Advanced statistical methods for data analysis Lecture 2
|
|
|
- Frank Wade
- 5 years ago
- Views:
Transcription

1 Advanced statistical methods for data analysis Lecture 2 RHUL Physics Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel September,
2 Outline Multivariate methods in particle physics Some general considerations Brief review of statistical formalism Multivariate classifiers: Linear discriminant function Neural networks Naive Bayes classifier k Nearest Neighbour method Decision trees Support Vector Machines Lecture 2 start 2

3 Linear decision boundaries A linear decision boundary is only optimal when both classes follow multivariate Gaussians with equal covariances and different means. x 2 x 1 x 2 x 1 For some other cases a linear boundary is almost useless. 3
 2 = x 1 2 x 2 2 2 x 1 1")
4 Nonlinear transformation of inputs We can try to find a transformation, x 2 x 1,, x n 1 x,, m x so that the transformed feature space variables can be separated better by a linear boundary: Here, guess fixed 1 =tan 1 x 2 / x 1 basis functions (no free parameters) 2 = x 1 2 x x 1 1 4
5 Neural networks Neural networks originate from attempts to model neural processes (McCulloch and Pitts, 1943; Rosenblatt, 1962). Widely used in many fields, and for many years the only advanced multivariate method popular in HEP. We can view a neural network as a specific way of parametrizing the basis functions used to define the feature space transformation. The training data are then used to adjust the parameters so that the resulting discriminant function has the best performance. 5
6 The single layer perceptron n Define the discriminant using y x =h w 0 i=1 w i x i where h is a nonlinear, monotonic activation function; we can use e.g. the logistic sigmoid h x = 1 e x 1. If the activation function is monotonic, the resulting y(x) is equivalent to the original linear discriminant. This is an example of a generalized linear model called the single layer perceptron. y x output node input layer 6
7 The multilayer perceptron Now use this idea to define not only the output y(x), but also the set of transformed inputs 1 x,, m x Superscript for weights indicates layer number that form a hidden layer : i x =h w i0 n 1 j=1 w 1 ij x j y x y x =h w 10 n 2 j=1 w 2 1 j j x inputs hidden layer i output This is the multilayer perceptron, our basic neural network model; straightforward to generalize to multiple hidden layers. 7
8 Network architecture: one hidden layer Theorem: An MLP with a single hidden layer having a sufficiently large number of nodes can approximate arbitrarily well the Bayes optimal decision boundary. Holds for any continuous non polynomial activation function Leshno, Lin, Pinkus and Schocken (1993), Neural Networks 6, In practice often choose a single hidden layer and try increasing the the number of nodes until no further improvement in performance is found. 8
9 More than one hidden layer Relatively little is known concerning the advantages and disadvantages of using a single hidden layer with many units (neurons) over many hidden layers with fewer units. The mathematics and approximation theory of the MLP model with more than one hidden layer is not well understood. Nonetheless there seems to be reason to conjecture that the two hidden layer model may be significantly more promising than the single hidden layer model,... A. Pinkus, Approximation theory of the MLP model in neural networks, Acta Numerica (1999), pp
10 Network training The type of each training event is known, i.e., for event a we have: x a = x 1,, x n t a =0,1 the input variables, and a numerical label for event type ( target value ) Let w denote the set of all of the weights of the network. We can determine their optimal values by minimizing a sum of squares error function N E w = 1 2 a=1 N y x a,w t a 2 = a=1 E a w Contribution to error function from each event 10
11 Numerical minimization of E(w) Consider gradient descent method: from an initial guess in weight space w (1) take a small step in the direction of maximum decrease. I.e. for the step to +1, w 1 =w E w learning rate ( >0) If we do this with the full error function E(w), gradient descent does surprisingly poorly; better to use conjugate gradients. But gradient descent turns out to be useful with an online (sequential) method, i.e., where we update w for each training event a, (cycle through all training events): w 1 =w E a w 11
12 Error backpropagation Error backpropagation ( backprop ) is an algorithm for finding the derivatives required for gradient descent minimization. The network output can be written y(x) = h(u(x)) where u x = j=0 w 2 1 j j x, j x =h w 1 jk x k k=0 where we defined 0 = x 0 = 1 and wrote the sums over the nodes in the preceding layers starting from 0 to include the offsets. So e.g. for event a we have Chain rule gives all the needed derivatives. E a w = y 2 a t a h' u x j x 1 j derivative of activation function 12
13 Overtraining If the network has too many nodes, after training it will tend to conform too closely to the training data: Overtraining The classification error rate on the training sample may be very low, but it would be much higher on an independent data sample. Therefore it is important to evaluate the error rate with a statistically independent validation sample. 13
14 Monitoring overtraining If we monitor the value of the error function E(w) at every cycle of the minimization, for the training sample it will continue to decrease. error But the validation sample it may initially decrease, and then at some point increase, indicating overtraining. validation sample training sample training cycle 14
15 Validation and testing The validation sample can be used to make various choices about the network architecture, e.g., adjust the number of hidden nodes so as to obtain good generalization performance (ability to correctly classify unseen data). If the validation stage is iterated may times, the estimated error rate based on the validation sample has a bias, so strictly speaking one should finally estimate the error rate with an independent test sample. Rule of thumb if data not too expensive (Narsky): train : validate : test 50 : 25 : 25 But this depends on the type of classifier. Often the bias in the error rate from the validation sample is small and one can omit the test step. 15
16 Bias variance trade off For a finite amount of training data, an increasing number of network parameters (layers, nodes) means that the estimates of these parameters have increasingly large statistical errors (variance, overtraining). Having too few parameters doesn't allow the network to exploit the existing nonlinearities, i.e., it has a bias. high variance high bias good trade off 16
17 Regularized neural networks Often one uses the test sample to optimize the number of hidden nodes. Alternatively one may use a relatively large number of hidden nodes but include in the error function a regularization term that penalizes overfitting, e.g., regularization parameter E w =E w 2 wt w Increasing gives a smoother boundary (higher bias, lower variance) Known as weight decay, since the weights are driven to zero unless supported by the data (an example of parameter shrinkage ). 17
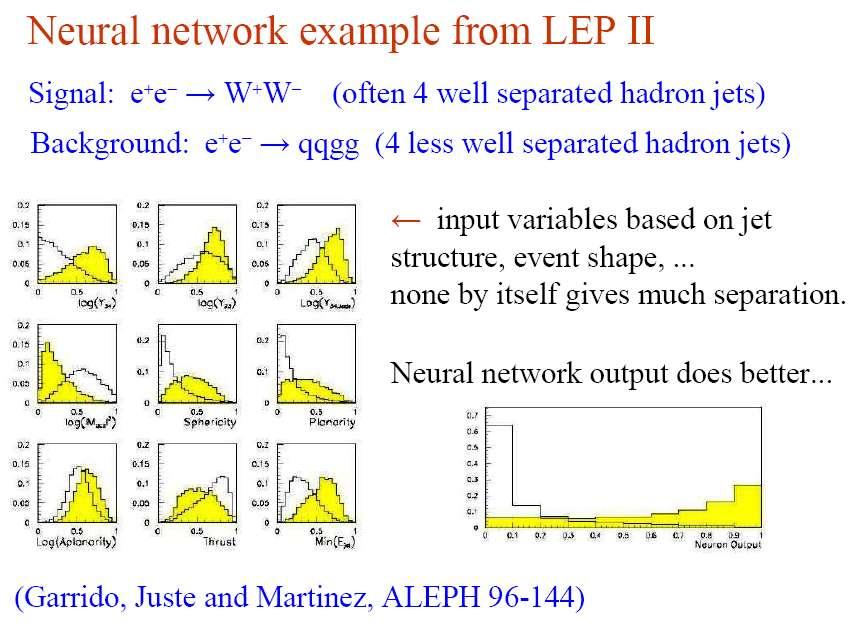
18 18
19 Probability Density Estimation (PDE) Construct non parametric estimators for the pdfs of the data x for the two event classes, p(x H 0 ), p(x H 1 ) and use these to construct the likelihood ratio, which we use for the discriminant function: y x = p x H 0 p x H 1 n dimensional histogram is a brute force example of this; we will see a number of ways that are much better. 19
20 Correlation vs. independence In a general a multivariate distribution p(x) does not factorize into a product of the marginal distributions for the individual variables: n p x = i=1 p i x i holds only if the components of x are independent Most importantly, the components of x will generally have nonzero covariances (i.e. they are correlated): V ij =cov[ x i, x j ]=E [ x i x j ] E [ x i ] E [ x j ] 0 20
21 Decorrelation of input variables But we can define a set of uncorrelated input variables by a linear transformation, i.e., find the matrix A such that for the covariances cov[y i, y j ] = 0: y=a x For the following suppose that the variables are decorrelated in this way for each of p(x H 0 ) and p(x H 1 ) separately (since in general their correlations are different). 21
22 Decorrelation is not enough But even with zero correlation, a multivariate pdf p(x) will in general have nonlinearities and thus the decorrelated variables are still not independent. x 2 pdf with zero covariance but components still not independent, since clearly p x 2 x 1 p x 1, x 2 p 1 x 1 p 2 x 2 and therefore x 1 p x 1, x 2 p 1 x 1 p 2 x 2 22
23 Naive Bayes But if the nonlinearities are not too great, it is reasonable to first decorrelate the inputs and take as our estimator for each pdf n p x = i=1 p i x i So this at least reduces the problem to one of finding estimates of one dimensional pdfs. The resulting estimated likelihood ratio gives the Naive Bayes classifier (in HEP sometimes called the likelihood method ). 23

24 Test example with TMVA 24
25 Test example, x vs. y with cuts on z no cut on z z < 0.75 z < 0.5 z <
26 Test example results Fisher discriminant Multilayer perceptron Naive Bayes, no decorrelation Naive Bayes with decorrelation 26

27 Test example ROC curves TMVA macro efficiencies.c 27

28 Efficiencies versus cut value Select signal by cutting on output: y > y cut Fisher discriminant TMVA macro mvaeffs.c 28

29 Efficiencies versus cut value Select signal by cutting on output: y > y cut Multilayer perceptron TMVA macro mvaeffs.c 29

30 Efficiencies versus cut value Select signal by cutting on output: y > y cut Naive Bayes, no decorrelation TMVA macro mvaeffs.c 30
31 Efficiencies versus cut value Select signal by cutting on output: y > y cut Naive Bayes with decorrelation TMVA macro mvaeffs.c 31
32 Lecture 2 summary We have generalized the classifiers to allow nonlinear decision boundaries. In neural networks, the user chooses a certain number of hidden layers and nodes; having more allows for an increasingly accurate approximation to the optimal decision boundary. But having more parameters means that their estimates given a finite amount of training data are increasingly subject to statistical fluctuations, which shows up as overtraining. The naive Bayes method seeks to approximate the joint pdfs of the classes as the product of 1 dimensional marginal pdfs (after decorrelation). To pursue this further we should therefore refine our approximations of 1 d pdfs. 32
Advanced statistical methods for data analysis Lecture 1
 Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Multivariate statistical methods and data mining in particle physics
 Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Statistical Methods for Particle Physics Lecture 2: multivariate methods
 Statistical Methods for Particle Physics Lecture 2: multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
Statistical Methods for Particle Physics Lecture 2: multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
Statistical Methods in Particle Physics
 Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Multivariate Data Analysis and Machine Learning in High Energy Physics (III)
") Multivariate Data Analysis and Machine Learning in High Energy Physics (III) Helge Voss (MPI K, Heidelberg) Graduierten-Kolleg, Freiburg, 11.5-15.5, 2009 Outline Summary of last lecture 1-dimensional Likelihood:
Multivariate Data Analysis and Machine Learning in High Energy Physics (III) Helge Voss (MPI K, Heidelberg) Graduierten-Kolleg, Freiburg, 11.5-15.5, 2009 Outline Summary of last lecture 1-dimensional Likelihood:
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Multi-layer Neural Networks
 Multi-layer Neural Networks Steve Renals Informatics 2B Learning and Data Lecture 13 8 March 2011 Informatics 2B: Learning and Data Lecture 13 Multi-layer Neural Networks 1 Overview Multi-layer neural
Multi-layer Neural Networks Steve Renals Informatics 2B Learning and Data Lecture 13 8 March 2011 Informatics 2B: Learning and Data Lecture 13 Multi-layer Neural Networks 1 Overview Multi-layer neural
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008)
") Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008) RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement
Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008) RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Lecture 3: Pattern Classification
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Machine Learning for NLP
 Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Machine Learning (CSE 446): Neural Networks
: Neural Networks") Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Artificial Neural Network
 Artificial Neural Network Eung Je Woo Department of Biomedical Engineering Impedance Imaging Research Center (IIRC) Kyung Hee University Korea ejwoo@khu.ac.kr Neuron and Neuron Model McCulloch and Pitts
Artificial Neural Network Eung Je Woo Department of Biomedical Engineering Impedance Imaging Research Center (IIRC) Kyung Hee University Korea ejwoo@khu.ac.kr Neuron and Neuron Model McCulloch and Pitts
Mark Gales October y (x) x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.
 x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.") University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
Applied Statistics. Multivariate Analysis - part II. Troels C. Petersen (NBI) Statistics is merely a quantization of common sense 1
 Statistics is merely a quantization of common sense 1") Applied Statistics Multivariate Analysis - part II Troels C. Petersen (NBI) Statistics is merely a quantization of common sense 1 Fisher Discriminant You want to separate two types/classes (A and B) of
Applied Statistics Multivariate Analysis - part II Troels C. Petersen (NBI) Statistics is merely a quantization of common sense 1 Fisher Discriminant You want to separate two types/classes (A and B) of
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers
 Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Lecture 2. G. Cowan Lectures on Statistical Data Analysis Lecture 2 page 1
 Lecture 2 1 Probability (90 min.) Definition, Bayes theorem, probability densities and their properties, catalogue of pdfs, Monte Carlo 2 Statistical tests (90 min.) general concepts, test statistics,
Lecture 2 1 Probability (90 min.) Definition, Bayes theorem, probability densities and their properties, catalogue of pdfs, Monte Carlo 2 Statistical tests (90 min.) general concepts, test statistics,
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Advanced Machine Learning
 Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Multivariate Analysis, TMVA, and Artificial Neural Networks
 http://tmva.sourceforge.net/ Multivariate Analysis, TMVA, and Artificial Neural Networks Matt Jachowski jachowski@stanford.edu 1 Multivariate Analysis Techniques dedicated to analysis of data with multiple
http://tmva.sourceforge.net/ Multivariate Analysis, TMVA, and Artificial Neural Networks Matt Jachowski jachowski@stanford.edu 1 Multivariate Analysis Techniques dedicated to analysis of data with multiple
Artificial Neural Networks
 Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Linear Classification. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
3.4 Linear Least-Squares Filter
 X(n) = [x(1), x(2),..., x(n)] T 1 3.4 Linear Least-Squares Filter Two characteristics of linear least-squares filter: 1. The filter is built around a single linear neuron. 2. The cost function is the sum
X(n) = [x(1), x(2),..., x(n)] T 1 3.4 Linear Least-Squares Filter Two characteristics of linear least-squares filter: 1. The filter is built around a single linear neuron. 2. The cost function is the sum
Statistical Data Analysis Stat 2: Monte Carlo Method, Statistical Tests
 Statistical Data Analysis Stat 2: Monte Carlo Method, Statistical Tests London Postgraduate Lectures on Particle Physics; University of London MSci course PH4515 Glen Cowan Physics Department Royal Holloway,
Statistical Data Analysis Stat 2: Monte Carlo Method, Statistical Tests London Postgraduate Lectures on Particle Physics; University of London MSci course PH4515 Glen Cowan Physics Department Royal Holloway,
Multivariate Analysis Techniques in HEP
 Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees:
Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees:
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods
 Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods www.pp.rhul.ac.uk/~cowan/stat_aachen.html Graduierten-Kolleg RWTH Aachen 10-14 February 2014 Glen Cowan Physics
Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods www.pp.rhul.ac.uk/~cowan/stat_aachen.html Graduierten-Kolleg RWTH Aachen 10-14 February 2014 Glen Cowan Physics
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
10-701/ Machine Learning, Fall
 0-70/5-78 Machine Learning, Fall 2003 Homework 2 Solution If you have questions, please contact Jiayong Zhang .. (Error Function) The sum-of-squares error is the most common training
0-70/5-78 Machine Learning, Fall 2003 Homework 2 Solution If you have questions, please contact Jiayong Zhang .. (Error Function) The sum-of-squares error is the most common training
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Multilayer Neural Networks
 Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Linear discriminant functions
 Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
CSC2515 Winter 2015 Introduction to Machine Learning. Lecture 2: Linear regression
 CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Generative v. Discriminative classifiers Intuition
 Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 1 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features
Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 1 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet.
 or two-page (one side) crib sheet.") CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Data Mining. Linear & nonlinear classifiers. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Ch.6 Deep Feedforward Networks (2/3)
") Ch.6 Deep Feedforward Networks (2/3) 16. 10. 17. (Mon.) System Software Lab., Dept. of Mechanical & Information Eng. Woonggy Kim 1 Contents 6.3. Hidden Units 6.3.1. Rectified Linear Units and Their Generalizations
Ch.6 Deep Feedforward Networks (2/3) 16. 10. 17. (Mon.) System Software Lab., Dept. of Mechanical & Information Eng. Woonggy Kim 1 Contents 6.3. Hidden Units 6.3.1. Rectified Linear Units and Their Generalizations
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1
 What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
An Introduction to Statistical and Probabilistic Linear Models
 An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
The classifier. Theorem. where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know
 The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The classifier. Linear discriminant analysis (LDA) Example. Challenges for LDA
 Example. Challenges for LDA") The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
NN V: The generalized delta learning rule
 NN V: The generalized delta learning rule We now focus on generalizing the delta learning rule for feedforward layered neural networks. The architecture of the two-layer network considered below is shown
NN V: The generalized delta learning rule We now focus on generalizing the delta learning rule for feedforward layered neural networks. The architecture of the two-layer network considered below is shown
Learning from Data: Multi-layer Perceptrons
 Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 6: Multi-Layer Perceptrons I
 Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 6: Multi-Layer Perceptrons I Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 2012 Engineering Part IIB: Module 4F10 Introduction In
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 6: Multi-Layer Perceptrons I Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 2012 Engineering Part IIB: Module 4F10 Introduction In
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
DEPARTMENT OF COMPUTER SCIENCE Autumn Semester MACHINE LEARNING AND ADAPTIVE INTELLIGENCE
 Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures