Machine Learning Lecture 10
|
|
|
- Laura Watkins
- 5 years ago
- Views:
Transcription
1 Machine Learning Lecture 10 Neural Networks Bastian Leibe RWTH Aachen

2 Today s Topic Deep Learning 2


3 Course Outline Fundamentals Bayes Decision Theory Probability Density Estimation Classification Approaches Linear Discriminants Support Vector Machines Ensemble Methods & Boosting (Random Forests) Deep Learning Foundations Convolutional Neural Networks Recurrent Neural Networks 3
4 Recap: AdaBoost Adaptive Boosting Main idea [Freund & Schapire, 1996] Iteratively select an ensemble of component classifiers After each iteration, reweight misclassified training examples. Increase the chance of being selected in a sampled training set. Or increase the misclassification cost when training on the full set. Components h m (x): weak or base classifier Condition: <50% training error over any distribution H(x): strong or final classifier AdaBoost: Construct a strong classifier as a thresholded linear combination of the weighted weak classifiers: H(x) = sign à M X m=1 m h m (x)! 4
 Train a new weak classifier h m (x) using the current weighting coefficients W (m) by minimizing the weighted error function NX J m = w n (m) I(h m(x) 6= t n ) n=1 b)")
5 Recap: AdaBoost Algorithm 1. Initialization: Set w n (1) = 1 for n = 1,,N. N 2. For m = 1,,M iterations a) Train a new weak classifier h m (x) using the current weighting coefficients W (m) by minimizing the weighted error function NX J m = w n (m) I(h m(x) 6= t n ) n=1 b) Estimate the weighted error of this classifier on X: P N n=1 ² m = w(m) n I(h m (x) 6= t n ) P N n=1 w(m) n c) Calculate a weighting coefficient for h m (x): m =? d) Update the weighting coefficients: w (m+1) n =? How should we do this exactly? 5
6 Recap: Minimizing Exponential Error The original algorithm used an exponential error function NX E = exp f t n f m (x n )g n=1 where f m (x) is a classifier defined as a linear combination of base classifiers h l (x): f m (x) = 1 2 mx l h l (x) l=1 Goal Minimize E with respect to both the weighting coefficients l and the parameters of the base classifiers h l (x). 6
7 Recap: Minimizing Exponential Error Sequential Minimization (continuation from last lecture) Only minimize with respect to m and h m (x) E = = = E = NX exp f t n f m (x n )g n=1 NX exp n=1 NX n=1 w (m) n ½ t n f m 1 (x n ) 1 ¾ 2 t n m h m (x n ) exp ³ X N e m=2 e m=2 with = const. ½ 1 ¾ 2 t n m h m (x n ) n=1 f m (x) = 1 2 = w (m) n I(h m(x n ) 6= t n ) + e m=2 mx l h l (x) l=1 NX n=1 w (m) n 7
8 AdaBoost Minimizing Exponential Error Minimize with respect to h m (x): E = ³ X N e m=2 e m (x n )! = 0 w (m) n I(h m(x n ) 6= t n ) + e m=2 NX n=1 w (m) n = const. = const. This is equivalent to minimizing NX J m = w n (m) I(h m(x) 6= t n ) n=1 (our weighted error function from step 2a) of the algorithm) We re on the right track. Let s continue 8
9 AdaBoost Minimizing Exponential Error Minimize with respect to m : E = ³ X N e m=2 e m! = 0 w (m) n I(h m(x n ) 6= t n ) + e m=2 NX n=1 w (m) n µ 1 2 e m=2 + 1 X N 2 e m=2 n=1 w (m) n I(h m(x n ) 6= t n )! = 1 2 e m=2 NX n=1 w (m) n weighted error ² m := Update for the coefficients: P N n=1 w(m) n I(h m (x n ) 6= t n ) P N n=1 w(m) n = e m=2 e m=2 + e m=2 1 ² m = e m + 1 ½ ¾ 1 ²m m = ln ² m 9
10 AdaBoost Minimizing Exponential Error Remaining step: update the weights Recall that E = NX n=1 w (m) n exp ½ 1 ¾ 2 t n m h m (x n ) Therefore w (m+1) n = w (m) n = ::: Update for the weight coefficients. w (m+1) This becomes n in the next iteration. exp ½ 1 ¾ 2 t n m h m (x n ) = w (m) n exp f m I(h m (x n ) 6= t n )g 10
11 AdaBoost Final Algorithm 1. Initialization: Set w n (1) = 1 for n = 1,,N. N 2. For m = 1,,M iterations a) Train a new weak classifier h m (x) using the current weighting coefficients W (m) by minimizing the weighted error function NX J m = w n (m) I(h m(x) 6= t n ) n=1 b) Estimate the weighted error of this classifier on X: P N n=1 ² m = w(m) n I(h m (x) 6= t n ) P N n=1 w(m) n c) Calculate a weighting ½coefficient ¾ for h m (x): 1 ²m m = ln d) Update the weighting coefficients: w (m+1) n ² m = w (m) n exp f m I(h m (x n ) 6= t n )g 11
12 AdaBoost Analysis Result of this derivation We now know that AdaBoost minimizes an exponential error function in a sequential fashion. This allows us to analyze AdaBoost s behavior in more detail. In particular, we can see how robust it is to outlier data points. 12
13 Recap: Error Functions Ideal misclassification error Not differentiable! z n = t n y(x n ) Ideal misclassification error function (black) This is what we want to approximate, Unfortunately, it is not differentiable. The gradient is zero for misclassified points. We cannot minimize it by gradient descent. 13 Image source: Bishop, 2006
14 Recap: Error Functions Ideal misclassification error Squared error Sensitive to outliers! Penalizes too correct data points! Squared error used in Least-Squares Classification Very popular, leads to closed-form solutions. However, sensitive to outliers due to squared penalty. Penalizes too correct data points z n = t n y(x n ) Generally does not lead to good classifiers. 14 Image source: Bishop, 2006
15 Recap: Error Functions Ideal misclassification error Squared error Hinge error Robust to outliers! Not differentiable! Favors sparse solutions! z n = t n y(x n ) Hinge error used in SVMs Zero error for points outside the margin (z n > 1) sparsity Linear penalty for misclassified points (z n < 1) robustness Not differentiable around z n = 1 Cannot be optimized directly. 15 Image source: Bishop, 2006
16 Discussion: AdaBoost Error Function Ideal misclassification error Squared error Hinge error Exponential error z n = t n y(x n ) Exponential error used in AdaBoost Continuous approximation to ideal misclassification function. Sequential minimization leads to simple AdaBoost scheme. Properties? 16 Image source: Bishop, 2006
17 Discussion: AdaBoost Error Function Sensitive to outliers! Ideal misclassification error Squared error Hinge error Exponential error z n = t n y(x n ) Exponential error used in AdaBoost No penalty for too correct data points, fast convergence. Disadvantage: exponential penalty for large negative values! Less robust to outliers or misclassified data points! 17 Image source: Bishop, 2006
18 Discussion: Other Possible Error Functions Ideal misclassification error Squared error Hinge error Exponential error Cross-entropy error E = X ft n ln y n + (1 t n ) ln(1 y n )g z n = t n y(x n ) Cross-entropy error used in Logistic Regression Similar to exponential error for z>0. Only grows linearly with large negative values of z. Make AdaBoost more robust by switching to this error function. GentleBoost 18 Image source: Bishop, 2006
19 Summary: AdaBoost Properties Simple combination of multiple classifiers. Easy to implement. Can be used with many different types of classifiers. None of them needs to be too good on its own. In fact, they only have to be slightly better than chance. Commonly used in many areas. Empirically good generalization capabilities. Limitations Original AdaBoost sensitive to misclassified training data points. Because of exponential error function. Improvement by GentleBoost Single-class classifier Multiclass extensions available 19
20 Today s Topic Deep Learning 20
21 Topics of This Lecture A Brief History of Neural Networks Perceptrons Definition Loss functions Regularization Limits Multi-Layer Perceptrons Definition Learning with hidden units Obtaining the Gradients Naive analytical differentiation Numerical differentiation Backpropagation 21



![..] will be able to walk, talk, see, write,](/docs-images/95/124609044/images/22-6.jpg "reproduce itself and be conscious of its")
22 A Brief History of Neural Networks 1957 Rosenblatt invents the Perceptron And a cool learning algorithm: Perceptron Learning Hardware implementation Mark I Perceptron for pixel image analysis The embryo of an electronic computer that [...] will be able to walk, talk, see, write, reproduce itself and be conscious of its existence. 22 Image source: Wikipedia, clipartpanda.com
23 A Brief History of Neural Networks 1957 Rosenblatt invents the Perceptron 1969 Minsky & Papert They showed that (single-layer) Perceptrons cannot solve all problems. This was misunderstood by many that they were worthless. Neural Networks don t work! 23 Image source: colourbox.de, thinkstock


24 A Brief History of Neural Networks 1957 Rosenblatt invents the Perceptron 1969 Minsky & Papert 1980s Resurgence of Neural Networks Some notable successes with multi-layer perceptrons. Backpropagation learning algorithm Oh no! Killer robots will achieve world domination! OMG! They work like the human brain! 24 Image sources: clipartpanda.com, cliparts.co



25 A Brief History of Neural Networks 1957 Rosenblatt invents the Perceptron 1969 Minsky & Papert 1980s Resurgence of Neural Networks Some notable successes with multi-layer perceptrons. Backpropagation learning algorithm But they are hard to train, tend to overfit, and have unintuitive parameters. So, the excitement fades again sigh! 25 Image source: clipartof.com, colourbox.de

26 A Brief History of Neural Networks 1957 Rosenblatt invents the Perceptron 1969 Minsky & Papert 1980s Resurgence of Neural Networks Interest shifts to other learning methods Notably Support Vector Machines Machine Learning becomes a discipline of its own. I can do science, me! 26 Image source: clipartof.com
27 A Brief History of Neural Networks 1957 Rosenblatt invents the Perceptron 1969 Minsky & Papert 1980s Resurgence of Neural Networks Interest shifts to other learning methods Notably Support Vector Machines Machine Learning becomes a discipline of its own. The general public and the press still love Neural Networks. I m doing Machine Learning. So, you re using Neural Networks? Actually... 27
28 A Brief History of Neural Networks 1957 Rosenblatt invents the Perceptron 1969 Minsky & Papert 1980s Resurgence of Neural Networks Interest shifts to other learning methods Gradual progress Better understanding how to successfully train deep networks Availability of large datasets and powerful GPUs Still largely under the radar for many disciplines applying ML Are you using Neural Networks? Come on. Get real! 28


29 A Brief History of Neural Networks 1957 Rosenblatt invents the Perceptron 1969 Minsky & Papert 1980s Resurgence of Neural Networks Interest shifts to other learning methods Gradual progress 2012 Breakthrough results ImageNet Large Scale Visual Recognition Challenge A ConvNet halves the error rate of dedicated vision approaches. Deep Learning is widely adopted. It works! 29 Image source: clipartpanda.com, clipartof.com
30 Topics of This Lecture A Brief History of Neural Networks Perceptrons Definition Loss functions Regularization Limits Multi-Layer Perceptrons Definition Learning with hidden units Obtaining the Gradients Naive analytical differentiation Numerical differentiation Backpropagation 30
31 Perceptrons (Rosenblatt 1957) Standard Perceptron Input Layer Hand-designed features based on common sense Outputs Output layer Weights Input layer Linear outputs Logistic outputs Learning = Determining the weights w 31


32 Extension: Multi-Class Networks One output node per class Output layer Weights Input layer Outputs Linear outputs Logistic outputs Can be used to do multidimensional linear regression or multiclass classification. Slide adapted from Stefan Roth 32



33 Extension: Non-Linear Basis Functions Straightforward generalization Output layer Weights Feature layer Mapping (fixed) Input layer Outputs Linear outputs Logistic outputs 33
34 Extension: Non-Linear Basis Functions Straightforward generalization Output layer W kd Weights Feature layer Mapping (fixed) Input layer Remarks Perceptrons are generalized linear discriminants! Everything we know about the latter can also be applied here. Note: feature functions Á(x) are kept fixed, not learned! 34
35 Perceptron Learning Very simple algorithm Process the training cases in some permutation If the output unit is correct, leave the weights alone. If the output unit incorrectly outputs a zero, add the input vector to the weight vector. If the output unit incorrectly outputs a one, subtract the input vector from the weight vector. This is guaranteed to converge to a correct solution if such a solution exists. Slide adapted from Geoff Hinton 35
36 Perceptron Learning Let s analyze this algorithm... Process the training cases in some permutation If the output unit is correct, leave the weights alone. If the output unit incorrectly outputs a zero, add the input vector to the weight vector. If the output unit incorrectly outputs a one, subtract the input vector from the weight vector. Translation w ( +1) kj = w ( ) kj (y k(x n ; w) t kn ) Á j (x n ) Slide adapted from Geoff Hinton 36
37 Perceptron Learning Let s analyze this algorithm... Process the training cases in some permutation If the output unit is correct, leave the weights alone. If the output unit incorrectly outputs a zero, add the input vector to the weight vector. If the output unit incorrectly outputs a one, subtract the input vector from the weight vector. Translation w ( +1) kj = w ( ) kj (y k(x n ; w) t kn ) Á j (x n ) This is the Delta rule a.k.a. LMS rule! Perceptron Learning corresponds to 1 st -order (stochastic) Gradient Descent (e.g., of a quadratic error function)! Slide adapted from Geoff Hinton 37
38 Loss Functions We can now also apply other loss functions L2 loss Least-squares regression L1 loss: Median regression Cross-entropy loss Logistic regression Hinge loss SVM classification Softmax loss L(t; y(x)) = P n P k Multi-class probabilistic classification n I (t n = k) ln exp(y k(x)) P j exp(y j(x)) o 38
39 Regularization In addition, we can apply regularizers E.g., an L2 regularizer This is known as weight decay in Neural Networks. We can also apply other regularizers, e.g. L1 sparsity Since Neural Networks often have many parameters, regularization becomes very important in practice. We will see more complex regularization techniques later on... 39
40 Limitations of Perceptrons What makes the task difficult? Perceptrons with fixed, hand-coded input features can model any separable function perfectly......given the right input features. For some tasks this requires an exponential number of input features. E.g., by enumerating all possible binary input vectors as separate feature units (similar to a look-up table). But this approach won t generalize to unseen test cases! It is the feature design that solves the task! Once the hand-coded features have been determined, there are very strong limitations on what a perceptron can learn. Classic example: XOR function. 40
41 Wait... Didn t we just say that... Perceptrons correspond to generalized linear discriminants And Perceptrons are very limited... Doesn t this mean that what we have been doing so far in this lecture has the same problems??? Yes, this is the case. A linear classifier cannot solve certain problems (e.g., XOR). However, with a non-linear classifier based on the right kind of features, the problem becomes solvable. So far, we have solved such problems by hand-designing good features Á and kernels Á > Á. Can we also learn such feature representations? 41
42 Topics of This Lecture A Brief History of Neural Networks Perceptrons Definition Loss functions Regularization Limits Multi-Layer Perceptrons Definition Learning with hidden units Obtaining the Gradients Naive analytical differentiation Numerical differentiation Backpropagation 42
43 Multi-Layer Perceptrons Adding more layers Output layer Hidden layer Mapping (learned!) Input layer Output Slide adapted from Stefan Roth 43
 can approximate any continuous function of a compact domain arbitrarily well!")
44 Multi-Layer Perceptrons Activation functions g : For example: g (2) (a) = ¾(a), g (1) (a) = a The hidden layer can have an arbitrary number of nodes There can also be multiple hidden layers. Universal approximators A 2-layer network (1 hidden layer) can approximate any continuous function of a compact domain arbitrarily well! (assuming sufficient hidden nodes) Slide credit: Stefan Roth 44
45 Learning with Hidden Units Networks without hidden units are very limited in what they can learn More layers of linear units do not help still linear Fixed output non-linearities are not enough. We need multiple layers of adaptive non-linear hidden units. But how can we train such nets? Need an efficient way of adapting all weights, not just the last layer. Learning the weights to the hidden units = learning features This is difficult, because nobody tells us what the hidden units should do. Main challenge in deep learning. Slide adapted from Geoff Hinton 45
 and a regu")
46 Learning with Hidden Units How can we train multi-layer networks efficiently? Need an efficient way of adapting all weights, not just the last layer. Idea: Gradient Descent Set up an error function with a loss L( ) and a regularizer ( ). E.g., L 2 loss L 2 regularizer ( weight decay ) Update each weight in the direction of the gradient 46
47 Gradient Descent Two main steps 1. Computing the gradients for each weight 2. Adjusting the weights in the direction of the gradient today next lecture 47
48 Topics of This Lecture A Brief History of Neural Networks Perceptrons Definition Loss functions Regularization Limits Multi-Layer Perceptrons Definition Learning with hidden units Obtaining the Gradients Naive analytical differentiation Numerical differentiation Backpropagation 48
49 Obtaining the Gradients Approach 1: Naive Analytical Differentiation Compute the gradients for each variable analytically. What is the problem when doing this? 49
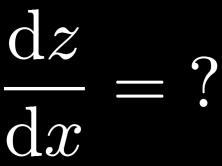
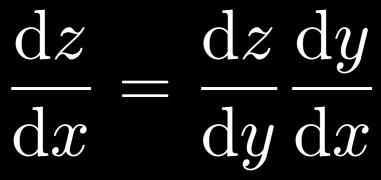
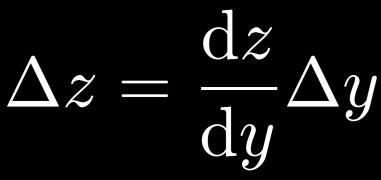
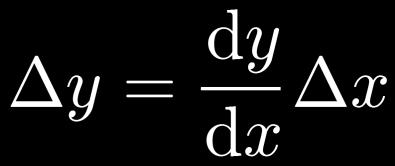
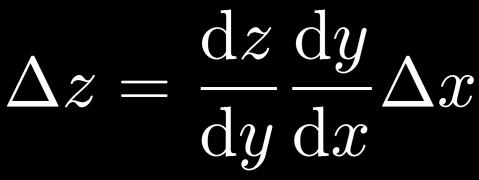
50 Excursion: Chain Rule of Differentiation One-dimensional case: Scalar functions 50


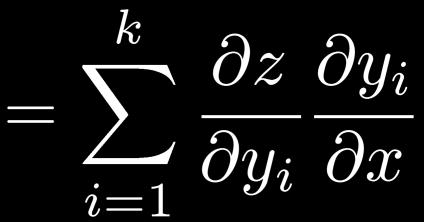
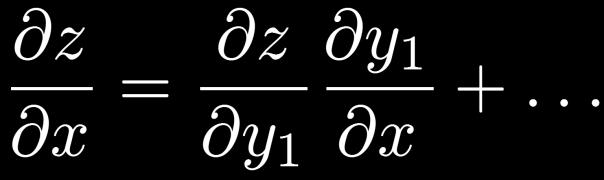
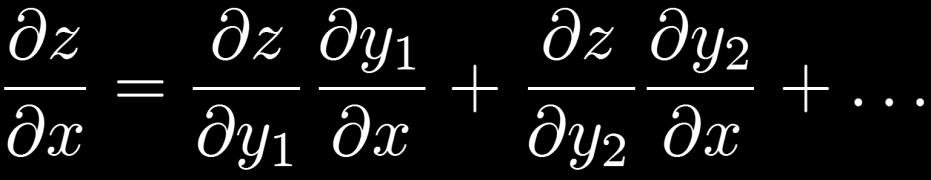
51 Excursion: Chain Rule of Differentiation Multi-dimensional case: Total derivative Need to sum over all paths that lead to the target variable x. 51

52 Obtaining the Gradients Approach 1: Naive Analytical Differentiation Compute the gradients for each variable analytically. What is the problem when doing this? With increasing depth, there will be exponentially many paths! Infeasible to compute this way. 52
53 Topics of This Lecture A Brief History of Neural Networks Perceptrons Definition Loss functions Regularization Limits Multi-Layer Perceptrons Definition Learning with hidden units Obtaining the Gradients Naive analytical differentiation Numerical differentiation Backpropagation 53
54 Obtaining the Gradients Approach 2: Numerical Differentiation Given the current state W ( ), we can evaluate E(W ( ) ). Idea: Make small changes to W ( ) and accept those that improve E(W ( ) ). Horribly inefficient! Need several forward passes for each weight. Each forward pass is one run over the entire dataset! 54
55 Topics of This Lecture A Brief History of Neural Networks Perceptrons Definition Loss functions Regularization Limits Multi-Layer Perceptrons Definition Learning with hidden units Obtaining the Gradients Naive analytical differentiation Numerical differentiation Backpropagation 55



56 Obtaining the Gradients Approach 3: Incremental Analytical Differentiation Idea: Compute the gradients layer by layer. Each layer below builds upon the results of the layer above. The gradient is propagated backwards through the layers. Backpropagation algorithm 56


57 Backpropagation Algorithm Core steps 1. Convert the discrepancy between each output and its target value into an error derivate. 2. Compute error derivatives in each hidden layer from error derivatives in the layer above. 3. Use error derivatives w.r.t. activities to get error derivatives w.r.t. the incoming weights E y j E y j E y i (k 1) E w ji (k 1) Slide adapted from Geoff Hinton 58
58 Backpropagation Algorithm y j z j E z = y j j z j E y j = g z j z j E y j y i (k 1) Notation y j Output of layer k Connections: w ji (k 1) yi (k 1) z j Slide adapted from Geoff Hinton Input of layer k z j = i y j = g zj 63
59 Backpropagation Algorithm y j z j E z = y j j z j E y j = g z j z j E y j y i (k 1) E y i (k 1) = j z j y i (k 1) E z j = j w ji (k 1) E z j Notation y j z j Slide adapted from Geoff Hinton Output of layer k Input of layer k Connections: z j = i z y j j = g zj (k 1) y = w ji i w ji (k 1) yi (k 1) (k 1) 64
60 Backpropagation Algorithm y j z j E z = y j j z j E y j = g z j z j E y j y i (k 1) E y i (k 1) = j z j y i (k 1) E z j = j w ji (k 1) E z j Notation y j z j Slide adapted from Geoff Hinton Output of layer k Input of layer k E w ji (k 1) = z j (k 1) w ji Connections: E z j = y i (k 1) E z j z j = i z y j j = g zj (k 1) w = y i ji w ji (k 1) yi (k 1) (k 1) 65
61 Backpropagation Algorithm y j z j E z = y j j z j E y j = g z j z j E y j y i (k 1) E y i (k 1) = j z j y i (k 1) E z j = j w ji (k 1) E z j E w ji (k 1) = Efficient propagation scheme z j (k 1) w ji E z j = y i (k 1) E z j y i (k 1) is already known from forward pass! (Dynamic Programming) Propagate back the gradient from layer k and multiply with y i (k 1). Slide adapted from Geoff Hinton 66

62 Summary: MLP Backpropagation Forward Pass Backward Pass for k = 1,..., l do for k = l, l-1,...,1 do endfor endfor Notes For efficiency, an entire batch of data X is processed at once. denotes the element-wise product 67
63 Analysis: Backpropagation Backpropagation is the key to make deep NNs tractable However... The Backprop algorithm given here is specific to MLPs It does not work with more complex architectures, e.g. skip connections or recurrent networks! Whenever a new connection function induces a different functional form of the chain rule, you have to derive a new Backprop algorithm for it. Tedious... Let s analyze Backprop in more detail This will lead us to a more flexible algorithm formulation Next lecture 68

64 References and Further Reading More information on Neural Networks can be found in Chapters 6 and 7 of the Goodfellow & Bengio book I. Goodfellow, Y. Bengio, A. Courville Deep Learning MIT Press,
Machine Learning Lecture 12
 Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Lecture 12. Neural Networks Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 12 Neural Networks 10.12.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 12 Neural Networks 10.12.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Lecture 12. Neural Networks Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 12 Neural Networks 24.11.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de Talk Announcement Yann LeCun (NYU & FaceBook AI)
Advanced Machine Learning Lecture 12 Neural Networks 24.11.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de Talk Announcement Yann LeCun (NYU & FaceBook AI)
Lecture 12. Talk Announcement. Neural Networks. This Lecture: Advanced Machine Learning. Recap: Generalized Linear Discriminants
 Advanced Machine Learning Lecture 2 Neural Networks 24..206 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de Talk Announcement Yann LeCun (NYU & FaceBook AI) 28..
Advanced Machine Learning Lecture 2 Neural Networks 24..206 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de Talk Announcement Yann LeCun (NYU & FaceBook AI) 28..
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Machine Learning Lecture 14
 Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Lecture 3. Linear Regression II Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Neural Networks Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav
 Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1
 What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
2018 EE448, Big Data Mining, Lecture 5. (Part II) Weinan Zhang Shanghai Jiao Tong University
 Weinan Zhang Shanghai Jiao Tong University") 2018 EE448, Big Data Mining, Lecture 5 Supervised Learning (Part II) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
2018 EE448, Big Data Mining, Lecture 5 Supervised Learning (Part II) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Feed-forward Networks Network Training Error Backpropagation Applications. Neural Networks. Oliver Schulte - CMPT 726. Bishop PRML Ch.
 Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will
Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Learning Deep Architectures for AI. Part I - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part I - Vijay Chakilam Chapter 0: Preliminaries Neural Network Models The basic idea behind the neural network approach is to model the response as a
Learning Deep Architectures for AI - Yoshua Bengio Part I - Vijay Chakilam Chapter 0: Preliminaries Neural Network Models The basic idea behind the neural network approach is to model the response as a
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Voting (Ensemble Methods)
") 1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Linear discriminant functions
 Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Neural Networks for Machine Learning. Lecture 2a An overview of the main types of neural network architecture
 Neural Networks for Machine Learning Lecture 2a An overview of the main types of neural network architecture Geoffrey Hinton with Nitish Srivastava Kevin Swersky Feed-forward neural networks These are
Neural Networks for Machine Learning Lecture 2a An overview of the main types of neural network architecture Geoffrey Hinton with Nitish Srivastava Kevin Swersky Feed-forward neural networks These are
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Advanced statistical methods for data analysis Lecture 2
 Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Machine Learning for NLP
 Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring /
 Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT. Slides credit: Graham Neubig
 Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Chapter 14 Combining Models
 Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Mark Gales October y (x) x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.
 x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.") University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
Introduction to Deep Learning
 Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Perceptron & Neural Networks
 School of Computer Science 10-701 Introduction to Machine Learning Perceptron & Neural Networks Readings: Bishop Ch. 4.1.7, Ch. 5 Murphy Ch. 16.5, Ch. 28 Mitchell Ch. 4 Matt Gormley Lecture 12 October
School of Computer Science 10-701 Introduction to Machine Learning Perceptron & Neural Networks Readings: Bishop Ch. 4.1.7, Ch. 5 Murphy Ch. 16.5, Ch. 28 Mitchell Ch. 4 Matt Gormley Lecture 12 October
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt.
 1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an