CSC 578 Neural Networks and Deep Learning
|
|
|
- Kathryn Harmon
- 5 years ago
- Views:
Transcription
1 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1
2 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross Entropy Log likelihood 2. Regularization L2 regularization L1 regularization Dropout Data expansion 3. Initial weights 4. Hyper-parameters Hessian technique Momentum 5. Other approaches to minimize error/cost Conjugate gradient L-BFGS 6. Other Activation/transfer functions Tanh Rectified Linear Unit (ReLU) Softmax 2
3 For classification: Quadratic 1 Various Cost Functions Cross Entropy CC = 1 nn xx y(x) ln aa (1 yy(xx)) ln(1 aa) Likelihood CC = 1 nn xx ln aa yy LL usually used with Softmax activation function (for multiple output nodes) For regression: Mean Squared Error (MSE) CC = 1 nn (yy xx aa) 2 xx Or Root Mean Squared Error (RMSE) 3
4 Differentials of Cost Functions General form (in gradient): For a cost function C and an activation function a (and z is the weighted sum, zz = ww ii xx ii ), Quadratic: CC = CC ww ii aa CC = CC ww ii ww ii aa zz = 1 2nn (yy xx aa) 2 xx = 1 2nn 2 yy xx aa xx = 1 nn (yy xx aa) xx zz ww ii ww ii ww ii ww ii 4
5 Cross Entropy: CC = CC ww ii ww ii = 1 nn xx yy xx ln aa (1 yy xx ) ln(1 aa) ww ii = 1 nn xx yy xx ln aa + (1 yy xx ) ln(1 aa) ww ii = 1 nn xx yy xx aa + 1 yy xx ln 1 aa ww ii = 1 nn xx yy xx aa 1 yy xx + 1 aa ( 1) ww ii = 1 nn xx aa yy xx aa (1 aa) ww ii 5
6 Log Likelihood, for one data instance <x, y>: CC = CC ww ii ww ii = aa kk ln aa yy LL ww ii = 1 aa yy LL ww ii where aa yy LL is the y th activation value where y is the index of the target category. The derivative values for all other components are 0. A good reference on cross-entropy cost function is at 6
7 1.1 Cross Entropy Since sigmoid curve is flat on both ends, cost functions whose gradient include sigmoid is slow to converge (to minimize the cost), especially when the output is very far from the target. Using sigmoid neurons but with a different cost function, in particular Cross Entropy, helps speed up convergence. With Cross Entropy, C is always > 0. where y is the target output, and a = network output 7
8 Cross-entropy cost (or loss ) can be divided into two separate cost functions: one for y=1 and one for y=0. The two cases are combined into one expression (since the cases are mutually exclusive). If y=0, the first side cancels out. If y=1, the second side cancels out. In both cases we only perform the operation we need to perform. ML Cheatsheet, 8
9 Differentials of the cost functions when aa = σσ(zz): Quadratic = ww jj aa aa zz zz ww jj = 1 nn xx σσ(zz) yy σσ zz xx jj Cross-Entropy = ww jj aa aa zz zz ww jj = 1 nn xx σσ zz yy σσ zz 1 σσ zz σσ zz xx jj = 1 nn xx (σσ zz yy) xx jj o Since the gradient of Cross-Entropy s formula removes the term σσ (zz), the weight convergence could become faster. o This also affects the BP algorithm, since the errors become different: o Step 3: Output error: δδ LL = aa LL yy o Step 4: Backpropagate the error: δδ ll = ww ll+1 TT δδ ll+1 o Step 5: Weight update is the same: ww jjjj = ηη δδ jj xx ii 9
10 10
11 You can specify the cost function in the constructor call (by cost= ). 11
12 1.2 Log Likelihood Log likelihood (or Maximum Likelihood Estimate) is essentially equivalent to cross entropy, but for multiple outcomes. CC = 1 nn xx ln aa yy LL where aa LL yy is the y th activation value where y is the index of the target category. Log likelihood cost function is used when the activation function is Softmax (applicable only when there are multiple output nodes). Softmax converts the activation values in the output layer to a probability distribution. where zz jj LL = mm ww jjjj LL aa mm LL 1 + bb jj LL 12
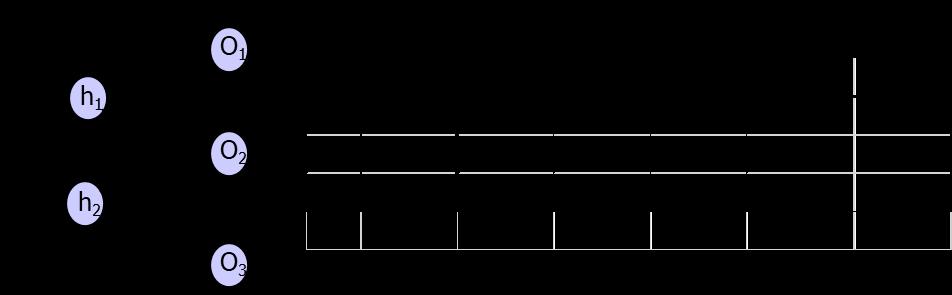
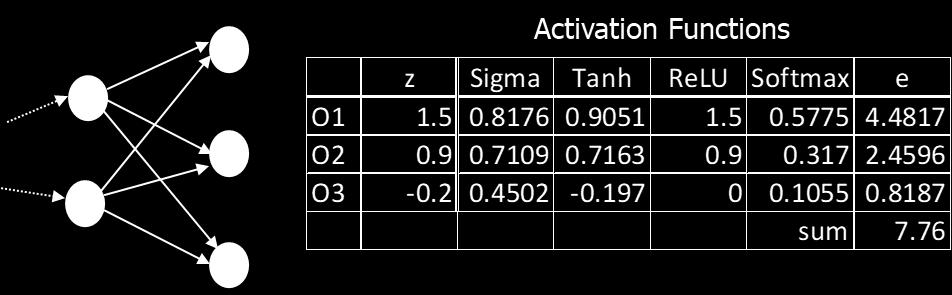
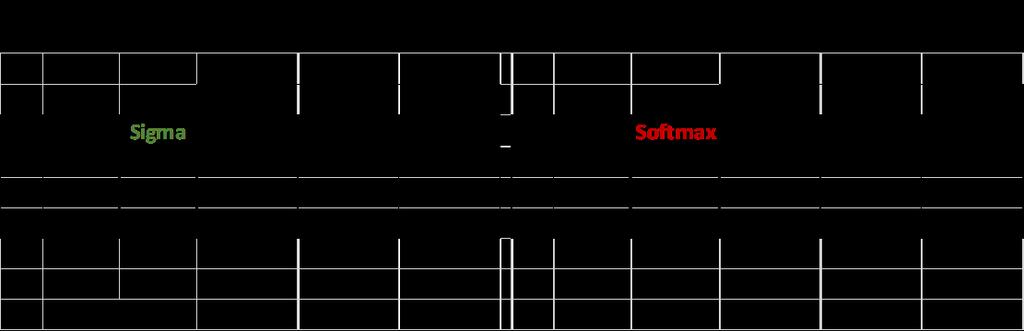
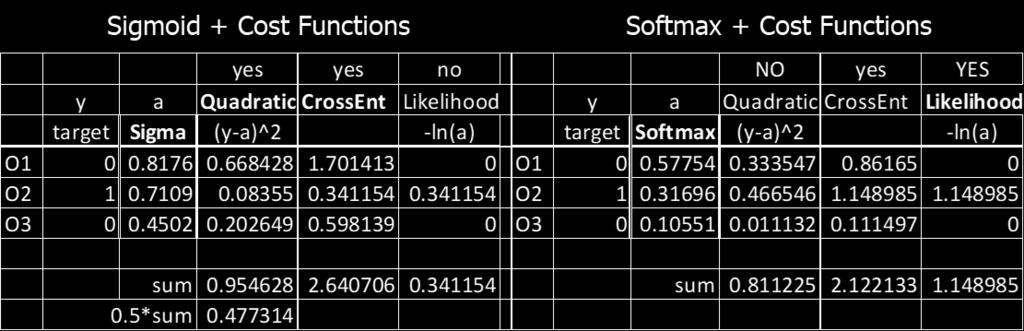
13 13
14 2 Regularization Methods Overfitting is a big problem in Machine Learning. Regularization is applied in Neural Networks to avoid overfitting. There are several regularization methods, such as: Weight decay / L2, L1 normalization Dropout Artificially enhancing the training data 14
15 Weight decay. 2.1 L2 Regularization Add an extra term, a quadratic values of the weights, in the cost function: For Cross-Entropy: For Quadratic: The extra term causes the gradient descent search to seek weight vectors with small magnitudes, thereby reducing the risk of overfitting (by biasing against complex model). 15
16 Differentials of the cost function with L2 regularization. An extra term for weights: No change for bias: Weight update rule in the BP algorithm: o A negative value ηηλλ nn ww in weights => weight decay: o No change for bias: 16
17 17
18 18
19 2.2 L1 Regularlization Similar to L1, but adds an extra term that is the absolute values of the weights in the cost function: Differentials of the cost function with L1 regularlization. An extra term for weights: where sgn ww = +1 if ww > 0 0 if ww == 0 1 if ww < 0 19
20 Weight update rule in the BP algorithm: o A negative value ηηλλ nn ssssss(ww) in weights => weight decay o No change for bias 20
21 L2 vs. L1 In L1 regularization, the weights shrink by a constant amount toward 0. In L2 regularization, the weights shrink by an amount which is proportional to w. So when a particular weight has a large magnitude, w, L1 regularization shrinks the weight much less than L2 regularization does. By contrast, when w is small, L1 regularization shrinks the weight much more than L2 regularization. The net result is that L1 regularization tends to concentrate the weight of the network in a relatively small number of high-importance connections, while the other weights are driven toward zero. 21
22 2.3 Dropout Dropout modifies the network by periodically disconnecting some nodes in the network. We start by randomly (and temporarily) deleting half the hidden neurons in the network, while leaving the input and output neurons untouched. We forward-propagate the input x through the modified network, and then backpropagate the result, also through the modified network. We then repeat the process, first restoring the dropout neurons, then choosing a new random subset of hidden neurons to delete,.. 22
23 Robustness (and generalization power) of dropout: Heuristically, when we dropout different sets of neurons, it's rather like we're training different neural networks. And so the dropout procedure is like averaging the effects of a very large number of different networks. The different networks will overfit in different ways, and so, hopefully, the net effect of dropout will be to reduce overfitting. we can think of dropout as a way of making sure that the model is robust to the loss of any individual piece of evidence. Dropout has been shown to be effective especially in training large, deep networks, where the problem of overfitting is often acute. 23
24 2.4 Artificial Expansion of Data In general, neural networks learn better with larger training data. We can expand the data by inserting artificially generated data instances obtained by distorting the original data. The general principle is to expand the training data by applying operations that reflect real-world variation. 24
 Gaussian (µ = 0, σ = 1) Gaussian (µ = 0, σ = 1 for bias, for weights on the input layer, nn iiii")
25 3 Initial Weights Setting good values for the initial weights could speed up the learning (convergence). Common values: Uniform random (in a fixed range) Gaussian (µ = 0, σ = 1) Gaussian (µ = 0, σ = 1 for bias, for weights on the input layer, nn iiii where nn iiii is the number of nodes) 1 25
26 4 Hyper-parameters How do we set good values for hyper parameters such as η (learning rate), λ (regularization parameter) to speed up the experimentation? A broad strategy is to try to obtain a signal during the early stages of experiment that gives a promising result. From there, you tweak hyper-parameters. Heuristics for specific hyper-parameters. 1. Learning rate: Try values of different magnitude, e.g , 0.25, Number of epochs: Try early stopping and monitor overfitting. 3. Regularization parameter: Start with 0 and fix η. Then try 1.0, then * or / by
27 5 Other Cost-minimization Techniques In addition to Stochastic Gradient Descent, there are other techniques to minimize cost function: 1. Hessian technique 2. Momentum 3. Other learning techniques 27
28 5.1 Hessian Technique The Hessian matrix or Hessian is a square matrix of second-order partial derivatives of a scalar-valued function (of many variables), ff: R nn R. Hessian is used to approximate the minimization of cost function. First approximate C(w) by CC ww = CC ww + ww at a point w (based on Taylor Series). That gives By dropping higher order terms above quadratic, we have Finally we set ww = HH 1 CC to minimize CC ww + ww. 28
29 Then in the algorithm, the weight update becomes ww + ww = ww HH 1 CC The Hessian technique incorporates information about second-order changes in the cost function, and has been shown to converge to a minimum faster. However, computing H at every step, for every weight, is computationally costly (with regard to memory as well computation time). 29
30 5.2 Momentum The momentum method is similar to Hessian in that it incorporates the second-order changes in the cost function as an analogical notion of velocity. Stochastic gradient descent with momentum remembers the update Δw at each iteration, and determines the next update as a linear combination of the gradient (ηη CC) and the previous update (α ww), that is, ww = α ww ηη CC and the base weight update rule: ww = ww + ww gives the final weight update formula ww + ww = ww + (α ww ηη CC) [Wikipedia] Momentum adds extra term for the same direction, thereby preventing oscillation. 30
31 5.3 Other Learning Techniques Resilient Propagation: Use only the magnitude of the gradient and allow each neuron to learn at its own rate. No need for learning rate/momentum; however, only works in full batch mode. Nesterov accelerated gradient: Helps mitigate the risk of choosing a bad mini-batch. Adagrad: Allows an automatically decaying per-weight learning rate and momentum concept. Adadelta: Extension of Adagrad that seeks to reduce its aggressive, monotonically decreasing learning rate. Non-Gradient Methods: Non-gradient methods can sometimes be useful, though rarely outperform gradient-based backpropagation methods. These include: simulated annealing, genetic algorithms, particle swarm optimization, Nelder Mead, and many more. 31
32 6 Other Neuron Types In addition to sigmoid, there are other types of neurons(with different activation functions), for example: 1. Tanh 2. Rectified Linear Unit (ReLU) 3. Softmax A good reference on various activation functions is found at ml?highlight=softmax 32
33 6.1 Tanh (Hyperbolic Tangent) Definition: tanh zz = eezz ee zz ee zz + ee zz The range of tanh is between -1 and 1 (rather than 0 and 1). Tanh is also a transformation of sigmoid: σσ zz = 1+tanh h 2 2 Derivative: Let y = ff zz = eezz ee zz ee zz + ee zz yy = ff xx = 1 yy 2, with ff 0 = 0 33
34 6.2 ReLU (Rectified Linear Unit) Definition:ff zz = zz + = max(0, zz) This function is also called a Ramp function. Advantage -- Neurons do not saturate when z > 0. Disadvantage -- Gradient vanishes when z < 0. Derivative: ff zz = 1, zz > 0 0, zz 0 But the function is technically NOT differentiable at 0. => 0 is arbitrarily substituted above. 34
35 6.3 Softmax Softmax function can be applied to neurons on the output layer only. where zz jj LL = mm ww jjjj LL aa mm LL 1 + bb jj LL First the function ensures all values are positive by taking the exponent. Then it normalizes the resulting values and makes them a probability distribution (which sum up to 1). And if we use the log likelihood as the cost function CC = ln aa yy LL, we have the error δδ jj LL = aa jj LL yy ii and derivatives: 35
 is a 2D matrix, NOT a vector because the activation of a j depends on all other activations ( kk aa kk ).")
36 Derivative of Softmax The derivative of Softmax (for a layer of node activations a 1... a n ) is a 2D matrix, NOT a vector because the activation of a j depends on all other activations ( kk aa kk ). Derivative: Let ss ii = eezz ii kk ee zz kk ss ii = ss ii 1 ss jj when ii = jj aa jj ss ii ss jj when ii jj References: [1] Eli Bendersky [2] Aerin Kim 36

37 Softmax activation + LogLikelihood cost function: 37
38 7 Two Problems to review 1. Vanishing Gradient problem With gradient descent, sometimes the gradient becomes vanishingly small, effectively preventing the weight from changing its value. In the worst case, this may completely stop the neural network from further training. 2. Neuron Saturation When a neuron s activation value becomes close to the maximum or minimum of the range (e.g. 0/1 for sigmoid, -1/1 for tanh), the neuron is said to be saturated. In those cases, the gradient becomes small (vanishing gradient), and the network stops learning. 38
Multilayer Perceptrons (MLPs)
") CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Lecture 6. Notes on Linear Algebra. Perceptron
 Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
Deep Learning & Artificial Intelligence WS 2018/2019
 Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Deep Learning II: Momentum & Adaptive Step Size
 Deep Learning II: Momentum & Adaptive Step Size CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following
Deep Learning II: Momentum & Adaptive Step Size CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Vasil Khalidov & Miles Hansard. C.M. Bishop s PRML: Chapter 5; Neural Networks
 C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS16
 SS16") COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS6 Lecture 3: Classification with Logistic Regression Advanced optimization techniques Underfitting & Overfitting Model selection (Training-
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS6 Lecture 3: Classification with Logistic Regression Advanced optimization techniques Underfitting & Overfitting Model selection (Training-
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Neural Network Tutorial & Application in Nuclear Physics. Weiguang Jiang ( 蒋炜光 ) UTK / ORNL
 UTK / ORNL") Neural Network Tutorial & Application in Nuclear Physics Weiguang Jiang ( 蒋炜光 ) UTK / ORNL Machine Learning Logistic Regression Gaussian Processes Neural Network Support vector machine Random Forest Genetic
Neural Network Tutorial & Application in Nuclear Physics Weiguang Jiang ( 蒋炜光 ) UTK / ORNL Machine Learning Logistic Regression Gaussian Processes Neural Network Support vector machine Random Forest Genetic
10-701/ Machine Learning, Fall
 0-70/5-78 Machine Learning, Fall 2003 Homework 2 Solution If you have questions, please contact Jiayong Zhang .. (Error Function) The sum-of-squares error is the most common training
0-70/5-78 Machine Learning, Fall 2003 Homework 2 Solution If you have questions, please contact Jiayong Zhang .. (Error Function) The sum-of-squares error is the most common training
CS60010: Deep Learning
 CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Artificial Neuron (Perceptron)
") 9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Machine Learning CS 4900/5900. Lecture 03. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
More Tips for Training Neural Network. Hung-yi Lee
 More Tips for Training Neural Network Hung-yi ee Outline Activation Function Cost Function Data Preprocessing Training Generalization Review: Training Neural Network Neural network: f ; θ : input (vector)
More Tips for Training Neural Network Hung-yi ee Outline Activation Function Cost Function Data Preprocessing Training Generalization Review: Training Neural Network Neural network: f ; θ : input (vector)
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
epochs epochs
 Neural Network Experiments To illustrate practical techniques, I chose to use the glass dataset. This dataset has 214 examples and 6 classes. Here are 4 examples from the original dataset. The last values
Neural Network Experiments To illustrate practical techniques, I chose to use the glass dataset. This dataset has 214 examples and 6 classes. Here are 4 examples from the original dataset. The last values
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Stochastic Gradient Descent
 Stochastic Gradient Descent Weihang Chen, Xingchen Chen, Jinxiu Liang, Cheng Xu, Zehao Chen and Donglin He March 26, 2017 Outline What is Stochastic Gradient Descent Comparison between BGD and SGD Analysis
Stochastic Gradient Descent Weihang Chen, Xingchen Chen, Jinxiu Liang, Cheng Xu, Zehao Chen and Donglin He March 26, 2017 Outline What is Stochastic Gradient Descent Comparison between BGD and SGD Analysis
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Feed-forward Network Functions
 Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification
Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification
Neural Networks. Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016
 Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Radial Basis Function (RBF) Networks
 Networks") CSE 5526: Introduction to Neural Networks Radial Basis Function (RBF) Networks 1 Function approximation We have been using MLPs as pattern classifiers But in general, they are function approximators Depending
CSE 5526: Introduction to Neural Networks Radial Basis Function (RBF) Networks 1 Function approximation We have been using MLPs as pattern classifiers But in general, they are function approximators Depending
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Neural Networks: Optimization & Regularization
 Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Support Vector Machine and Neural Network Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 1 Announcements Due end of the day of this Friday (11:59pm) Reminder
CS249: ADVANCED DATA MINING Support Vector Machine and Neural Network Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 1 Announcements Due end of the day of this Friday (11:59pm) Reminder
Machine Learning Lecture 14
 Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Regularization in Neural Networks
 Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
ECE521 lecture 4: 19 January Optimization, MLE, regularization
 ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
Dan Roth 461C, 3401 Walnut
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
Rapid Introduction to Machine Learning/ Deep Learning
 Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/59 Lecture 4a Feedforward neural network October 30, 2015 2/59 Table of contents 1 1. Objectives of Lecture
Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/59 Lecture 4a Feedforward neural network October 30, 2015 2/59 Table of contents 1 1. Objectives of Lecture
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Understanding Neural Networks : Part I
 TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
DeepLearning on FPGAs
 DeepLearning on FPGAs Introduction to Deep Learning Sebastian Buschäger Technische Universität Dortmund - Fakultät Informatik - Lehrstuhl 8 October 21, 2017 1 Recap Computer Science Approach Technical
DeepLearning on FPGAs Introduction to Deep Learning Sebastian Buschäger Technische Universität Dortmund - Fakultät Informatik - Lehrstuhl 8 October 21, 2017 1 Recap Computer Science Approach Technical
Multiclass Logistic Regression
 Multiclass Logistic Regression Sargur. Srihari University at Buffalo, State University of ew York USA Machine Learning Srihari Topics in Linear Classification using Probabilistic Discriminative Models
Multiclass Logistic Regression Sargur. Srihari University at Buffalo, State University of ew York USA Machine Learning Srihari Topics in Linear Classification using Probabilistic Discriminative Models
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Non-Convex Optimization. CS6787 Lecture 7 Fall 2017
 Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
Gradient-Based Learning. Sargur N. Srihari
 Gradient-Based Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Gradient-Based Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Simple Techniques for Improving SGD. CS6787 Lecture 2 Fall 2017
 Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Neural Nets Supervised learning
 6.034 Artificial Intelligence Big idea: Learning as acquiring a function on feature vectors Background Nearest Neighbors Identification Trees Neural Nets Neural Nets Supervised learning y s(z) w w 0 w
6.034 Artificial Intelligence Big idea: Learning as acquiring a function on feature vectors Background Nearest Neighbors Identification Trees Neural Nets Neural Nets Supervised learning y s(z) w w 0 w
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Classification. Sandro Cumani. Politecnico di Torino
 Politecnico di Torino Outline Generative model: Gaussian classifier (Linear) discriminative model: logistic regression (Non linear) discriminative model: neural networks Gaussian Classifier We want to
Politecnico di Torino Outline Generative model: Gaussian classifier (Linear) discriminative model: logistic regression (Non linear) discriminative model: neural networks Gaussian Classifier We want to
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
An overview of deep learning methods for genomics
 An overview of deep learning methods for genomics Matthew Ploenzke STAT115/215/BIO/BIST282 Harvard University April 19, 218 1 Snapshot 1. Brief introduction to convolutional neural networks What is deep
An overview of deep learning methods for genomics Matthew Ploenzke STAT115/215/BIO/BIST282 Harvard University April 19, 218 1 Snapshot 1. Brief introduction to convolutional neural networks What is deep
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation
 Computational Graphs, Learning Algorithms, Initialisation") Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
Deep Feedforward Networks. Lecture slides for Chapter 6 of Deep Learning Ian Goodfellow Last updated
 Deep Feedforward Networks Lecture slides for Chapter 6 of Deep Learning www.deeplearningbook.org Ian Goodfellow Last updated 2016-10-04 Roadmap Example: Learning XOR Gradient-Based Learning Hidden Units
Deep Feedforward Networks Lecture slides for Chapter 6 of Deep Learning www.deeplearningbook.org Ian Goodfellow Last updated 2016-10-04 Roadmap Example: Learning XOR Gradient-Based Learning Hidden Units
Deep Learning & Neural Networks Lecture 4
 Deep Learning & Neural Networks Lecture 4 Kevin Duh Graduate School of Information Science Nara Institute of Science and Technology Jan 23, 2014 2/20 3/20 Advanced Topics in Optimization Today we ll briefly
Deep Learning & Neural Networks Lecture 4 Kevin Duh Graduate School of Information Science Nara Institute of Science and Technology Jan 23, 2014 2/20 3/20 Advanced Topics in Optimization Today we ll briefly
Overview of gradient descent optimization algorithms. HYUNG IL KOO Based on
 Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Lecture 6 Optimization for Deep Neural Networks
 Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent
 CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
Optimization for Training I. First-Order Methods Training algorithm
 Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden