Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
|
|
|
- Phyllis Hancock
- 6 years ago
- Views:
Transcription

1 ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
2 Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
3 Database ImageNet 15M images 22K categories Images collected from Web RGB Images Variable-resolution Human labelers (Amazon s Mechanical Turk crowd-sourcing) ImageNet Large Scale Visual Recognition Challenge (ILSVRC-2010) 1K categories 1.2M training images (~1000 per category) 50,000 validation images 150,000 testing images


4 Strategy Deep Learning Shallow vs. deep architectures Learn a feature hierarchy all the way from pixels to classifier reference :
5 Neuron - Perceptron Input (raw pixel) x 1 Weights w 1 x 2 x 3 w 2 w 3 f Output: f(w*x+b) w d x d reference :
6 Multi-Layer Neural Networks Input Layer Hidden Layer Output Layer Nonlinear classifier Learning can be done by gradient descent Back-Propagation algorithm
7 Feed Forward Operation input layer: d features hidden layer: output layer: m outputs, one for each class x (1) w ji v kj z 1 x (2) x (d) z m bias unit
8 Notation for Weights Use w ji to denote the weight between input unit i and hidden unit j input unit i w ji hidden unit j x (i) w ji x (i) y j Use v kj to denote the weight between hidden unit j and output unit k hidden unit j output unit k y j v kj vkj y j z k
9 Notation for Activation Use net i to denote the activation and hidden unit j net j = d i= 1 x ( i ) w ji + w j 0 hidden unit j y j Use net* k to denote the activation at output unit k net * k N = H j= 1 y j v kj + v k 0 output unit k z j
10 Network Training 1. Initialize weights w ji and v kj randomly but not to 0 2. Iterate until a stopping criterion is reached choose p input sample x p MNN with weights w ji and v kj output z z = M 1 z m Compare output z with the desired target t; adjust w ji and v kj to move closer to the goal t (by backpropagation)
11 BackPropagation Learn w ji and v kj by minimizing the training error What is the training error? Suppose the output of MNN for sample x is z and the target (desired output for x ) is t Error on one sample: J 1 2 ( w, v ) = ( t z ) m c= 1 t c z c 2 Training error: J 1 2 n ( i ) ( i ) ( w, v ) = t c z m ( ) c i= 1 c= 1 2 Use gradient descent: v ( 0 ) (,w 0) = repeat until convergence: ( t + 1) ( t ) ( t ) w v = random w η w ( w ) ( t v ) J ( t + 1) ( t ) ( ) = v η v J
12 BackPropagation: Layered Model activation at hidden unit j net j = d i= 1 x ( i ) w ji + w j 0 output at hidden unit j y ( ) j= f net j activation at output unit k net * k N = H j= 1 y j v kj + v k 0 activation at output unit k ( * z ) k= f net k chain rule chain rule objective function J 1 2 m ( w, v ) = ( t c z c ) c= 1 2 J v kj J w ji
13 J w BackPropagation of Errors ji = f m ( ) i * ( net j ) x ( tk zk ) f ( netk ) v J kj = ( tk zk ) f' ( netk ) * y j k= 1 unit i unit j v kj error z 1 z m Name backpropagation because during training, errors propagated back from output to hidden layer
14 Learning Curves classi ification error training time this is a good time to stop training, since after this time we start to overfit Stopping criterion is part of training phase, thus validation data is part of the training data To assess how the network will work on the unseen examples, we still need test data
15 Momentum Gradient descent finds only a local minima not a problem if J(w) is small at a local minima. Indeed, we do not wish to find w s.t. J(w) = 0 due to overfitting J(w) reasonable local minimum problem if J(w) is large at a local minimum w J(w) global minimum bad local minimum global minimum
16 Momentum Momentum: popular method to avoid local minima and also speeds up descent in plateau regions weight update at time t is w ( t ) ( t ) ( t 1) w add temporal average direction in which weights have been moving recently = w w J = w + 1 α η + α w w ( t + 1 ) ( t ) ( t 1 ) ( ) steepest descent direction previous direction at α = 0, equivalent to gradient descent at α = 1, gradient descent is ignored, weight update continues in the direction in which it was moving previously (momentum) usually, α is around 0.9
17 1D Convolution
18 Neural 1D Convolution Implementation
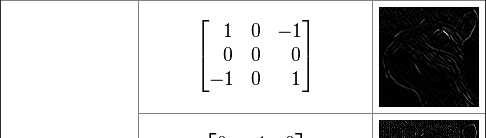
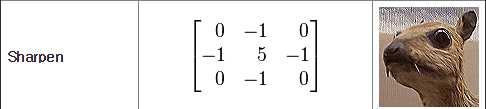
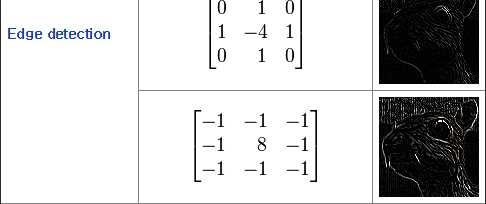
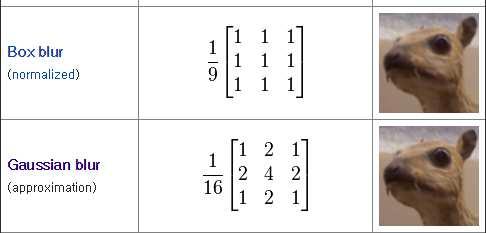
19 2D Convolution Matrix reference :






20 Convolutional Filter... Input Feature Map reference :
21 Architecture Trained with stochastic gradient descent on two NVIDIA GPUs for about a week (5~6 days) 650,000 neurons, 60 million parameters, 630 million connections The last layer contains 1,000 neurons which produces a distribution over the 1,000 class labels.

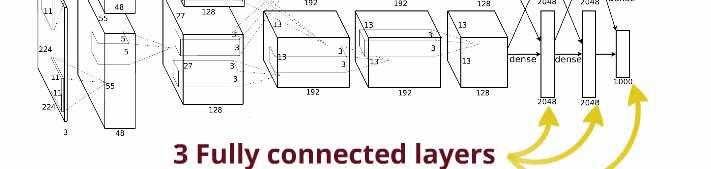
22 Architecture
23 Architecture
24 Architecture
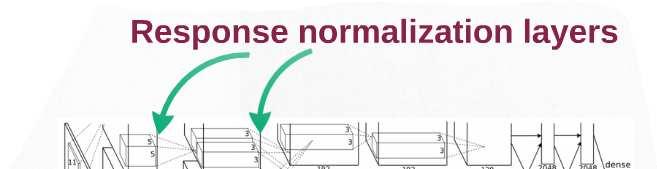
25 Response-Normalization Layer : the activity of a neuron computed by applying kernel i at position (x, y) The response-normalized activity is given by N : the total # of kernels in the layer n : hyper-parameter, n=5 k : hyper-parameter, k=2 α : hyper-parameter, α=10^(-4) β : hyper-parameter, β =0.75 This aids generalization even though ReLU don t require it. This reduces top-1 error by 1.4, top-5 error rate by 1.2%




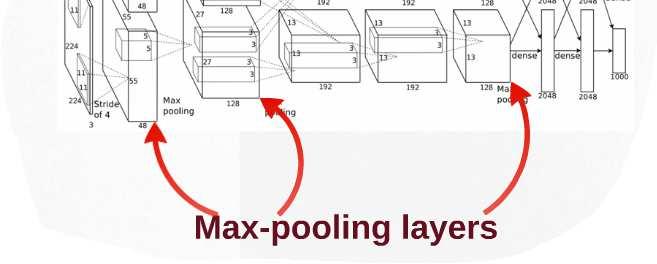
26 Pooling Layer Non-overlapping / overlapping regions Sum or max Max Sum Reduces the error rate of top-1 by 0.4% and top-5 by 0.3% reference :

27 Architecture
28 First Layer Visualization
29 ReLU
30 Learning rule Use stochastic gradient descent with a batch size of 128 examples, momentum of 0.9, and weigh decay of The update rule for weight w was i : the iteration index : the learning rate, initialized at 0.01 and reduced three times prior to termination : the average over the i-th batch D i of the derivative of the objective with respect to w Train for 90 cycles through the training set of 1.2 million images

31 Fighting overfitting - input This neural net has 60M real-valued parameters and 650,000 neurons It overfils a lot therefore train on five 224x224 patches extracted randomly from 256x256 images, and also their horizontal reflections
32 Fighting overfitting - Dropout Independently set each hidden unit activity to zero with 0.5 probability Used in the two globally-connected hidden layers at the net's output Doubles the number of iterations required to converge reference :


33 Results - Classification ILSVRC-2010 test set ILSVRC-2012 test set
34 Results Classification
35 Results Retrival
36 The End Thank you for your attention
37 Refernces sglab.kaist.ac.kr/~sungeui/ir/.../second/ 오은수.pptx 701/slides/14_PrincipalComp.pdf Hagit Hel-or (Convolution Slide) /NN.pdf
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Multilayer Neural Networks
 Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Neural Networks. Learning and Computer Vision Prof. Olga Veksler CS9840. Lecture 10
 CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Architecture Multilayer Perceptron (MLP)
") Architecture Multilayer Perceptron (MLP) 1 Output Hidden Input Neurons partitioned into layers; y 1 y 2 one input layer, one output layer, possibly several hidden layers layers numbered from 0; the input
Architecture Multilayer Perceptron (MLP) 1 Output Hidden Input Neurons partitioned into layers; y 1 y 2 one input layer, one output layer, possibly several hidden layers layers numbered from 0; the input
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Deep Learning (CNNs)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
Deep Learning: a gentle introduction
 Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSCI 315: Artificial Intelligence through Deep Learning
 CSCI 35: Artificial Intelligence through Deep Learning W&L Fall Term 27 Prof. Levy Convolutional Networks http://wernerstudio.typepad.com/.a/6ad83549adb53ef53629ccf97c-5wi Convolution: Convolution is
CSCI 35: Artificial Intelligence through Deep Learning W&L Fall Term 27 Prof. Levy Convolutional Networks http://wernerstudio.typepad.com/.a/6ad83549adb53ef53629ccf97c-5wi Convolution: Convolution is
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Multilayer Perceptron = FeedForward Neural Network
 Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Regularization in Neural Networks
 Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Introduction Neural Networks - Architecture Network Training Small Example - ZIP Codes Summary. Neural Networks - I. Henrik I Christensen
 Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16 Slides adapted from Jordan Boyd-Graber, Justin Johnson, Andrej Karpathy, Chris Ketelsen, Fei-Fei Li, Mike Mozer, Michael Nielson
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16 Slides adapted from Jordan Boyd-Graber, Justin Johnson, Andrej Karpathy, Chris Ketelsen, Fei-Fei Li, Mike Mozer, Michael Nielson
Convolutional Neural Networks. Srikumar Ramalingam
 Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Introduction to Neural Networks
 Introduction to Neural Networks Philipp Koehn 3 October 207 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models
Introduction to Neural Networks Philipp Koehn 3 October 207 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Bayesian Networks (Part I)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
Machine Learning
 Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Introduction Biologically Motivated Crude Model Backpropagation
 Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Lecture 7 Convolutional Neural Networks
 Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Convolutional Neural Network Architecture
 Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Introduction to Deep Learning
 Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
Artificial Neural Networks. Edward Gatt
 Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Multilayer Perceptrons and Backpropagation
 Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
arxiv: v1 [cs.cv] 11 May 2015 Abstract
![arxiv: v1 [cs.cv] 11 May 2015 Abstract](/thumbs/80/80674557.jpg "arxiv: v1 [cs.cv] 11 May 2015 Abstract") Training Deeper Convolutional Networks with Deep Supervision Liwei Wang Computer Science Dept UIUC lwang97@illinois.edu Chen-Yu Lee ECE Dept UCSD chl260@ucsd.edu Zhuowen Tu CogSci Dept UCSD ztu0@ucsd.edu
Training Deeper Convolutional Networks with Deep Supervision Liwei Wang Computer Science Dept UIUC lwang97@illinois.edu Chen-Yu Lee ECE Dept UCSD chl260@ucsd.edu Zhuowen Tu CogSci Dept UCSD ztu0@ucsd.edu
CSC321 Lecture 9: Generalization
 CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 26 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 26 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Deep Feedforward Networks
 Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
 CSE446: Neural Networks Winter 2015 Luke Ze
CSE446: Neural Networks Winter 2015 Luke Ze Feature Design. Feature Design. Feature Design. & Deep Learning
 Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Multilayer Perceptrons (MLPs)
") CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural
 learning techniques for neural") 1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
Neural Networks. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Theories of Deep Learning
 Theories of Deep Learning Lecture 02 Donoho, Monajemi, Papyan Department of Statistics Stanford Oct. 4, 2017 1 / 50 Stats 385 Fall 2017 2 / 50 Stats 285 Fall 2017 3 / 50 Course info Wed 3:00-4:20 PM in
Theories of Deep Learning Lecture 02 Donoho, Monajemi, Papyan Department of Statistics Stanford Oct. 4, 2017 1 / 50 Stats 385 Fall 2017 2 / 50 Stats 285 Fall 2017 3 / 50 Course info Wed 3:00-4:20 PM in
Introduction to Deep Learning
 Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Classification of Higgs Boson Tau-Tau decays using GPU accelerated Neural Networks
 Classification of Higgs Boson Tau-Tau decays using GPU accelerated Neural Networks Mohit Shridhar Stanford University mohits@stanford.edu, mohit@u.nus.edu Abstract In particle physics, Higgs Boson to tau-tau
Classification of Higgs Boson Tau-Tau decays using GPU accelerated Neural Networks Mohit Shridhar Stanford University mohits@stanford.edu, mohit@u.nus.edu Abstract In particle physics, Higgs Boson to tau-tau
Introduction to Neural Networks
 Introduction to Neural Networks Steve Renals Automatic Speech Recognition ASR Lecture 10 24 February 2014 ASR Lecture 10 Introduction to Neural Networks 1 Neural networks for speech recognition Introduction
Introduction to Neural Networks Steve Renals Automatic Speech Recognition ASR Lecture 10 24 February 2014 ASR Lecture 10 Introduction to Neural Networks 1 Neural networks for speech recognition Introduction
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets)
") COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Neural Networks for Machine Learning. Lecture 2a An overview of the main types of neural network architecture
 Neural Networks for Machine Learning Lecture 2a An overview of the main types of neural network architecture Geoffrey Hinton with Nitish Srivastava Kevin Swersky Feed-forward neural networks These are
Neural Networks for Machine Learning Lecture 2a An overview of the main types of neural network architecture Geoffrey Hinton with Nitish Srivastava Kevin Swersky Feed-forward neural networks These are
8. Lecture Neural Networks
 Soft Control (AT 3, RMA) 8. Lecture Neural Networks Learning Process Contents of the 8 th lecture 1. Introduction of Soft Control: Definition and Limitations, Basics of Intelligent" Systems 2. Knowledge
Soft Control (AT 3, RMA) 8. Lecture Neural Networks Learning Process Contents of the 8 th lecture 1. Introduction of Soft Control: Definition and Limitations, Basics of Intelligent" Systems 2. Knowledge
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Lab 5: 16 th April Exercises on Neural Networks
 Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
RegML 2018 Class 8 Deep learning
 RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x