UNSUPERVISED LEARNING
|
|
|
- Charles Horn
- 5 years ago
- Views:
Transcription
1 UNSUPERVISED LEARNING
2 Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders
3 LAYER-WISE (UNSUPERVISED) PRE-TRAINING
4 Breakthrough in 2006 Layer-wise (unsupervised) pre-training
5 Breakthrough in 2006 Key idea: Focus on modeling the input P(X) better with each successive layer. Worry about optimizing the task P(Y X) later. X=observation, Y=label Build generative mode P(X) with a unsupervised manner from unlabeled data. "If you want to do computer vision, first learn computer graphics." -- Geoffrey Hinton

6 Unsupervised learning Supervised learning Unsupervised learning
7 Unsupervised learning How to constrain the model to represent training samples better than other data points? [Restricted Boltzmann Machine] Make models that defines the distribution of samples [Auto-encoder with bottleneck] reconstruct the input from the code & make code compact [Sparse auto-encoder] reconstruct the input from the code & make code sparse [Denoising auto-encoder] Add noise to the input or code

8 Auto-encoder with bottleneck Input Code Output
9 Sparse auto-encoder Input layer Hidden layer Output layer Input : MNIST Dataset Input dimension : 784(28x28) Reconstructions Output dimension : 784(28x28)


10 Denoising auto-encoder Training the denoising auto-encoder Update weight & bias Input Input with noise Reconstruction Auto-encoder Result Input Input with noise Reconstruction
11 RESTRICTED BOLTZMANN MACHINE
12 Restricted Boltzmann Machine (RBM) RBM is a simple energy-based model: p v, h = 1 exp( E Z θ(v, h)) With only h v interactions: E θ v, h = v T Wh b T v d T h here, we assume h j and v i are binary variables. Normalizer Z = v,h exp( E θ (v, h)) is called a partition function h 1 h 2 h 3 v 1 v 2 v 3
13 Restricted Boltzmann Machine (RBM) The probability that the network assigns to a visible vector v: p v = 1 Z h exp( E θ (v, h)) h 50 binary feature neurons h 1 h 2 h 3 v 16 x 16 pixel image v 1 v 2 v 3
14 The weights of the 50 feature detectors We start with small random weights to break symmetry
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29

30
31 The final 50 x 256 weights Each neuron grabs a different feature.
32 Efficient learning procedure for RBMs The probability that the network assigns to a visible vector v: p v = 1 Z h exp( E θ (v, h)) w = arg max n log p(v n ) w The derivative of the log probability w. r. t. a weight: 1 N N log p(vn ) n=1 w ij =< v i h j > data < v i h j > model Stochastic steepest ascent Δw ij = ε(< v i h j > data < v i h j > model ) h 1 h 2 h 3 v 1 v 2 v 3
33 Efficient learning procedure for RBMs Computing posteriors p h v = j=1 p h j v p v h = i=1 p v i h The absence of direct connections between hidden units in an RBM allows us to have p h j = 1 v = σ(d j + w ij v i ) The absence of direct connects between visible units in an RBM allows us to have p v i = 1 h = σ(b i + w ij h j )
34 Efficient learning procedure for RBMs h j h j < v i h j > data < v i h j > 1 v i v i Δw ij = ε < v i h j > data < v i h j > model = ε(< v i h j > data < v i h j > )
35 Efficient learning procedure for RBMs h j h j < v i h j > data < v i h j > 1 v i v i Δw ij = ε < v i h j > data < v i h j > model = ε(< v i h j > data < v i h j > ) ε(< v i h j > data < v i h j > 1 )
36 Training RBMs with Contrastive Divergence The term < v i h j > model is expensive because it requires sampling (v, h) from the model Gibbs sampling (sample v then h iteratively) works, but waiting for convergence at each gradient step is slow. Contrastive Divergence is faster: initialize with training point and wait only a few (usually 1) sampling steps Let v be a training point. Sample h j {0,1} from p h j = 1 v = σ(d j + w ij v i ) Sample v i {0,1} from p v i = 1 h = σ(b i + w ij h j ) Sample h j {0,1} from p h j = 1 v = σ b i + w ij v i w ij w ij + ε(v i h j v i h j )
37 DEEP BELIEF NETWORK Ruslan Salakhutdinov and Geoffrey Hinton, Deep Boltzmann Machine, 2009
 p(h, h ) Stacked RBMs can also be used to initialize a Deep Neural Network (DNN).")
38 Deep Belief Nets (DBN) = Stacked RBM DBN defines a probabilistic generative model p x = h,h,h p x h p(h h ) p(h, h ) Stacked RBMs can also be used to initialize a Deep Neural Network (DNN).
 that are amazingly")
39 Generating Data from a Deep Generative Model After training on 20k images, the generative model of can generate random mages (dimension=8976) that are amazingly realistic!
40 DEEP AUTOENCODER Hinton and Salakhutdinov, Reducing the Dimensionality of Data with Neural Networks, Science, 2006
41 Auto-encoder An auto-encoder is trained to encode the input in some representation so that the input can be reconstructed from that representation. Hence the target output is the input itself x encoder h decoder r x
42 Deep auto-encoder Pre-training consists of learning a stack of RBMs, each having only one layer of feature detectors. The learned feature activations of one RBM are used as the data for training the next RBM in the stack. After the pre-training, the RBMs are unrolled to create a deep auto-encoder, which is then fine-tuned using back-propagation of error derivatives.

43 Deep auto-encoder Can be used to reduce the dimensionality of the data Better reconstruction than PCA Original Deep autoencoder PCA

44 Deep auto-encoder (digit data) PCA Deep auto-encoder
")
45 Deep auto-encoder (documents) Visualization of the data (dimension reduction to 2D)
46 Summary Layer-wise pre-training is the innovation that rekindled interest in deep architectures. Pre-training focuses on optimizing likelihood on the data, not the target label. First model p(v) to do better p(y v). Why RBM? p(h x) is tractable, so it's easy to stack. RBM training can be expensive. Solution: contrastive divergence DBN formed by stacking RBMs is a probabilistic generative mode
47 RBM + SUPERVISED LEARNING

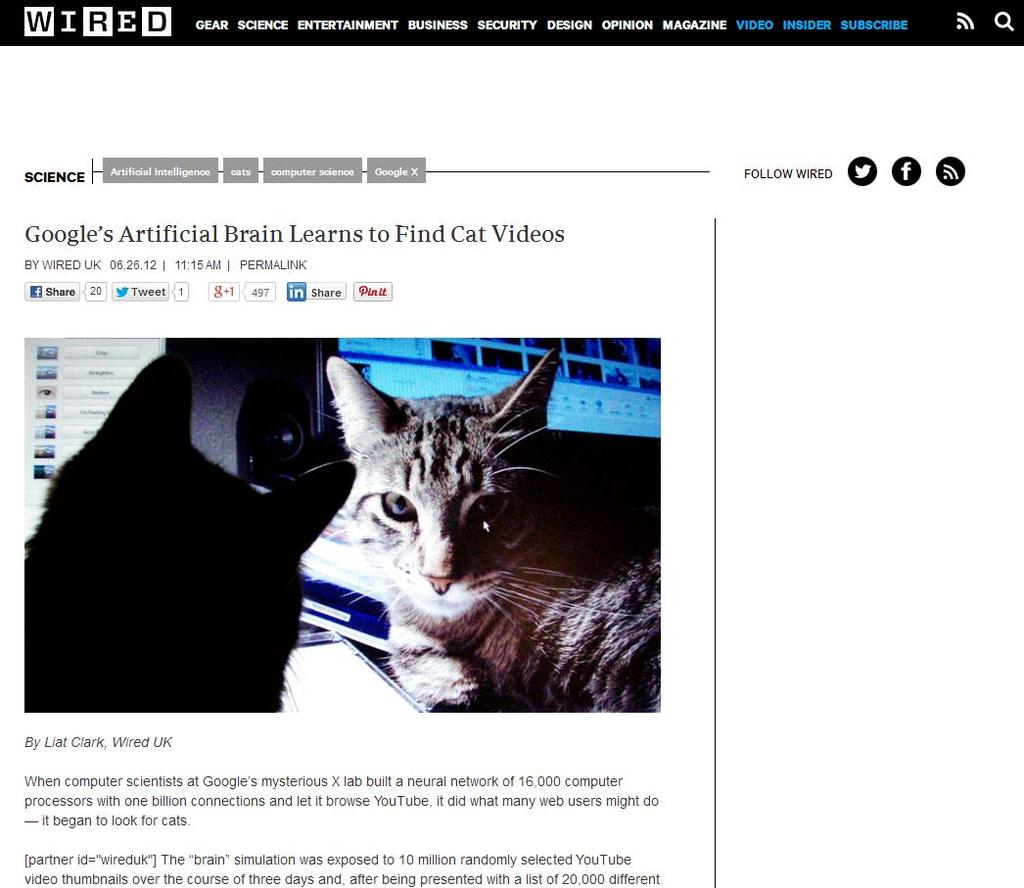
48 UNSUPERVISED PRE-TRAINING We will use a greedy, layer-wise procedure train one layer at a time, from first to last, with unsupervised criterion fix the parameters of previous hidden layers previous layers viewed as feature extraction

49 FINE-TUNING Once all layers are pre-trained add output layer train the whole network using supervised learning Supervised learning is performed as in a regular feed-forward network forward propagation, backpropagation and update We call this last phase fine-tuning all parameters are tuned for the supervised task at hand representation is adjusted to be more discriminative
50 ONE LEARNING ALGORITHM HYPOTHESIS? GRANDMOTHER CELL HYPOTHESIS?


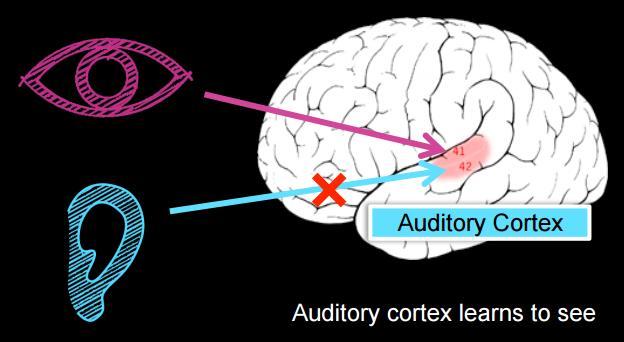
51

52
53

54 BUILDING HIGH-LEVEL FEATURES USING LARGE SCALE UNSUPERVISED LEARNING Quoc V. Le et al, ICML, 2012
55 Motivating Question Is it possible to learn high-level features (e.g. face detectors) using only unlabeled images? "Grandmother Cell" Hypothesis Grandmother cell: A neuron that lights up when you see or hear your grandmother Lots of interesting (controversial) discussions in the neuroscience literature
56 Architecture ( sparse deep auto-encoder)
57 Training Using a deep network of 1 billion parameters 10 million images (sampled from Youtube) 1000 machines (16,000 cores) x 3 week. Model parallelism Distributing the local weights W d, W e in different machines Asynchronous SGD

58 Face neuron

59 Cat neuron

60 More examples
61 APPLICATION
62 Methods Traditional Deep-Learning based Non-machine Learning Machine-Learning based method Supervised SVM MLP CNN RNN (LSTM) Localizati on GPS, SLAM Self Driving Perception Pedestrian detection (HOG+SVM) Detection/ Segmentat ion/classif ication Dry/wet road classificati on ADAS Planning/ Control Optimal control End-toend Learning End-toend Learning Tasks Driver state Behavior Prediction/ Driver identificati on Vehicle Diagnosis Smart factory DNN * * Reinforcement * Unsupervised * *
63 Rotor System Diagnosis Vibration image generation RK4 test-bed (Labeled) Power plant (Labeled) Power plant (Unlabeled) Vibration images using ODR High level feature abstraction Greedy layer-wise unsupervised pre-training : Restricted Boltzmann Machine in deep belief network (DBN) v h 1 h 2 h N 1 h N Health reasoning Classification : multi-layer perceptron (MLP) Clustering : self-organizing map Clustered_con1 Clustered_con2 Clustered_con3 Clustered_con4 Clustered_con5 Clustered_con6 Clustered_con7 Clustered_con8 Normal Rubbing Misalignment Oil whirl U_Anomaly 1 U_Anomaly 2 U_Anomaly 3 Known Unknown
Deep unsupervised learning
 Deep unsupervised learning Advanced data-mining Yongdai Kim Department of Statistics, Seoul National University, South Korea Unsupervised learning In machine learning, there are 3 kinds of learning paradigm.
Deep unsupervised learning Advanced data-mining Yongdai Kim Department of Statistics, Seoul National University, South Korea Unsupervised learning In machine learning, there are 3 kinds of learning paradigm.
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Deep Learning & Neural Networks Lecture 2
 Deep Learning & Neural Networks Lecture 2 Kevin Duh Graduate School of Information Science Nara Institute of Science and Technology Jan 16, 2014 2/45 Today s Topics 1 General Ideas in Deep Learning Motivation
Deep Learning & Neural Networks Lecture 2 Kevin Duh Graduate School of Information Science Nara Institute of Science and Technology Jan 16, 2014 2/45 Today s Topics 1 General Ideas in Deep Learning Motivation
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Reading Group on Deep Learning Session 4 Unsupervised Neural Networks
 Reading Group on Deep Learning Session 4 Unsupervised Neural Networks Jakob Verbeek & Daan Wynen 206-09-22 Jakob Verbeek & Daan Wynen Unsupervised Neural Networks Outline Autoencoders Restricted) Boltzmann
Reading Group on Deep Learning Session 4 Unsupervised Neural Networks Jakob Verbeek & Daan Wynen 206-09-22 Jakob Verbeek & Daan Wynen Unsupervised Neural Networks Outline Autoencoders Restricted) Boltzmann
Tasks ADAS. Self Driving. Non-machine Learning. Traditional MLP. Machine-Learning based method. Supervised CNN. Methods. Deep-Learning based
 UNDERSTANDING CNN ADAS Tasks Self Driving Localizati on Perception Planning/ Control Driver state Vehicle Diagnosis Smart factory Methods Traditional Deep-Learning based Non-machine Learning Machine-Learning
UNDERSTANDING CNN ADAS Tasks Self Driving Localizati on Perception Planning/ Control Driver state Vehicle Diagnosis Smart factory Methods Traditional Deep-Learning based Non-machine Learning Machine-Learning
Greedy Layer-Wise Training of Deep Networks
 Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Deep Learning Srihari. Deep Belief Nets. Sargur N. Srihari
 Deep Belief Nets Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines for continuous
Deep Belief Nets Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines for continuous
An efficient way to learn deep generative models
 An efficient way to learn deep generative models Geoffrey Hinton Canadian Institute for Advanced Research & Department of Computer Science University of Toronto Joint work with: Ruslan Salakhutdinov, Yee-Whye
An efficient way to learn deep generative models Geoffrey Hinton Canadian Institute for Advanced Research & Department of Computer Science University of Toronto Joint work with: Ruslan Salakhutdinov, Yee-Whye
How to do backpropagation in a brain. Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto
 1 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto What is wrong with back-propagation? It requires labeled training data. (fixed) Almost
1 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto What is wrong with back-propagation? It requires labeled training data. (fixed) Almost
The Origin of Deep Learning. Lili Mou Jan, 2015
 The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
Deep Boltzmann Machines
 Deep Boltzmann Machines Ruslan Salakutdinov and Geoffrey E. Hinton Amish Goel University of Illinois Urbana Champaign agoel10@illinois.edu December 2, 2016 Ruslan Salakutdinov and Geoffrey E. Hinton Amish
Deep Boltzmann Machines Ruslan Salakutdinov and Geoffrey E. Hinton Amish Goel University of Illinois Urbana Champaign agoel10@illinois.edu December 2, 2016 Ruslan Salakutdinov and Geoffrey E. Hinton Amish
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Learning Deep Architectures
 Learning Deep Architectures Yoshua Bengio, U. Montreal Microsoft Cambridge, U.K. July 7th, 2009, Montreal Thanks to: Aaron Courville, Pascal Vincent, Dumitru Erhan, Olivier Delalleau, Olivier Breuleux,
Learning Deep Architectures Yoshua Bengio, U. Montreal Microsoft Cambridge, U.K. July 7th, 2009, Montreal Thanks to: Aaron Courville, Pascal Vincent, Dumitru Erhan, Olivier Delalleau, Olivier Breuleux,
Deep Generative Models. (Unsupervised Learning)
") Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What
Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What
Knowledge Extraction from DBNs for Images
 Knowledge Extraction from DBNs for Images Son N. Tran and Artur d Avila Garcez Department of Computer Science City University London Contents 1 Introduction 2 Knowledge Extraction from DBNs 3 Experimental
Knowledge Extraction from DBNs for Images Son N. Tran and Artur d Avila Garcez Department of Computer Science City University London Contents 1 Introduction 2 Knowledge Extraction from DBNs 3 Experimental
Unsupervised Learning
 CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding
 Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Deep Neural Networks
 Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
Deep Learning Architectures and Algorithms
 Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
CSC321 Lecture 20: Autoencoders
 CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
Deep Belief Networks are compact universal approximators
 1 Deep Belief Networks are compact universal approximators Nicolas Le Roux 1, Yoshua Bengio 2 1 Microsoft Research Cambridge 2 University of Montreal Keywords: Deep Belief Networks, Universal Approximation
1 Deep Belief Networks are compact universal approximators Nicolas Le Roux 1, Yoshua Bengio 2 1 Microsoft Research Cambridge 2 University of Montreal Keywords: Deep Belief Networks, Universal Approximation
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]
![Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]](/thumbs/88/117565192.jpg "Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]") Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
Basic Principles of Unsupervised and Unsupervised
 Basic Principles of Unsupervised and Unsupervised Learning Toward Deep Learning Shun ichi Amari (RIKEN Brain Science Institute) collaborators: R. Karakida, M. Okada (U. Tokyo) Deep Learning Self Organization
Basic Principles of Unsupervised and Unsupervised Learning Toward Deep Learning Shun ichi Amari (RIKEN Brain Science Institute) collaborators: R. Karakida, M. Okada (U. Tokyo) Deep Learning Self Organization
Denoising Autoencoders
 Denoising Autoencoders Oliver Worm, Daniel Leinfelder 20.11.2013 Oliver Worm, Daniel Leinfelder Denoising Autoencoders 20.11.2013 1 / 11 Introduction Poor initialisation can lead to local minima 1986 -
Denoising Autoencoders Oliver Worm, Daniel Leinfelder 20.11.2013 Oliver Worm, Daniel Leinfelder Denoising Autoencoders 20.11.2013 1 / 11 Introduction Poor initialisation can lead to local minima 1986 -
Course Structure. Psychology 452 Week 12: Deep Learning. Chapter 8 Discussion. Part I: Deep Learning: What and Why? Rufus. Rufus Processed By Fetch
 Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
Deep Learning Autoencoder Models
 Deep Learning Autoencoder Models Davide Bacciu Dipartimento di Informatica Università di Pisa Intelligent Systems for Pattern Recognition (ISPR) Generative Models Wrap-up Deep Learning Module Lecture Generative
Deep Learning Autoencoder Models Davide Bacciu Dipartimento di Informatica Università di Pisa Intelligent Systems for Pattern Recognition (ISPR) Generative Models Wrap-up Deep Learning Module Lecture Generative
Speaker Representation and Verification Part II. by Vasileios Vasilakakis
 Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Deep Learning Basics Lecture 8: Autoencoder & DBM. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 8: Autoencoder & DBM Princeton University COS 495 Instructor: Yingyu Liang Autoencoder Autoencoder Neural networks trained to attempt to copy its input to its output Contain
Deep Learning Basics Lecture 8: Autoencoder & DBM Princeton University COS 495 Instructor: Yingyu Liang Autoencoder Autoencoder Neural networks trained to attempt to copy its input to its output Contain
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Restricted Boltzmann Machines
 Restricted Boltzmann Machines http://deeplearning4.org/rbm-mnist-tutorial.html Slides from Hugo Larochelle, Geoffrey Hinton, and Yoshua Bengio CSC321: Intro to Machine Learning and Neural Networks, Winter
Restricted Boltzmann Machines http://deeplearning4.org/rbm-mnist-tutorial.html Slides from Hugo Larochelle, Geoffrey Hinton, and Yoshua Bengio CSC321: Intro to Machine Learning and Neural Networks, Winter
Au-delà de la Machine de Boltzmann Restreinte. Hugo Larochelle University of Toronto
 Au-delà de la Machine de Boltzmann Restreinte Hugo Larochelle University of Toronto Introduction Restricted Boltzmann Machines (RBMs) are useful feature extractors They are mostly used to initialize deep
Au-delà de la Machine de Boltzmann Restreinte Hugo Larochelle University of Toronto Introduction Restricted Boltzmann Machines (RBMs) are useful feature extractors They are mostly used to initialize deep
Using Deep Belief Nets to Learn Covariance Kernels for Gaussian Processes
 Using Deep Belief Nets to Learn Covariance Kernels for Gaussian Processes Ruslan Salakhutdinov and Geoffrey Hinton Department of Computer Science, University of Toronto 6 King s College Rd, M5S 3G4, Canada
Using Deep Belief Nets to Learn Covariance Kernels for Gaussian Processes Ruslan Salakhutdinov and Geoffrey Hinton Department of Computer Science, University of Toronto 6 King s College Rd, M5S 3G4, Canada
Measuring the Usefulness of Hidden Units in Boltzmann Machines with Mutual Information
 Measuring the Usefulness of Hidden Units in Boltzmann Machines with Mutual Information Mathias Berglund, Tapani Raiko, and KyungHyun Cho Department of Information and Computer Science Aalto University
Measuring the Usefulness of Hidden Units in Boltzmann Machines with Mutual Information Mathias Berglund, Tapani Raiko, and KyungHyun Cho Department of Information and Computer Science Aalto University
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY,
 WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Neural Networks. Mark van Rossum. January 15, School of Informatics, University of Edinburgh 1 / 28
 1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
arxiv: v2 [cs.ne] 22 Feb 2013
![arxiv: v2 [cs.ne] 22 Feb 2013](/thumbs/76/74046790.jpg "arxiv: v2 [cs.ne] 22 Feb 2013") Sparse Penalty in Deep Belief Networks: Using the Mixed Norm Constraint arxiv:1301.3533v2 [cs.ne] 22 Feb 2013 Xanadu C. Halkias DYNI, LSIS, Universitè du Sud, Avenue de l Université - BP20132, 83957 LA
Sparse Penalty in Deep Belief Networks: Using the Mixed Norm Constraint arxiv:1301.3533v2 [cs.ne] 22 Feb 2013 Xanadu C. Halkias DYNI, LSIS, Universitè du Sud, Avenue de l Université - BP20132, 83957 LA
TUTORIAL PART 1 Unsupervised Learning
 TUTORIAL PART 1 Unsupervised Learning Marc'Aurelio Ranzato Department of Computer Science Univ. of Toronto ranzato@cs.toronto.edu Co-organizers: Honglak Lee, Yoshua Bengio, Geoff Hinton, Yann LeCun, Andrew
TUTORIAL PART 1 Unsupervised Learning Marc'Aurelio Ranzato Department of Computer Science Univ. of Toronto ranzato@cs.toronto.edu Co-organizers: Honglak Lee, Yoshua Bengio, Geoff Hinton, Yann LeCun, Andrew
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Chapter 16. Structured Probabilistic Models for Deep Learning
 Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Part 2. Representation Learning Algorithms
 53 Part 2 Representation Learning Algorithms 54 A neural network = running several logistic regressions at the same time If we feed a vector of inputs through a bunch of logis;c regression func;ons, then
53 Part 2 Representation Learning Algorithms 54 A neural network = running several logistic regressions at the same time If we feed a vector of inputs through a bunch of logis;c regression func;ons, then
Learning Deep Architectures
 Learning Deep Architectures Yoshua Bengio, U. Montreal CIFAR NCAP Summer School 2009 August 6th, 2009, Montreal Main reference: Learning Deep Architectures for AI, Y. Bengio, to appear in Foundations and
Learning Deep Architectures Yoshua Bengio, U. Montreal CIFAR NCAP Summer School 2009 August 6th, 2009, Montreal Main reference: Learning Deep Architectures for AI, Y. Bengio, to appear in Foundations and
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
Chapter 20. Deep Generative Models
 Peng et al.: Deep Learning and Practice 1 Chapter 20 Deep Generative Models Peng et al.: Deep Learning and Practice 2 Generative Models Models that are able to Provide an estimate of the probability distribution
Peng et al.: Deep Learning and Practice 1 Chapter 20 Deep Generative Models Peng et al.: Deep Learning and Practice 2 Generative Models Models that are able to Provide an estimate of the probability distribution
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Training an RBM: Contrastive Divergence. Sargur N. Srihari
 Training an RBM: Contrastive Divergence Sargur N. srihari@cedar.buffalo.edu Topics in Partition Function Definition of Partition Function 1. The log-likelihood gradient 2. Stochastic axiu likelihood and
Training an RBM: Contrastive Divergence Sargur N. srihari@cedar.buffalo.edu Topics in Partition Function Definition of Partition Function 1. The log-likelihood gradient 2. Stochastic axiu likelihood and
COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines COMP9444 17s2 Boltzmann Machines 1 Outline Content Addressable Memory Hopfield Network Generative Models Boltzmann Machine Restricted Boltzmann
COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines COMP9444 17s2 Boltzmann Machines 1 Outline Content Addressable Memory Hopfield Network Generative Models Boltzmann Machine Restricted Boltzmann
Contrastive Divergence
 Contrastive Divergence Training Products of Experts by Minimizing CD Hinton, 2002 Helmut Puhr Institute for Theoretical Computer Science TU Graz June 9, 2010 Contents 1 Theory 2 Argument 3 Contrastive
Contrastive Divergence Training Products of Experts by Minimizing CD Hinton, 2002 Helmut Puhr Institute for Theoretical Computer Science TU Graz June 9, 2010 Contents 1 Theory 2 Argument 3 Contrastive
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
CONVOLUTIONAL DEEP BELIEF NETWORKS
 CONVOLUTIONAL DEEP BELIEF NETWORKS Talk by Emanuele Coviello Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations Honglak Lee Roger Grosse Rajesh Ranganath
CONVOLUTIONAL DEEP BELIEF NETWORKS Talk by Emanuele Coviello Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations Honglak Lee Roger Grosse Rajesh Ranganath
Lecture 14: Deep Generative Learning
 Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Learning to Disentangle Factors of Variation with Manifold Learning
 Learning to Disentangle Factors of Variation with Manifold Learning Scott Reed Kihyuk Sohn Yuting Zhang Honglak Lee University of Michigan, Department of Electrical Engineering and Computer Science 08
Learning to Disentangle Factors of Variation with Manifold Learning Scott Reed Kihyuk Sohn Yuting Zhang Honglak Lee University of Michigan, Department of Electrical Engineering and Computer Science 08
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Unsupervised Neural Nets
 Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
Robust Classification using Boltzmann machines by Vasileios Vasilakakis
 Robust Classification using Boltzmann machines by Vasileios Vasilakakis The scope of this report is to propose an architecture of Boltzmann machines that could be used in the context of classification,
Robust Classification using Boltzmann machines by Vasileios Vasilakakis The scope of this report is to propose an architecture of Boltzmann machines that could be used in the context of classification,
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Modeling Documents with a Deep Boltzmann Machine
 Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava, Ruslan Salakhutdinov & Geoffrey Hinton UAI 2013 Presented by Zhe Gan, Duke University November 14, 2014 1 / 15 Outline Replicated Softmax
Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava, Ruslan Salakhutdinov & Geoffrey Hinton UAI 2013 Presented by Zhe Gan, Duke University November 14, 2014 1 / 15 Outline Replicated Softmax
Autoencoders and Score Matching. Based Models. Kevin Swersky Marc Aurelio Ranzato David Buchman Benjamin M. Marlin Nando de Freitas
 On for Energy Based Models Kevin Swersky Marc Aurelio Ranzato David Buchman Benjamin M. Marlin Nando de Freitas Toronto Machine Learning Group Meeting, 2011 Motivation Models Learning Goal: Unsupervised
On for Energy Based Models Kevin Swersky Marc Aurelio Ranzato David Buchman Benjamin M. Marlin Nando de Freitas Toronto Machine Learning Group Meeting, 2011 Motivation Models Learning Goal: Unsupervised
Stochastic Gradient Estimate Variance in Contrastive Divergence and Persistent Contrastive Divergence
 ESANN 0 proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning. Bruges (Belgium), 7-9 April 0, idoc.com publ., ISBN 97-7707-. Stochastic Gradient
ESANN 0 proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning. Bruges (Belgium), 7-9 April 0, idoc.com publ., ISBN 97-7707-. Stochastic Gradient
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Deep Learning Architecture for Univariate Time Series Forecasting
 CS229,Technical Report, 2014 Deep Learning Architecture for Univariate Time Series Forecasting Dmitry Vengertsev 1 Abstract This paper studies the problem of applying machine learning with deep architecture
CS229,Technical Report, 2014 Deep Learning Architecture for Univariate Time Series Forecasting Dmitry Vengertsev 1 Abstract This paper studies the problem of applying machine learning with deep architecture
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
arxiv: v3 [cs.lg] 18 Mar 2013
![arxiv: v3 [cs.lg] 18 Mar 2013](/thumbs/72/67390553.jpg "arxiv: v3 [cs.lg] 18 Mar 2013") Hierarchical Data Representation Model - Multi-layer NMF arxiv:1301.6316v3 [cs.lg] 18 Mar 2013 Hyun Ah Song Department of Electrical Engineering KAIST Daejeon, 305-701 hyunahsong@kaist.ac.kr Abstract Soo-Young
Hierarchical Data Representation Model - Multi-layer NMF arxiv:1301.6316v3 [cs.lg] 18 Mar 2013 Hyun Ah Song Department of Electrical Engineering KAIST Daejeon, 305-701 hyunahsong@kaist.ac.kr Abstract Soo-Young
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
An Efficient Learning Procedure for Deep Boltzmann Machines
 ARTICLE Communicated by Yoshua Bengio An Efficient Learning Procedure for Deep Boltzmann Machines Ruslan Salakhutdinov rsalakhu@utstat.toronto.edu Department of Statistics, University of Toronto, Toronto,
ARTICLE Communicated by Yoshua Bengio An Efficient Learning Procedure for Deep Boltzmann Machines Ruslan Salakhutdinov rsalakhu@utstat.toronto.edu Department of Statistics, University of Toronto, Toronto,
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Restricted Boltzmann Machines for Collaborative Filtering
 Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Feature Design. Feature Design. Feature Design. & Deep Learning
 Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
CENG 783. Special topics in. Deep Learning. AlchemyAPI. Week 14. Sinan Kalkan
 CENG 783 Special topics in Deep Learning AlchemyAPI Week 14 Sinan Kalkan Today Hopfield Networks Boltzmann Machines Deep BM, Restricted BM Generative Adversarial Networks Variational Auto-encoders Autoregressive
CENG 783 Special topics in Deep Learning AlchemyAPI Week 14 Sinan Kalkan Today Hopfield Networks Boltzmann Machines Deep BM, Restricted BM Generative Adversarial Networks Variational Auto-encoders Autoregressive
Restricted Boltzmann Machines
 Restricted Boltzmann Machines Boltzmann Machine(BM) A Boltzmann machine extends a stochastic Hopfield network to include hidden units. It has binary (0 or 1) visible vector unit x and hidden (latent) vector
Restricted Boltzmann Machines Boltzmann Machine(BM) A Boltzmann machine extends a stochastic Hopfield network to include hidden units. It has binary (0 or 1) visible vector unit x and hidden (latent) vector
10. Artificial Neural Networks
 Foundations of Machine Learning CentraleSupélec Fall 217 1. Artificial Neural Networks Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning
Foundations of Machine Learning CentraleSupélec Fall 217 1. Artificial Neural Networks Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning
RegML 2018 Class 8 Deep learning
 RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
Ruslan Salakhutdinov Joint work with Geoff Hinton. University of Toronto, Machine Learning Group
 NON-LINEAR DIMENSIONALITY REDUCTION USING NEURAL NETORKS Ruslan Salakhutdinov Joint work with Geoff Hinton University of Toronto, Machine Learning Group Overview Document Retrieval Present layer-by-layer
NON-LINEAR DIMENSIONALITY REDUCTION USING NEURAL NETORKS Ruslan Salakhutdinov Joint work with Geoff Hinton University of Toronto, Machine Learning Group Overview Document Retrieval Present layer-by-layer
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Variational Autoencoders. Presented by Alex Beatson Materials from Yann LeCun, Jaan Altosaar, Shakir Mohamed
 Variational Autoencoders Presented by Alex Beatson Materials from Yann LeCun, Jaan Altosaar, Shakir Mohamed Contents 1. Why unsupervised learning, and why generative models? (Selected slides from Yann
Variational Autoencoders Presented by Alex Beatson Materials from Yann LeCun, Jaan Altosaar, Shakir Mohamed Contents 1. Why unsupervised learning, and why generative models? (Selected slides from Yann
The connection of dropout and Bayesian statistics
 The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
Knowledge Extraction from Deep Belief Networks for Images
 Knowledge Extraction from Deep Belief Networks for Images Son N. Tran City University London Northampton Square, ECV 0HB, UK Son.Tran.@city.ac.uk Artur d Avila Garcez City University London Northampton
Knowledge Extraction from Deep Belief Networks for Images Son N. Tran City University London Northampton Square, ECV 0HB, UK Son.Tran.@city.ac.uk Artur d Avila Garcez City University London Northampton
Reward-modulated inference
 Buck Shlegeris Matthew Alger COMP3740, 2014 Outline Supervised, unsupervised, and reinforcement learning Neural nets RMI Results with RMI Types of machine learning supervised unsupervised reinforcement
Buck Shlegeris Matthew Alger COMP3740, 2014 Outline Supervised, unsupervised, and reinforcement learning Neural nets RMI Results with RMI Types of machine learning supervised unsupervised reinforcement
Introduction to Restricted Boltzmann Machines
 Introduction to Restricted Boltzmann Machines Ilija Bogunovic and Edo Collins EPFL {ilija.bogunovic,edo.collins}@epfl.ch October 13, 2014 Introduction Ingredients: 1. Probabilistic graphical models (undirected,
Introduction to Restricted Boltzmann Machines Ilija Bogunovic and Edo Collins EPFL {ilija.bogunovic,edo.collins}@epfl.ch October 13, 2014 Introduction Ingredients: 1. Probabilistic graphical models (undirected,
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Auto-Encoding Variational Bayes
 Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Sum-Product Networks: A New Deep Architecture
 Sum-Product Networks: A New Deep Architecture Pedro Domingos Dept. Computer Science & Eng. University of Washington Joint work with Hoifung Poon 1 Graphical Models: Challenges Bayesian Network Markov Network
Sum-Product Networks: A New Deep Architecture Pedro Domingos Dept. Computer Science & Eng. University of Washington Joint work with Hoifung Poon 1 Graphical Models: Challenges Bayesian Network Markov Network
Deep Learning: a gentle introduction
 Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why