The Success of Deep Generative Models
|
|
|
- Daniela Pearl Porter
- 5 years ago
- Views:
Transcription
1 The Success of Deep Generative Models Jakub Tomczak AMLAB, University of Amsterdam CERN, 2018
2 What is AI about?
3 What is AI about? Decision making:
4 What is AI about? Decision making: new data High probability of the red label. = Highly probable decision!
5 What is AI about? Decision making: Understanding: new data High probability of the red label. = Highly probable decision!

6 What is AI about? new data Decision making: High probability of the red label. = Highly probable decision! Understanding: High probability of the red label. x Low probability of the object = Uncertain decision!
7 What is generative modeling about? Understanding: finding underlying factors (discovery) detecting rare events (anomaly detection) predicting and anticipating future events (planning) finding analogies (transfer learning) decision making
8 Why generative modeling? Why? Uncertainty Less labeled data Data simulation Hidden structure Compression Exploration
9 Generative modeling: How? How? Fully-observed (e.g., PixelCNN) Latent variable models Implicit models (e.g., GANs) Prescribed models (e.g., VAE)

10 Recent successes: Style transfer Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. CVPR 2017.


11 Recent successes: Image generation generated real Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2017). Progressive growing of gans for improved quality, stability, and variation. ICLR 2017.


12 Recent successes: Text generation Yang, Z., Hu, Z., Salakhutdinov, R., & Berg-Kirkpatrick, T. (2017). Improved variational autoencoders for text modeling using dilated convolutions. ICML 2017
13 Recent successes: Audio generation reconstruction van den Oord, A., & Vinyals, O. (2017). Neural discrete representation learning. NIPS generation


14 Recent successes: Reinforcement learning Ha, D., & Schmidhuber, J. (2018). World models. arxiv preprint. arxiv preprint arxiv:

15 Recent successes: Drug discovery Gómez-Bombarelli, R., et al. (2018). Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules ACS Cent. Kusner, M. J., Paige, B., & Hernández-Lobato, J. M. (2017). Grammar variational autoencoder. arxiv preprint arxiv:
 Kipf, T., Fetaya, E., Wang, K. C.")

16 Recent successes: Physics (interacting systems) Kipf, T., Fetaya, E., Wang, K. C., Welling, M., & Zemel, R. (2018). Neural relational inference for interacting systems. ICML 2018.

. Wavenet: A generative model for raw audio.")
17 Generative modeling: Auto-regressive models General idea is to factorise the joint distribution: and use neural networks (e.g., convolutional NN) to model it efficiently: Van Den Oord, A., et al. (2016). Wavenet: A generative model for raw audio. arxiv preprint arxiv:
18 Generative modeling: Latent Variable Models We assume data lies on a low-dimensional manifold so the generator is: where: Two main approaches: Generative Adversarial Networks (GANs) Variational Auto-Encoders (VAEs)
19 Generative modeling: GANs We assume a deterministic generator: and a prior over latent space:
20 Generative modeling: GANs We assume a deterministic generator: and a prior over latent space: How to train it?
21 Generative modeling: GANs We assume a deterministic generator: and a prior over latent space: How to train it? By using a game!
22 Generative modeling: GANs We assume a deterministic generator: and a prior over latent space: How to train it? By using a game! For this purpose, we assume a discriminator:
23 Generative modeling: GANs The learning process is as follows: the generator tries to fool the discriminator; the discriminator tries to distinguish between the real and fake images. We define the learning problem as a min-max problem: In fact, we have a learnable loss function! Goodfellow, I., et al. (2014). Generative adversarial nets. NIPS 2014
24 Generative modeling: GANs The learning process is as follows: the generator tries to fool the discriminator; the discriminator tries to distinguish between the real and fake images. We define the learning problem as a min-max problem: In fact, we have a learnable loss function! It learns high-order statistics. Goodfellow, I., et al. (2014). Generative adversarial nets. NIPS 2014
25 Generative modeling: GANs
26 Generative modeling: GANs Pros: we don t need to specify a likelihood function; very flexible; the loss function is trainable; perfect for data simulation. Cons: we don t know the distribution; training is highly unstable (min-max objective); missing mode problem.
27 Generative modeling: VAEs We assume a stochastic generator (decoder): and a prior over latent space:
28 Generative modeling: VAEs We assume a stochastic generator (decoder): and a prior over latent space: Additionally, we use a variational posterior (encoder):
29 Generative modeling: VAEs We assume a stochastic generator (decoder): and a prior over latent space: Additionally, we use a variational posterior (encoder): How to train it?
: How to train it?")
30 Generative modeling: VAEs We assume a stochastic generator (decoder): and a prior over latent space: Additionally, we use a variational posterior (encoder): How to train it? Using the log-likelihood function!
31 Variational inference for Latent Variable Models
32 Variational inference for Latent Variable Models Variational posterior
33 Variational inference for Latent Variable Models Jensen s inequality
34 Variational inference for Latent Variable Models Reconstruction error Regularization
35 Variational inference for Latent Variable Models decoder encoder prior
36 Variational inference for Latent Variable Models decoder (Neural Net) encoder (Neural Net) prior + reparameterization trick = Variational Auto-Encoder Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arxiv preprint arxiv: (ICLR 2014)
37 Variational Auto-Encoder (Encoding-Decoding)
38 Variational Auto-Encoder (Encoding-Decoding)
39 Variational Auto-Encoder (Encoding-Decoding)
40 Variational Auto-Encoder (Encoding-Decoding)
41 Variational Auto-Encoder (Generating)
42 Variational Auto-Encoder: Extensions Normalizing flows Volume-preserving flows non-gaussian distributions Importance Weighted AE Renyi Divergence Stein Divergence Fully-connected ConvNets PixelCNN Other Autoregressive Prior Objective Prior Stick-Breaking Prior VampPrior Tomczak, J. M., & Welling, M. (2016). Improving variational auto-encoders using householder flow. NIPS Workshop Berg, R. V. D., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference. UAI Tomczak, J. M., & Welling, M. (2017). VAE with a VampPrior. arxiv preprint arxiv: (AISTATS 2018) Davidson, T. R., Falorsi, L., De Cao, N., Kipf, T., & Tomczak, J. M. (2018). Hyperspherical Variational Auto-Encoders. UAI 2018.
43 Generative modeling: VAEs Pros: we know the distribution and can calculate the likelihood function; we can encode an object in a low-dim manifold (compression); training is stable; no missing modes. Cons: we need know the distribution; we need a flexible encoder and prior; blurry images (so far ).
44 Generative modeling: VAEs (extensions) Normalizing flows Intro Householder flow Sylvester flow VampPrior
45 Conclusion Generative modeling: the way to go to achieve AI. Deep generative modeling: very successful in recent years in many domains. Two main approaches: GANs and VAEs. Next steps: video processing, better priors and decoders, geometric methods,
46 Conclusion Generative modeling: the way to go to achieve AI. Deep generative modeling: very successful in recent years in many domains. Two main approaches: GANs and VAEs. Next steps: video processing, better priors and decoders, geometric methods,
47 Conclusion Generative modeling: the way to go to achieve AI. Deep generative modeling: very successful in recent years in many domains. Two main approaches: GANs and VAEs. Next steps: video processing, better priors and decoders, geometric methods,
48 Conclusion Generative modeling: the way to go to achieve AI. Deep generative modeling: very successful in recent years in many domains. Two main approaches: GANs and VAEs. Next steps: video processing, better priors and decoders, geometric methods,
49 Conclusion Generative modeling: the way to go to achieve AI. Deep generative modeling: very successful in recent years in many domains. Two main approaches: GANs and VAEs. Next steps: video processing, better priors and decoders, geometric methods,

50 Code on github: Webpage: Contact: The research conducted by Jakub M. Tomczak was funded by the European Commission within the Marie Skłodowska-Curie Individual Fellowship (Grant No , Deep learning and Bayesian inference for medical imaging ).
51 APPENDIX
52 Variational Auto-Encoder Normalizing flows Volume-preserving flows non-gaussian distributions
. Variational inference with normalizing flows.")
53 Improving posterior using Normalizing Flows Diagonal posterior - insufficient and inflexible. How to get more flexible posterior? Apply a series of T invertible transformations New objective: Rezende, D. J., & Mohamed, S. (2015). Variational inference with normalizing flows. arxiv preprint arxiv: ICML 2015
. Variational inference with normalizing flows.")
54 Improving posterior using Normalizing Flows Diagonal posterior - insufficient and inflexible. How to get more flexible posterior? Apply a series of T invertible transformations New objective: Change of variables: Rezende, D. J., & Mohamed, S. (2015). Variational inference with normalizing flows. arxiv preprint arxiv: ICML 2015
. Variational inference with normalizing flows.")
55 Improving posterior using Normalizing Flows Diagonal posterior - insufficient and inflexible. How to get more flexible posterior? Apply a series of T invertible transformations New objective: Rezende, D. J., & Mohamed, S. (2015). Variational inference with normalizing flows. arxiv preprint arxiv: ICML 2015
56 Improving posterior using Normalizing Flows Diagonal posterior - insufficient and inflexible. How to get more flexible posterior? Apply a series of T invertible transformations New objective: Rezende, D. J., & Mohamed, S. (2015). Variational inference with normalizing flows. arxiv preprint arxiv: ICML 2015
57 Improving posterior using Normalizing Flows Diagonal posterior - insufficient and inflexible. How to get more flexible posterior? Apply a series of T invertible transformations New objective: Jacobian determinant: (i) general normalizing flow ( det J is easy to calculate); (ii) volume-preserving flow, i.e., det J = 1. Rezende, D. J., & Mohamed, S. (2015). Variational inference with normalizing flows. arxiv preprint arxiv: ICML 2015
58 BACK Volume-preserving flows How to obtain more flexible posterior and preserve det J =1? Model full-covariance posterior using orthogonal matrices. Proposition: Apply a linear transformation: and since U is orthogonal, Jacobian-determinant is 1. Question: Is it possible to model an orthogonal matrix efficiently? Tomczak, J. M., & Welling, M. (2016). Improving Variational Inference with Householder Flow. arxiv preprint arxiv: NIPS Workshop on Bayesian Deep Learning 2016
59 Householder Flow How to obtain more flexible posterior and preserve det J =1? Model full-covariance posterior using orthogonal matrices. Proposition: Apply a linear transformation: and since U is orthogonal, Jacobian-determinant is 1. Question: Is it possible to model an orthogonal matrix efficiently? Tomczak, J. M., & Welling, M. (2016). Improving Variational Inference with Householder Flow. arxiv preprint arxiv: NIPS Workshop on Bayesian Deep Learning 2016
60 Householder Flow Theorem How to obtain more flexible posterior and preserve det J =1? Any orthogonal matrix with the basis acting on the K-dimensional subspace Model full-covariance posterior using orthogonal can be expressed as a product of exactly Kmatrices. Householder transformations. Proposition: Apply a linear transformation: Sun, X., & Bischof, C. (1995). A basis-kernel representation of orthogonal matrices. SIAM Journal on Matrix Analysis and Applications, 16(4), and since U is orthogonal, Jacobian-determinant would be 1. Question: Is it possible to model an orthogonal matrix efficiently? YES Tomczak, J. M., & Welling, M. (2016). Improving Variational Inference with Householder Flow. arxiv preprint arxiv: NIPS Workshop on Bayesian Deep Learning 2016
. Tomczak, J. M., & Welling, M. (2016). Improving Variational Inference with Householder Flow. arxiv preprint arxiv:1611.09630.")
61 Householder Flow In the Householder transformation we reflect a vector around a hyperplane defined by a Householder vector Very efficient: small number of parameters, J =1, easy amortization (!). Tomczak, J. M., & Welling, M. (2016). Improving Variational Inference with Householder Flow. arxiv preprint arxiv: NIPS Workshop on Bayesian Deep Learning 2016
62 Householder Flow (MNIST) Method ELBO VAE VAE+HF(T=1) VAE+HF(T=10) VAE+NICE(T=10) Volume-preserving VAE+NICE(T=80) VAE+HVI(T=1) VAE+HVI(T=8) VAE+PlanarFlow(T=10) VAE+PlanarFlow(T=80) Non-linear Tomczak, J. M., & Welling, M. (2016). Improving Variational Inference with Householder Flow. arxiv preprint arxiv: NIPS Workshop on Bayesian Deep Learning 2016
63 BACK General normalizing flow van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
64 Sylvester Flow Can we have a non-linear flow with a simple Jacobian-determinant? Let us consider the following normalizing flow: where A is DxM, B is MxD. How to calculate the Jacobian-determinant efficiently? Sylvester s determinant identity van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
65 Sylvester Flow Can we have a non-linear flow with a simple Jacobian-determinant? Let us consider the following normalizing flow: where A is DxM, B is MxD. How to calculate the Jacobian-determinant efficiently? Sylvester s determinant identity van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
66 Sylvester Flow Can we have a non-linear flow with a simple Jacobian-determinant? Let us consider the following normalizing flow: where A is DxM, B is MxD. How to calculate the Jacobian-determinant efficiently? Sylvester s determinant identity van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
67 Sylvester Flow Can we have a non-linear flow with a simple Jacobian-determinant? Theorem Let us consider the following normalizing flow: For all where A is MxD, B is DxM. How to calculate the Jacobian-determinant efficiently? Sylvester s determinant identity van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
68 Sylvester Flow How to use the Sylvester s determinant identity? How to parameterize matrices A and B? van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
.")
69 Sylvester Flow How to use the Sylvester s determinant identity? How to parameterize matrices A and B? Householder matrices, permutation matrix, orthogonalization procedure van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
.")
70 Sylvester Flow The Jacobian-determinant: As a result, for properly chosen h, the determinant is upper-triangular and, thus, easy to calculate. van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
71 Sylvester Flow (MNIST) van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
.")
72 Sylvester Flow (MNIST) van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
73 Sylvester Flow van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
.")
74 Sylvester Flow van den Berg, R., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester Normalizing Flows for Variational Inference, UAI 2018 (oral presentation)
75 BACK Variational Auto-Encoder Autoregressive Prior Objective Prior Stick-Breaking Prior VampPrior
76 New Prior Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018 (oral presentation, 14% of accepted papers)
77 New Prior Let s re-write the ELBO: Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018
78 New Prior Let s re-write the ELBO: Empirical distribution Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018

.")
79 New Prior Let s re-write the ELBO: Aggregated posterior Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018
80 New Prior (Variational Mixture of Posteriors Prior) We look for the optimal prior using the Lagrange function: The solution is simply the aggregated posterior. We approximate it using K pseudo-inputs instead of N observations: Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018
81 New Prior (Variational Mixture of Posteriors Prior) We look for the optimal prior using the Lagrange function: The solution is simply the aggregated posterior. We approximate it using K pseudo-inputs instead of N observations: Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018
.")
82 New Prior (Variational Mixture of Posteriors Prior) We look for the optimal prior using the Lagrange function: The solution is simply the aggregated posterior. We approximate it using K pseudo-inputs instead of N observations: infeasible Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018
83 New Prior (Variational Mixture of Posteriors Prior) We look for the optimal prior using the Lagrange function: The solution is simply the aggregated posterior. We approximate it using K pseudo-inputs instead of N observations: Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018
84 New Prior (Variational Mixture of Posteriors Prior) We look for the optimal prior using the Lagrange function: The solution is simply the aggregated posterior. We approximate it using K pseudo-inputs instead of N observations: they are trained from scratch by SGD Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018
85 New Prior (Variational Mixture of Posteriors Prior) pseudoinputs
86 New Prior (Variational Mixture of Posteriors Prior) pseudoinputs
87 New Prior (Variational Mixture of Posteriors Prior) pseudoinputs
 standard")
88 Toy problem (MNIST): VAE with dim(z)=2 Latent space representation + psedoinputs (black dots) standard K=10
 standard")
89 Toy problem (MNIST): VAE with dim(z)=2 Latent space representation + psedoinputs (black dots) standard K=100
90 Experiments Tomczak, J. M., & Welling, M. (2018). VAE with a VampPrior, AISTATS 2018
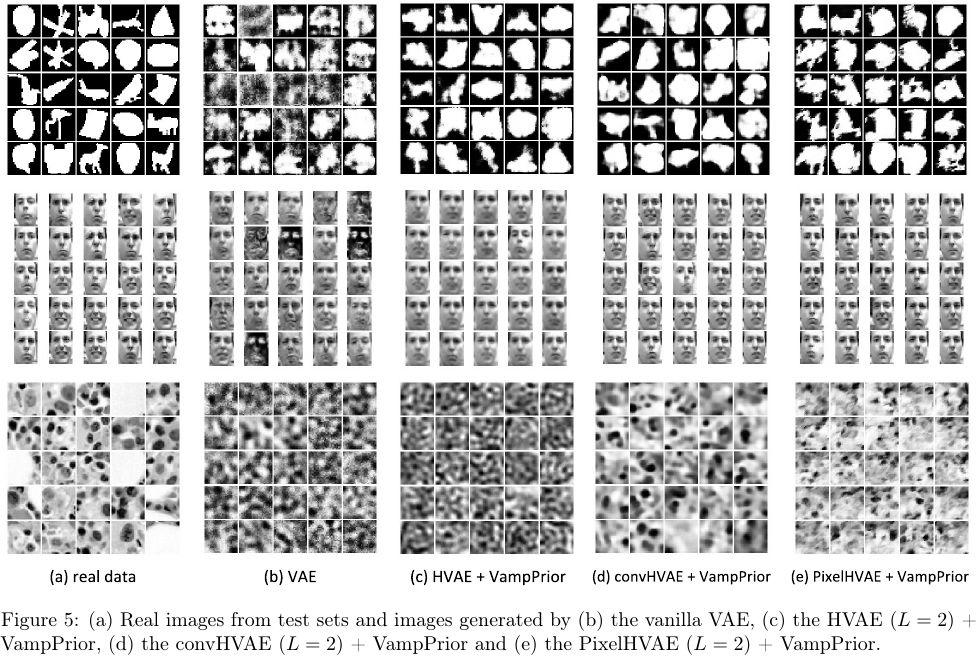
91 BACK
CSC321 Lecture 20: Reversible and Autoregressive Models
 CSC321 Lecture 20: Reversible and Autoregressive Models Roger Grosse Roger Grosse CSC321 Lecture 20: Reversible and Autoregressive Models 1 / 23 Overview Four modern approaches to generative modeling:
CSC321 Lecture 20: Reversible and Autoregressive Models Roger Grosse Roger Grosse CSC321 Lecture 20: Reversible and Autoregressive Models 1 / 23 Overview Four modern approaches to generative modeling:
Bayesian Semi-supervised Learning with Deep Generative Models
 Bayesian Semi-supervised Learning with Deep Generative Models Jonathan Gordon Department of Engineering Cambridge University jg801@cam.ac.uk José Miguel Hernández-Lobato Department of Engineering Cambridge
Bayesian Semi-supervised Learning with Deep Generative Models Jonathan Gordon Department of Engineering Cambridge University jg801@cam.ac.uk José Miguel Hernández-Lobato Department of Engineering Cambridge
Lecture 14: Deep Generative Learning
 Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
A Unified View of Deep Generative Models
 SAILING LAB Laboratory for Statistical Artificial InteLigence & INtegreative Genomics A Unified View of Deep Generative Models Zhiting Hu and Eric Xing Petuum Inc. Carnegie Mellon University 1 Deep generative
SAILING LAB Laboratory for Statistical Artificial InteLigence & INtegreative Genomics A Unified View of Deep Generative Models Zhiting Hu and Eric Xing Petuum Inc. Carnegie Mellon University 1 Deep generative
Sylvester Normalizing Flows for Variational Inference
 Sylvester Normalizing Flows for Variational Inference Rianne van den Berg Informatics Institute University of Amsterdam Leonard Hasenclever Department of statistics University of Oxford Jakub M. Tomczak
Sylvester Normalizing Flows for Variational Inference Rianne van den Berg Informatics Institute University of Amsterdam Leonard Hasenclever Department of statistics University of Oxford Jakub M. Tomczak
arxiv: v1 [cs.lg] 6 Dec 2018
![arxiv: v1 [cs.lg] 6 Dec 2018](/thumbs/91/107120580.jpg "arxiv: v1 [cs.lg] 6 Dec 2018") Embedding-reparameterization procedure for manifold-valued latent variables in generative models arxiv:1812.02769v1 [cs.lg] 6 Dec 2018 Eugene Golikov Neural Networks and Deep Learning Lab Moscow Institute
Embedding-reparameterization procedure for manifold-valued latent variables in generative models arxiv:1812.02769v1 [cs.lg] 6 Dec 2018 Eugene Golikov Neural Networks and Deep Learning Lab Moscow Institute
VAE with a VampPrior. Abstract. 1 Introduction
 Jakub M. Tomczak University of Amsterdam Max Welling University of Amsterdam Abstract Many different methods to train deep generative models have been introduced in the past. In this paper, we propose
Jakub M. Tomczak University of Amsterdam Max Welling University of Amsterdam Abstract Many different methods to train deep generative models have been introduced in the past. In this paper, we propose
GENERATIVE ADVERSARIAL LEARNING
 GENERATIVE ADVERSARIAL LEARNING OF MARKOV CHAINS Jiaming Song, Shengjia Zhao & Stefano Ermon Computer Science Department Stanford University {tsong,zhaosj12,ermon}@cs.stanford.edu ABSTRACT We investigate
GENERATIVE ADVERSARIAL LEARNING OF MARKOV CHAINS Jiaming Song, Shengjia Zhao & Stefano Ermon Computer Science Department Stanford University {tsong,zhaosj12,ermon}@cs.stanford.edu ABSTRACT We investigate
UvA-DARE (Digital Academic Repository) Improving Variational Auto-Encoders using Householder Flow Tomczak, J.M.; Welling, M. Link to publication
 Improving Variational Auto-Encoders using Householder Flow Tomczak, J.M.; Welling, M. Link to publication") UvA-DARE (Digital Academic Repository) Improving Variational Auto-Encoders using Householder Flow Tomczak, J.M.; Welling, M. Link to publication Citation for published version (APA): Tomczak, J. M., &
UvA-DARE (Digital Academic Repository) Improving Variational Auto-Encoders using Householder Flow Tomczak, J.M.; Welling, M. Link to publication Citation for published version (APA): Tomczak, J. M., &
Variational Autoencoders (VAEs)
") September 26 & October 3, 2017 Section 1 Preliminaries Kullback-Leibler divergence KL divergence (continuous case) p(x) andq(x) are two density distributions. Then the KL-divergence is defined as Z KL(p
September 26 & October 3, 2017 Section 1 Preliminaries Kullback-Leibler divergence KL divergence (continuous case) p(x) andq(x) are two density distributions. Then the KL-divergence is defined as Z KL(p
Deep Generative Models. (Unsupervised Learning)
") Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What
Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What
Deep Generative Models for Graph Generation. Jian Tang HEC Montreal CIFAR AI Chair, Mila
 Deep Generative Models for Graph Generation Jian Tang HEC Montreal CIFAR AI Chair, Mila Email: jian.tang@hec.ca Deep Generative Models Goal: model data distribution p(x) explicitly or implicitly, where
Deep Generative Models for Graph Generation Jian Tang HEC Montreal CIFAR AI Chair, Mila Email: jian.tang@hec.ca Deep Generative Models Goal: model data distribution p(x) explicitly or implicitly, where
Nonparametric Inference for Auto-Encoding Variational Bayes
 Nonparametric Inference for Auto-Encoding Variational Bayes Erik Bodin * Iman Malik * Carl Henrik Ek * Neill D. F. Campbell * University of Bristol University of Bath Variational approximations are an
Nonparametric Inference for Auto-Encoding Variational Bayes Erik Bodin * Iman Malik * Carl Henrik Ek * Neill D. F. Campbell * University of Bristol University of Bath Variational approximations are an
REINTERPRETING IMPORTANCE-WEIGHTED AUTOENCODERS
 Worshop trac - ICLR 207 REINTERPRETING IMPORTANCE-WEIGHTED AUTOENCODERS Chris Cremer, Quaid Morris & David Duvenaud Department of Computer Science University of Toronto {ccremer,duvenaud}@cs.toronto.edu
Worshop trac - ICLR 207 REINTERPRETING IMPORTANCE-WEIGHTED AUTOENCODERS Chris Cremer, Quaid Morris & David Duvenaud Department of Computer Science University of Toronto {ccremer,duvenaud}@cs.toronto.edu
Inference Suboptimality in Variational Autoencoders
 Inference Suboptimality in Variational Autoencoders Chris Cremer Department of Computer Science University of Toronto ccremer@cs.toronto.edu Xuechen Li Department of Computer Science University of Toronto
Inference Suboptimality in Variational Autoencoders Chris Cremer Department of Computer Science University of Toronto ccremer@cs.toronto.edu Xuechen Li Department of Computer Science University of Toronto
Deep Variational Inference. FLARE Reading Group Presentation Wesley Tansey 9/28/2016
 Deep Variational Inference FLARE Reading Group Presentation Wesley Tansey 9/28/2016 What is Variational Inference? What is Variational Inference? Want to estimate some distribution, p*(x) p*(x) What is
Deep Variational Inference FLARE Reading Group Presentation Wesley Tansey 9/28/2016 What is Variational Inference? What is Variational Inference? Want to estimate some distribution, p*(x) p*(x) What is
Variational Autoencoders
 Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
arxiv: v1 [stat.ml] 6 Dec 2018
![arxiv: v1 [stat.ml] 6 Dec 2018](/thumbs/92/107935971.jpg "arxiv: v1 [stat.ml] 6 Dec 2018") missiwae: Deep Generative Modelling and Imputation of Incomplete Data arxiv:1812.02633v1 [stat.ml] 6 Dec 2018 Pierre-Alexandre Mattei Department of Computer Science IT University of Copenhagen pima@itu.dk
missiwae: Deep Generative Modelling and Imputation of Incomplete Data arxiv:1812.02633v1 [stat.ml] 6 Dec 2018 Pierre-Alexandre Mattei Department of Computer Science IT University of Copenhagen pima@itu.dk
Variational AutoEncoder: An Introduction and Recent Perspectives
 Metode de optimizare Riemanniene pentru învățare profundă Proiect cofinanțat din Fondul European de Dezvoltare Regională prin Programul Operațional Competitivitate 2014-2020 Variational AutoEncoder: An
Metode de optimizare Riemanniene pentru învățare profundă Proiect cofinanțat din Fondul European de Dezvoltare Regională prin Programul Operațional Competitivitate 2014-2020 Variational AutoEncoder: An
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
arxiv: v1 [cs.lg] 15 Jun 2016
![arxiv: v1 [cs.lg] 15 Jun 2016](/thumbs/86/93343117.jpg "arxiv: v1 [cs.lg] 15 Jun 2016") Improving Variational Inference with Inverse Autoregressive Flow arxiv:1606.04934v1 [cs.lg] 15 Jun 2016 Diederik P. Kingma, Tim Salimans and Max Welling OpenAI, San Francisco University of Amsterdam, University
Improving Variational Inference with Inverse Autoregressive Flow arxiv:1606.04934v1 [cs.lg] 15 Jun 2016 Diederik P. Kingma, Tim Salimans and Max Welling OpenAI, San Francisco University of Amsterdam, University
Natural Gradients via the Variational Predictive Distribution
 Natural Gradients via the Variational Predictive Distribution Da Tang Columbia University datang@cs.columbia.edu Rajesh Ranganath New York University rajeshr@cims.nyu.edu Abstract Variational inference
Natural Gradients via the Variational Predictive Distribution Da Tang Columbia University datang@cs.columbia.edu Rajesh Ranganath New York University rajeshr@cims.nyu.edu Abstract Variational inference
Generative Adversarial Networks
 Generative Adversarial Networks SIBGRAPI 2017 Tutorial Everything you wanted to know about Deep Learning for Computer Vision but were afraid to ask Presentation content inspired by Ian Goodfellow s tutorial
Generative Adversarial Networks SIBGRAPI 2017 Tutorial Everything you wanted to know about Deep Learning for Computer Vision but were afraid to ask Presentation content inspired by Ian Goodfellow s tutorial
LEARNING TO SAMPLE WITH ADVERSARIALLY LEARNED LIKELIHOOD-RATIO
 LEARNING TO SAMPLE WITH ADVERSARIALLY LEARNED LIKELIHOOD-RATIO Chunyuan Li, Jianqiao Li, Guoyin Wang & Lawrence Carin Duke University {chunyuan.li,jianqiao.li,guoyin.wang,lcarin}@duke.edu ABSTRACT We link
LEARNING TO SAMPLE WITH ADVERSARIALLY LEARNED LIKELIHOOD-RATIO Chunyuan Li, Jianqiao Li, Guoyin Wang & Lawrence Carin Duke University {chunyuan.li,jianqiao.li,guoyin.wang,lcarin}@duke.edu ABSTRACT We link
Unsupervised Learning
 CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
Improving Variational Inference with Inverse Autoregressive Flow
 Improving Variational Inference with Inverse Autoregressive Flow Diederik P. Kingma dpkingma@openai.com Tim Salimans tim@openai.com Rafal Jozefowicz rafal@openai.com Xi Chen peter@openai.com Ilya Sutskever
Improving Variational Inference with Inverse Autoregressive Flow Diederik P. Kingma dpkingma@openai.com Tim Salimans tim@openai.com Rafal Jozefowicz rafal@openai.com Xi Chen peter@openai.com Ilya Sutskever
Generative Adversarial Networks
 Generative Adversarial Networks Stefano Ermon, Aditya Grover Stanford University Lecture 10 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 10 1 / 17 Selected GANs https://github.com/hindupuravinash/the-gan-zoo
Generative Adversarial Networks Stefano Ermon, Aditya Grover Stanford University Lecture 10 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 10 1 / 17 Selected GANs https://github.com/hindupuravinash/the-gan-zoo
Cycle-Consistent Adversarial Learning as Approximate Bayesian Inference
 Cycle-Consistent Adversarial Learning as Approximate Bayesian Inference Louis C. Tiao 1 Edwin V. Bonilla 2 Fabio Ramos 1 July 22, 2018 1 University of Sydney, 2 University of New South Wales Motivation:
Cycle-Consistent Adversarial Learning as Approximate Bayesian Inference Louis C. Tiao 1 Edwin V. Bonilla 2 Fabio Ramos 1 July 22, 2018 1 University of Sydney, 2 University of New South Wales Motivation:
Quasi-Monte Carlo Flows
 Quasi-Monte Carlo Flows Florian Wenzel TU Kaiserslautern Germany wenzelfl@hu-berlin.de Alexander Buchholz ENSAE-CREST, Paris France alexander.buchholz@ensae.fr Stephan Mandt Univ. of California, Irvine
Quasi-Monte Carlo Flows Florian Wenzel TU Kaiserslautern Germany wenzelfl@hu-berlin.de Alexander Buchholz ENSAE-CREST, Paris France alexander.buchholz@ensae.fr Stephan Mandt Univ. of California, Irvine
Sandwiching the marginal likelihood using bidirectional Monte Carlo. Roger Grosse
 Sandwiching the marginal likelihood using bidirectional Monte Carlo Roger Grosse Ryan Adams Zoubin Ghahramani Introduction When comparing different statistical models, we d like a quantitative criterion
Sandwiching the marginal likelihood using bidirectional Monte Carlo Roger Grosse Ryan Adams Zoubin Ghahramani Introduction When comparing different statistical models, we d like a quantitative criterion
Deep latent variable models
 Deep latent variable models Pierre-Alexandre Mattei IT University of Copenhagen http://pamattei.github.io @pamattei 19 avril 2018 Séminaire de statistique du CNAM 1 Overview of talk A short introduction
Deep latent variable models Pierre-Alexandre Mattei IT University of Copenhagen http://pamattei.github.io @pamattei 19 avril 2018 Séminaire de statistique du CNAM 1 Overview of talk A short introduction
Improved Bayesian Compression
 Improved Bayesian Compression Marco Federici University of Amsterdam marco.federici@student.uva.nl Karen Ullrich University of Amsterdam karen.ullrich@uva.nl Max Welling University of Amsterdam Canadian
Improved Bayesian Compression Marco Federici University of Amsterdam marco.federici@student.uva.nl Karen Ullrich University of Amsterdam karen.ullrich@uva.nl Max Welling University of Amsterdam Canadian
Variational Auto Encoders
 Variational Auto Encoders 1 Recap Deep Neural Models consist of 2 primary components A feature extraction network Where important aspects of the data are amplified and projected into a linearly separable
Variational Auto Encoders 1 Recap Deep Neural Models consist of 2 primary components A feature extraction network Where important aspects of the data are amplified and projected into a linearly separable
arxiv: v2 [stat.ml] 15 Aug 2017
![arxiv: v2 [stat.ml] 15 Aug 2017](/thumbs/90/102672222.jpg "arxiv: v2 [stat.ml] 15 Aug 2017") Worshop trac - ICLR 207 REINTERPRETING IMPORTANCE-WEIGHTED AUTOENCODERS Chris Cremer, Quaid Morris & David Duvenaud Department of Computer Science University of Toronto {ccremer,duvenaud}@cs.toronto.edu
Worshop trac - ICLR 207 REINTERPRETING IMPORTANCE-WEIGHTED AUTOENCODERS Chris Cremer, Quaid Morris & David Duvenaud Department of Computer Science University of Toronto {ccremer,duvenaud}@cs.toronto.edu
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
INFERENCE SUBOPTIMALITY
 INFERENCE SUBOPTIMALITY IN VARIATIONAL AUTOENCODERS Anonymous authors Paper under double-blind review ABSTRACT Amortized inference has led to efficient approximate inference for large datasets. The quality
INFERENCE SUBOPTIMALITY IN VARIATIONAL AUTOENCODERS Anonymous authors Paper under double-blind review ABSTRACT Amortized inference has led to efficient approximate inference for large datasets. The quality
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Continuous-Time Flows for Efficient Inference and Density Estimation
 for Efficient Inference and Density Estimation Changyou Chen Chunyuan Li Liqun Chen Wenlin Wang Yunchen Pu Lawrence Carin Abstract Two fundamental problems in unsupervised learning are efficient inference
for Efficient Inference and Density Estimation Changyou Chen Chunyuan Li Liqun Chen Wenlin Wang Yunchen Pu Lawrence Carin Abstract Two fundamental problems in unsupervised learning are efficient inference
Generative Adversarial Networks. Presented by Yi Zhang
 Generative Adversarial Networks Presented by Yi Zhang Deep Generative Models N(O, I) Variational Auto-Encoders GANs Unreasonable Effectiveness of GANs GANs Discriminator tries to distinguish genuine data
Generative Adversarial Networks Presented by Yi Zhang Deep Generative Models N(O, I) Variational Auto-Encoders GANs Unreasonable Effectiveness of GANs GANs Discriminator tries to distinguish genuine data
Auto-Encoding Variational Bayes
 Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Masked Autoregressive Flow for Density Estimation
 Masked Autoregressive Flow for Density Estimation George Papamakarios University of Edinburgh g.papamakarios@ed.ac.uk Theo Pavlakou University of Edinburgh theo.pavlakou@ed.ac.uk Iain Murray University
Masked Autoregressive Flow for Density Estimation George Papamakarios University of Edinburgh g.papamakarios@ed.ac.uk Theo Pavlakou University of Edinburgh theo.pavlakou@ed.ac.uk Iain Murray University
Structured deep models: Deep learning on graphs and beyond
 Structured deep models: Deep learning on graphs and beyond Hidden layer Hidden layer Input Output ReLU ReLU, 25 May 2018 CompBio Seminar, University of Cambridge In collaboration with Ethan Fetaya, Rianne
Structured deep models: Deep learning on graphs and beyond Hidden layer Hidden layer Input Output ReLU ReLU, 25 May 2018 CompBio Seminar, University of Cambridge In collaboration with Ethan Fetaya, Rianne
Probabilistic Graphical Models
 10-708 Probabilistic Graphical Models Homework 3 (v1.1.0) Due Apr 14, 7:00 PM Rules: 1. Homework is due on the due date at 7:00 PM. The homework should be submitted via Gradescope. Solution to each problem
10-708 Probabilistic Graphical Models Homework 3 (v1.1.0) Due Apr 14, 7:00 PM Rules: 1. Homework is due on the due date at 7:00 PM. The homework should be submitted via Gradescope. Solution to each problem
Bayesian Deep Learning
 Bayesian Deep Learning Mohammad Emtiyaz Khan AIP (RIKEN), Tokyo http://emtiyaz.github.io emtiyaz.khan@riken.jp June 06, 2018 Mohammad Emtiyaz Khan 2018 1 What will you learn? Why is Bayesian inference
Bayesian Deep Learning Mohammad Emtiyaz Khan AIP (RIKEN), Tokyo http://emtiyaz.github.io emtiyaz.khan@riken.jp June 06, 2018 Mohammad Emtiyaz Khan 2018 1 What will you learn? Why is Bayesian inference
Generative Adversarial Networks (GANs) Ian Goodfellow, OpenAI Research Scientist Presentation at Berkeley Artificial Intelligence Lab,
 Ian Goodfellow, OpenAI Research Scientist Presentation at Berkeley Artificial Intelligence Lab,") Generative Adversarial Networks (GANs) Ian Goodfellow, OpenAI Research Scientist Presentation at Berkeley Artificial Intelligence Lab, 2016-08-31 Generative Modeling Density estimation Sample generation
Generative Adversarial Networks (GANs) Ian Goodfellow, OpenAI Research Scientist Presentation at Berkeley Artificial Intelligence Lab, 2016-08-31 Generative Modeling Density estimation Sample generation
TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter Variational Autoencoders
 TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter 2018 Variational Autoencoders 1 The Latent Variable Cross-Entropy Objective We will now drop the negation and switch to argmax. Φ = argmax
TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter 2018 Variational Autoencoders 1 The Latent Variable Cross-Entropy Objective We will now drop the negation and switch to argmax. Φ = argmax
arxiv: v1 [cs.lg] 28 Dec 2017
![arxiv: v1 [cs.lg] 28 Dec 2017](/thumbs/80/82263025.jpg "arxiv: v1 [cs.lg] 28 Dec 2017") PixelSNAIL: An Improved Autoregressive Generative Model arxiv:1712.09763v1 [cs.lg] 28 Dec 2017 Xi Chen, Nikhil Mishra, Mostafa Rohaninejad, Pieter Abbeel Embodied Intelligence UC Berkeley, Department of
PixelSNAIL: An Improved Autoregressive Generative Model arxiv:1712.09763v1 [cs.lg] 28 Dec 2017 Xi Chen, Nikhil Mishra, Mostafa Rohaninejad, Pieter Abbeel Embodied Intelligence UC Berkeley, Department of
Denoising Criterion for Variational Auto-Encoding Framework
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Denoising Criterion for Variational Auto-Encoding Framework Daniel Jiwoong Im, Sungjin Ahn, Roland Memisevic, Yoshua
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Denoising Criterion for Variational Auto-Encoding Framework Daniel Jiwoong Im, Sungjin Ahn, Roland Memisevic, Yoshua
FAST ADAPTATION IN GENERATIVE MODELS WITH GENERATIVE MATCHING NETWORKS
 FAST ADAPTATION IN GENERATIVE MODELS WITH GENERATIVE MATCHING NETWORKS Sergey Bartunov & Dmitry P. Vetrov National Research University Higher School of Economics (HSE), Yandex Moscow, Russia ABSTRACT We
FAST ADAPTATION IN GENERATIVE MODELS WITH GENERATIVE MATCHING NETWORKS Sergey Bartunov & Dmitry P. Vetrov National Research University Higher School of Economics (HSE), Yandex Moscow, Russia ABSTRACT We
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Spring 2018 http://vllab.ee.ntu.edu.tw/dlcv.html (primary) https://ceiba.ntu.edu.tw/1062dlcv (grade, etc.) FB: DLCV Spring 2018 Yu-Chiang Frank Wang 王鈺強, Associate Professor
Deep Learning for Computer Vision Spring 2018 http://vllab.ee.ntu.edu.tw/dlcv.html (primary) https://ceiba.ntu.edu.tw/1062dlcv (grade, etc.) FB: DLCV Spring 2018 Yu-Chiang Frank Wang 王鈺強, Associate Professor
Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning
 Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning Diederik (Durk) Kingma Danilo J. Rezende (*) Max Welling Shakir Mohamed (**) Stochastic Gradient Variational Inference Bayesian
Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning Diederik (Durk) Kingma Danilo J. Rezende (*) Max Welling Shakir Mohamed (**) Stochastic Gradient Variational Inference Bayesian
CSC411: Final Review. James Lucas & David Madras. December 3, 2018
 CSC411: Final Review James Lucas & David Madras December 3, 2018 Agenda 1. A brief overview 2. Some sample questions Basic ML Terminology The final exam will be on the entire course; however, it will be
CSC411: Final Review James Lucas & David Madras December 3, 2018 Agenda 1. A brief overview 2. Some sample questions Basic ML Terminology The final exam will be on the entire course; however, it will be
Gradient Estimation Using Stochastic Computation Graphs
 Gradient Estimation Using Stochastic Computation Graphs Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology May 9, 2017 Outline Stochastic Gradient Estimation
Gradient Estimation Using Stochastic Computation Graphs Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology May 9, 2017 Outline Stochastic Gradient Estimation
Deep Learning Srihari. Deep Belief Nets. Sargur N. Srihari
 Deep Belief Nets Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines for continuous
Deep Belief Nets Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines for continuous
Variational Dropout via Empirical Bayes
 Variational Dropout via Empirical Bayes Valery Kharitonov 1 kharvd@gmail.com Dmitry Molchanov 1, dmolch111@gmail.com Dmitry Vetrov 1, vetrovd@yandex.ru 1 National Research University Higher School of Economics,
Variational Dropout via Empirical Bayes Valery Kharitonov 1 kharvd@gmail.com Dmitry Molchanov 1, dmolch111@gmail.com Dmitry Vetrov 1, vetrovd@yandex.ru 1 National Research University Higher School of Economics,
An Overview of Edward: A Probabilistic Programming System. Dustin Tran Columbia University
 An Overview of Edward: A Probabilistic Programming System Dustin Tran Columbia University Alp Kucukelbir Eugene Brevdo Andrew Gelman Adji Dieng Maja Rudolph David Blei Dawen Liang Matt Hoffman Kevin Murphy
An Overview of Edward: A Probabilistic Programming System Dustin Tran Columbia University Alp Kucukelbir Eugene Brevdo Andrew Gelman Adji Dieng Maja Rudolph David Blei Dawen Liang Matt Hoffman Kevin Murphy
Variational Inference in TensorFlow. Danijar Hafner Stanford CS University College London, Google Brain
 Variational Inference in TensorFlow Danijar Hafner Stanford CS 20 2018-02-16 University College London, Google Brain Outline Variational Inference Tensorflow Distributions VAE in TensorFlow Variational
Variational Inference in TensorFlow Danijar Hafner Stanford CS 20 2018-02-16 University College London, Google Brain Outline Variational Inference Tensorflow Distributions VAE in TensorFlow Variational
Wild Variational Approximations
 Wild Variational Approximations Yingzhen Li University of Cambridge Cambridge, CB2 1PZ, UK yl494@cam.ac.uk Qiang Liu Dartmouth College Hanover, NH 03755, USA qiang.liu@dartmouth.edu Abstract We formalise
Wild Variational Approximations Yingzhen Li University of Cambridge Cambridge, CB2 1PZ, UK yl494@cam.ac.uk Qiang Liu Dartmouth College Hanover, NH 03755, USA qiang.liu@dartmouth.edu Abstract We formalise
LDA with Amortized Inference
 LDA with Amortied Inference Nanbo Sun Abstract This report describes how to frame Latent Dirichlet Allocation LDA as a Variational Auto- Encoder VAE and use the Amortied Variational Inference AVI to optimie
LDA with Amortied Inference Nanbo Sun Abstract This report describes how to frame Latent Dirichlet Allocation LDA as a Variational Auto- Encoder VAE and use the Amortied Variational Inference AVI to optimie
Recurrent Latent Variable Networks for Session-Based Recommendation
 Recurrent Latent Variable Networks for Session-Based Recommendation Panayiotis Christodoulou Cyprus University of Technology paa.christodoulou@edu.cut.ac.cy 27/8/2017 Panayiotis Christodoulou (C.U.T.)
Recurrent Latent Variable Networks for Session-Based Recommendation Panayiotis Christodoulou Cyprus University of Technology paa.christodoulou@edu.cut.ac.cy 27/8/2017 Panayiotis Christodoulou (C.U.T.)
Operator Variational Inference
 Operator Variational Inference Rajesh Ranganath Princeton University Jaan Altosaar Princeton University Dustin Tran Columbia University David M. Blei Columbia University Abstract Variational inference
Operator Variational Inference Rajesh Ranganath Princeton University Jaan Altosaar Princeton University Dustin Tran Columbia University David M. Blei Columbia University Abstract Variational inference
arxiv: v3 [stat.ml] 31 Jul 2018
![arxiv: v3 [stat.ml] 31 Jul 2018](/thumbs/89/100197109.jpg "arxiv: v3 [stat.ml] 31 Jul 2018") Training VAEs Under Structured Residuals Garoe Dorta 1,2 Sara Vicente 2 Lourdes Agapito 3 Neill D.F. Campbell 1 Ivor Simpson 2 1 University of Bath 2 Anthropics Technology Ltd. 3 University College London
Training VAEs Under Structured Residuals Garoe Dorta 1,2 Sara Vicente 2 Lourdes Agapito 3 Neill D.F. Campbell 1 Ivor Simpson 2 1 University of Bath 2 Anthropics Technology Ltd. 3 University College London
CSC321 Lecture 20: Autoencoders
 CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
Variational Autoencoder
 Variational Autoencoder Göker Erdo gan August 8, 2017 The variational autoencoder (VA) [1] is a nonlinear latent variable model with an efficient gradient-based training procedure based on variational
Variational Autoencoder Göker Erdo gan August 8, 2017 The variational autoencoder (VA) [1] is a nonlinear latent variable model with an efficient gradient-based training procedure based on variational
Dropout as a Bayesian Approximation: Insights and Applications
 Dropout as a Bayesian Approximation: Insights and Applications Yarin Gal and Zoubin Ghahramani Discussion by: Chunyuan Li Jan. 15, 2016 1 / 16 Main idea In the framework of variational inference, the authors
Dropout as a Bayesian Approximation: Insights and Applications Yarin Gal and Zoubin Ghahramani Discussion by: Chunyuan Li Jan. 15, 2016 1 / 16 Main idea In the framework of variational inference, the authors
Singing Voice Separation using Generative Adversarial Networks
 Singing Voice Separation using Generative Adversarial Networks Hyeong-seok Choi, Kyogu Lee Music and Audio Research Group Graduate School of Convergence Science and Technology Seoul National University
Singing Voice Separation using Generative Adversarial Networks Hyeong-seok Choi, Kyogu Lee Music and Audio Research Group Graduate School of Convergence Science and Technology Seoul National University
CONTINUOUS-TIME FLOWS FOR EFFICIENT INFER-
 CONTINUOUS-TIME FLOWS FOR EFFICIENT INFER- ENCE AND DENSITY ESTIMATION Anonymous authors Paper under double-blind review ABSTRACT Two fundamental problems in unsupervised learning are efficient inference
CONTINUOUS-TIME FLOWS FOR EFFICIENT INFER- ENCE AND DENSITY ESTIMATION Anonymous authors Paper under double-blind review ABSTRACT Two fundamental problems in unsupervised learning are efficient inference
Variational Autoencoders. Presented by Alex Beatson Materials from Yann LeCun, Jaan Altosaar, Shakir Mohamed
 Variational Autoencoders Presented by Alex Beatson Materials from Yann LeCun, Jaan Altosaar, Shakir Mohamed Contents 1. Why unsupervised learning, and why generative models? (Selected slides from Yann
Variational Autoencoders Presented by Alex Beatson Materials from Yann LeCun, Jaan Altosaar, Shakir Mohamed Contents 1. Why unsupervised learning, and why generative models? (Selected slides from Yann
Conditional Image Generation with PixelCNN Decoders
 Conditional Image Generation with PixelCNN Decoders Aaron van den Oord 1 Nal Kalchbrenner 1 Oriol Vinyals 1 Lasse Espeholt 1 Alex Graves 1 Koray Kavukcuoglu 1 1 Google DeepMind NIPS, 2016 Presenter: Beilun
Conditional Image Generation with PixelCNN Decoders Aaron van den Oord 1 Nal Kalchbrenner 1 Oriol Vinyals 1 Lasse Espeholt 1 Alex Graves 1 Koray Kavukcuoglu 1 1 Google DeepMind NIPS, 2016 Presenter: Beilun
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
TUTORIAL PART 1 Unsupervised Learning
 TUTORIAL PART 1 Unsupervised Learning Marc'Aurelio Ranzato Department of Computer Science Univ. of Toronto ranzato@cs.toronto.edu Co-organizers: Honglak Lee, Yoshua Bengio, Geoff Hinton, Yann LeCun, Andrew
TUTORIAL PART 1 Unsupervised Learning Marc'Aurelio Ranzato Department of Computer Science Univ. of Toronto ranzato@cs.toronto.edu Co-organizers: Honglak Lee, Yoshua Bengio, Geoff Hinton, Yann LeCun, Andrew
arxiv: v2 [stat.ml] 23 Mar 2018 Abstract
![arxiv: v2 [stat.ml] 23 Mar 2018 Abstract](/thumbs/84/89532337.jpg "arxiv: v2 [stat.ml] 23 Mar 2018 Abstract") Published as a conference paper at CVPR 2018 Structured Uncertainty Prediction Networks Garoe Dorta 1,2 Sara Vicente 2 Lourdes Agapito 3 Neill D.F. Campbell 1 Ivor Simpson 2 1 University of Bath 2 Anthropics
Published as a conference paper at CVPR 2018 Structured Uncertainty Prediction Networks Garoe Dorta 1,2 Sara Vicente 2 Lourdes Agapito 3 Neill D.F. Campbell 1 Ivor Simpson 2 1 University of Bath 2 Anthropics
Robust Locally-Linear Controllable Embedding
 Ershad Banijamali Rui Shu 2 Mohammad Ghavamzadeh 3 Hung Bui 3 Ali Ghodsi University of Waterloo 2 Standford University 3 DeepMind Abstract Embed-to-control (E2C) 7] is a model for solving high-dimensional
Ershad Banijamali Rui Shu 2 Mohammad Ghavamzadeh 3 Hung Bui 3 Ali Ghodsi University of Waterloo 2 Standford University 3 DeepMind Abstract Embed-to-control (E2C) 7] is a model for solving high-dimensional
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
arxiv: v6 [cs.lg] 10 Apr 2015
![arxiv: v6 [cs.lg] 10 Apr 2015](/thumbs/76/73390586.jpg "arxiv: v6 [cs.lg] 10 Apr 2015") NICE: NON-LINEAR INDEPENDENT COMPONENTS ESTIMATION Laurent Dinh David Krueger Yoshua Bengio Département d informatique et de recherche opérationnelle Université de Montréal Montréal, QC H3C 3J7 arxiv:1410.8516v6
NICE: NON-LINEAR INDEPENDENT COMPONENTS ESTIMATION Laurent Dinh David Krueger Yoshua Bengio Département d informatique et de recherche opérationnelle Université de Montréal Montréal, QC H3C 3J7 arxiv:1410.8516v6
Generative models for missing value completion
 Generative models for missing value completion Kousuke Ariga Department of Computer Science and Engineering University of Washington Seattle, WA 98105 koar8470@cs.washington.edu Abstract Deep generative
Generative models for missing value completion Kousuke Ariga Department of Computer Science and Engineering University of Washington Seattle, WA 98105 koar8470@cs.washington.edu Abstract Deep generative
A QUANTITATIVE MEASURE OF GENERATIVE ADVERSARIAL NETWORK DISTRIBUTIONS
 A QUANTITATIVE MEASURE OF GENERATIVE ADVERSARIAL NETWORK DISTRIBUTIONS Dan Hendrycks University of Chicago dan@ttic.edu Steven Basart University of Chicago xksteven@uchicago.edu ABSTRACT We introduce a
A QUANTITATIVE MEASURE OF GENERATIVE ADVERSARIAL NETWORK DISTRIBUTIONS Dan Hendrycks University of Chicago dan@ttic.edu Steven Basart University of Chicago xksteven@uchicago.edu ABSTRACT We introduce a
Dimensionality Reduction and Principle Components Analysis
 Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
arxiv: v1 [cs.lg] 22 Mar 2016
![arxiv: v1 [cs.lg] 22 Mar 2016](/thumbs/72/67041268.jpg "arxiv: v1 [cs.lg] 22 Mar 2016") Information Theoretic-Learning Auto-Encoder arxiv:1603.06653v1 [cs.lg] 22 Mar 2016 Eder Santana University of Florida Jose C. Principe University of Florida Abstract Matthew Emigh University of Florida
Information Theoretic-Learning Auto-Encoder arxiv:1603.06653v1 [cs.lg] 22 Mar 2016 Eder Santana University of Florida Jose C. Principe University of Florida Abstract Matthew Emigh University of Florida
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY,
 WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
Variational Inference via Stochastic Backpropagation
 Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation
Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation
Deep Learning Autoencoder Models
 Deep Learning Autoencoder Models Davide Bacciu Dipartimento di Informatica Università di Pisa Intelligent Systems for Pattern Recognition (ISPR) Generative Models Wrap-up Deep Learning Module Lecture Generative
Deep Learning Autoencoder Models Davide Bacciu Dipartimento di Informatica Università di Pisa Intelligent Systems for Pattern Recognition (ISPR) Generative Models Wrap-up Deep Learning Module Lecture Generative
Classification. The goal: map from input X to a label Y. Y has a discrete set of possible values. We focused on binary Y (values 0 or 1).
.") Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Deep Generative Models
 Deep Generative Models Durk Kingma Max Welling Deep Probabilistic Models Worksop Wednesday, 1st of Oct, 2014 D.P. Kingma Deep generative models Transformations between Bayes nets and Neural nets Transformation
Deep Generative Models Durk Kingma Max Welling Deep Probabilistic Models Worksop Wednesday, 1st of Oct, 2014 D.P. Kingma Deep generative models Transformations between Bayes nets and Neural nets Transformation
Bayesian Deep Learning
 Bayesian Deep Learning Mohammad Emtiyaz Khan RIKEN Center for AI Project, Tokyo http://emtiyaz.github.io Keywords Bayesian Statistics Gaussian distribution, Bayes rule Continues Optimization Gradient descent,
Bayesian Deep Learning Mohammad Emtiyaz Khan RIKEN Center for AI Project, Tokyo http://emtiyaz.github.io Keywords Bayesian Statistics Gaussian distribution, Bayes rule Continues Optimization Gradient descent,
Learnable Explicit Density for Continuous Latent Space and Variational Inference
 Learnable Eplicit Density for Continuous Latent Space and Variational Inference Chin-Wei Huang 1 Ahmed Touati 1 Laurent Dinh 1 Michal Drozdzal 1 Mohammad Havaei 1 Laurent Charlin 1 3 Aaron Courville 1
Learnable Eplicit Density for Continuous Latent Space and Variational Inference Chin-Wei Huang 1 Ahmed Touati 1 Laurent Dinh 1 Michal Drozdzal 1 Mohammad Havaei 1 Laurent Charlin 1 3 Aaron Courville 1
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net
 Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net Supplementary Material Xingang Pan 1, Ping Luo 1, Jianping Shi 2, and Xiaoou Tang 1 1 CUHK-SenseTime Joint Lab, The Chinese University
Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net Supplementary Material Xingang Pan 1, Ping Luo 1, Jianping Shi 2, and Xiaoou Tang 1 1 CUHK-SenseTime Joint Lab, The Chinese University
WaveNet: A Generative Model for Raw Audio
 WaveNet: A Generative Model for Raw Audio Ido Guy & Daniel Brodeski Deep Learning Seminar 2017 TAU Outline Introduction WaveNet Experiments Introduction WaveNet is a deep generative model of raw audio
WaveNet: A Generative Model for Raw Audio Ido Guy & Daniel Brodeski Deep Learning Seminar 2017 TAU Outline Introduction WaveNet Experiments Introduction WaveNet is a deep generative model of raw audio
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Probabilistic & Bayesian deep learning. Andreas Damianou
 Probabilistic & Bayesian deep learning Andreas Damianou Amazon Research Cambridge, UK Talk at University of Sheffield, 19 March 2019 In this talk Not in this talk: CRFs, Boltzmann machines,... In this
Probabilistic & Bayesian deep learning Andreas Damianou Amazon Research Cambridge, UK Talk at University of Sheffield, 19 March 2019 In this talk Not in this talk: CRFs, Boltzmann machines,... In this
Generative adversarial networks
 14-1: Generative adversarial networks Prof. J.C. Kao, UCLA Generative adversarial networks Why GANs? GAN intuition GAN equilibrium GAN implementation Practical considerations Much of these notes are based
14-1: Generative adversarial networks Prof. J.C. Kao, UCLA Generative adversarial networks Why GANs? GAN intuition GAN equilibrium GAN implementation Practical considerations Much of these notes are based
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
B PROOF OF LEMMA 1. Published as a conference paper at ICLR 2018
 A ADVERSARIAL DOMAIN ADAPTATION (ADA ADA aims to transfer prediction nowledge learned from a source domain with labeled data to a target domain without labels, by learning domain-invariant features. Let
A ADVERSARIAL DOMAIN ADAPTATION (ADA ADA aims to transfer prediction nowledge learned from a source domain with labeled data to a target domain without labels, by learning domain-invariant features. Let
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far