Artificial Intelligence
|
|
|
- August Hoover
- 5 years ago
- Views:
Transcription


1 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory




2 Announcements Be making progress on your projects!
3 Three Types of Learning Unsupervised Supervised Reinforcement
4 Perceptron Learning Rule Typically applied one example at a time choosing samples at random Guaranteed to find a perfect boundary if data are linearly separable Example Run
5 Perceptron Learning Rule Not guaranteed to find optimal solution if data are not linearly separable below it gets to the minimal error many times, but keeps changing the weights With Non-Separable Data
6 Perceptron Learning Rule Not guaranteed to find optimal solution if data are not linearly separable below it gets to the minimal error many times, but keeps changing the weights decreasing learning rate (setting alpha to 1/numIterations) will find a minimum-error solution With Non-Separable Data With Cooling
7 Perceptron Learning Rule Lots!,, With Linearly Separable Data With Non-Separable Data With Cooling
8 Logistic Regression in contrast to linear regression Threshold ( step-function ) has drawbacks non-differentiable always produces a 1 or 0 classification - even near the boundary
9 Logistic Regression Threshold ( step-function ) has drawbacks non-differentiable always produces a 1 or 0 classification - even near the boundary Solutions the differentiable logistic function output is a probability of the class near boundary towards 0 or 1 farther away
10 Logistic Regression Sigmoid for Earthquakes vs. Explosions

11 No closed-form solution Logistic Regression Weight update rule (see book for derivation) Linearly Separable Data Bit slower than linear regression, but more predictable not linearly separable, fixed learning rate Faster than linear regression not linearly separable, decaying learning rate Faster than linear regression
12 Logistic Regression

13 Your brain is a neural network Neural Networks
14

15 Neural Networks We create computational brains called Artificial Neural Networks or ANNs
16 Neural Networks Nodes feed forward - layered


17 Neural Networks Nodes feedforward - layers recurrent - allows memory recurrent
 typically real valued")
18 Neural Networks Connections excitatory or inhibitory different weights (magnitudes) typically real valued
19 Neural Networks Nodes often layered function of inputs - step/threshold - sigmoid - other...
20 Neural Networks Nodes often layered function of inputs - step/threshold - sigmoid - other... biases - often treated as another input set to 1 - always use them! - otherwise decision boundary has to pass through origin - also good when default output is non-zero, such as a robot that moves forward unless X - make sure they are on for your projects!

 = 1 if >=0, Bias 0")
21 Neural Networks Simple example: kiwi classifier binary inputs weights =?? bias = 1 Roundess Furriness T=0 = 1 0 f(x) = 1 if >=0, Bias 0 otherwise
22 Non-Linear Activation Functions Combining many of them builds an ANN that can represent non-linear functions - because activation functions are nonlinear

23 Outputs Can have single or multiple outputs e.g. one output for each class
24 Perceptron Perceptron: Single unit Default activation function: step Sigmoid: sigmoid perceptron Perceptron Network: single-layer network McCullough & Pitts (1943)
25 Perceptron Training Rule Training: step activation function: perceptron learning rule logistic activation function: gradient descent both work for linearly separable data - we already new that just a new metaphor now
26 Neural Networks Outputs 1 if >= number in node 1 neuron2 (right) 1 2D Non-Linear Mapping 1 Outputs of each node x y Left Center Right Output neuron3 (center) 3D neuron1 (left)
27 Neural Networks neuron2 (right) 1 1 neuron3 (center) neuron1 (left) 3D
28 Neural Networks Cover s theorem: The probability that classes are linearly separable increases when the features are nonlinearly mapped to a higher dimensional feature space. [Coover 1965] The output layer requires linear separability. The purpose of the hidden layers is to make the problem linearly separable! From:
29 Neural Networks Multi-layer networks thus allow non-linear regression
30 Neural Networks Multi-layer networks thus allow non-linear regression Single hidden layer (often very large): can represent any continuous function Two hidden layers: can represent any discontinuous function
31 Neural Networks Multi-layer networks thus allow non-linear regression Single hidden layer (often very large): can represent any continuous function Two hidden layers: can represent any discontinuous function But how do we train them?
32 Training Multi-Layer Neural Networks General Idea: Propagate the error backwards Called Backpropagation
33 Backpropagation Can still write the equation of a neuron Activation of Neuron 5 Bias
34 Backpropagation Can still write the equation of a neuron Allows us to calculate loss and take derivative Activation of Neuron 5 Bias
35 Backpropagation Can still write the equation of a neuron Allows us to calculate loss and take derivative At the output, the loss eq. is the same as before prev. gradient descent eq. now generalized to multiple output nodes
36 Backpropagation But what is the error at hidden nodes? We don t know what the right answer is for hidden nodes
37 Backpropagation
38 Backpropagation Detailed Pseudocode in Book
39 ANNs How do we choose the topology? number of layers number of neurons per layer Too many neurons = memorization/overfitting No perfect answer try different ones and cross-validate evolve (take my class in the Spring!) many others
40 Deep Learning Hierarchically composed feature representations Deep Neural Networks ~6+ Layers Each layer transforms data to new space could be higher-dimensional, lower, or just different
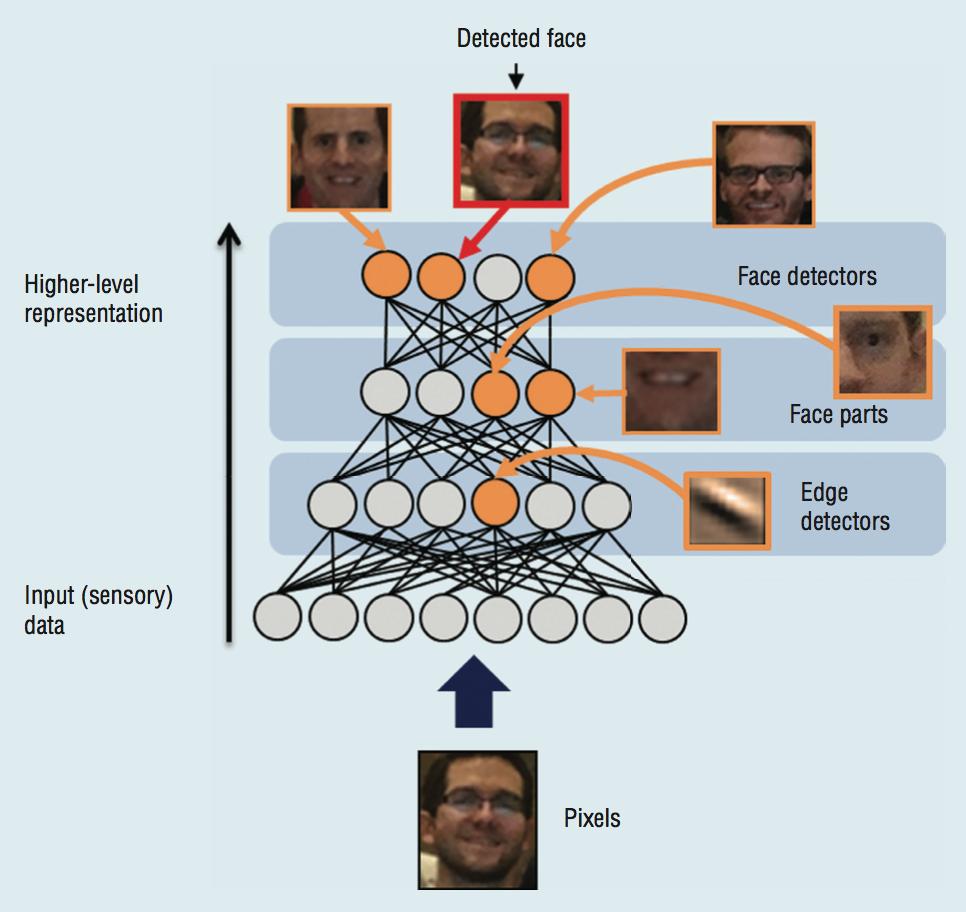
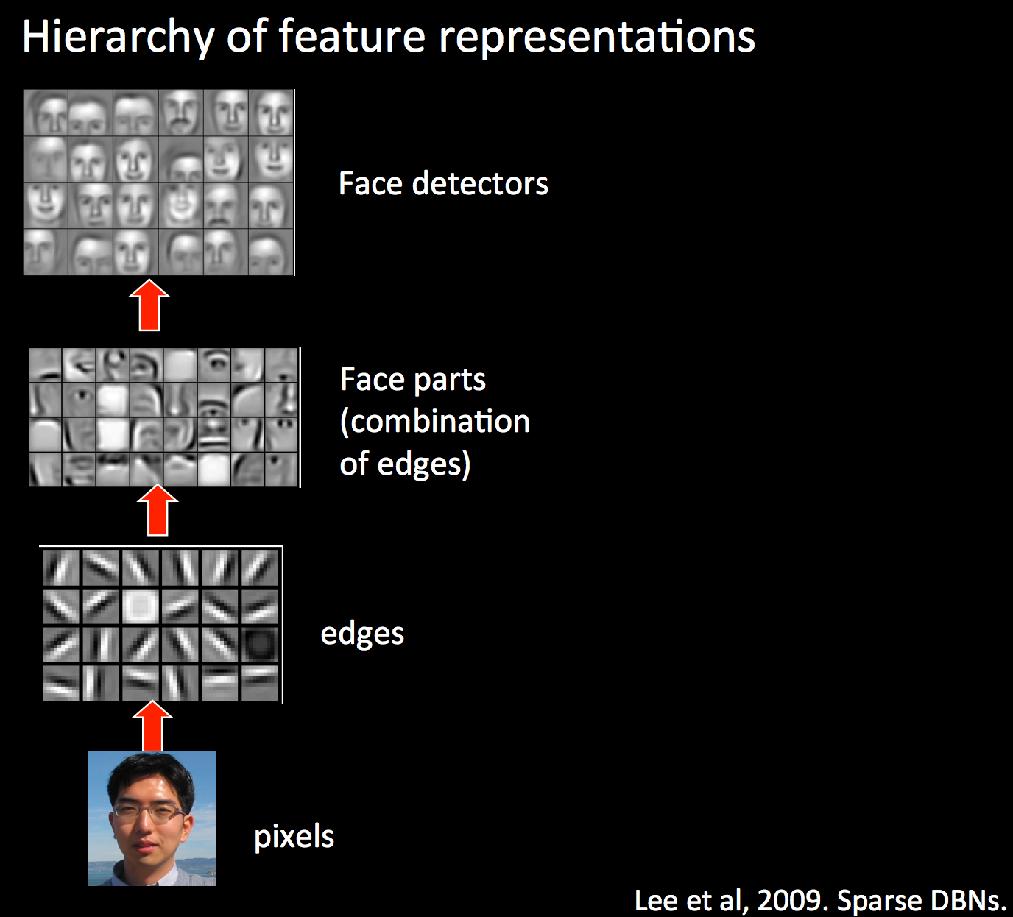
41 Hierarchically composed feature representations

42 Learning features relevant to the data Lehman, Clune, & Risi 2015 Lee et al. 2007

 Quiroga et al.")
43 Deep Learning Follows biology closely V1, V2, etc. in Visual Cortex go from edges to more abstract features eventually to a Halle Berry Neuron responded to her picture a line drawing of her her picture in her Catwoman costume her name (typed out) Quiroga et al. Nature 2005 For more, see:
Revision: Neural Network
 Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
EEE 241: Linear Systems
 EEE 4: Linear Systems Summary # 3: Introduction to artificial neural networks DISTRIBUTED REPRESENTATION An ANN consists of simple processing units communicating with each other. The basic elements of
EEE 4: Linear Systems Summary # 3: Introduction to artificial neural networks DISTRIBUTED REPRESENTATION An ANN consists of simple processing units communicating with each other. The basic elements of
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Artificial Neural Networks
 Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
Artificial Neural Networks. Historical description
 Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Artificial Neural Networks. Edward Gatt
 Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
2015 Todd Neller. A.I.M.A. text figures 1995 Prentice Hall. Used by permission. Neural Networks. Todd W. Neller
 2015 Todd Neller. A.I.M.A. text figures 1995 Prentice Hall. Used by permission. Neural Networks Todd W. Neller Machine Learning Learning is such an important part of what we consider "intelligence" that
2015 Todd Neller. A.I.M.A. text figures 1995 Prentice Hall. Used by permission. Neural Networks Todd W. Neller Machine Learning Learning is such an important part of what we consider "intelligence" that
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Neural Networks. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Lab 5: 16 th April Exercises on Neural Networks
 Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Neural Networks and Fuzzy Logic Rajendra Dept.of CSE ASCET
 Unit-. Definition Neural network is a massively parallel distributed processing system, made of highly inter-connected neural computing elements that have the ability to learn and thereby acquire knowledge
Unit-. Definition Neural network is a massively parallel distributed processing system, made of highly inter-connected neural computing elements that have the ability to learn and thereby acquire knowledge
AN INTRODUCTION TO NEURAL NETWORKS. Scott Kuindersma November 12, 2009
 AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning
 LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning") CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
Artificial Neural Networks. Q550: Models in Cognitive Science Lecture 5
 Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Network and Fuzzy Logic
 Artificial Neural Network and Fuzzy Logic 1 Syllabus 2 Syllabus 3 Books 1. Artificial Neural Networks by B. Yagnanarayan, PHI - (Cover Topologies part of unit 1 and All part of Unit 2) 2. Neural Networks
Artificial Neural Network and Fuzzy Logic 1 Syllabus 2 Syllabus 3 Books 1. Artificial Neural Networks by B. Yagnanarayan, PHI - (Cover Topologies part of unit 1 and All part of Unit 2) 2. Neural Networks
CMSC 421: Neural Computation. Applications of Neural Networks
 CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
COGS Q250 Fall Homework 7: Learning in Neural Networks Due: 9:00am, Friday 2nd November.
 COGS Q250 Fall 2012 Homework 7: Learning in Neural Networks Due: 9:00am, Friday 2nd November. For the first two questions of the homework you will need to understand the learning algorithm using the delta
COGS Q250 Fall 2012 Homework 7: Learning in Neural Networks Due: 9:00am, Friday 2nd November. For the first two questions of the homework you will need to understand the learning algorithm using the delta
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Linear classification with logistic regression
 Section 8.6. Regression and Classification with Linear Models 725 Proportion correct.9.7 Proportion correct.9.7 2 3 4 5 6 7 2 4 6 8 2 4 6 8 Number of weight updates Number of weight updates Number of weight
Section 8.6. Regression and Classification with Linear Models 725 Proportion correct.9.7 Proportion correct.9.7 2 3 4 5 6 7 2 4 6 8 2 4 6 8 Number of weight updates Number of weight updates Number of weight
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
ECLT 5810 Classification Neural Networks. Reference: Data Mining: Concepts and Techniques By J. Hand, M. Kamber, and J. Pei, Morgan Kaufmann
 ECLT 5810 Classification Neural Networks Reference: Data Mining: Concepts and Techniques By J. Hand, M. Kamber, and J. Pei, Morgan Kaufmann Neural Networks A neural network is a set of connected input/output
ECLT 5810 Classification Neural Networks Reference: Data Mining: Concepts and Techniques By J. Hand, M. Kamber, and J. Pei, Morgan Kaufmann Neural Networks A neural network is a set of connected input/output
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Recurrent Neural Networks
 Recurrent Neural Networks Datamining Seminar Kaspar Märtens Karl-Oskar Masing Today's Topics Modeling sequences: a brief overview Training RNNs with back propagation A toy example of training an RNN Why
Recurrent Neural Networks Datamining Seminar Kaspar Märtens Karl-Oskar Masing Today's Topics Modeling sequences: a brief overview Training RNNs with back propagation A toy example of training an RNN Why
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Lecture 4: Feed Forward Neural Networks
 Lecture 4: Feed Forward Neural Networks Dr. Roman V Belavkin Middlesex University BIS4435 Biological neurons and the brain A Model of A Single Neuron Neurons as data-driven models Neural Networks Training
Lecture 4: Feed Forward Neural Networks Dr. Roman V Belavkin Middlesex University BIS4435 Biological neurons and the brain A Model of A Single Neuron Neurons as data-driven models Neural Networks Training
Introduction to Artificial Neural Networks
 Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Multilayer Perceptrons and Backpropagation
 Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Unit 8: Introduction to neural networks. Perceptrons
 Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Neural Networks. Intro to AI Bert Huang Virginia Tech
 Neural Networks Intro to AI Bert Huang Virginia Tech Outline Biological inspiration for artificial neural networks Linear vs. nonlinear functions Learning with neural networks: back propagation https://en.wikipedia.org/wiki/neuron#/media/file:chemical_synapse_schema_cropped.jpg
Neural Networks Intro to AI Bert Huang Virginia Tech Outline Biological inspiration for artificial neural networks Linear vs. nonlinear functions Learning with neural networks: back propagation https://en.wikipedia.org/wiki/neuron#/media/file:chemical_synapse_schema_cropped.jpg
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
Introduction Biologically Motivated Crude Model Backpropagation
 Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction to Deep Learning
 Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Learning and Neural Networks
 Artificial Intelligence Learning and Neural Networks Readings: Chapter 19 & 20.5 of Russell & Norvig Example: A Feed-forward Network w 13 I 1 H 3 w 35 w 14 O 5 I 2 w 23 w 24 H 4 w 45 a 5 = g 5 (W 3,5 a
Artificial Intelligence Learning and Neural Networks Readings: Chapter 19 & 20.5 of Russell & Norvig Example: A Feed-forward Network w 13 I 1 H 3 w 35 w 14 O 5 I 2 w 23 w 24 H 4 w 45 a 5 = g 5 (W 3,5 a
Sections 18.6 and 18.7 Analysis of Artificial Neural Networks
 Sections 18.6 and 18.7 Analysis of Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline Univariate regression
Sections 18.6 and 18.7 Analysis of Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline Univariate regression
CSC321 Lecture 5 Learning in a Single Neuron
 CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
Neural Networks. Mark van Rossum. January 15, School of Informatics, University of Edinburgh 1 / 28
 1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
Sections 18.6 and 18.7 Artificial Neural Networks
 Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs artifical neural networks
Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs artifical neural networks
ECE 471/571 - Lecture 17. Types of NN. History. Back Propagation. Recurrent (feedback during operation) Feedforward
 Feedforward") ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
HISTORY. In the 70 s vs today variants. (Multi-layer) Feed-forward (perceptron) Hebbian Recurrent
 Feed-forward (perceptron) Hebbian Recurrent") NEURAL NETWORKS REFERENCES: ARTIFICIAL INTELLIGENCE FOR GAMES "ARTIFICIAL INTELLIGENCE: A NEW SYNTHESIS HTTPS://MATTMAZUR.COM/2015/03/17/A- STEP- BY- STEP- BACKPROPAGATION- EXAMPLE/ " HISTORY In the 70
NEURAL NETWORKS REFERENCES: ARTIFICIAL INTELLIGENCE FOR GAMES "ARTIFICIAL INTELLIGENCE: A NEW SYNTHESIS HTTPS://MATTMAZUR.COM/2015/03/17/A- STEP- BY- STEP- BACKPROPAGATION- EXAMPLE/ " HISTORY In the 70
Artificial Neural Network
 Artificial Neural Network Contents 2 What is ANN? Biological Neuron Structure of Neuron Types of Neuron Models of Neuron Analogy with human NN Perceptron OCR Multilayer Neural Network Back propagation
Artificial Neural Network Contents 2 What is ANN? Biological Neuron Structure of Neuron Types of Neuron Models of Neuron Analogy with human NN Perceptron OCR Multilayer Neural Network Back propagation
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92
 ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
Introduction to Machine Learning Spring 2018 Note Neural Networks
 CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
Introduction Neural Networks - Architecture Network Training Small Example - ZIP Codes Summary. Neural Networks - I. Henrik I Christensen
 Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Supervised (BPL) verses Hybrid (RBF) Learning. By: Shahed Shahir
 verses Hybrid (RBF) Learning. By: Shahed Shahir") Supervised (BPL) verses Hybrid (RBF) Learning By: Shahed Shahir 1 Outline I. Introduction II. Supervised Learning III. Hybrid Learning IV. BPL Verses RBF V. Supervised verses Hybrid learning VI. Conclusion
Supervised (BPL) verses Hybrid (RBF) Learning By: Shahed Shahir 1 Outline I. Introduction II. Supervised Learning III. Hybrid Learning IV. BPL Verses RBF V. Supervised verses Hybrid learning VI. Conclusion
Part 8: Neural Networks
 METU Informatics Institute Min720 Pattern Classification ith Bio-Medical Applications Part 8: Neural Netors - INTRODUCTION: BIOLOGICAL VS. ARTIFICIAL Biological Neural Netors A Neuron: - A nerve cell as
METU Informatics Institute Min720 Pattern Classification ith Bio-Medical Applications Part 8: Neural Netors - INTRODUCTION: BIOLOGICAL VS. ARTIFICIAL Biological Neural Netors A Neuron: - A nerve cell as
Statistical NLP for the Web
 Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Sections 18.6 and 18.7 Artificial Neural Networks
 Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs. artifical neural
Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs. artifical neural
Lecture 6. Notes on Linear Algebra. Perceptron
 Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Artificial neural networks
 Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Neural Networks Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav
 Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Introduction and Perceptron Learning
 Artificial Neural Networks Introduction and Perceptron Learning CPSC 565 Winter 2003 Christian Jacob Department of Computer Science University of Calgary Canada CPSC 565 - Winter 2003 - Emergent Computing
Artificial Neural Networks Introduction and Perceptron Learning CPSC 565 Winter 2003 Christian Jacob Department of Computer Science University of Calgary Canada CPSC 565 - Winter 2003 - Emergent Computing