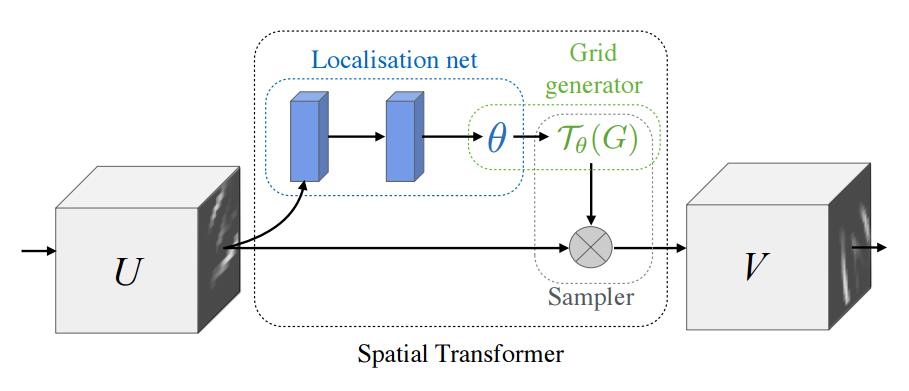
Spatial Transformer. Ref: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transformer Networks, NIPS, 2015
|
|
|
- Olivia Perry
- 5 years ago
- Views:
Transcription
1 Spatial Transormer Re: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transormer Networks, NIPS, 2015




2 Spatial Transormer Layer CNN is not invariant to scaling and rotation CNN 5 CNN 6 NN layer End-to-end learn Can also transorm eature map
3 Spatial Transormer Layer How to transorm an image/eature map Layer l-1 Layer l a l 1 11 a l 1 l 1 12 a 13 a l 1 21 a l 1 l 1 22 a 23 a l 1 31 a l 1 l 1 32 a 33 Spatial Transormer Layer Translate l l l a 11 a 12 a 13 l l l a 21 a 22 a 23 l l l a 31 a 32 a 33 General layer: al nm 3 = i=1 3 j=1 l I we want translate as above: a nm l w nm,ij l l 1 w nm,ij a ij l 1 = a (n 1)m l = 1 i i = n 1, j = m w nm,ij = 0 otherwise
4 Spatial Transormer Layer How to transorm an image/eature map Layer l-1 Layer l Layer l-1 Layer l a l 1 11 a l 1 l 1 12 a 13 l l l a 11 a 12 a 13 a l 1 11 a l 1 l 1 12 a 13 l l l a 11 a 12 a 13 a l 1 21 a l 1 l 1 22 a 23 l l l a 21 a 22 a 23 a l 1 21 a l 1 l 1 22 a 23 l l l a 21 a 22 a 23 a l 1 31 a l 1 l 1 32 a 33 l l l a 31 a 32 a 33 a l 1 31 a l 1 l 1 32 a 33 l l l a 31 a 32 a 33 NN Control the connection NN Control the connection

5 Image Transormation Expansion, Compression, Translation x y = x y x y x y 1 1 x y = x y x y
6 reationdetail.php?sn= Image Transormation Rotation x y = cosθ sinθ sinθ cosθ x y x y x y Rotate θ
7 Spatial Transormer Layer x y = a b c d x y + e 6 parameters to describe the aine transormation Index o layer l-1 Index o layer l a l 1 11 a l 1 l 1 12 a 13 l l l a 11 a 12 a 13 Layer l-1 a l 1 21 a l 1 l 1 22 a 23 a l 1 31 a l 1 l 1 32 a 33 a c b d e l l l a 21 a 22 a 23 l l l a 31 a 32 a 33 Layer l NN
8 Spatial Transormer Layer x y = 0a 1b 1c 0d x y + 1 e 1 6 parameters to describe the aine transormation Index o layer l-1 Index o layer l a l 1 11 a l 1 l 1 12 a 13 l l l a 11 a 12 a 13 Layer l-1 a l 1 21 a l 1 l 1 22 a 23 a l 1 31 a l 1 l 1 32 a 33 0a 1b 1c 0d 1 e 1 l a 21 l a 22 l a 23 l a 31 l a 32 l a 33 Layer l NN
9 Spatial Transormer Layer 1.6 x 2.4 y = 0a 0.5 b 1c 0d x2 y e parameters to describe the aine transormation Index o layer l-1 Index o layer l What is the problem? a l 1 11 a l 1 l 1 12 a 13 l l l a 11 a 12 a 13 Layer l-1 a l 1 21 a l 1 l 1 22 a 23 a l 1 31 a l 1 l 1 32 a 33 0a 0.5 b 1 c 0d 0.6 e 0.4 l a 21 l a 22 l a 23 l a 31 l a 32 l a 33 Layer l NN Gradient is always zero
10 Interpolation Now we can use gradient descent 1.6 x 2.4 y = 0a 0.5 b 1c 0d x2 y e parameters to describe the aine transormation Index o layer l-1 Index o layer l l l l a 11 a 12 a l l l a 21 a 22 a 23 Layer l l l l a 31 a 32 a l a 22 l 1 = (1 0.4) (1 0.4) a 22 l (1 0.4) a 12 l (1 0.6) a 13 l (1 0.6) a 23
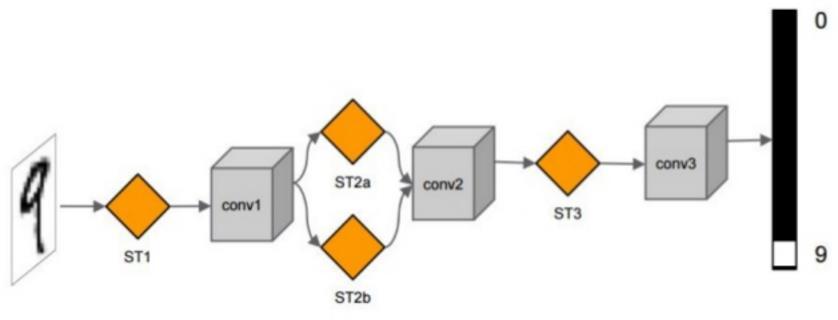
11

12


13 Street View House Number Single: one transormation layer Multi: many transormation layer
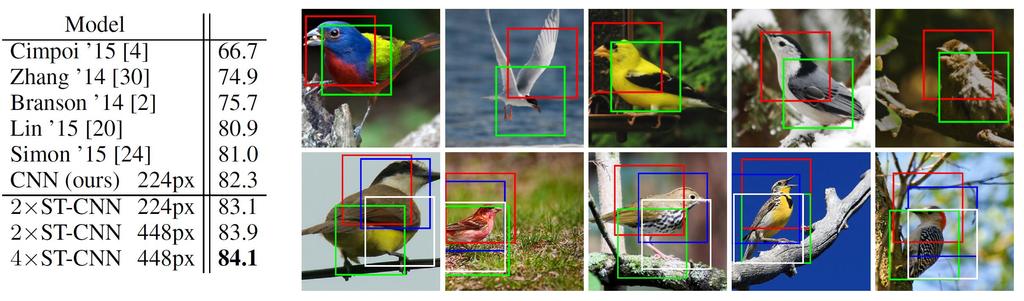
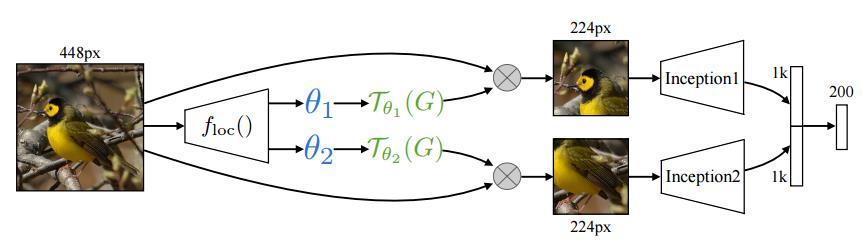
14 Brid Recognition a c 0 b d 0 e

15 Highway Network & Grid LSTM
16 Feedorward v.s. Recurrent 1. Feedorward network does not have input at each step 2. Feedorward network has dierent parameters or each layer x 1 a 1 2 a 2 3 a 3 4 y a t = l a t 1 = σ W t a t 1 + b t t is layer h 0 h 1 h 2 h 3 g y 4 x 1 x 2 a t = a t 1, x t x 3 x 4 = σ W h a t 1 + W i x t + b i t is time step Applying gated structure in eedorward network
-th layer reset update 1- a t is the output o the t-th layer r z h' No reset gate ah t-1 x")
17 GRU Highway Network y t No input x t at each step ha t-1 + ha t No output y t at each step a t-1 is the output o the (t-1)-th layer reset update 1- a t is the output o the t-th layer r z h' No reset gate ah t-1 x t x t
18 Highway Network Highway Network Gate controller z h a t copy h = σ Wa t 1 z = σ W a t 1 a t = z a t z h Residual Network h + a t a t 1 copy a t 1 a t 1 Training Very Deep Networks 8v2.pd Deep Residual Learning or Image Recognition


19 output layer output layer output layer Input layer Highway Network automatically determines the layers needed! Input layer Input layer
20 Highway Network
21 Grid LSTM y depth Memory or both time and depth a b c h LSTM c h t c h Grid LSTM c h x a b time
22 a l+1 b l+1 a l+1 b l+1 c t-1 h t-1 Grid LSTM c t h t Grid LSTM c t+1 h t+1 a l b l a l b l c t-1 h t-1 Grid LSTM c t h t Grid LSTM c t+1 h t+1 a l-1 b l-1 a l-1 b l-1

23 Grid LSTM h ' b' a b c c' c h Grid LSTM c h a z z i + tanh z z o a' a b h b
24 3D Grid LSTM a b e c c h e h a b
25 Recursive Structure
26 Application: Sentiment Analysis h 0 h 1 h 2 h 3 g sentiment x 1 x 2 x 3 x 4 word vector Word Sequence Recurrent Structure Special case o recursive structure Recursive Structure How to stack unction is already determined x 1 h 1 h 3 same dimension x 2 x 3 g h 2 x 4
27 Recursive Model syntactic structure not very good How to do it is out o the scope word sequence: not very good
28 Recursive Model By composing the two meaning, what should the meaning be. Dimension o word vector = Z Input: 2 X Z, output: Z Meaning o very good V( very good ) syntactic structure not very good V( not ) V( very ) V( good ) not very good
29 Recursive Model V(w A w B ) V(w A ) + V(w B ) syntactic structure not : neutral good : positive not very good not good : negative Meaning o very good V( very good ) V( not ) V( very ) V( good ) not very good
30 Recursive Model V(w A w B ) V(w A ) + V(w B ) syntactic structure 棒 : positive 好棒 : positive not very good 好棒棒 : negative Meaning o very good V( very good ) network V( not ) V( very ) V( good ) not very good
31 Recursive Model not good not bad syntactic structure not very good not good not bad Meaning o very good V( very good ) not : reverse another input V( not ) V( very ) V( good ) not very good
32 Recursive Model very good very bad syntactic structure not very good very good very bad Meaning o very good V( very good ) very : emphasize another input V( not ) V( very ) V( good ) not very good
33 - output re 5 classes ( --, -, 0, +, ++ ) V( not very good ) g Train both g V( not ) V( very ) V( good ) not very good
34 Recursive Neural Tensor Network p = σ W Little interaction between a and b a b = σ x T W x + W ij x i x j i,j
35 Experiments 5-class sentiment classiication ( --, -, 0, +, ++ ) Demo:
36 Experiments Socher, Richard, et al. "Recursive deep models or semantic compositionality over a sentiment treebank." Proceedings o the conerence on empirical methods in natural language processing (EMNLP). Vol
37 Matrix-Vector Recursive Network inherent meaning how it changes the others = = σ W = W M = Zero? a A Inormative? b B 1 0 Identity? 0 1? not good

38 Tree LSTM h t-1 h t Typical LSTM Tree LSTM m t-1 LSTM m t x t h 3 m 3 LSTM h 1 m 1 m 2 h 2
.")
39 More Applications Sentence relatedness NN Tai, Kai Sheng, Richard Socher, and Christopher D. Manning. "Improved semantic representations rom treestructured long short-term memory networks." arxiv preprint arxiv: (2015). Recursive Neural Network Recursive Neural Network Sentence 1 Sentence 2
40 Batch Normalization
41 Experimental Results
Spatial Transformer Networks
 BIL722 - Deep Learning for Computer Vision Spatial Transformer Networks Max Jaderberg Andrew Zisserman Karen Simonyan Koray Kavukcuoglu Contents Introduction to Spatial Transformers Related Works Spatial
BIL722 - Deep Learning for Computer Vision Spatial Transformer Networks Max Jaderberg Andrew Zisserman Karen Simonyan Koray Kavukcuoglu Contents Introduction to Spatial Transformers Related Works Spatial
Deep Learning For Mathematical Functions
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM
![a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM](/thumbs/92/107948882.jpg "a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM") c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
 2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Neural Networks Language Models
 Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Memory-Augmented Attention Model for Scene Text Recognition
 Memory-Augmented Attention Model for Scene Text Recognition Cong Wang 1,2, Fei Yin 1,2, Cheng-Lin Liu 1,2,3 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences
Memory-Augmented Attention Model for Scene Text Recognition Cong Wang 1,2, Fei Yin 1,2, Cheng-Lin Liu 1,2,3 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences
EE-559 Deep learning LSTM and GRU
 EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
Slide credit from Hung-Yi Lee & Richard Socher
 Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook
 Sumit Chopra Facebook") Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
TTIC 31230, Fundamentals of Deep Learning David McAllester, April Vanishing and Exploding Gradients. ReLUs. Xavier Initialization
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Vanishing and Exploding Gradients ReLUs Xavier Initialization Batch Normalization Highway Architectures: Resnets, LSTMs and GRUs Causes
Recurrent Neural Networks
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Recurrent Neural Networks Neural Networks and Deep Learning, Springer, 218 Chapter 7.1 7.2 The Challenges of Processing Sequences Conventional
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Neural Networks for NLP. COMP-599 Nov 30, 2016
 Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Deep Learning. Recurrent Neural Network (RNNs) Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning
 Ali Ghodsi. October 23, Slides are partially based on Book in preparation, Deep Learning") Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Recurrent Neural Network (RNNs) University of Waterloo October 23, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Sequential data Recurrent neural
Implicitly-Defined Neural Networks for Sequence Labeling
 Implicitly-Defined Neural Networks for Sequence Labeling Michaeel Kazi MIT Lincoln Laboratory 244 Wood St, Lexington, MA, 02420, USA michaeel.kazi@ll.mit.edu Abstract We relax the causality assumption
Implicitly-Defined Neural Networks for Sequence Labeling Michaeel Kazi MIT Lincoln Laboratory 244 Wood St, Lexington, MA, 02420, USA michaeel.kazi@ll.mit.edu Abstract We relax the causality assumption
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Recurrent Neural Networks (RNN) and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST
 and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST") 1 Recurrent Neural Networks (RNN) and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST Summary We have shown: Now First order optimization methods: GD (BP), SGD, Nesterov, Adagrad, ADAM, RMSPROP, etc. Second
1 Recurrent Neural Networks (RNN) and Long-Short-Term-Memory (LSTM) Yuan YAO HKUST Summary We have shown: Now First order optimization methods: GD (BP), SGD, Nesterov, Adagrad, ADAM, RMSPROP, etc. Second
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Faster Training of Very Deep Networks Via p-norm Gates
 Faster Training of Very Deep Networks Via p-norm Gates Trang Pham, Truyen Tran, Dinh Phung, Svetha Venkatesh Center for Pattern Recognition and Data Analytics Deakin University, Geelong Australia Email:
Faster Training of Very Deep Networks Via p-norm Gates Trang Pham, Truyen Tran, Dinh Phung, Svetha Venkatesh Center for Pattern Recognition and Data Analytics Deakin University, Geelong Australia Email:
MULTIPLICATIVE LSTM FOR SEQUENCE MODELLING
 MULTIPLICATIVE LSTM FOR SEQUENCE MODELLING Ben Krause, Iain Murray & Steve Renals School of Informatics, University of Edinburgh Edinburgh, Scotland, UK {ben.krause,i.murray,s.renals}@ed.ac.uk Liang Lu
MULTIPLICATIVE LSTM FOR SEQUENCE MODELLING Ben Krause, Iain Murray & Steve Renals School of Informatics, University of Edinburgh Edinburgh, Scotland, UK {ben.krause,i.murray,s.renals}@ed.ac.uk Liang Lu
COMPARING FIXED AND ADAPTIVE COMPUTATION TIME FOR RE-
 Workshop track - ICLR COMPARING FIXED AND ADAPTIVE COMPUTATION TIME FOR RE- CURRENT NEURAL NETWORKS Daniel Fojo, Víctor Campos, Xavier Giró-i-Nieto Universitat Politècnica de Catalunya, Barcelona Supercomputing
Workshop track - ICLR COMPARING FIXED AND ADAPTIVE COMPUTATION TIME FOR RE- CURRENT NEURAL NETWORKS Daniel Fojo, Víctor Campos, Xavier Giró-i-Nieto Universitat Politècnica de Catalunya, Barcelona Supercomputing
Recurrent Autoregressive Networks for Online Multi-Object Tracking. Presented By: Ishan Gupta
 Recurrent Autoregressive Networks for Online Multi-Object Tracking Presented By: Ishan Gupta Outline Multi Object Tracking Recurrent Autoregressive Networks (RANs) RANs for Online Tracking Other State
Recurrent Autoregressive Networks for Online Multi-Object Tracking Presented By: Ishan Gupta Outline Multi Object Tracking Recurrent Autoregressive Networks (RANs) RANs for Online Tracking Other State
RECURRENT NETWORKS I. Philipp Krähenbühl
 RECURRENT NETWORKS I Philipp Krähenbühl RECAP: CLASSIFICATION conv 1 conv 2 conv 3 conv 4 1 2 tu RECAP: SEGMENTATION conv 1 conv 2 conv 3 conv 4 RECAP: DETECTION conv 1 conv 2 conv 3 conv 4 RECAP: GENERATION
RECURRENT NETWORKS I Philipp Krähenbühl RECAP: CLASSIFICATION conv 1 conv 2 conv 3 conv 4 1 2 tu RECAP: SEGMENTATION conv 1 conv 2 conv 3 conv 4 RECAP: DETECTION conv 1 conv 2 conv 3 conv 4 RECAP: GENERATION
Recurrent and Recursive Networks
 Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Gated Recurrent Neural Tensor Network
 Gated Recurrent Neural Tensor Network Andros Tjandra, Sakriani Sakti, Ruli Manurung, Mirna Adriani and Satoshi Nakamura Faculty of Computer Science, Universitas Indonesia, Indonesia Email: andros.tjandra@gmail.com,
Gated Recurrent Neural Tensor Network Andros Tjandra, Sakriani Sakti, Ruli Manurung, Mirna Adriani and Satoshi Nakamura Faculty of Computer Science, Universitas Indonesia, Indonesia Email: andros.tjandra@gmail.com,
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Conditional Image Generation with PixelCNN Decoders
 Conditional Image Generation with PixelCNN Decoders Aaron van den Oord 1 Nal Kalchbrenner 1 Oriol Vinyals 1 Lasse Espeholt 1 Alex Graves 1 Koray Kavukcuoglu 1 1 Google DeepMind NIPS, 2016 Presenter: Beilun
Conditional Image Generation with PixelCNN Decoders Aaron van den Oord 1 Nal Kalchbrenner 1 Oriol Vinyals 1 Lasse Espeholt 1 Alex Graves 1 Koray Kavukcuoglu 1 1 Google DeepMind NIPS, 2016 Presenter: Beilun
Deep Learning Tutorial. 李宏毅 Hung-yi Lee
 Deep Learning Tutorial 李宏毅 Hung-yi Lee Outline Part I: Introduction of Deep Learning Part II: Why Deep? Part III: Tips for Training Deep Neural Network Part IV: Neural Network with Memory Part I: Introduction
Deep Learning Tutorial 李宏毅 Hung-yi Lee Outline Part I: Introduction of Deep Learning Part II: Why Deep? Part III: Tips for Training Deep Neural Network Part IV: Neural Network with Memory Part I: Introduction
Machine Translation. 10: Advanced Neural Machine Translation Architectures. Rico Sennrich. University of Edinburgh. R. Sennrich MT / 26
 Machine Translation 10: Advanced Neural Machine Translation Architectures Rico Sennrich University of Edinburgh R. Sennrich MT 2018 10 1 / 26 Today s Lecture so far today we discussed RNNs as encoder and
Machine Translation 10: Advanced Neural Machine Translation Architectures Rico Sennrich University of Edinburgh R. Sennrich MT 2018 10 1 / 26 Today s Lecture so far today we discussed RNNs as encoder and
Deep Learning and Lexical, Syntactic and Semantic Analysis. Wanxiang Che and Yue Zhang
 Deep Learning and Lexical, Syntactic and Semantic Analysis Wanxiang Che and Yue Zhang 2016-10 Part 2: Introduction to Deep Learning Part 2.1: Deep Learning Background What is Machine Learning? From Data
Deep Learning and Lexical, Syntactic and Semantic Analysis Wanxiang Che and Yue Zhang 2016-10 Part 2: Introduction to Deep Learning Part 2.1: Deep Learning Background What is Machine Learning? From Data
Sequence Models. Ji Yang. Department of Computing Science, University of Alberta. February 14, 2018
 Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Recurrent Neural Networks 2. CS 287 (Based on Yoav Goldberg s notes)
") Recurrent Neural Networks 2 CS 287 (Based on Yoav Goldberg s notes) Review: Representation of Sequence Many tasks in NLP involve sequences w 1,..., w n Representations as matrix dense vectors X (Following
Recurrent Neural Networks 2 CS 287 (Based on Yoav Goldberg s notes) Review: Representation of Sequence Many tasks in NLP involve sequences w 1,..., w n Representations as matrix dense vectors X (Following
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
Seq2Tree: A Tree-Structured Extension of LSTM Network
 Seq2Tree: A Tree-Structured Extension of LSTM Network Weicheng Ma Computer Science Department, Boston University 111 Cummington Mall, Boston, MA wcma@bu.edu Kai Cao Cambia Health Solutions kai.cao@cambiahealth.com
Seq2Tree: A Tree-Structured Extension of LSTM Network Weicheng Ma Computer Science Department, Boston University 111 Cummington Mall, Boston, MA wcma@bu.edu Kai Cao Cambia Health Solutions kai.cao@cambiahealth.com
Recurrent Neuronal Network tailored for Weather Radar Nowcasting
 Recurrent Neuronal Network tailored for Weather Radar Nowcasting Andreas Scheidegger, June 23 2016 Eawag: Swiss Federal Institute of Aquatic Science and Technology Weather Radar Nowcasting t-4 t-3 t-2
Recurrent Neuronal Network tailored for Weather Radar Nowcasting Andreas Scheidegger, June 23 2016 Eawag: Swiss Federal Institute of Aquatic Science and Technology Weather Radar Nowcasting t-4 t-3 t-2
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
arxiv: v1 [cs.cl] 5 Jul 2017
![arxiv: v1 [cs.cl] 5 Jul 2017](/thumbs/72/66380526.jpg "arxiv: v1 [cs.cl] 5 Jul 2017") A Deep Network with Visual Text Composition Behavior Hongyu Guo National Research Council Canada 1200 Montreal Road, Ottawa, Ontario, K1A 0R6 hongyu.guo@nrc-cnrc.gc.ca arxiv:1707.01555v1 [cs.cl] 5 Jul
A Deep Network with Visual Text Composition Behavior Hongyu Guo National Research Council Canada 1200 Montreal Road, Ottawa, Ontario, K1A 0R6 hongyu.guo@nrc-cnrc.gc.ca arxiv:1707.01555v1 [cs.cl] 5 Jul
Recurrent Neural Networks. deeplearning.ai. Why sequence models?
 Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Conditional Language modeling with attention
 Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Spring 2018 http://vllab.ee.ntu.edu.tw/dlcv.html (primary) https://ceiba.ntu.edu.tw/1062dlcv (grade, etc.) FB: DLCV Spring 2018 Yu-Chiang Frank Wang 王鈺強, Associate Professor
Deep Learning for Computer Vision Spring 2018 http://vllab.ee.ntu.edu.tw/dlcv.html (primary) https://ceiba.ntu.edu.tw/1062dlcv (grade, etc.) FB: DLCV Spring 2018 Yu-Chiang Frank Wang 王鈺強, Associate Professor
BEYOND WORD IMPORTANCE: CONTEXTUAL DE-
 BEYOND WORD IMPORTANCE: CONTEXTUAL DE- COMPOSITION TO EXTRACT INTERACTIONS FROM LSTMS W. James Murdoch Department of Statistics University of California, Berkeley jmurdoch@berkeley.edu Peter J. Liu Google
BEYOND WORD IMPORTANCE: CONTEXTUAL DE- COMPOSITION TO EXTRACT INTERACTIONS FROM LSTMS W. James Murdoch Department of Statistics University of California, Berkeley jmurdoch@berkeley.edu Peter J. Liu Google
Recurrent Neural Network
 Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop
 Different descriptions and viewpoints of backprop") Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop Project Tips Announcement: Hint for PSet1: Understand
Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop Project Tips Announcement: Hint for PSet1: Understand
Lecture 8: Recurrent Neural Networks
 Lecture 8: Recurrent Neural Networks André Martins Deep Structured Learning Course, Fall 2018 André Martins (IST) Lecture 8 IST, Fall 2018 1 / 85 Announcements The deadline for the project midterm report
Lecture 8: Recurrent Neural Networks André Martins Deep Structured Learning Course, Fall 2018 André Martins (IST) Lecture 8 IST, Fall 2018 1 / 85 Announcements The deadline for the project midterm report
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
CSC321 Lecture 10 Training RNNs
 CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Introduction to RNNs!
 Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
arxiv: v3 [cs.lg] 14 Jan 2018
![arxiv: v3 [cs.lg] 14 Jan 2018](/thumbs/92/109503708.jpg "arxiv: v3 [cs.lg] 14 Jan 2018") A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
COMP 408/508. Computer Vision Fall 2017 PCA for Recognition
 COMP 408/508 Computer Vision Fall 07 PCA or Recognition Recall: Color Gradient by PCA v λ ( G G, ) x x x R R v, v : eigenvectors o D D with v ^v (, ) x x λ, λ : eigenvalues o D D with λ >λ v λ ( B B, )
COMP 408/508 Computer Vision Fall 07 PCA or Recognition Recall: Color Gradient by PCA v λ ( G G, ) x x x R R v, v : eigenvectors o D D with v ^v (, ) x x λ, λ : eigenvalues o D D with λ >λ v λ ( B B, )
Improved Learning through Augmenting the Loss
 Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
arxiv: v1 [cs.cl] 21 May 2017
![arxiv: v1 [cs.cl] 21 May 2017](/thumbs/92/109535705.jpg "arxiv: v1 [cs.cl] 21 May 2017") Spelling Correction as a Foreign Language Yingbo Zhou yingbzhou@ebay.com Utkarsh Porwal uporwal@ebay.com Roberto Konow rkonow@ebay.com arxiv:1705.07371v1 [cs.cl] 21 May 2017 Abstract In this paper, we
Spelling Correction as a Foreign Language Yingbo Zhou yingbzhou@ebay.com Utkarsh Porwal uporwal@ebay.com Roberto Konow rkonow@ebay.com arxiv:1705.07371v1 [cs.cl] 21 May 2017 Abstract In this paper, we
Tackling the Limits of Deep Learning for NLP
 Tackling the Limits of Deep Learning for NLP Richard Socher Salesforce Research Caiming Xiong, Romain Paulus, Stephen Merity, James Bradbury, Victor Zhong Einstein s Deep Learning Einstein Vision Einstein
Tackling the Limits of Deep Learning for NLP Richard Socher Salesforce Research Caiming Xiong, Romain Paulus, Stephen Merity, James Bradbury, Victor Zhong Einstein s Deep Learning Einstein Vision Einstein
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Incorporating Pre-Training in Long Short-Term Memory Networks for Tweets Classification
 Incorporating Pre-Training in Long Short-Term Memory Networks for Tweets Classification Shuhan Yuan, Xintao Wu and Yang Xiang Tongji University, Shanghai, China, Email: {4e66,shxiangyang}@tongji.edu.cn
Incorporating Pre-Training in Long Short-Term Memory Networks for Tweets Classification Shuhan Yuan, Xintao Wu and Yang Xiang Tongji University, Shanghai, China, Email: {4e66,shxiangyang}@tongji.edu.cn
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
A Survey of Techniques for Sentiment Analysis in Movie Reviews and Deep Stochastic Recurrent Nets
 A Survey of Techniques for Sentiment Analysis in Movie Reviews and Deep Stochastic Recurrent Nets Chase Lochmiller Department of Computer Science Stanford University cjloch11@stanford.edu Abstract In this
A Survey of Techniques for Sentiment Analysis in Movie Reviews and Deep Stochastic Recurrent Nets Chase Lochmiller Department of Computer Science Stanford University cjloch11@stanford.edu Abstract In this
Recurrent Neural Networks Deep Learning Lecture 5. Efstratios Gavves
 Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Today s Lecture. Dropout
 Today s Lecture so far we discussed RNNs as encoder and decoder we discussed some architecture variants: RNN vs. GRU vs. LSTM attention mechanisms Machine Translation 1: Advanced Neural Machine Translation
Today s Lecture so far we discussed RNNs as encoder and decoder we discussed some architecture variants: RNN vs. GRU vs. LSTM attention mechanisms Machine Translation 1: Advanced Neural Machine Translation
Neural Architectures for Image, Language, and Speech Processing
 Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Differentiable Fine-grained Quantization for Deep Neural Network Compression
 Differentiable Fine-grained Quantization for Deep Neural Network Compression Hsin-Pai Cheng hc218@duke.edu Yuanjun Huang University of Science and Technology of China Anhui, China yjhuang@mail.ustc.edu.cn
Differentiable Fine-grained Quantization for Deep Neural Network Compression Hsin-Pai Cheng hc218@duke.edu Yuanjun Huang University of Science and Technology of China Anhui, China yjhuang@mail.ustc.edu.cn
Short-term water demand forecast based on deep neural network ABSTRACT
 Short-term water demand forecast based on deep neural network Guancheng Guo 1, Shuming Liu 2 1,2 School of Environment, Tsinghua University, 100084, Beijing, China 2 shumingliu@tsinghua.edu.cn ABSTRACT
Short-term water demand forecast based on deep neural network Guancheng Guo 1, Shuming Liu 2 1,2 School of Environment, Tsinghua University, 100084, Beijing, China 2 shumingliu@tsinghua.edu.cn ABSTRACT
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSCI 315: Artificial Intelligence through Deep Learning
 CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates
 Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates Hiroaki Hayashi 1,* Jayanth Koushik 1,* Graham Neubig 1 arxiv:1611.01505v3 [cs.lg] 11 Jun 2018 Abstract Adaptive
Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates Hiroaki Hayashi 1,* Jayanth Koushik 1,* Graham Neubig 1 arxiv:1611.01505v3 [cs.lg] 11 Jun 2018 Abstract Adaptive
Natural Language Understanding. Recap: probability, language models, and feedforward networks. Lecture 12: Recurrent Neural Networks and LSTMs
 Natural Language Understanding Lecture 12: Recurrent Neural Networks and LSTMs Recap: probability, language models, and feedforward networks Simple Recurrent Networks Adam Lopez Credits: Mirella Lapata
Natural Language Understanding Lecture 12: Recurrent Neural Networks and LSTMs Recap: probability, language models, and feedforward networks Simple Recurrent Networks Adam Lopez Credits: Mirella Lapata
Deep Sequence Models. Context Representation, Regularization, and Application to Language. Adji Bousso Dieng
 Deep Sequence Models Context Representation, Regularization, and Application to Language Adji Bousso Dieng All Data Are Born Sequential Time underlies many interesting human behaviors. Elman, 1990. Why
Deep Sequence Models Context Representation, Regularization, and Application to Language Adji Bousso Dieng All Data Are Born Sequential Time underlies many interesting human behaviors. Elman, 1990. Why
(
 Class 15 - Long Short-Term Memory (LSTM) Study materials http://colah.github.io/posts/2015-08-understanding-lstms/ (http://colah.github.io/posts/2015-08-understanding-lstms/) http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Class 15 - Long Short-Term Memory (LSTM) Study materials http://colah.github.io/posts/2015-08-understanding-lstms/ (http://colah.github.io/posts/2015-08-understanding-lstms/) http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Recurrent Neural Network
 Recurrent Neural Network The Deepest of All Deep Learning Slides by Chen Liang Deep Learning Deep Learning Deep learning works like the human brain? Demystify Deep Learning Deep Learning: Building Blocks
Recurrent Neural Network The Deepest of All Deep Learning Slides by Chen Liang Deep Learning Deep Learning Deep learning works like the human brain? Demystify Deep Learning Deep Learning: Building Blocks
arxiv: v3 [cs.cl] 24 Feb 2018
![arxiv: v3 [cs.cl] 24 Feb 2018](/thumbs/82/86952145.jpg "arxiv: v3 [cs.cl] 24 Feb 2018") FACTORIZATION TRICKS FOR LSTM NETWORKS Oleksii Kuchaiev NVIDIA okuchaiev@nvidia.com Boris Ginsburg NVIDIA bginsburg@nvidia.com ABSTRACT arxiv:1703.10722v3 [cs.cl] 24 Feb 2018 We present two simple ways
FACTORIZATION TRICKS FOR LSTM NETWORKS Oleksii Kuchaiev NVIDIA okuchaiev@nvidia.com Boris Ginsburg NVIDIA bginsburg@nvidia.com ABSTRACT arxiv:1703.10722v3 [cs.cl] 24 Feb 2018 We present two simple ways
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
EE-559 Deep learning Recurrent Neural Networks
 EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
Conditional Kronecker Batch Normalization for Compositional Reasoning
 STUDENT, PROF, COLLABORATOR: BMVC AUTHOR GUIDELINES 1 Conditional Kronecker Batch Normalization for Compositional Reasoning Cheng Shi 12 shic17@mails.tsinghua.edu.cn Chun Yuan 2 yuanc@sz.tsinghua.edu.cn
STUDENT, PROF, COLLABORATOR: BMVC AUTHOR GUIDELINES 1 Conditional Kronecker Batch Normalization for Compositional Reasoning Cheng Shi 12 shic17@mails.tsinghua.edu.cn Chun Yuan 2 yuanc@sz.tsinghua.edu.cn
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Language Modeling. Hung-yi Lee 李宏毅
 Language Modeling Hung-yi Lee 李宏毅 Language modeling Language model: Estimated the probability of word sequence Word sequence: w 1, w 2, w 3,., w n P(w 1, w 2, w 3,., w n ) Application: speech recognition
Language Modeling Hung-yi Lee 李宏毅 Language modeling Language model: Estimated the probability of word sequence Word sequence: w 1, w 2, w 3,., w n P(w 1, w 2, w 3,., w n ) Application: speech recognition
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing Xipeng Qiu xpqiu@fudan.edu.cn http://nlp.fudan.edu.cn http://nlp.fudan.edu.cn Fudan University 2016/5/29, CCF ADL, Beijing Xipeng Qiu (Fudan University) Deep
Deep Learning for Natural Language Processing Xipeng Qiu xpqiu@fudan.edu.cn http://nlp.fudan.edu.cn http://nlp.fudan.edu.cn Fudan University 2016/5/29, CCF ADL, Beijing Xipeng Qiu (Fudan University) Deep
Generative Models for Sentences
 Generative Models for Sentences Amjad Almahairi PhD student August 16 th 2014 Outline 1. Motivation Language modelling Full Sentence Embeddings 2. Approach Bayesian Networks Variational Autoencoders (VAE)
Generative Models for Sentences Amjad Almahairi PhD student August 16 th 2014 Outline 1. Motivation Language modelling Full Sentence Embeddings 2. Approach Bayesian Networks Variational Autoencoders (VAE)
A QUESTION ANSWERING SYSTEM USING ENCODER-DECODER, SEQUENCE-TO-SEQUENCE, RECURRENT NEURAL NETWORKS. A Project. Presented to
 A QUESTION ANSWERING SYSTEM USING ENCODER-DECODER, SEQUENCE-TO-SEQUENCE, RECURRENT NEURAL NETWORKS A Project Presented to The Faculty of the Department of Computer Science San José State University In
A QUESTION ANSWERING SYSTEM USING ENCODER-DECODER, SEQUENCE-TO-SEQUENCE, RECURRENT NEURAL NETWORKS A Project Presented to The Faculty of the Department of Computer Science San José State University In
ATASS: Word Embeddings
 ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
Very Deep Residual Networks with Maxout for Plant Identification in the Wild Milan Šulc, Dmytro Mishkin, Jiří Matas
 Very Deep Residual Networks with Maxout for Plant Identification in the Wild Milan Šulc, Dmytro Mishkin, Jiří Matas Center for Machine Perception Department of Cybernetics Faculty of Electrical Engineering
Very Deep Residual Networks with Maxout for Plant Identification in the Wild Milan Šulc, Dmytro Mishkin, Jiří Matas Center for Machine Perception Department of Cybernetics Faculty of Electrical Engineering
Development of a Deep Recurrent Neural Network Controller for Flight Applications
 Development of a Deep Recurrent Neural Network Controller for Flight Applications American Control Conference (ACC) May 26, 2017 Scott A. Nivison Pramod P. Khargonekar Department of Electrical and Computer
Development of a Deep Recurrent Neural Network Controller for Flight Applications American Control Conference (ACC) May 26, 2017 Scott A. Nivison Pramod P. Khargonekar Department of Electrical and Computer
Modelling Time Series with Neural Networks. Volker Tresp Summer 2017
 Modelling Time Series with Neural Networks Volker Tresp Summer 2017 1 Modelling of Time Series The next figure shows a time series (DAX) Other interesting time-series: energy prize, energy consumption,
Modelling Time Series with Neural Networks Volker Tresp Summer 2017 1 Modelling of Time Series The next figure shows a time series (DAX) Other interesting time-series: energy prize, energy consumption,
Neural Networks. Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016
 Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Multi-Source Neural Translation
 Multi-Source Neural Translation Barret Zoph and Kevin Knight Information Sciences Institute Department of Computer Science University of Southern California {zoph,knight}@isi.edu In the neural encoder-decoder
Multi-Source Neural Translation Barret Zoph and Kevin Knight Information Sciences Institute Department of Computer Science University of Southern California {zoph,knight}@isi.edu In the neural encoder-decoder
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Control-oriented model learning with a recurrent neural network
 Control-oriented model learning with a recurrent neural network M. A. Bucci O. Semeraro A. Allauzen L. Cordier G. Wisniewski L. Mathelin 20 November 2018, APS Atlanta Kuramoto-Sivashinsky (KS) u t = 4
Control-oriented model learning with a recurrent neural network M. A. Bucci O. Semeraro A. Allauzen L. Cordier G. Wisniewski L. Mathelin 20 November 2018, APS Atlanta Kuramoto-Sivashinsky (KS) u t = 4
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets)
") COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Spatial Transformation
 Spatial Transformation Presented by Liqun Chen June 30, 2017 1 Overview 2 Spatial Transformer Networks 3 STN experiments 4 Recurrent Models of Visual Attention (RAM) 5 Recurrent Models of Visual Attention
Spatial Transformation Presented by Liqun Chen June 30, 2017 1 Overview 2 Spatial Transformer Networks 3 STN experiments 4 Recurrent Models of Visual Attention (RAM) 5 Recurrent Models of Visual Attention