EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN)
|
|
|
- Philippa Johnson
- 5 years ago
- Views:
Transcription


1 EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN)
2 TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent (SGD) Back-propagation Convolution Pooling (or Sub-sampling) Convolutional Neural Networks (CNN) Features maps Dropout Batch Normalization
3 NOTATION {x, y}: a training example (x the input, y the label) x: a scalar x: a vector X: a matrix W, θ: network weights J(θ): a loss function
4 MNIST DATASET Dataset of handwritten digits training data and test data. Digits are size-normalized and centered in fixed-size images. Easy dataset for beginners in machine learning.




5 SUPERVISED LEARNING 5 Label Input Function Loss Output ( Classes : 0, 1, 2, etc ) Error
6 OUR FIRST NEURAL NETWORK
7 LINEAR REGRESSION Linear regression y x Linear function: f x, w = w 2 + w 4 x Objective: find w 2, w 4 = w which minimize the error ; J w = 1 2 7(f x 8, w y 8 ) : 8<4 Animation of the optimizationproblem
8 CLASSIFICATION FUNCTION Linear classification y x Binary classification: f x, w { 1; +1} Using a non linearity function f x, w =? 1 if tanh w 2 + w 4 x 0 1 otherwise
9 ACTIVATION FUNCTION Threshold tanh sigmoid Rectified Linear Unit (ReLU) Threshold Tanh Sigmoïd Recitified Linear Unit (ReLU) Leaky ReLU PReLU Etc
10 PERCEPTRON x 1 1 w 1 w 0 If h(x) is an activation function, then a perceptron if define as follows: x 2 x 3 w 2 y F x, w = h(w 2 + w 4 x 4 + w : x : + w N x N ) w 3 = h 7 w 8 x 8 = h w O x P
11 FIRST LAYER OF NEURONES 1 y 1 x 1 y 2 x 2 y F (x, W) =h(x t W) =h( 4 5 x 1 x 2 t w 01 w 02 w 03 w 01 + x 1 w 11 + x 2 w 21 4w 11 w 12 w 13 5) =h( 4w 02 + x 1 w 12 + x 2 w 22 5 w 21 w 22 w 23 w 03 + x 1 w 13 + x 2 w 23 t 2 )=h( 4 y 1 y 2 y t )= 2 3 h(y 1 ) 4h(y 2 ) 5 h(y 3 ) t x W y
12 MLP: MULTI LAYER PERCEPTRON y 1 x 1 y 2 x 2 y 3 F 1 F 2 F 3 F N (F : (F 4 x, W 4, W : ), W N ) = F N F : F 4 x = (F N F : F 4 )(x)
13 BUILDING OUR MLP Torch7 works with modules. Module is an abstract class which defines fundamental methods necessary for a training a neural network. Modules are serializable. nn.sequential Input nn.linear nn.relu nn.linear Output
14 LOSS FUNCTION FOR CLASSIFICATION Converting the network outputs into probabilities: f y = j u = e u T u X V <4 Negative log likelihood: J p, t = log (p^) e u TV u = f(u) = Network output: Class probabilities: Combination of both: J u, t = u^ + log ( 7 e u T V ) u X V <4 Error: J f u, 3 = log =
15 LOSS FUNCTION IN TORCH7 Criterion is a special kind of Module who take to parameters has input Target Output nn.logsoft Max nn.classnllcriterion Error Or Target Output nn.crossentropycriterion Error
16 HOW TO TRAIN A NEURAL NETWORK?
17 GRADIENT DESCENT J(θ) J(θ) θ θ θ θ η Objective: minimizing an objective (loss) function J(θ) Gradient gives the slope of the function Updating the parameters θ in the opposite direction of the gradient according to a learning rate η Repeat until convergence
18 CHAIN RULE Composition function: F x = f g x = f(g x ) Derivative of a composition function: F j x = f j g x g j x = f j g x g (x) Using the Leibniz s notation: F j x = F(x) f(g x ) f(g x ) = = x x g(x) g(x) x
19 BACK-PROPAGATION w 4 f 4 w : w 4 f : w N f N w : w N x y 4 = f 4 (x, w 4 ) f 1 y 4 f 2 y : f 3 y N f : f N y 4 y : y : = f : y 4, w : = f : f 4 x, w 4, w : y N = f N y :, w N = f N f : y 4, w :, w N = f N (f : f 4 x, w 4, w :, w N ) mp y N = y N w N = f N y :, w N δw N Objective: mn,m o,m p y N = mn y N ; mo y N ; m p y N mp y N = f N y :, w N w N mo y N = f N y :, w N y : f : y 4, w : w : mn y N = f N y :, w N y : f : y 4, w : y 4 f 4 x, w 4 w 4 mo y N = y N w : = f N y :, w N w : = f N y :, w N y : y : w : = f N y :, w N y : f : y 4, w : w : mn y N = y N δw 4 = f N y :, w N w 4 = f N y :, w N y : y : w 4 = f N y :, w N y : f : y 4, w : w 4 = f N y :, w N y : f : y 4, w : y 4 y 4 w 4
20 ONE STEP IN TORCH7 data Model θ θ + ηgθ gθ 0gθ + θ output dfdo Loss function ferror target Reset gradients model : zerogradparameters () Forward local output = model : forward(data) local f error = loss function :forward(output, target) Backward local df do = loss function :backward(output, target) model : backward(data, df do) Update parameters model : updateparameters (0.01 )
21 BATCH GRADIENT DESCENT Computes the gradient of the cost function for the entire dataset: θ θ η v J(θ) Reset gradients model : zerogradparameters () for i=1, traindata:size() do Forward local output = model : forward( traindata.data [ i ]) local f error = loss function :forward(output, traindata.labels [ i ]) end Backward local df do = loss function :backward(output, traindata.labels [ i ]) model : backward( traindata.data [ i ], df do) Update parameters model : updateparameters (0.01 )
22 STOCHASTIC GRADIENT DESCENT Performs a parameter update for each training example x (8), y (8) : θ θ η v J(θ, x (8), y (8) ) Create a random permutation shuffle = torch.randperm(traindata: size ()) for i=1, traindata:size() do Reset gradients model : zerogradparameters () Forward local output = model : forward( traindata.data [ shuffle [ i ]]) local f error = loss function :forward(output, traindata.labels [ shuffle [ i ]]) Backward local df do = loss function :backward(output, traindata.labels [ shuffle [ i ]]) model : backward( traindata.data [ shuffle [ i ] ], df do) end Update parameters model : updateparameters (0.01 )
23 MINI-BATCH SGD Takes the best of both worlds and performs an update for every minibatch of n training examples: θ θ η v J(θ, x (8:8yz), y (8:8yz) ) for i=1, traindata:size(), batchsize do Reset gradients model : zerogradparameters () Create batch batch = getbatch(traindata, batchsize ) Forward local output = model : forward( batch.inputs ) local f error = loss function :forward(output, batch.targets) Backward local df do = loss function :backward(output, batch.targets) model : backward( batch.inputs, df do) end Update parameters model : updateparameters (0.01 )
24 SGD OPTIMIZATION ALGORITHMS Momentum: adds a fraction of the previously computed gradient (gives inertia to the gradient) v^ γv^}4 + η v J θ θ θ v^ NAG: extension of momentum Adagrad: adapts the learning rate to each parameters individually Adadelta: extension of Adagrad RMSprop: another extension of Adagrad Adam: takes into account the mean and variance of gradients Etc

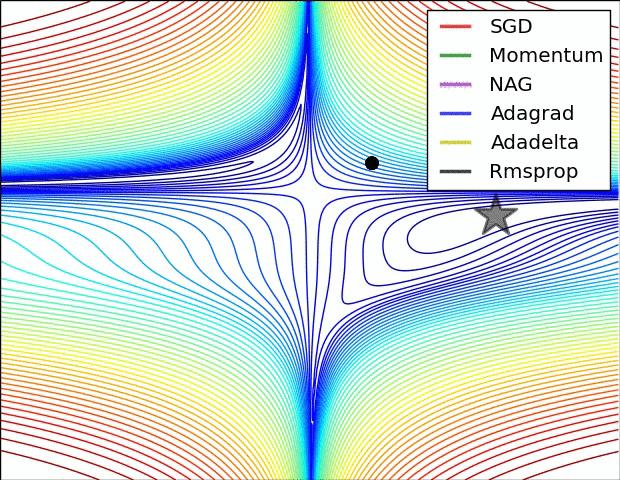
25 GRADIENT DESCENT ILLUSTRATION See:
26 PACKAGE OPTIM IN TORCH7 Torch package providing several optimization algorithms. Easy to use, easy to switch from one optimizer to another.
27 CONVOLUTIONAL NEURAL NETWORK
28 y f g x = f t g x t dt } CONVOLUTION
 g(m)")
29 DISCRETE CONVOLUTION f g n = 7 f(n m) g(m) ƒ<}

30 SLIDING MASK Convolution tool from Rémi Emonet: Convolution layer in Torch7:
31 CONVOLUTION EXAMPLE Original image Sharpen Emboss Blur Edge detect
32 CONVOLUTIONAL NEURAL NETWORK y y 2 y 3
33 CONVOLUTIONAL NEURAL NETWORK y 1 w 1 w 2 w 3 w 4 w 5 w 6 y 2 w 7 w 8 w 9 y 3

34 CONVOLUTIONAL NEURAL NETWORK w 1 w 2 w 3 w 4 w 5 w 6 w 7 w 8 w 9 y 1 w 1 w 2 w 3 w 4 w 5 w 6 y 2 w 7 w 8 w 9 w 1 w 2 w 3 y 3 w 4 w 5 w 6 w 7 w 8 w 9
35 POOLING Maximum Pooling Effect: Reduces the feature map s size Increases the field of view Average pooling Sum pooling Stochastic pooling Etc
36 FIELD OF VIEW Convolution with mask size = 3 Pooling with mask size = 2

37 LENET 5 Gradient-based learning applied to document recognition, Yann LeCun, Léon Bottou, Yoshua Bengio and Patrick Haffner [1998].
38 IF WE HAVE TIME
39 During training, for each forward pass, randomly set units to 0. DROPOUT Dropout Input Drop factor = Output At test time, keep the same «energy» into the network
40 BATCH NORMALIZATION During training, for each forward pass, normalized the data according to the mini-batch
41 CREATING OUR OWN LAYERS x w 4 f 4 w : f : w N f N w 4 w : w N f 1 y 4 f 2 y : f 3 y N f : f N y 4 y : Each module f x, w = y have to compute: y f x f w In Torch7 a new module have to overload 3 functions: [output] updateoutput(input) [gradinput] updategradinput(input, gradoutput) accgradparameters(input, gradoutput) Torch7 documentations:
42 LINKS
43 TORCH7 Torch7 Documentation: Torch7: Optim package: Criterions: Convolutional modules: Some tutorials code in torch7: Torch7 tutorials: Digit classifier:
44 TUTORIALS A Visual and Interactive Guide to the Basics of Neural Networks: An overview of gradient descent optimization algorithms: Artificial Inteligence: Andrew Ng lesson on coursera:
45 TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent (SGD) Back-propagation Convolution Pooling (or Sub-sampling) Convolutional Neural Networks (CNN) Features maps Dropout Batch Normalization
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning & Artificial Intelligence WS 2018/2019
 Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Overview of gradient descent optimization algorithms. HYUNG IL KOO Based on
 Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Architecture Multilayer Perceptron (MLP)
") Architecture Multilayer Perceptron (MLP) 1 Output Hidden Input Neurons partitioned into layers; y 1 y 2 one input layer, one output layer, possibly several hidden layers layers numbered from 0; the input
Architecture Multilayer Perceptron (MLP) 1 Output Hidden Input Neurons partitioned into layers; y 1 y 2 one input layer, one output layer, possibly several hidden layers layers numbered from 0; the input
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Machine Learning Lecture 14
 Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Optimization for Training I. First-Order Methods Training algorithm
 Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Lecture 35: Optimization and Neural Nets
 Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks. Lecture 2. Rob Fergus
 Neural Networks Lecture 2 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Neural Networks Lecture 2 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Convolutional Neural Networks. Srikumar Ramalingam
 Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
Introduction to (Convolutional) Neural Networks
 Neural Networks") Introduction to (Convolutional) Neural Networks Philipp Grohs Summer School DL and Vis, Sept 2018 Syllabus 1 Motivation and Definition 2 Universal Approximation 3 Backpropagation 4 Stochastic Gradient
Introduction to (Convolutional) Neural Networks Philipp Grohs Summer School DL and Vis, Sept 2018 Syllabus 1 Motivation and Definition 2 Universal Approximation 3 Backpropagation 4 Stochastic Gradient
Computational Photography
 Computational Photography Si Lu Spring 2018 http://web.cecs.pdx.edu/~lusi/cs510/cs510_computati onal_photography.htm 05/29/2018 Last Time o 3D Video Stabilization 2 Introduction of Neural Networks 3 Content
Computational Photography Si Lu Spring 2018 http://web.cecs.pdx.edu/~lusi/cs510/cs510_computati onal_photography.htm 05/29/2018 Last Time o 3D Video Stabilization 2 Introduction of Neural Networks 3 Content
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Feed-forward Networks Network Training Error Backpropagation Applications. Neural Networks. Oliver Schulte - CMPT 726. Bishop PRML Ch.
 Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will
Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Machine Learning CS 4900/5900. Lecture 03. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks. Lecture 6. Rob Fergus
 Neural Networks Lecture 6 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Neural Networks Lecture 6 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Neural networks (NN) 1
 1") Neural networks (NN) 1 Hedibert F. Lopes Insper Institute of Education and Research São Paulo, Brazil 1 Slides based on Chapter 11 of Hastie, Tibshirani and Friedman s book The Elements of Statistical
Neural networks (NN) 1 Hedibert F. Lopes Insper Institute of Education and Research São Paulo, Brazil 1 Slides based on Chapter 11 of Hastie, Tibshirani and Friedman s book The Elements of Statistical
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Understanding Neural Networks : Part I
 TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
OPTIMIZATION METHODS IN DEEP LEARNING
 Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
Introduction to Machine Learning (67577)
") Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Machine Learning. Boris
 Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
Machine Learning
 Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Stochastic Gradient Estimate Variance in Contrastive Divergence and Persistent Contrastive Divergence
 ESANN 0 proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning. Bruges (Belgium), 7-9 April 0, idoc.com publ., ISBN 97-7707-. Stochastic Gradient
ESANN 0 proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning. Bruges (Belgium), 7-9 April 0, idoc.com publ., ISBN 97-7707-. Stochastic Gradient
Stochastic gradient descent; Classification
 Stochastic gradient descent; Classification Steve Renals Machine Learning Practical MLP Lecture 2 28 September 2016 MLP Lecture 2 Stochastic gradient descent; Classification 1 Single Layer Networks MLP
Stochastic gradient descent; Classification Steve Renals Machine Learning Practical MLP Lecture 2 28 September 2016 MLP Lecture 2 Stochastic gradient descent; Classification 1 Single Layer Networks MLP
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Theories of Deep Learning
 Theories of Deep Learning Lecture 02 Donoho, Monajemi, Papyan Department of Statistics Stanford Oct. 4, 2017 1 / 50 Stats 385 Fall 2017 2 / 50 Stats 285 Fall 2017 3 / 50 Course info Wed 3:00-4:20 PM in
Theories of Deep Learning Lecture 02 Donoho, Monajemi, Papyan Department of Statistics Stanford Oct. 4, 2017 1 / 50 Stats 385 Fall 2017 2 / 50 Stats 285 Fall 2017 3 / 50 Course info Wed 3:00-4:20 PM in
Demystifying deep learning. Artificial Intelligence Group Department of Computer Science and Technology, University of Cambridge, UK
 Demystifying deep learning Petar Veličković Artificial Intelligence Group Department of Computer Science and Technology, University of Cambridge, UK London Data Science Summit 20 October 2017 Introduction
Demystifying deep learning Petar Veličković Artificial Intelligence Group Department of Computer Science and Technology, University of Cambridge, UK London Data Science Summit 20 October 2017 Introduction
Advanced computational methods X Selected Topics: SGD
 Advanced computational methods X071521-Selected Topics: SGD. In this lecture, we look at the stochastic gradient descent (SGD) method 1 An illustrating example The MNIST is a simple dataset of variety
Advanced computational methods X071521-Selected Topics: SGD. In this lecture, we look at the stochastic gradient descent (SGD) method 1 An illustrating example The MNIST is a simple dataset of variety
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Introduction to Deep Learning CMPT 733. Steven Bergner
 Introduction to Deep Learning CMPT 733 Steven Bergner Overview Renaissance of artificial neural networks Representation learning vs feature engineering Background Linear Algebra, Optimization Regularization
Introduction to Deep Learning CMPT 733 Steven Bergner Overview Renaissance of artificial neural networks Representation learning vs feature engineering Background Linear Algebra, Optimization Regularization
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Normalization Techniques in Training of Deep Neural Networks
 Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
Lecture 2: Learning with neural networks
 Lecture 2: Learning with neural networks Deep Learning @ UvA LEARNING WITH NEURAL NETWORKS - PAGE 1 Lecture Overview o Machine Learning Paradigm for Neural Networks o The Backpropagation algorithm for
Lecture 2: Learning with neural networks Deep Learning @ UvA LEARNING WITH NEURAL NETWORKS - PAGE 1 Lecture Overview o Machine Learning Paradigm for Neural Networks o The Backpropagation algorithm for
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
Advanced Machine Learning
 Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Rapid Introduction to Machine Learning/ Deep Learning
 Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/59 Lecture 4a Feedforward neural network October 30, 2015 2/59 Table of contents 1 1. Objectives of Lecture
Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/59 Lecture 4a Feedforward neural network October 30, 2015 2/59 Table of contents 1 1. Objectives of Lecture
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Non-Linearity. CS 188: Artificial Intelligence. Non-Linear Separators. Non-Linear Separators. Deep Learning I
 Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Deep Learning (CNNs)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
CS260: Machine Learning Algorithms
 CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Importance Reweighting Using Adversarial-Collaborative Training
 Importance Reweighting Using Adversarial-Collaborative Training Yifan Wu yw4@andrew.cmu.edu Tianshu Ren tren@andrew.cmu.edu Lidan Mu lmu@andrew.cmu.edu Abstract We consider the problem of reweighting a
Importance Reweighting Using Adversarial-Collaborative Training Yifan Wu yw4@andrew.cmu.edu Tianshu Ren tren@andrew.cmu.edu Lidan Mu lmu@andrew.cmu.edu Abstract We consider the problem of reweighting a
Logistic Regression. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent
 CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
Machine Learning Basics: Stochastic Gradient Descent. Sargur N. Srihari
 Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Topic 3: Neural Networks
 CS 4850/6850: Introduction to Machine Learning Fall 2018 Topic 3: Neural Networks Instructor: Daniel L. Pimentel-Alarcón c Copyright 2018 3.1 Introduction Neural networks are arguably the main reason why
CS 4850/6850: Introduction to Machine Learning Fall 2018 Topic 3: Neural Networks Instructor: Daniel L. Pimentel-Alarcón c Copyright 2018 3.1 Introduction Neural networks are arguably the main reason why
Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization
 Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization Changyou Chen, David Carlson, Zhe Gan, Chunyuan Li, Lawrence Carin May 2, 2016 1 Changyou Chen Bridging the Gap between Stochastic
Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization Changyou Chen, David Carlson, Zhe Gan, Chunyuan Li, Lawrence Carin May 2, 2016 1 Changyou Chen Bridging the Gap between Stochastic
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Neural Network Tutorial & Application in Nuclear Physics. Weiguang Jiang ( 蒋炜光 ) UTK / ORNL
 UTK / ORNL") Neural Network Tutorial & Application in Nuclear Physics Weiguang Jiang ( 蒋炜光 ) UTK / ORNL Machine Learning Logistic Regression Gaussian Processes Neural Network Support vector machine Random Forest Genetic
Neural Network Tutorial & Application in Nuclear Physics Weiguang Jiang ( 蒋炜光 ) UTK / ORNL Machine Learning Logistic Regression Gaussian Processes Neural Network Support vector machine Random Forest Genetic
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden