CSCI 315: Artificial Intelligence through Deep Learning
|
|
|
- Ellen Davis
- 5 years ago
- Views:
Transcription
1 CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7)
2 Recall our first-week discussion...


3 How do we know stuff?

4 (MIT Press 1996)

5 Intelligence as Prediction
6 Context Simple Recurrent Network (Elman 1990) Context layer is just a copy of hidden layer at previous time. Like input layer, it is fully connected to hidden layer. It acts as an additional input that provides a history (context) for the current input. So C in ABCABC looks different to the hidden layer than the C in BACBAC. COPY
7 Experiment #1: Sequential XOR Recall XOR (Exclusive OR) as a minimal test case for nontrivial machine learning: Input Output This is a purely static learning task: for a given input, the output is always the same. We can turn XOR into a prediction task by repeating a sequence consisting of two random bits, followed by their XOR:
8 Target sequence is input sequence shifted left by one time step: input: target: Training sequences was 3000 bits long. SRN had one input / target unit; two hidden / context units. 600 iterations of back-prop (each iteration = one pass through the entire sequence) What sort of results do we expect : how good will network be at predicting each next target?
9
10 Experiment #4: Discovering Lexical Classes Lexical class: noun, verb, adjective, etc. Can be further analyzed into animate noun (person, animal), inanimate noun (car, rock), transitive verb (take, see), intransitive (leave, go), etc.
11 Used a little grammar to generate simple English sentences from these words:

12 31 words, each represented by a one-hot code: 150 hidden/context units Training set of sentences 27,354 words long Six passes through the training sequence
13 Instead of looking at the error signal, Elman looked at the average values (vector) computed by the hidden units when presented with each word. With 150 hidden units, it is difficult to see coherent patterns. So Elman used Hierarchical Cluster Analysis to group hidden-layer vectors recursively: 1) Create a distance matrix of the Euclidean distance of each vector from the others 2) If two words have a small distance, put them in the same group 3) Average vector for a group can be used to represent the group as a whole, enabling distance comparisons between groups.
14 Hypothetical distance matrix break break cat man move plate smash woman cat man move plate smash woman
15 Results
16 Responding to Novelty
 became one of the top-cited papers in psychology and cognitive science Led researchers to wonder whether training algorithm could be beefed up to deal with real-world, practical")
17 SRN: Summing Up SRN revived the nature / nurture debate in cognitive science, revealing a huge amount of learnable hidden structure in word sequences. Elman (1990) became one of the top-cited papers in psychology and cognitive science Led researchers to wonder whether training algorithm could be beefed up to deal with real-world, practical sequence tasks (translation, part-of-speech tagging)
18 From SRN to BPTT SRN back-prop is truncated in that it uses only the most recent hidden-layer activations Hence there is a rapid discounting of errors computed at the previous time steps. By unrolling (copying) the net over time, we can make better use of errors computed farther back in time: hence, Back-Prop Through Time. In essence, we turn a simple recurrent net into a complicated non-recurrent net.
19 Back-Prop Through Time During training, we maintain a distinct copy of the weights at each time step, and modify them independently using backprop. After training, we re-roll the unrolled network back into its original form, averaging trained weight copies to get the final weights.
20 BPTT: The Vanishing Gradient Problem Even with an unrolled network, the error gradient will eventually become too small to be useful for weight update The figure at right illustrates this for a toy network of three units (input, hidden, output), but it is true of any BPTT network in general.
21 Long Short-Term Memory: A Solution to the Vanishing Gradient LSTM: Invented by Schmidhüber in 1997, but citations have exploded recently thanks to Deep Learning Best intro: google COLAH LSTM Consider a general RNN architecture, shown at right:
22 General RNN Architecture our yt Architecture (?)
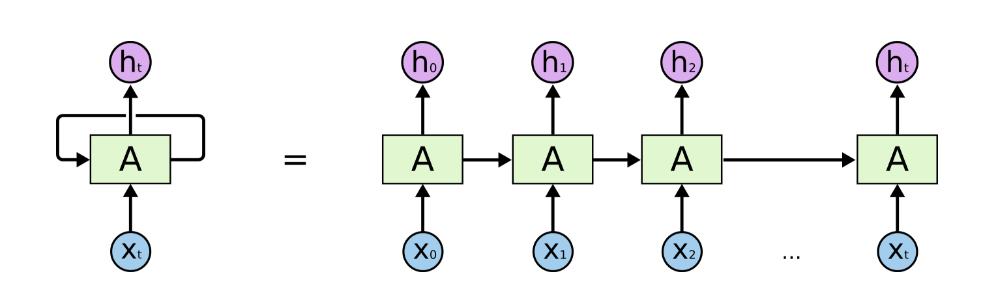
23 Unrolled

24 SRN Revisited As in previous SRN illustration, hidden layer is computed from current input and previous hidden. But modern approach uses hyperbolic tangent tanh() here, instead of logistic sigmoid.
25 tanh()
26 LSTM = layer x = elementwise multiply + = elementwise add σ = logistic sigmoid
27 Cell State gate


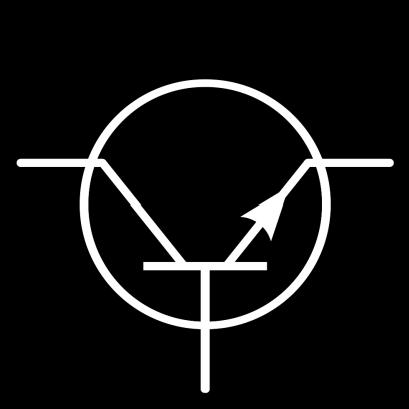
28 Cell State gate transistor
29 Forget Gate Layer ft will be 0 where we want to forget a vector component, 1 where we want to remember it. For example, introduction of a singular noun in xt might override a previous plural noun, for verb agreement later. So we forget the plural noun.

30 Input Gate Layer it will be 1 where we want to learn a vector component, 0 where we don t. For example, introduction of a singular noun in xt might override a previous plural noun, for verb agreement later. So we remember the singular noun. Ĉt is the actual data that we want to remember.

31 Cell State Update New cell state Ct is what we want to forget from previous state, plus what we want to remember from new info.

32 Output ot is yet another sigmoidal gate that allows us to select the components of the output. Finally, we pass the current cell state Ct through tanh(), to keep it in [-1,+1].
33 LSTM vs. SRN: Summary SRN has two layers of weights - input,context hidden - hidden output LSTM has four: - Wf - Wi - Wc - Wo Traditional SRN used logistic sigmoid everywhere. LSTM uses tanh(), with sigmoid reserved for gating. So how does LSTM avoid the vanishing gradient?

34
CSCI 252: Neural Networks and Graphical Models. Fall Term 2016 Prof. Levy. Architecture #7: The Simple Recurrent Network (Elman 1990)
") CSCI 252: Neural Networks and Graphical Models Fall Term 2016 Prof. Levy Architecture #7: The Simple Recurrent Network (Elman 1990) Part I Multi-layer Neural Nets Taking Stock: What can we do with neural
CSCI 252: Neural Networks and Graphical Models Fall Term 2016 Prof. Levy Architecture #7: The Simple Recurrent Network (Elman 1990) Part I Multi-layer Neural Nets Taking Stock: What can we do with neural
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Neural Networks Language Models
 Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
RECURRENT NETWORKS I. Philipp Krähenbühl
 RECURRENT NETWORKS I Philipp Krähenbühl RECAP: CLASSIFICATION conv 1 conv 2 conv 3 conv 4 1 2 tu RECAP: SEGMENTATION conv 1 conv 2 conv 3 conv 4 RECAP: DETECTION conv 1 conv 2 conv 3 conv 4 RECAP: GENERATION
RECURRENT NETWORKS I Philipp Krähenbühl RECAP: CLASSIFICATION conv 1 conv 2 conv 3 conv 4 1 2 tu RECAP: SEGMENTATION conv 1 conv 2 conv 3 conv 4 RECAP: DETECTION conv 1 conv 2 conv 3 conv 4 RECAP: GENERATION
Recurrent Neural Networks Deep Learning Lecture 5. Efstratios Gavves
 Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Lecture 15: Exploding and Vanishing Gradients
 Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook
 Sumit Chopra Facebook") Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
(
 Class 15 - Long Short-Term Memory (LSTM) Study materials http://colah.github.io/posts/2015-08-understanding-lstms/ (http://colah.github.io/posts/2015-08-understanding-lstms/) http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Class 15 - Long Short-Term Memory (LSTM) Study materials http://colah.github.io/posts/2015-08-understanding-lstms/ (http://colah.github.io/posts/2015-08-understanding-lstms/) http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Lecture 15: Recurrent Neural Nets
 Lecture 15: Recurrent Neural Nets Roger Grosse 1 Introduction Most of the prediction tasks we ve looked at have involved pretty simple kinds of outputs, such as real values or discrete categories. But
Lecture 15: Recurrent Neural Nets Roger Grosse 1 Introduction Most of the prediction tasks we ve looked at have involved pretty simple kinds of outputs, such as real values or discrete categories. But
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Modelling Time Series with Neural Networks. Volker Tresp Summer 2017
 Modelling Time Series with Neural Networks Volker Tresp Summer 2017 1 Modelling of Time Series The next figure shows a time series (DAX) Other interesting time-series: energy prize, energy consumption,
Modelling Time Series with Neural Networks Volker Tresp Summer 2017 1 Modelling of Time Series The next figure shows a time series (DAX) Other interesting time-series: energy prize, energy consumption,
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
CSC321 Lecture 10 Training RNNs
 CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
Sequence Models. Ji Yang. Department of Computing Science, University of Alberta. February 14, 2018
 Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Slide credit from Hung-Yi Lee & Richard Socher
 Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Natural Language Understanding. Recap: probability, language models, and feedforward networks. Lecture 12: Recurrent Neural Networks and LSTMs
 Natural Language Understanding Lecture 12: Recurrent Neural Networks and LSTMs Recap: probability, language models, and feedforward networks Simple Recurrent Networks Adam Lopez Credits: Mirella Lapata
Natural Language Understanding Lecture 12: Recurrent Neural Networks and LSTMs Recap: probability, language models, and feedforward networks Simple Recurrent Networks Adam Lopez Credits: Mirella Lapata
Recurrent Neural Networks 2. CS 287 (Based on Yoav Goldberg s notes)
") Recurrent Neural Networks 2 CS 287 (Based on Yoav Goldberg s notes) Review: Representation of Sequence Many tasks in NLP involve sequences w 1,..., w n Representations as matrix dense vectors X (Following
Recurrent Neural Networks 2 CS 287 (Based on Yoav Goldberg s notes) Review: Representation of Sequence Many tasks in NLP involve sequences w 1,..., w n Representations as matrix dense vectors X (Following
Long-Short Term Memory
 Long-Short Term Memory Sepp Hochreiter, Jürgen Schmidhuber Presented by Derek Jones Table of Contents 1. Introduction 2. Previous Work 3. Issues in Learning Long-Term Dependencies 4. Constant Error Flow
Long-Short Term Memory Sepp Hochreiter, Jürgen Schmidhuber Presented by Derek Jones Table of Contents 1. Introduction 2. Previous Work 3. Issues in Learning Long-Term Dependencies 4. Constant Error Flow
EE-559 Deep learning Recurrent Neural Networks
 EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
Recurrent and Recursive Networks
 Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
Long Short-Term Memory (LSTM)
") Long Short-Term Memory (LSTM) A brief introduction Daniel Renshaw 24th November 2014 1 / 15 Context and notation Just to give the LSTM something to do: neural network language modelling Vocabulary, size
Long Short-Term Memory (LSTM) A brief introduction Daniel Renshaw 24th November 2014 1 / 15 Context and notation Just to give the LSTM something to do: neural network language modelling Vocabulary, size
CSC321 Lecture 15: Recurrent Neural Networks
 CSC321 Lecture 15: Recurrent Neural Networks Roger Grosse Roger Grosse CSC321 Lecture 15: Recurrent Neural Networks 1 / 26 Overview Sometimes we re interested in predicting sequences Speech-to-text and
CSC321 Lecture 15: Recurrent Neural Networks Roger Grosse Roger Grosse CSC321 Lecture 15: Recurrent Neural Networks 1 / 26 Overview Sometimes we re interested in predicting sequences Speech-to-text and
NLP Programming Tutorial 8 - Recurrent Neural Nets
 NLP Programming Tutorial 8 - Recurrent Neural Nets Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Feed Forward Neural Nets All connections point forward ϕ( x) y It is a directed acyclic
NLP Programming Tutorial 8 - Recurrent Neural Nets Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Feed Forward Neural Nets All connections point forward ϕ( x) y It is a directed acyclic
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Neural Turing Machine. Author: Alex Graves, Greg Wayne, Ivo Danihelka Presented By: Tinghui Wang (Steve)
") Neural Turing Machine Author: Alex Graves, Greg Wayne, Ivo Danihelka Presented By: Tinghui Wang (Steve) Introduction Neural Turning Machine: Couple a Neural Network with external memory resources The combined
Neural Turing Machine Author: Alex Graves, Greg Wayne, Ivo Danihelka Presented By: Tinghui Wang (Steve) Introduction Neural Turning Machine: Couple a Neural Network with external memory resources The combined
Course Structure. Psychology 452 Week 12: Deep Learning. Chapter 8 Discussion. Part I: Deep Learning: What and Why? Rufus. Rufus Processed By Fetch
 Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
arxiv: v3 [cs.lg] 14 Jan 2018
![arxiv: v3 [cs.lg] 14 Jan 2018](/thumbs/92/109503708.jpg "arxiv: v3 [cs.lg] 14 Jan 2018") A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
On the use of Long-Short Term Memory neural networks for time series prediction
 On the use of Long-Short Term Memory neural networks for time series prediction Pilar Gómez-Gil National Institute of Astrophysics, Optics and Electronics ccc.inaoep.mx/~pgomez In collaboration with: J.
On the use of Long-Short Term Memory neural networks for time series prediction Pilar Gómez-Gil National Institute of Astrophysics, Optics and Electronics ccc.inaoep.mx/~pgomez In collaboration with: J.
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
Deep Learning. Recurrent Neural Network (RNNs) Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning
 Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning") Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function
 Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Recurrent Neural Networks
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
Introduction to RNNs!
 Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
EE-559 Deep learning LSTM and GRU
 EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
Gianluca Pollastri, Head of Lab School of Computer Science and Informatics and. University College Dublin
 Introduction ti to Neural Networks Gianluca Pollastri, Head of Lab School of Computer Science and Informatics and Complex and Adaptive Systems Labs University College Dublin gianluca.pollastri@ucd.ie Credits
Introduction ti to Neural Networks Gianluca Pollastri, Head of Lab School of Computer Science and Informatics and Complex and Adaptive Systems Labs University College Dublin gianluca.pollastri@ucd.ie Credits
Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials
 Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials Contents 1 Pseudo-code for the damped Gauss-Newton vector product 2 2 Details of the pathological synthetic problems
Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials Contents 1 Pseudo-code for the damped Gauss-Newton vector product 2 2 Details of the pathological synthetic problems
Recurrent Neural Network
 Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Direct Method for Training Feed-forward Neural Networks using Batch Extended Kalman Filter for Multi- Step-Ahead Predictions
 Direct Method for Training Feed-forward Neural Networks using Batch Extended Kalman Filter for Multi- Step-Ahead Predictions Artem Chernodub, Institute of Mathematical Machines and Systems NASU, Neurotechnologies
Direct Method for Training Feed-forward Neural Networks using Batch Extended Kalman Filter for Multi- Step-Ahead Predictions Artem Chernodub, Institute of Mathematical Machines and Systems NASU, Neurotechnologies
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Tracking the World State with Recurrent Entity Networks
 Tracking the World State with Recurrent Entity Networks Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, Yann LeCun Task At each timestep, get information (in the form of a sentence) about the
Tracking the World State with Recurrent Entity Networks Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, Yann LeCun Task At each timestep, get information (in the form of a sentence) about the
Financial Risk and Returns Prediction with Modular Networked Learning
 arxiv:1806.05876v1 [cs.lg] 15 Jun 2018 Financial Risk and Returns Prediction with Modular Networked Learning Carlos Pedro Gonçalves June 18, 2018 University of Lisbon, Instituto Superior de Ciências Sociais
arxiv:1806.05876v1 [cs.lg] 15 Jun 2018 Financial Risk and Returns Prediction with Modular Networked Learning Carlos Pedro Gonçalves June 18, 2018 University of Lisbon, Instituto Superior de Ciências Sociais
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Structured Neural Networks (I)
") Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
Deep Learning Recurrent Networks 10/11/2017
 Deep Learning Recurrent Networks 10/11/2017 1 Which open source project? Related math. What is it talking about? And a Wikipedia page explaining it all The unreasonable effectiveness of recurrent neural
Deep Learning Recurrent Networks 10/11/2017 1 Which open source project? Related math. What is it talking about? And a Wikipedia page explaining it all The unreasonable effectiveness of recurrent neural
Recurrent Neural Networks. deeplearning.ai. Why sequence models?
 Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Recurrent Neural Networks. COMP-550 Oct 5, 2017
 Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Contents. (75pts) COS495 Midterm. (15pts) Short answers
 COS495 Midterm. (15pts) Short answers") Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Recurrent neural networks
 12-1: Recurrent neural networks Prof. J.C. Kao, UCLA Recurrent neural networks Motivation Network unrollwing Backpropagation through time Vanishing and exploding gradients LSTMs GRUs 12-2: Recurrent neural
12-1: Recurrent neural networks Prof. J.C. Kao, UCLA Recurrent neural networks Motivation Network unrollwing Backpropagation through time Vanishing and exploding gradients LSTMs GRUs 12-2: Recurrent neural
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
 2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Recurrent Neural Networks (RNNs) Lecture 9 - Networks for Sequential Data RNNs & LSTMs. RNN with no outputs. RNN with no outputs
 Lecture 9 - Networks for Sequential Data RNNs & LSTMs. RNN with no outputs. RNN with no outputs") Recurrent Neural Networks (RNNs) RNNs are a family of networks for processing sequential data. Lecture 9 - Networks for Sequential Data RNNs & LSTMs DD2424 September 6, 2017 A RNN applies the same function
Recurrent Neural Networks (RNNs) RNNs are a family of networks for processing sequential data. Lecture 9 - Networks for Sequential Data RNNs & LSTMs DD2424 September 6, 2017 A RNN applies the same function
Generating Sequences with Recurrent Neural Networks
 Generating Sequences with Recurrent Neural Networks Alex Graves University of Toronto & Google DeepMind Presented by Zhe Gan, Duke University May 15, 2015 1 / 23 Outline Deep recurrent neural network based
Generating Sequences with Recurrent Neural Networks Alex Graves University of Toronto & Google DeepMind Presented by Zhe Gan, Duke University May 15, 2015 1 / 23 Outline Deep recurrent neural network based
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Long Short- Term Memory (LSTM) M1 Yuichiro Sawai Computa;onal Linguis;cs Lab. January 15, Deep Lunch
 M1 Yuichiro Sawai Computa;onal Linguis;cs Lab. January 15, Deep Lunch") Long Short- Term Memory (LSTM) M1 Yuichiro Sawai Computa;onal Linguis;cs Lab. January 15, 2015 @ Deep Lunch 1 Why LSTM? OJen used in many recent RNN- based systems Machine transla;on Program execu;on Can
Long Short- Term Memory (LSTM) M1 Yuichiro Sawai Computa;onal Linguis;cs Lab. January 15, 2015 @ Deep Lunch 1 Why LSTM? OJen used in many recent RNN- based systems Machine transla;on Program execu;on Can
Recurrent Neural Networks
 Recurrent Neural Networks Datamining Seminar Kaspar Märtens Karl-Oskar Masing Today's Topics Modeling sequences: a brief overview Training RNNs with back propagation A toy example of training an RNN Why
Recurrent Neural Networks Datamining Seminar Kaspar Märtens Karl-Oskar Masing Today's Topics Modeling sequences: a brief overview Training RNNs with back propagation A toy example of training an RNN Why
Artificial Neuron (Perceptron)
") 9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
CMSC 421: Neural Computation. Applications of Neural Networks
 CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent
 Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent 1 Xi-Lin Li, lixilinx@gmail.com arxiv:1606.04449v2 [stat.ml] 8 Dec 2016 Abstract This paper studies the performance of
Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent 1 Xi-Lin Li, lixilinx@gmail.com arxiv:1606.04449v2 [stat.ml] 8 Dec 2016 Abstract This paper studies the performance of
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Input layer. Weight matrix [ ] Output layer
![Input layer. Weight matrix [ ] Output layer](/thumbs/94/121286844.jpg "Input layer. Weight matrix [ ] Output layer") MASSACHUSETTS INSTITUTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2003 Recitation 10, November 4 th & 5 th 2003 Learning by perceptrons
MASSACHUSETTS INSTITUTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2003 Recitation 10, November 4 th & 5 th 2003 Learning by perceptrons
Analysis of Multilayer Neural Network Modeling and Long Short-Term Memory
 Analysis of Multilayer Neural Network Modeling and Long Short-Term Memory Danilo López, Nelson Vera, Luis Pedraza International Science Index, Mathematical and Computational Sciences waset.org/publication/10006216
Analysis of Multilayer Neural Network Modeling and Long Short-Term Memory Danilo López, Nelson Vera, Luis Pedraza International Science Index, Mathematical and Computational Sciences waset.org/publication/10006216
Statistical NLP for the Web
 Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Learning Unitary Operators with Help from u(n)
") @_hylandsl Learning Unitary Operators with Help from u(n) Stephanie L. Hyland 1,2, Gunnar Rätsch 1 1 Department of Computer Science, ETH Zurich 2 Tri-Institutional Training Program in Computational Biology
@_hylandsl Learning Unitary Operators with Help from u(n) Stephanie L. Hyland 1,2, Gunnar Rätsch 1 1 Department of Computer Science, ETH Zurich 2 Tri-Institutional Training Program in Computational Biology
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Synaptic Devices and Neuron Circuits for Neuron-Inspired NanoElectronics
 Synaptic Devices and Neuron Circuits for Neuron-Inspired NanoElectronics Byung-Gook Park Inter-university Semiconductor Research Center & Department of Electrical and Computer Engineering Seoul National
Synaptic Devices and Neuron Circuits for Neuron-Inspired NanoElectronics Byung-Gook Park Inter-university Semiconductor Research Center & Department of Electrical and Computer Engineering Seoul National
) (d o f. For the previous layer in a neural network (just the rightmost layer if a single neuron), the required update equation is: 2.
 (d o f. For the previous layer in a neural network (just the rightmost layer if a single neuron), the required update equation is: 2.") 1 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2011 Recitation 8, November 3 Corrected Version & (most) solutions
1 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2011 Recitation 8, November 3 Corrected Version & (most) solutions
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Stephen Scott.
 1 / 35 (Adapted from Vinod Variyam and Ian Goodfellow) sscott@cse.unl.edu 2 / 35 All our architectures so far work on fixed-sized inputs neural networks work on sequences of inputs E.g., text, biological
1 / 35 (Adapted from Vinod Variyam and Ian Goodfellow) sscott@cse.unl.edu 2 / 35 All our architectures so far work on fixed-sized inputs neural networks work on sequences of inputs E.g., text, biological
Machine Learning. Boris
 Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
Deep Learning and Lexical, Syntactic and Semantic Analysis. Wanxiang Che and Yue Zhang
 Deep Learning and Lexical, Syntactic and Semantic Analysis Wanxiang Che and Yue Zhang 2016-10 Part 2: Introduction to Deep Learning Part 2.1: Deep Learning Background What is Machine Learning? From Data
Deep Learning and Lexical, Syntactic and Semantic Analysis Wanxiang Che and Yue Zhang 2016-10 Part 2: Introduction to Deep Learning Part 2.1: Deep Learning Background What is Machine Learning? From Data
Neural Architectures for Image, Language, and Speech Processing
 Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Spike-based Long Short-Term Memory networks
 Spike-based Long Short-Term Memory networks MSc Thesis Roeland Nusselder Mathematical Institute Utrecht University Machine Learning CWI Amsterdam Project supervisor: Prof. dr. R.H. Bisseling Daily supervisors:
Spike-based Long Short-Term Memory networks MSc Thesis Roeland Nusselder Mathematical Institute Utrecht University Machine Learning CWI Amsterdam Project supervisor: Prof. dr. R.H. Bisseling Daily supervisors:
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
A Tutorial On Backward Propagation Through Time (BPTT) In The Gated Recurrent Unit (GRU) RNN
 In The Gated Recurrent Unit (GRU) RNN") A Tutorial On Backward Propagation Through Time (BPTT In The Gated Recurrent Unit (GRU RNN Minchen Li Department of Computer Science The University of British Columbia minchenl@cs.ubc.ca Abstract In this
A Tutorial On Backward Propagation Through Time (BPTT In The Gated Recurrent Unit (GRU RNN Minchen Li Department of Computer Science The University of British Columbia minchenl@cs.ubc.ca Abstract In this
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Machine Learning (CSE 446): Neural Networks
: Neural Networks") Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Natural Language Processing
 Natural Language Processing Pushpak Bhattacharyya CSE Dept, IIT Patna and Bombay LSTM 15 jun, 2017 lgsoft:nlp:lstm:pushpak 1 Recap 15 jun, 2017 lgsoft:nlp:lstm:pushpak 2 Feedforward Network and Backpropagation
Natural Language Processing Pushpak Bhattacharyya CSE Dept, IIT Patna and Bombay LSTM 15 jun, 2017 lgsoft:nlp:lstm:pushpak 1 Recap 15 jun, 2017 lgsoft:nlp:lstm:pushpak 2 Feedforward Network and Backpropagation
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1
 What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Speech and Language Processing
 Speech and Language Processing Lecture 5 Neural network based acoustic and language models Information and Communications Engineering Course Takahiro Shinoaki 08//6 Lecture Plan (Shinoaki s part) I gives
Speech and Language Processing Lecture 5 Neural network based acoustic and language models Information and Communications Engineering Course Takahiro Shinoaki 08//6 Lecture Plan (Shinoaki s part) I gives
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design