Neural Networks. Learning and Computer Vision Prof. Olga Veksler CS9840. Lecture 10
|
|
|
- Coleen Cooper
- 6 years ago
- Views:
Transcription
1 CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard
2 Outline Short Intro Perceptron ( layer NN) Multilayer Perceptron (MLP) Deep Networks Convolutional Network
3 Neural Networks Neural Networks correspond to some discriminant function g NN (x) Can carve out arbitrarily complex decision boundaries without requiring so many terms as polynomial functions Neural Nets were inspired by research in how human brain works But also proved to be quite successful in practice Are used nowadays successfully for a wide variety of applications took some time to get them to work now used by US post for postal code recognition x 2 x

4 Neuron: Basic Brain Processor Neurons (or nerve cells) are special cells that process and transmit information by electrical signaling in brain and also spinal cord Human brain has around 0 neurons A neuron connects to other neurons to form a network Each neuron cell communicates to anywhere from 000 to 0,000 other neurons
 splits in possibly thousands branches at the end, axon")
5 Neuron: Main Components dendrites cell body axon terminals cell body computational unit dendrites axon nucleus input wires, receive inputs from other neurons a neuron may have thousands of dendrites, usually short axon output wire, sends signal to other neurons single long structure (up to meter) splits in possibly thousands branches at the end, axon terminals 5
6 ANN History: First Successes 958, F. Rosenblatt, Cornell University perceptron, oldest neural network still in use today that s what we studied in lecture on linear classifiers Algorithm to train the perceptron network Built in hardware Proved convergence in linearly separable case initially seemed promising, but too many claims were made
7 ANN History: Stagnation Early success lead to a lot of claims which were not fulfilled 969, M. Minsky and S. Pappert Book Perceptrons Proved that perceptrons can learn only linearly separable classes In particular cannot learn very simple XOR function Conectured that multilayer neural networks also limited by linearly separable functions No funding and almost no research (at least in North America) in 970 s as the result of 2 things above
8 ANN History: Revival Revival of ANN in 980 s 982, J. Hopfield New kind of networks (Hopfield s networks) Not ust model of how human brain might work, but also how to create useful devices Implements associative memory 982 oint US-Japanese conference on ANN US worries that it will stay behind Many examples of mulitlayer Neural Networks appear 986, re-discovery of backpropagation algorithm by Werbos, Rumelhart, Hinton and Ronald Williams Allows a network to learn not linearly separable classes Lots of successes in the past 5 years due to better training
9 Artificial Neural Nets (ANN): Perceptron bias unit layer input layer x x 2 w 0 w layer 2 output layer h()=sign() w 2 sign(w t x+w 0 ) w 3 x 3 Linear classifier f(x) = sign(w t x+w 0 ) is a single neuron net Input layer units output features, except bias outputs Output layer unit applies sign() or some other function h() h() is also called an activation function
10 Multilayer Neural Network (MLP) layer Input layer layer 2 hidden layer layer 3 output layer x x 2 w w h( w h( )+w h( ) ) x 3 First hidden unit outputs: h( ) = h(w 0 +w x +w 2 x 2 +w 3 x 3 ) Second hidden unit outputs: h( ) = h(w 0 +w x +w 2 x 2 +w 3 x 3 ) Network corresponds to classifier f(x) = h( w h( )+w h( ) ) More complex than Perceptron, more complex boundaries
11 MLP Small Example layer : input x x layer 2: hidden layer 3: output Let activation function h() = sign() MLP Corresponds to classifier f(x) = sign( 4 h( )+2 h( ) + 7 ) = sign(4 sign(3x +5x 2 )+2 sign(6+3x 2 ) + 7) MLP terminology: computing f(x) is called feed forward operation graphically, function is computed from left to right Edge weights are learned through training
12 MLP: Multiple Classes layer Input layer layer 2 hidden layer layer 3 output layer x x 2 3 classes, 2 features, hidden layer 3 input units, one for each feature 3 output units, one for each class 2 hidden units bias unit, usually drawn in layer
13 MLP: General Structure layer Input layer x x 2 layer 2 hidden layer layer 3 output layer h(...) h(...) h(...) = f (x) = f 2 (x) = f 3 (x) f(x) = [f (x), f 2 (x), f 3 (x)] is multi-dimensional Classification: If f (x) is largest, decide class If f 2 (x) is largest, decide class 2 If f 3 (x) is largest, decide class 3
14 MLP: General Structure layer Input layer layer 2 hidden layer layer 3 output layer x x 2 Input layer: d features, d input units Output layer: m classes, m output units Hidden layer: how many units?
15 MLP: General Structure layer Input layer layer 2 hidden layer layer 3 hidden layer layer 4 output layer w w w h(...) x w x 2 Can have more than hidden layer ith layer connects to (i+)th layer except bias unit can connect to any layer can have different number of units in each hidden layer First output unit outputs: h(...) = h( w h( ) + w ) = h( w h(w h( ) + w h( )) + w )
16 MLP: Activation Function h() = sign() is discontinuous, not good for gradient descent Instead can use continuous sigmoid function Rectified Linear is gaining popularity recently (ReLu) Or another differentiable function Can even use different activation functions at different layers/units From now, assume h() is a differentiable function
17 MLP: Overview A neural network corresponds to a classifier f(x,w) that can be rather complex complexity depends on the number of hidden layers/units f(x,w) is a composition of many functions easier to visualize as a network notation gets ugly To train neural network, ust as before formulate an obective function J(w) optimize it with gradient descent That s all! Except we need quite a few slides to write down details due to complexity of f(x,w)
18 Expressive Power of MLP Every continuous function from input to output can be implemented with enough hidden units, hidden layer, and proper nonlinear activation functions easy to show that with linear activation function, multilayer neural network is equivalent to perceptron This is more of theoretical than practical interest Proof is not constructive (does not tell how construct MLP) Even if constructive, would be of no use, we do not know the desired function, our goal is to learn it through the samples But this result gives confidence that we are on the right track MLP is general (expressive) enough to construct any required decision boundaries, unlike the Perceptron
19 Decision Boundaries Perceptron (single layer neural net) Arbitrarily complex decision regions Even not contiguous
20 Nonlinear Decision Boundary: Example Start with two Perceptrons, h() = sign() x + x 2 > 0 class - x - x 2 3 > 0 class -3 x - x - x 2 x 2 x 2 x 2 - x 3 x -3
21 Nonlinear Decision Boundary: Example Now combine them into a 3 layer NN - - x -3 x x 2 x 2 x 2 + x x 3 - x
22 MLP: Modes of Operation For Neural Networks, due to historical reasons, training and testing stages have special names Backpropagation (or training) Minimize obective function with gradient descent Feedforward (or testing)
23 x d. MLP: Notation for Edge Weights layer input layer 2 hidden layer k- hidden layer k output unit x.. w k m. unit d bias unit or unit 0 w k 0m w k p is edge weight from unit p in layer k- to unit in layer k w k 0 is edge weight from bias unit to unit in layer k w k is all weights to unit in layer k, i.e. w k 0, w k,, w k N(k-) N(k) is the number of units in layer k, excluding the bias unit
24 x MLP: More Notation layer layer 2 layer 3 z 0 = z 3 2 = h( ) x 2 z 2 = x 2 z 2 2 = h( ) Denote the output of unit in layer k as z k For the input layer (k=), z 0 = and z = x, 0 For all other layers, (k > ), z k = h( ) Convenient to set z k 0 = for all k Set z k = [z k 0, z k,, z k N(k)]
25 MLP: More Notation layer layer 2 layer 3 x x 2 Net activation at unit in layer k > is the sum of inputs a k N k = p= z k p w k p + w k 0 a + For k >, z k = h(a k ) N k = p= = z0w0 + zw z2w2 k k z p wp k k = z w
26 MLP: Class Representation m class problem, let Neural Net have t layers Let x i be a example of class c It is convenient to denote its label as y i = row c 0 0 Recall that z t c is the output of unit c in layer t (output layer) f(x)= z t =. If x i is of class c, want z t = t m t c t z z z 0 0 row c
27 Training MLP: Obective Function Want to minimize difference between y i and f(x i ) Use squared difference Let w be all edge weights in MLP collected in one vector m ( ) ( ( i = ) i ) 2 Error on one example x i : Ji w fc x yc 2 Error on all examples: J 2 c= n m ( ) ( ( i) i w = f ) c x yc i= c= 2 Gradient descent: initialize w to random choose ε, α while α J(w) > ε w = w - α J(w)
28 Training MLP: Single Sample For simplicity, first consider error for one example x i m i ( ) ( i) 2 = = ( ( i) i ) 2 Ji w y f x fc x yc 2 2 f c (x i ) depends on w y i is independent of w Compute partial derivatives w.r.t. w k p for all k, p, Suppose have t layers f c c= ( i) t ( t ) ( t t x = z = h a = h z w ) c c c
29 Training MLP: Single Sample For derivation, we use: For weights w t p to the output layer t: w t p w J ( ) ( ( i) i ) ( ( i w = f x y f x ) y ) w t p J i w t p ( ( i) i ) ( t ) t f x y = h' a z t p Therefore, ( ) p J i ( ) ( ( i) i w = f ) c x yc i 2 m c= ( ) ( ( i) i ) ( t ) t w = f x y h' a z f c ( i) ( t ) ( t t x = h a = h z w ) t t both h' a and depend on x i z p. For simpler notation, we don t make this dependence explicit. c p 2 c
30 Training MLP: Single Sample For a layer k, compute partial derivatives w.r.t. w k p Gets complex, since have lots of function compositions Will give the rest of derivatives First define e k, the error attributed to unit in layer k: For layer t (output): For layers k < t: Thus for 2 k t: e e t k w = = k p ( ( i f x ) y ) N J i ( k+ ) c= e i h' k ( ) ( k ) k w = e h' a z ( k+ ) k a w k+ + c c c p
31 MLP Training: Multiple Samples ( ) ( ) ( ) = = = n i m c i c i c y x f w J 2 2 Error on all examples: ( ) ( ) ( ) = = m c i c i c i y x f w J 2 2 Error on one example x i : ( ) ( ) = k p k k i k p z a h' e w J w ( ) ( ) = = n i k p k k k p z a h' e w J w
32 Batch Protocol true gradient descent Training Protocols weights are updated only after all examples are processed might be very slow to train Single Sample Protocol examples are chosen randomly from the training set weights are updated after every example weighs get changed faster than batch, less stable Mini Batch Update weights after processing a batch of examples Middle ground between single sample and batch protocols Helps to prevent over-fitting in practice think of it as noisy gradient allows CPU/GPU memory hierarchy to be exploited so that it trains much faster than single-sample in terms of wall-clock time
33 MLP Training: Single Sample initialize w to small random numbers choose ε, α while α J(w) > ε for i = to n r = random index from {,2,,n} delta pk = 0 p,,k e t = ( ( r ) r f x y ) for k = t to 2 delta = delta e k pk N ( k) = e c= h' pk e w k p = w k p + delta pk p,,k k c k h' ( k ) k a w c c ( k ) k a z p
34 MLP Training: Batch initialize w to small random numbers choose ε, α while α J(w) > ε for i = to n delta pk = 0 p,,k e t = ( ( i) i f x y ) for k = t to 2 delta = delta e k pk N w k p = w k p + delta pk p,,k ( k) = e c= k c h' pk e k h' ( k ) k a w c c ( k ) k a z p
35 BackPropagation of Errors In MLP terminology, training is called backpropagation errors computed (propagated) backwards from the output to the input layer while α J(w) > ε for i = to n delta pk = 0 p,,k e t = ( r ( r y f x ) for k = t to 2 delta = delta e k pk N ( k) = e c= h' pk w k p = w k p + delta pk p,,k k c first last layer errors computed then errors computed backwards e k h' ( k ) k a w c c ( k ) k a z p
36 MLP Training Important: weights should be initialized to random nonzero numbers k ( ) ( k ) k Ji w = e k h' a zp w e k p = ( k+ ) c= ( k+ ) k a w k+ + c c c if w k c = 0, errors e k are zero for layers k < t weights in layers k < t will not be updated N e h'
37 Practical tips for BP: Weight Decay To avoid overfitting, it is recommended to keep weights small Implement weight decay after each weight update: w new = w new (-β), 0 < β < Additional benefit is that unused weights grow small and may be eliminated altogether a weight is unused if it is left almost unchanged by the backpropagation algorithm
38 Practical Tips for BP: Momentum Gradient descent finds only a local minima Momentum: popular method to avoid local minima and speed up descent in flat (plateau) regions Add temporal average direction in which weights have been moving recently Previous direction: w t =w t -w t- Weight update rule with momentum: w t+ = w t + J w t ( β) α + β w steepest descent direction previous direction
39 Practical Tips for BP: Normalization Features should be normalized for faster convergence Suppose we measure fish length in meters and weight in grams Typical sample [length = 0.5, weight = 3000] Feature length will be almost ignored If length is in fact important, learning will be very slow Any normalization we looked at before (lecture on knn) will do Test samples should be normalized exactly as the training samples
40 Practical Tips: Learning Rate As any gradient descent algorithm, backpropagation depends on the learning rate α Rule of thumb α = 0. However can adust α at the training time The obective function J(w) should decrease during gradient descent If J(w) oscillates, α is too large, decrease it If J(w) goes down but very slowly, α is too small, increase it
41 MLP Training: How long to Train? training time Large training error: random decision regions in the beginning - underfit Small training error: decision regions improve with time Zero training error: decision regions fit training data perfectly - overfit can learn when to stop training through validation
42 MLP as Non-Linear Feature Mapping x x 2 MLP can be interpreted as first mapping input features to new features Then applying Perceptron (linear classifier) to the new features
43 MLP as Non-Linear Feature Mapping y x y 2 x 2 y 3 this part implements Perceptron (liner classifier)
44 MLP as Non-Linear Feature Mapping y x y 2 x 2 y 3 this part implements mapping to new features y
45 MLP as Nonlinear Feature Mapping Consider 3 layer NN example we saw previously: x -3.5 x 2 - x 2 y 2 x y non linearly separable in the original feature space linearly separable in the new feature space
46 Shallow vs. Deep Architecture How many layers should we choose? Shallow network Deep network Deep network lead to many successful applications recently

47 Why Deep Networks 2 layer networks can represent any function But deep architectures are more efficient for representing some classes of functions problems which can be represented with a polynomial number of nodes with k layers, may require an exponential number of nodes with k- layers thus with deep architecture, less units might be needed overall less weights, less parameter updates maybe especially in image processing, with structure being mainly local Sub-features created in deep architecture can potentially be shared between multiple tasks



 Third layer: obects")
48 Why Deep Networks: Hierarchical Feature Extraction Deep architecture works well for hierarchical feature extraction hierarchies are natural, especially in vision Each stage is a trainable feature transform Level of abstraction increases with the level Input layer: pixels First layer: edges Second layer: obect parts (combination of edges) Third layer: obects (combinations of obect parts)



49 Why Deep Networks: Hierarchical Feature Extraction Another example (from M. Zeiler 203) Visualization of learned features Patches that result in high response Layer Layer 2




50 Why Deep Networks: Hierarchical Feature Extraction Visualization of learned features Patches that result in high response Layer 3 Layer 4
51 Early Work Fukushima (980) Neo-Cognitron LeCun (998) Convolutional Neural Networks Similarities to Neo-Cognitron Many layered Networks trained with backpropagation Tried early but without much success Very slow Diffusion of gradient recent work has shown significant training improvements with various tricks (drop-out, unsupervised learning of early layers, etc.)
52 Prior Knowledge for Network Architecture We can put our prior knowledge about the task into the network by designing appropriate connectivity structure weight constraints neuron activation functions This is less intrusive than hand-designing the features but it still preudices the network towards the particular way of solving the problem that we had in mind
53 Convolutional Nets Neural Networks with special type of architecture that is particularly good for image processing input image feature maps subsample feature subsample final layer maps C S Convolution layer: feature extraction Subsampling layer: shift and distortion invariance C S
54 Feature extraction or Convolution layer Use convolution (and thresholding) to detect the same feature at different image positions convolve with w w2 w2 w22 w3 w23 threshold w3 w32 w33 Recall how convolution works: neuron w w2 w3 w w2 w3 w2 w22 w23 w2 w22 w23 w3 w32 w33 w3 w32 w33 input image convolved thresholded image = feature map
55 Feature extraction Convolution masks are learned tunable parameters of the network Shared weights: all neurons in a feature share the same weights but not the biases Thus all neurons detect the same feature at different positions in the input image if a feature is useful in one image location, it should be useful in all other locations also greatly reduces the number of tunable parameters The red connections all have the same weight The red connections all have the same weight The red connections all have the same weight


56 Weight Sharing Constraints It is easy to modify backpropagation algorithm to incorporate weight sharing We compute the gradients as usual, and then modify the gradients so that they satisfy the constraints. so if the weights started off satisfying the constraints, they will continue to satisfy them

")
 feature map 4 (convolve with mask 4) feature map 5")
57 Feature extraction or Convolution layer features Use several different feature types, each with its own mask, and the resulting map of replicated detectors Allows each patch of image to be represented in several ways feature map (convolve with mask ) feature map 2 (convolve with mask 2) feature map 3 (convolve with mask 3) feature map 4 (convolve with mask 4) feature map 5 (convolve with mask 5)

58 Subsampling layers reduce spatial resolution of each feature map weighted sum This achieves certain degree of shift and distortion invariance Weight sharing is also applied in subsampling layers reduce the effect of noise and shift or distortion feature map Subsampling Layer subsampled
59 Subsampling Layer Subsampling is also called pooling Instead of subsampling, sometimes max pooling works betters replace weighted sum with max operation feature map subsampled


60 Subsampling Layer Subsampling achieves certain degree of shift and distortion invariance is



61 Subsampling Layer

62 62 Convolutional Nets
63 Problem with Subsampling (Pooling) Averaging (or taking a max) of four pixels gets a small amount of shift invariance Problem to be aware of After several levels of pooling, we have lost information about the precise positions of things This makes it impossible to use the precise spatial relationships between high-level parts for recognition.
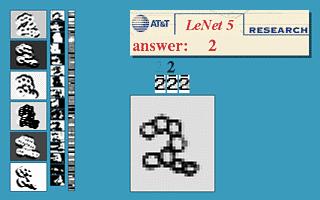
64 Le Net Yann LeCun and his collaborators developed a good recognizer for handwritten digits by using backpropagation in a convoluitonal net LeNet uses knowledge about the invariance to design local connectivity weight-sharing pooling This net was used for reading ~0% of the checks in North America Look the impressive demos of LENET at


65 Conv Nets: Character Recognition
66 ConvNet for ImageNet Krizhevsky et.al.(nips 202) developed deep convolutional neural net of the type pioneered by Yann LeCun Architecture: 7 hidden layers not counting some max pooling layers. the early layers were convolutional. the last two layers were globally connected. Activation function: rectified linear units in every hidden layer train much faster and are more expressive than logistic unit



67 ConvNet on Image Classification
68 Tricks to Improve Generalization To get more data: Use left-right reflections of the images Train on random 224x224 patches from the 256x256 images At test time: combine the opinions from ten different patches: four 224x224 corner patches plus the central 224x224 patch the reflections of those five patches Use dropout to regularize weights in the fully connected layers half of the hidden units in a layer are randomly removed for each training example This stops hidden units from relying too much on other hidden units
69 Training Deep Networks Difficulties of supervised training of deep networks Early layers of MLN do not get trained well Diffusion of Gradient error attenuates as it propagates to earlier layers Exacerbated since top couple layers can usually learn any task "pretty well" and thus the error to earlier layers drops quickly as the top layers "mostly" solve the task lower layers never get the opportunity to use their capacity to improve results, they ust do a random feature map Need a way for early layers to do effective work Often not enough labeled data available while there may be lots of unlabeled data Can we use unsupervised/semi-supervised approaches to take advantage of the unlabeled data Deep networks tend to have more local minima problems than shallow networks during supervised training
70 Greedy Layer-Wise Training Greedy layer-wise training to insure lower layers learn. Train first layer using your data without the labels (unsupervised) we do not know targets at this level anyway can use the more abundant unlabeled data which is not part of the training set 2. Freeze the first layer parameters and start training the second layer using the output of the first layer as the unsupervised input to the second layer 3. Repeat this for as many layers as desired This builds our set of robust features 4. Use the outputs of the final layer as inputs to a supervised layer/model and train the last supervised layer(s) leave early weights frozen 5. Unfreeze all weights and fine tune the full network by training with a supervised approach, given the pre-processed weight settings
71 Greedy Layer-Wise Training Greedy layer-wise training avoids many of the problems of trying to train a deep net in a supervised fashion Each layer gets full learning focus in its turn since it is the only current "top" layer Can take advantage of the unlabeled data When you finally tune the entire network with supervised training the network weights have already been adusted so that you are in a good error basin and ust need fine tuning This helps with problems of Ineffective early layer learning Deep network local minima


72 Unsupervised Learning: Auto-Encoders A type of unsupervised learning which tries to discover generic features of the data Input sample = output Learn identity function by learning important sub-features, not by ust passing through data bottleneck
73 Advantages MLP can learn complex mappings from inputs to outputs, based only on the training samples Easy to incorporate a lot of heuristics Many competitions won recently Disadvantages Concluding Remarks May be difficult to analyze and predict its behavior May take a long time to train May get trapped in a bad local minima A lot of tricks for successful implementation
CS4442/9542b Artificial Intelligence II prof. Olga Veksler. Lecture 5 Machine Learning. Neural Networks. Many presentation Ideas are due to Andrew NG
 CS4442/9542b Artificial Intelligence II prof. Olga Vesler Lecture 5 Machine Learning Neural Networs Many presentation Ideas are due to Andrew NG Outline Motivation Non linear discriminant functions Introduction
CS4442/9542b Artificial Intelligence II prof. Olga Vesler Lecture 5 Machine Learning Neural Networs Many presentation Ideas are due to Andrew NG Outline Motivation Non linear discriminant functions Introduction
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Introduction Biologically Motivated Crude Model Backpropagation
 Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
CS:4420 Artificial Intelligence
 CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Neural Networks. Historical description
 Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Deep Learning: a gentle introduction
 Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural
 learning techniques for neural") 1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ECE 471/571 - Lecture 17. Types of NN. History. Back Propagation. Recurrent (feedback during operation) Feedforward
 Feedforward") ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Introduction to Artificial Neural Networks
 Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92
 ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Introduction to Deep Learning
 Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
Lecture 4: Feed Forward Neural Networks
 Lecture 4: Feed Forward Neural Networks Dr. Roman V Belavkin Middlesex University BIS4435 Biological neurons and the brain A Model of A Single Neuron Neurons as data-driven models Neural Networks Training
Lecture 4: Feed Forward Neural Networks Dr. Roman V Belavkin Middlesex University BIS4435 Biological neurons and the brain A Model of A Single Neuron Neurons as data-driven models Neural Networks Training
Lecture 35: Optimization and Neural Nets
 Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Introduction to Neural Networks
 Introduction to Neural Networks Philipp Koehn 3 October 207 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models
Introduction to Neural Networks Philipp Koehn 3 October 207 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
CS 4700: Foundations of Artificial Intelligence Prof. Bart Selman selman@cs.cornell.edu Machine Learning: Neural Networks R&N 18.7 Intro & perceptron learning 1 2 Neuron: How the brain works # neurons
Multilayer Perceptrons (MLPs)
") CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
CSE 5526: Introduction to Neural Networks Multilayer Perceptrons (MLPs) 1 Motivation Multilayer networks are more powerful than singlelayer nets Example: XOR problem x 2 1 AND x o x 1 x 2 +1-1 o x x 1-1
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Lecture 7 Artificial neural networks: Supervised learning
 Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Introduction to Deep Learning
 Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2014 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2014 1 / 35 Outline 1 Universality of Neural Networks
Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2014 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2014 1 / 35 Outline 1 Universality of Neural Networks
Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]
![Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]](/thumbs/88/117565192.jpg "Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]") Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Supervised Learning. George Konidaris
 Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
8. Lecture Neural Networks
 Soft Control (AT 3, RMA) 8. Lecture Neural Networks Learning Process Contents of the 8 th lecture 1. Introduction of Soft Control: Definition and Limitations, Basics of Intelligent" Systems 2. Knowledge
Soft Control (AT 3, RMA) 8. Lecture Neural Networks Learning Process Contents of the 8 th lecture 1. Introduction of Soft Control: Definition and Limitations, Basics of Intelligent" Systems 2. Knowledge
Neural Networks and Fuzzy Logic Rajendra Dept.of CSE ASCET
 Unit-. Definition Neural network is a massively parallel distributed processing system, made of highly inter-connected neural computing elements that have the ability to learn and thereby acquire knowledge
Unit-. Definition Neural network is a massively parallel distributed processing system, made of highly inter-connected neural computing elements that have the ability to learn and thereby acquire knowledge
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Introduction to Deep Learning
 Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Multilayer Perceptrons and Backpropagation
 Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Artificial Neural Networks 2
 CSC2515 Machine Learning Sam Roweis Artificial Neural s 2 We saw neural nets for classification. Same idea for regression. ANNs are just adaptive basis regression machines of the form: y k = j w kj σ(b
CSC2515 Machine Learning Sam Roweis Artificial Neural s 2 We saw neural nets for classification. Same idea for regression. ANNs are just adaptive basis regression machines of the form: y k = j w kj σ(b
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning
 LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning") CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Multilayer Neural Networks
 Pattern Recognition Lecture 4 Multilayer Neural Netors Prof. Daniel Yeung School of Computer Science and Engineering South China University of Technology Lec4: Multilayer Neural Netors Outline Introduction
Pattern Recognition Lecture 4 Multilayer Neural Netors Prof. Daniel Yeung School of Computer Science and Engineering South China University of Technology Lec4: Multilayer Neural Netors Outline Introduction
Chapter 9: The Perceptron
 Chapter 9: The Perceptron 9.1 INTRODUCTION At this point in the book, we have completed all of the exercises that we are going to do with the James program. These exercises have shown that distributed
Chapter 9: The Perceptron 9.1 INTRODUCTION At this point in the book, we have completed all of the exercises that we are going to do with the James program. These exercises have shown that distributed
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
Neural Networks Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav
 Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Artificial Neural Networks. Q550: Models in Cognitive Science Lecture 5
 Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Artificial neural networks
 Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Introduction to Machine Learning (67577)
") Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Neural Networks. Xiaojin Zhu Computer Sciences Department University of Wisconsin, Madison. slide 1
 Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not