Deep Learning for Computer Vision
|
|
|
- Bryan Harvey
- 5 years ago
- Views:
Transcription
1 Deep Learning for Computer Vision Spring (primary) (grade, etc.) FB: DLCV Spring 2018 Yu-Chiang Frank Wang 王鈺強, Associate Professor Dept. Electrical Engineering, National Taiwan University 2018/05/09
2 What s to Be Covered Today Visualization of NNs t-sne Visualization of Feature Maps Neural Style Transfer Understanding NNs Image Translation Feature Disentanglement Recurrent Neural Networks LSTM & GRU Many slides from Fei-Fei Li, Yaser Sheikh, Simon Lucey, Kaiming He, J.-B. Huang, Yuying Yeh, and Hsuan-I Ho


3 Representation Disentanglement Goal Interpretable deep feature representation Disentangle attribute of interest c from the derived latent representation z Unsupervised: InfoGAN Supervised: AC-GAN InfoGAN Chen et al. NIPS 16 ACGAN Odena et al. ICML 17 Chen et al., InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets., NIPS Odena et al., Conditional image synthesis with auxiliary classifier GANs. ICML 17 3
4 AC-GAN Supervised Disentanglement Learning Overall objective function D G = arg min G max D Adversarial Loss L GGGGGG G, D + L cccccc G, D yy (real) Supervised cc G(zz, cc) G zz L GGGGGG G, D = EE log 1 D(G(zz, cc)) + EE log D yy Disentanglement loss L cccccc G, D = EE log D cls (cc yy) + EE log D cls (cc G(xx, cc)) Real data w.r.t. its domain label Generated data w.r.t. assigned label Odena et al., Conditional image synthesis with auxiliary classifier GANs. ICML 17 4

5 AC-GAN Supervised Disentanglement D yy (real) Supervised cc G(zz, cc) G zz Different cc values Odena et al., Conditional image synthesis with auxiliary classifier GANs. ICML 17 5
6 InfoGAN Unsupervised Disentanglement Learning Overall objective function G = arg min G max D Adversarial Loss L GGGGGG G, D + L cccccc G, D L GGGGGG G, D = EE log 1 D(G(zz, cc)) Disentanglement loss L cccccc G, D = EE log D cls (cc G(xx, cc)) + EE log D yy Generated data w.r.t. assigned label Chen et al., InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets., NIPS


7 InfoGAN Unsupervised Disentanglement No guarantee in disentangling particular semantics Different cc Different cc Rotation Angle Width Loss Training process Chen et al., InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets., NIPS Time 7
8 From Image Understanding to Image Manipulation Representation Disentanglement InfoGAN: Unsupervised representation disentanglement AC-GAN: Supervised representation disentanglement Image Translation Pix2pix (CVPR 17): Pairwise cross-domain training data CycleGAN/DualGAN/DiscoGAN: Unpaired cross-domain training data UNIT (NIPS 17): Learning cross-domain image representation (with unpaired training data) DTN (ICLR 17) : Learning cross-domain image representation (with unpaired training data) Joint Image Translation & Disentanglement StarGAN (CVPR 18) : Image translation via representation disentanglement CDRD (CVPR 18) : Cross-domain representation disentanglement and translation 8

9 Pix2pix Image-to-image translation with conditional adversarial networks (CVPR 17) Can be viewed as image style transfer Sketch Photo Isola et al. " Image-to-image translation with conditional adversarial networks." CVPR

10 Pix2pix Testing Phase Goal / Problem Setting Image translation across two distinct domains (e.g., sketch v.s. photo) Pairwise training data Method: Conditional GAN Example: Sketch to Photo Generator (VAE) Input: Sketch Output: Photo Discriminator Input Input: Concatenation of Input(Sketch) & Synthesized/Real(Photo) images Output: Real or Fake Training Phase Generated Input real Concat Concat Input Isola et al. " Image-to-image translation with conditional adversarial networks." CVPR
 = EE xx log 1 D(xx, G(xx)) Reconstruction Loss L LLL (G) = EE xx,yy yy G(xx) 1 Fake (Generated) Concatenate + EE xx,yy log D xx, yy Real Input Isola et al.")
11 Pix2pix Learning the model Training Phase Input Generated Overall objective function G = arg min max L cccccccc G, D + L LLL (G) G D Input Real Concat Concat Conditional GAN loss Concatenate L cccccccc (G, D) = EE xx log 1 D(xx, G(xx)) Reconstruction Loss L LLL (G) = EE xx,yy yy G(xx) 1 Fake (Generated) Concatenate + EE xx,yy log D xx, yy Real Input Isola et al. " Image-to-image translation with conditional adversarial networks." CVPR

12 Pix2pix Experiment results Demo page: Isola et al. " Image-to-image translation with conditional adversarial networks." CVPR
13 From Image Understanding to Image Manipulation Representation Disentanglement InfoGAN: Unsupervised representation disentanglement AC-GAN: Supervised representation disentanglement Image Translation Pix2pix (CVPR 17): Pairwise cross-domain training data CycleGAN/DualGAN/DiscoGAN: Unpaired cross-domain training data UNIT (NIPS 17): Learning cross-domain image representation (with unpaired training data) DTN (ICLR 17) : Learning cross-domain image representation (with unpaired training data) Joint Image Translation & Disentanglement StarGAN (CVPR 18) : Image translation via representation disentanglement CDRD (CVPR 18) : Cross-domain representation disentanglement and translation

14 CycleGAN/DiscoGAN/DualGAN CycleGAN (CVPR 17) Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks -to-image translation with conditional adversarial networks Paired Unpaired Easier to collect training data More practical 1-to-1 Correspondence No Correspondence Zhu et al. "Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks." CVPR 2017.
15 CycleGAN Training data Goal / Problem Setting Image translation across two distinct domains Photo Unpaired Painting Unpaired training data Idea Autoencoding-like image translation Cycle consistency between two domains Photo Painting Photo Cycle Consistency Painting Photo Painting Cycle Consistency Zhu et al. "Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks." CVPR 2017.
16 CycleGAN Method (Example: Photo & Painting) Based on 2 GANs First GAN (G1, D1): Photo to Painting Second GAN (G2, D2): Painting to Photo Photo (Input) G1 Painting (Generated) or D1 Real / Fake Cycle Consistency Photo consistency Painting consistency Painting (Input) G2 Painting (Real) Photo (Generated) or D2 Real / Fake Photo (Real) Zhu et al. "Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks." CVPR 2017.
17 CycleGAN Method (Example: Photo vs. Painting) Based on 2 GANs First GAN (G1, D1): Photo to Painting Second GAN (G2, D2): Photo to Painting Photo Painting Photo G1 G2 Photo Consistency Cycle Consistency Photo consistency Painting consistency Painting Photo Painting G2 G1 Painting Consistency Zhu et al. "Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks." CVPR 2017.
18 Learning CycleGAN Photo (Input) xx G1 Painting (Generated) G 1 (xx) or D1 Overall objective function G 1, G 2 = arg min max L GGGGGG G 1, D 1 G 1,G 2 D 1,D 2 + L GGGGGG G 2, D 2 + L cccccc G 1, G 2 First GAN Second GAN Adversarial Loss First GAN (G1, D1): L GGGGGG G 1, D 1 = EE log 1 D 1 (G 1 (xx)) + EE log D 1 yy Painting (Input) yy G2 yy Painting (Real) Photo (Generated) G 2 (yy) or D2 Real / Fake Second GAN (G2, D2): L GGGGGG G 2, D 2 = EE log 1 D 2 (G 2 (yy)) + EE log D 2 xx xx Photo (Real) Real / Fake Zhu et al. "Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks." CVPR 2017.
19 CycleGAN Photo Painting Photo xx G 1 xx G 2 G 1 xx G1 G2 Learning Overall objective function G 1, G 2 = arg min G 1,G 2 max D 1,D 2 L GGGGGG G 1, D 1 + L GGGGGG G 2, D 2 + L cccccc G 1, G 2 Consistency Loss Photo and Painting consistency L cccccc G 1, G 2 = EE G 2 G 1 xx xx 1 + G 1 G 2 yy yy 1 Photo Consistency Cycle Consistency Painting Photo Painting yy G 2 yy G 1 G 2 yy G2 G1 Painting Consistency Zhu et al. "Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks." CVPR 2017.



20 CycleGAN Example results Project Page: Zhu et al. "Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks." CVPR 2017.


21 Image Translation Using Unpaired Training Data CycleGAN, DiscoGAN, and DualGAN CycleGAN ICCV 17 DiscoGAN ICML 17 DualGAN ICCV 17 Zhu et al. "Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks." CVPR Kim et al. "Learning to Discover Cross-Domain Relations with Generative Adversarial Networks., ICML 2017 Yi et al. "DualGAN: Unsupervised dual learning for image-to-image translation." ICCV 2017
22 From Image Understanding to Image Manipulation Representation Disentanglement InfoGAN: Unsupervised representation disentanglement AC-GAN: Supervised representation disentanglement Image Translation Pix2pix (CVPR 17): Pairwise cross-domain training data CycleGAN/DualGAN/DiscoGAN: Unpaired cross-domain training data UNIT (NIPS 17): Learning cross-domain image representation (with unpaired training data) DTN (ICLR 17) : Learning cross-domain image representation (with unpaired training data) Joint Image Translation & Disentanglement StarGAN (CVPR 18) : Image translation via representation disentanglement CDRD (CVPR 18) : Cross-domain representation disentanglement and translation

23 UNIT Unsupervised Image-to-Image Translation Networks (NIPS 17) Image translation via learning cross-domain joint representation Stage1: Encode to the joint space ZZ: Joint latent space zz Stage2: Generate cross-domain images ZZ: Joint latent space zz Day Night Day Night xx 2 xx xx 1 1 XX 1 XX XX 2 1 XX 2 xx 2 Liu et al., "Unsupervised image-to-image translation networks., NIPS 2017
24 UNIT Goal/Problem Setting Image translation across two distinct domains Unpaired training image data Idea Based on two parallel VAE-GAN models VAE GAN Liu et al., "Unsupervised image-to-image translation networks., NIPS 2017


25 UNIT Goal/Problem Setting Image translation across two distinct domains Unpaired training image data Idea Based on two parallel VAE-GAN models Learning of joint representation across image domains Liu et al., "Unsupervised image-to-image translation networks., NIPS 2017

26 UNIT Goal/Problem Setting Image translation across two distinct domains Unpaired training image data Idea Based on two parallel VAE-GAN models Learning of joint representation across image domains Generate cross-domain images from joint representation Liu et al., "Unsupervised image-to-image translation networks., NIPS 2017
27 UNIT Learning Overall objective function G = arg min G max D L VVVVVV E 1, G 1, E 2, G 2 + L GGGGGG G 1, D 1, G 2, D 2 Variation Autoencoder Adversarial VAE E 1 G 1 D 1 G 1 (zz) G 2 (zz) GAN Variation Autoencoder Loss L VVVVVV E 1, G 1, E 2, G 2 = EE G 1 E 1 xx 1 xx EE KKL(qq 1 (zz) pp(zz)) EE G 2 E 2 xx 2 xx EE KKL(qq 2 (zz) pp(zz)) Adversarial Loss L GGGGGG G 1, D 1, G 2, D 2 = EE log 1 D 1 (G 1 (zz) + EE log D 1 yy 1 EE log 1 D 2 (G 2 (zz) + EE log D 2 yy 2 E 2 G 2 D 2
28 UNIT Learning Overall objective function G = arg min max L VVVVVV E 1, G 1, E 2, G 2 + L GGGGGG G 1, D 1, G 2, D 2 G D Variation Autoencoder Loss VAE E 1 G 1 D 1 G 1 E 1 xx 1 G 2 E 2 xx 2 E 2 G 2 D 2 L VVVVVV E 1, G 1, E 2, G 2 = EE G 1 E 1 xx 1 xx EE KKL(qq 1 (zz) pp(zz)) EE G 2 E 2 xx 2 xx EE KKL(qq 2 (zz) pp(zz)) Adversarial Loss Reconstruction L GGGGGG G 1, D 1, G 2, D 2 = EE log 1 D 1 (G 1 (zz) + EE log D 1 yy 1 EE log 1 D 2 (G 2 (zz) + EE log D 2 yy 2
29 UNIT Learning Overall objective function G = arg min max L VVVVVV E 1, G 1, E 2, G 2 + L GGGGGG G 1, D 1, G 2, D 2 G D Variation Autoencoder Loss VAE E 1 G 1 D 1 G 1 E 1 xx 1 G 2 E 2 xx 2 E 2 G 2 D 2 L VVVVVV E 1, G 1, E 2, G 2 = EE G 1 E 1 xx 1 xx EE KKL(qq 1 (zz) pp(zz)) EE G 2 E 2 xx 2 xx EE KKL(qq 2 (zz) pp(zz)) Adversarial Loss Prior Loss L GGGGGG G 1, D 1, G 2, D 2 = EE log 1 D 1 (G 1 (zz) + EE log D 1 yy 1 EE log 1 D 2 (G 2 (zz) + EE log D 2 yy 2
30 UNIT Learning Overall objective function G = arg min max L VVVVVV E 1, G 1, E 2, G 2 + L GGGGGG G 1, D 1, G 2, D 2 G D E 1 D 1 G 1 G 1 (zz) GAN yy 1 Variation Autoencoder Loss L VVVVVV E 1, G 1, E 2, G 2 = EE G 1 E 1 xx 1 xx EE KKL(qq 1 (zz) pp(zz)) EE G 2 E 2 xx 2 xx EE KKL(qq 2 (zz) pp(zz)) Adversarial Loss L GGGGGG G 1, D 1, G 2, D 2 = EE log 1 D 1 (G 1 (zz) + EE log D 1 yy 1 EE log 1 D 2 (G 2 (zz) + EE log D 2 yy 2 Generated G 2 (zz) yy 2 E 2 G 2 D 2
31 UNIT Learning Overall objective function G = arg min max L VVVVVV E 1, G 1, E 2, G 2 + L GGGGGG G 1, D 1, G 2, D 2 G D E 1 GAN Real G 1 yy 1 D 1 G 1 (zz) G 2 (zz) Variation Autoencoder Loss L VVVVVV E 1, G 1, E 2, G 2 = EE G 1 E 1 xx 1 xx EE KKL(qq 1 (zz) pp(zz)) EE G 2 E 2 xx 2 xx EE KKL(qq 2 (zz) pp(zz)) E 2 G yy 2 2 D 2 Real Adversarial Loss L GGGGGG G 1, D 1, G 2, D 2 = EE log 1 D 1 (G 1 (zz) + EE log D 1 yy 1 EE log 1 D 2 (G 2 (zz) + EE log D 2 yy 2 Real




32 UNIT Example results Sunny Rainy Real Street-view Synthetic Street-view Rainy Sunny Synthetic Street-view Real Street-view Github Page: Liu et al., "Unsupervised image-to-image translation networks., NIPS 2017
33 From Image Understanding to Image Manipulation Representation Disentanglement InfoGAN: Unsupervised representation disentanglement AC-GAN: Supervised representation disentanglement Image Translation Pix2pix (CVPR 17): Pairwise cross-domain training data CycleGAN/DualGAN/DiscoGAN: Unpaired cross-domain training data UNIT (NIPS 17): Learning cross-domain image representation (with unpaired training data) DTN (ICLR 17) : Learning cross-domain image representation (with unpaired training data) Joint Image Translation & Disentanglement StarGAN (CVPR 18) : Image translation via representation disentanglement CDRD (CVPR 18) : Cross-domain representation disentanglement and translation
34 Domain Transfer Networks Unsupervised Cross-Domain Image Generation (ICLR 17) Goal/Problem Setting Image translation across two domains One-way only translation Unpaired training data Idea Apply unified model to learn joint representation across domains. Taigman et al., "Unsupervised cross-domain image generation., ICLR 2016
35 Domain Transfer Networks Unsupervised Cross-Domain Image Generation (ICLR 17) Goal/Problem Setting Image translation across two domains One-way only translation Unpaired training data Idea Apply unified model to learn joint representation across domains. Consistency observed in image and feature spaces Image consistency feature consistency Taigman et al., "Unsupervised cross-domain image generation., ICLR 2016
36 Domain Transfer Networks Learning Unified model to translate across domains G = arg min G max L iiiiii G + L ffffffff G + L GGGGGG G, D D Consistency of feature and image space L iiiiii G = EE gg ff yy yy 2 G D L ffffffff G = EE ff(gg ff xx ) ff(xx) 2 Adversarial loss L GGGGGG G, D = EE log 1 D(G(xx) + EE log 1 D(G(yy) + EE log D yy
37 Domain Transfer Networks Learning Unified model to translate across domains G = arg min G max L iiiiii G + L ffffffff G + L GGGGGG G, D D Consistency of image and feature space L iiiiii G = EE gg ff yy yy 2 yy xx Image consistency G D L ffffffff G = EE ff(gg ff xx ) ff(xx) 2 feature consistency G = {ff, gg} Adversarial loss L GGGGGG G, D = EE log 1 D(G(xx) + EE log 1 D(G(yy) + EE log D yy
38 Domain Transfer Networks Learning Unified model to translate across domains G = arg min G max L iiiiii G + L ffffffff G + L GGGGGG G, D D Consistency of feature and image space L iiiiii G = EE gg ff yy yy 2 yy xx G G(yy) G(xx) D L ffffffff G = EE ff(gg ff xx ) ff(xx) 2 Adversarial loss L GGGGGG G, D = EE log 1 D(G(xx) + EE log 1 D(G(yy) + EE log D yy
 G(xx) D L ffffffff G = EE ff(gg ff xx ) ff(xx) 2 Adversarial loss L GGGGGG G, D = EE log 1 D(G(xx) + EE log 1 D(G(yy) + EE")
39 Domain Transfer Networks Learning Unified model to translate across domains G = arg min G max L iiiiii G + L ffffffff G + L GGGGGG G, D D Consistency of feature and image space L iiiiii G = EE gg ff yy yy 2 yy xx G G(yy) G(xx) D L ffffffff G = EE ff(gg ff xx ) ff(xx) 2 Adversarial loss L GGGGGG G, D = EE log 1 D(G(xx) + EE log 1 D(G(yy) + EE log D yy


40 DTN Example results SVHN 2 MNIST Photo 2 Emoji Taigman et al., "Unsupervised cross-domain image generation., ICLR 2016
41 From Image Understanding to Image Manipulation Representation Disentanglement InfoGAN: Unsupervised representation disentanglement AC-GAN: Supervised representation disentanglement Image Translation Pix2pix (CVPR 17): Pairwise cross-domain training data CycleGAN/DualGAN/DiscoGAN: Unpaired cross-domain training data UNIT (NIPS 17): Learning cross-domain image representation (with unpaired training data) DTN (ICLR 17) : Learning cross-domain image representation (with unpaired training data) Joint Image Translation & Disentanglement StarGAN (CVPR 18) : Image translation via representation disentanglement CDRD (CVPR 18) : Cross-domain representation disentanglement and translation
 Choi et al. \"StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation.\" CVPR 2018")
42 StarGAN Goal Unified GAN for multi-domain image-to-image translation Traditional Cross-Domain Models Unified Multi-Domain Model (StarGAN) Choi et al. "StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation." CVPR 2018
 GG 12")

43 StarGAN Goal Unified GAN for multi-domain image-to-image translation Traditional Cross-Domain Models Unified Multi-Domain Model (StarGAN) GG 12 GG 14 GG 13 GG 24 GG 23 Unified G GG 34 Choi et al. "StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation." CVPR 2018
44 StarGAN Goal / Problem Setting Single image translation model across multiple domains Unpaired training data
45 StarGAN Goal / Problem Setting Single Image translation model across multiple domains Unpaired training data Idea Concatenate image and target domain label as input of generator Auxiliary domain classifier on Discriminator Target domain Image
46 StarGAN Goal / Problem Setting Single Image translation model across multiple domains Unpaired training data Idea Concatenate image and target domain label as input of Generator Auxiliary domain classifier as discriminator too
47 StarGAN Goal / Problem Setting Single Image translation model across multiple domains Unpaired training data Idea Concatenate image and target domain label as input of Generator Auxiliary domain classifier on Discriminator Cycle consistency across domains
48 StarGAN Goal / Problem Setting Single Image translation model across multiple domains Unpaired training data Idea Auxiliary domain classifier as discriminator Concatenate image and target domain label as input Cycle consistency across domains
49 StarGAN Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D + L cccccc G G D
50 StarGAN Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D + L cccccc G G D Adversarial Loss G(xx, cc) yy Adversarial Loss L GGGGGG G, D = EE log 1 D(G(xx, cc)) + EE log D yy cc xx
51 StarGAN Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D + L cccccc G G D Domain Classification Loss G(xx, cc) yy Adversarial Loss L GGGGGG G, D = EE log 1 D(G(xx, cc)) + EE log D yy cc xx Domain Classification Loss (Disentanglement) L cccccc G, D = EE log D cls (cc yy) + EE log D cls (cc G(xx, cc))
52 StarGAN Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D + L cccccc G G D Domain Classification Loss G(xx, cc) yy Adversarial L GGGGGG G, D Loss = EE log 1 D(G(xx, cc)) + EE log D yy Domain Classification Loss (Disentanglement) L cccccc G, D = EE log D cls (cc yy) + EE log D cls (cc G(xx, cc)) cc xx D cls (cc yy) Real data w.r.t. its domain label
 D cls (cc G(xx, cc)) L cccccc G, D = EE log D cls (cc yy) + EE log D cls (cc G(xx, cc)) Generated data w.r.t. assigned label")
53 StarGAN Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D + L cccccc G G D Domain Classification Loss G(xx, cc) yy L GGGGGG G, D = EE log 1 D(G(xx, cc)) Adversarial Loss + EE log D yy cc xx Domain Classification Loss (Disentanglement) D cls (cc G(xx, cc)) L cccccc G, D = EE log D cls (cc yy) + EE log D cls (cc G(xx, cc)) Generated data w.r.t. assigned label
54 StarGAN Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D + L cccccc G G D Consistency Loss G(xx, cc) Adversarial Loss L GGGGGG G, D = EE log 1 D(G(xx, cc)) + EE log D yy cc xx L cccccc G, D = EE log D cls (cc yy) + EE log D cls (cc G(xx, cc)) Domain Classification Loss (Disentanglement) cc xx G G xx, cc, cc xx Cycle Consistency Loss L cccccc G = EE G G xx, cc, cc xx xx 1
 + EE log D cls (cc G(xx, cc)) Cycle Consistency Loss L cccccc G = EE G G xx, cc, cc xx xx")
55 StarGAN Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D + L cccccc G G D Adversarial Loss L GGGGGG G, D = EE log 1 D(G(xx, cc)) + EE log D yy Domain Classification Loss L cccccc G, D = EE log D cls (cc yy) + EE log D cls (cc G(xx, cc)) Cycle Consistency Loss L cccccc G = EE G G xx, cc, cc xx xx 1


56 StarGAN Example results StarGAN can somehow be viewed as a representation disentanglement model, instead of an image translation one. Multiple Domains Multiple Domains Github Page: Choi et al. "StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation." CVPR 2018
57 From Image Understanding to Image Manipulation Representation Disentanglement InfoGAN: Unsupervised representation disentanglement AC-GAN: Supervised representation disentanglement Image Translation Pix2pix (CVPR 17): Pairwise cross-domain training data CycleGAN/DualGAN/DiscoGAN: Unpaired cross-domain training data UNIT (NIPS 17): Learning cross-domain image representation (with unpaired training data) DTN (ICLR 17) : Learning cross-domain image representation (with unpaired training data) Joint Image Translation & Disentanglement StarGAN (CVPR 18) : Image translation via representation disentanglement CDRD (CVPR 18) : Cross-domain representation disentanglement and translation 57
58 Cross-Domain Representation Disnentanglement (CDRD) Goal / Problem Setting Learning cross-domain joint disentangled representation Single domain supervision Cross-domain image translation with attribute of interest Idea Bridge the domain gap across domains Auxiliary attribute classifier on Discriminator Semantics of disentangled factor is learned from label in source domain Joint Space Wang et al., Detach and Adapt: Learning Cross-Domain Disentangled Deep Representation. CVPR
59 CDRD Goal / Problem Setting Learning cross-domain joint disentangled representation Single domain supervision Cross-domain image translation with attribute of interest Supervised (w/ or w/o Eyeglass) Unsupervised Idea Bridge the domain gap across domains Auxiliary attribute classifier on Discriminator Semantics of disentangled factor is learned from label in source domain 59
60 CDRD Goal / Problem Setting Learning cross-domain joint disentangled representation Single domain supervision Cross-domain image translation with attribute of interest w/ eyeglasses w/o eyeglasses Idea Bridge the domain gap across domains Auxiliary attribute classifier on Discriminator Semantics of disentangled factor is learned from label in source domain w/ eyeglasses w/o eyeglasses 60
61 CDRD Goal / Problem Setting Learning cross-domain joint disentangled representation Single domain supervision Cross-domain image translation with attribute of interest Real or Fake D Discriminator Idea Based on GAN Auxiliary attribute classifier on Discriminator Bridge the domain gap across domains Semantics of disentangled factor is learned from label in source domain XX SS XX SS Generator G zz 61
62 CDRD Goal / Problem Setting Learning cross-domain joint disentangled representation Single domain supervision Cross-domain image translation with attribute of interest Real or Fake D Discriminator Classification w.r.t. ll SS or ll Idea Based on GAN Auxiliary attribute classifier as Discriminator Bridge the domain gap across domains Semantics of disentangled factor is learned from label in source domain XX SS Supervised ll SS XX SS Generator G zz ll 62
63 CDRD Goal / Problem Setting Learning cross-domain joint disentangled representation Single domain supervision Cross-domain image translation with attribute of interest Idea Based on GAN Auxiliary attribute classifier on Discriminator Bridge the domain gap with division of high and low-level layers Semantics of disentangled factor is learned from label in source domain 63
64 CDRD Goal / Problem Setting Learning cross-domain joint disentangled representation Single domain supervision Cross-domain image translation with attribute of interest Idea Based on GAN Auxiliary attribute classifier on Discriminator Bridge the domain gap with division of high- and lowlevel layer Semantics of disentangled factor is learned from label info in source domain 64

65 CDRD Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D G D 65
66 CDRD Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D G D Adversarial Loss SS TT L GGGGGG G, D = L GGGGGG G, D + L GGGGGG G, D SS G, D = EE log D CC (D S (XX SS )) + EE log 1 D CC (D S ( XX SS )) L GGGGGG TT G, D = EE log D CC (D T (XX TT )) + EE log 1 D CC (D T ( XX TT )) L GGGGGG 66
67 CDRD Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D G D Adversarial Loss SS L GGGGGG G, D = L GGGGGG TT G, D + L GGGGGG G, D SS L GGGGGG G, D = EE log D CC (D S (XX SS )) + EE log 1 D CC (D S ( XX SS )) TT L GGGGGG G, D = EE log D CC (D T (XX TT )) + EE log 1 D CC (D T ( XX TT )) Real 67
68 CDRD Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D G D Adversarial Loss SS L GGGGGG G, D = L GGGGGG TT G, D + L GGGGGG G, D SS L GGGGGG G, D = EE log D CC (D S (XX SS )) + EE log 1 D CC (D S ( XX SS )) TT L GGGGGG G, D = EE log D CC (D T (XX TT )) + EE log 1 D CC (D T ( XX TT )) Generated 68
69 CDRD Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D G D Adversarial Loss SS TT L GGGGGG G, D = L GGGGGG G, D + L GGGGGG G, D SS G, D = EE log D CC (D S (XX SS )) + EE log 1 D CC (D S ( XX SS )) TT G, D = EE log D CC (D T (XX TT )) + EE log 1 D CC (D T ( XX TT )) L GGGGGG L GGGGGG Disentangle Loss SS L cccccc G, D = L cccccc TT G, D + L cccccc G, D SS G, D = EE log PP(ll = ll XX SS ) + EE log PP(ll = ll SS XX SS ) L cccccc TT L cccccc G, D = EE log PP(ll = ll XX TT ) AC-GAN 69
70 CDRD Learning Overall objective function G = arg min max L GGGGGG G, D + L cccccc G, D G D Adversarial Loss SS TT L GGGGGG G, D = L GGGGGG G, D + L GGGGGG G, D SS G, D = EE log D CC (D S (XX SS )) + EE log 1 D CC (D S ( XX SS )) TT G, D = EE log D CC (D T (XX TT )) + EE log 1 D CC (D T ( XX TT )) L GGGGGG L GGGGGG Disentangle Loss SS L cccccc G, D = L cccccc TT G, D + L cccccc G, D SS G, D = EE log PP(ll = ll XX SS ) + EE log PP(ll = ll SS XX SS ) L cccccc TT L cccccc G, D = EE log PP(ll = ll XX TT ) InfoGAN 70



71 CDRD Add an additional encoder Input: Gaussian Noise Image Image translation with attribute of interest 71


72 CDRD Experiment results No Label Supervision Input Wang et al., Detach and Adapt: Learning Cross-Domain Disentangled Deep Representation. CVPR


73 CDRD Experiment results Cross-Domain Classification CVPR 13 CVPR 14 PAMI 17 CVPR 17 ICCV 15 ICML 15 NIPS 16 CVPR 17 ECCV 16 arxiv 16 Digits NIPS 16 NIPS 17 Face NIPS 16 NIPS 17 Scene Figure: t-sne for digit Wang et al., Detach and Adapt: Learning Cross-Domain Disentangled Deep Representation. CVPR

 O O O O Partially")
74 Comparisons Cross-Domain Image Translation Representation Disentanglement Unpaired Training Data Multidomains Bi-direction Joint Representation Unsupervised Interpretability of disentangled factor Pix2pix X X X X CycleGAN O X O X StarGAN O O O X Cannot disentangle representation UNIT O X O O DTN O X X O infogan Cannot translate image across domains O X AC-GAN X O CDRD (Ours) O O O O Partially O 74
75 What s to Be Covered Today Visualization of NNs t-sne Visualization of Feature Maps Neural Style Transfer Understanding NNs Image Translation Feature Disentanglement Recurrent Neural Networks LSTM & GRU Many slides from Fei-Fei Li, Bhiksha Raj, Yuying Yeh, and Hsuan-I Ho 75
76 What We Have Learned CNN for Image Classification DOG CAT MONKEY 76

77 What We Have Learned Generative Models (e.g., GAN) for Image Synthesis 77

78 But Is it sufficiently effective and robust to perform visual analysis from a single image? E.g., Are the hands of this man tied? 78

79 But Is it sufficiently effective and robust to perform visual analysis from a single image? E.g., Are the hands of this man tied? 79
80 So What Are The Limitations of CNN? Can t easily model series data Both input and output might be sequential data (scalar or vector) Simply feed-forward processing Cannot memorize, no long-term feedback DOG CAT MONKEY 80

81 Example of (Visual) Sequential Data 81

82 More Applications in Vision Image Captioning Figure from Vinyals et al, Show and tell: A neural image caption generator, CVPR

83 More Applications in Vision Visual Question Answering (VQA) Input output Figure from Zhu et al, Visual 7W: Grounded Question Answering in Images, CVPR
84 How to Model Sequential Data? Deep learning for sequential data Recurrent neural networks (RNN) 3-dimensional convolution neural networks RNN 3D convolution 84

85 Recurrent Neural Networks Parameter sharing + unrolling Keeps the number of parameters fixed Allows sequential data with varying lengths Memory ability Capture and preserve information which has been extracted 85
86 Recurrence Formula Same function and parameters used at every time step: h tt, yy tt = ff WW h tt 1, xx tt yy new state for time t output vector at time t state at time t-1 input vector at time t function with parameters W RNN xx 86
87 Recurrence Formula Same function and parameters used at every time step: h tt, yy tt = ff WW h tt 1, xx tt yy RNN h tt = ttttttt WW hh h tt 1 + WW xxx xx tt yy tt = WW hyy h tt xx 87
88 Multiple Recurrent Layers 88
89 Multiple Recurrent Layers 89
90 h 0 ff WW h 1 xx 1 90
91 h 0 ff WW h 1 ff WW h 2 xx 1 xx 2 91
92 h 0 ff WW h 1 ff WW h 2 ff WW h 3 h TT xx 1 xx 2 xx 3 92
93 W hh h 0 ff WW h 1 ff WW h 2 ff WW h 3 h TT xx 1 xx 2 xx 3 W xh 93
94 W hy yy 1 yy 2 yy 3 yy TT h 0 ff WW h 1 ff WW h 2 ff WW h 3 h TT xx 1 xx 2 xx 3 94

95 e.g., image caption e.g., action recognition e.g., video prediction e.g., video indexing 95


96 Example: Image Captioning Figure from Karpathy et a, Deep Visual-Semantic Alignments for Generating Image Descriptions, CVPR
97 CNN 97
98 98
99 99
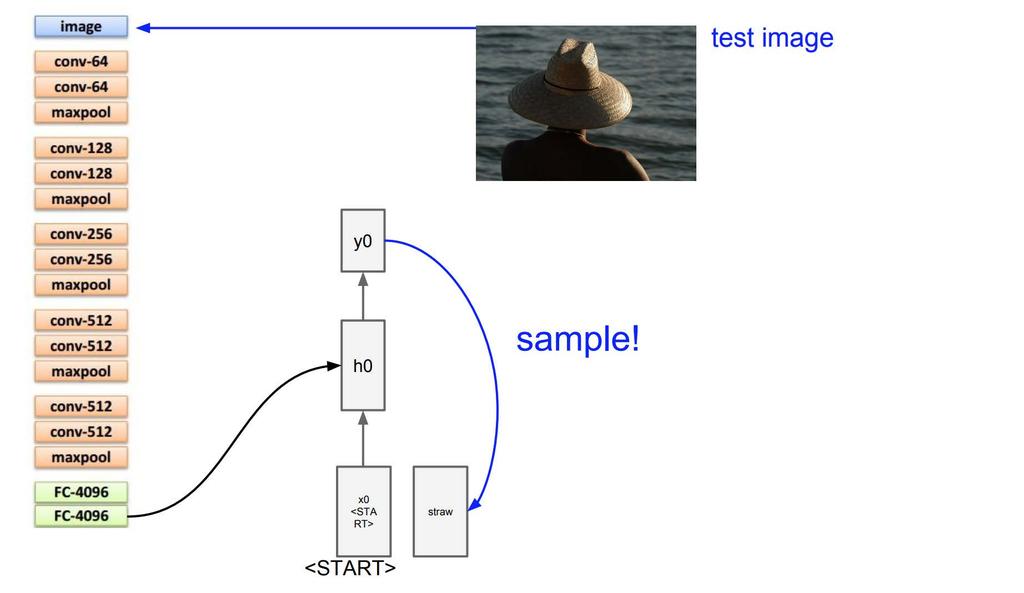
100 100
101 101
102 102
103 103

104 Example: Action Recognition Figure from Action Recognition in Video Sequences using Deep Bi-Directional LSTM With CNN Features 104
105 yy 1 yy 2 yy 3 yy TT h 0 ff WW h 1 ff WW h 2 ff WW h 3 h TT xx 1 xx 2 xx 3 105
106 golf standing exercise softmax yy 1 yy 2 yy 3 yy TT h 0 ff WW h 1 ff WW h 2 ff WW h 3 h TT xx 1 xx 2 xx 3 106

107 Back propagation through time cross entropy loss action label softmax yy 1 yy 2 yy 3 yy TT h 0 ff WW h 1 ff WW h 2 ff WW h 3 h TT xx 1 xx 2 xx 3 107
108 Back Propagation Through Time (BPTT) 108

109 Back Propagation Through Time (BPTT) Pascanu et al, On the difficulty of training recurrent neural networks, ICML
110 Training RNNs via BPTT 110
111 Training RNNs: Forward Pass Forward pass each training instance: Pass the entire data sequence through the net Generate outputs 111

112 Training RNNs: Computing Gradients After forward passing each training instance: Backward pass: compute gradients via BP More specifically, BPTT 112

113 Training RNNs: BPTT Let s focus on one training instance. The divergence computed is between the sequence of outputs by the network and the desired sequence of outputs. Generally, this is not just the sum of the divergences at individual times. 113
114 Gradient Vanishing & Exploding Computing gradient involves many factors of W Exploding gradients : Largest singular value > 1 Vanishing gradients : Largest singular value < 1 114

115 Solutions Gradients clipping : rescale gradients if too large standard gradient descent trajectories gradient clipping to fix problem How about vanishing gradients? 115
116 Variants of RNN Long Short-term Memory (LSTM) [Hochreiter et al., 1997] Additional memory cell Input/Forget/Output Gates Handle gradient vanishing Learn long-term dependencies Gated Recurrent Unit (GRU) [Cho et al., EMNLP 2014] Similar to LSTM No additional memory cell Reset / Update Gates Fewer parameters than LSTM Comparable performance to LSTM [Chung et al., NIPS Workshop 2014] 116
117 Vanilla RNN vs. LSTM LSTM Output in time t Input in time t Forget gate Input gate Input activation Output gate Cell state Hidden state Memory Cell Output in time t Input in time t 117

118 Long Short-Term Memory (LSTM) Forget gate Input gate Input activation Output gate Cell state Hidden state Memory Cell Output in time t Input in time t Image Credit: Hung-Yi Lee 118
119 Long Short-Term Memory (LSTM) Cell state Hidden state tanh tanh Forget gate Input gate Input activation Output gate Cell state Hidden state 119
120 Long Short-Term Memory (LSTM) Cell state Calculate forget gate f Forget gate Hidden state 120
121 Long Short-Term Memory (LSTM) Cell state Calculate forget gate f Input gate Hidden state 121
122 Long Short-Term Memory (LSTM) Cell state Calculate input activation Input activation tanh Hidden state 122
123 Long Short-Term Memory (LSTM) Cell state Calculate output gate Output gate tanh Hidden state 123
124 Long Short-Term Memory (LSTM) Cell state Update memory cell Hidden state tanh Cell state 124
125 Long Short-Term Memory (LSTM) Cell state Calculate output ht tanh tanh Hidden state Hidden state 125
126 Long Short-Term Memory (LSTM) Cell state Prevent gradient vanishing if forget gate is open (>0). tanh tanh Hidden state Remarks: - Forget gate f provides shortcut connection across time steps - Linear relationship between c t and c t-1 instead of multiplication relationship of h t and h t-1 in vanilla RNN 126
127 Variants of RNN Long Short-term Memory (LSTM) [Hochreiter et al., 1997] Additional memory cell Input / Forget / Output Gates Handle gradient vanishing Learn long-term dependencies Gated Recurrent Unit (GRU) [Cho et al., EMNLP 2014] Similar to LSTM No additional memory cell Reset/Update Gates Fewer parameters than LSTM Comparable performance to LSTM [Chung et al., NIPS Workshop 2014] 127
128 LSTM vs. GRU LSTM GRU Forget gate Input gate Input activation Output gate Cell state Hidden state Reset gate Update gate Input activation Hidden state 128
129 Gated Recurrent Unit (GRU) Hidden state tanh 129
130 Gated Recurrent Unit (GRU) Hidden state Calculate reset gate r Reset gate 130
131 Gated Recurrent Unit (GRU) Hidden state Calculate update gate z Update gate 131
132 Gated Recurrent Unit (GRU) Hidden state Calculate input activation tanh Input activation 132
133 Gated Recurrent Unit (GRU) Hidden state Calculate output tanh Hidden state 133
134 Gated Recurrent Unit (GRU) Hidden state Prevent gradient vanishing if update gate is open! tanh Remarks: - Update gate z provides shortcut connection across time steps - Linear relationship between ht and ht-1 instead of multiplication relationship of ht and ht-1 in vanilla RNN 134
135 Vanilla RNN, LSTM, & GRU yy RNN Output in time t Input in time t xx tanh tanh tanh 135
136 LSTM vs. GRU Cell state Number of Gates Parameters Gradient Vanishing / Exploding Vanilla RNN LSTM GRU 136
137 References book VT CS231n Jia-Bing Huang MLDS adl/doc/ _attention.pdf 137
138 Web Tutorial
139 What We ve Learned Today Understanding NNs Image Translation Feature Disentanglement Recurrent Neural Networks LSTM & GRU HW4 is due 5/18 Fri 23:59! 139
Slide credit from Hung-Yi Lee & Richard Socher
 Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Recurrent Neural Networks (RNN) and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST
 and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST") 1 Recurrent Neural Networks (RNN) and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST Summary We have shown: Now First order optimization methods: GD (BP), SGD, Nesterov, Adagrad, ADAM, RMSPROP, etc. Second
1 Recurrent Neural Networks (RNN) and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST Summary We have shown: Now First order optimization methods: GD (BP), SGD, Nesterov, Adagrad, ADAM, RMSPROP, etc. Second
Deep Learning. Recurrent Neural Network (RNNs) Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning
 Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning") Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Lecture 14: Deep Generative Learning
 Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
arxiv: v3 [cs.lg] 14 Jan 2018
![arxiv: v3 [cs.lg] 14 Jan 2018](/thumbs/92/109503708.jpg "arxiv: v3 [cs.lg] 14 Jan 2018") A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Recurrent Neural Network
 Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Introduction to RNNs!
 Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Deep Generative Models. (Unsupervised Learning)
") Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What
Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
 2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook
 Sumit Chopra Facebook") Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Recurrent neural networks
 12-1: Recurrent neural networks Prof. J.C. Kao, UCLA Recurrent neural networks Motivation Network unrollwing Backpropagation through time Vanishing and exploding gradients LSTMs GRUs 12-2: Recurrent neural
12-1: Recurrent neural networks Prof. J.C. Kao, UCLA Recurrent neural networks Motivation Network unrollwing Backpropagation through time Vanishing and exploding gradients LSTMs GRUs 12-2: Recurrent neural
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Neural Networks Language Models
 Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
RECURRENT NETWORKS I. Philipp Krähenbühl
 RECURRENT NETWORKS I Philipp Krähenbühl RECAP: CLASSIFICATION conv 1 conv 2 conv 3 conv 4 1 2 tu RECAP: SEGMENTATION conv 1 conv 2 conv 3 conv 4 RECAP: DETECTION conv 1 conv 2 conv 3 conv 4 RECAP: GENERATION
RECURRENT NETWORKS I Philipp Krähenbühl RECAP: CLASSIFICATION conv 1 conv 2 conv 3 conv 4 1 2 tu RECAP: SEGMENTATION conv 1 conv 2 conv 3 conv 4 RECAP: DETECTION conv 1 conv 2 conv 3 conv 4 RECAP: GENERATION
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Recurrent Neural Networks Deep Learning Lecture 5. Efstratios Gavves
 Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Generative adversarial networks
 14-1: Generative adversarial networks Prof. J.C. Kao, UCLA Generative adversarial networks Why GANs? GAN intuition GAN equilibrium GAN implementation Practical considerations Much of these notes are based
14-1: Generative adversarial networks Prof. J.C. Kao, UCLA Generative adversarial networks Why GANs? GAN intuition GAN equilibrium GAN implementation Practical considerations Much of these notes are based
The Success of Deep Generative Models
 The Success of Deep Generative Models Jakub Tomczak AMLAB, University of Amsterdam CERN, 2018 What is AI about? What is AI about? Decision making: What is AI about? Decision making: new data High probability
The Success of Deep Generative Models Jakub Tomczak AMLAB, University of Amsterdam CERN, 2018 What is AI about? What is AI about? Decision making: What is AI about? Decision making: new data High probability
High Order LSTM/GRU. Wenjie Luo. January 19, 2016
 High Order LSTM/GRU Wenjie Luo January 19, 2016 1 Introduction RNN is a powerful model for sequence data but suffers from gradient vanishing and explosion, thus difficult to be trained to capture long
High Order LSTM/GRU Wenjie Luo January 19, 2016 1 Introduction RNN is a powerful model for sequence data but suffers from gradient vanishing and explosion, thus difficult to be trained to capture long
Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net
 Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net Supplementary Material Xingang Pan 1, Ping Luo 1, Jianping Shi 2, and Xiaoou Tang 1 1 CUHK-SenseTime Joint Lab, The Chinese University
Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net Supplementary Material Xingang Pan 1, Ping Luo 1, Jianping Shi 2, and Xiaoou Tang 1 1 CUHK-SenseTime Joint Lab, The Chinese University
Stephen Scott.
 1 / 35 (Adapted from Vinod Variyam and Ian Goodfellow) sscott@cse.unl.edu 2 / 35 All our architectures so far work on fixed-sized inputs neural networks work on sequences of inputs E.g., text, biological
1 / 35 (Adapted from Vinod Variyam and Ian Goodfellow) sscott@cse.unl.edu 2 / 35 All our architectures so far work on fixed-sized inputs neural networks work on sequences of inputs E.g., text, biological
EE-559 Deep learning LSTM and GRU
 EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Lecture 15: Exploding and Vanishing Gradients
 Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Deep Learning Recurrent Networks 10/11/2017
 Deep Learning Recurrent Networks 10/11/2017 1 Which open source project? Related math. What is it talking about? And a Wikipedia page explaining it all The unreasonable effectiveness of recurrent neural
Deep Learning Recurrent Networks 10/11/2017 1 Which open source project? Related math. What is it talking about? And a Wikipedia page explaining it all The unreasonable effectiveness of recurrent neural
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation
 Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
Generative Adversarial Networks, and Applications
 Generative Adversarial Networks, and Applications Ali Mirzaei Nimish Srivastava Kwonjoon Lee Songting Xu CSE 252C 4/12/17 2/44 Outline: Generative Models vs Discriminative Models (Background) Generative
Generative Adversarial Networks, and Applications Ali Mirzaei Nimish Srivastava Kwonjoon Lee Songting Xu CSE 252C 4/12/17 2/44 Outline: Generative Models vs Discriminative Models (Background) Generative
CSC321 Lecture 10 Training RNNs
 CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Sequence Models. Ji Yang. Department of Computing Science, University of Alberta. February 14, 2018
 Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM
![a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM](/thumbs/92/107948882.jpg "a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM") c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Convolutional Neural Network. Hung-yi Lee
 al Neural Network Hung-yi Lee Why CNN for Image? [Zeiler, M. D., ECCV 2014] x 1 x 2 Represented as pixels x N The most basic classifiers Use 1 st layer as module to build classifiers Use 2 nd layer as
al Neural Network Hung-yi Lee Why CNN for Image? [Zeiler, M. D., ECCV 2014] x 1 x 2 Represented as pixels x N The most basic classifiers Use 1 st layer as module to build classifiers Use 2 nd layer as
Structured Neural Networks (I)
") Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
Multimodal context analysis and prediction
 Multimodal context analysis and prediction Valeria Tomaselli (valeria.tomaselli@st.com) Sebastiano Battiato Giovanni Maria Farinella Tiziana Rotondo (PhD student) Outline 2 Context analysis vs prediction
Multimodal context analysis and prediction Valeria Tomaselli (valeria.tomaselli@st.com) Sebastiano Battiato Giovanni Maria Farinella Tiziana Rotondo (PhD student) Outline 2 Context analysis vs prediction
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Neural Architectures for Image, Language, and Speech Processing
 Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Spatial Transformation
 Spatial Transformation Presented by Liqun Chen June 30, 2017 1 Overview 2 Spatial Transformer Networks 3 STN experiments 4 Recurrent Models of Visual Attention (RAM) 5 Recurrent Models of Visual Attention
Spatial Transformation Presented by Liqun Chen June 30, 2017 1 Overview 2 Spatial Transformer Networks 3 STN experiments 4 Recurrent Models of Visual Attention (RAM) 5 Recurrent Models of Visual Attention
A Unified View of Deep Generative Models
 SAILING LAB Laboratory for Statistical Artificial InteLigence & INtegreative Genomics A Unified View of Deep Generative Models Zhiting Hu and Eric Xing Petuum Inc. Carnegie Mellon University 1 Deep generative
SAILING LAB Laboratory for Statistical Artificial InteLigence & INtegreative Genomics A Unified View of Deep Generative Models Zhiting Hu and Eric Xing Petuum Inc. Carnegie Mellon University 1 Deep generative
Spatial Transformer. Ref: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transformer Networks, NIPS, 2015
 Spatial Transormer Re: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transormer Networks, NIPS, 2015 Spatial Transormer Layer CNN is not invariant to scaling and rotation
Spatial Transormer Re: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transormer Networks, NIPS, 2015 Spatial Transormer Layer CNN is not invariant to scaling and rotation
Recurrent Neural Networks (RNNs) Lecture 9 - Networks for Sequential Data RNNs & LSTMs. RNN with no outputs. RNN with no outputs
 Lecture 9 - Networks for Sequential Data RNNs & LSTMs. RNN with no outputs. RNN with no outputs") Recurrent Neural Networks (RNNs) RNNs are a family of networks for processing sequential data. Lecture 9 - Networks for Sequential Data RNNs & LSTMs DD2424 September 6, 2017 A RNN applies the same function
Recurrent Neural Networks (RNNs) RNNs are a family of networks for processing sequential data. Lecture 9 - Networks for Sequential Data RNNs & LSTMs DD2424 September 6, 2017 A RNN applies the same function
TUTORIAL PART 1 Unsupervised Learning
 TUTORIAL PART 1 Unsupervised Learning Marc'Aurelio Ranzato Department of Computer Science Univ. of Toronto ranzato@cs.toronto.edu Co-organizers: Honglak Lee, Yoshua Bengio, Geoff Hinton, Yann LeCun, Andrew
TUTORIAL PART 1 Unsupervised Learning Marc'Aurelio Ranzato Department of Computer Science Univ. of Toronto ranzato@cs.toronto.edu Co-organizers: Honglak Lee, Yoshua Bengio, Geoff Hinton, Yann LeCun, Andrew
Speech and Language Processing
 Speech and Language Processing Lecture 5 Neural network based acoustic and language models Information and Communications Engineering Course Takahiro Shinoaki 08//6 Lecture Plan (Shinoaki s part) I gives
Speech and Language Processing Lecture 5 Neural network based acoustic and language models Information and Communications Engineering Course Takahiro Shinoaki 08//6 Lecture Plan (Shinoaki s part) I gives
Domain adaptation for deep learning
 What you saw is not what you get Domain adaptation for deep learning Kate Saenko Successes of Deep Learning in AI A Learning Advance in Artificial Intelligence Rivals Human Abilities Deep Learning for
What you saw is not what you get Domain adaptation for deep learning Kate Saenko Successes of Deep Learning in AI A Learning Advance in Artificial Intelligence Rivals Human Abilities Deep Learning for
Recurrent Neural Networks. deeplearning.ai. Why sequence models?
 Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Deep Learning Architectures and Algorithms
 Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
An overview of deep learning methods for genomics
 An overview of deep learning methods for genomics Matthew Ploenzke STAT115/215/BIO/BIST282 Harvard University April 19, 218 1 Snapshot 1. Brief introduction to convolutional neural networks What is deep
An overview of deep learning methods for genomics Matthew Ploenzke STAT115/215/BIO/BIST282 Harvard University April 19, 218 1 Snapshot 1. Brief introduction to convolutional neural networks What is deep
Multimodal Machine Learning
 Multimodal Machine Learning Louis-Philippe (LP) Morency CMU Multimodal Communication and Machine Learning Laboratory [MultiComp Lab] 1 CMU Course 11-777: Multimodal Machine Learning 2 Lecture Objectives
Multimodal Machine Learning Louis-Philippe (LP) Morency CMU Multimodal Communication and Machine Learning Laboratory [MultiComp Lab] 1 CMU Course 11-777: Multimodal Machine Learning 2 Lecture Objectives
Generating Sequences with Recurrent Neural Networks
 Generating Sequences with Recurrent Neural Networks Alex Graves University of Toronto & Google DeepMind Presented by Zhe Gan, Duke University May 15, 2015 1 / 23 Outline Deep recurrent neural network based
Generating Sequences with Recurrent Neural Networks Alex Graves University of Toronto & Google DeepMind Presented by Zhe Gan, Duke University May 15, 2015 1 / 23 Outline Deep recurrent neural network based
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
RECURRENT NEURAL NETWORKS WITH FLEXIBLE GATES USING KERNEL ACTIVATION FUNCTIONS
 2018 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 17 20, 2018, AALBORG, DENMARK RECURRENT NEURAL NETWORKS WITH FLEXIBLE GATES USING KERNEL ACTIVATION FUNCTIONS Simone Scardapane,
2018 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 17 20, 2018, AALBORG, DENMARK RECURRENT NEURAL NETWORKS WITH FLEXIBLE GATES USING KERNEL ACTIVATION FUNCTIONS Simone Scardapane,
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Long Short- Term Memory (LSTM) M1 Yuichiro Sawai Computa;onal Linguis;cs Lab. January 15, Deep Lunch
 M1 Yuichiro Sawai Computa;onal Linguis;cs Lab. January 15, Deep Lunch") Long Short- Term Memory (LSTM) M1 Yuichiro Sawai Computa;onal Linguis;cs Lab. January 15, 2015 @ Deep Lunch 1 Why LSTM? OJen used in many recent RNN- based systems Machine transla;on Program execu;on Can
Long Short- Term Memory (LSTM) M1 Yuichiro Sawai Computa;onal Linguis;cs Lab. January 15, 2015 @ Deep Lunch 1 Why LSTM? OJen used in many recent RNN- based systems Machine transla;on Program execu;on Can
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Normalization Techniques in Training of Deep Neural Networks
 Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
UNSUPERVISED LEARNING
 UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials
 Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials Contents 1 Pseudo-code for the damped Gauss-Newton vector product 2 2 Details of the pathological synthetic problems
Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials Contents 1 Pseudo-code for the damped Gauss-Newton vector product 2 2 Details of the pathological synthetic problems
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Deep Recurrent Neural Networks
 Deep Recurrent Neural Networks Artem Chernodub e-mail: a.chernodub@gmail.com web: http://zzphoto.me ZZ Photo IMMSP NASU 2 / 28 Neuroscience Biological-inspired models Machine Learning p x y = p y x p(x)/p(y)
Deep Recurrent Neural Networks Artem Chernodub e-mail: a.chernodub@gmail.com web: http://zzphoto.me ZZ Photo IMMSP NASU 2 / 28 Neuroscience Biological-inspired models Machine Learning p x y = p y x p(x)/p(y)
Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting 卷积 LSTM 网络 : 利用机器学习预测短期降雨 施行健 香港科技大学 VALSE 2016/03/23
 Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting 卷积 LSTM 网络 : 利用机器学习预测短期降雨 施行健 香港科技大学 VALSE 2016/03/23 Content Quick Review of Recurrent Neural Network Introduction
Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting 卷积 LSTM 网络 : 利用机器学习预测短期降雨 施行健 香港科技大学 VALSE 2016/03/23 Content Quick Review of Recurrent Neural Network Introduction
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function
 Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
CSC321 Lecture 20: Reversible and Autoregressive Models
 CSC321 Lecture 20: Reversible and Autoregressive Models Roger Grosse Roger Grosse CSC321 Lecture 20: Reversible and Autoregressive Models 1 / 23 Overview Four modern approaches to generative modeling:
CSC321 Lecture 20: Reversible and Autoregressive Models Roger Grosse Roger Grosse CSC321 Lecture 20: Reversible and Autoregressive Models 1 / 23 Overview Four modern approaches to generative modeling:
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1
 What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
Towards a Data-driven Approach to Exploring Galaxy Evolution via Generative Adversarial Networks
 Towards a Data-driven Approach to Exploring Galaxy Evolution via Generative Adversarial Networks Tian Li tian.li@pku.edu.cn EECS, Peking University Abstract Since laboratory experiments for exploring astrophysical
Towards a Data-driven Approach to Exploring Galaxy Evolution via Generative Adversarial Networks Tian Li tian.li@pku.edu.cn EECS, Peking University Abstract Since laboratory experiments for exploring astrophysical
Natural Language Processing
 Natural Language Processing Pushpak Bhattacharyya CSE Dept, IIT Patna and Bombay LSTM 15 jun, 2017 lgsoft:nlp:lstm:pushpak 1 Recap 15 jun, 2017 lgsoft:nlp:lstm:pushpak 2 Feedforward Network and Backpropagation
Natural Language Processing Pushpak Bhattacharyya CSE Dept, IIT Patna and Bombay LSTM 15 jun, 2017 lgsoft:nlp:lstm:pushpak 1 Recap 15 jun, 2017 lgsoft:nlp:lstm:pushpak 2 Feedforward Network and Backpropagation
CSCI 315: Artificial Intelligence through Deep Learning
 CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Lecture given by Daniel Khashabi Slides were created
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Lecture given by Daniel Khashabi Slides were created
Conditional Language modeling with attention
 Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
COMPARING FIXED AND ADAPTIVE COMPUTATION TIME FOR RE-
 Workshop track - ICLR COMPARING FIXED AND ADAPTIVE COMPUTATION TIME FOR RE- CURRENT NEURAL NETWORKS Daniel Fojo, Víctor Campos, Xavier Giró-i-Nieto Universitat Politècnica de Catalunya, Barcelona Supercomputing
Workshop track - ICLR COMPARING FIXED AND ADAPTIVE COMPUTATION TIME FOR RE- CURRENT NEURAL NETWORKS Daniel Fojo, Víctor Campos, Xavier Giró-i-Nieto Universitat Politècnica de Catalunya, Barcelona Supercomputing
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
CSC321 Lecture 20: Autoencoders
 CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
Support Vector Machines. CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Machine Learning Summer 2018 Exercise Sheet 4
 Ludwig-Maimilians-Universitaet Muenchen 17.05.2018 Institute for Informatics Prof. Dr. Volker Tresp Julian Busch Christian Frey Machine Learning Summer 2018 Eercise Sheet 4 Eercise 4-1 The Simpsons Characters
Ludwig-Maimilians-Universitaet Muenchen 17.05.2018 Institute for Informatics Prof. Dr. Volker Tresp Julian Busch Christian Frey Machine Learning Summer 2018 Eercise Sheet 4 Eercise 4-1 The Simpsons Characters
Memory-Augmented Attention Model for Scene Text Recognition
 Memory-Augmented Attention Model for Scene Text Recognition Cong Wang 1,2, Fei Yin 1,2, Cheng-Lin Liu 1,2,3 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences
Memory-Augmented Attention Model for Scene Text Recognition Cong Wang 1,2, Fei Yin 1,2, Cheng-Lin Liu 1,2,3 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Long-Short Term Memory
 Long-Short Term Memory Sepp Hochreiter, Jürgen Schmidhuber Presented by Derek Jones Table of Contents 1. Introduction 2. Previous Work 3. Issues in Learning Long-Term Dependencies 4. Constant Error Flow
Long-Short Term Memory Sepp Hochreiter, Jürgen Schmidhuber Presented by Derek Jones Table of Contents 1. Introduction 2. Previous Work 3. Issues in Learning Long-Term Dependencies 4. Constant Error Flow
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Learning Long-Term Dependencies with Gradient Descent is Difficult
 Learning Long-Term Dependencies with Gradient Descent is Difficult Y. Bengio, P. Simard & P. Frasconi, IEEE Trans. Neural Nets, 1994 June 23, 2016, ICML, New York City Back-to-the-future Workshop Yoshua
Learning Long-Term Dependencies with Gradient Descent is Difficult Y. Bengio, P. Simard & P. Frasconi, IEEE Trans. Neural Nets, 1994 June 23, 2016, ICML, New York City Back-to-the-future Workshop Yoshua
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
TTIC 31230, Fundamentals of Deep Learning David McAllester, April Vanishing and Exploding Gradients. ReLUs. Xavier Initialization
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
Recurrent Autoregressive Networks for Online Multi-Object Tracking. Presented By: Ishan Gupta
 Recurrent Autoregressive Networks for Online Multi-Object Tracking Presented By: Ishan Gupta Outline Multi Object Tracking Recurrent Autoregressive Networks (RANs) RANs for Online Tracking Other State
Recurrent Autoregressive Networks for Online Multi-Object Tracking Presented By: Ishan Gupta Outline Multi Object Tracking Recurrent Autoregressive Networks (RANs) RANs for Online Tracking Other State
Recurrent Neural Networks
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)