Normalization Techniques in Training of Deep Neural Networks
|
|
|
- Ruth Robinson
- 5 years ago
- Views:
Transcription
1 Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th, 2017
2 Outline Introduction to Deep Neural Networks (DNNs) Training DNNs: Optimization Batch Normalization Other Normalization Techniques Centered Weight Normalization
 Parametric model Y=F(X;")
3 Machine learning dataset D={X, Y} Input: X Output: Y Learning: Y=F(X) or P(Y X) Y=F(X) P(Y X) Fitting and Generalization Types: view of models Non-parametric model Y=F(X; x 1, x 2 x n ) Parametric model Y=F(X; θ)
=f T (f T 1 (")

4 Neural network Neural network Y=F(X)=f T (f T 1 ( f 1 (X))) f i x = g(wx + b) Nonlinear activation sigmod Relu

5 Deep neural network Why deep? Powerful representation capacity

6 Key properties of Deep learning End to End learning no distinction between feature extractor and classifier Deep architectures: Hierarchy of simpler non-linear modules
7 Applications and techniques of DNNs Successful applications in a range of domains Speech Computer Vision Natural Language processing Main techniques in using deep neural networks networks Design the architecture Module selection and Module connection Loss function Train the model based on optimization Initialize the parameters Search direction in parameters space Learning rate schedule Regularization techniques
8 Outline Introduction to Deep Neural Networks (DNNs) Training DNNs: Optimization Batch Normalization Other Normalization Techniques Centered Weight Normalization
 2 output (1, 0, 0) T 2 Backward,Calculate d L d x : d L =2(y y) y d L da (2)=d L σ dy a(2) (1 σ a (2) ) d L d L d W (2)= d L da d L d W (1)= d L da d h (1)=d L da (2) W(2) d L = d L")
9 Training of Neural Networks Multi-layer perceptron (example) x 0 = 1 h 0 (1) = 1 x 1 x 2 x 3 input hidden layer 1 Forward calculate y: a (1) = W (1) x h (1) = σ a (1) a (2) = W (2) h 1 y = σ a (2) MSE Loss: L=(y y) 2 output (1, 0, 0) T 2 Backward,Calculate d L d x : d L =2(y y) y d L da (2)=d L σ dy a(2) (1 σ a (2) ) d L d L d W (2)= d L da d L d W (1)= d L da d h (1)=d L da (2) W(2) d L = d L σ a (1) d h (1) a(1) (1 σ a (1) ) d L =d L dx da (2) h(1) 9 (1) x (1) W(1) 3 calculate gradient d L d W :


10 Optimization in Deep Model Goal: Update Iteratively: Challenge: Non-convex and local optimal points Saddle point Severe correlation between dimensions and highly non-isotropic parameter space (ill-shaped)

11 First order optimization First order stochastic gradient descent (SGD): The direction of the gradient Gradient is averaged by the sampled examples Disadvantage Over-aggressive steps on ridges Too small steps on plateaus Slow convergence non-robust performance. Figure 2: zig-zag iteration path for SGD

12 Advanced Optimization Estimate curvature or scale Quadratic optimization Newton or quasi-newton Inverse of Hessian Natural Gradient Inverse of FIM Estimate the scale AdaGrad Rmsprop Adam Iteration path of SGD (red) and NGD (green) Normalize input/activation Intuition:the landscape of cost w.r.t parameters is controlled by Input/activation L=(f(x,θ),y) Method: Stabilize the distribution of input/activation Normalize the input explicitly Normalize the input implicitly (constrain weights)
13 Some intuitions of normalization for optimization How Normalizing activation affect the optimization? y = w 1 x 1 + w 2 x 2 +b L=(y y)^2 w 2 0 < x 1 < 2 0 < x 2 < 0.5 w 2 0 < x1 = x 1 /2 < 1 0 < x 2 = x 2 2 < 1 L(w 1, w 2 ) L(w 1, w 2 ) w 1 w 1
14 Outline Introduction to Deep Neural Networks (DNNs) Training DNNs: Optimization Batch Normalization Other Normalization Techniques Centered Weight Normalization
15 Batch Normalization--motivation Solving Internal Covariate Shift h 2 = wh 1 h 1 = wx Whitening Input benefits optimization (1998,Lecun, Efficient back-propagation) centering Centering Decorrelate stretch y=wx, MSE loss stretch decorrelate
16 Batch Normalization--method Only standardize input: decorrelating is expensive Centering Stretch centering stretch How to do it? x = x E(x) std(x)
17 Batch Normalization--training Forward
18 Batch Normalization--training Backward
 Running average E x = α μ B + (1 α)e x Var x = α σ 2 B + 1 α")
19 Batch Normalization--Inference Inference (in paper) Inference (in practice) Running average E x = α μ B + (1 α)e x Var x = α σ 2 B + 1 α var x
 For deep model, before nonlinear Advantage of before nonlinear For Relu, half activated For sigmod, avoiding")
20 Batch Normalization how to use Convolution layer Wrapped as a module Before or after nonlinear? For shallow module, after nonlinear (Layer <11) For deep model, before nonlinear Advantage of before nonlinear For Relu, half activated For sigmod, avoiding saturated region. Advantage of after nonlinear The intuition of whitening


21 Batch Normalization how to use Example: Residual block (CVPR 2015) Pre-activation Residual block (ECCV 2016)
 For generalization Stochastic, works like")
22 Batch Normalization characteristics For accelerating training: Weight scale invariant: Not sensitive for weight initialization Adjustable learning rate Large learning rate Better conditioning, (1998 Lecun) For generalization Stochastic, works like Dropout
23 Batch Normalization Routine in deep feed forward neural networks, especially for CNNs. Weakness Can not be used for online learning Unstable for small mini batch size Used in RNN with caution
24 Batch Normalization for RNN The extra problems need be considered: Where BN should put? Sequence data 2016,ICASSP, Batch Normalized Recurrent Neural Networks How to put BN module Sequence data problem Frame-wise normalization Sequence-wise normalization
25 Batch Normalization for RNN 2017, ICLR, Recurrent Batch Normalization How to put BN module Sequence data problem T_max Frame-wise normalization It depends..
26 Outline Introduction to Deep Neural Networks (DNNs) Training DNNs: Optimization Batch Normalization Other Normalization Techniques Centered Weight Normalization
27 Norm-propagation (2016, ICML) Target BN s drawback: Can not be used for online learning Unstable for small mini batch size. Data independent parametric estimate of mean and variance Normalize input: 0-mean and unit variance Assuming W is orthogonal Derivate the nonlinear dynamic Relu:

28 Layer Normalization (2016, Arxiv) Target BN s drawback: Can not be used for online learning Unstable for small mini batch size RNN Normalizing each example, over dimensions BN LN
: h i = f i (W i h i 1 + b i ) Natural neural network Model parameters: Ω = {,V 1, d 1, V L, d L }")
29 Natural Neural Network (2015, NIPS) How about decorrelate the activations? Canonical model(mlp): h i = f i (W i h i 1 + b i ) Natural neural network Model parameters: Ω = {,V 1, d 1, V L, d L } Whitening coefficients : Φ = {,U 0, c 0, U L 1, c L 1 }
30 Weight Normalization (2016, NIPS) Target BN s drawback: Can not be used for online learning Unstable for small mini batch size RNN Express weight as new parameters Decouple direction and length of vectors
31 Reference batch normalization accelerating deep network training by reducing internal covariate shift, ICML 2015 (Batch Normalization) Normalization Propagation A Parametric Technique for Removing Internal Covariate Shift in Deep Networks, ICML, 2016 Weight Normalization A Simple Reparameterization to Accelerate Training of Deep Neural Networks, NIPS, 2016 Layer Normalization, Arxiv: , 2016 Recurrent Batch Normalization, ICLR,2017 Batch Normalized Recurrent Neural Networks, ICASSP, 2016 Natural Neural Networks, NIPS, 2015 Normalizing the normaliziers-comparing and extending network normalization schemes, ICLR, 2017 Batch Renormalization, Arxiv: , 2017 mean-normalized stochastic gradient for large-scale deep learning, ICASSP 2014 deep learning made easier by linear transformations in perceptrons, AISTATS
32 Outline Introduction to Deep Neural Networks (DNNs) Training DNNs: Optimization Batch Normalization Other Normalization Techniques Centered Weight Normalization
33 Centered Weight Normalization in Accelerating Training of Deep Neural Networks Lei Huang, Xianglong Liu, Yang Liu, Bo Lang, Dacheng Tao International Conference on Computer Vision (ICCV) 2017
34 Motivation Stable distribution in hidden layer Initialization method Random Init (1998, YanLecun) Zero-mean, stable-var Xavier Init (2010, Xavier) He Init (2015, He Kaiming) W~N 0, 2 n, n = out H W Keep desired characters during training
35 Method Formulation: Constrained optimization problem: Solution by re-parameterization
36 Method Using proxy parameter v: Gradient Information: Adjustable scale:

37 Method Wrapped as module for practitioner: Forward
38 Method Wrapped as module for practitioner: Backward


39 Discussion Beneficial Characters for training Stabilize the distributions Better Conditioning of Hessian Regularization in improving performance
40 Data set Yale-B SVHN Cifar10, Cifar100 ImageNet Experiments Reproducible experiments and Code:

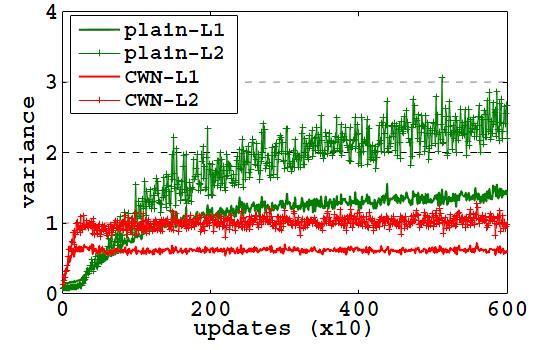


41 Experiments Ablation study YaleB, MLP{128,64,48,48}
42 Experiments MLP SVHN, {128,128,128,128,128} SGD optimization SGD+BN Adam optimization

43 Experiments MLP SVHN, {128,128,128,128,128} SGD optimization SGD+BN Adam optimization
44 Cifar10 & Cifar100 BN-Inception Experiments Cifar-10 Residual Network-56 layers. Cifar-100 Plain 6.14 ± ±0.15 WN 6.18 ± ±0.35 WCBN 6.01 ± ±0.54 Cifar-10 Cifar-100 Plain 7.34 ± ±0.14 WN 7.58 ± ±0.66 WCBN 6.85 ± ±0.14
45 ImageNet BN-Inception Experiments
46 Conclusion and Feature work Conclusion: CWN shows the advantages in accelerating training and better generalization CWN module as a optimal module to replace linear module Apply CWN module RNNs Reinforcement learning scene


47 Thanks!
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Normalization Techniques
 Normalization Techniques Devansh Arpit Normalization Techniques 1 / 39 Table of Contents 1 Introduction 2 Motivation 3 Batch Normalization 4 Normalization Propagation 5 Weight Normalization 6 Layer Normalization
Normalization Techniques Devansh Arpit Normalization Techniques 1 / 39 Table of Contents 1 Introduction 2 Motivation 3 Batch Normalization 4 Normalization Propagation 5 Weight Normalization 6 Layer Normalization
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Tutorial on: Optimization I. (from a deep learning perspective) Jimmy Ba
 Jimmy Ba") Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Neural Networks. Intro to AI Bert Huang Virginia Tech
 Neural Networks Intro to AI Bert Huang Virginia Tech Outline Biological inspiration for artificial neural networks Linear vs. nonlinear functions Learning with neural networks: back propagation https://en.wikipedia.org/wiki/neuron#/media/file:chemical_synapse_schema_cropped.jpg
Neural Networks Intro to AI Bert Huang Virginia Tech Outline Biological inspiration for artificial neural networks Linear vs. nonlinear functions Learning with neural networks: back propagation https://en.wikipedia.org/wiki/neuron#/media/file:chemical_synapse_schema_cropped.jpg
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Advanced Training Techniques. Prajit Ramachandran
 Advanced Training Techniques Prajit Ramachandran Outline Optimization Regularization Initialization Optimization Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise
Advanced Training Techniques Prajit Ramachandran Outline Optimization Regularization Initialization Optimization Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise
Nonlinear Optimization Methods for Machine Learning
 Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
Optimization for Training I. First-Order Methods Training algorithm
 Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
TTIC 31230, Fundamentals of Deep Learning David McAllester, April Vanishing and Exploding Gradients. ReLUs. Xavier Initialization
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
Internal Covariate Shift Batch Normalization Implementation Experiments. Batch Normalization. Devin Willmott. University of Kentucky.
 Batch Normalization Devin Willmott University of Kentucky October 23, 2017 Overview 1 Internal Covariate Shift 2 Batch Normalization 3 Implementation 4 Experiments Covariate Shift Suppose we have two distributions,
Batch Normalization Devin Willmott University of Kentucky October 23, 2017 Overview 1 Internal Covariate Shift 2 Batch Normalization 3 Implementation 4 Experiments Covariate Shift Suppose we have two distributions,
Deep Residual. Variations
 Deep Residual Network and Its Variations Diyu Yang (Originally prepared by Kaiming He from Microsoft Research) Advantages of Depth Degradation Problem Possible Causes? Vanishing/Exploding Gradients. Overfitting
Deep Residual Network and Its Variations Diyu Yang (Originally prepared by Kaiming He from Microsoft Research) Advantages of Depth Degradation Problem Possible Causes? Vanishing/Exploding Gradients. Overfitting
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Deep Learning & Neural Networks Lecture 4
 Deep Learning & Neural Networks Lecture 4 Kevin Duh Graduate School of Information Science Nara Institute of Science and Technology Jan 23, 2014 2/20 3/20 Advanced Topics in Optimization Today we ll briefly
Deep Learning & Neural Networks Lecture 4 Kevin Duh Graduate School of Information Science Nara Institute of Science and Technology Jan 23, 2014 2/20 3/20 Advanced Topics in Optimization Today we ll briefly
CSE 591: Introduction to Deep Learning in Visual Computing. - Parag S. Chandakkar - Instructors: Dr. Baoxin Li and Ragav Venkatesan
 CSE 591: Introduction to Deep Learning in Visual Computing - Parag S. Chandakkar - Instructors: Dr. Baoxin Li and Ragav Venkatesan Overview Background Why another network structure? Vanishing and exploding
CSE 591: Introduction to Deep Learning in Visual Computing - Parag S. Chandakkar - Instructors: Dr. Baoxin Li and Ragav Venkatesan Overview Background Why another network structure? Vanishing and exploding
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Lecture 6 Optimization for Deep Neural Networks
 Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Centered Weight Normalization in Accelerating Training of Deep Neural Networks
 Centered Weight Normalization in Accelerating Training of Deep Neural Networks Lei Huang Xianglong Liu Yang Liu Bo Lang Dacheng Tao State Key Laboratory of Software Development Environment, Beihang University,
Centered Weight Normalization in Accelerating Training of Deep Neural Networks Lei Huang Xianglong Liu Yang Liu Bo Lang Dacheng Tao State Key Laboratory of Software Development Environment, Beihang University,
Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates
 Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates Hiroaki Hayashi 1,* Jayanth Koushik 1,* Graham Neubig 1 arxiv:1611.01505v3 [cs.lg] 11 Jun 2018 Abstract Adaptive
Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates Hiroaki Hayashi 1,* Jayanth Koushik 1,* Graham Neubig 1 arxiv:1611.01505v3 [cs.lg] 11 Jun 2018 Abstract Adaptive
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent
 CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
Optimization for neural networks
 0 - : Optimization for neural networks Prof. J.C. Kao, UCLA Optimization for neural networks We previously introduced the principle of gradient descent. Now we will discuss specific modifications we make
0 - : Optimization for neural networks Prof. J.C. Kao, UCLA Optimization for neural networks We previously introduced the principle of gradient descent. Now we will discuss specific modifications we make
Lecture 14: Deep Generative Learning
 Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
arxiv: v1 [cs.lg] 16 Jun 2017
![arxiv: v1 [cs.lg] 16 Jun 2017](/thumbs/81/83659469.jpg "arxiv: v1 [cs.lg] 16 Jun 2017") L 2 Regularization versus Batch and Weight Normalization arxiv:1706.05350v1 [cs.lg] 16 Jun 2017 Twan van Laarhoven Institute for Computer Science Radboud University Postbus 9010, 6500GL Nijmegen, The Netherlands
L 2 Regularization versus Batch and Weight Normalization arxiv:1706.05350v1 [cs.lg] 16 Jun 2017 Twan van Laarhoven Institute for Computer Science Radboud University Postbus 9010, 6500GL Nijmegen, The Netherlands
Deep Learning & Artificial Intelligence WS 2018/2019
 Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
The K-FAC method for neural network optimization
 The K-FAC method for neural network optimization James Martens Thanks to my various collaborators on K-FAC research and engineering: Roger Grosse, Jimmy Ba, Vikram Tankasali, Matthew Johnson, Daniel Duckworth,
The K-FAC method for neural network optimization James Martens Thanks to my various collaborators on K-FAC research and engineering: Roger Grosse, Jimmy Ba, Vikram Tankasali, Matthew Johnson, Daniel Duckworth,
OPTIMIZATION METHODS IN DEEP LEARNING
 Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Unraveling the mysteries of stochastic gradient descent on deep neural networks
 Unraveling the mysteries of stochastic gradient descent on deep neural networks Pratik Chaudhari UCLA VISION LAB 1 The question measures disagreement of predictions with ground truth Cat Dog... x = argmin
Unraveling the mysteries of stochastic gradient descent on deep neural networks Pratik Chaudhari UCLA VISION LAB 1 The question measures disagreement of predictions with ground truth Cat Dog... x = argmin
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation
 Computational Graphs, Learning Algorithms, Initialisation") Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
Introduction to Convolutional Neural Networks 2018 / 02 / 23
 Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Convolutional Neural Network Architecture
 Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Overview of gradient descent optimization algorithms. HYUNG IL KOO Based on
 Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Machine Learning CS 4900/5900. Lecture 03. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
A picture of the energy landscape of! deep neural networks
 A picture of the energy landscape of! deep neural networks Pratik Chaudhari December 15, 2017 UCLA VISION LAB 1 Dy (x; w) = (w p (w p 1 (... (w 1 x))...)) w = argmin w (x,y ) 2 D kx 1 {y =i } log Dy i
A picture of the energy landscape of! deep neural networks Pratik Chaudhari December 15, 2017 UCLA VISION LAB 1 Dy (x; w) = (w p (w p 1 (... (w 1 x))...)) w = argmin w (x,y ) 2 D kx 1 {y =i } log Dy i
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Machine Learning Lecture 14
 Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Deep Learning Lecture 2
 Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Ch.6 Deep Feedforward Networks (2/3)
") Ch.6 Deep Feedforward Networks (2/3) 16. 10. 17. (Mon.) System Software Lab., Dept. of Mechanical & Information Eng. Woonggy Kim 1 Contents 6.3. Hidden Units 6.3.1. Rectified Linear Units and Their Generalizations
Ch.6 Deep Feedforward Networks (2/3) 16. 10. 17. (Mon.) System Software Lab., Dept. of Mechanical & Information Eng. Woonggy Kim 1 Contents 6.3. Hidden Units 6.3.1. Rectified Linear Units and Their Generalizations
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
Neural Networks Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav
 Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Maxout Networks. Hien Quoc Dang
 Maxout Networks Hien Quoc Dang Outline Introduction Maxout Networks Description A Universal Approximator & Proof Experiments with Maxout Why does Maxout work? Conclusion 10/12/13 Hien Quoc Dang Machine
Maxout Networks Hien Quoc Dang Outline Introduction Maxout Networks Description A Universal Approximator & Proof Experiments with Maxout Why does Maxout work? Conclusion 10/12/13 Hien Quoc Dang Machine
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Presentation in Convex Optimization
 Dec 22, 2014 Introduction Sample size selection in optimization methods for machine learning Introduction Sample size selection in optimization methods for machine learning Main results: presents a methodology
Dec 22, 2014 Introduction Sample size selection in optimization methods for machine learning Introduction Sample size selection in optimization methods for machine learning Main results: presents a methodology
Kernel Learning via Random Fourier Representations
 Kernel Learning via Random Fourier Representations L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Module 5: Machine Learning L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Kernel Learning via Random
Kernel Learning via Random Fourier Representations L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Module 5: Machine Learning L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Kernel Learning via Random
FreezeOut: Accelerate Training by Progressively Freezing Layers
 FreezeOut: Accelerate Training by Progressively Freezing Layers Andrew Brock, Theodore Lim, & J.M. Ritchie School of Engineering and Physical Sciences Heriot-Watt University Edinburgh, UK {ajb5, t.lim,
FreezeOut: Accelerate Training by Progressively Freezing Layers Andrew Brock, Theodore Lim, & J.M. Ritchie School of Engineering and Physical Sciences Heriot-Watt University Edinburgh, UK {ajb5, t.lim,
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Deep Learning II: Momentum & Adaptive Step Size
 Deep Learning II: Momentum & Adaptive Step Size CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following
Deep Learning II: Momentum & Adaptive Step Size CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN)
") EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
Stochastic Optimization Methods for Machine Learning. Jorge Nocedal
 Stochastic Optimization Methods for Machine Learning Jorge Nocedal Northwestern University SIAM CSE, March 2017 1 Collaborators Richard Byrd R. Bollagragada N. Keskar University of Colorado Northwestern
Stochastic Optimization Methods for Machine Learning Jorge Nocedal Northwestern University SIAM CSE, March 2017 1 Collaborators Richard Byrd R. Bollagragada N. Keskar University of Colorado Northwestern
UNSUPERVISED LEARNING
 UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
Non-Linearity. CS 188: Artificial Intelligence. Non-Linear Separators. Non-Linear Separators. Deep Learning I
 Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Convolutional Neural Networks. Srikumar Ramalingam
 Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
Neural Networks: Optimization & Regularization
 Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16 Slides adapted from Jordan Boyd-Graber, Justin Johnson, Andrej Karpathy, Chris Ketelsen, Fei-Fei Li, Mike Mozer, Michael Nielson
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16 Slides adapted from Jordan Boyd-Graber, Justin Johnson, Andrej Karpathy, Chris Ketelsen, Fei-Fei Li, Mike Mozer, Michael Nielson
Introduction to Machine Learning (67577)
") Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Sub-Sampled Newton Methods for Machine Learning. Jorge Nocedal
 Sub-Sampled Newton Methods for Machine Learning Jorge Nocedal Northwestern University Goldman Lecture, Sept 2016 1 Collaborators Raghu Bollapragada Northwestern University Richard Byrd University of Colorado
Sub-Sampled Newton Methods for Machine Learning Jorge Nocedal Northwestern University Goldman Lecture, Sept 2016 1 Collaborators Raghu Bollapragada Northwestern University Richard Byrd University of Colorado
A summary of Deep Learning without Poor Local Minima
 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
Contents. 1 Introduction. 1.1 History of Optimization ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016
 ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016 LECTURERS: NAMAN AGARWAL AND BRIAN BULLINS SCRIBE: KIRAN VODRAHALLI Contents 1 Introduction 1 1.1 History of Optimization.....................................
ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016 LECTURERS: NAMAN AGARWAL AND BRIAN BULLINS SCRIBE: KIRAN VODRAHALLI Contents 1 Introduction 1 1.1 History of Optimization.....................................
Lecture 7 Convolutional Neural Networks
 Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
Sajid Anwar, Kyuyeon Hwang and Wonyong Sung
 Sajid Anwar, Kyuyeon Hwang and Wonyong Sung Department of Electrical and Computer Engineering Seoul National University Seoul, 08826 Korea Email: sajid@dsp.snu.ac.kr, khwang@dsp.snu.ac.kr, wysung@snu.ac.kr
Sajid Anwar, Kyuyeon Hwang and Wonyong Sung Department of Electrical and Computer Engineering Seoul National University Seoul, 08826 Korea Email: sajid@dsp.snu.ac.kr, khwang@dsp.snu.ac.kr, wysung@snu.ac.kr
CSC321 Lecture 7: Optimization
 CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
Numerical Optimization Techniques
 Numerical Optimization Techniques Léon Bottou NEC Labs America COS 424 3/2/2010 Today s Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification,
Numerical Optimization Techniques Léon Bottou NEC Labs America COS 424 3/2/2010 Today s Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification,
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
IMPROVING STOCHASTIC GRADIENT DESCENT
 IMPROVING STOCHASTIC GRADIENT DESCENT WITH FEEDBACK Jayanth Koushik & Hiroaki Hayashi Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213, USA {jkoushik,hiroakih}@cs.cmu.edu
IMPROVING STOCHASTIC GRADIENT DESCENT WITH FEEDBACK Jayanth Koushik & Hiroaki Hayashi Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213, USA {jkoushik,hiroakih}@cs.cmu.edu
CSC321 Lecture 8: Optimization
 CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
Deep Feedforward Networks
 Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Normalized Gradient with Adaptive Stepsize Method for Deep Neural Network Training
 Normalized Gradient with Adaptive Stepsize Method for Deep Neural Network raining Adams Wei Yu, Qihang Lin, Ruslan Salakhutdinov, and Jaime Carbonell School of Computer Science, Carnegie Mellon University
Normalized Gradient with Adaptive Stepsize Method for Deep Neural Network raining Adams Wei Yu, Qihang Lin, Ruslan Salakhutdinov, and Jaime Carbonell School of Computer Science, Carnegie Mellon University
Improving L-BFGS Initialization for Trust-Region Methods in Deep Learning
 Improving L-BFGS Initialization for Trust-Region Methods in Deep Learning Jacob Rafati http://rafati.net jrafatiheravi@ucmerced.edu Ph.D. Candidate, Electrical Engineering and Computer Science University
Improving L-BFGS Initialization for Trust-Region Methods in Deep Learning Jacob Rafati http://rafati.net jrafatiheravi@ucmerced.edu Ph.D. Candidate, Electrical Engineering and Computer Science University
Mark Gales October y (x) x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.
 x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.") University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
Speaker Representation and Verification Part II. by Vasileios Vasilakakis
 Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Deep Feedforward Networks. Sargur N. Srihari
 Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Training Neural Networks Practical Issues
 Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Improving training of deep neural networks via Singular Value Bounding
 Improving training of deep neural networks via Singular Value Bounding Kui Jia 1, Dacheng Tao 2, Shenghua Gao 3, and Xiangmin Xu 1 1 School of Electronic and Information Engineering, South China University
Improving training of deep neural networks via Singular Value Bounding Kui Jia 1, Dacheng Tao 2, Shenghua Gao 3, and Xiangmin Xu 1 1 School of Electronic and Information Engineering, South China University
RegML 2018 Class 8 Deep learning
 RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
An overview of deep learning methods for genomics
 An overview of deep learning methods for genomics Matthew Ploenzke STAT115/215/BIO/BIST282 Harvard University April 19, 218 1 Snapshot 1. Brief introduction to convolutional neural networks What is deep
An overview of deep learning methods for genomics Matthew Ploenzke STAT115/215/BIO/BIST282 Harvard University April 19, 218 1 Snapshot 1. Brief introduction to convolutional neural networks What is deep
Convex Optimization Algorithms for Machine Learning in 10 Slides
 Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost