Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
|
|
|
- Lionel Bridges
- 5 years ago
- Views:
Transcription
1 Machine Learning Neural Networks (slides from Domingos, Pardo, others)
2 For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward AI Learning Deep Architectures for AI

3 Human Brain
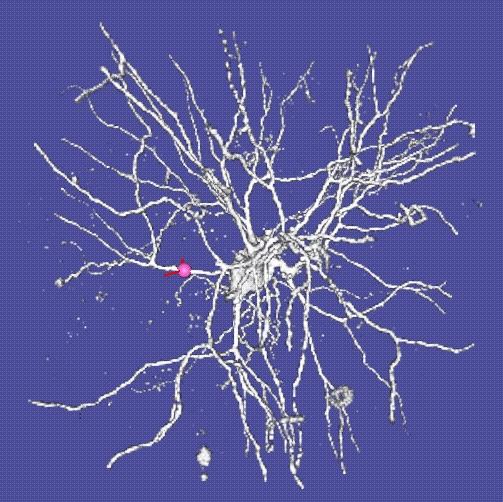
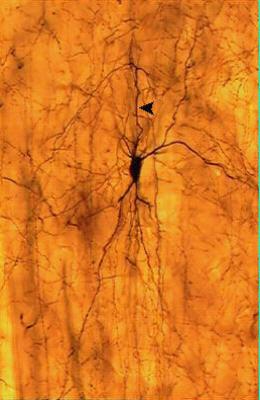
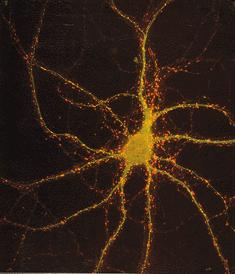
4 Neurons
5 Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
6 Human Learning Number of neurons: ~ Connections per neuron: ~ 10 3 to 10 5 Neuron switching time: ~ second Scene recognition time: ~ 0.1 second 100 inference steps doesn t seem much

7 Machine Learning Abstraction
8 Artificial Neural Networks Typically, machine learning ANNs are very artificial, ignoring: Time Space Biological learning processes More realistic neural models exist Hodgkin & Huxley (1952) won a Nobel prize for theirs (in 1963) Nonetheless, very artificial ANNs have been useful in many ML applications
9 Perceptrons The first wave in neural networks Big in the 1960 s McCulloch & Pitts (1943), Woodrow & Hoff (1960), Rosenblatt (1962)
10 Problem def: Perceptrons Let f be a target function from X = <x 1, x 2, > where x i {0, 1} to y {0, 1} Given training data {(X 1, y 1 ), (X 2, y 2 ) } Learn h (X ), an approximation of f (X )
11 A single perceptron x 1 x 0 Bias (x 0 =1,always) w 1 w 0 x 2 Inputs x 3 w 2 w 3 n 1 if σ = i= 0 0 else w i x i > 0 x 4 w 4 x 5 w 5
12 Logical Operators x 1 x x n 1 if = w i x σ i i= 0 0 else x > 0 AND x x n 1 if = w i x σ i i= 0 0 else > 0 NOT x 1 x n 1 if = w i x σ i i= 0 0 else > 0 OR
13 Learning Weights Perceptron Training Rule Gradient Descent (other approaches: Genetic Algorithms) x 1? x 0? x 2? n 1 if = w i x σ i i= 0 0 else > 0
14 Perceptron Training Rule Weights modified for each training example Update Rule: w i w i + w i where w = η( t o) x i i learning rate target value perceptron output input value
15 Perception Training for NOT Initialize: w w = 0, 1 0 x 1 x 0 w 1 w 0 n 1 if = w i x σ i i= 0 0 else > 0 NOT w i w i + w w = η( t o) x i i Work i Start End Bryan Pardo, Machine Learning: EECS 349 Fall
16 What weights make XOR? x 1 x 0? x 2?? n 1 if = w i x σ i i= 0 0 else > 0 No combination of weights works Perceptrons can only represent linearly separable functions
17 Linear Separability x OR + x 1
18 Linear Separability x 2 + AND x 1
19 Linear Separability x 2 + XOR + x 1
20 Perceptron Training Rule Converges to the correct classification IF Cases are linearly separable Learning rate is slow enough Proved by Minsky and Papert in 1969 Killed widespread interest in perceptrons till the 80 s
21 XOR x 0 0 x 1 x n 1 if = w i x σ i i= 0 0 else x 0 0 n 1 if = w i x σ i i= 0 0 else > 0 > x 0 0 n 1 if = w i x σ i i= 0 0 else > 0 XOR
22 What s wrong with perceptrons? You can always plug multiple perceptrons together to calculate any function. BUT who decides what the weights are? Assignment of error to parental inputs becomes a problem.
23 Perceptrons use a step function x 1 x 2?? x 0? n 1 if = w i x σ i i= 0 0 else > 0 Perceptron Threshold Step function Small changes in inputs -> either no change or large change in output.
24 Solution: Differentiable Function x 0? Simple linear function x 1 x 2?? σ = n i= 0 w i x i Varying any input a little creates a perceptible change in the output We can now characterize how error changes w i even in multi-layer case
25 Measuring error for linear units Output Function σ ( x) = w x Error Measure: E( w ) 1 2 d D ( t o d d 2 ) data target value linear unit output

26 Gradient Descent Gradient: Training rule:
27 Gradient Descent Rule D d d d i i o t w w E 2 ) ( 2 1 = D d d i d d x o t ) )( (, + D d d i d d i i x o t w w, ) ( η Update Rule:
28 Gradient Descent for Multiple Layers x 0 x 1 w ij σ = x 0 n i= 0 w i x i x 0 σ = n i= 0 w i x i XOR? x 2 σ = n i= 0 w i x i We can compute: E w ij =
29 Gradient Descent vs. Perceptrons Perceptron Rule & Threshold Units Learner converges on an answer ONLY IF data is linearly separable Can t assign proper error to parent nodes Gradient Descent (locally) Minimizes error even if examples are not linearly separable Works for multi-layer networks But linear units only make linear decision surfaces (can t learn XOR even with many layers) And the step function isn t differentiable
30 Perceptron A compromise function output n 1 if w > = i x i 0 i= 0 0 else Linear output = net = n w i x i i= 0 Sigmoid (Logistic) output = σ ( net) = 1+ 1 e net
31 The sigmoid (logistic) unit Has differentiable function Allows gradient descent Can be used to learn non-linear functions x 1? σ = n 1+ 1 w i x i e i= 0 x 2?
32 Logistic function Inputs Output Age 34 Gender 1 Stage Σ 0.6 Probability of beingalive Independent variables Coefficients σ = n 1+ 1 w i x i i= e 0 Prediction
33 Neural Network Model Inputs Age 34 Gender 2 Stage Σ Σ Σ Output 0.6 Probability of beingalive Independent variables Weights Hidden Layer Weights Dependent variable Prediction
34 Getting an answer from a NN Inputs Age 34.6 Output Gender 2 Stage Σ 0.6 Probability of beingalive Independent variables Weights Hidden Layer Weights Dependent variable Prediction
35 Getting an answer from a NN Inputs Age 34 Gender 2 Stage Σ Output 0.6 Probability of beingalive Independent variables Weights Hidden Layer Weights Dependent variable Prediction
36 Getting an answer from a NN Inputs Age 34 Gender 1 Stage Σ Output 0.6 Probability of beingalive Independent variables Weights Hidden Layer Weights Dependent variable Prediction
37 Minimizing the Error Error surface initial error negative derivative final error local minimum w initial w trained positive change
38 Differentiability is key! Sigmoid is easy to differentiate σ ( y) = σ ( y) (1 σ ( y)) y For gradient descent on multiple layers, a little dynamic programming can help: Compute errors at each output node Use these to compute errors at each hidden node Use these to compute weight gradient
39 The Backpropagation Algorithm For each input training example, x,t 1. Input instance x to the network and compute the output for every unit u in the network 2. For each output unit k, δ δ k h w ji o o k h w (1 o (1 o ji k h +ηδ )( t kii k hk k outputs x ji o k w 4.Update each network weight ) ) calculateits error term δ 3. For each hidden unit h, calculateits error term δ δ k w ji k h o u
40 Learning Weights Inputs Age 34 Gender 1 Stage Σ Output 0.6 Probability of beingalive Independent variables Weights Hidden Layer Weights Dependent variable Prediction
41 The fine print Don t implement back-propagation Use a package Second-order or variable step-size optimization techniques exist Feature normalization Typical to normalize inputs to lie in [0,1] (and outputs must be normalized) Problems with NN training: Slow training times (though, getting better) Local minima

42 Minimizing the Error Error surface initial error negative derivative final error local minimum w initial w trained positive change
43 Expressive Power of ANNs Universal Function Approximator: Given enough hidden units, can approximate any continuous function f Need 2+ hidden units to learn XOR Why not use millions of hidden units? Efficiency (training is slow) Overfitting
44 Overfitting Real Distribution Overfitted Model
45 Combating Overfitting in Neural Nets Many techniques Two popular ones: Early Stopping (most popular) Use a lot of hidden units Just don t over-train Cross-validation Test different architectures to choose right number of hidden units
46 Early Stopping error Overfitted model error a min ( error) a = validation set b = training set error b Stopping criterion Epochs
47 Learning Rate? A knob you twist empirically Important One popular option: look for validation set acc to decrease/stabilize, then halve learning rate
48 Modern Neural Networks (Deep Nets) Local minima in large networks is less of an issue Early stopping is useful, but so is initializing at zero and training until almost zero training error count on stochastic gradient descent to perform implicit regularization Also: Dropout Many layers are now common And specific structure: convolution, max pooling
49 Summary of Neural Networks When are Neural Networks useful? Instances represented by attribute-value pairs Particularly when attributes are real valued The target function is Discrete-valued Real-valued Vector-valued Training examples may contain errors Fast evaluation times are necessary When not? Fast training times are necessary Understandability of the function is required
50 Summary of Neural Networks Non-linear regression technique that is trained with gradient descent. Question: How important is the biological metaphor?
51 Other Topics in Neural Nets Batch Move vs. stochastic Auto-Encoders Neural Networks on Silicon
52 Stochastic vs. Batch Mode Stochastic Gradient Descent
53 Incremental vs. Batch Mode In Batch Mode we minimize: Same as computing: Δww DD = dd DD Δww dd Then setting ww = ww + Δww DD
54 Advanced Topics in Neural Nets Batch Move vs. incremental Auto-Encoders Neural Networks on Silicon
55 Hidden Layer Representations Input->Hidden Layer mapping: representation of input vectors tailored to the task Can also be exploited for dimensionality reduction Form of unsupervised learning in which we output a more compact representation of input vectors <x 1,,x n > -> <x 1,,x m > where m < n Useful for visualization, problem simplification, data compression, etc.

56 Dimensionality Reduction Model: Function to learn:
57 Dimensionality Reduction: Example
58 Dimensionality Reduction: Example
59 Dimensionality Reduction: Example
60 Dimensionality Reduction: Example
61 Advanced Topics in Neural Nets Batch Move vs. incremental Auto-encoders Neural Networks on Silicon
62 Neural Networks on Silicon Currently: Simulation of continuous device physics (neural networks) Why not skip this? Digital computational model (thresholding) Continuous device physics (voltage)

63 Example: Silicon Retina Simulates function of biological retina Single-transistor synapses adapt to luminance, temporal contrast Modeling retina directly on chip => requires 100x less power!

64 Example: Silicon Retina Synapses modeled with single transistors
65 Luminance Adaptation
66 Comparison with Mammal Data Real: Artificial:
67 Graphics and results taken from:
68 General NN learning in silicon? People seem more excited about / satisfied with GPUs But, that could change
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Introduction Biologically Motivated Crude Model Backpropagation
 Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Artificial Neural Networks
 Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Introduction To Artificial Neural Networks
 Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Machine Learning. Neural Networks. Le Song. CSE6740/CS7641/ISYE6740, Fall Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
Artificial Neural Networks
 0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
AN INTRODUCTION TO NEURAL NETWORKS. Scott Kuindersma November 12, 2009
 AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
Plan. Perceptron Linear discriminant. Associative memories Hopfield networks Chaotic networks. Multilayer perceptron Backpropagation
 Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Sections 18.6 and 18.7 Artificial Neural Networks
 Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs. artifical neural
Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs. artifical neural
CMSC 421: Neural Computation. Applications of Neural Networks
 CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
CMSC 42: Neural Computation definition synonyms neural networks artificial neural networks neural modeling connectionist models parallel distributed processing AI perspective Applications of Neural Networks
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
COMP9444 Neural Networks and Deep Learning 2. Perceptrons. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 2. Perceptrons COMP9444 17s2 Perceptrons 1 Outline Neurons Biological and Artificial Perceptron Learning Linear Separability Multi-Layer Networks COMP9444 17s2
COMP9444 Neural Networks and Deep Learning 2. Perceptrons COMP9444 17s2 Perceptrons 1 Outline Neurons Biological and Artificial Perceptron Learning Linear Separability Multi-Layer Networks COMP9444 17s2
Neural Networks. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
CS:4420 Artificial Intelligence
 CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Artificial Neural Networks. Historical description
 Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
Sections 18.6 and 18.7 Artificial Neural Networks
 Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs artifical neural networks
Sections 18.6 and 18.7 Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline The brain vs artifical neural networks
Artificial Neural Networks The Introduction
 Artificial Neural Networks The Introduction 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001 00100000
Artificial Neural Networks The Introduction 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001 00100000
Artificial Neural Networks. Edward Gatt
 Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Machine Learning
 Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Artificial Neural Network
 Artificial Neural Network Contents 2 What is ANN? Biological Neuron Structure of Neuron Types of Neuron Models of Neuron Analogy with human NN Perceptron OCR Multilayer Neural Network Back propagation
Artificial Neural Network Contents 2 What is ANN? Biological Neuron Structure of Neuron Types of Neuron Models of Neuron Analogy with human NN Perceptron OCR Multilayer Neural Network Back propagation
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Multilayer Perceptrons (MLPs)
") CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Artificial Neural Networks (ANN) Xiaogang Su, Ph.D. Department of Mathematical Science University of Texas at El Paso
 Xiaogang Su, Ph.D. Department of Mathematical Science University of Texas at El Paso") Artificial Neural Networks (ANN) Xiaogang Su, Ph.D. Department of Mathematical Science University of Texas at El Paso xsu@utep.edu Fall, 2018 Outline Introduction A Brief History ANN Architecture Terminology
Artificial Neural Networks (ANN) Xiaogang Su, Ph.D. Department of Mathematical Science University of Texas at El Paso xsu@utep.edu Fall, 2018 Outline Introduction A Brief History ANN Architecture Terminology
Incremental Stochastic Gradient Descent
 Incremental Stochastic Gradient Descent Batch mode : gradient descent w=w - η E D [w] over the entire data D E D [w]=1/2σ d (t d -o d ) 2 Incremental mode: gradient descent w=w - η E d [w] over individual
Incremental Stochastic Gradient Descent Batch mode : gradient descent w=w - η E D [w] over the entire data D E D [w]=1/2σ d (t d -o d ) 2 Incremental mode: gradient descent w=w - η E d [w] over individual
22c145-Fall 01: Neural Networks. Neural Networks. Readings: Chapter 19 of Russell & Norvig. Cesare Tinelli 1
 Neural Networks Readings: Chapter 19 of Russell & Norvig. Cesare Tinelli 1 Brains as Computational Devices Brains advantages with respect to digital computers: Massively parallel Fault-tolerant Reliable
Neural Networks Readings: Chapter 19 of Russell & Norvig. Cesare Tinelli 1 Brains as Computational Devices Brains advantages with respect to digital computers: Massively parallel Fault-tolerant Reliable
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Neural Networks Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav
 Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Machine Learning
 Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Neural Networks. Mark van Rossum. January 15, School of Informatics, University of Edinburgh 1 / 28
 1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
 CSE446: Neural Networks Winter 2015 Luke Ze
CSE446: Neural Networks Winter 2015 Luke Ze Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Sections 18.6 and 18.7 Analysis of Artificial Neural Networks
 Sections 18.6 and 18.7 Analysis of Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline Univariate regression
Sections 18.6 and 18.7 Analysis of Artificial Neural Networks CS4811 - Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University Outline Univariate regression
Simple Neural Nets For Pattern Classification
 CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
Neural Networks DWML, /25
 DWML, 2007 /25 Neural networks: Biological and artificial Consider humans: Neuron switching time 0.00 second Number of neurons 0 0 Connections per neuron 0 4-0 5 Scene recognition time 0. sec 00 inference
DWML, 2007 /25 Neural networks: Biological and artificial Consider humans: Neuron switching time 0.00 second Number of neurons 0 0 Connections per neuron 0 4-0 5 Scene recognition time 0. sec 00 inference
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Introduction to Artificial Neural Networks
 Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Lecture 4: Feed Forward Neural Networks
 Lecture 4: Feed Forward Neural Networks Dr. Roman V Belavkin Middlesex University BIS4435 Biological neurons and the brain A Model of A Single Neuron Neurons as data-driven models Neural Networks Training
Lecture 4: Feed Forward Neural Networks Dr. Roman V Belavkin Middlesex University BIS4435 Biological neurons and the brain A Model of A Single Neuron Neurons as data-driven models Neural Networks Training
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Neural Networks. Xiaojin Zhu Computer Sciences Department University of Wisconsin, Madison. slide 1
 Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Artificial Neural Networks. Q550: Models in Cognitive Science Lecture 5
 Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Revision: Neural Network
 Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
COMP-4360 Machine Learning Neural Networks
 COMP-4360 Machine Learning Neural Networks Jacky Baltes Autonomous Agents Lab University of Manitoba Winnipeg, Canada R3T 2N2 Email: jacky@cs.umanitoba.ca WWW: http://www.cs.umanitoba.ca/~jacky http://aalab.cs.umanitoba.ca
COMP-4360 Machine Learning Neural Networks Jacky Baltes Autonomous Agents Lab University of Manitoba Winnipeg, Canada R3T 2N2 Email: jacky@cs.umanitoba.ca WWW: http://www.cs.umanitoba.ca/~jacky http://aalab.cs.umanitoba.ca
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Neural Networks. Fundamentals of Neural Networks : Architectures, Algorithms and Applications. L, Fausett, 1994
 Neural Networks Neural Networks Fundamentals of Neural Networks : Architectures, Algorithms and Applications. L, Fausett, 1994 An Introduction to Neural Networks (nd Ed). Morton, IM, 1995 Neural Networks
Neural Networks Neural Networks Fundamentals of Neural Networks : Architectures, Algorithms and Applications. L, Fausett, 1994 An Introduction to Neural Networks (nd Ed). Morton, IM, 1995 Neural Networks
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Statistical NLP for the Web
 Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
EEE 241: Linear Systems
 EEE 4: Linear Systems Summary # 3: Introduction to artificial neural networks DISTRIBUTED REPRESENTATION An ANN consists of simple processing units communicating with each other. The basic elements of
EEE 4: Linear Systems Summary # 3: Introduction to artificial neural networks DISTRIBUTED REPRESENTATION An ANN consists of simple processing units communicating with each other. The basic elements of
Chapter 2 Single Layer Feedforward Networks
 Chapter 2 Single Layer Feedforward Networks By Rosenblatt (1962) Perceptrons For modeling visual perception (retina) A feedforward network of three layers of units: Sensory, Association, and Response Learning
Chapter 2 Single Layer Feedforward Networks By Rosenblatt (1962) Perceptrons For modeling visual perception (retina) A feedforward network of three layers of units: Sensory, Association, and Response Learning
Neural Networks and Fuzzy Logic Rajendra Dept.of CSE ASCET
 Unit-. Definition Neural network is a massively parallel distributed processing system, made of highly inter-connected neural computing elements that have the ability to learn and thereby acquire knowledge
Unit-. Definition Neural network is a massively parallel distributed processing system, made of highly inter-connected neural computing elements that have the ability to learn and thereby acquire knowledge
Artificial Neural Network and Fuzzy Logic
 Artificial Neural Network and Fuzzy Logic 1 Syllabus 2 Syllabus 3 Books 1. Artificial Neural Networks by B. Yagnanarayan, PHI - (Cover Topologies part of unit 1 and All part of Unit 2) 2. Neural Networks
Artificial Neural Network and Fuzzy Logic 1 Syllabus 2 Syllabus 3 Books 1. Artificial Neural Networks by B. Yagnanarayan, PHI - (Cover Topologies part of unit 1 and All part of Unit 2) 2. Neural Networks
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Unit 8: Introduction to neural networks. Perceptrons
 Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Machine Learning Lecture 12
 Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Artificial Neural Networks Examination, March 2004
 Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Lab 5: 16 th April Exercises on Neural Networks
 Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Artificial Neural Networks. Part 2
 Artificial Neural Netorks Part Artificial Neuron Model Folloing simplified model of real neurons is also knon as a Threshold Logic Unit x McCullouch-Pitts neuron (943) x x n n Body of neuron f out Biological
Artificial Neural Netorks Part Artificial Neuron Model Folloing simplified model of real neurons is also knon as a Threshold Logic Unit x McCullouch-Pitts neuron (943) x x n n Body of neuron f out Biological
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4