Computational statistics
|
|
|
- Terence Mathews
- 5 years ago
- Views:
Transcription
1 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016
2 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial intelligence based on essentially identical models The central idea is to extract linear combinations of the inputs as derived features, and then model the target as a nonlinear function of these features The result is a powerful learning method, with widespread applications in many fields There exist many neural network models. Here we describe the most widely used vanilla neural net, sometimes called the single hidden layer back-propagation network, or single layer perceptron
3 Overview Neural network model Learning Practical issues Examples Simulated data Example in R
4 Multi-layer architecture A neural network is a two-stage regression or classification model, typically represented by a network diagram as in the next slide It is composed of three layers: input, hidden and output This network applies both to regression or classification For regression, typically K = 1 and there is only one output unit Y 1 at the top. However, these networks can handle multiple quantitative responses in a seamless fashion, so we will deal with the general case For K-class classification, there are K units at the top, with the kth unit modeling the probability of class k. There are K target values Y k, k = 1,..., K, each being coded as a 0 1 variable for the kth class
5 Graphical representation
6 Propagation equations Derived features Z m are created from linear combinations of the inputs, and then the target Y k is modeled as a function of linear combinations of the Z m : Z m = σ(α 0m + α T mx ), m = 1,..., M, T k = β 0k + βk T Z, k = 1,..., K, f k (X ) = g k (T ), k = 1,..., K where Z = (Z 1, Z 2,..., Z M ), and T = (T 1, T 2,..., T K ) Terminology α mj : connection weight between input unit j and hidden unit m β km : connection weight between hidden unit m and output unit k α 0m, β 0k : bias terms σ: hidden unit activation function g k : output activation functions
7 Activation function The activation function σ(v) is usually chosen to be the sigmoid (see next slide) σ(v) = e v Variant: sometimes the output of hidden unit m is defined using a Gaussian radial basis function as Z m = exp( γ m X α m 2 ) We then have a radial basis function network
8 Sigmoid activation function Plot of σ(sv) as a function of v for s = 0.5 (blue curve), s = 1 (red curve) and s = 10 (purple curve). The scale parameter s controls the activation rate
9 Output function The output function g k (T ) allows a final transformation of the vector of outputs T For regression we typically choose the identity function g k (T ) = T k Early work in K-class classification also used the identity function, but this was later abandoned in favor of the softmax function g k (T ) = exp(t k ) K l=1 exp(t l) This is exactly the transformation used in the multi-class logistic regression model; it produces positive estimates that sum to one
10 Why neural networks? The name neural networks derives from the fact that they were first developed as models for the human brain Each unit represents a neuron, and the connections represent synapses In early models, the neurons fired when the total signal passed to that unit exceeded a certain threshold In the model above, this corresponds to use of a step function for σ(z) and g k (T ) Later the neural network was recognized as a useful tool for nonlinear statistical modeling, and for this purpose the step function is not smooth enough for optimization. Hence, the step function was replaced by the smoother sigmoid function
11 Overview Neural network model Learning Practical issues Examples Simulated data Example in R
12 Learning problem The neural network model has unknown parameters, often called weights, and we seek values for them that make the model fit the training data well We denote the complete set of weights by θ, which consists of M(p + 1) hidden layer weights {α 0m, α m ; m = 1, 2,..., M} K(M + 1) output layer weights {β 0k, β k ; k = 1, 2,..., K} To train a neural network, we need a measure of fit, or error function
13 Error functions For regression, we use sum-of-squared errors R(θ) = n K (y ik f k (x i )) 2 i=1 k=1 For classification we use either squared error or cross-entropy (deviance) n K R(θ) = y ik log f k (x i ) i=1 k=1 and the corresponding classifier is G(x) = arg max k f k (x) With the softmax activation function and the cross-entropy error function, the neural network model is exactly a linear logistic regression model in the hidden units, and all the parameters are estimated by maximum likelihood
14 Back-propagation algorithm Principle The generic approach to minimizing R(θ) is by gradient descent, called back-propagation in this setting Because of the compositional form of the model, the gradient can be easily derived using the chain rule for differentiation This can be computed by a forward and backward sweep over the network, keeping track only of quantities local to each unit
15 Back-propagation algorithm Gradient calculation Let z mi = σ(α 0m + αmx T i ) and let z i = (z 1i, z 2i,..., z Mi ) Then we have R(θ) = n i=1 R i with R i = K k=1 (y ik f k (x i )) 2 Derivatives R i β km = R i f k (x i ) f k (x i ) β km = 2(y ik f k (x i ))g k (βt k z i)z mi R i K R i f k (x i ) z mi = α mj f k (x i ) z mi α mj = k=1 K 2(y ik f k (x i ))g k (βt k z i)β km σ (αmx T i )x ij k=1
16 Back-propagation algorithm Weight updates Given these derivatives, a gradient descent update at the t + 1st iteration has the form β (t+1) km α (t+1) mj = β (t) km η t = α (t) mj η t n i=1 n i=1 where η t is the learning rate, discussed below How to compute the gradient efficiently? R i β (t) km R i α (t) mj
17 Back-propagation algorithm Back-propagation equations We can write R i β km = δ ki z mi, R i α mj = s mi x ij The quantities δ ki and s mi are errors from the current model at the output and hidden layer units, respectively. They satisfy K s mi = σ (αmx T i ) β km δ ki k=1 Using this, the weight updates can be implemented with a two-pass algorithm: 1 In the forward pass, the current weights are fixed and the predicted values f k (x i ) are computed 2 In the backward pass, the errors δ ki are computed, and then back-propagated to give the errors s mi Both sets of errors are then used to compute the gradients for the weight updates
18 Advantages of back-propagation The advantages of back-propagation are its simple, local nature In the back propagation algorithm, each hidden unit passes and receives information only to and from units that share a connection Hence it can be implemented efficiently on a parallel architecture computer
19 Batch vs. online training The previous update equations are a kind of batch learning, with the parameter updates being a sum over all of the training cases Learning can also be carried out online processing each observation one at a time, updating the gradient after each training case, and cycling through the training cases many times In this case, the update equations become β (t+1) km α (t+1) mj = β (t) km η R t t β (t) km = α (t) mj η R t t α (t) mj A training epoch refers to one sweep through the entire training set Online training allows the network to handle very large training sets, and also to update the weights as new observations come in
20 Learning rate tuning and optimization algorithms The learning rate η t for batch learning was originally taken to be a constant; it can also be optimized by a line search that minimizes the error function at each update With online learning η t should decrease to zero as the iteration t to ensure convergence (e.g., η t = 1/t) Back-propagation can be very slow, and for that reason is usually not the method of choice Second-order techniques such as Newton s method are not attractive, because the second derivative matrix of R (the Hessian) can be very large Better approaches to fitting include conjugate gradients and variable metric methods, which avoid explicit computation of the second derivative matrix while still providing faster convergence
21 Overview Neural network model Learning Practical issues Examples Simulated data Example in R
22 The art of neural network training There is quite an art in training neural networks The model is generally overparametrized, and the optimization problem is nonconvex and unstable, unless certain guidelines are followed Here, we summarize some of the important issues
23 Starting Values If the weights are near zero, then the operative part of the sigmoid is roughly linear, and hence the neural network collapses into an approximately linear model Usually starting values for weights are chosen to be random values near zero. Hence the model starts out nearly linear, and becomes nonlinear as the weights increase Use of exact zero weights leads to zero derivatives and perfect symmetry, and the algorithm never moves Starting instead with large weights often leads to poor solutions
24 Overfitting Early stopping Often neural networks have too many weights and will overfit the data at the global minimum of R In early developments of neural networks, an early stopping rule was used to avoid overfitting: we train the model only for a while, and stop well before we approach the global minimum Since the weights start at a highly regularized (linear) solution, this has the effect of shrinking the final model toward a linear model A validation dataset is useful for determining when to stop, since we expect the validation error to start increasing
25 Overfitting Weight decay A more explicit method for regularization is weight decay, which is analogous to ridge regression used for linear models We add a penalty to the error function R(θ) + λj(θ), with J(θ) = k,m β 2 km + m,j α 2 mj The hyper-parameter λ is usually determined by cross-validation Other forms for the penalty have been proposed, for example, J(θ) = k,m β 2 km 1 + β 2 km + m,j α 2 mj 1 + α 2 mj known as the weight elimination penalty. This has the effect of shrinking smaller weights more than weight decay does
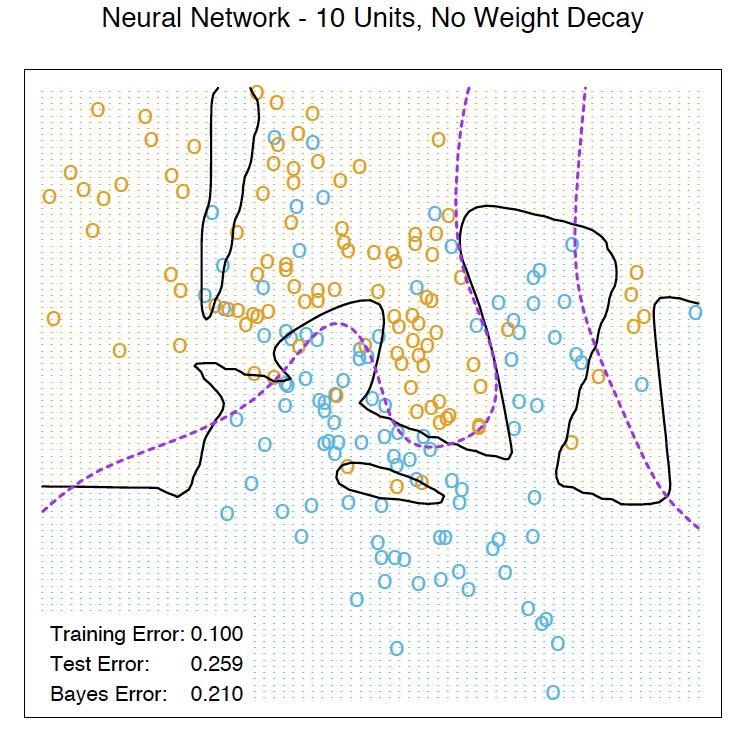
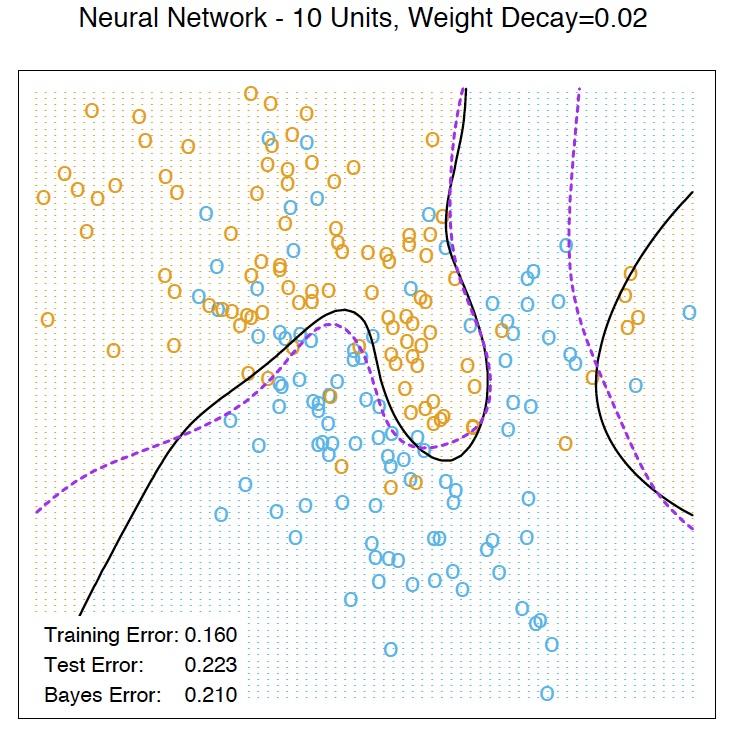
26 Example

27 Heat maps of estimated weights
28 Scaling of the Inputs Since the scaling of the inputs determines the effective scaling of the weights in the bottom layer, it can have a large effect on the quality of the final solution It is best to standardize all inputs to have mean zero and standard deviation one This ensures all inputs are treated equally in the regularization process, and allows one to choose a meaningful range for the random starting weights With standardized inputs, it is typical to take random uniform weights over the range [ 0.7, +0.7]
29 Overview Neural network model Learning Practical issues Examples Simulated data Example in R
30 Simulated data Model Y = f (X ) + ε with f (X ) = σ(a T 1 X ) + σ(a T 2 X ), X = (X 1, X 2 ), a 1 = (3, 3), a 2 = (3, 3), Var(f (X ))/Var(ε) = 4 Training sample of size 100, a test sample of size 10,000 Neural networks with weight decay and various numbers of hidden units Average test error for each of 10 random starting weights
31 Results without and with weight decay
32 Influence of the weight decay hyper-parameter
33 Example with the nnet package library( MASS ) mcycle.data<-data.frame(mcycle,x=scale(mcycle$times)) test.data<-data.frame(x=seq(-2,3,0.01)) library( nnet ) nn1<- nnet(accel x, data=mcycle.data, size=2, linout = TRUE, decay=0) pred1<- predict(nn1,newdata=test.data) nn2<- nnet(accel x, data=mcycle.data, size=10, linout = TRUE, decay=0) pred2<- predict(nn2,newdata=test.data) nn3<- nnet(accel x, data=mcycle.data, size=10, linout = TRUE, decay=1) pred3<- predict(nn3,newdata=test.data)
34 Results accel M=2 M=10, λ = 0 M=10, λ = x
35 Selection of λ by 10-fold cross-validation CV lambda
36 Conclusions Powerful and very general approach for regression and classification Training a neural network implies solving a non-convex optimization problem with a large number of parameter: computer-intensive approach Neural networks are especially effective in settings where prediction without interpretation is the goal They are less effective for problems where the goal is to describe the physical process that generated the data and the roles of individual inputs. The difficulty of interpreting these models has limited their use in fields like medicine, where interpretation of the model is very important
Neural networks (NN) 1
 1") Neural networks (NN) 1 Hedibert F. Lopes Insper Institute of Education and Research São Paulo, Brazil 1 Slides based on Chapter 11 of Hastie, Tibshirani and Friedman s book The Elements of Statistical
Neural networks (NN) 1 Hedibert F. Lopes Insper Institute of Education and Research São Paulo, Brazil 1 Slides based on Chapter 11 of Hastie, Tibshirani and Friedman s book The Elements of Statistical
Neural Networks. Haiming Zhou. Division of Statistics Northern Illinois University.
 Neural Networks Haiming Zhou Division of Statistics Northern Illinois University zhouh@niu.edu Neural Networks The term neural network has evolved to encompass a large class of models and learning methods.
Neural Networks Haiming Zhou Division of Statistics Northern Illinois University zhouh@niu.edu Neural Networks The term neural network has evolved to encompass a large class of models and learning methods.
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Mark Gales October y (x) x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.
 x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.") University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Artificial Neural Networks (ANN) Xiaogang Su, Ph.D. Department of Mathematical Science University of Texas at El Paso
 Xiaogang Su, Ph.D. Department of Mathematical Science University of Texas at El Paso") Artificial Neural Networks (ANN) Xiaogang Su, Ph.D. Department of Mathematical Science University of Texas at El Paso xsu@utep.edu Fall, 2018 Outline Introduction A Brief History ANN Architecture Terminology
Artificial Neural Networks (ANN) Xiaogang Su, Ph.D. Department of Mathematical Science University of Texas at El Paso xsu@utep.edu Fall, 2018 Outline Introduction A Brief History ANN Architecture Terminology
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Multi-layer Neural Networks
 Multi-layer Neural Networks Steve Renals Informatics 2B Learning and Data Lecture 13 8 March 2011 Informatics 2B: Learning and Data Lecture 13 Multi-layer Neural Networks 1 Overview Multi-layer neural
Multi-layer Neural Networks Steve Renals Informatics 2B Learning and Data Lecture 13 8 March 2011 Informatics 2B: Learning and Data Lecture 13 Multi-layer Neural Networks 1 Overview Multi-layer neural
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
Machine Learning
 Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Introduction Neural Networks - Architecture Network Training Small Example - ZIP Codes Summary. Neural Networks - I. Henrik I Christensen
 Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS16
 SS16") COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS6 Lecture 3: Classification with Logistic Regression Advanced optimization techniques Underfitting & Overfitting Model selection (Training-
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS6 Lecture 3: Classification with Logistic Regression Advanced optimization techniques Underfitting & Overfitting Model selection (Training-
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Stochastic gradient descent; Classification
 Stochastic gradient descent; Classification Steve Renals Machine Learning Practical MLP Lecture 2 28 September 2016 MLP Lecture 2 Stochastic gradient descent; Classification 1 Single Layer Networks MLP
Stochastic gradient descent; Classification Steve Renals Machine Learning Practical MLP Lecture 2 28 September 2016 MLP Lecture 2 Stochastic gradient descent; Classification 1 Single Layer Networks MLP
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Neural Networks. Xiaojin Zhu Computer Sciences Department University of Wisconsin, Madison. slide 1
 Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Neural Networks Xiaoin Zhu erryzhu@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison slide 1 Terminator 2 (1991) JOHN: Can you learn? So you can be... you know. More human. Not
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural Network Models in Statistical Learning
 Neural Network Models in Statistical Learning Stephen Talley April 25, 2014 Abstract Neural network models can solve problems more easily than traditional methods by emulating the human brain. We examine
Neural Network Models in Statistical Learning Stephen Talley April 25, 2014 Abstract Neural network models can solve problems more easily than traditional methods by emulating the human brain. We examine
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Vasil Khalidov & Miles Hansard. C.M. Bishop s PRML: Chapter 5; Neural Networks
 C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
Artificial Neural Networks. Edward Gatt
 Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Multilayer Perceptron
 Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
epochs epochs
 Neural Network Experiments To illustrate practical techniques, I chose to use the glass dataset. This dataset has 214 examples and 6 classes. Here are 4 examples from the original dataset. The last values
Neural Network Experiments To illustrate practical techniques, I chose to use the glass dataset. This dataset has 214 examples and 6 classes. Here are 4 examples from the original dataset. The last values
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
Learning from Data: Multi-layer Perceptrons
 Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Machine Learning. 7. Logistic and Linear Regression
 Sapienza University of Rome, Italy - Machine Learning (27/28) University of Rome La Sapienza Master in Artificial Intelligence and Robotics Machine Learning 7. Logistic and Linear Regression Luca Iocchi,
Sapienza University of Rome, Italy - Machine Learning (27/28) University of Rome La Sapienza Master in Artificial Intelligence and Robotics Machine Learning 7. Logistic and Linear Regression Luca Iocchi,
Regularization in Neural Networks
 Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning
 LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning") CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
Computational Intelligence Winter Term 2017/18
 Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
C4 Phenomenological Modeling - Regression & Neural Networks : Computational Modeling and Simulation Instructor: Linwei Wang
 C4 Phenomenological Modeling - Regression & Neural Networks 4040-849-03: Computational Modeling and Simulation Instructor: Linwei Wang Recall.. The simple, multiple linear regression function ŷ(x) = a
C4 Phenomenological Modeling - Regression & Neural Networks 4040-849-03: Computational Modeling and Simulation Instructor: Linwei Wang Recall.. The simple, multiple linear regression function ŷ(x) = a
Neural Networks. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5 Slides adapted from Jordan Boyd-Graber, Tom Mitchell, Ziv Bar-Joseph Machine Learning: Chenhao Tan Boulder 1 of 27 Quiz question For
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5 Slides adapted from Jordan Boyd-Graber, Tom Mitchell, Ziv Bar-Joseph Machine Learning: Chenhao Tan Boulder 1 of 27 Quiz question For
Lecture 6. Regression
 Lecture 6. Regression Prof. Alan Yuille Summer 2014 Outline 1. Introduction to Regression 2. Binary Regression 3. Linear Regression; Polynomial Regression 4. Non-linear Regression; Multilayer Perceptron
Lecture 6. Regression Prof. Alan Yuille Summer 2014 Outline 1. Introduction to Regression 2. Binary Regression 3. Linear Regression; Polynomial Regression 4. Non-linear Regression; Multilayer Perceptron
Learning Neural Networks
 Learning Neural Networks Neural Networks can represent complex decision boundaries Variable size. Any boolean function can be represented. Hidden units can be interpreted as new features Deterministic
Learning Neural Networks Neural Networks can represent complex decision boundaries Variable size. Any boolean function can be represented. Hidden units can be interpreted as new features Deterministic
Speaker Representation and Verification Part II. by Vasileios Vasilakakis
 Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Neural Networks: Optimization & Regularization
 Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Computational Intelligence
 Plan for Today Single-Layer Perceptron Computational Intelligence Winter Term 00/ Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Accelerated Learning
Plan for Today Single-Layer Perceptron Computational Intelligence Winter Term 00/ Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Accelerated Learning
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
ECE 471/571 - Lecture 17. Types of NN. History. Back Propagation. Recurrent (feedback during operation) Feedforward
 Feedforward") ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Artificial Neural Networks
 Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Artificial Neural Network
 Artificial Neural Network Contents 2 What is ANN? Biological Neuron Structure of Neuron Types of Neuron Models of Neuron Analogy with human NN Perceptron OCR Multilayer Neural Network Back propagation
Artificial Neural Network Contents 2 What is ANN? Biological Neuron Structure of Neuron Types of Neuron Models of Neuron Analogy with human NN Perceptron OCR Multilayer Neural Network Back propagation
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
CS60010: Deep Learning
 CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
Gradient-Based Learning. Sargur N. Srihari
 Gradient-Based Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Gradient-Based Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Feed-forward Networks Network Training Error Backpropagation Applications. Neural Networks. Oliver Schulte - CMPT 726. Bishop PRML Ch.
 Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will
Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will
Introduction to Neural Networks
 Introduction to Neural Networks Steve Renals Automatic Speech Recognition ASR Lecture 10 24 February 2014 ASR Lecture 10 Introduction to Neural Networks 1 Neural networks for speech recognition Introduction
Introduction to Neural Networks Steve Renals Automatic Speech Recognition ASR Lecture 10 24 February 2014 ASR Lecture 10 Introduction to Neural Networks 1 Neural networks for speech recognition Introduction
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient