Overview of gradient descent optimization algorithms. HYUNG IL KOO Based on
|
|
|
- Iris Matthews
- 6 years ago
- Views:
Transcription
1 Overview of gradient descent optimization algorithms HYUNG IL KOO Based on
2 Problem Statement Machine Learning Optimization Problem Training samples: x i, y i Cost function: J(θ; X; Y) = i d(f(x (i) ; θ), y (i) ) θ = arg min θ J(θ; X; Y)
 parameterized by a model's parameters θ R d by updating the parameters in the opposite direction of the gradient of the objective function θ J(θ) with respect to the")
3 Optimization method Gradient Descent The most common way to optimize neural networks Deep learning library contains implementations of various gradient descent algorithms To minimize an objective function J(θ) parameterized by a model's parameters θ R d by updating the parameters in the opposite direction of the gradient of the objective function θ J(θ) with respect to the parameters.
4 CONTENTS
5 Gradient descent variants Batch gradient descent Stochastic gradient descent Mini-batch gradient descent Challenges
6 Gradient descent optimization algorithms Momentum Adaptive Gradient Visualization Which optimizer to choose? Additional strategies for optimizing SGD Shuffling and Curriculum Learning Batch normalization
7 GRADIENT DESCENT VARIANTS
8 Batch gradient descent Computes the gradient of the cost function w.r.t. θ for the entire training dataset: θ new = θ old η θ J(θ; X; Y) Properties Very slow Intractable for datasets that don't fit in memory No online learning
9 Stochastic Gradient descent (SGD) To perform a parameter update for each training example x (i) and label y (i) θ new = θ old η θ J(θ; x i ; y (i) ) Properties: Faster Online learning Heavy fluctuation Capability to jump to new (potentially better local minima) Complicated convergence (overshooting)
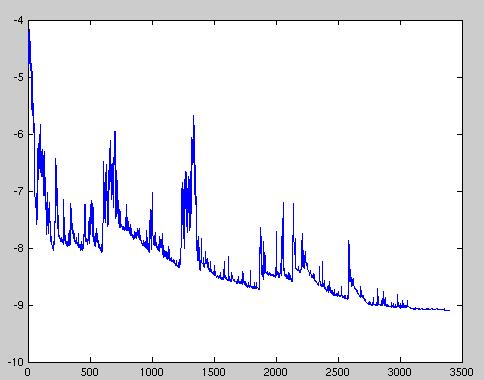
10 SGD fluctuation

11 Batch Gradient vs SGD Batch gradient It converges to the minimum of the basin the parameters are placed in. Stochastic gradient descent It is able to jump to new and potentially better local minima. This complicates convergence to the exact minimum, as SGD will keep overshooting

12 Mini-batch (stochastic) gradient descent To perform an update for every mini-batch of n training examples: θ new = θ old η θ J(θ; x i:i+n ; y (i:i+n) )
13 Properties of mini-batch gradient descent Compared with SGD It reduces the variance of the parameter updates, which can lead to more stable convergence; It can make use of highly optimized matrix optimizations common to state-of-the-art deep learning libraries that make computing the gradient w.r.t. a mini-batch very efficient Mini-batch gradient descent is typically the algorithm of choice when training a neural network and the term SGD usually is employed also when mini-batches are used.
14 CHALLENGES
15 Challenges Choosing a proper learning rate can be difficult. Small learning rate leads to painfully slow convergence Large learning rate can hinder convergence and cause the loss function to fluctuate around the minimum or even to diverge Learning rate schedules and thresholds It has to be defined in advance and unable to adapt to a dataset's characteristics. Same learning rate applies to all parameter updates. If our data is sparse and our features have very different frequencies, we might not want to update all of them to the same extent, but perform a larger update for rarely occurring features.

16 Challenges Avoiding getting trapped in their numerous suboptimal local minima and saddle points Dauphin et al. argue that the difficulty arises in fact not from local minima but from saddle points. These saddle points are usually surrounded by a plateau of the same error, which makes it notoriously hard for SGD to escape, as the gradient is close to zero in all dimensions.
17 MOMENTUM
18 Momentum One of the main limitations of gradient descent) is local minima When the gradient descent algorithm reaches a local minimum, the gradient becomes zero and the weights converge to a sub-optimal solution A very popular method to avoid local minima is to compute a temporal average direction in which the weights have been moving recently An easy way to implement this is by using an exponential average v t = γv t 1 + η θ J(θ) θ new = θ old v t The term γ is called the momentum The momentum has a value between 0 and 1 (typically 0.9) Properties Fast convergence Less oscillation
.")
19 Momentum Essentially, when using momentum, we push a ball down a hill. The ball accumulates momentum as it rolls downhill, becoming faster and faster on the way (until it reaches its terminal velocity if there is air resistance). The same thing happens to our parameter updates: The momentum term increases for dimensions whose gradients point in the same directions and reduces updates for dimensions whose gradients change directions. As a result, we gain faster convergence and reduced oscillation.

20 Momentum The momentum term is also useful in spaces with long ravines characterized by sharp curvature across the ravine and a gently sloping floor Sharp curvature tends to cause divergent oscillations across the ravine To avoid this problem, we could decrease the learning rate, but this is too slow The momentum term filters out the high curvature and allows the effective weight steps to be bigger It turns out that ravines are not uncommon in optimization problems, so the use of momentum can be helpful in many situations However, a momentum term can hurt when the search is close to the minima (think of the error surface as a bowl) As the network approaches the bottom of the error surface, it builds enough momentum to propel the weights in the opposite direction, creating an undesirable oscillation that results in slower convergence

21 Smarter Ball?
22 NGD (Nesterov accelerated gradient) Nesterov accelerated gradient improved on the basis of Momentum algorithm Approximation of the next position of the parameters. v t = γv t 1 + η θ J(θ γv t 1 ). θ new = θ old v t
23 ADAPTIVE GRADIENTS
24 Adaptive Gradient Methods Let us adapt the learning rate of each parameter, performing larger updates for infrequent and smaller updates for frequent parameters. Methods AdaGrad (Adaptive Gradient Method) AdaDelta RMSProp (Root Mean Square Propagation) Adam (Adaptive Moment Estimation)
25 Adaptive Gradient Methods These methods use a different learning rate for each parameter θ i R at every time step t. For brevity, we set g i (t) to be the gradient of the objective function w.r.t. θ i R at time step t: θ i (t+1) = θi (t) η gi (t) These methods modify the learning rate η at each time step (t) for every parameter θ i based on the past gradients that have been computed for θ i.
26 Adagrad Adagrad modifies the general learning rate η at each time step t for every parameter θ i based on the past gradients that have been computed for θ i : (t+1) (t) η θ i = θi G t,i + ε g t,i G t,i = k t g i k 2 g i (k) = J(θ) θ i θ (k)
27 Adagrad Pros It eliminates the need to manually tune the learning rate. Most implementations use a default value of Cons Its accumulation of the squared gradients in the denominator: the accumulated sum keeps growing during training. This causes the learning rate to shrink and eventually become infinitesimally small. The following algorithms aim to resolve this flaw.
28 RMSprop RMSprop has been developed to resolve Adagrad's diminishing learning rates. λ t,i = γ λ t 1,i + 1 γ 2 t g i (t+1) (t) η θ i = θi λ t,i + ε g t,i η : Learning rate is suggest to set to γ : Fixed momentum term
29 Adam (Adaptive moment Estimation) Adam keeps an exponentially decaying average of past gradients m t, similar to momentum. m t,i = β 1 m t 1,i + (1 β 1 )g i t v t,i = β 2 v t 1,i + 1 β 2 They counteract these biases by computing bias-corrected first and second moment estimates. m t,i = m t,i v t,i = v t,i 1 β 1 1 β 2 g i t 2 m t : Estimate of the first moment(the mean) v t : Estimate of the second moment (the un-centered variance) β 1 : suggest to set to 0.9 β 2 : suggest to set to which yields the Adam update rule. θ i (t+1) = θi (t) η v t + ε m t,i ε : suggest to set to 10 8
30 COMPARISON

31 Visualization of algorithms
32 Which optimizer to choose? RMSprop is an extension of Adagrad that deals with its radically diminishing learning rates. Adam slightly outperform RMSprop towards the end of optimization as gradients become sparser.
33 CONCLUSION
34 Conclusion Three variants of gradient descent, among which mini-batch gradient descent is the most popular.
Machine Learning CS 4900/5900. Lecture 03. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
CSC321 Lecture 8: Optimization
 CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
Optimization for neural networks
 0 - : Optimization for neural networks Prof. J.C. Kao, UCLA Optimization for neural networks We previously introduced the principle of gradient descent. Now we will discuss specific modifications we make
0 - : Optimization for neural networks Prof. J.C. Kao, UCLA Optimization for neural networks We previously introduced the principle of gradient descent. Now we will discuss specific modifications we make
CSC321 Lecture 7: Optimization
 CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
Optimization for Training I. First-Order Methods Training algorithm
 Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent
 CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Stochastic Gradient Descent
 Stochastic Gradient Descent Weihang Chen, Xingchen Chen, Jinxiu Liang, Cheng Xu, Zehao Chen and Donglin He March 26, 2017 Outline What is Stochastic Gradient Descent Comparison between BGD and SGD Analysis
Stochastic Gradient Descent Weihang Chen, Xingchen Chen, Jinxiu Liang, Cheng Xu, Zehao Chen and Donglin He March 26, 2017 Outline What is Stochastic Gradient Descent Comparison between BGD and SGD Analysis
CS260: Machine Learning Algorithms
 CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
Tutorial on: Optimization I. (from a deep learning perspective) Jimmy Ba
 Jimmy Ba") Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Deep Learning II: Momentum & Adaptive Step Size
 Deep Learning II: Momentum & Adaptive Step Size CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following
Deep Learning II: Momentum & Adaptive Step Size CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following
Deep Learning & Artificial Intelligence WS 2018/2019
 Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Adam: A Method for Stochastic Optimization
 Adam: A Method for Stochastic Optimization Diederik P. Kingma, Jimmy Ba Presented by Content Background Supervised ML theory and the importance of optimum finding Gradient descent and its variants Limitations
Adam: A Method for Stochastic Optimization Diederik P. Kingma, Jimmy Ba Presented by Content Background Supervised ML theory and the importance of optimum finding Gradient descent and its variants Limitations
Lecture 6 Optimization for Deep Neural Networks
 Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Gradient Descent. Sargur Srihari
 Gradient Descent Sargur srihari@cedar.buffalo.edu 1 Topics Simple Gradient Descent/Ascent Difficulties with Simple Gradient Descent Line Search Brent s Method Conjugate Gradient Descent Weight vectors
Gradient Descent Sargur srihari@cedar.buffalo.edu 1 Topics Simple Gradient Descent/Ascent Difficulties with Simple Gradient Descent Line Search Brent s Method Conjugate Gradient Descent Weight vectors
ECE521 lecture 4: 19 January Optimization, MLE, regularization
 ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
OPTIMIZATION METHODS IN DEEP LEARNING
 Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Regularization and Optimization of Backpropagation
 Regularization and Optimization of Backpropagation The Norwegian University of Science and Technology (NTNU) Trondheim, Norway keithd@idi.ntnu.no October 17, 2017 Regularization Definition of Regularization
Regularization and Optimization of Backpropagation The Norwegian University of Science and Technology (NTNU) Trondheim, Norway keithd@idi.ntnu.no October 17, 2017 Regularization Definition of Regularization
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN)
") EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
Non-Linearity. CS 188: Artificial Intelligence. Non-Linear Separators. Non-Linear Separators. Deep Learning I
 Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Adaptive Gradient Methods AdaGrad / Adam
 Case Study 1: Estimating Click Probabilities Adaptive Gradient Methods AdaGrad / Adam Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade 1 The Problem with GD (and SGD)
Case Study 1: Estimating Click Probabilities Adaptive Gradient Methods AdaGrad / Adam Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade 1 The Problem with GD (and SGD)
Neural Networks: Optimization & Regularization
 Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Adaptive Gradient Methods AdaGrad / Adam. Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade
 Adaptive Gradient Methods AdaGrad / Adam Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade 1 Announcements: HW3 posted Dual coordinate ascent (some review of SGD and random
Adaptive Gradient Methods AdaGrad / Adam Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade 1 Announcements: HW3 posted Dual coordinate ascent (some review of SGD and random
Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates
 Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates Hiroaki Hayashi 1,* Jayanth Koushik 1,* Graham Neubig 1 arxiv:1611.01505v3 [cs.lg] 11 Jun 2018 Abstract Adaptive
Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates Hiroaki Hayashi 1,* Jayanth Koushik 1,* Graham Neubig 1 arxiv:1611.01505v3 [cs.lg] 11 Jun 2018 Abstract Adaptive
CSC2541 Lecture 5 Natural Gradient
 CSC2541 Lecture 5 Natural Gradient Roger Grosse Roger Grosse CSC2541 Lecture 5 Natural Gradient 1 / 12 Motivation Two classes of optimization procedures used throughout ML (stochastic) gradient descent,
CSC2541 Lecture 5 Natural Gradient Roger Grosse Roger Grosse CSC2541 Lecture 5 Natural Gradient 1 / 12 Motivation Two classes of optimization procedures used throughout ML (stochastic) gradient descent,
Large-scale Stochastic Optimization
 Large-scale Stochastic Optimization 11-741/641/441 (Spring 2016) Hanxiao Liu hanxiaol@cs.cmu.edu March 24, 2016 1 / 22 Outline 1. Gradient Descent (GD) 2. Stochastic Gradient Descent (SGD) Formulation
Large-scale Stochastic Optimization 11-741/641/441 (Spring 2016) Hanxiao Liu hanxiaol@cs.cmu.edu March 24, 2016 1 / 22 Outline 1. Gradient Descent (GD) 2. Stochastic Gradient Descent (SGD) Formulation
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Rapid Introduction to Machine Learning/ Deep Learning
 Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/59 Lecture 4a Feedforward neural network October 30, 2015 2/59 Table of contents 1 1. Objectives of Lecture
Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/59 Lecture 4a Feedforward neural network October 30, 2015 2/59 Table of contents 1 1. Objectives of Lecture
Nonlinear Optimization Methods for Machine Learning
 Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
More Tips for Training Neural Network. Hung-yi Lee
 More Tips for Training Neural Network Hung-yi ee Outline Activation Function Cost Function Data Preprocessing Training Generalization Review: Training Neural Network Neural network: f ; θ : input (vector)
More Tips for Training Neural Network Hung-yi ee Outline Activation Function Cost Function Data Preprocessing Training Generalization Review: Training Neural Network Neural network: f ; θ : input (vector)
Optimizing CNNs. Timothy Dozat Stanford. Abstract. 1. Introduction. 2. Background Momentum
 Optimizing CNNs Timothy Dozat Stanford tdozat@stanford.edu Abstract This work aims to explore the performance of a popular class of related optimization algorithms in the context of convolutional neural
Optimizing CNNs Timothy Dozat Stanford tdozat@stanford.edu Abstract This work aims to explore the performance of a popular class of related optimization algorithms in the context of convolutional neural
Advanced Training Techniques. Prajit Ramachandran
 Advanced Training Techniques Prajit Ramachandran Outline Optimization Regularization Initialization Optimization Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise
Advanced Training Techniques Prajit Ramachandran Outline Optimization Regularization Initialization Optimization Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise
Non-convex optimization. Issam Laradji
 Non-convex optimization Issam Laradji Strongly Convex Objective function f(x) x Strongly Convex Objective function Assumptions Gradient Lipschitz continuous f(x) Strongly convex x Strongly Convex Objective
Non-convex optimization Issam Laradji Strongly Convex Objective function f(x) x Strongly Convex Objective function Assumptions Gradient Lipschitz continuous f(x) Strongly convex x Strongly Convex Objective
Speaker Representation and Verification Part II. by Vasileios Vasilakakis
 Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Machine Learning Basics: Stochastic Gradient Descent. Sargur N. Srihari
 Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Don t Decay the Learning Rate, Increase the Batch Size. Samuel L. Smith, Pieter-Jan Kindermans, Quoc V. Le December 9 th 2017
 Don t Decay the Learning Rate, Increase the Batch Size Samuel L. Smith, Pieter-Jan Kindermans, Quoc V. Le December 9 th 2017 slsmith@ Google Brain Three related questions: What properties control generalization?
Don t Decay the Learning Rate, Increase the Batch Size Samuel L. Smith, Pieter-Jan Kindermans, Quoc V. Le December 9 th 2017 slsmith@ Google Brain Three related questions: What properties control generalization?
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation
 Computational Graphs, Learning Algorithms, Initialisation") Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Logistic Regression. Stochastic Gradient Descent
 Tutorial 8 CPSC 340 Logistic Regression Stochastic Gradient Descent Logistic Regression Model A discriminative probabilistic model for classification e.g. spam filtering Let x R d be input and y { 1, 1}
Tutorial 8 CPSC 340 Logistic Regression Stochastic Gradient Descent Logistic Regression Model A discriminative probabilistic model for classification e.g. spam filtering Let x R d be input and y { 1, 1}
Optimization Methods for Machine Learning
 Optimization Methods for Machine Learning Sathiya Keerthi Microsoft Talks given at UC Santa Cruz February 21-23, 2017 The slides for the talks will be made available at: http://www.keerthis.com/ Introduction
Optimization Methods for Machine Learning Sathiya Keerthi Microsoft Talks given at UC Santa Cruz February 21-23, 2017 The slides for the talks will be made available at: http://www.keerthis.com/ Introduction
Normalization Techniques in Training of Deep Neural Networks
 Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
Stochastic Gradient Descent. CS 584: Big Data Analytics
 Stochastic Gradient Descent CS 584: Big Data Analytics Gradient Descent Recap Simplest and extremely popular Main Idea: take a step proportional to the negative of the gradient Easy to implement Each iteration
Stochastic Gradient Descent CS 584: Big Data Analytics Gradient Descent Recap Simplest and extremely popular Main Idea: take a step proportional to the negative of the gradient Easy to implement Each iteration
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
IMPROVING STOCHASTIC GRADIENT DESCENT
 IMPROVING STOCHASTIC GRADIENT DESCENT WITH FEEDBACK Jayanth Koushik & Hiroaki Hayashi Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213, USA {jkoushik,hiroakih}@cs.cmu.edu
IMPROVING STOCHASTIC GRADIENT DESCENT WITH FEEDBACK Jayanth Koushik & Hiroaki Hayashi Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213, USA {jkoushik,hiroakih}@cs.cmu.edu
Understanding Neural Networks : Part I
 TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Deep Learning. Authors: I. Goodfellow, Y. Bengio, A. Courville. Chapter 4: Numerical Computation. Lecture slides edited by C. Yim. C.
 Chapter 4: Numerical Computation Deep Learning Authors: I. Goodfellow, Y. Bengio, A. Courville Lecture slides edited by 1 Chapter 4: Numerical Computation 4.1 Overflow and Underflow 4.2 Poor Conditioning
Chapter 4: Numerical Computation Deep Learning Authors: I. Goodfellow, Y. Bengio, A. Courville Lecture slides edited by 1 Chapter 4: Numerical Computation 4.1 Overflow and Underflow 4.2 Poor Conditioning
Modern Stochastic Methods. Ryan Tibshirani (notes by Sashank Reddi and Ryan Tibshirani) Convex Optimization
 Convex Optimization") Modern Stochastic Methods Ryan Tibshirani (notes by Sashank Reddi and Ryan Tibshirani) Convex Optimization 10-725 Last time: conditional gradient method For the problem min x f(x) subject to x C where
Modern Stochastic Methods Ryan Tibshirani (notes by Sashank Reddi and Ryan Tibshirani) Convex Optimization 10-725 Last time: conditional gradient method For the problem min x f(x) subject to x C where
Comparison of Modern Stochastic Optimization Algorithms
 Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
An Introduction to Optimization Methods in Deep Learning. Yuan YAO HKUST
 1 An Introduction to Optimization Methods in Deep Learning Yuan YAO HKUST Acknowledgement Feifei Li, Stanford cs231n Ruder, Sebastian (2016). An overview of gradient descent optimization algorithms. arxiv:1609.04747.
1 An Introduction to Optimization Methods in Deep Learning Yuan YAO HKUST Acknowledgement Feifei Li, Stanford cs231n Ruder, Sebastian (2016). An overview of gradient descent optimization algorithms. arxiv:1609.04747.
Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization
 Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization Changyou Chen, David Carlson, Zhe Gan, Chunyuan Li, Lawrence Carin May 2, 2016 1 Changyou Chen Bridging the Gap between Stochastic
Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization Changyou Chen, David Carlson, Zhe Gan, Chunyuan Li, Lawrence Carin May 2, 2016 1 Changyou Chen Bridging the Gap between Stochastic
Simple Techniques for Improving SGD. CS6787 Lecture 2 Fall 2017
 Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Notes on AdaGrad. Joseph Perla 2014
 Notes on AdaGrad Joseph Perla 2014 1 Introduction Stochastic Gradient Descent (SGD) is a common online learning algorithm for optimizing convex (and often non-convex) functions in machine learning today.
Notes on AdaGrad Joseph Perla 2014 1 Introduction Stochastic Gradient Descent (SGD) is a common online learning algorithm for optimizing convex (and often non-convex) functions in machine learning today.
Non-Convex Optimization in Machine Learning. Jan Mrkos AIC
 Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Accelerating Stochastic Optimization
 Accelerating Stochastic Optimization Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem and Mobileye Master Class at Tel-Aviv, Tel-Aviv University, November 2014 Shalev-Shwartz
Accelerating Stochastic Optimization Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem and Mobileye Master Class at Tel-Aviv, Tel-Aviv University, November 2014 Shalev-Shwartz
Learning with Momentum, Conjugate Gradient Learning
 Learning with Momentum, Conjugate Gradient Learning Introduction to Neural Networks : Lecture 8 John A. Bullinaria, 2004 1. Visualising Learning 2. Learning with Momentum 3. Learning with Line Searches
Learning with Momentum, Conjugate Gradient Learning Introduction to Neural Networks : Lecture 8 John A. Bullinaria, 2004 1. Visualising Learning 2. Learning with Momentum 3. Learning with Line Searches
Nostalgic Adam: Weighing more of the past gradients when designing the adaptive learning rate
 Nostalgic Adam: Weighing more of the past gradients when designing the adaptive learning rate Haiwen Huang School of Mathematical Sciences Peking University, Beijing, 100871 smshhw@pku.edu.cn Chang Wang
Nostalgic Adam: Weighing more of the past gradients when designing the adaptive learning rate Haiwen Huang School of Mathematical Sciences Peking University, Beijing, 100871 smshhw@pku.edu.cn Chang Wang
Mini-Course 1: SGD Escapes Saddle Points
 Mini-Course 1: SGD Escapes Saddle Points Yang Yuan Computer Science Department Cornell University Gradient Descent (GD) Task: min x f (x) GD does iterative updates x t+1 = x t η t f (x t ) Gradient Descent
Mini-Course 1: SGD Escapes Saddle Points Yang Yuan Computer Science Department Cornell University Gradient Descent (GD) Task: min x f (x) GD does iterative updates x t+1 = x t η t f (x t ) Gradient Descent
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Non-Convex Optimization. CS6787 Lecture 7 Fall 2017
 Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Computational Photography
 Computational Photography Si Lu Spring 2018 http://web.cecs.pdx.edu/~lusi/cs510/cs510_computati onal_photography.htm 05/29/2018 Last Time o 3D Video Stabilization 2 Introduction of Neural Networks 3 Content
Computational Photography Si Lu Spring 2018 http://web.cecs.pdx.edu/~lusi/cs510/cs510_computati onal_photography.htm 05/29/2018 Last Time o 3D Video Stabilization 2 Introduction of Neural Networks 3 Content
2015 Todd Neller. A.I.M.A. text figures 1995 Prentice Hall. Used by permission. Neural Networks. Todd W. Neller
 2015 Todd Neller. A.I.M.A. text figures 1995 Prentice Hall. Used by permission. Neural Networks Todd W. Neller Machine Learning Learning is such an important part of what we consider "intelligence" that
2015 Todd Neller. A.I.M.A. text figures 1995 Prentice Hall. Used by permission. Neural Networks Todd W. Neller Machine Learning Learning is such an important part of what we consider "intelligence" that
GRADIENT DESCENT. CSE 559A: Computer Vision GRADIENT DESCENT GRADIENT DESCENT [0, 1] Pr(y = 1) w T x. 1 f (x; θ) = 1 f (x; θ) = exp( w T x)
![GRADIENT DESCENT. CSE 559A: Computer Vision GRADIENT DESCENT GRADIENT DESCENT [0, 1] Pr(y = 1) w T x. 1 f (x; θ) = 1 f (x; θ) = exp( w T x)](/thumbs/81/84408888.jpg "GRADIENT DESCENT. CSE 559A: Computer Vision GRADIENT DESCENT GRADIENT DESCENT [0, 1] Pr(y = 1) w T x. 1 f (x; θ) = 1 f (x; θ) = exp( w T x)") 0 x x x CSE 559A: Computer Vision For Binary Classification: [0, ] f (x; ) = σ( x) = exp( x) + exp( x) Output is interpreted as probability Pr(y = ) x are the log-odds. Fall 207: -R: :30-pm @ Lopata 0
0 x x x CSE 559A: Computer Vision For Binary Classification: [0, ] f (x; ) = σ( x) = exp( x) + exp( x) Output is interpreted as probability Pr(y = ) x are the log-odds. Fall 207: -R: :30-pm @ Lopata 0
Optimization and Gradient Descent
 Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
IFT Lecture 6 Nesterov s Accelerated Gradient, Stochastic Gradient Descent
 IFT 6085 - Lecture 6 Nesterov s Accelerated Gradient, Stochastic Gradient Descent This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s):
IFT 6085 - Lecture 6 Nesterov s Accelerated Gradient, Stochastic Gradient Descent This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s):
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Least Mean Squares Regression
 Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
Lecture 3: Deep Learning Optimizations
 Lecture 3: Deep Learning Optimizations Deep Learning @ UvA UVA DEEP LEARNING COURSE EFSTRATIOS GAVVES DEEP LEARNING OPTIMIZATIONS - 1 Lecture overview o How to define our model and optimize it in practice
Lecture 3: Deep Learning Optimizations Deep Learning @ UvA UVA DEEP LEARNING COURSE EFSTRATIOS GAVVES DEEP LEARNING OPTIMIZATIONS - 1 Lecture overview o How to define our model and optimize it in practice
Unraveling the mysteries of stochastic gradient descent on deep neural networks
 Unraveling the mysteries of stochastic gradient descent on deep neural networks Pratik Chaudhari UCLA VISION LAB 1 The question measures disagreement of predictions with ground truth Cat Dog... x = argmin
Unraveling the mysteries of stochastic gradient descent on deep neural networks Pratik Chaudhari UCLA VISION LAB 1 The question measures disagreement of predictions with ground truth Cat Dog... x = argmin
Stochastic Analogues to Deterministic Optimizers
 Stochastic Analogues to Deterministic Optimizers ISMP 2018 Bordeaux, France Vivak Patel Presented by: Mihai Anitescu July 6, 2018 1 Apology I apologize for not being here to give this talk myself. I injured
Stochastic Analogues to Deterministic Optimizers ISMP 2018 Bordeaux, France Vivak Patel Presented by: Mihai Anitescu July 6, 2018 1 Apology I apologize for not being here to give this talk myself. I injured
Stochastic Gradient Descent. Ryan Tibshirani Convex Optimization
 Stochastic Gradient Descent Ryan Tibshirani Convex Optimization 10-725 Last time: proximal gradient descent Consider the problem min x g(x) + h(x) with g, h convex, g differentiable, and h simple in so
Stochastic Gradient Descent Ryan Tibshirani Convex Optimization 10-725 Last time: proximal gradient descent Consider the problem min x g(x) + h(x) with g, h convex, g differentiable, and h simple in so
Variational Autoencoders
 Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Neural Networks: Optimization Part 2. Intro to Deep Learning, Fall 2017
 Neural Networks: Optimization Part 2 Intro to Deep Learning, Fall 2017 Quiz 3 Quiz 3 Which of the following are necessary conditions for a value x to be a local minimum of a twice differentiable function
Neural Networks: Optimization Part 2 Intro to Deep Learning, Fall 2017 Quiz 3 Quiz 3 Which of the following are necessary conditions for a value x to be a local minimum of a twice differentiable function
Why should you care about the solution strategies?
 Optimization Why should you care about the solution strategies? Understanding the optimization approaches behind the algorithms makes you more effectively choose which algorithm to run Understanding the
Optimization Why should you care about the solution strategies? Understanding the optimization approaches behind the algorithms makes you more effectively choose which algorithm to run Understanding the
CPSC 340: Machine Learning and Data Mining. Stochastic Gradient Fall 2017
 CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
LECTURE # - NEURAL COMPUTATION, Feb 04, Linear Regression. x 1 θ 1 output... θ M x M. Assumes a functional form
 LECTURE # - EURAL COPUTATIO, Feb 4, 4 Linear Regression Assumes a functional form f (, θ) = θ θ θ K θ (Eq) where = (,, ) are the attributes and θ = (θ, θ, θ ) are the function parameters Eample: f (, θ)
LECTURE # - EURAL COPUTATIO, Feb 4, 4 Linear Regression Assumes a functional form f (, θ) = θ θ θ K θ (Eq) where = (,, ) are the attributes and θ = (θ, θ, θ ) are the function parameters Eample: f (, θ)
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
More Optimization. Optimization Methods. Methods
 More More Optimization Optimization Methods Methods Yann YannLeCun LeCun Courant CourantInstitute Institute http://yann.lecun.com http://yann.lecun.com (almost) (almost) everything everything you've you've
More More Optimization Optimization Methods Methods Yann YannLeCun LeCun Courant CourantInstitute Institute http://yann.lecun.com http://yann.lecun.com (almost) (almost) everything everything you've you've
Deep Learning Lecture 2
 Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Stable Adaptive Momentum for Rapid Online Learning in Nonlinear Systems
 Stable Adaptive Momentum for Rapid Online Learning in Nonlinear Systems Thore Graepel and Nicol N. Schraudolph Institute of Computational Science ETH Zürich, Switzerland {graepel,schraudo}@inf.ethz.ch
Stable Adaptive Momentum for Rapid Online Learning in Nonlinear Systems Thore Graepel and Nicol N. Schraudolph Institute of Computational Science ETH Zürich, Switzerland {graepel,schraudo}@inf.ethz.ch
Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
 Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima J. Nocedal with N. Keskar Northwestern University D. Mudigere INTEL P. Tang INTEL M. Smelyanskiy INTEL 1 Initial Remarks SGD
Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima J. Nocedal with N. Keskar Northwestern University D. Mudigere INTEL P. Tang INTEL M. Smelyanskiy INTEL 1 Initial Remarks SGD
Linear Regression 1 / 25. Karl Stratos. June 18, 2018
 Linear Regression Karl Stratos June 18, 2018 1 / 25 The Regression Problem Problem. Find a desired input-output mapping f : X R where the output is a real value. x = = y = 0.1 How much should I turn my
Linear Regression Karl Stratos June 18, 2018 1 / 25 The Regression Problem Problem. Find a desired input-output mapping f : X R where the output is a real value. x = = y = 0.1 How much should I turn my
Reinforcement. Function Approximation. Learning with KATJA HOFMANN. Researcher, MSR Cambridge
 Reinforcement Learning with Function Approximation KATJA HOFMANN Researcher, MSR Cambridge Representation and Generalization in RL Focus on training stability Learning generalizable value functions Navigating
Reinforcement Learning with Function Approximation KATJA HOFMANN Researcher, MSR Cambridge Representation and Generalization in RL Focus on training stability Learning generalizable value functions Navigating
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Machine Learning. Lecture 2: Linear regression. Feng Li. https://funglee.github.io
 Machine Learning Lecture 2: Linear regression Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2017 Supervised Learning Regression: Predict
Machine Learning Lecture 2: Linear regression Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2017 Supervised Learning Regression: Predict