PROBABILITY DISTRIBUTIONS. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
|
|
|
- Silas Webster
- 5 years ago
- Views:
Transcription
1 PROBABILITY DISTRIBUTIONS
2 Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK

3 Parametric Distributions 3 Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting

4 4 Binary Variables Coin flipping: heads=1, tails=0 Bernoulli Distribution
5 END OF LECTURE MON SEPT 20, 2010
6 Guidelines for Paper Presentations 6 Everyone should read the paper prior to the presentation and be prepared to discuss it. What is the objective? What tools from the course are being used? What did you not understand?
7 Guidelines for Paper Presentations 7 For the presenter: Your presentation should be around 10 minutes long no more than 15! (About 10 slides) What is the objective? What tools from the course are being used and how? What are the key ideas? What are the unsolved problems? Be prepared to answer questions from other students.


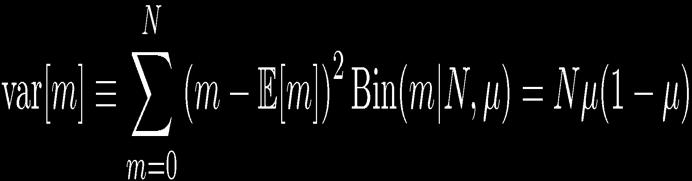
8 8 Binary Variables N coin flips: Binomial Distribution
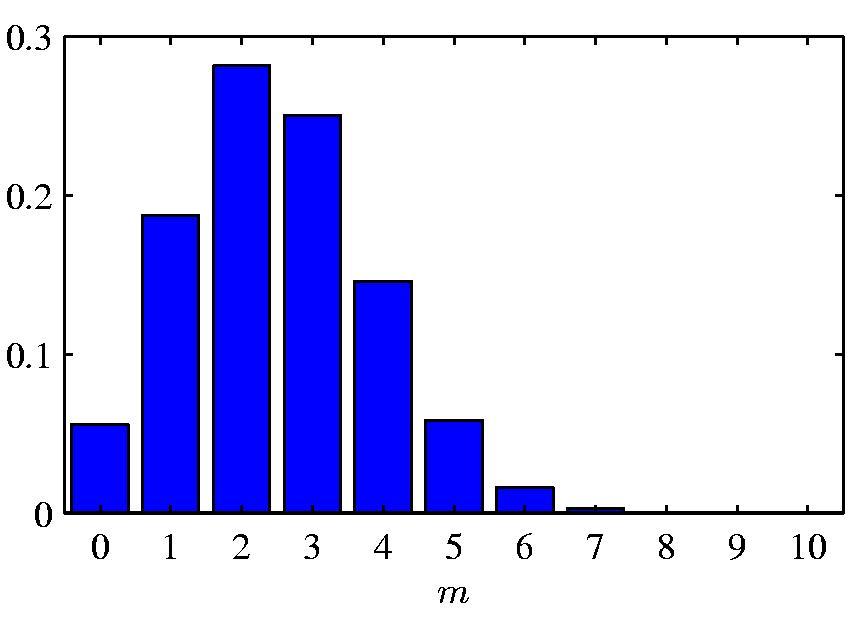
9 9 Binomial Distribution
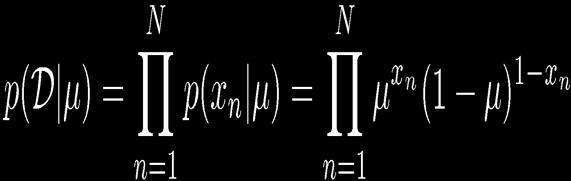
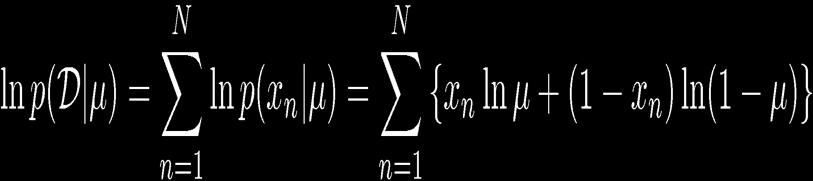
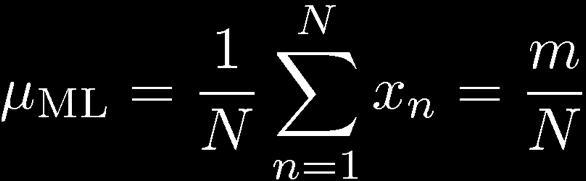
10 Parameter Estimation 10 ML for Bernoulli Given:

11 11 Parameter Estimation Example: Prediction: all future tosses will land heads up Overfitting to D
 = Note that 0 u x 1 e u du Γ(x + 1) = xγ(x) Γ(1) = 1 Γ(x +")
12 12 Beta Distribution Distribution over. where Γ(x) = Note that 0 u x 1 e u du Γ(x + 1) = xγ(x) Γ(1) = 1 Γ(x + 1) = x! when x is an integer.

13 13 Bayesian Bernoulli The Beta distribution provides the conjugate prior for the Bernoulli distribution.
14 14 Beta Distribution
15 15 Prior Likelihood = Posterior

16 16 Properties of the Posterior As the size N of the data set increases
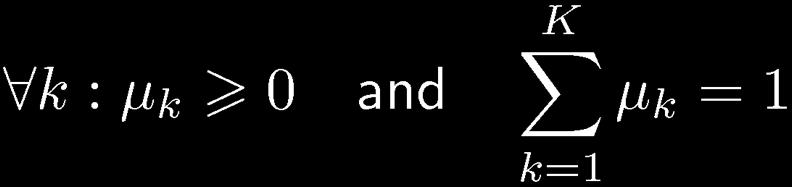
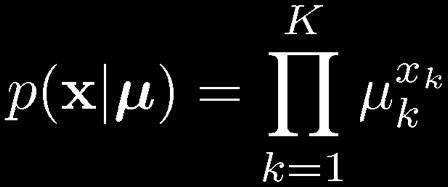
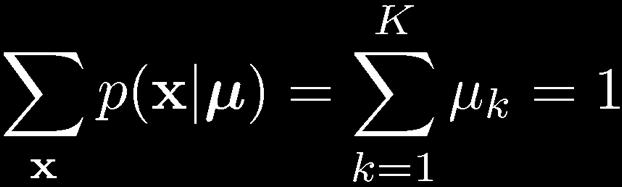
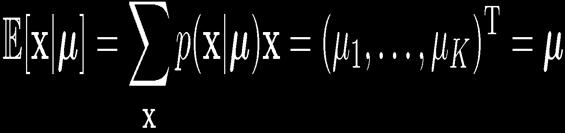
17 17 Multinomial Variables 1-of-K coding scheme:



18 18 ML Parameter estimation Given: To ensure, use a Lagrange multiplier, λ See Appendix E for a review of Lagrange multipliers.

19 19 The Multinomial Distribution,,, for j k where N m 1,m 2,,m K N! m 1!m 2!,m K!


20 20 The Dirichlet Distribution Since K µ k = 1 k =1 Conjugate prior for the multinomial distribution.

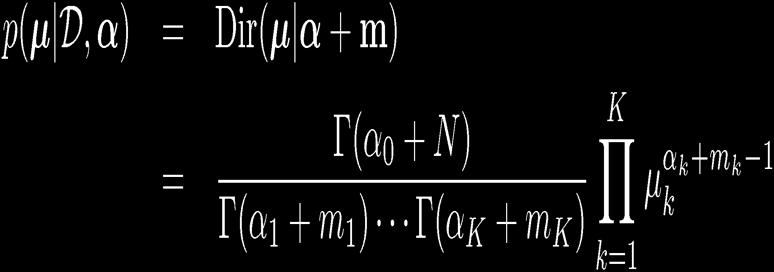
21 21 Bayesian Multinomial
22 22 Bayesian Multinomial

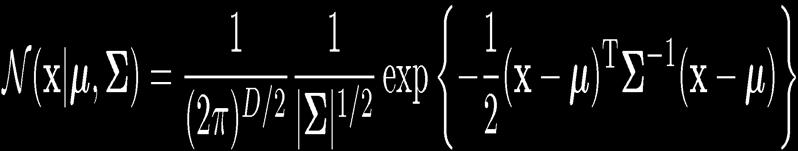
23 23 The Gaussian Distribution


24 Central Limit Theorem 24 The distribution of the sum of N i.i.d. random variables becomes increasingly Gaussian as N grows. Example: N uniform [0,1] random variables.
25 25 Geometry of the Multivariate Gaussian where Δ Mahalanobis distance from µ to x Eigenvector equation: Σu i = λ i u i where (u i,λ i ) are the ith eigenvector and eigenvalue of Σ. Note that Σ real and symmetric λ i real. Proof? See Appendix C for a review of matrices and eigenvectors.


26 26 Geometry of the Multivariate Gaussian Δ = Mahalanobis distance from µ to x where (u i,λ i ) are the ith eigenvector and eigenvalue of Σ. or y = U(x - µ)

27 27 Moments of the Multivariate Gaussian thanks to anti-symmetry of z
28 28 Moments of the Multivariate Gaussian
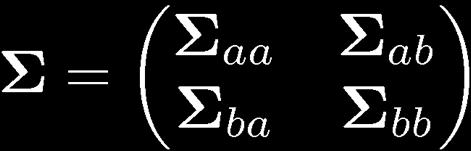
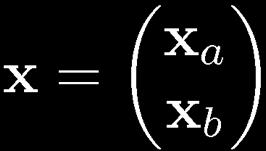
29 29 Partitioned Gaussian Distributions
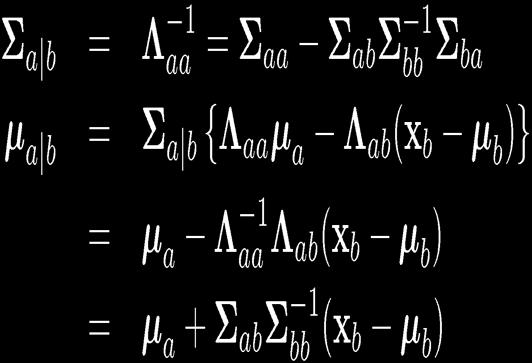
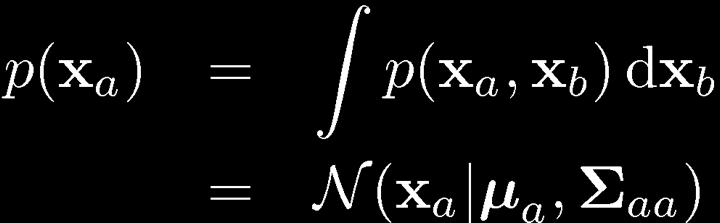
30 30 Partitioned Conditionals and Marginals
31 31 Partitioned Conditionals and Marginals

32 Maximum Likelihood for the Gaussian 32 Given i.i.d. data, the log likelihood function is given by Sufficient statistics


 = (")
33 Maximum Likelihood for the Gaussian 33 Set the derivative of the log likelihood function to zero, and solve to obtain Similarly Recall: If x and a are vectors, then ( x xt a) = ( x at x) = a


34 34 Maximum Likelihood for the Gaussian Under the true distribution Hence define

35 Bayesian Inference for the Gaussian (Univariate Case) 35 Assume σ 2 is known. Given i.i.d. data, the likelihood function for µ is given by This has a Gaussian shape as a function of µ (but it is not a distribution over µ ).
36 Bayesian Inference for the Gaussian (Univariate Case) 36 Combined with a Gaussian prior over µ, this gives the posterior Completing the square over µ, we see that


37 Bayesian Inference for the Gaussian 37 where Note: Shortcut: Get Δ 2 in form aµ 2 2bµ + c = a(µ b / a) 2 + const and identify µ N = b / a 1 σ N 2 = a
38 38 Bayesian Inference for the Gaussian Example: for N = 0, 1, 2 and 10.

39 39 Bayesian Inference for the Gaussian Sequential Estimation The posterior obtained after observing N { 1 data points becomes the prior when we observe the N th data point.

40 40 Bayesian Inference for the Gaussian Now assume µ is known. The likelihood function for λ = 1/ σ 2 is given by This has a Gamma shape as a function of λ.

41 41 Bayesian Inference for the Gaussian The Gamma distribution


42 42 Bayesian Inference for the Gaussian Now we combine a Gamma prior, with the likelihood function for λ to obtain which we recognize as with

43 43 Bayesian Inference for the Gaussian If both µ and λ are unknown, the joint likelihood function is given by We need a prior with the same functional dependence on µ and λ.

44 44 Bayesian Inference for the Gaussian The Gaussian-gamma distribution
45 Bayesian Inference for the Gaussian 45 The Gaussian-gamma distribution

 Wishart, µ and Λ")
46 Bayesian Inference for the Gaussian 46 Multivariate conjugate priors µ unknown, Λ known: p( µ ) Gaussian. Λ unknown, µ known: p( Λ) Wishart, µ and Λ unknown: p( µ, Λ) Gaussian-Wishart,

47 47 Student s t-distribution where Infinite mixture of Gaussians.

48 48 Student s t-distribution
49 49 Student s t-distribution Robustness to outliers: Gaussian vs t-distribution.


50 50 Student s t-distribution The D-variate case: where. Properties:

51 Periodic variables 51 Examples: time of day, direction, We require


52 52 von Mises Distribution This requirement is satisfied by where is the 0 th order modified Bessel function of the 1 st kind. (The von Mises distribution is the intersection of an isotropic bivariate Gaussian with the unit circle)
53 53 von Mises Distribution



54 54 Maximum Likelihood for von Mises Given a data set, function is given by, the log likelihood Maximizing with respect to µ 0 we directly obtain Similarly, maximizing with respect to m we get which can be solved numerically for m ML.
55 55 Mixtures of Gaussians Old Faithful data set Duration of last eruption (min) Time to next eruption (min) Single Gaussian Mixture of two Gaussians


56 56 Mixtures of Gaussians Combine simple models into a complex model: Component Mixing coefficient K=3

57 57 Mixtures of Gaussians

58 58 Mixtures of Gaussians Determining parameters log likelihood µ, σ and π using maximum Log of a sum; no closed form maximum. Solution: use standard, iterative, numeric optimization methods or the expectation maximization algorithm (Chapter 9).
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Curve Fitting Re-visited, Bishop1.2.5
 Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
ECE285/SIO209, Machine learning for physical applications, Spring 2017
 ECE285/SIO209, Machine learning for physical applications, Spring 2017 Peter Gerstoft, 534-7768, gerstoft@ucsd.edu We meet Wednesday from 5 to 6:20pm in Spies Hall 330 Text Bishop Grading A or maybe S
ECE285/SIO209, Machine learning for physical applications, Spring 2017 Peter Gerstoft, 534-7768, gerstoft@ucsd.edu We meet Wednesday from 5 to 6:20pm in Spies Hall 330 Text Bishop Grading A or maybe S
Pattern Recognition and Machine Learning. Bishop Chapter 2: Probability Distributions
 Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Stat 5101 Lecture Notes
 Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Machine Learning Overview
 Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2
 Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Machine Learning using Bayesian Approaches
 Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 2 Linear Least Squares From
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 2 Linear Least Squares From
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP
 INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP Personal Healthcare Revolution Electronic health records (CFH) Personal genomics (DeCode, Navigenics, 23andMe) X-prize: first $10k human genome technology
INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP Personal Healthcare Revolution Electronic health records (CFH) Personal genomics (DeCode, Navigenics, 23andMe) X-prize: first $10k human genome technology
Lecture 11: Probability Distributions and Parameter Estimation
 Intelligent Data Analysis and Probabilistic Inference Lecture 11: Probability Distributions and Parameter Estimation Recommended reading: Bishop: Chapters 1.2, 2.1 2.3.4, Appendix B Duncan Gillies and
Intelligent Data Analysis and Probabilistic Inference Lecture 11: Probability Distributions and Parameter Estimation Recommended reading: Bishop: Chapters 1.2, 2.1 2.3.4, Appendix B Duncan Gillies and
MIXTURE MODELS AND EM
 Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
CS 361: Probability & Statistics
 October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
Point Estimation. Vibhav Gogate The University of Texas at Dallas
 Point Estimation Vibhav Gogate The University of Texas at Dallas Some slides courtesy of Carlos Guestrin, Chris Bishop, Dan Weld and Luke Zettlemoyer. Basics: Expectation and Variance Binary Variables
Point Estimation Vibhav Gogate The University of Texas at Dallas Some slides courtesy of Carlos Guestrin, Chris Bishop, Dan Weld and Luke Zettlemoyer. Basics: Expectation and Variance Binary Variables
Outline. Binomial, Multinomial, Normal, Beta, Dirichlet. Posterior mean, MAP, credible interval, posterior distribution
 Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Fundamentals. CS 281A: Statistical Learning Theory. Yangqing Jia. August, Based on tutorial slides by Lester Mackey and Ariel Kleiner
 Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
CS 361: Probability & Statistics
 March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Machine Learning CMPT 726 Simon Fraser University. Binomial Parameter Estimation
 Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Probability Theory for Machine Learning. Chris Cremer September 2015
 Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
A Derivation of the EM Updates for Finding the Maximum Likelihood Parameter Estimates of the Student s t Distribution
 A Derivation of the EM Updates for Finding the Maximum Likelihood Parameter Estimates of the Student s t Distribution Carl Scheffler First draft: September 008 Contents The Student s t Distribution The
A Derivation of the EM Updates for Finding the Maximum Likelihood Parameter Estimates of the Student s t Distribution Carl Scheffler First draft: September 008 Contents The Student s t Distribution The
Lecture 2: Priors and Conjugacy
 Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
Slides modified from: PATTERN RECOGNITION AND MACHINE LEARNING CHRISTOPHER M. BISHOP
 Slides modified from: PATTERN RECOGNITION AND MACHINE LEARNING CHRISTOPHER M. BISHOP Predic?ve Distribu?on (1) Predict t for new values of x by integra?ng over w: where The Evidence Approxima?on (1) The
Slides modified from: PATTERN RECOGNITION AND MACHINE LEARNING CHRISTOPHER M. BISHOP Predic?ve Distribu?on (1) Predict t for new values of x by integra?ng over w: where The Evidence Approxima?on (1) The
p L yi z n m x N n xi
 y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
Lecture 2: Conjugate priors
 (Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
(Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
Stat 5101 Lecture Slides: Deck 8 Dirichlet Distribution. Charles J. Geyer School of Statistics University of Minnesota
 Stat 5101 Lecture Slides: Deck 8 Dirichlet Distribution Charles J. Geyer School of Statistics University of Minnesota 1 The Dirichlet Distribution The Dirichlet Distribution is to the beta distribution
Stat 5101 Lecture Slides: Deck 8 Dirichlet Distribution Charles J. Geyer School of Statistics University of Minnesota 1 The Dirichlet Distribution The Dirichlet Distribution is to the beta distribution
Computational Cognitive Science
 Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory
 Bayesian Inference Statistical Decison Theory") Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Probability Distributions
 Probability Distributions Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr 1 / 25 Outline Summarize the main properties of some of
Probability Distributions Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr 1 / 25 Outline Summarize the main properties of some of
ECE521 Tutorial 11. Topic Review. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides. ECE521 Tutorial 11 / 4
 ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
Probability Distributions
 2 Probability Distributions In Chapter, we emphasized the central role played by probability theory in the solution of pattern recognition problems. We turn now to an exploration of some particular examples
2 Probability Distributions In Chapter, we emphasized the central role played by probability theory in the solution of pattern recognition problems. We turn now to an exploration of some particular examples
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
ECE521 W17 Tutorial 6. Min Bai and Yuhuai (Tony) Wu
 Wu") ECE521 W17 Tutorial 6 Min Bai and Yuhuai (Tony) Wu Agenda knn and PCA Bayesian Inference k-means Technique for clustering Unsupervised pattern and grouping discovery Class prediction Outlier detection
ECE521 W17 Tutorial 6 Min Bai and Yuhuai (Tony) Wu Agenda knn and PCA Bayesian Inference k-means Technique for clustering Unsupervised pattern and grouping discovery Class prediction Outlier detection
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Lecture 10. Announcement. Mixture Models II. Topics of This Lecture. This Lecture: Advanced Machine Learning. Recap: GMMs as Latent Variable Models
 Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Quantitative Biology II Lecture 4: Variational Methods
 10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
DS-GA 1002 Lecture notes 11 Fall Bayesian statistics
 DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
Introduction to Probability and Statistics (Continued)
") Introduction to Probability and Statistics (Continued) Prof. icholas Zabaras Center for Informatics and Computational Science https://cics.nd.edu/ University of otre Dame otre Dame, Indiana, USA Email:
Introduction to Probability and Statistics (Continued) Prof. icholas Zabaras Center for Informatics and Computational Science https://cics.nd.edu/ University of otre Dame otre Dame, Indiana, USA Email:
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
Language as a Stochastic Process
 CS769 Spring 2010 Advanced Natural Language Processing Language as a Stochastic Process Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Basic Statistics for NLP Pick an arbitrary letter x at random from any
CS769 Spring 2010 Advanced Natural Language Processing Language as a Stochastic Process Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Basic Statistics for NLP Pick an arbitrary letter x at random from any
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
COS513 LECTURE 8 STATISTICAL CONCEPTS
 COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference
 COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
Probability and Estimation. Alan Moses
 Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Introduction to Machine Learning
 Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Probabilistic Graphical Models
 School of Computer Science Probabilistic Graphical Models Infinite Feature Models: The Indian Buffet Process Eric Xing Lecture 21, April 2, 214 Acknowledgement: slides first drafted by Sinead Williamson
School of Computer Science Probabilistic Graphical Models Infinite Feature Models: The Indian Buffet Process Eric Xing Lecture 21, April 2, 214 Acknowledgement: slides first drafted by Sinead Williamson
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Multivariate Bayesian Linear Regression MLAI Lecture 11
 Multivariate Bayesian Linear Regression MLAI Lecture 11 Neil D. Lawrence Department of Computer Science Sheffield University 21st October 2012 Outline Univariate Bayesian Linear Regression Multivariate
Multivariate Bayesian Linear Regression MLAI Lecture 11 Neil D. Lawrence Department of Computer Science Sheffield University 21st October 2012 Outline Univariate Bayesian Linear Regression Multivariate
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Learning Bayesian network : Given structure and completely observed data
 Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Overview of Course. Nevin L. Zhang (HKUST) Bayesian Networks Fall / 58
 Bayesian Networks Fall / 58") Overview of Course So far, we have studied The concept of Bayesian network Independence and Separation in Bayesian networks Inference in Bayesian networks The rest of the course: Data analysis using Bayesian
Overview of Course So far, we have studied The concept of Bayesian network Independence and Separation in Bayesian networks Inference in Bayesian networks The rest of the course: Data analysis using Bayesian
More Spectral Clustering and an Introduction to Conjugacy
 CS8B/Stat4B: Advanced Topics in Learning & Decision Making More Spectral Clustering and an Introduction to Conjugacy Lecturer: Michael I. Jordan Scribe: Marco Barreno Monday, April 5, 004. Back to spectral
CS8B/Stat4B: Advanced Topics in Learning & Decision Making More Spectral Clustering and an Introduction to Conjugacy Lecturer: Michael I. Jordan Scribe: Marco Barreno Monday, April 5, 004. Back to spectral
Introduction to Machine Learning. Lecture 2
 Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
NPFL108 Bayesian inference. Introduction. Filip Jurčíček. Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic
 NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
Part 6: Multivariate Normal and Linear Models
 Part 6: Multivariate Normal and Linear Models 1 Multiple measurements Up until now all of our statistical models have been univariate models models for a single measurement on each member of a sample of
Part 6: Multivariate Normal and Linear Models 1 Multiple measurements Up until now all of our statistical models have been univariate models models for a single measurement on each member of a sample of
The Expectation-Maximization Algorithm
 1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
Bayesian inference. Fredrik Ronquist and Peter Beerli. October 3, 2007
 Bayesian inference Fredrik Ronquist and Peter Beerli October 3, 2007 1 Introduction The last few decades has seen a growing interest in Bayesian inference, an alternative approach to statistical inference.
Bayesian inference Fredrik Ronquist and Peter Beerli October 3, 2007 1 Introduction The last few decades has seen a growing interest in Bayesian inference, an alternative approach to statistical inference.
2.3. The Gaussian Distribution
 78 2. PROBABILITY DISTRIBUTIONS Figure 2.5 Plots of the Dirichlet distribution over three variables, where the two horizontal axes are coordinates in the plane of the simplex and the vertical axis corresponds
78 2. PROBABILITY DISTRIBUTIONS Figure 2.5 Plots of the Dirichlet distribution over three variables, where the two horizontal axes are coordinates in the plane of the simplex and the vertical axis corresponds
CLASS NOTES Models, Algorithms and Data: Introduction to computing 2018
 CLASS NOTES Models, Algorithms and Data: Introduction to computing 208 Petros Koumoutsakos, Jens Honore Walther (Last update: June, 208) IMPORTANT DISCLAIMERS. REFERENCES: Much of the material (ideas,
CLASS NOTES Models, Algorithms and Data: Introduction to computing 208 Petros Koumoutsakos, Jens Honore Walther (Last update: June, 208) IMPORTANT DISCLAIMERS. REFERENCES: Much of the material (ideas,
Variational Mixture of Gaussians. Sargur Srihari
 Variational Mixture of Gaussians Sargur srihari@cedar.buffalo.edu 1 Objective Apply variational inference machinery to Gaussian Mixture Models Demonstrates how Bayesian treatment elegantly resolves difficulties
Variational Mixture of Gaussians Sargur srihari@cedar.buffalo.edu 1 Objective Apply variational inference machinery to Gaussian Mixture Models Demonstrates how Bayesian treatment elegantly resolves difficulties
Some Asymptotic Bayesian Inference (background to Chapter 2 of Tanner s book)
") Some Asymptotic Bayesian Inference (background to Chapter 2 of Tanner s book) Principal Topics The approach to certainty with increasing evidence. The approach to consensus for several agents, with increasing
Some Asymptotic Bayesian Inference (background to Chapter 2 of Tanner s book) Principal Topics The approach to certainty with increasing evidence. The approach to consensus for several agents, with increasing
Probability. Machine Learning and Pattern Recognition. Chris Williams. School of Informatics, University of Edinburgh. August 2014
 Probability Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh August 2014 (All of the slides in this course have been adapted from previous versions
Probability Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh August 2014 (All of the slides in this course have been adapted from previous versions
Computational Cognitive Science
 Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Stat 5101 Notes: Brand Name Distributions
 Stat 5101 Notes: Brand Name Distributions Charles J. Geyer September 5, 2012 Contents 1 Discrete Uniform Distribution 2 2 General Discrete Uniform Distribution 2 3 Uniform Distribution 3 4 General Uniform
Stat 5101 Notes: Brand Name Distributions Charles J. Geyer September 5, 2012 Contents 1 Discrete Uniform Distribution 2 2 General Discrete Uniform Distribution 2 3 Uniform Distribution 3 4 General Uniform
TABLE OF CONTENTS CHAPTER 1 COMBINATORIAL PROBABILITY 1
 TABLE OF CONTENTS CHAPTER 1 COMBINATORIAL PROBABILITY 1 1.1 The Probability Model...1 1.2 Finite Discrete Models with Equally Likely Outcomes...5 1.2.1 Tree Diagrams...6 1.2.2 The Multiplication Principle...8
TABLE OF CONTENTS CHAPTER 1 COMBINATORIAL PROBABILITY 1 1.1 The Probability Model...1 1.2 Finite Discrete Models with Equally Likely Outcomes...5 1.2.1 Tree Diagrams...6 1.2.2 The Multiplication Principle...8
Test Code: STA/STB (Short Answer Type) 2013 Junior Research Fellowship for Research Course in Statistics
 2013 Junior Research Fellowship for Research Course in Statistics") Test Code: STA/STB (Short Answer Type) 2013 Junior Research Fellowship for Research Course in Statistics The candidates for the research course in Statistics will have to take two shortanswer type tests
Test Code: STA/STB (Short Answer Type) 2013 Junior Research Fellowship for Research Course in Statistics The candidates for the research course in Statistics will have to take two shortanswer type tests
CS839: Probabilistic Graphical Models. Lecture 7: Learning Fully Observed BNs. Theo Rekatsinas
 CS839: Probabilistic Graphical Models Lecture 7: Learning Fully Observed BNs Theo Rekatsinas 1 Exponential family: a basic building block For a numeric random variable X p(x ) =h(x)exp T T (x) A( ) = 1
CS839: Probabilistic Graphical Models Lecture 7: Learning Fully Observed BNs Theo Rekatsinas 1 Exponential family: a basic building block For a numeric random variable X p(x ) =h(x)exp T T (x) A( ) = 1
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
2 Inference for Multinomial Distribution
 Markov Chain Monte Carlo Methods Part III: Statistical Concepts By K.B.Athreya, Mohan Delampady and T.Krishnan 1 Introduction In parts I and II of this series it was shown how Markov chain Monte Carlo
Markov Chain Monte Carlo Methods Part III: Statistical Concepts By K.B.Athreya, Mohan Delampady and T.Krishnan 1 Introduction In parts I and II of this series it was shown how Markov chain Monte Carlo
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
A Few Special Distributions and Their Properties
 A Few Special Distributions and Their Properties Econ 690 Purdue University Justin L. Tobias (Purdue) Distributional Catalog 1 / 20 Special Distributions and Their Associated Properties 1 Uniform Distribution
A Few Special Distributions and Their Properties Econ 690 Purdue University Justin L. Tobias (Purdue) Distributional Catalog 1 / 20 Special Distributions and Their Associated Properties 1 Uniform Distribution
Qualifier: CS 6375 Machine Learning Spring 2015
 Qualifier: CS 6375 Machine Learning Spring 2015 The exam is closed book. You are allowed to use two double-sided cheat sheets and a calculator. If you run out of room for an answer, use an additional sheet
Qualifier: CS 6375 Machine Learning Spring 2015 The exam is closed book. You are allowed to use two double-sided cheat sheets and a calculator. If you run out of room for an answer, use an additional sheet
Lecture 2: Repetition of probability theory and statistics
 Algorithms for Uncertainty Quantification SS8, IN2345 Tobias Neckel Scientific Computing in Computer Science TUM Lecture 2: Repetition of probability theory and statistics Concept of Building Block: Prerequisites:
Algorithms for Uncertainty Quantification SS8, IN2345 Tobias Neckel Scientific Computing in Computer Science TUM Lecture 2: Repetition of probability theory and statistics Concept of Building Block: Prerequisites:
Discrete Binary Distributions
 Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
DS-GA 1003: Machine Learning and Computational Statistics Homework 7: Bayesian Modeling
 DS-GA 1003: Machine Learning and Computational Statistics Homework 7: Bayesian Modeling Due: Tuesday, May 10, 2016, at 6pm (Submit via NYU Classes) Instructions: Your answers to the questions below, including
DS-GA 1003: Machine Learning and Computational Statistics Homework 7: Bayesian Modeling Due: Tuesday, May 10, 2016, at 6pm (Submit via NYU Classes) Instructions: Your answers to the questions below, including
Machine Learning. Probability Basics. Marc Toussaint University of Stuttgart Summer 2014
 Machine Learning Probability Basics Basic definitions: Random variables, joint, conditional, marginal distribution, Bayes theorem & examples; Probability distributions: Binomial, Beta, Multinomial, Dirichlet,
Machine Learning Probability Basics Basic definitions: Random variables, joint, conditional, marginal distribution, Bayes theorem & examples; Probability distributions: Binomial, Beta, Multinomial, Dirichlet,
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Why Bayesian? Rigorous approach to address statistical estimation problems. The Bayesian philosophy is mature and powerful.
 Why Bayesian? Rigorous approach to address statistical estimation problems. The Bayesian philosophy is mature and powerful. Even if you aren t Bayesian, you can define an uninformative prior and everything
Why Bayesian? Rigorous approach to address statistical estimation problems. The Bayesian philosophy is mature and powerful. Even if you aren t Bayesian, you can define an uninformative prior and everything
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
Data Mining Techniques. Lecture 3: Probability
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 3: Probability Jan-Willem van de Meent (credit: Zhao, CS 229, Bishop) Project Vote 1. Freeform: Develop your own project proposals 30% of
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 3: Probability Jan-Willem van de Meent (credit: Zhao, CS 229, Bishop) Project Vote 1. Freeform: Develop your own project proposals 30% of
5. Conditional Distributions
 1 of 12 7/16/2009 5:36 AM Virtual Laboratories > 3. Distributions > 1 2 3 4 5 6 7 8 5. Conditional Distributions Basic Theory As usual, we start with a random experiment with probability measure P on an
1 of 12 7/16/2009 5:36 AM Virtual Laboratories > 3. Distributions > 1 2 3 4 5 6 7 8 5. Conditional Distributions Basic Theory As usual, we start with a random experiment with probability measure P on an
BAYESIAN DECISION THEORY. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 BAYESIAN DECISION THEORY Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis, University of Athens
BAYESIAN DECISION THEORY Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis, University of Athens