Natural Language Processing
|
|
|
- Mavis Bailey
- 5 years ago
- Views:
Transcription
1 Natural Language Processing Pushpak Bhattacharyya CSE Dept, IIT Patna and Bombay LSTM 15 jun, 2017 lgsoft:nlp:lstm:pushpak 1
2 Recap 15 jun, 2017 lgsoft:nlp:lstm:pushpak 2
3 Feedforward Network and Backpropagation 15 jun, 2017 lgsoft:nlp:lstm:pushpak 3
4 Backpropagation algorithm i w ji j... Output layer (m o/p neurons) Hidden layers. Input layer (n i/p neurons) n Fully connected feed forward network n Pure FF network (no jumping of connections over layers) 15 jun, 2017 lgsoft:nlp:lstm:pushpak 4
5 General Backpropagation Rule General weight updating rule: Where Δw = ηδ ji jo i δ j = ( t j o j ) o j (1 o j ) for outermost layer = ( w δ kj k ) o j (1 o j ) o k next layer i for hidden layers 15 jun, 2017 lgsoft:nlp:lstm:pushpak 5
6 Recurrent Neural Network 15 jun, 2017 lgsoft:nlp:lstm:pushpak 6
7 Sequence processing m/c 15 jun, 2017 lgsoft:nlp:lstm:pushpak 7
8 E.g. POS Tagging VBD NNP NN Purchased Videocon machine 15 jun, 2017 lgsoft:nlp:lstm:pushpak 8
9 E.g. Sentiment Analysis I Decision on a piece of text h 0 h 1 c 1 a 11 a 12 a 13 a 14 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 9
10 I like h 0 h 1 h 2 c 2 a 21 a 22 a 23 a 24 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 10
11 I like the h 0 h 1 h 2 h 3 c 3 a 31 a32 a33 a 34 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 11
12 I like the camera h 0 h 1 h 2 h 3 h 4 c 4 a 41 a42 a 43 a 44 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 12
13 I like the camera <EOS > h 0 h 1 h 2 h 3 h 4 h 5 Positive sentiment c 5 a 51 a52 a 53 a 54 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 13
14 Notation: input and state n x t : input at time step t n s t : hidden state at time step t. It is the memory of the network. n s t = f(u.x t +Ws t-1 ) U and W matrices are learnt n f is Usually tanh or ReLU (approximated by softplus) 15 jun, 2017 lgsoft:nlp:lstm:pushpak 14
15 Tanh, ReLU (rectifier linear unit) and Softplus tanh = e e x x + e e tanh = x x f ( x) = max(0, x) g ( x) = ln(1 + e x ) 15 jun, 2017 lgsoft:nlp:lstm:pushpak 15
16 Notation: output n o t is the output at step t n For example, if we wanted to predict the next word in a sentence it would be a vector of probabilities across our vocabulary n o t =softmax(v.s t ) 15 jun, 2017 lgsoft:nlp:lstm:pushpak 16
17 Backpropagation through time (BPTT algorithm) n The forward pass at each time step. n n The backward pass computes the error derivatives at each time step. n After the backward pass we add together the derivatives at all the different times for each weight. 15 jun, 2017 lgsoft:nlp:lstm:pushpak 17
18 A recurrent net for binary addition Two input units and one output unit. Given two input digits at each time step. The desired output at each time step is the output for the column that was provided as input two time steps ago. It takes one time step to update the hidden units based on the two input digits. It takes another time step for the hidden units to cause the output time 15 jun, 2017 lgsoft:nlp:lstm:pushpak 18
19 The connectivity of the network The input units have feed forward connections Allow them to vote for the next hidden activity pattern. 3 fully interconnected hidden units 15 jun, 2017 lgsoft:nlp:lstm:pushpak 19
20 What the network learns n Learns four distinct patterns of activity for the 3 hidden units. n Patterns correspond to the nodes in the finite state automaton n Nodes in FSM are like activity vectors n The automaton is restricted to be in exactly one state at each time n The hidden units are restricted to have exactly one vector of activity at each time. 15 jun, 2017 lgsoft:nlp:lstm:pushpak 20
21 Recall: Backpropagation Rule General weight updating rule: Where Δw = ηδ ji jo i δ j = ( t j o j ) o j (1 o j ) for outermost layer = ( w δ kj k ) o j (1 o j ) o k next layer i for hidden layers 15 jun, 2017 lgsoft:nlp:lstm:pushpak 21
22 The problem of exploding or vanishing gradients If the weights are small, the gradients shrink exponentially If the weights are big the gradients grow exponentially. Typical feed-forward neural nets can cope with these exponential effects because they only have a few hidden layers. 15 jun, 2017 lgsoft:nlp:lstm:pushpak 22
23 LSTM (Ack: Lecture notes of Taylor Arnold, Yale and Understanding-LSTMs/) 15 jun, 2017 lgsoft:nlp:lstm:pushpak 23

24 LSTM: a variation of vanilla RNN Vanilla RNN 15 jun, 2017 lgsoft:nlp:lstm:pushpak 24

25 LSTM: complexity within the block 15 jun, 2017 lgsoft:nlp:lstm:pushpak 25
26 Central idea n Memory cell maintains its state over time n Non-linear gating units regulate the information flow into and out of the cell 15 jun, 2017 lgsoft:nlp:lstm:pushpak 26
27 A simple line diagram for LSTM 15 jun, 2017 lgsoft:nlp:lstm:pushpak 27
28 Stepping through Constituents of LSTM 15 jun, 2017 lgsoft:nlp:lstm:pushpak 28
29 Again: Example of Refrigerator complaint n Visiting service person is becoming rarer and rarer, (ambiguous! visit to service person OR visit by service person?) n and I am regretting/appreciating my decision to have bought the refrigerator from this company (appreciating à to ; regretting à by ) 15 jun, 2017 lgsoft:nlp:lstm:pushpak 29
30 Possibilities n Visiting : visit to or visit by (ambiguity, syntactic opacity) n Problem: solved or unsolved (not known, semantic opacity) n Appreciating / Regretting : transparent; available on the surface 15 jun, 2017 lgsoft:nlp:lstm:pushpak 30
31 4 possibilities (states) Clue-1 Clue-2 Problem Sentiment Visit to service person Visit to service person Appreciating solved Positive Appreciating Not solved Not making sense! Incoherent Visit to service person Regretting solved May be reverse sarcasm Visit to service person Regretting Not solved Negative 15 jun, 2017 lgsoft:nlp:lstm:pushpak 31
32 4 possibilities (states) Clue-1 Clue-2 Problem Sentiment Visit by service person Visit by service person Appreciating solved Positive Appreciating Not solved May be sarcastic Visit by service person Regretting solved May be reverse sarcasm Visit by service person Regretting Not solved Negative 15 jun, 2017 lgsoft:nlp:lstm:pushpak 32

33 LSTM constituents: Cell State The first and foremost component- the controller of flow of information 15 jun, 2017 lgsoft:nlp:lstm:pushpak 33

34 LSTM constituents- Forget Gate Helps forget irrelevant information. Sigmoid function. Output is between 0 and 1. Because of product, close to 1 will be full pass, close to 0 no pass 15 jun, 2017 lgsoft:nlp:lstm:pushpak 34

35 LSTM constituents: Input gate tanh produces a cell state vector; multiplied with input gate which again 0-1 controls what and how much input goes FOWARD 15 jun, 2017 lgsoft:nlp:lstm:pushpak 35

36 Cell state operation 15 jun, 2017 lgsoft:nlp:lstm:pushpak 36
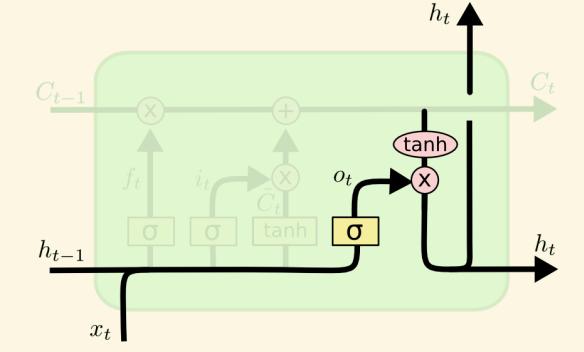
37 15 jun, 2017 lgsoft:nlp:lstm:pushpak 37

38 Finally 15 jun, 2017 lgsoft:nlp:lstm:pushpak 38
39 Better picture (the one we started with) 15 jun, 2017 lgsoft:nlp:lstm:pushpak 39
40 Another picture 15 jun, 2017 lgsoft:nlp:lstm:pushpak 40

41 LSTM schematic greff et al. LSTM a Space Odyssey, arxiv jun, 2017 lgsoft:nlp:lstm:pushpak 41
42 Legend 15 jun, 2017 lgsoft:nlp:lstm:pushpak 42
43 Required mathematics 15 jun, 2017 lgsoft:nlp:lstm:pushpak 43
44 Training of LSTM 15 jun, 2017 lgsoft:nlp:lstm:pushpak 44
45 Many layers and gates n Though complex, in principle possible to train n Gates are also sigmoid or tanh networks n Remember the FUNDAMENTAL backpropagation rule 15 jun, 2017 lgsoft:nlp:lstm:pushpak 45
46 General Backpropagation Rule General weight updating rule: Where Δw = ηδ ji jo i δ j = ( t j o j ) o j (1 o j ) for outermost layer = ( w δ kj k ) o j (1 o j ) o k next layer i for hidden layers 15 jun, 2017 lgsoft:nlp:lstm:pushpak 46
47 LSTM tools n Tensorflow, Ocropus, RNNlib etc. n Tools do everything internally n Still insights and concepts are inevitable 15 jun, 2017 lgsoft:nlp:lstm:pushpak 47
48 LSTM applications 15 jun, 2017 lgsoft:nlp:lstm:pushpak 48
49 Many applications n n n n Language modeling (The tensorflow tutorial on PTB is a good place to start Recurrent Neural Networks) character and word level LSTM s are used Machine Translation also known as sequence to sequence learning ( Image captioning (with and without attention, Hand writing generation ( n Image generation using attention models - my favorite ( n n Question answering ( Video to text ( 15 jun, 2017 lgsoft:nlp:lstm:pushpak 49
50 Deep Learning Based Seq2Seq Models and POS Tagging Acknowledgement: Anoop Kunchukuttan, PhD Scholar, IIT Bombay 15 jun, 2017 lgsoft:nlp:lstm:pushpak 50
51 So far we are seen POS tagging as a sequence labelling task For every element, predict the tag/label (using function f ) I read the book f f f f PRP VB DT NN Length of output sequence is same as input sequence Prediction of tag at time t can use only the words seen till time t 15 jun, 2017 lgsoft:nlp:lstm:pushpak 51
52 We can also look at POS tagging as a sequence to sequence transformation problem Read the entire sequence and predict the output sequence (using function F) Length of output I read the book sequence need not be the same as input sequence F Prediction at any time step t has access to the entire input A more general PRP VB DT NN framework than sequence labelling 15 jun, 2017 lgsoft:nlp:lstm:pushpak 52
53 Sequence to Sequence transformation is a more general framework than sequence labelling Many other problems can be expressed as sequence to sequence transformation e.g. machine translation, summarization, question answering, dialog Adds more capabilities which can be useful for problems like MT: many many mappings: insertion/deletion to words, one-one mappings non-monotone mappings: reordering of words For POS tagging, these capabilites are not required How does a sequence to sequence model work? Let s see two paradigms 15 jun, 2017 lgsoft:nlp:lstm:pushpak 53
54 Encode - Decode Paradigm (5) continue till end of sequence tag is generated Use two RNN networks: the encoder and the decoder (4) Decoder generates one element at a time (1) Encoder processes one sequences at a time (3) This is used to initialize the decoder state PRP VB DT h 0 h 1 h 2 h 3 NN h 4 <EO S> s 0 s 1 s 1 s 3 s 4 I read the book Decodin g (2) A representation of the sentence is generated Encoding 15 jun, 2017 lgsoft:nlp:lstm:pushpak 54
55 This approach reduces the entire sentence representation to a single vector Two problems with this design choice: This is not sufficient to represent to capture all the syntactic and semantic complexities of a sentence Solution: Use a richer representation for the sentences Problem of capturing long term dependencies: The decoder RNN will not be able to able to make use of source sentence representation after a few time steps Solution: Make source sentence information when making the next prediction Even better, make RELEVANT source sentence information available These solutions motivate the next paradigm 15 jun, 2017 lgsoft:nlp:lstm:pushpak 55
56 Encode - Attend - Decode Paradigm Annotation vectors Represent the source sentence by the set of output vectors from the encoder Each output vector at time t is a contextual representation of the input at time t s 0 s 1 s2 s 3 s 4 I read the book Note: in the encoderdecode paradigm, we ignore the encoder outputs Let s call these encoder output vectors annotation vectors 15 jun, 2017 lgsoft:nlp:lstm:pushpak 56
 Not all annotation vectors are equally important for prediction of the next element (2) The annotation vector to use next depends on what has been generated so far by the decoder eg.")
57 How should the decoder use the set of annotation vectors while predicting the next character? Key Insight: (1) Not all annotation vectors are equally important for prediction of the next element (2) The annotation vector to use next depends on what has been generated so far by the decoder eg. To generate the 3 rd POS tag, the 3 rd annotation vector (hence 3 rd word) is most important One way to achieve this: Take a weighted average of the annotation vectors, with more weight to annotation vectors which need more focus or attention This averaged context vector is an input to the decoder For generation of i th output character: c i : context vector a ij : annotation weight for the j th annotation vector o j : j th annotation vector 15 jun, 2017 lgsoft:nlp:lstm:pushpak 57
58 PRP h 0 h 1 Let s see an example of how the attention mechanism works c 1 a 11 a 12 a 13 a 14 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 58
59 PRP VB h 0 h 1 h 2 c 2 a 21 a 22 a 23 a 24 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 59
60 PRP VB DT h 0 h 1 h 2 h 3 c 3 a 31 a32 a33 a 34 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 60
61 PRP VB DT NN h 0 h 1 h 2 h 3 h 4 c 4 a 41 a42 a 43 a 44 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 61
62 PRP VB DT NN <EOS > h 0 h 1 h 2 h 3 h 4 h 5 c 5 a 51 a52 a 53 a 54 o 1 o 2 o 3 o 4 15 jun, 2017 lgsoft:nlp:lstm:pushpak 62
63 But we do not know the attention weights? How do we find them? Let the training data help you decide!! Idea: Pick the attention weights that maximize the POS tagging accuracy (more precisely, decrease training data loss) Have an attention function that predicts the attention weights: a ij = A(o j,h i ;o) A could be implemented as a feedforward network which is a component of the overall network Then training the attention network with the rest of the network ensures that the attention weights are learnt to minimize the translation loss 15 jun, 2017 lgsoft:nlp:lstm:pushpak 63

64 OK, but do the attention weights actually show focus on certain parts? Here is an example of how attention weights represent a soft alignment for machine translation 15 jun, 2017 lgsoft:nlp:lstm:pushpak 64
65 Let s go back to the encoder. What type of encoder cell should we use there? Basic RNN: models sequence history by maintaining state information But, cannot model long range dependencies LSTM: can model history and is better at handling long range dependencies The RNN units model only the sequence seen so far, cannot see the sequence ahead Can use a bidirectional RNN/LSTM This is just 2 LSTM encoders run from opposite ends of the sequence and resulting output vectors are composed Both types of RNN units process the sequence sequentially, hence parallelism is limited Alternatively, we can use a CNN Can operate on a sequence in parallel However, cannot model entire sequence history Model only a short local context. This may be sufficient for some applications or deep CNN layers can overcome the problem 15 jun, 2017 lgsoft:nlp:lstm:pushpak 65
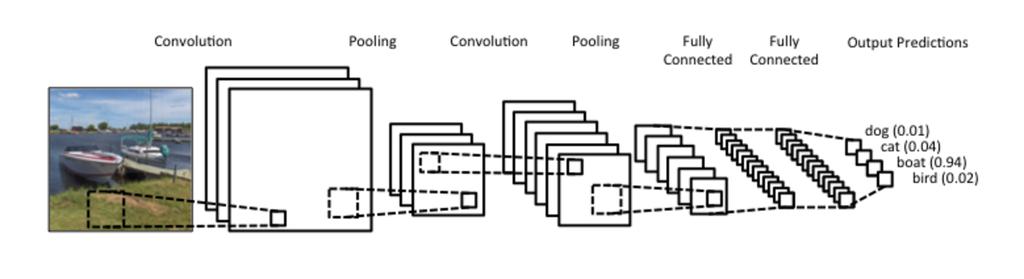
66 Convolutional Neural Network (CNN) 15 jun, 2017 lgsoft:nlp:lstm:pushpak 66
67 CNN= feedforward + recurrent! n Whatever we learnt so far in FF-BP is useful to understand CNN n So also is the case with RNN (and LSTM) n Input divided into regions and fed forward n Window slides over the input: input changes, but filter parameters remain same n That is RNN 15 jun, 2017 lgsoft:nlp:lstm:pushpak 67
68 Remember Neocognitron 15 jun, 2017 lgsoft:nlp:lstm:pushpak 68
69 15 jun, 2017 lgsoft:nlp:lstm:pushpak 69
70 Convolution Matrix on the left represents an black and white image Each entry corresponds to one pixel, 0 for black and 1 for white (typically it s between 0 and 255 for grayscale images). The sliding window is called a kernel, filter, or feature detector. Here we use a 3 3 filter, multiply its values element-wise with the original matrix, then sum them up. To get the full convolution we do this for each element by sliding the filter over the whole matrix. 15 jun, 2017 lgsoft:nlp:lstm:pushpak 70
71 CNN architecture n n n n Several layers of convolution with tanh or ReLU applied to the results In a traditional feedforward neural network we connect each input neuron to each output neuron in the next layer. That s also called a fully connected layer, or affine layer. In CNNs we use convolutions over the input layer to compute the output. This results in local connections, where each region of the input is connected to a neuron in the output 15 jun, 2017 lgsoft:nlp:lstm:pushpak 71
72 Learning in CNN n Automatically learns the values of its filters n For example, in Image Classification learn to n n n n detect edges from raw pixels in the first layer, then use the edges to detect simple shapes in the second layer, and then use these shapes to deter higher-level features, such as facial shapes in higher layers. The last layer is then a classifier that uses these high-level features. 15 jun, 2017 lgsoft:nlp:lstm:pushpak 72
73 Remember Neocognitron 15 jun, 2017 lgsoft:nlp:lstm:pushpak 73
74 15 jun, 2017 lgsoft:nlp:lstm:pushpak 74
75 What about NLP and CNN? n Natural Match! n NLP happens in layers 15 jun, 2017 lgsoft:nlp:lstm:pushpak 75
76 NLP: multilayered, multidimensional Parsing Problem Semantics NLP Trinity Discourse and Coreference Part of Speech Tagging Increased Complexity Of Processing Semantics Parsing CRF Morph Analysis HMM MEMM Hindi Marathi English French Language Chunking Algorithm POS tagging Morphology 22 Apr, 2017 LG:nlp:pos:pushpak 76
77 NLP layers and CNN n Morph layer à n POS layer à n Parse layer à n Semantics layer 15 jun, 2017 lgsoft:nlp:lstm:pushpak 77
78 15 jun, 2017 lgsoft:nlp:lstm:pushpak 78
79 15 jun, 2017 lgsoft:nlp:lstm:pushpak 79
80 Pooling n Gives invariance in translation, rotation and scaling n Important for image recognition n Role in NLP? 15 jun, 2017 lgsoft:nlp:lstm:pushpak 80
81 Input matrix for CNN: NLP image for NLP ßà word vectors in the rows For a 10 word sentence using a 100-dimensional Embedding, we would have a matrix as our input jun, 2017 lgsoft:nlp:lstm:pushpak 81
82 Credit: Denny Britz CNN for NLP 15 jun, 2017 lgsoft:nlp:lstm:pushpak 82
83 CNN Hyper parameters n Narrow width vs. wide width n Stride size n Pooling layers n Channels 15 jun, 2017 lgsoft:nlp:lstm:pushpak 83

84 Abhijit Mishra, Kuntal Dey and Pushpak Bhattacharyya, Learning Cognitive Features from Gaze Data for Sentiment and Sarcasm Classification Using Convolutional Neural Network, ACL 2017, Vancouver, Canada, July 30-August 4, jun, 2017 lgsoft:nlp:lstm:pushpak 84
85 Learning Cognitive Features from Gaze Data for Sentiment and Sarcasm Classification n In complex classification tasks like sentiment analysis and sarcasm detection, even the extraction and choice of features should be delegated to the learning system n CNN learns features from both gaze and text and uses them to classify the input text 15 jun, 2017 lgsoft:nlp:lstm:pushpak 85
Natural Language Processing
 Natural Language Processing Pushpak Bhattacharyya CSE Dept, IIT Patna and Bombay Recurrent Neural Network 1 NLP-ML marriage 2 An eample SMS complaint n I have purchased a 80 litre Videocon fridge about
Natural Language Processing Pushpak Bhattacharyya CSE Dept, IIT Patna and Bombay Recurrent Neural Network 1 NLP-ML marriage 2 An eample SMS complaint n I have purchased a 80 litre Videocon fridge about
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Slide credit from Hung-Yi Lee & Richard Socher
 Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Neural Architectures for Image, Language, and Speech Processing
 Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
arxiv: v3 [cs.lg] 14 Jan 2018
![arxiv: v3 [cs.lg] 14 Jan 2018](/thumbs/92/109503708.jpg "arxiv: v3 [cs.lg] 14 Jan 2018") A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
Task-Oriented Dialogue System (Young, 2000)
") 2 Review Task-Oriented Dialogue System (Young, 2000) 3 http://rsta.royalsocietypublishing.org/content/358/1769/1389.short Speech Signal Speech Recognition Hypothesis are there any action movies to see
2 Review Task-Oriented Dialogue System (Young, 2000) 3 http://rsta.royalsocietypublishing.org/content/358/1769/1389.short Speech Signal Speech Recognition Hypothesis are there any action movies to see
Recurrent Neural Networks
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Introduction to RNNs!
 Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Conditional Language modeling with attention
 Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Modelling Time Series with Neural Networks. Volker Tresp Summer 2017
 Modelling Time Series with Neural Networks Volker Tresp Summer 2017 1 Modelling of Time Series The next figure shows a time series (DAX) Other interesting time-series: energy prize, energy consumption,
Modelling Time Series with Neural Networks Volker Tresp Summer 2017 1 Modelling of Time Series The next figure shows a time series (DAX) Other interesting time-series: energy prize, energy consumption,
Stephen Scott.
 1 / 35 (Adapted from Vinod Variyam and Ian Goodfellow) sscott@cse.unl.edu 2 / 35 All our architectures so far work on fixed-sized inputs neural networks work on sequences of inputs E.g., text, biological
1 / 35 (Adapted from Vinod Variyam and Ian Goodfellow) sscott@cse.unl.edu 2 / 35 All our architectures so far work on fixed-sized inputs neural networks work on sequences of inputs E.g., text, biological
Recurrent and Recursive Networks
 Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Statistical NLP for the Web
 Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook
 Sumit Chopra Facebook") Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Recurrent Neural Network
 Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Neural Networks in Structured Prediction. November 17, 2015
 Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets)
") COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
Recurrent Neural Networks
 Recurrent Neural Networks Datamining Seminar Kaspar Märtens Karl-Oskar Masing Today's Topics Modeling sequences: a brief overview Training RNNs with back propagation A toy example of training an RNN Why
Recurrent Neural Networks Datamining Seminar Kaspar Märtens Karl-Oskar Masing Today's Topics Modeling sequences: a brief overview Training RNNs with back propagation A toy example of training an RNN Why
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function
 Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Natural Language Understanding. Recap: probability, language models, and feedforward networks. Lecture 12: Recurrent Neural Networks and LSTMs
 Natural Language Understanding Lecture 12: Recurrent Neural Networks and LSTMs Recap: probability, language models, and feedforward networks Simple Recurrent Networks Adam Lopez Credits: Mirella Lapata
Natural Language Understanding Lecture 12: Recurrent Neural Networks and LSTMs Recap: probability, language models, and feedforward networks Simple Recurrent Networks Adam Lopez Credits: Mirella Lapata
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Long-Short Term Memory
 Long-Short Term Memory Sepp Hochreiter, Jürgen Schmidhuber Presented by Derek Jones Table of Contents 1. Introduction 2. Previous Work 3. Issues in Learning Long-Term Dependencies 4. Constant Error Flow
Long-Short Term Memory Sepp Hochreiter, Jürgen Schmidhuber Presented by Derek Jones Table of Contents 1. Introduction 2. Previous Work 3. Issues in Learning Long-Term Dependencies 4. Constant Error Flow
Recurrent Neural Networks Deep Learning Lecture 5. Efstratios Gavves
 Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
TTIC 31230, Fundamentals of Deep Learning David McAllester, April Vanishing and Exploding Gradients. ReLUs. Xavier Initialization
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
Sequence Models. Ji Yang. Department of Computing Science, University of Alberta. February 14, 2018
 Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Deep Learning for NLP
 Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
EE-559 Deep learning Recurrent Neural Networks
 EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
Recurrent Neural Networks. deeplearning.ai. Why sequence models?
 Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Speech and Language Processing
 Speech and Language Processing Lecture 5 Neural network based acoustic and language models Information and Communications Engineering Course Takahiro Shinoaki 08//6 Lecture Plan (Shinoaki s part) I gives
Speech and Language Processing Lecture 5 Neural network based acoustic and language models Information and Communications Engineering Course Takahiro Shinoaki 08//6 Lecture Plan (Shinoaki s part) I gives
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Lecture 15: Exploding and Vanishing Gradients
 Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Deep Feedforward Networks
 Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Deep Feedforward Networks. Sargur N. Srihari
 Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Deep Learning and Lexical, Syntactic and Semantic Analysis. Wanxiang Che and Yue Zhang
 Deep Learning and Lexical, Syntactic and Semantic Analysis Wanxiang Che and Yue Zhang 2016-10 Part 2: Introduction to Deep Learning Part 2.1: Deep Learning Background What is Machine Learning? From Data
Deep Learning and Lexical, Syntactic and Semantic Analysis Wanxiang Che and Yue Zhang 2016-10 Part 2: Introduction to Deep Learning Part 2.1: Deep Learning Background What is Machine Learning? From Data
Analysis of Multilayer Neural Network Modeling and Long Short-Term Memory
 Analysis of Multilayer Neural Network Modeling and Long Short-Term Memory Danilo López, Nelson Vera, Luis Pedraza International Science Index, Mathematical and Computational Sciences waset.org/publication/10006216
Analysis of Multilayer Neural Network Modeling and Long Short-Term Memory Danilo López, Nelson Vera, Luis Pedraza International Science Index, Mathematical and Computational Sciences waset.org/publication/10006216
Recurrent Neural Networks (RNN) and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST
 and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST") 1 Recurrent Neural Networks (RNN) and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST Summary We have shown: Now First order optimization methods: GD (BP), SGD, Nesterov, Adagrad, ADAM, RMSPROP, etc. Second
1 Recurrent Neural Networks (RNN) and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST Summary We have shown: Now First order optimization methods: GD (BP), SGD, Nesterov, Adagrad, ADAM, RMSPROP, etc. Second
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 6
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 6 Slides adapted from Jordan Boyd-Graber, Chris Ketelsen Machine Learning: Chenhao Tan Boulder 1 of 39 HW1 turned in HW2 released Office
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 6 Slides adapted from Jordan Boyd-Graber, Chris Ketelsen Machine Learning: Chenhao Tan Boulder 1 of 39 HW1 turned in HW2 released Office
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Lecture 13: Structured Prediction
 Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
NLP Programming Tutorial 8 - Recurrent Neural Nets
 NLP Programming Tutorial 8 - Recurrent Neural Nets Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Feed Forward Neural Nets All connections point forward ϕ( x) y It is a directed acyclic
NLP Programming Tutorial 8 - Recurrent Neural Nets Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Feed Forward Neural Nets All connections point forward ϕ( x) y It is a directed acyclic
Deep Learning (CNNs)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Deep Learning Recurrent Networks 10/11/2017
 Deep Learning Recurrent Networks 10/11/2017 1 Which open source project? Related math. What is it talking about? And a Wikipedia page explaining it all The unreasonable effectiveness of recurrent neural
Deep Learning Recurrent Networks 10/11/2017 1 Which open source project? Related math. What is it talking about? And a Wikipedia page explaining it all The unreasonable effectiveness of recurrent neural
Deep Recurrent Neural Networks
 Deep Recurrent Neural Networks Artem Chernodub e-mail: a.chernodub@gmail.com web: http://zzphoto.me ZZ Photo IMMSP NASU 2 / 28 Neuroscience Biological-inspired models Machine Learning p x y = p y x p(x)/p(y)
Deep Recurrent Neural Networks Artem Chernodub e-mail: a.chernodub@gmail.com web: http://zzphoto.me ZZ Photo IMMSP NASU 2 / 28 Neuroscience Biological-inspired models Machine Learning p x y = p y x p(x)/p(y)
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
with Local Dependencies
 CS11-747 Neural Networks for NLP Structured Prediction with Local Dependencies Xuezhe Ma (Max) Site https://phontron.com/class/nn4nlp2017/ An Example Structured Prediction Problem: Sequence Labeling Sequence
CS11-747 Neural Networks for NLP Structured Prediction with Local Dependencies Xuezhe Ma (Max) Site https://phontron.com/class/nn4nlp2017/ An Example Structured Prediction Problem: Sequence Labeling Sequence
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
CSCI 315: Artificial Intelligence through Deep Learning
 CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks for Machine Learning. Lecture 2a An overview of the main types of neural network architecture
 Neural Networks for Machine Learning Lecture 2a An overview of the main types of neural network architecture Geoffrey Hinton with Nitish Srivastava Kevin Swersky Feed-forward neural networks These are
Neural Networks for Machine Learning Lecture 2a An overview of the main types of neural network architecture Geoffrey Hinton with Nitish Srivastava Kevin Swersky Feed-forward neural networks These are
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Deep Learning. Recurrent Neural Network (RNNs) Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning
 Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning") Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Recurrent Neural Networks. COMP-550 Oct 5, 2017
 Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Part-of-Speech Tagging + Neural Networks 2 CS 287
 Part-of-Speech Tagging + Neural Networks 2 CS 287 Review: Bilinear Model Bilinear model, ŷ = f ((x 0 W 0 )W 1 + b) x 0 R 1 d 0 start with one-hot. W 0 R d 0 d in, d 0 = F W 1 R d in d out, b R 1 d out
Part-of-Speech Tagging + Neural Networks 2 CS 287 Review: Bilinear Model Bilinear model, ŷ = f ((x 0 W 0 )W 1 + b) x 0 R 1 d 0 start with one-hot. W 0 R d 0 d in, d 0 = F W 1 R d in d out, b R 1 d out
Homework 3 COMS 4705 Fall 2017 Prof. Kathleen McKeown
 Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Deep Learning Architectures and Algorithms
 Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Deep Learning: a gentle introduction
 Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT. Slides credit: Graham Neubig
 Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
Deep Learning. Convolutional Neural Network (CNNs) Ali Ghodsi. October 30, Slides are partially based on Book in preparation, Deep Learning
 Ali Ghodsi. October 30, Slides are partially based on Book in preparation, Deep Learning") Convolutional Neural Network (CNNs) University of Waterloo October 30, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Convolutional Networks Convolutional
Convolutional Neural Network (CNNs) University of Waterloo October 30, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Convolutional Networks Convolutional
Natural Language Processing
 Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
 2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,