New York University April 26, 2017 David Rosenberg, Brett Bernstein (New York University) DS-GA 1003 April 26, 2017 1 / 42 Intro Question Intro
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Computer Vision Group Prof. Daniel Cremers. 6. Mixture Models and Expectation-Maximization
 Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
CS 6140: Machine Learning Spring 2017
 CS 6140: Machine Learning Spring 2017 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis@cs Assignment
CS 6140: Machine Learning Spring 2017 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis@cs Assignment
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Gaussian Mixture Models, Expectation Maximization
 Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Independent Component Analysis and Unsupervised Learning
 Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien National Cheng Kung University TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent
Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien National Cheng Kung University TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Variational inference
 Simon Leglaive Télécom ParisTech, CNRS LTCI, Université Paris Saclay November 18, 2016, Télécom ParisTech, Paris, France. Outline Introduction Probabilistic model Problem Log-likelihood decomposition EM
Simon Leglaive Télécom ParisTech, CNRS LTCI, Université Paris Saclay November 18, 2016, Télécom ParisTech, Paris, France. Outline Introduction Probabilistic model Problem Log-likelihood decomposition EM
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
Variational Autoencoder
 Variational Autoencoder Göker Erdo gan August 8, 2017 The variational autoencoder (VA) [1] is a nonlinear latent variable model with an efficient gradient-based training procedure based on variational
Variational Autoencoder Göker Erdo gan August 8, 2017 The variational autoencoder (VA) [1] is a nonlinear latent variable model with an efficient gradient-based training procedure based on variational
IEOR E4570: Machine Learning for OR&FE Spring 2015 c 2015 by Martin Haugh. The EM Algorithm
 IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
Statistical learning. Chapter 20, Sections 1 4 1
 Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Variational Learning : From exponential families to multilinear systems
 Variational Learning : From exponential families to multilinear systems Ananth Ranganathan th February 005 Abstract This note aims to give a general overview of variational inference on graphical models.
Variational Learning : From exponential families to multilinear systems Ananth Ranganathan th February 005 Abstract This note aims to give a general overview of variational inference on graphical models.
Variational Methods in Bayesian Deconvolution
 PHYSTAT, SLAC, Stanford, California, September 8-, Variational Methods in Bayesian Deconvolution K. Zarb Adami Cavendish Laboratory, University of Cambridge, UK This paper gives an introduction to the
PHYSTAT, SLAC, Stanford, California, September 8-, Variational Methods in Bayesian Deconvolution K. Zarb Adami Cavendish Laboratory, University of Cambridge, UK This paper gives an introduction to the
Lecture 21: Spectral Learning for Graphical Models
 10-708: Probabilistic Graphical Models 10-708, Spring 2016 Lecture 21: Spectral Learning for Graphical Models Lecturer: Eric P. Xing Scribes: Maruan Al-Shedivat, Wei-Cheng Chang, Frederick Liu 1 Motivation
10-708: Probabilistic Graphical Models 10-708, Spring 2016 Lecture 21: Spectral Learning for Graphical Models Lecturer: Eric P. Xing Scribes: Maruan Al-Shedivat, Wei-Cheng Chang, Frederick Liu 1 Motivation
Part 1: Expectation Propagation
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
ECE521 Tutorial 11. Topic Review. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides. ECE521 Tutorial 11 / 4
 ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
27 : Distributed Monte Carlo Markov Chain. 1 Recap of MCMC and Naive Parallel Gibbs Sampling
 10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
Least Absolute Shrinkage is Equivalent to Quadratic Penalization
 Least Absolute Shrinkage is Equivalent to Quadratic Penalization Yves Grandvalet Heudiasyc, UMR CNRS 6599, Université de Technologie de Compiègne, BP 20.529, 60205 Compiègne Cedex, France Yves.Grandvalet@hds.utc.fr
Least Absolute Shrinkage is Equivalent to Quadratic Penalization Yves Grandvalet Heudiasyc, UMR CNRS 6599, Université de Technologie de Compiègne, BP 20.529, 60205 Compiègne Cedex, France Yves.Grandvalet@hds.utc.fr
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
U-Likelihood and U-Updating Algorithms: Statistical Inference in Latent Variable Models
 U-Likelihood and U-Updating Algorithms: Statistical Inference in Latent Variable Models Jaemo Sung 1, Sung-Yang Bang 1, Seungjin Choi 1, and Zoubin Ghahramani 2 1 Department of Computer Science, POSTECH,
U-Likelihood and U-Updating Algorithms: Statistical Inference in Latent Variable Models Jaemo Sung 1, Sung-Yang Bang 1, Seungjin Choi 1, and Zoubin Ghahramani 2 1 Department of Computer Science, POSTECH,