A summary of Deep Learning without Poor Local Minima
|
|
|
- Pauline Stone
- 5 years ago
- Views:
Transcription
1 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016
2 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given a labeled set of input-ouput pairs (the training set) D n = {(X i, Y i ), i = 1,..., n} We learn the classification function f = 1 if versicolor, f = 1 if virginica 1
 classification (type, mode, etc) y is a non-deterministic and")
3 Supervised learning Training set: D n = {(X i, Y i ), i = 1,..., n} - Input features: X i R d - Output: Y i Y i Y { R finite regression (price, position, etc) classification (type, mode, etc) y is a non-deterministic and complicated function of x i.e., y = f(x, z) where z is unknown (e.g. noise). Goal: learn f. Learning algorithm: 2
4 Objectives Empirical risk: ˆR(f) := 1 n n i=1 f(x i) Y i 2 2. Look for the mapping in a class of functions F that minimizes the risk (or a regularized version of it): f arg min f F ˆR(f). 3

5 Neural networks Loosely inspired by how the brain works 1. Construct a network of simplified neurones, with the hope of approximating and learning any possible function 1 Mc Culloch-Pitts,
6 The perceptron The first artificial neural network with one layer, and σ(x) = sgn(x) (classification) Input x R d, output in { 1, 1}. Can represent separating hyperplanes. 5
7 Multilayer perceptrons They can represent any function of R d to { 1, 1}... but the structure depends on the unknown target function f, and is difficult to optimise 6
8 From perceptrons to neural networks... and the number of layers can rapidly grow with the complexity of the function A key idea to make neural networks practical: soft-thresholding... 7
9 Soft-thresholding Replace hard-thresholding function σ by smoother functions Theorem (Cybenko 1989) Any continuous function f from [0, 1] d to R can be approximated as a function of the form: N j=1 α jσ(w j x + b j), where σ is any sigmoid function. 8
10 Soft-thresholding Cybenko s theorem tells us that f can be represented using a single hidden layer network... A non-constructive proof: how many neurones do we need? Might depend on f... 9
")
11 Neural networks A feedforward layered network (deep learning = enough layers) 10
12 Deep Learning and the ILSVR challenge Deep learning outperformed any other techniques in all major machine learning competitions (image classification, speech recognition and natural language processing) The ImageNet Large Scale Visual Recognition Challenge (ILSVRC). 1. Training: 1.2 million images ( ), labeled one out of 1000 categories 2. Test: images ( ) 3. Error measure: The teams have to predict 5 (out of 1000) classes and an image is considered to be correct if at least one of the predictions is the ground truth. 2 11

13 ILSVR challenge 1 From Stanford CS231n lecture notes 12
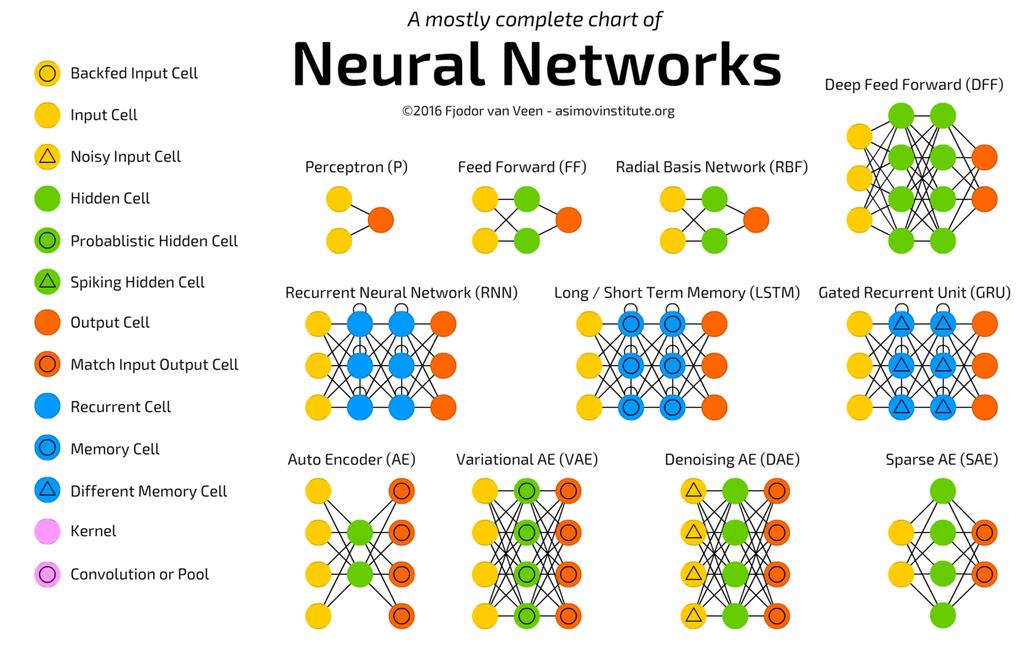
14 Architectures 13
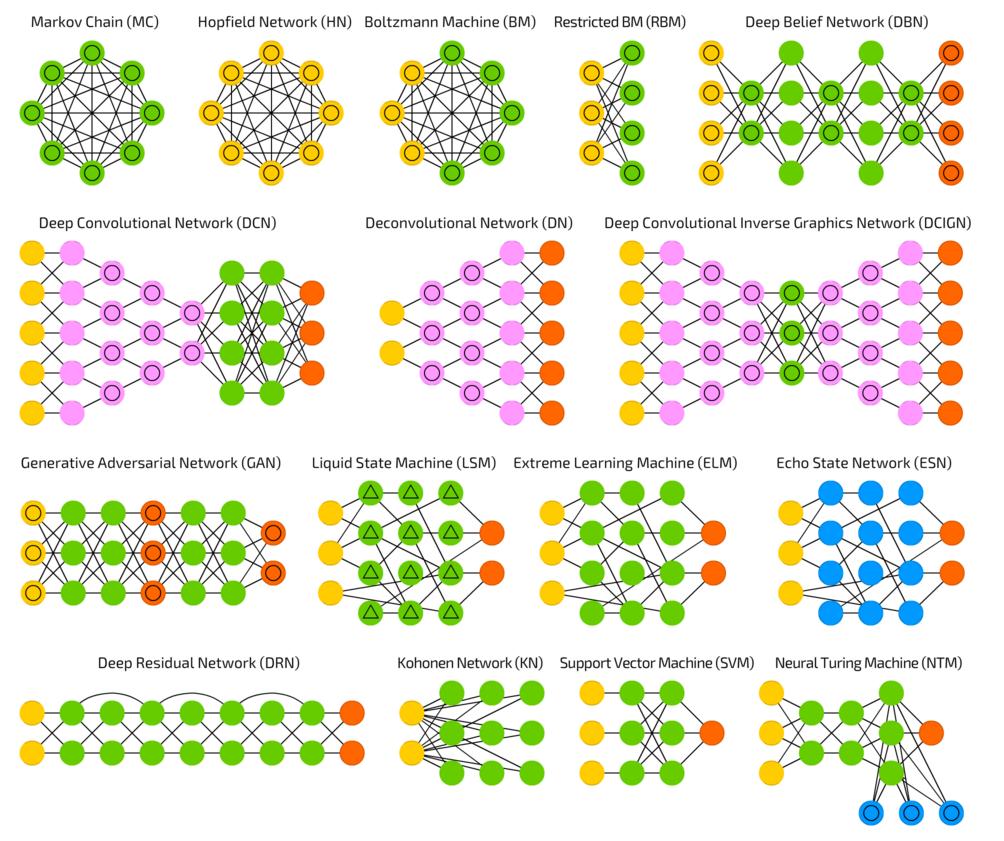
15 Architectures 14
16 Computing with neural networks Layer 0: inputs x = (x (0) 1,..., x(0) ) and x(0) 0 = 1 x (l) i d Layer 1,..., L 1: hidden layer l, d (l) + 1 nodes, state of node i, with x (l) 0 = 1 Layer L: output y = x (L) 1 Signal at k: s (l) k State at k: x (l) k = d (l 1) i=0 w (l) ik x(l 1) i = σ(s (l) k ) Output: the state of y = x (L) 1 15
17 Training neural networks The output of the network is a function of w = (w (l) ij ) i,j,l: y = f w (x) We wish to optimise over w to find the most accurate estimation of the target function Training data: (X 1, Y 1 ),..., (X n, Y n ) R d { 1, 1} Objective: find w minimising the empirical risk: E(w) := R(f w ) = 1 2n n f w (X l ) Y l 2 l=1 16
18 Stochastic Gradient Descent E(w) = 1 n 2n l=1 E l(w) where E l (w) := f w (X l ) Y l 2 In each iteration of the SGD algorithm, only one function E l is considered... Parameter. learning rate α > 0 1. Initialization. w := w 0 2. Sample selection. Select l uniformly at random in {1,..., n} 3. GD iteration. w := w α E l (w), go to 2. Is there an efficient way of computing E l (w)? 17
19 Backpropagation We fix l, and introduce e(w) = E l (w). Let us compute e(w): e w (l) ij = e s (l) j }{{} :=δ (l) j s(l) j w (l) ij }{{} =x (l 1) i The sensitivity of the error w.r.t. the signal at node j can be computed recursively... 18
20 Backward recursion Output layer. δ (L) 1 := e s (L) 1 From layer l to layer l 1. δ (l 1) i := e = s (l 1) i and e(w) = (σ(s (L) 1 ) Y l ) 2 δ (L) 1 = 2(x (L) 1 Y l )σ (s (L) 1 ) d (l) j=1 e s (l) j }{{} :=δ (l) j s(l) j x (l 1) i }{{} =w (l) ij x(l 1) i s (l 1) i }{{} =σ (s (l 1) i ) Summary. E l w (l) ij d (l) = δ (l) j x (l 1) i, δ (l 1) i = j=1 δ (l) j w (l) ij σ (s (l 1) i ) 19
21 Backpropagation algorithm Parameter. Learning rate α > 0 Input. (X 1, Y 1 ),..., (X n, Y n ) R d { 1, 1} 1. Initialization. w := w 0 2. Sample selection. Select l uniformly at random in {1,..., n} 3. Gradient of E l. x (0) i := X li for all i = 1,... d Forward propagation: compute the state and signal at each node (x (l) i, s (l) i ) Backward propagation: propagate back Y l to compute δ (l) at each node and the partial derivative E l w (l) ij 4. GD iteration. w := w α E l (w), go to 2. i 20

22 Example: tensorflow 21
23 Deep Learning without Local Minima Critical question: The SGD algorithm will converge to a global minimum of the risk, if we can guarantee that local minima have the same risk as a global minimum. What does the loss surface look like? Related work: P. Baldi, K. Hornik. Neural Networks and PCA: Learning from Examples without Local Minima. Neural Networks, I. Goodfellow, Y. Bengio, A. Courville. Deep Learning, A. Choromanska et al.. The Loss Surface of Multilayer Networks. ICML
24 Notations Data: X i R dx, Y i R dy, m data points X: d x m matrix whose columns are the X i s Y : d y m matrix whose columns are the Y i s H hidden layers Layer k with d k neurons, input weight matrix W k R d k d k 1 p = min{d 1,..., d H } Output: Ŷ (W, X) = qσ H+1 (W H+1 σ(w H σ(w H σ(W 2 σ(w 1 X)...) Linear activation function: Ŷ (W, X) = W H+1... W 1 X. 23
25 Baldi-Hornik: 1-hidden linear networks Linear regression: fitting a linear model to the data. X i R dx, Y i R dy. Find the matrix L R dy dx minimizing L(L) = m i=1 Y i LX i 2 2. When XX is invertible, L is equal to L = Y X (XX ) 1. Convexity of L. Now in a 1-hidden layer network, we are looking for L that can be factorized as W 2 W 1 where W 1 R p dx and W 2 R dy p. In particular the rank of L is at most p. Non uniqueness: W 1 = CW 1 and W 2 = W 2 C 1 work as well. 24
26 Baldi-Hornik: 1-hidden linear networks Define the d y d y matrix Σ = Y X (XX ) 1 XY (covariance matrix of the best unconstrained linear approximation of Y ). d x = d y. Theorem (Baldi-Hornik 1989) Assume that Σ is full rank, and has d y distinct eigenvalues λ 1 >... > λ dy. Let W 1 and W 2 define a critical point of L(W 1, W 2 ). Then there exists a subset Γ of p (orthonormal) eigenvectors of Σ, and a p p invertible matrix C such that: W 2 = U Γ C, W 1 = C 1 U Γ Y X (XX ) 1, where U Γ is the matrix formed by the eigenvectors in Γ. Moreover L(W 1, W 2 ) = trace(y Y ) i Γ λ i. 25
27 Baldi-Hornik: 1-hidden linear networks Theorem (Baldi-Hornik 1989) Assume that Σ is full rank, and has d y distinct eigenvalues λ 1 >... > λ dy. Let W 1 and W 2 define a critical point of L(W 1, W 2 ). Then there exists a subset Γ of p (orthonormal) eigenvectors of Σ, and a p p invertible matrix C such that: W 2 = U Γ C, W 1 = C 1 U Γ Y X (XX ) 1, where U Γ is the matrix formed by the eigenvectors in Γ. Moreover L(W 1, W 2 ) = trace(y Y ) i Γ λ i. Up to C, the global minimizer is unique, and is the projection on the subspace spanned by the p top eigenvectors of Σ of the ordinary least square regression matrix! Taking an other set of eigenvectors for the projection yields a saddle point. 26
28 This paper: networks with any depth and width Theorem (Kawaguchi 2016) Assume that XX and XY are full rank, d x d y. Assume that Σ is full rank, and has d y distinct eigenvalues. The loss function L(W 1,..., W H+1 ) satisfies: (i) it is non-convex and non-concave. (ii) Every local minimum is a global minimum. (iii) Every critical point that is not a minimum is a saddle point. (iv) If rank(w H,..., W 2 ) = p, then the Hessian at any saddle point has at least one strictly negative eigenvalue. 27
29 Proof sketch: example Assume that W is a critical point and a local minimum, and that rank(w H... W 2 ) = p Necessary conditions: L = 0 and 2 L positive semidefinite. From the latter conditions, we deduce that X(Ŷ (W, X) Y ) = 0. Go back to the unconstrained linear case: f(w ) = W X Y 2 F for W R dy dx. Let r = (W X Y ) denote the error matrix. By convexity, if Xr = 0 then W is a global minimizer of f. Now with W = W H+1... W 1, we have Xr = Xr = 0, and hence W is a global minimizer of f. 28
30 This paper: non-linear networks with any depth and width Rectified linear activation function: σ(x) = max(0, x). Output: Ŷ (W, X) = qσ H+1 (W H+1 σ(w H σ(w H σ(W 2 σ(w 1 X)...) An other way of writing the output: Ŷ (W, X) = q d x i=1 j=1 γ X i,j A i,j H k=1 W (k) i,j, where the first sum is voer the input coordinates, the second sum is on the path from the i-th input to the output, X i,j = X i,1 for all j is the i-th input, and A i,j is the activation (binary variable) of the path j for input i 29
31 This paper: non-linear networks with any depth and width Critical simplification: the A i,j s are independent Bernoulli r.v. with mean ρ! Under this assumption (among others), there is an equivalence with a linear network. The previous theorem holds... 30
32 Summary SGD could well find global minimizer of the empirical risk, under some conditions... What is the impact of regularization? What about other activation functions? 31
Bits of Machine Learning Part 1: Supervised Learning
 Bits of Machine Learning Part 1: Supervised Learning Alexandre Proutiere and Vahan Petrosyan KTH (The Royal Institute of Technology) Outline of the Course 1. Supervised Learning Regression and Classification
Bits of Machine Learning Part 1: Supervised Learning Alexandre Proutiere and Vahan Petrosyan KTH (The Royal Institute of Technology) Outline of the Course 1. Supervised Learning Regression and Classification
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
Machine Learning
 Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Advanced Machine Learning
 Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Machine Learning
 Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Understanding Neural Networks : Part I
 TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Learning Deep Architectures for AI. Part I - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part I - Vijay Chakilam Chapter 0: Preliminaries Neural Network Models The basic idea behind the neural network approach is to model the response as a
Learning Deep Architectures for AI - Yoshua Bengio Part I - Vijay Chakilam Chapter 0: Preliminaries Neural Network Models The basic idea behind the neural network approach is to model the response as a
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Introduction to Machine Learning Spring 2018 Note Neural Networks
 CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Artificial Neural Networks
 Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Neural networks COMS 4771
 Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Multilayer Perceptrons and Backpropagation
 Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 03: Multi-layer Perceptron Outline Failure of Perceptron Neural Network Backpropagation Universal Approximator 2 Outline Failure of Perceptron Neural Network Backpropagation
CS489/698: Intro to ML Lecture 03: Multi-layer Perceptron Outline Failure of Perceptron Neural Network Backpropagation Universal Approximator 2 Outline Failure of Perceptron Neural Network Backpropagation
Mark Gales October y (x) x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.
 x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.") University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 6: Multi-Layer Perceptrons I
 Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 6: Multi-Layer Perceptrons I Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 2012 Engineering Part IIB: Module 4F10 Introduction In
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 6: Multi-Layer Perceptrons I Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 2012 Engineering Part IIB: Module 4F10 Introduction In
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
AN INTRODUCTION TO NEURAL NETWORKS. Scott Kuindersma November 12, 2009
 AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
Neural Networks. Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016
 Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Nonlinear Models. Numerical Methods for Deep Learning. Lars Ruthotto. Departments of Mathematics and Computer Science, Emory University.
 Nonlinear Models Numerical Methods for Deep Learning Lars Ruthotto Departments of Mathematics and Computer Science, Emory University Intro 1 Course Overview Intro 2 Course Overview Lecture 1: Linear Models
Nonlinear Models Numerical Methods for Deep Learning Lars Ruthotto Departments of Mathematics and Computer Science, Emory University Intro 1 Course Overview Intro 2 Course Overview Lecture 1: Linear Models
Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville
 Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville Chapter 6 :Deep Feedforward Networks Benoit Massé Dionyssos Kounades-Bastian Benoit Massé, Dionyssos Kounades-Bastian Deep Feedforward
Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville Chapter 6 :Deep Feedforward Networks Benoit Massé Dionyssos Kounades-Bastian Benoit Massé, Dionyssos Kounades-Bastian Deep Feedforward
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Advanced computational methods X Selected Topics: SGD
 Advanced computational methods X071521-Selected Topics: SGD. In this lecture, we look at the stochastic gradient descent (SGD) method 1 An illustrating example The MNIST is a simple dataset of variety
Advanced computational methods X071521-Selected Topics: SGD. In this lecture, we look at the stochastic gradient descent (SGD) method 1 An illustrating example The MNIST is a simple dataset of variety
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Introduction to Deep Learning
 Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods.
 Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
NEURAL NETWORKS
 5 Neural Networks In Chapters 3 and 4 we considered models for regression and classification that comprised linear combinations of fixed basis functions. We saw that such models have useful analytical
5 Neural Networks In Chapters 3 and 4 we considered models for regression and classification that comprised linear combinations of fixed basis functions. We saw that such models have useful analytical
Machine Learning (CSE 446): Backpropagation
: Backpropagation") Machine Learning (CSE 446): Backpropagation Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 8, 2017 1 / 32 Neuron-Inspired Classifiers correct output y n L n loss hidden units
Machine Learning (CSE 446): Backpropagation Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 8, 2017 1 / 32 Neuron-Inspired Classifiers correct output y n L n loss hidden units
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
Unit 8: Introduction to neural networks. Perceptrons
 Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Non-Convex Optimization in Machine Learning. Jan Mrkos AIC
 Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Introduction to (Convolutional) Neural Networks
 Neural Networks") Introduction to (Convolutional) Neural Networks Philipp Grohs Summer School DL and Vis, Sept 2018 Syllabus 1 Motivation and Definition 2 Universal Approximation 3 Backpropagation 4 Stochastic Gradient
Introduction to (Convolutional) Neural Networks Philipp Grohs Summer School DL and Vis, Sept 2018 Syllabus 1 Motivation and Definition 2 Universal Approximation 3 Backpropagation 4 Stochastic Gradient
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Machine Learning. Neural Networks. Le Song. CSE6740/CS7641/ISYE6740, Fall Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Machine Learning (CSE 446): Neural Networks
: Neural Networks") Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
J. Sadeghi E. Patelli M. de Angelis
 J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Introduction to Deep Learning
 Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2014 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2014 1 / 35 Outline 1 Universality of Neural Networks
Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2014 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2014 1 / 35 Outline 1 Universality of Neural Networks
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Nets Supervised learning
 6.034 Artificial Intelligence Big idea: Learning as acquiring a function on feature vectors Background Nearest Neighbors Identification Trees Neural Nets Neural Nets Supervised learning y s(z) w w 0 w
6.034 Artificial Intelligence Big idea: Learning as acquiring a function on feature vectors Background Nearest Neighbors Identification Trees Neural Nets Neural Nets Supervised learning y s(z) w w 0 w
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
2018 EE448, Big Data Mining, Lecture 5. (Part II) Weinan Zhang Shanghai Jiao Tong University
 Weinan Zhang Shanghai Jiao Tong University") 2018 EE448, Big Data Mining, Lecture 5 Supervised Learning (Part II) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
2018 EE448, Big Data Mining, Lecture 5 Supervised Learning (Part II) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
Tutorial on Machine Learning for Advanced Electronics
 Tutorial on Machine Learning for Advanced Electronics Maxim Raginsky March 2017 Part I (Some) Theory and Principles Machine Learning: estimation of dependencies from empirical data (V. Vapnik) enabling
Tutorial on Machine Learning for Advanced Electronics Maxim Raginsky March 2017 Part I (Some) Theory and Principles Machine Learning: estimation of dependencies from empirical data (V. Vapnik) enabling
UNDERSTANDING LOCAL MINIMA IN NEURAL NET-
 UNDERSTANDING LOCAL MINIMA IN NEURAL NET- WORKS BY LOSS SURFACE DECOMPOSITION Anonymous authors Paper under double-blind review ABSTRACT To provide principled ways of designing proper Deep Neural Network
UNDERSTANDING LOCAL MINIMA IN NEURAL NET- WORKS BY LOSS SURFACE DECOMPOSITION Anonymous authors Paper under double-blind review ABSTRACT To provide principled ways of designing proper Deep Neural Network
Neural Networks. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Machine Learning. Lecture 04: Logistic and Softmax Regression. Nevin L. Zhang
 Machine Learning Lecture 04: Logistic and Softmax Regression Nevin L. Zhang lzhang@cse.ust.hk Department of Computer Science and Engineering The Hong Kong University of Science and Technology This set
Machine Learning Lecture 04: Logistic and Softmax Regression Nevin L. Zhang lzhang@cse.ust.hk Department of Computer Science and Engineering The Hong Kong University of Science and Technology This set
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
MLPR: Logistic Regression and Neural Networks
 MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
Artificial Neuron (Perceptron)
") 9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where