Demystifying deep learning. Artificial Intelligence Group Department of Computer Science and Technology, University of Cambridge, UK
|
|
|
- Valentine Gregory
- 5 years ago
- Views:
Transcription
1 Demystifying deep learning Petar Veličković Artificial Intelligence Group Department of Computer Science and Technology, University of Cambridge, UK London Data Science Summit 20 October 2017
2 Introduction In this talk, I will guide you through a condensed story of how deep learning became what it was today, and where it s going. This will involve a journey through the essentials of how neural networks normally work, and an overview of some of their many variations and applications. Not a deep learning tutorial! (wait for Sunday. :)) Disclaimer: Any views expressed (especially with respect to influential papers) are entirely my own, and influenced perhaps by the kinds of problems I m solving. It s fairly certain that any deep learning researcher would give a different account of what s the most important work in the field. :)
 Imagine someone asked you to write a program that recognises characters from")
3 Motivation: notmnist Which characters do you see? (How did you conclude this?) Imagine someone asked you to write a program that recognises characters from arbitrary glyphs...
4 Intelligent systems Although the previous task was likely simple to you, you (probably) couldn t turn your thought process into a concise sequence of instructions for a program! Unlike a dumb program (that just blindly executes preprogrammed instructions), you ve been exposed to a lot of A characters during your lifetimes, and eventually learnt the complex features making something an A! Desire to design such systems (capable of generalising from past experiences) is the essence of machine learning! How many such systems do we know from nature?

5 Specialisation in the brain We know that different parts of the brain perform different tasks: There is increasing evidence that the brain: Learns from exposure to data; Is not preprogrammed!
6 Brain & data The majority of what we know about the brain comes from studying brain damage: Rerouting visual inputs into the auditory region of baby ferrets makes this region capable of dealing with visual input! As far as we know (for now), the modified region works equally good as the visual cortex of healthy ferrets! If there are no major biological differences in learning to process different kinds of input... = the brain likely uses a general learning algorithm, capable of adapting to a wide spectrum of inputs. We d very much like to capture this algorithm!
7 A real neuron!
8 An artificial neuron! Within this context sometimes also called a perceptron (... ) +1 x 1 x 2 x 3. x n w 1 w 2 w 3 b w n Σ ( b + n i=1 w i x i ) > 0? This model of a binary classifier was created by Rosenblatt in 1957.
9 Gradient descent There needed to be a way to learn the neuron s parameters ( w, b) from data. One very popular technique to do this was gradient descent if we have a way of quantifying the errors (a differentiable loss function, L) that our neuron makes on training data, we can then iteratively update our weights as w t+1 w t η L w where the gradients L w wt are computed on the training data. Here, η is the learning rate, and properly choosing it is critical remember it, it will be important later on!

10 Gradient descent
11 Custom activations Fundamental issue: the function we apply to our network s output (essentially the step function) is non-differentiable! Solution: use its smooth variant, the logistic sigmoid σ(x) = exp( ax) and classify depending on whether σ(x) > 0.5. We can generalise this to k-class classification using the softmax function: P(Class i) = softmax( x) i = exp(x i) j exp(x j)
12 The logistic function
13 The loss function If we now define a suitable loss function to minimise, we may train the neuron using gradient descent! If we don t know anything about the problem, we may often use the squared error loss if our perceptron computes the function h( x; w) = σ ( b + n i=1 w ix i ), then on training example ( xp, y p ): L p ( w) = (y p h( x p ; w)) 2 Since the logistic function outputs a probability, we may exploit this to create a more informed loss the cross-entropy loss: L p ( w) = y p log h( x p ; w) (1 y p ) log(1 h( x p ; w)) You may recognise the setup so far as logistic regression.
14 The infamous XOR problem
15 Neural networks and deep learning To get any further, we need to be able to introduce nonlinearity into the function our system computes. It is easy to extend a single neuron to a neural network simply connect outputs of neurons to inputs of other neurons. If we apply nonlinear activation functions to intermediate outputs, this will introduce the desirable properties. Typically we organise neural networks in a sequence of layers, such that a single layer only processes output from the previous layer.
16 Multilayer perceptrons The most potent feedforward architecture allows for full connectivity between layers sometimes also called a multilayer perceptron. Input layer Hidden layer Output layer +1 x 1 x 2 x 3. x n w 1 w 2 w 3 b w n Σ σ ( σ b + n ) w i x i i=1 I 1 I 2 I 3 O 1 O 2
17 Backpropagation Variants of multilayer perceptrons (MLPs) have been known since the 1960s. In a way, everything that modern deep learning is utilising are specialised MLPs! Stacking neurons in this manner will preserve differentiability, so we can re-use gradient descent to train them once again. However, computing L w for an arbitrary weight w in such a network was not initially very efficient until 1985, when the backpropagation algorithm was introduced by Rumelhart, Hinton and Williams.
18 Backpropagation Compute gradients directly at output neurons, and then propagate them backwards using the chain rule! Input 1 Input layer Hidden layer Error backpropagation Output layer Input 2 Input 3 error Input 4 Input 5
19 Hyperparameters Gradient descent optimises solely the weights and biases in the network. How about: the number of hidden layers? the amount of neurons in each hidden layer? the activation functions of these neurons? the number of iterations of gradient descent? the learning rate?... These parameters must be fixed before training commences! For this reason, we often call them hyperparameters. Optimising them remains an extremely difficult problem we often can t do better than separating some of our training data for evaluating various combinations of hyperparameter values.
20 Neural network depth I d like to highlight a specific hyperparameter: the number of hidden layers, i.e. the network s depth. What do you think, how many hidden layers are sufficient to learn any (bounded continuous) real function?
21 Neural network depth I d like to highlight a specific hyperparameter: the number of hidden layers, i.e. the network s depth. What do you think, how many hidden layers are sufficient to learn any (bounded continuous) real function? One! (Cybenko s theorem, 1989.)
22 Neural network depth I d like to highlight a specific hyperparameter: the number of hidden layers, i.e. the network s depth. What do you think, how many hidden layers are sufficient to learn any (bounded continuous) real function? One! (Cybenko s theorem, 1989.) However, the proof is not constructive, i.e. does not give the optimal width of this layer or a training algorithm. We must go deeper... Every network with > 1 hidden layer is considered deep! Today s state-of-the-art networks often have over 150 layers.
23 Deep neural networks O 1 O 2 I 1 I 2 I 3


24 Quiz: What do we have here?
25 DeepBlue vs. AlphaGo Main idea (roughly) the same: assume that a grandmaster is only capable of thinking k steps ahead then generate a (near-)optimal move when considering k > k steps ahead. DeepBlue does this exhaustively, AlphaGo sparsely (discarding many highly unlikely moves). One of the key issues: when stopping exploration, how do we determine the advantage that player 1 has? DeepBlue: Gather a team of chess experts, and define a function f : Board R, to define this advantage. AlphaGo: Feed the raw state of the board to a deep neural network, and have it learn the advantage function by itself. This highlights an important paradigm shift brought about by deep learning...
26 Feature engineering Historically, machine learning problems were tackled by defining a set of features to be manually extracted from raw data, and given as inputs for shallow models. Many scientists built entire PhDs focusing on features of interest for just one such problem! Generalisability: very small (often zero)! With deep learning, the network learns the best features by itself, directly from raw data! For the first time connected researchers from fully distinct areas, e.g. natural language processing and computer vision. = a person capable of working with deep neural networks may readily apply their knowledge to create state-of-the-art models in virtually any domain (assuming a large dataset)!
27 Representation learning As inputs propagate through the layers, the network captures more complex representations of them. It will be extremely valuable for us to be able to reason about these representations! Typically, models that deal with images will tend to have the best visualisations. Therefore, I will now provide a brief introduction to these models (convolutional neural networks). Then we can look into the kinds of representations they capture...
28 Working with images Simple fully-connected neural networks (as described already) typically fail on high-dimensional datasets (e.g. images). Treating each pixel as an independent input results in h w d new parameters per neuron in the first hidden layer quickly deteriorating as images become larger requiring exponentially more data to properly fit those parameters! Key idea: downsample the image until it is small enough to be tackled by such a network! Would ideally want to extract some useful features first... = exploit spatial structure!

29 The convolution operator
30 Enter the convolution operator Define a small (e.g. 3 3) matrix (the kernel, K). Overlay it in all possible ways over the input image, I. Record sums of elementwise products in a new image. (I K) xy = h i=1 j=1 w K ij I x+i 1,y+j 1 This operator exploits structure neighbouring pixels influence one another stronger than ones on opposite corners! Start with random kernels and let the network find the optimal ones on its own!
31 Convolution example = I K I K
32 Convolution example = I K I K
33 Convolution example = I K I K
34 Convolution example = I K I K
35 Downsampling ( max-pooling) Convolutions light up when they detect a particular feature in a region of the image. Therefore, when downsampling, it is a good idea to preserve maximally activated parts. This is the inspiration behind the max-pooling operation Max-Pool
36 Stacking convolutions and poolings Rough rule of thumb: increase the depth (number of convolutions) as the height and width decrease. FC Softmax Conv. Pool Conv. Pool FC

37 CNN representations Convolutional neural networks are by no means a new idea... they ve been known since the late 1970s! Popularised by LeCun et al. in 1989 to classify handwritten digits (the MNIST dataset, now a standard benchmark).
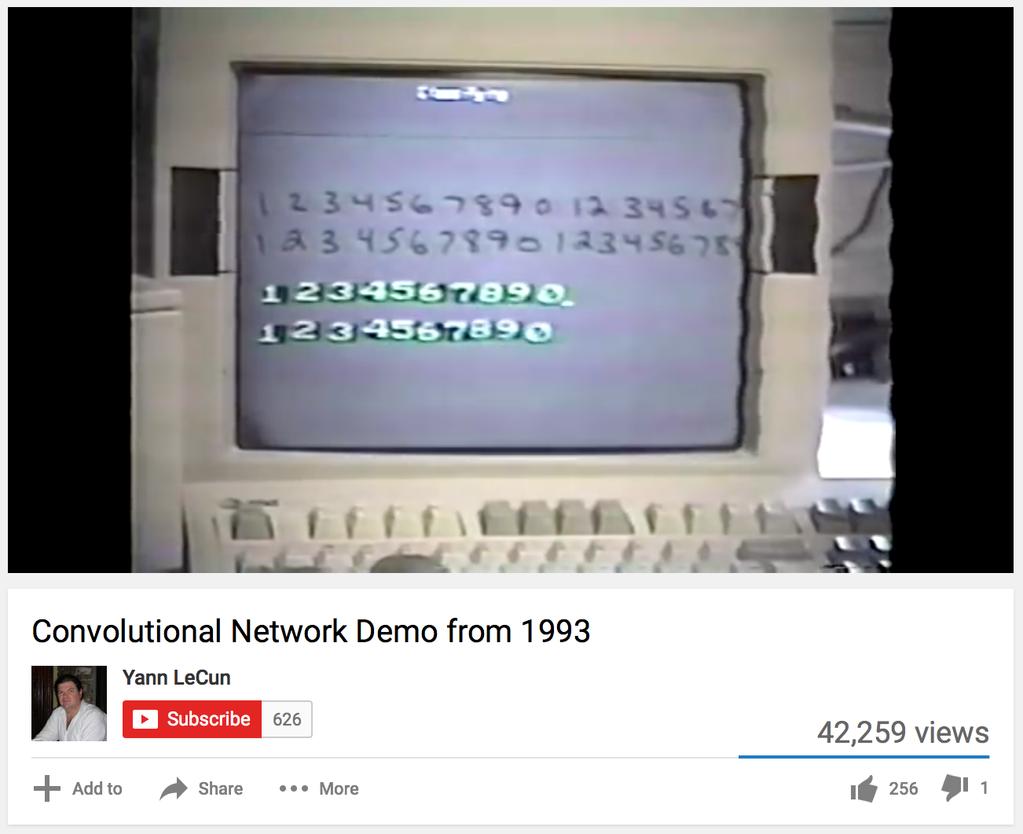
38 LeNet-1

39 Observing kernels Typically, as the kernels are small, gaining useful information from them becomes difficult already past the first layer. However, the first layer of kernels reveals something magical... In almost all cases, these kernels will learn to become edge detectors!

40 Passing data through the network: Input O 1 O 2 I 1 I 2 I 3

41 Passing data through the network: Shallow layer O 1 O 2 I 1 I 2 I 3

42 Passing data through the network: Deep layer O 1 O 2 I 1 I 2 I 3
43 Passing data through the network: Output O 1 O 2 I 1 I 2 I 3
44 Sequential inputs Now, consider a classification problem where the input is sequential a sequence consisting of arbitrarily many steps, wherein at each step we have n features. This kind of input corresponds nicely to problems involving sound or natural language. x 1 x 2 x 3 x 4 x 5... x t... The fully connected layers will no longer even work, as they expect a fixed-size input!
45 Making it work Key ideas: Summarize the entire input into m features (describing the most important patterns for classifying it); Exploit relations between adjacent steps process the input in a step-by-step manner, iteratively building up the features, h: ht = f ( x t, h t 1 ) If we declare a pattern to be interesting, then it does not matter when it occurs in the sequence = employ weight sharing!
46 An RNN cell y t y t 1 RNN x t
47 Unrolling the cell... Compute y T iteratively, then feed it into the usual multilayer perceptron to get the final answer. y T y 1 y 2 y 3 y y 0 RNN RNN RNN... T 1 RNN x 1 x 2 x... 3 x T N.B. Every RNN block has the same parameters!
48 RNN variants Initial versions (SimpleRNN) introduced by Jordan (1986), Elman (1990). Simply apply a fully-connected layer on both x t and y t 1, and apply an activation. Suffers from vanishing gradients over long paths (as σ (x) < 1)... cannot capture long-term dependencies! The problem is solved by the long short-term memory (LSTM) model (Hochreiter and Schmidhuber, 1997). The LSTM cell explicitly learns (from data!) the proportion by which it forgets the result of its previous computations. Several models proposed since then, but none improve significantly on the LSTM on average.
49 An LSTM block LSTM M c t 1 x t forget gate input gate c t y t 1 new fts. + σ y t output gate
50 Where are we? By now, we ve covered all the essential architectures that are used across the board for modern deep learning and we re not even in the 21st century yet! It turns out that we had the required methodology all along, but several key factors were missing... demanding gamers ( GPU development!) big companies ( lots of resources, and DL frameworks!) big data ( for big parameter spaces!) So, what s exactly new, methodologically?
51 Improving gradient descent In the past, gradient descent was performed in a batch fashion, by accumulating gradients over the entire training set: w w η m L p ( w) p=1 For big datasets, this may not only be remarkably expensive for just one step, but may not even fit within memory constraints!
52 Stochastic gradient descent (SGD) This problem may be solved by using stochastic gradient descent at one iteration consider only one (randomly chosen) training example (x p, y p ): w w η L p ( w) In practice, we use the golden middle consider a randomly chosen minibatch of examples, B = {(x 1, y 1 ),..., (x bs, y bs )}. bs w w η L p ( w) p=1 We also have efficent methods to automatically estimate the optimal choice of η (such as Adam and RMSProp).
53 Vanishing gradients strike back As networks get deeper, the same kind of vanishing gradient problem that we used LSTMs to solve appears with non-recurrent networks. We cannot really re-use ideas from LSTMs here cleanly... Solution: change the activation function! The rectified linear unit (ReLU) is the simplest nonlinearity not to suffer from this problem: ReLU(x) = max(0, x) as its gradient is exactly 1 when active and 0 when dead. First deployed by Nair and Hinton in 2010, now ubiquitous across deep learning architectures.
54 Better regularisation 4.5 Learning the sine function y Training set Target Linear fit Degree-3 Degree x
55 Dropout dropout Randomly kill each neuron in a layer with probability p during training only...?!
56 Batch normalisation Internal covariance shift...?!
57 Batch normalisation Solution: renormalise outputs of the current layer across the current batch, B = {x 1,..., x m } (but allow the network to revert if necessary)! µ B = 1 m m i=1 x i σ 2 B = 1 m m (x i µ B ) 2 i=1 ˆx i = x i µ B σ 2B + ε y i = γˆx i + β where γ and β are trainable! Now ubiquitously used across deeper networks Published in February 2015, 1500 citations by now!

58 Traffic sign classification

59 ImageNet classification
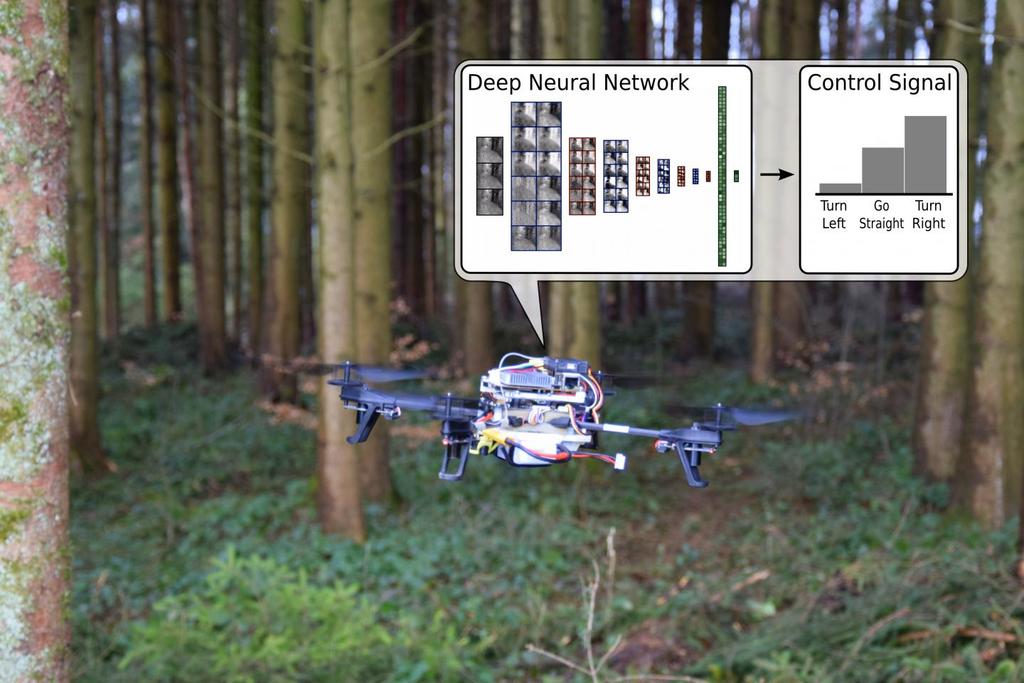
60 Simple navigation

61 Self-driving cars

62 Greatest hits


63 Neural style transfer

64 Video captioning

65 Playing Atari...
66 ... and Cooling
67 Challenge: Multimodal data fusion
68 Challenge: Unsupervised learning
69 Challenge: General AI Output (Task 1) Output (Task 2) Input
70 Thank you! Questions?
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Convolutional Neural Networks. Srikumar Ramalingam
 Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
Introduction to Convolutional Neural Networks 2018 / 02 / 23
 Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Deep Learning: a gentle introduction
 Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Lecture 15: Exploding and Vanishing Gradients
 Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
Convolutional Neural Network Architecture
 Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Topic 3: Neural Networks
 CS 4850/6850: Introduction to Machine Learning Fall 2018 Topic 3: Neural Networks Instructor: Daniel L. Pimentel-Alarcón c Copyright 2018 3.1 Introduction Neural networks are arguably the main reason why
CS 4850/6850: Introduction to Machine Learning Fall 2018 Topic 3: Neural Networks Instructor: Daniel L. Pimentel-Alarcón c Copyright 2018 3.1 Introduction Neural networks are arguably the main reason why
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Neural Turing Machine. Author: Alex Graves, Greg Wayne, Ivo Danihelka Presented By: Tinghui Wang (Steve)
") Neural Turing Machine Author: Alex Graves, Greg Wayne, Ivo Danihelka Presented By: Tinghui Wang (Steve) Introduction Neural Turning Machine: Couple a Neural Network with external memory resources The combined
Neural Turing Machine Author: Alex Graves, Greg Wayne, Ivo Danihelka Presented By: Tinghui Wang (Steve) Introduction Neural Turning Machine: Couple a Neural Network with external memory resources The combined
Introduction to (Convolutional) Neural Networks
 Neural Networks") Introduction to (Convolutional) Neural Networks Philipp Grohs Summer School DL and Vis, Sept 2018 Syllabus 1 Motivation and Definition 2 Universal Approximation 3 Backpropagation 4 Stochastic Gradient
Introduction to (Convolutional) Neural Networks Philipp Grohs Summer School DL and Vis, Sept 2018 Syllabus 1 Motivation and Definition 2 Universal Approximation 3 Backpropagation 4 Stochastic Gradient
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Artificial Neural Networks. Historical description
 Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets)
") COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
 2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
arxiv: v3 [cs.lg] 14 Jan 2018
![arxiv: v3 [cs.lg] 14 Jan 2018](/thumbs/92/109503708.jpg "arxiv: v3 [cs.lg] 14 Jan 2018") A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Deep Feedforward Networks. Sargur N. Srihari
 Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Backpropagation Introduction to Machine Learning. Matt Gormley Lecture 12 Feb 23, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Neural Networks. Intro to AI Bert Huang Virginia Tech
 Neural Networks Intro to AI Bert Huang Virginia Tech Outline Biological inspiration for artificial neural networks Linear vs. nonlinear functions Learning with neural networks: back propagation https://en.wikipedia.org/wiki/neuron#/media/file:chemical_synapse_schema_cropped.jpg
Neural Networks Intro to AI Bert Huang Virginia Tech Outline Biological inspiration for artificial neural networks Linear vs. nonlinear functions Learning with neural networks: back propagation https://en.wikipedia.org/wiki/neuron#/media/file:chemical_synapse_schema_cropped.jpg
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN)
") EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
TTIC 31230, Fundamentals of Deep Learning David McAllester, April Vanishing and Exploding Gradients. ReLUs. Xavier Initialization
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 14. Deep Learning An Overview Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Guest lecturer: Frank Hutter Albert-Ludwigs-Universität Freiburg July 14, 2017
Foundations of Artificial Intelligence 14. Deep Learning An Overview Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Guest lecturer: Frank Hutter Albert-Ludwigs-Universität Freiburg July 14, 2017
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Deep Feedforward Networks
 Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Feature Design. Feature Design. Feature Design. & Deep Learning
 Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
AN INTRODUCTION TO NEURAL NETWORKS. Scott Kuindersma November 12, 2009
 AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation
 Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Neural Networks
 Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
Advanced Machine Learning
 Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function
 Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Deep Feedforward Networks. Han Shao, Hou Pong Chan, and Hongyi Zhang
 Deep Feedforward Networks Han Shao, Hou Pong Chan, and Hongyi Zhang Deep Feedforward Networks Goal: approximate some function f e.g., a classifier, maps input to a class y = f (x) x y Defines a mapping
Deep Feedforward Networks Han Shao, Hou Pong Chan, and Hongyi Zhang Deep Feedforward Networks Goal: approximate some function f e.g., a classifier, maps input to a class y = f (x) x y Defines a mapping
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Computational Intelligence Winter Term 2017/18
 Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Neural Networks and Introduction to Deep Learning
 1 Neural Networks and Introduction to Deep Learning Neural Networks and Introduction to Deep Learning 1 Introduction Deep learning is a set of learning methods attempting to model data with complex architectures
1 Neural Networks and Introduction to Deep Learning Neural Networks and Introduction to Deep Learning 1 Introduction Deep learning is a set of learning methods attempting to model data with complex architectures
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4