Advanced Training Techniques. Prajit Ramachandran
|
|
|
- Chrystal Rich
- 5 years ago
- Views:
Transcription
1 Advanced Training Techniques Prajit Ramachandran
2 Outline Optimization Regularization Initialization
3 Optimization
4 Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise
5 Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise

6
7 Gradient Descent Goal: optimize parameters to minimize loss Step along the direction of steepest descent (negative gradient)

8 Gradient Descent Andrew Ng s Machine Learning Course
9
10 2nd order Taylor series approximation around x
11 Hessian measures curvature Wikipedia
12
13 Approximate Hessian with scaled identity
14
15 Set gradient of function to 0 to get minimum
16 0 Take the gradient
17 Solve for y

18 Same equation!
19 Computing the gradient Use backpropagation to compute gradients efficiently Need a differentiable function Can t use functions like argmax or hard binary Unless using a different way to compute gradients
20 Stochastic Gradient Descent Gradient over entire dataset is impractical Better to take quick, noisy steps Estimate gradient over a mini-batch of examples
21 Mini-batch tips Use as large of a batch as possible Increasing batch size on GPU is essentially free up to a point Crank up learning rate when increasing batch size Trick: use small batches for small datasets
22 How to pick the learning rate?
23 Too big learning rate gordon/10725-f12/slides/0 5-gd-revisited.pdf
24 Too small learning rate gordon/10725-f12/slides/0 5-gd-revisited.pdf
25 How to pick the learning rate? Too big = diverge, too small = slow convergence No one learning rate to rule them all Start from a high value and keep cutting by half if model diverges Learning rate schedule: decay learning rate over time
26
27 Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise

28 What will SGD do? Start
29 Zig-zagging
30 What we would like Avoid sliding back and forth along high curvature Go fast in along the consistent direction
31
32 Same as vanilla gradient descent

33 ontentitem dwh6d2q9i1qw1-or.png
34 SGD with Momentum Move faster in directions with consistent gradient Damps oscillating gradients in directions of high curvature Friction / momentum hyperparameter μ typically set to {0.50, 0.90, 0.99} Nesterov s Accelerated Gradient is a variant


35 Momentum Cancels out oscillation Gathers speed in direction that matters
36 Per parameter learning rate Gradients of different layers have different magnitudes Different units have different firing rates Want different learning rates for different parameters Infeasible to set all of them by hand
37
38 Adagrad Gradient update depends on history of magnitude of gradients Parameters with small / sparse updates have larger learning rates Square root important for good performance More tolerance for learning rate Duchi et al Adaptive Subgradient Methods for Online Learning and Stochastic Optimization
39 What happens as t increases?
40 Adagrad learning rate goes to 0 Maintain entire history of gradients Sum of magnitude of gradients always increasing Forces learning rate to 0 over time Hard to compensate for in advance
41 Don t maintain all history Monotonically increasing because we hold all the history Instead, forget gradients far in the past In practice, downweight previous gradients exponentially
42
43
44 RMSProp Only cares about recent gradients Good property because optimization landscape changes Otherwise like Adagrad Standard gamma is 0.9 Hinton et al. 2012,
45 Momentum RMSProp

46
47 Adam Essentially, combine RMSProp and Momentum Includes bias correction term from initializing m and v to 0 Default parameters are surprisingly good Trick: learning rate decay still helps Trick: Adam first then SGD
48 What to use SGD + momentum and Adam are good first steps Just use default parameters for Adam Learning rate decay always good


49 Alec Radford
50 Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise

51 How to scale beyond 1 GPU: Model parallelism: partition model across multiple GPUs Dean et al Large scale distributed deep learning.
52 Hogwild! Lock-free update of parameters across multiple threads Fast for sparse updates Surprisingly can work for dense updates Niu et al Hogwild! A lock-free approach to parallelizing stochastic gradient descent
53 Data Parallelism and Async SGD Dean et al Large scale distributed deep learning.
54 Async SGD Trivial to scale up Robust to individual worker failures Equally partition variables across parameter server Trick: at the start of training, slowly add more workers
55 Stale Gradients These are gradients for w, not w
56 Stale Gradients Each worker has a different copy of parameters Using old gradients to update new parameters Staleness grows as more workers are added Hack: reject gradients that are from too far ago

57 Sync SGD Wait for all gradients before update Chen et al Revisiting Distributed Synchronous SGD

58 els/tree/master/inception
59 Sync SGD Equivalent to increasing up the batch size N times, but faster Crank up learning rate Problem: have to wait for slowest worker Solution: add extra backup workers, and update when N gradients received Chen et al Revisiting Distributed Synchronous SGD
60

61 Gradient Noise Add Gaussian noise to each gradient Can be a savior for exotic models Neelakantan et al Adding gradient noise improves learning for very deep networks Anandkumar and Ge, 2016 Efficient approaches for escaping higher order saddle points in non-convex optimization
62 Regularization
63 Regularization Outline Early stopping L1 / L2 Auxiliary classifiers Penalizing confident output distributions Dropout Batch normalization + variants
64 Regularization Outline Early stopping L1 / L2 Auxiliary classifiers Penalizing confident output distributions Dropout Batch normalization + variants
65 Stephen Marsland

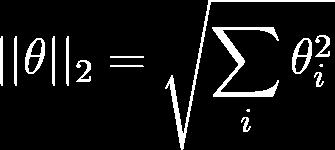
66 L1 / L2 regularization
67 L1 / L2 regularization L1 encourages sparsity L2 discourages large weights Gaussian prior on weight
68 Auxiliary Classifiers Lee et al Deeply Supervised Nets
69 Regularization Outline Early stopping L1 / L2 Auxiliary classifiers Penalizing confident output distributions Dropout Batch normalization + variants
70 Penalizing confident distributions Do not want overconfident model Prefer smoother output distribution Invariant to model parameterization (1) Train towards smoother distribution (2) Penalize entropy Pereyra et al Regularizing neural networks by penalizing confident output distributions
71 True Label Baseline Mixed Target Szegedy et al Rethinking the Inception architecture for computer vision
72 When is uniform a good choice? Bad? Szegedy et al Rethinking the Inception architecture for computer vision
73 AAAAAAAcM/UI6aq-yDEJs/s1600/bernoulli_entropy.png
74 Enforce entropy to be above some threshold AAAAAAAcM/UI6aq-yDEJs/s1600/bernoulli_entropy.png
75 Regularization Outline Early stopping L1 / L2 Auxiliary classifiers Penalizing confident output distributions Dropout Batch normalization + variants
76 Dropout Srivastava et al Dropout: a simple way to prevent neural networks from overfitting
77 Dropout Complex co-adaptations probably do not generalize Forces hidden units to derive useful features on own Sampling from 2n possible related networks Srivastava et al Dropout: a simple way to prevent neural networks from overfitting
78 Srivastava et al Dropout: a simple way to prevent neural networks from overfitting
79 Bayesian interpretation of dropout Variational inference for Gaussian processes Monte Carlo integration over GP posterior
80 Dropout for RNNs Can dropout layer-wise connections as normal Recurrent connections use same dropout mask over time Or dropout specific portion of recurrent cell Zaremba et al Recurrent neural network regularization Gal A theoretically grounded application of dropout in recurrent neural networks Semenuita et al Recurrent dropout without memory loss
81 Regularization Outline Early stopping L1 / L2 Auxiliary classifiers Penalizing confident output distributions Dropout Batch normalization + variants

82
83 Internal Covariate Shift Distribution of inputs to a layer is changing during training Harder to train: smaller learning rate, careful initialization Easier if distribution of inputs stayed same How to enforce same distribution? Ioffe and Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift
84 Fighting internal covariate shift Whitening would be a good first step Would remove nasty correlations Problems with whitening? Ioffe and Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift
85 Problems with whitening Slow (have to do PCA for every layer) Cannot backprop through whitening Next best alternative? Ioffe and Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift
86 Normalization Make mean = 0 and standard deviation = 1 Doesn t eliminate correlations Fast and can backprop through it How to compute the statistics? Ioffe and Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift
87 How to compute the statistics Going over the entire dataset is too slow Idea: the batch is an approximation of the dataset Compute statistics over the batch Ioffe and Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift
88 Batch size Mean Variance Normalize Ioffe and Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift

89 Distribution of an activation before normalization
90 Distribution of an activation after normalization
91 Not all distributions should be normalized A rare feature should not be forced to fire 50% of the time Let the model decide how the distribution should look Even undo the normalization if needed
92 Ioffe and Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift
93 Test time batch normalization Want deterministic inference Different test batches will give different results Solution: precompute mean and variance on training set and use for inference Practically: maintain running average of statistics during training Ioffe and Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift
94 Advantages Enables higher learning rate by stabilizing gradients More resilient to parameter scale Regularizes model, making dropout unnecessary Most SOTA CNN models use BN Ioffe and Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift
95 Batch Norm for RNNs? Naive application doesn t work Compute different statistics for different time steps? Ideally should be able to reuse existing architectures like LSTM Laurent et al Batch normalized recurrent neural networks
96 Cooijmans et al Recurrent Batch Normalization

97 Cooijmans et al Recurrent Batch Normalization
98 Recurrent Batch Normalization Maintain independent statistics for the first T steps t > T uses the statistics from time T Have to initialize to ~0.1 Cooijmans et al Recurrent Batch Normalization
99 Batch Normalization Layer Normalization Hidden Batch Hidden Batch Ba et al Layer Normalization
100 Advantages of LayerNorm Don t have to worry about normalizing across time Don t have to worry about batch size
101 Practical tips for regularization Batch normalization for feedforward structures Dropout still gives good performance for RNNs Entropy regularization good for reinforcement learning Don t go crazy with regularization
102 Initialization
103 Initialization Outline Basic initialization Smarter initialization schemes Pretraining
104 Initialization Outline Basic initialization Smarter initialization schemes Pretraining
105 Baseline Initialization Weights cannot be initialized to same value because all the gradients will be the same Instead, draw from some distribution Uniform from [-0.1, 0.1] is a reasonable starting spot Biases may need special constant initialization
106 Initialization Outline Basic initialization Smarter initialization schemes Pretraining
107 He initialization for ReLU networks Call variance of input Var[y0] and of last layer activations Var[yL] If Var[yL] >> Var[y0]? If Var[yL] << Var[y0]? He et al Delving deep into rectifiers: surpassing human level performance on ImageNet classification
108 He initialization for ReLU networks Call variance of input Var[y0] and of last layer activations Var[yL] If Var[yL] >> Var[y0], exploding activations diverge If Var[yL] << Var[y0], diminishing activations vanishing gradient Key idea: Var[yL] = Var[y0] He et al Delving deep into rectifiers: surpassing human level performance on ImageNet classification
109 He initialization Number of inputs to neuron He et al Delving deep into rectifiers: surpassing human level performance on ImageNet classification
110

111 Identity RNN Basic RNN with ReLU as nonlinearity (instead of tanh) Initialize hidden-to-hidden matrix to identity matrix Le et al A simple way to initialize recurrent neural networks of rectified linear units
112 Initialization Outline Basic initialization Smarter initialization schemes Pretraining
113 Pretraining Initialize with weights from a network trained for another task / dataset Much faster convergence and better generalization Can either freeze or finetune the pretrained weights

114 Zeiler and Fergus, Visualizing and Understanding Convolutional Networks
115 Pretraining for CNNs in vision New dataset is small New dataset is large Pretrained dataset is similar to new dataset Freeze weights and train linear classifier from top level features Fine-tune all layers (pretrain for faster convergence and better generalization) Pretrained dataset is different from new dataset Freeze weights and train linear classifier from non-top level features Fine-tune all the layers (pretrain for improved convergence speed)


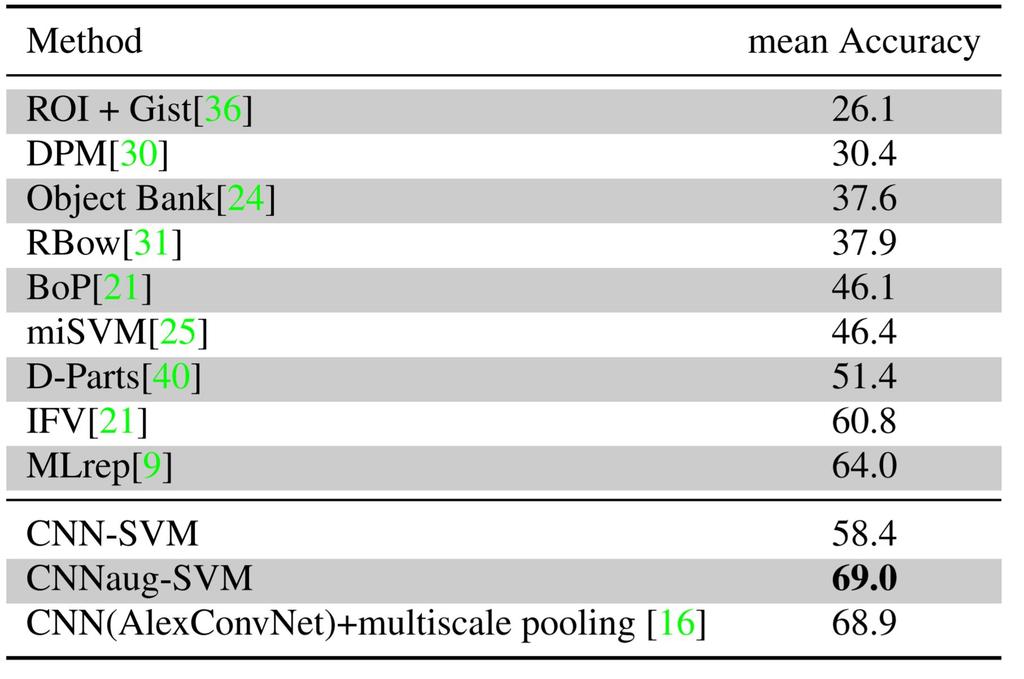
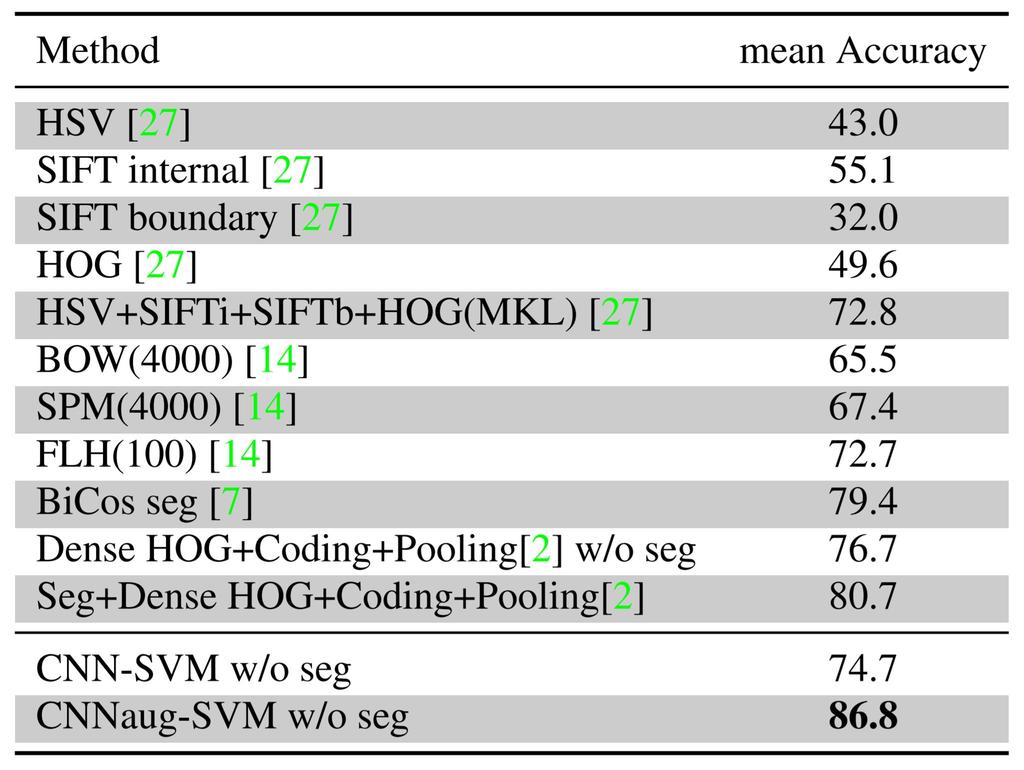
116 Razavian et al CNN features off-the-shelf: an astounding baseline for recognition

117 Pretraining for Seq2Seq Ramachandran et al Unsupervised pretraining for sequence to sequence learning
118 Progressive networks Rusu et al Progressive Neural Networks
119 Key Takeaways Adam and SGD + momentum address key issues of SGD, and are good baseline optimization methods to use Batch norm, dropout, and entropy regularization should be used for improved performance Use smart initialization schemes when possible
120 Questions?
121 Appendix
122 Proof of He initialization
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141



142
143
144
145

146
147

148
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Deep Learning & Artificial Intelligence WS 2018/2019
 Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates
 Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates Hiroaki Hayashi 1,* Jayanth Koushik 1,* Graham Neubig 1 arxiv:1611.01505v3 [cs.lg] 11 Jun 2018 Abstract Adaptive
Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates Hiroaki Hayashi 1,* Jayanth Koushik 1,* Graham Neubig 1 arxiv:1611.01505v3 [cs.lg] 11 Jun 2018 Abstract Adaptive
Overview of gradient descent optimization algorithms. HYUNG IL KOO Based on
 Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Normalization Techniques in Training of Deep Neural Networks
 Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Deep Learning II: Momentum & Adaptive Step Size
 Deep Learning II: Momentum & Adaptive Step Size CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following
Deep Learning II: Momentum & Adaptive Step Size CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following
Understanding Neural Networks : Part I
 TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Tutorial on: Optimization I. (from a deep learning perspective) Jimmy Ba
 Jimmy Ba") Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Machine Learning Lecture 14
 Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent
 CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
Lecture 6 Optimization for Deep Neural Networks
 Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
CSC321 Lecture 8: Optimization
 CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
Regularization and Optimization of Backpropagation
 Regularization and Optimization of Backpropagation The Norwegian University of Science and Technology (NTNU) Trondheim, Norway keithd@idi.ntnu.no October 17, 2017 Regularization Definition of Regularization
Regularization and Optimization of Backpropagation The Norwegian University of Science and Technology (NTNU) Trondheim, Norway keithd@idi.ntnu.no October 17, 2017 Regularization Definition of Regularization
Optimization for neural networks
 0 - : Optimization for neural networks Prof. J.C. Kao, UCLA Optimization for neural networks We previously introduced the principle of gradient descent. Now we will discuss specific modifications we make
0 - : Optimization for neural networks Prof. J.C. Kao, UCLA Optimization for neural networks We previously introduced the principle of gradient descent. Now we will discuss specific modifications we make
DeepLearning on FPGAs
 DeepLearning on FPGAs Introduction to Deep Learning Sebastian Buschäger Technische Universität Dortmund - Fakultät Informatik - Lehrstuhl 8 October 21, 2017 1 Recap Computer Science Approach Technical
DeepLearning on FPGAs Introduction to Deep Learning Sebastian Buschäger Technische Universität Dortmund - Fakultät Informatik - Lehrstuhl 8 October 21, 2017 1 Recap Computer Science Approach Technical
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
UNSUPERVISED LEARNING
 UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Deep Learning & Neural Networks Lecture 4
 Deep Learning & Neural Networks Lecture 4 Kevin Duh Graduate School of Information Science Nara Institute of Science and Technology Jan 23, 2014 2/20 3/20 Advanced Topics in Optimization Today we ll briefly
Deep Learning & Neural Networks Lecture 4 Kevin Duh Graduate School of Information Science Nara Institute of Science and Technology Jan 23, 2014 2/20 3/20 Advanced Topics in Optimization Today we ll briefly
Non-Convex Optimization. CS6787 Lecture 7 Fall 2017
 Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
ECE521 lecture 4: 19 January Optimization, MLE, regularization
 ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent
 Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent 1 Xi-Lin Li, lixilinx@gmail.com arxiv:1606.04449v2 [stat.ml] 8 Dec 2016 Abstract This paper studies the performance of
Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent 1 Xi-Lin Li, lixilinx@gmail.com arxiv:1606.04449v2 [stat.ml] 8 Dec 2016 Abstract This paper studies the performance of
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation
 Computational Graphs, Learning Algorithms, Initialisation") Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
CSC321 Lecture 7: Optimization
 CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
Training Neural Networks Practical Issues
 Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Normalization Techniques
 Normalization Techniques Devansh Arpit Normalization Techniques 1 / 39 Table of Contents 1 Introduction 2 Motivation 3 Batch Normalization 4 Normalization Propagation 5 Weight Normalization 6 Layer Normalization
Normalization Techniques Devansh Arpit Normalization Techniques 1 / 39 Table of Contents 1 Introduction 2 Motivation 3 Batch Normalization 4 Normalization Propagation 5 Weight Normalization 6 Layer Normalization
Neural Networks: Optimization & Regularization
 Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Optimization for Training I. First-Order Methods Training algorithm
 Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Don t Decay the Learning Rate, Increase the Batch Size. Samuel L. Smith, Pieter-Jan Kindermans, Quoc V. Le December 9 th 2017
 Don t Decay the Learning Rate, Increase the Batch Size Samuel L. Smith, Pieter-Jan Kindermans, Quoc V. Le December 9 th 2017 slsmith@ Google Brain Three related questions: What properties control generalization?
Don t Decay the Learning Rate, Increase the Batch Size Samuel L. Smith, Pieter-Jan Kindermans, Quoc V. Le December 9 th 2017 slsmith@ Google Brain Three related questions: What properties control generalization?
Machine Learning CS 4900/5900. Lecture 03. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Machine Learning Techniques
 Machine Learning Techniques ( 機器學習技法 ) Lecture 13: Deep Learning Hsuan-Tien Lin ( 林軒田 ) htlin@csie.ntu.edu.tw Department of Computer Science & Information Engineering National Taiwan University ( 國立台灣大學資訊工程系
Machine Learning Techniques ( 機器學習技法 ) Lecture 13: Deep Learning Hsuan-Tien Lin ( 林軒田 ) htlin@csie.ntu.edu.tw Department of Computer Science & Information Engineering National Taiwan University ( 國立台灣大學資訊工程系
Introduction to Deep Learning CMPT 733. Steven Bergner
 Introduction to Deep Learning CMPT 733 Steven Bergner Overview Renaissance of artificial neural networks Representation learning vs feature engineering Background Linear Algebra, Optimization Regularization
Introduction to Deep Learning CMPT 733 Steven Bergner Overview Renaissance of artificial neural networks Representation learning vs feature engineering Background Linear Algebra, Optimization Regularization
OPTIMIZATION METHODS IN DEEP LEARNING
 Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
The K-FAC method for neural network optimization
 The K-FAC method for neural network optimization James Martens Thanks to my various collaborators on K-FAC research and engineering: Roger Grosse, Jimmy Ba, Vikram Tankasali, Matthew Johnson, Daniel Duckworth,
The K-FAC method for neural network optimization James Martens Thanks to my various collaborators on K-FAC research and engineering: Roger Grosse, Jimmy Ba, Vikram Tankasali, Matthew Johnson, Daniel Duckworth,
More Tips for Training Neural Network. Hung-yi Lee
 More Tips for Training Neural Network Hung-yi ee Outline Activation Function Cost Function Data Preprocessing Training Generalization Review: Training Neural Network Neural network: f ; θ : input (vector)
More Tips for Training Neural Network Hung-yi ee Outline Activation Function Cost Function Data Preprocessing Training Generalization Review: Training Neural Network Neural network: f ; θ : input (vector)
Ways to make neural networks generalize better
 Ways to make neural networks generalize better Seminar in Deep Learning University of Tartu 04 / 10 / 2014 Pihel Saatmann Topics Overview of ways to improve generalization Limiting the size of the weights
Ways to make neural networks generalize better Seminar in Deep Learning University of Tartu 04 / 10 / 2014 Pihel Saatmann Topics Overview of ways to improve generalization Limiting the size of the weights
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
Rapid Introduction to Machine Learning/ Deep Learning
 Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/59 Lecture 4a Feedforward neural network October 30, 2015 2/59 Table of contents 1 1. Objectives of Lecture
Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/59 Lecture 4a Feedforward neural network October 30, 2015 2/59 Table of contents 1 1. Objectives of Lecture
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Deep Learning Lecture 2
 Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Introduction to Machine Learning (67577)
") Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Nonlinear Models. Numerical Methods for Deep Learning. Lars Ruthotto. Departments of Mathematics and Computer Science, Emory University.
 Nonlinear Models Numerical Methods for Deep Learning Lars Ruthotto Departments of Mathematics and Computer Science, Emory University Intro 1 Course Overview Intro 2 Course Overview Lecture 1: Linear Models
Nonlinear Models Numerical Methods for Deep Learning Lars Ruthotto Departments of Mathematics and Computer Science, Emory University Intro 1 Course Overview Intro 2 Course Overview Lecture 1: Linear Models
Introduction to Convolutional Neural Networks 2018 / 02 / 23
 Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
CSC321 Lecture 9: Generalization
 CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 26 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 26 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Lecture 14: Deep Generative Learning
 Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Comparison of Modern Stochastic Optimization Algorithms
 Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding
 Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
J. Sadeghi E. Patelli M. de Angelis
 J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
Nonlinear Optimization Methods for Machine Learning
 Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization
 Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization Changyou Chen, David Carlson, Zhe Gan, Chunyuan Li, Lawrence Carin May 2, 2016 1 Changyou Chen Bridging the Gap between Stochastic
Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization Changyou Chen, David Carlson, Zhe Gan, Chunyuan Li, Lawrence Carin May 2, 2016 1 Changyou Chen Bridging the Gap between Stochastic
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
Lecture 9: Generalization
 Lecture 9: Generalization Roger Grosse 1 Introduction When we train a machine learning model, we don t just want it to learn to model the training data. We want it to generalize to data it hasn t seen
Lecture 9: Generalization Roger Grosse 1 Introduction When we train a machine learning model, we don t just want it to learn to model the training data. We want it to generalize to data it hasn t seen
Large-scale Stochastic Optimization
 Large-scale Stochastic Optimization 11-741/641/441 (Spring 2016) Hanxiao Liu hanxiaol@cs.cmu.edu March 24, 2016 1 / 22 Outline 1. Gradient Descent (GD) 2. Stochastic Gradient Descent (SGD) Formulation
Large-scale Stochastic Optimization 11-741/641/441 (Spring 2016) Hanxiao Liu hanxiaol@cs.cmu.edu March 24, 2016 1 / 22 Outline 1. Gradient Descent (GD) 2. Stochastic Gradient Descent (SGD) Formulation
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
IMPROVING STOCHASTIC GRADIENT DESCENT
 IMPROVING STOCHASTIC GRADIENT DESCENT WITH FEEDBACK Jayanth Koushik & Hiroaki Hayashi Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213, USA {jkoushik,hiroakih}@cs.cmu.edu
IMPROVING STOCHASTIC GRADIENT DESCENT WITH FEEDBACK Jayanth Koushik & Hiroaki Hayashi Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213, USA {jkoushik,hiroakih}@cs.cmu.edu
Neural Networks. Learning and Computer Vision Prof. Olga Veksler CS9840. Lecture 10
 CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
Summary and discussion of: Dropout Training as Adaptive Regularization
 Summary and discussion of: Dropout Training as Adaptive Regularization Statistics Journal Club, 36-825 Kirstin Early and Calvin Murdock November 21, 2014 1 Introduction Multi-layered (i.e. deep) artificial
Summary and discussion of: Dropout Training as Adaptive Regularization Statistics Journal Club, 36-825 Kirstin Early and Calvin Murdock November 21, 2014 1 Introduction Multi-layered (i.e. deep) artificial
Non-Linearity. CS 188: Artificial Intelligence. Non-Linear Separators. Non-Linear Separators. Deep Learning I
 Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
CSC321 Lecture 9: Generalization
 CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 27 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 27 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
Neural Networks: Optimization Part 2. Intro to Deep Learning, Fall 2017
 Neural Networks: Optimization Part 2 Intro to Deep Learning, Fall 2017 Quiz 3 Quiz 3 Which of the following are necessary conditions for a value x to be a local minimum of a twice differentiable function
Neural Networks: Optimization Part 2 Intro to Deep Learning, Fall 2017 Quiz 3 Quiz 3 Which of the following are necessary conditions for a value x to be a local minimum of a twice differentiable function
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results