DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
|
|
|
- Shonda Freeman
- 5 years ago
- Views:
Transcription

1 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1
2 On-line Resources Online book by Michael Nielsen - of convolutions /mnist.html - demo of CNN - 3D visualization Stanford CS class CS231n: Convolutional Neural Networks for Visual Recognition. MIT Press book from Bengio et al, free online version 2
3 A history of neural networks 1940s-60 s: McCulloch & Pitts; Hebb: modeling real neurons Rosenblatt, Widrow-Hoff: : perceptrons 1969: Minskey & Papert, Perceptrons book showed formal limitations of one-layer linear network 1970 s-mid-1980 s: mid-1980 s mid-1990 s: backprop and multi-layer networks Rumelhart and McClelland PDP book set Sejnowski s NETTalk, BP-based text-to-speech Neural Info Processing Systems (NIPS) conference starts Mid 1990 s-early 2000 s: Mid-2000 s to current: More and more interest and experimental success 3



4 4
5 5
6 6

7 7
8 Multilayer networks Simplest case: classifier is a multilayer network of logistic units Each unit takes some inputs and produces one output using a logistic classifier Output of one unit can be the input of another Input layer Hidden layer Output layer 1 w 0,2 w 0,1 w 1,1 v 1 =S(w T X) w 1 x 1 w 1,2 w 2,1 w 2 z 1 =S(w T V) x 2 w 2,2 v 2 =S(w T X) 8
9 Learning a multilayer network Define a loss (simplest case: squared error) But over a network of units Minimize loss with gradient descent J X,y (w) = ( y i y ˆ i 2 ) i You can do this over complex networks if you can take the gradient of each unit: every computation is differentiable 1 w 0,2 w 0,1 w 1,1 v 1 =S(w T X) w 1 x 1 w 1,2 w 2,1 w 2 z 1 =S(w T V) x 2 w 2,2 v 2 =S(w T X) 9
10 ANNs in the 90 s Mostly 2-layer networks or else carefully constructed deep networks (eg CNNs) Worked well but training was slow and finicky Nov 1998 Yann LeCunn, Bottou, Bengio, Haffner 10


11 ANNs in the 90 s Mostly 2-layer networks or else carefully constructed deep networks Worked well but training typically took weeks when guided by an expert SVM: % accurate CNNs: % accurate 11
12 Learning a multilayer network Define a loss (simplest case: squared error) But over a network of units Minimize loss with gradient descent J X,y (w) = ( y i y ˆ i 2 ) i You can do this over complex networks if you can take the gradient of each unit: every computation is differentiable 12
 k a ( k 1 a ) k For nodes j in hidden layer: δ j ( δ k w ) kj")

13 Example: weight updates for multilayer ANN with square loss and logistic units For nodes k in output layer: δ k ( t k a ) k a ( k 1 a ) k For nodes j in hidden layer: δ j ( δ k w ) kj a j 1 a j k For all weights: ( ) w kj = w kj ε δ k a j w ji = w ji ε δ j a i Propagate errors backward BACKPROP Can carry this recursion out further if you have multiple hidden layers 13
14 BACKPROP FOR MLPS 14
15 BackProp in Matrix-Vector Notation Michael Nielson: 15
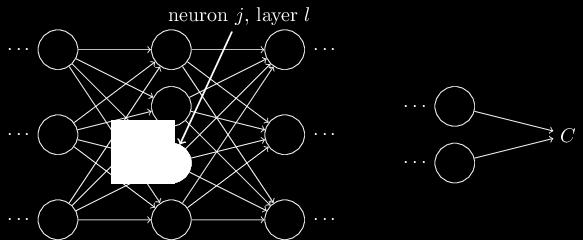
16 Notation 16


17 Notation Each digit is 28x28 pixels = 784 inputs 17

18 Notation w l is weight matrix for layer l 18



19 Notation w l a l and b l bias activation 19



20 Notation Matrix: w l Vector: a l Vector: b l Vector: z l bias weight activation vectoràvector function: componentwise logistic 20


21 Computation is feedforward for l=1, 2, L: 21

22 Notation Cost function to optimize: sum over examples x where Matrix: w l Vector: a l Vector: b l Vector: z l Vector: y 22

23 Notation 23

24 BackProp: last layer Matrix form: componentwise product of vectors components are components are Level l for l=1,,l Matrix: w l Vectors: bias b l activation a l pre-sigmoid activ: z l target output y local error δ l 24
25 BackProp: last layer Matrix form for square loss: Level l for l=1,,l Matrix: w l Vectors: bias b l activation a l pre-sigmoid activ: z l target output y local error δ l 25
26 BackProp: error at level l in terms of error at level l+1 which we can use to compute Level l for l=1,,l Matrix: w l Vectors: bias b l activation a l pre-sigmoid activ: z l target output y local error δ l 26
27 BackProp: summary Level l for l=1,,l Matrix: w l Vectors: bias b l activation a l pre-sigmoid activ: z l target output y local error δ l 27
28 Computation propagates errors backward for l=1, 2, L: for l=l,l-1, 1: 28
29 EXPRESSIVENESS OF DEEP NETWORKS 29
30 Deep ANNs are expressive One logistic unit can implement and AND or an OR of a subset of inputs e.g., (x 3 AND x 5 AND AND x 19 ) Every boolean function can be expressed as an OR of ANDs e.g., (x 3 AND x 5 ) OR (x 7 AND x 19 ) OR So one hidden layer can express any BF (But it might need lots and lots of hidden units) 30
31 Deep ANNs are expressive One logistic unit can implement and AND or an OR of a subset of inputs e.g., (x 3 AND x 5 AND AND x 19 ) Every boolean function can be expressed as an OR of ANDs e.g., (x 3 AND x 5 ) OR (x 7 AND x 19 ) OR So one hidden layer can express any BF Example: parity(x1,,xn)=1 iff off number of xi s are set to one Parity(a,b,c,d) = (a & -b & -c & -d) OR (-a & b & -c & -d) OR #list all the 1s (a & b & c & -d) OR (a & b & -c & d) OR #list all the 3s Size in general is O(2 N ) 31


32 Deeper ANNs are more expressive A two-layer network needs O(2 N ) units A two-layer network can express binary XOR A 2*logN layer network can express the parity of N inputs (even/odd number of 1 s) With O(logN) units in a binary tree Deep network + parameter tying ~= subroutines x1 x2 x3 x4 x5 x6 x7 x8 32
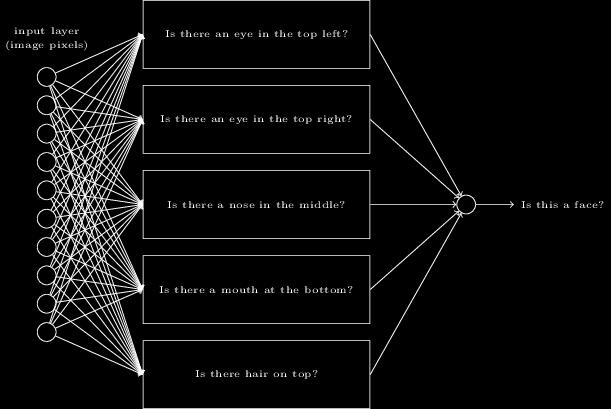

33 Hypothetical code for face recognition.. 33
34 PARALLEL TRAINING FOR ANNS 34
35 How are ANNs trained? Typically, with some variant of streaming SGD Keep the data on disk, in a preprocessed form Loop over it multiple times Keep the model in memory Solution to big data: but long training times! However, some parallelism is often used. 35



36 Recap: logistic regression with SGD 1 P(Y =1 X = x) = p = 1+ e x w This part computes inner product <x,w> This part logistic of <x,w> 36
 = p = 1+ e x w a z On one example:")

37 Recap: logistic regression with SGD 1 P(Y =1 X = x) = p = 1+ e x w a z On one example: computes inner product <x,w> There s some chance to compute this in parallel can we do more? 37
38 In ANNs we have many many logistic regression nodes 38
39 Recap: logistic regression with SGD Let x be an example Let w i be the input weights for the i-th hidden unit Then output a i = x. w i a i z i 39
40 Recap: logistic regression with SGD Let x be an example Let w i be the input weights for the i-th hidden unit Then a = x W is output for all m units w 1 w 2 w 3 w m W = a i z i 40
41 Recap: logistic regression with SGD Let X be a matrix with k examples Let w i be the input weights for the i-th hidden unit Then A = X W is output for all m units for all k examples w 1 w 2 w 3 w m x x 2 x k There s a lot of chances to do this in parallel XW = x 1.w 1 x 1.w 2 x 1.w m x k.w 1 x k.w m 41
42 ANNs and multicore CPUs Modern libraries (Matlab, numpy, ) do matrix operations fast, in parallel Many ANN implementations exploit this parallelism automatically Key implementation issue is working with matrices comfortably 42
43 ANNs and GPUs GPUs do matrix operations very fast, in parallel For dense matrixes, not sparse ones! Training ANNs on GPUs is common SGD and minibatch sizes of 128 Modern ANN implementations can exploit this GPUs are not super-expensive $500 for high-end one large models with O(10 7 ) parameters can fit in a large-memory GPU (12Gb) Speedups of 20x-50x have been reported 43
44 ANNs and multi-gpu systems There are ways to set up ANN computations so that they are spread across multiple GPUs Sometimes involves some sort of IPM Sometimes involves partitioning the model across multiple GPUs Often needed for very large networks Not especially easy to implement and do with most current tools 44
45 WHY ARE DEEP NETWORKS HARD TO TRAIN? 45
46 Recap: weight updates for multilayer δ L k t k a k ANN For nodes k in output layer L: ( ) a k ( 1 a k ) For nodes j in hidden layer h: ( ) δ h δ h+1 w j j kj a j 1 a j k ( ) What happens as the layers get further and further from the output layer? E.g., what s gradient for the bias term with several layers after it? 46
47 Gradients are unstable Max at 1/4 If weights are usually < 1 then we are multiplying by many numbers < 1 so the gradients get very small. The vanishing gradient problem What happens as the layers get further and further from the output layer? E.g., what s gradient for the bias term with several layers after it in a trivial net? 47
 get further and further from the output layer? E.g., what s gradient for the bias term with several layers after it in a trivial net?")
48 Gradients are unstable Max at 1/4 If weights are usually > 1 then we are multiplying by many numbers > 1 so the gradients get very big. The exploding gradient problem What happens (less common as the but layers possible) get further and further from the output layer? E.g., what s gradient for the bias term with several layers after it in a trivial net? 48
49 AI Stats 2010 input output Histogram of gradients in a 5-layer network for an artificial image recognition task 49

50 AI Stats 2010 We will get to these tricks eventually. 50



51 It s easy for sigmoid units to saturate components Learning are rate approaches zero and unit is stuck 51
52 It s easy for sigmoid units to saturate For a big network there are lots of weighted inputs to each neuron. If any of them are too large then the neuron will saturate. So neurons get stuck with a few large inputs OR many small ones. 52
53 It s easy for sigmoid units to saturate If there are 500 non-zero inputs initialized with a Gaussian ~N(0,1) then the SD is

54 It s easy for sigmoid units to saturate Saturation visualization from Glorot & Bengio using a smarter initialization scheme Closest-to-output hidden layer still stuck for first 100 epochs 54
55 WHAT S DIFFERENT ABOUT MODERN ANNS? 55
56 Some key differences Use of softmax and entropic loss instead of quadratic loss. Use of alternate non-linearities relu and hyperbolic tangent Better understanding of weight initialization Data augmentation Especially for image data 56
57 Cross-entropy loss Compare to gradient for square loss when a~=1 y=0 and x=1 C w = σ (z) y a z 57
58 Cross-entropy loss 58
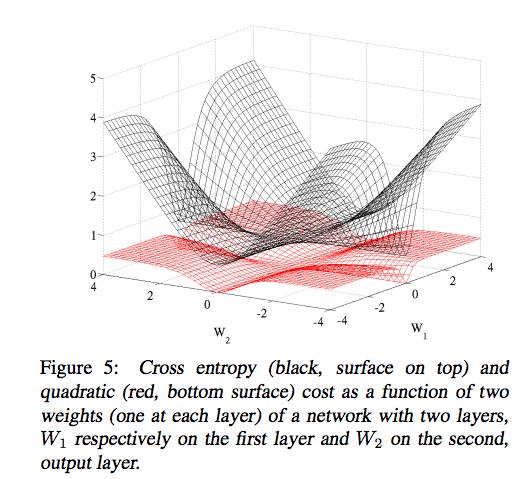
59 Cross-entropy loss 59


60 Softmax output layer Softmax Network outputs a probability distribution! Cross-entropy loss after a softmax layer gives a very simple, numerically stable gradient Δw ij = (y i -z i )y j 60
61 Some key differences Use of softmax and entropic loss instead of quadratic loss. Often learning is faster and more stable as well as getting better accuracies in the limit Use of alternate non-linearities Better understanding of weight initialization Data augmentation Especially for image data 61
62 Some key differences Use of softmax and entropic loss instead of quadratic loss. Often learning is faster and more stable as well as getting better accuracies in the limit Use of alternate non-linearities relu and hyperbolic tangent Better understanding of weight initialization Data augmentation Especially for image data 62
63 Alternative non-linearities Changes so far Changed the loss from square error to crossentropy Proposed adding another output layer (softmax) A new change: modifying the nonlinearity The logistic is not widely used in modern ANNs 63

64 Alternative non-linearities A new change: modifying the nonlinearity The logistic is not widely used in modern ANNs Alternate 1: tanh Like logistic function but shifted to range [-1, +1] 64
65 AI Stats 2010 depth 5 We will get to these tricks eventually. 65

66 Alternative non-linearities A new change: modifying the nonlinearity relu often used in vision tasks Alternate 2: rectified linear unit Linear with a cutoff at zero (Implement: clip the gradient when you pass zero) 66
67 Alternative non-linearities A new change: modifying the nonlinearity relu often used in vision tasks Alternate 2: rectified linear unit Soft version: log(exp(x)+1) Doesn t saturate (at one end) Sparsifies outputs Helps with vanishing gradient 67
68 Some key differences Use of softmax and entropic loss instead of quadratic loss. Often learning is faster and more stable as well as getting better accuracies in the limit Use of alternate non-linearities relu and hyperbolic tangent Better understanding of weight initialization Data augmentation Especially for image data 68
69 It s easy for sigmoid units to saturate For a big network there are lots of weighted inputs to each neuron. If any of them are too large then the neuron will saturate. So neurons get stuck with a few large inputs OR many small ones. 69
70 It s easy for sigmoid units to saturate If there are 500 non-zero inputs initialized with a Gaussian ~N(0,1) then the SD is Common heuristics for initializing weights:! N # 0, " 1 #inputs $ & % " U $ # 1 #inputs, 1 #inputs % ' & 70
71 It s easy for sigmoid units to saturate Saturation visualization from Glorot & Bengio 2010 using " U $ # 1 #inputs, 1 #inputs % ' & 71
 from based on clever pre-training")

72 Initializing to avoid saturation In Glorot First breakthrough and Bengiodeep they learning suggest results weights were if level j (with n j inputs) from based on clever pre-training initialization schemes, where deep networks were seeded with weights learned from unsupervised strategies This is not always the solution but good initialization is very important for deep nets! 72
Deep neural networks
 Deep neural networks On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo - of convolutions
Deep neural networks On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo - of convolutions
Backpropagation Introduction to Machine Learning. Matt Gormley Lecture 12 Feb 23, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
Neural Networks Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav
 Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]
![Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]](/thumbs/88/117565192.jpg "Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]") Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Artificial Neuron (Perceptron)
") 9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Feed-forward Network Functions
 Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification
Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Deep Feedforward Networks. Han Shao, Hou Pong Chan, and Hongyi Zhang
 Deep Feedforward Networks Han Shao, Hou Pong Chan, and Hongyi Zhang Deep Feedforward Networks Goal: approximate some function f e.g., a classifier, maps input to a class y = f (x) x y Defines a mapping
Deep Feedforward Networks Han Shao, Hou Pong Chan, and Hongyi Zhang Deep Feedforward Networks Goal: approximate some function f e.g., a classifier, maps input to a class y = f (x) x y Defines a mapping
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
EEE 241: Linear Systems
 EEE 4: Linear Systems Summary # 3: Introduction to artificial neural networks DISTRIBUTED REPRESENTATION An ANN consists of simple processing units communicating with each other. The basic elements of
EEE 4: Linear Systems Summary # 3: Introduction to artificial neural networks DISTRIBUTED REPRESENTATION An ANN consists of simple processing units communicating with each other. The basic elements of
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Multilayer Perceptrons (MLPs)
") CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Back-Propagation Algorithm. Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples
 Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Machine Learning Lecture 14
 Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1
 What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Lecture 35: Optimization and Neural Nets
 Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Perceptron & Neural Networks
 School of Computer Science 10-701 Introduction to Machine Learning Perceptron & Neural Networks Readings: Bishop Ch. 4.1.7, Ch. 5 Murphy Ch. 16.5, Ch. 28 Mitchell Ch. 4 Matt Gormley Lecture 12 October
School of Computer Science 10-701 Introduction to Machine Learning Perceptron & Neural Networks Readings: Bishop Ch. 4.1.7, Ch. 5 Murphy Ch. 16.5, Ch. 28 Mitchell Ch. 4 Matt Gormley Lecture 12 October
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Introduction Biologically Motivated Crude Model Backpropagation
 Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
DEEP LEARNING PART ONE - INTRODUCTION CS/CNS/EE MACHINE LEARNING & DATA MINING - LECTURE 7
 DEEP LEARNING PART ONE - INTRODUCTION CS/CNS/EE 155 - MACHINE LEARNING & DATA MINING - LECTURE 7 INTRODUCTION & MOTIVATION data labels 3 y is continuous y is binary or categorical y y x x regression classification
DEEP LEARNING PART ONE - INTRODUCTION CS/CNS/EE 155 - MACHINE LEARNING & DATA MINING - LECTURE 7 INTRODUCTION & MOTIVATION data labels 3 y is continuous y is binary or categorical y y x x regression classification
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
2018 EE448, Big Data Mining, Lecture 5. (Part II) Weinan Zhang Shanghai Jiao Tong University
 Weinan Zhang Shanghai Jiao Tong University") 2018 EE448, Big Data Mining, Lecture 5 Supervised Learning (Part II) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
2018 EE448, Big Data Mining, Lecture 5 Supervised Learning (Part II) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural networks COMS 4771
 Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Artificial Neural Networks
 Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
10. Artificial Neural Networks
 Foundations of Machine Learning CentraleSupélec Fall 217 1. Artificial Neural Networks Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning
Foundations of Machine Learning CentraleSupélec Fall 217 1. Artificial Neural Networks Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Introduction To Artificial Neural Networks
 Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Supervised (BPL) verses Hybrid (RBF) Learning. By: Shahed Shahir
 verses Hybrid (RBF) Learning. By: Shahed Shahir") Supervised (BPL) verses Hybrid (RBF) Learning By: Shahed Shahir 1 Outline I. Introduction II. Supervised Learning III. Hybrid Learning IV. BPL Verses RBF V. Supervised verses Hybrid learning VI. Conclusion
Supervised (BPL) verses Hybrid (RBF) Learning By: Shahed Shahir 1 Outline I. Introduction II. Supervised Learning III. Hybrid Learning IV. BPL Verses RBF V. Supervised verses Hybrid learning VI. Conclusion
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation
 Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
Deep Learning: a gentle introduction
 Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
CS60010: Deep Learning
 CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
CMSC 421: Neural Computation. Applications of Neural Networks
 CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
Advanced Machine Learning
 Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning Lecture 12
 Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features