Semi-Supervised Learning by Multi-Manifold Separation
|
|
|
- Victoria Charles
- 5 years ago
- Views:
Transcription
1 Semi-Supervised Learning by Multi-Manifold Separation Xiaojin (Jerry) Zhu Department of Computer Sciences University of Wisconsin Madison Joint work with Andrew Goldberg, Zhiting Xu, Aarti Singh, and Rob Nowak Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 1 / 36
2 Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 2 / 36
3 Supervised Learning Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 3 / 36
 Semi-Supervised Learning 4")
4 Semi-Supervised Learning Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 4 / 36
5 Prediction Problems The feature space X = R d The label space Y = {0, 1} or R Samples (X, Y ) X Y P XY X: feature vector Y : label Goal: construct a predictor f : X Y to minimize R(f) E (X,Y ) PXY [loss(y, f(x))] Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 5 / 36
6 Learning from Data The optimal predictor f = argmin f E (X,Y ) PXY [loss(y, f(x))] depends on P XY, which is often unknown. However, we can learn a good predictor from a training set Supervised Learning: {(X i, Y i )} n i=1 iid P XY {(X i, Y i )} n i=1 ˆf n Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 6 / 36
7 Semi-Supervised Learning In many applications in science and engineering, labeled data are scarce, but unlabeled data are abundant and cheap. {(X i, Y i )} n i=1 Semi-Supervised Learning (SSL): iid P XY, {X j } m iid j=1 P X, m n {(X i, Y i )} n i=1, {X j } m j=1 ˆf m,n Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 7 / 36
 Semi-Supervised Learning 8 / 36")
8 Example: Handwritten Digits Recognition Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 8 / 36
9 Example: Handwritten Digits Recognition many unlabeled data + a few labeled data knowledge of manifold/cluster + a few labels in each manifold/cluster is sufficient to design a good predictor Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 9 / 36

10 Common Assumptions in SSL Cluster assumption: f is constant or smooth on connected high density regions. Manifold assumption: Support set of P X lies on low-dimensional manifolds. f is smooth wrt geodesic distance on manifolds. Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 10 / 36
11 Mathematical Formalization Generic Learning Classes: P XY = { P X P Y X : P X P X, P Y X P Y X } Linked Learning Classes: P XY = { P X P Y X : P X P X, P Y X P Y X (P X ) P Y X } Link: unlabeled data may inform design of predictor SSL can yield faster rate of error convergence than supervised learning: sup E[R( ˆf m,n )] inf sup E[R(f n )] P XY f n P XY ˆfn : predictor based on n labeled examples ˆfm,n : based on n labeled and m unlabeled examples Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 11 / 36
12 The Value of Unlabeled Data Castelli and Cover 95 (classification): assume identifiable mixture p(x) = p(x Y = 0)p(Y = 0) + p(x Y = 1)p(Y = 1) Learn decision regions from (the many) unlabeled examples Label decision regions from (the few) labeled examples Main result: sup E[R( ˆf,n )] R Ce αn P XY What about more general cluster or manifold assumptions? Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 12 / 36
13 Do Unlabeled Data Help in General? No. Lafferty & Wasserman (2007) fix complexity of P XY, let n grow given enough labeled data, unlabeled data is superfluous (no faster rates of convergence for SSL). Yes. Niyogi (2008) let complexity of P XY grow with n given finite n, the complexity of the learning problem can be such that supervised learning fails, while SSL has small expected error. Both are correct, capturing two extremes. Finite sample bounds give a more complete picture. Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 13 / 36
 Hölder-α smooth on each support set Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 14 /")
14 Decision Regions Our assumption: P XY (p X, f) supp(p X ) = i C i, union of compact sets with γ separation marginal density p X bounded away from zero, smooth in C i regression function f(x) Hölder-α smooth on each support set Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 14 / 36
![Adaptive Supervised Learning If γ γ 0 > 0 and n, SL will discover decision regions, eventually the excess risk of SL (squared loss) is minimax (SSL has no advantage): sup E[R( ˆf n )] R Cn 2α 2α+d P](/docs-images/87/97090743/images/15-0.jpg "XY But, if n fixed and γ 0, eventually SL will mix up decision regions and mess up: cn 1 d inf f n sup E[R(f n )] R P XY Unlabeled data identify decision regions, mess up later (smaller γ) Xiaojin")
15 Adaptive Supervised Learning If γ γ 0 > 0 and n, SL will discover decision regions, eventually the excess risk of SL (squared loss) is minimax (SSL has no advantage): sup E[R( ˆf n )] R Cn 2α 2α+d P XY But, if n fixed and γ 0, eventually SL will mix up decision regions and mess up: cn 1 d inf f n sup E[R(f n )] R P XY Unlabeled data identify decision regions, mess up later (smaller γ) Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 15 / 36




16 Unlabeled Data: Now it helps, now it doesn t (Singh, Nowak & Zhu, NIPS 2008) margin SSL SL SSL upper lower helps? n 1 d γ n 2α 2α+d n 2α 2α+d no m 1 d γ < n 1 d n 2α 2α+d n 1 d yes m 1 d γ < m 1 d n 1 d n 1 d no γ < m 1 d n 2α 2α+d n 1 d yes Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 16 / 36
17 An SSL Algorithm Given n labeled examples and m unlabeled examples, 1 Use unlabeled data to infer log(n) decision regions Ĉi plug in your favorite manifold clustering algorithm that detects abrupt change in support, density, dimensionality, etc. carve up ambient space into Ĉi: Voronoi each Ĉi has to be big enough, n/ log 2 (n) labeled examples, m/ log 2 (n) unlabeled examples 2 Use the labeled data in Ĉi to train SL ˆf i 3 If a test point x Ĉi, predict ˆf i (x ) Similar to cluster & label. Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 17 / 36
18 Building Blocks: Local Covariance Matrix For x {x i } n+m i=1, find its [log(n + m)] nearest neighbors (in Euclidean distance) The local covariance matrix of the neighbors Σ x = 1 [log(n + m)] 1 Σ x captures local geometry (x j µ x )(x j µ x ) j Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 18 / 36
 Semi-Supervised Learning 19 / 36")
19 Building Blocks: Local Covariance Matrix Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 19 / 36
20 A Distance Between Σ 1 and Σ 2 Hellinger distance H 2 (p, q) = 1 ( ) 2 p(x) q(x) dx 2 H(p, q) symmetric, in [0, 1] Let p = N(0, Σ 1 ), q = N(0, Σ 2 ). We define d H(Σ 1, Σ 2 ) = Σ Σ Σ 1 + Σ (computed in common subspace) Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 20 / 36
")



21 Hellinger Distance Comment H(Σ 1, Σ 2 ) similar 0.02 density 0.28 dimension 1 orientation 1 * smoothed version: Σ + ɛi Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 21 / 36
 nearest neighbors Let x 1 be the next nearest neighbor, repeat Include all labeled data Random sampling might work too Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 22 /")
22 A Sparse Subset Two close points will have similar neighbors small H even they are on different manifolds Compute a sparse subset of m = points (red dots): m log(m) Start from an arbitrary x 0 Remove its log(m) nearest neighbors Let x 1 be the next nearest neighbor, repeat Include all labeled data Random sampling might work too Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 22 / 36
23 A Sparse Graph on the Sparse Subset Sparse nearest neighbor graph on the sparse subset, use Mahalanobis distance to trace the manifold d 2 (x, y) = (x y) Σ 1 x (x y) Gaussian edge weight on sparse edges Combines locality and shape w ij = e H 2 (Σxi,Σx j ) 2σ 2 Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 23 / 36
 Semi-Supervised Learning 24 /")
24 A Sparse Graph on the Sparse Subset Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 24 / 36
 Semi-Supervised")
25 A Sparse Graph on the Sparse Subset Red=large w, yellow=small w Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 25 / 36
26 Multi-Manifold Separation as Graph Cut Cut the graph W = [w ij ] into k [log(n)] parts Each part has at least n/ log 2 (n) labeled examples, m / log 2 (n) unlabeled examples Formally: RatioCut with size constraints Let the k parts be A 1,..., A k cut(a i, Ā i ) = s A w i,t Āi st cut(a 1,..., A k ) = k i=1 cut(a i, Āi) Minimize cut directly tend to produce very unbalanced parts RatioCut(A 1,..., A k ) = k cut(a i,āi) i=1 A i However, this balancing heuristic may not satisfy our size constraints Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 26 / 36
27 RatioCut Approximated by Spectral Clustering Well-known RatioCut approximation (without size constraints) [e.g., von Luxburg 2006] Define k indicator vectors h 1,..., h k { 1/ Aj if i A h ij = j 0 otherwise Matrix H has columns h 1,..., h k, H H = I RatioCut(A 1,..., A k ) = 1 2 tr(h LH) min H tr(h LH) subject to H H = I Relax elements of H to R [Rayleigh-Ritz] h 1,..., h k are the first k eigenvectors of L. Un-relax H to hard partition: k-way clustering Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 27 / 36
28 RatioCut Approximated by Spectral Clustering The spectral clustering algorithm (without size constraints): 1 Unnormalized Laplacian L = D W 2 First k eigenvectors v 1,..., v k of L 3 V matrix: v 1,..., v k as columns, n + m rows 4 New representation of x i : the ith row of V 5 Cluster x i into k clusters with k-means. The clusters define A 1,..., A k. Next: enforce size constraints in k-means. Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 28 / 36
29 Standard (Unconstrained) k-means k-means clusters x 1... x N into k clusters with center C 1... C k : min C 1...C k N i=1 min h=1...k ( ) 1 2 x i C h 2 Introduce indicator matrix T, T ih = 1 if x i belongs to C h min C,T s.t. N k i=1 h=1 T ( 1 ih 2 x i C h 2) k h=1 T ih = 1, T 0 Local optimum found by starting from arbitrary C 1... C k and iterating: 1 Update T i : assign each point x i to its closest center C h 2 Update centers C 1... C k by the mean of points assigned to that center Note: each step reduces the objective. Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 29 / 36
30 Size Constrained k-means (Bradley, Bennett, Demiriz. 2000) Size constraints: cluster h must have at least τ h points min C,T s.t. N k i=1 h=1 T ( 1 ih 2 x i C h 2) k h=1 T ih = 1, T 0 N i=1 T ih τ h, h = 1... k. Solving T looks like a difficult integer problem Surprise: efficient integer solution found by Minimum Cost Flow linear program Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 30 / 36
31 Minimum Cost Flow A graph with supply nodes (b i > 0) and demand nodes (b i < 0); directed edge i j has unit transportation cost c ij, traffic variable y ij 0; Meet demand with minimum transportation cost min y s.t. i j c ijy ij j y ij j y ji = b i Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 31 / 36
32 Minimum Cost Flow with Two Constraints Each cluster has at least n/ log 2 (n) labeled examples, m / log 2 (n) unlabeled examples Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 32 / 36

")
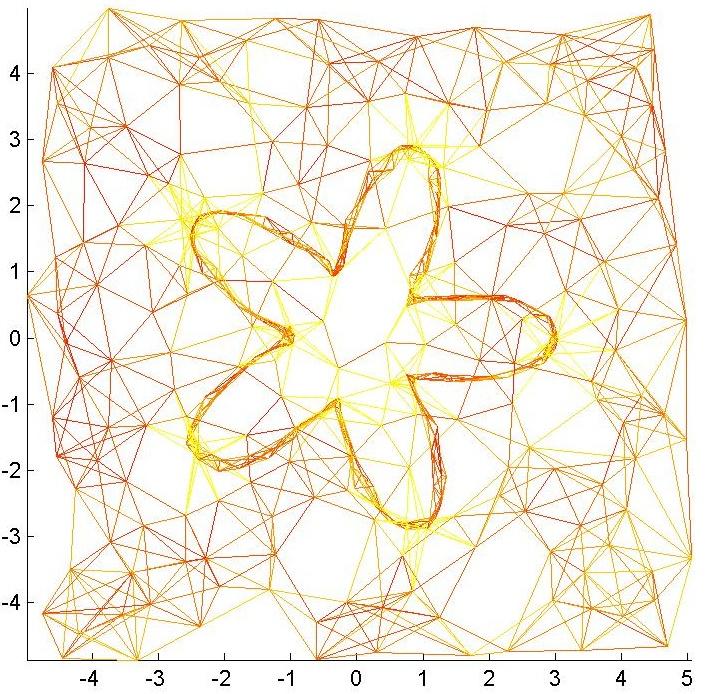
33 Example Cuts Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 33 / 36
34 SSL Example: Two Squares Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 34 / 36
35 SSL Example: Two Squares Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 35 / 36
 Semi-Supervised Learning 36")
36 SSL Example: Dollar Sign Xiaojin Zhu (Wisconsin) Semi-Supervised Learning 36 / 36
Unlabeled Data: Now It Helps, Now It Doesn t
 institution-logo-filena A. Singh, R. D. Nowak, and X. Zhu. In NIPS, 2008. 1 Courant Institute, NYU April 21, 2015 Outline institution-logo-filena 1 Conflicting Views in Semi-supervised Learning The Cluster
institution-logo-filena A. Singh, R. D. Nowak, and X. Zhu. In NIPS, 2008. 1 Courant Institute, NYU April 21, 2015 Outline institution-logo-filena 1 Conflicting Views in Semi-supervised Learning The Cluster
Unlabeled data: Now it helps, now it doesn t
 Unlabeled data: Now it helps, now it doesn t Aarti Singh, Robert D. Nowak Xiaojin Zhu Department of Electrical and Computer Engineering Department of Computer Sciences University of Wisconsin - Madison
Unlabeled data: Now it helps, now it doesn t Aarti Singh, Robert D. Nowak Xiaojin Zhu Department of Electrical and Computer Engineering Department of Computer Sciences University of Wisconsin - Madison
Hou, Ch. et al. IEEE Transactions on Neural Networks March 2011
 Hou, Ch. et al. IEEE Transactions on Neural Networks March 2011 Semi-supervised approach which attempts to incorporate partial information from unlabeled data points Semi-supervised approach which attempts
Hou, Ch. et al. IEEE Transactions on Neural Networks March 2011 Semi-supervised approach which attempts to incorporate partial information from unlabeled data points Semi-supervised approach which attempts
Spectral Clustering on Handwritten Digits Database
 University of Maryland-College Park Advance Scientific Computing I,II Spectral Clustering on Handwritten Digits Database Author: Danielle Middlebrooks Dmiddle1@math.umd.edu Second year AMSC Student Advisor:
University of Maryland-College Park Advance Scientific Computing I,II Spectral Clustering on Handwritten Digits Database Author: Danielle Middlebrooks Dmiddle1@math.umd.edu Second year AMSC Student Advisor:
Spectral Clustering. Zitao Liu
 Spectral Clustering Zitao Liu Agenda Brief Clustering Review Similarity Graph Graph Laplacian Spectral Clustering Algorithm Graph Cut Point of View Random Walk Point of View Perturbation Theory Point of
Spectral Clustering Zitao Liu Agenda Brief Clustering Review Similarity Graph Graph Laplacian Spectral Clustering Algorithm Graph Cut Point of View Random Walk Point of View Perturbation Theory Point of
Manifold Regularization
 9.520: Statistical Learning Theory and Applications arch 3rd, 200 anifold Regularization Lecturer: Lorenzo Rosasco Scribe: Hooyoung Chung Introduction In this lecture we introduce a class of learning algorithms,
9.520: Statistical Learning Theory and Applications arch 3rd, 200 anifold Regularization Lecturer: Lorenzo Rosasco Scribe: Hooyoung Chung Introduction In this lecture we introduce a class of learning algorithms,
Unsupervised Learning Techniques Class 07, 1 March 2006 Andrea Caponnetto
 Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
A graph based approach to semi-supervised learning
 A graph based approach to semi-supervised learning 1 Feb 2011 Two papers M. Belkin, P. Niyogi, and V Sindhwani. Manifold regularization: a geometric framework for learning from labeled and unlabeled examples.
A graph based approach to semi-supervised learning 1 Feb 2011 Two papers M. Belkin, P. Niyogi, and V Sindhwani. Manifold regularization: a geometric framework for learning from labeled and unlabeled examples.
Spectral Clustering. Guokun Lai 2016/10
 Spectral Clustering Guokun Lai 2016/10 1 / 37 Organization Graph Cut Fundamental Limitations of Spectral Clustering Ng 2002 paper (if we have time) 2 / 37 Notation We define a undirected weighted graph
Spectral Clustering Guokun Lai 2016/10 1 / 37 Organization Graph Cut Fundamental Limitations of Spectral Clustering Ng 2002 paper (if we have time) 2 / 37 Notation We define a undirected weighted graph
Beyond the Point Cloud: From Transductive to Semi-Supervised Learning
 Beyond the Point Cloud: From Transductive to Semi-Supervised Learning Vikas Sindhwani, Partha Niyogi, Mikhail Belkin Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of
Beyond the Point Cloud: From Transductive to Semi-Supervised Learning Vikas Sindhwani, Partha Niyogi, Mikhail Belkin Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of
Analysis of Spectral Kernel Design based Semi-supervised Learning
 Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
Seeing stars when there aren't many stars Graph-based semi-supervised learning for sentiment categorization
 Seeing stars when there aren't many stars Graph-based semi-supervised learning for sentiment categorization Andrew B. Goldberg, Xiaojin Jerry Zhu Computer Sciences Department University of Wisconsin-Madison
Seeing stars when there aren't many stars Graph-based semi-supervised learning for sentiment categorization Andrew B. Goldberg, Xiaojin Jerry Zhu Computer Sciences Department University of Wisconsin-Madison
MATH 567: Mathematical Techniques in Data Science Clustering II
 This lecture is based on U. von Luxburg, A Tutorial on Spectral Clustering, Statistics and Computing, 17 (4), 2007. MATH 567: Mathematical Techniques in Data Science Clustering II Dominique Guillot Departments
This lecture is based on U. von Luxburg, A Tutorial on Spectral Clustering, Statistics and Computing, 17 (4), 2007. MATH 567: Mathematical Techniques in Data Science Clustering II Dominique Guillot Departments
Fast learning rates for plug-in classifiers under the margin condition
 Fast learning rates for plug-in classifiers under the margin condition Jean-Yves Audibert 1 Alexandre B. Tsybakov 2 1 Certis ParisTech - Ecole des Ponts, France 2 LPMA Université Pierre et Marie Curie,
Fast learning rates for plug-in classifiers under the margin condition Jean-Yves Audibert 1 Alexandre B. Tsybakov 2 1 Certis ParisTech - Ecole des Ponts, France 2 LPMA Université Pierre et Marie Curie,
MLCC Clustering. Lorenzo Rosasco UNIGE-MIT-IIT
 MLCC 2018 - Clustering Lorenzo Rosasco UNIGE-MIT-IIT About this class We will consider an unsupervised setting, and in particular the problem of clustering unlabeled data into coherent groups. MLCC 2018
MLCC 2018 - Clustering Lorenzo Rosasco UNIGE-MIT-IIT About this class We will consider an unsupervised setting, and in particular the problem of clustering unlabeled data into coherent groups. MLCC 2018
Online Manifold Regularization: A New Learning Setting and Empirical Study
 Online Manifold Regularization: A New Learning Setting and Empirical Study Andrew B. Goldberg 1, Ming Li 2, Xiaojin Zhu 1 1 Computer Sciences, University of Wisconsin Madison, USA. {goldberg,jerryzhu}@cs.wisc.edu
Online Manifold Regularization: A New Learning Setting and Empirical Study Andrew B. Goldberg 1, Ming Li 2, Xiaojin Zhu 1 1 Computer Sciences, University of Wisconsin Madison, USA. {goldberg,jerryzhu}@cs.wisc.edu
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering
 Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
Classification Semi-supervised learning based on network. Speakers: Hanwen Wang, Xinxin Huang, and Zeyu Li CS Winter
 Classification Semi-supervised learning based on network Speakers: Hanwen Wang, Xinxin Huang, and Zeyu Li CS 249-2 2017 Winter Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions Xiaojin
Classification Semi-supervised learning based on network Speakers: Hanwen Wang, Xinxin Huang, and Zeyu Li CS 249-2 2017 Winter Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions Xiaojin
Graphs in Machine Learning
 Graphs in Machine Learning Michal Valko INRIA Lille - Nord Europe, France Partially based on material by: Ulrike von Luxburg, Gary Miller, Doyle & Schnell, Daniel Spielman January 27, 2015 MVA 2014/2015
Graphs in Machine Learning Michal Valko INRIA Lille - Nord Europe, France Partially based on material by: Ulrike von Luxburg, Gary Miller, Doyle & Schnell, Daniel Spielman January 27, 2015 MVA 2014/2015
Plug-in Approach to Active Learning
 Plug-in Approach to Active Learning Stanislav Minsker Stanislav Minsker (Georgia Tech) Plug-in approach to active learning 1 / 18 Prediction framework Let (X, Y ) be a random couple in R d { 1, +1}. X
Plug-in Approach to Active Learning Stanislav Minsker Stanislav Minsker (Georgia Tech) Plug-in approach to active learning 1 / 18 Prediction framework Let (X, Y ) be a random couple in R d { 1, +1}. X
Semi-Supervised Learning in Gigantic Image Collections. Rob Fergus (New York University) Yair Weiss (Hebrew University) Antonio Torralba (MIT)
 Yair Weiss (Hebrew University) Antonio Torralba (MIT)") Semi-Supervised Learning in Gigantic Image Collections Rob Fergus (New York University) Yair Weiss (Hebrew University) Antonio Torralba (MIT) Gigantic Image Collections What does the world look like? High
Semi-Supervised Learning in Gigantic Image Collections Rob Fergus (New York University) Yair Weiss (Hebrew University) Antonio Torralba (MIT) Gigantic Image Collections What does the world look like? High
Manifold Coarse Graining for Online Semi-supervised Learning
 for Online Semi-supervised Learning Mehrdad Farajtabar, Amirreza Shaban, Hamid R. Rabiee, Mohammad H. Rohban Digital Media Lab, Department of Computer Engineering, Sharif University of Technology, Tehran,
for Online Semi-supervised Learning Mehrdad Farajtabar, Amirreza Shaban, Hamid R. Rabiee, Mohammad H. Rohban Digital Media Lab, Department of Computer Engineering, Sharif University of Technology, Tehran,
Graphs, Geometry and Semi-supervised Learning
 Graphs, Geometry and Semi-supervised Learning Mikhail Belkin The Ohio State University, Dept of Computer Science and Engineering and Dept of Statistics Collaborators: Partha Niyogi, Vikas Sindhwani In
Graphs, Geometry and Semi-supervised Learning Mikhail Belkin The Ohio State University, Dept of Computer Science and Engineering and Dept of Statistics Collaborators: Partha Niyogi, Vikas Sindhwani In
Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking p. 1/31
 Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking Dengyong Zhou zhou@tuebingen.mpg.de Dept. Schölkopf, Max Planck Institute for Biological Cybernetics, Germany Learning from
Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking Dengyong Zhou zhou@tuebingen.mpg.de Dept. Schölkopf, Max Planck Institute for Biological Cybernetics, Germany Learning from
Graphs in Machine Learning
 Graphs in Machine Learning Michal Valko Inria Lille - Nord Europe, France TA: Pierre Perrault Partially based on material by: Mikhail Belkin, Jerry Zhu, Olivier Chapelle, Branislav Kveton October 30, 2017
Graphs in Machine Learning Michal Valko Inria Lille - Nord Europe, France TA: Pierre Perrault Partially based on material by: Mikhail Belkin, Jerry Zhu, Olivier Chapelle, Branislav Kveton October 30, 2017
Computer Vision Group Prof. Daniel Cremers. 10a. Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Machine Learning for Data Science (CS4786) Lecture 11
 Lecture 11") Machine Learning for Data Science (CS4786) Lecture 11 Spectral clustering Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ ANNOUNCEMENT 1 Assignment P1 the Diagnostic assignment 1 will
Machine Learning for Data Science (CS4786) Lecture 11 Spectral clustering Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ ANNOUNCEMENT 1 Assignment P1 the Diagnostic assignment 1 will
Semi-Supervised Learning with Graphs
 Semi-Supervised Learning with Graphs Xiaojin (Jerry) Zhu LTI SCS CMU Thesis Committee John Lafferty (co-chair) Ronald Rosenfeld (co-chair) Zoubin Ghahramani Tommi Jaakkola 1 Semi-supervised Learning classifiers
Semi-Supervised Learning with Graphs Xiaojin (Jerry) Zhu LTI SCS CMU Thesis Committee John Lafferty (co-chair) Ronald Rosenfeld (co-chair) Zoubin Ghahramani Tommi Jaakkola 1 Semi-supervised Learning classifiers
Semi-Supervised Learning
 Semi-Supervised Learning getting more for less in natural language processing and beyond Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning many human
Semi-Supervised Learning getting more for less in natural language processing and beyond Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning many human
How to learn from very few examples?
 How to learn from very few examples? Dengyong Zhou Department of Empirical Inference Max Planck Institute for Biological Cybernetics Spemannstr. 38, 72076 Tuebingen, Germany Outline Introduction Part A
How to learn from very few examples? Dengyong Zhou Department of Empirical Inference Max Planck Institute for Biological Cybernetics Spemannstr. 38, 72076 Tuebingen, Germany Outline Introduction Part A
MATH 567: Mathematical Techniques in Data Science Clustering II
 Spectral clustering: overview MATH 567: Mathematical Techniques in Data Science Clustering II Dominique uillot Departments of Mathematical Sciences University of Delaware Overview of spectral clustering:
Spectral clustering: overview MATH 567: Mathematical Techniques in Data Science Clustering II Dominique uillot Departments of Mathematical Sciences University of Delaware Overview of spectral clustering:
What is semi-supervised learning?
 What is semi-supervised learning? In many practical learning domains, there is a large supply of unlabeled data but limited labeled data, which can be expensive to generate text processing, video-indexing,
What is semi-supervised learning? In many practical learning domains, there is a large supply of unlabeled data but limited labeled data, which can be expensive to generate text processing, video-indexing,
Semi-Supervised Learning of Speech Sounds
 Aren Jansen Partha Niyogi Department of Computer Science Interspeech 2007 Objectives 1 Present a manifold learning algorithm based on locality preserving projections for semi-supervised phone classification
Aren Jansen Partha Niyogi Department of Computer Science Interspeech 2007 Objectives 1 Present a manifold learning algorithm based on locality preserving projections for semi-supervised phone classification
Intelligent Systems:
 Intelligent Systems: Undirected Graphical models (Factor Graphs) (2 lectures) Carsten Rother 15/01/2015 Intelligent Systems: Probabilistic Inference in DGM and UGM Roadmap for next two lectures Definition
Intelligent Systems: Undirected Graphical models (Factor Graphs) (2 lectures) Carsten Rother 15/01/2015 Intelligent Systems: Probabilistic Inference in DGM and UGM Roadmap for next two lectures Definition
Distribution-Free Distribution Regression
 Distribution-Free Distribution Regression Barnabás Póczos, Alessandro Rinaldo, Aarti Singh and Larry Wasserman AISTATS 2013 Presented by Esther Salazar Duke University February 28, 2014 E. Salazar (Reading
Distribution-Free Distribution Regression Barnabás Póczos, Alessandro Rinaldo, Aarti Singh and Larry Wasserman AISTATS 2013 Presented by Esther Salazar Duke University February 28, 2014 E. Salazar (Reading
Active and Semi-supervised Kernel Classification
 Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Semi-supervised Learning
 Semi-supervised Learning Introduction Supervised learning: x r, y r R r=1 E.g.x r : image, y r : class labels Semi-supervised learning: x r, y r r=1 R, x u R+U u=r A set of unlabeled data, usually U >>
Semi-supervised Learning Introduction Supervised learning: x r, y r R r=1 E.g.x r : image, y r : class labels Semi-supervised learning: x r, y r r=1 R, x u R+U u=r A set of unlabeled data, usually U >>
Semi-Supervised Learning with Graphs. Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University
 Zhu School of Computer Science Carnegie Mellon University") Semi-Supervised Learning with Graphs Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning classification classifiers need labeled data to train labeled data
Semi-Supervised Learning with Graphs Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning classification classifiers need labeled data to train labeled data
Semi Supervised Distance Metric Learning
 Semi Supervised Distance Metric Learning wliu@ee.columbia.edu Outline Background Related Work Learning Framework Collaborative Image Retrieval Future Research Background Euclidean distance d( x, x ) =
Semi Supervised Distance Metric Learning wliu@ee.columbia.edu Outline Background Related Work Learning Framework Collaborative Image Retrieval Future Research Background Euclidean distance d( x, x ) =
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Classification. The goal: map from input X to a label Y. Y has a discrete set of possible values. We focused on binary Y (values 0 or 1).
.") Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Semi-Supervised Learning in Reproducing Kernel Hilbert Spaces Using Local Invariances
 Semi-Supervised Learning in Reproducing Kernel Hilbert Spaces Using Local Invariances Wee Sun Lee,2, Xinhua Zhang,2, and Yee Whye Teh Department of Computer Science, National University of Singapore. 2
Semi-Supervised Learning in Reproducing Kernel Hilbert Spaces Using Local Invariances Wee Sun Lee,2, Xinhua Zhang,2, and Yee Whye Teh Department of Computer Science, National University of Singapore. 2
Recap from previous lecture
 Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA
 Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Graph-Based Semi-Supervised Learning
 Graph-Based Semi-Supervised Learning Olivier Delalleau, Yoshua Bengio and Nicolas Le Roux Université de Montréal CIAR Workshop - April 26th, 2005 Graph-Based Semi-Supervised Learning Yoshua Bengio, Olivier
Graph-Based Semi-Supervised Learning Olivier Delalleau, Yoshua Bengio and Nicolas Le Roux Université de Montréal CIAR Workshop - April 26th, 2005 Graph-Based Semi-Supervised Learning Yoshua Bengio, Olivier
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
Spectral Techniques for Clustering
 Nicola Rebagliati 1/54 Spectral Techniques for Clustering Nicola Rebagliati 29 April, 2010 Nicola Rebagliati 2/54 Thesis Outline 1 2 Data Representation for Clustering Setting Data Representation and Methods
Nicola Rebagliati 1/54 Spectral Techniques for Clustering Nicola Rebagliati 29 April, 2010 Nicola Rebagliati 2/54 Thesis Outline 1 2 Data Representation for Clustering Setting Data Representation and Methods
Introduction to Machine Learning (67577) Lecture 3
 Lecture 3") Introduction to Machine Learning (67577) Lecture 3 Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem General Learning Model and Bias-Complexity tradeoff Shai Shalev-Shwartz
Introduction to Machine Learning (67577) Lecture 3 Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem General Learning Model and Bias-Complexity tradeoff Shai Shalev-Shwartz
Global vs. Multiscale Approaches
 Harmonic Analysis on Graphs Global vs. Multiscale Approaches Weizmann Institute of Science, Rehovot, Israel July 2011 Joint work with Matan Gavish (WIS/Stanford), Ronald Coifman (Yale), ICML 10' Challenge:
Harmonic Analysis on Graphs Global vs. Multiscale Approaches Weizmann Institute of Science, Rehovot, Israel July 2011 Joint work with Matan Gavish (WIS/Stanford), Ronald Coifman (Yale), ICML 10' Challenge:
Vector spaces. DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis.
 Vector spaces DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Vector space Consists of: A set V A scalar
Vector spaces DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Vector space Consists of: A set V A scalar
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Large Scale Semi-supervised Linear SVMs. University of Chicago
 Large Scale Semi-supervised Linear SVMs Vikas Sindhwani and Sathiya Keerthi University of Chicago SIGIR 2006 Semi-supervised Learning (SSL) Motivation Setting Categorize x-billion documents into commercial/non-commercial.
Large Scale Semi-supervised Linear SVMs Vikas Sindhwani and Sathiya Keerthi University of Chicago SIGIR 2006 Semi-supervised Learning (SSL) Motivation Setting Categorize x-billion documents into commercial/non-commercial.
Clustering K-means. Machine Learning CSE546. Sham Kakade University of Washington. November 15, Review: PCA Start: unsupervised learning
 Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Graphs in Machine Learning
 Graphs in Machine Learning Michal Valko INRIA Lille - Nord Europe, France Partially based on material by: Mikhail Belkin, Jerry Zhu, Olivier Chapelle, Branislav Kveton February 10, 2015 MVA 2014/2015 Previous
Graphs in Machine Learning Michal Valko INRIA Lille - Nord Europe, France Partially based on material by: Mikhail Belkin, Jerry Zhu, Olivier Chapelle, Branislav Kveton February 10, 2015 MVA 2014/2015 Previous
Logic and machine learning review. CS 540 Yingyu Liang
 Logic and machine learning review CS 540 Yingyu Liang Propositional logic Logic If the rules of the world are presented formally, then a decision maker can use logical reasoning to make rational decisions.
Logic and machine learning review CS 540 Yingyu Liang Propositional logic Logic If the rules of the world are presented formally, then a decision maker can use logical reasoning to make rational decisions.
Nonlinear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Lecture 3: Pattern Classification
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering and Gaussian Mixture Models
 Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
c 4, < y 2, 1 0, otherwise,
 Fundamentals of Big Data Analytics Univ.-Prof. Dr. rer. nat. Rudolf Mathar Problem. Probability theory: The outcome of an experiment is described by three events A, B and C. The probabilities Pr(A) =,
Fundamentals of Big Data Analytics Univ.-Prof. Dr. rer. nat. Rudolf Mathar Problem. Probability theory: The outcome of an experiment is described by three events A, B and C. The probabilities Pr(A) =,
Regularizing objective functionals in semi-supervised learning
 Regularizing objective functionals in semi-supervised learning Dejan Slepčev Carnegie Mellon University February 9, 2018 1 / 47 References S,Thorpe, Analysis of p-laplacian regularization in semi-supervised
Regularizing objective functionals in semi-supervised learning Dejan Slepčev Carnegie Mellon University February 9, 2018 1 / 47 References S,Thorpe, Analysis of p-laplacian regularization in semi-supervised
Accelerated Block-Coordinate Relaxation for Regularized Optimization
 Accelerated Block-Coordinate Relaxation for Regularized Optimization Stephen J. Wright Computer Sciences University of Wisconsin, Madison October 09, 2012 Problem descriptions Consider where f is smooth
Accelerated Block-Coordinate Relaxation for Regularized Optimization Stephen J. Wright Computer Sciences University of Wisconsin, Madison October 09, 2012 Problem descriptions Consider where f is smooth
Clustering. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Clustering CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Supervised vs Unsupervised Learning Supervised learning Given x ", y " "%& ', learn a function f: X Y Categorical output classification
Clustering CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Supervised vs Unsupervised Learning Supervised learning Given x ", y " "%& ', learn a function f: X Y Categorical output classification
Iterative Laplacian Score for Feature Selection
 Iterative Laplacian Score for Feature Selection Linling Zhu, Linsong Miao, and Daoqiang Zhang College of Computer Science and echnology, Nanjing University of Aeronautics and Astronautics, Nanjing 2006,
Iterative Laplacian Score for Feature Selection Linling Zhu, Linsong Miao, and Daoqiang Zhang College of Computer Science and echnology, Nanjing University of Aeronautics and Astronautics, Nanjing 2006,
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc.
 Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
L26: Advanced dimensionality reduction
 L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
Distribution-specific analysis of nearest neighbor search and classification
 Distribution-specific analysis of nearest neighbor search and classification Sanjoy Dasgupta University of California, San Diego Nearest neighbor The primeval approach to information retrieval and classification.
Distribution-specific analysis of nearest neighbor search and classification Sanjoy Dasgupta University of California, San Diego Nearest neighbor The primeval approach to information retrieval and classification.
Final Exam, Machine Learning, Spring 2009
 Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Multiscale Wavelets on Trees, Graphs and High Dimensional Data
 Multiscale Wavelets on Trees, Graphs and High Dimensional Data ICML 2010, Haifa Matan Gavish (Weizmann/Stanford) Boaz Nadler (Weizmann) Ronald Coifman (Yale) Boaz Nadler Ronald Coifman Motto... the relationships
Multiscale Wavelets on Trees, Graphs and High Dimensional Data ICML 2010, Haifa Matan Gavish (Weizmann/Stanford) Boaz Nadler (Weizmann) Ronald Coifman (Yale) Boaz Nadler Ronald Coifman Motto... the relationships
Semi-Supervised Learning with the Graph Laplacian: The Limit of Infinite Unlabelled Data
 Semi-Supervised Learning with the Graph Laplacian: The Limit of Infinite Unlabelled Data Boaz Nadler Dept. of Computer Science and Applied Mathematics Weizmann Institute of Science Rehovot, Israel 76 boaz.nadler@weizmann.ac.il
Semi-Supervised Learning with the Graph Laplacian: The Limit of Infinite Unlabelled Data Boaz Nadler Dept. of Computer Science and Applied Mathematics Weizmann Institute of Science Rehovot, Israel 76 boaz.nadler@weizmann.ac.il
Decision trees COMS 4771
 Decision trees COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random pairs (i.e., labeled examples).
Decision trees COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random pairs (i.e., labeled examples).
Persistent homology and nonparametric regression
 Cleveland State University March 10, 2009, BIRS: Data Analysis using Computational Topology and Geometric Statistics joint work with Gunnar Carlsson (Stanford), Moo Chung (Wisconsin Madison), Peter Kim
Cleveland State University March 10, 2009, BIRS: Data Analysis using Computational Topology and Geometric Statistics joint work with Gunnar Carlsson (Stanford), Moo Chung (Wisconsin Madison), Peter Kim
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Metric-based classifiers. Nuno Vasconcelos UCSD
 Metric-based classifiers Nuno Vasconcelos UCSD Statistical learning goal: given a function f. y f and a collection of eample data-points, learn what the function f. is. this is called training. two major
Metric-based classifiers Nuno Vasconcelos UCSD Statistical learning goal: given a function f. y f and a collection of eample data-points, learn what the function f. is. this is called training. two major
1 Matrix notation and preliminaries from spectral graph theory
 Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Statistical Machine Learning Hilary Term 2018
 Statistical Machine Learning Hilary Term 2018 Pier Francesco Palamara Department of Statistics University of Oxford Slide credits and other course material can be found at: http://www.stats.ox.ac.uk/~palamara/sml18.html
Statistical Machine Learning Hilary Term 2018 Pier Francesco Palamara Department of Statistics University of Oxford Slide credits and other course material can be found at: http://www.stats.ox.ac.uk/~palamara/sml18.html
Convex Optimization in Classification Problems
 New Trends in Optimization and Computational Algorithms December 9 13, 2001 Convex Optimization in Classification Problems Laurent El Ghaoui Department of EECS, UC Berkeley elghaoui@eecs.berkeley.edu 1
New Trends in Optimization and Computational Algorithms December 9 13, 2001 Convex Optimization in Classification Problems Laurent El Ghaoui Department of EECS, UC Berkeley elghaoui@eecs.berkeley.edu 1
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Classification of handwritten digits using supervised locally linear embedding algorithm and support vector machine
 Classification of handwritten digits using supervised locally linear embedding algorithm and support vector machine Olga Kouropteva, Oleg Okun, Matti Pietikäinen Machine Vision Group, Infotech Oulu and
Classification of handwritten digits using supervised locally linear embedding algorithm and support vector machine Olga Kouropteva, Oleg Okun, Matti Pietikäinen Machine Vision Group, Infotech Oulu and
Lecture Notes 1: Vector spaces
 Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Nonnegative Matrix Factorization Clustering on Multiple Manifolds
 Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Nonnegative Matrix Factorization Clustering on Multiple Manifolds Bin Shen, Luo Si Department of Computer Science,
Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Nonnegative Matrix Factorization Clustering on Multiple Manifolds Bin Shen, Luo Si Department of Computer Science,
Machine Learning (CS 567) Lecture 5
 Lecture 5") Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Clustering by Mixture Models. General background on clustering Example method: k-means Mixture model based clustering Model estimation
 Clustering by Mixture Models General bacground on clustering Example method: -means Mixture model based clustering Model estimation 1 Clustering A basic tool in data mining/pattern recognition: Divide
Clustering by Mixture Models General bacground on clustering Example method: -means Mixture model based clustering Model estimation 1 Clustering A basic tool in data mining/pattern recognition: Divide
How can a Machine Learn: Passive, Active, and Teaching
 How can a Machine Learn: Passive, Active, and Teaching Xiaojin Zhu jerryzhu@cs.wisc.edu Department of Computer Sciences University of Wisconsin-Madison NLP&CC 2013 Zhu (Univ. Wisconsin-Madison) How can
How can a Machine Learn: Passive, Active, and Teaching Xiaojin Zhu jerryzhu@cs.wisc.edu Department of Computer Sciences University of Wisconsin-Madison NLP&CC 2013 Zhu (Univ. Wisconsin-Madison) How can
CSE446: Clustering and EM Spring 2017
 CSE446: Clustering and EM Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, and Luke Zettlemoyer Clustering systems: Unsupervised learning Clustering Detect patterns in unlabeled
CSE446: Clustering and EM Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, and Luke Zettlemoyer Clustering systems: Unsupervised learning Clustering Detect patterns in unlabeled
Nonparametric Bayesian Methods
 Nonparametric Bayesian Methods Debdeep Pati Florida State University October 2, 2014 Large spatial datasets (Problem of big n) Large observational and computer-generated datasets: Often have spatial and
Nonparametric Bayesian Methods Debdeep Pati Florida State University October 2, 2014 Large spatial datasets (Problem of big n) Large observational and computer-generated datasets: Often have spatial and
Statistical Learning. Dong Liu. Dept. EEIS, USTC
 Statistical Learning Dong Liu Dept. EEIS, USTC Chapter 6. Unsupervised and Semi-Supervised Learning 1. Unsupervised learning 2. k-means 3. Gaussian mixture model 4. Other approaches to clustering 5. Principle
Statistical Learning Dong Liu Dept. EEIS, USTC Chapter 6. Unsupervised and Semi-Supervised Learning 1. Unsupervised learning 2. k-means 3. Gaussian mixture model 4. Other approaches to clustering 5. Principle
Diffuse interface methods on graphs: Data clustering and Gamma-limits
 Diffuse interface methods on graphs: Data clustering and Gamma-limits Yves van Gennip joint work with Andrea Bertozzi, Jeff Brantingham, Blake Hunter Department of Mathematics, UCLA Research made possible
Diffuse interface methods on graphs: Data clustering and Gamma-limits Yves van Gennip joint work with Andrea Bertozzi, Jeff Brantingham, Blake Hunter Department of Mathematics, UCLA Research made possible
Scalable robust hypothesis tests using graphical models
 Scalable robust hypothesis tests using graphical models Umamahesh Srinivas ipal Group Meeting October 22, 2010 Binary hypothesis testing problem Random vector x = (x 1,...,x n ) R n generated from either
Scalable robust hypothesis tests using graphical models Umamahesh Srinivas ipal Group Meeting October 22, 2010 Binary hypothesis testing problem Random vector x = (x 1,...,x n ) R n generated from either
Clustering using Mixture Models
 Clustering using Mixture Models The full posterior of the Gaussian Mixture Model is p(x, Z, µ,, ) =p(x Z, µ, )p(z )p( )p(µ, ) data likelihood (Gaussian) correspondence prob. (Multinomial) mixture prior
Clustering using Mixture Models The full posterior of the Gaussian Mixture Model is p(x, Z, µ,, ) =p(x Z, µ, )p(z )p( )p(µ, ) data likelihood (Gaussian) correspondence prob. (Multinomial) mixture prior
Final Overview. Introduction to ML. Marek Petrik 4/25/2017
 Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Finding normalized and modularity cuts by spectral clustering. Ljubjana 2010, October
 Finding normalized and modularity cuts by spectral clustering Marianna Bolla Institute of Mathematics Budapest University of Technology and Economics marib@math.bme.hu Ljubjana 2010, October Outline Find
Finding normalized and modularity cuts by spectral clustering Marianna Bolla Institute of Mathematics Budapest University of Technology and Economics marib@math.bme.hu Ljubjana 2010, October Outline Find
12. Structural Risk Minimization. ECE 830 & CS 761, Spring 2016
 12. Structural Risk Minimization ECE 830 & CS 761, Spring 2016 1 / 23 General setup for statistical learning theory We observe training examples {x i, y i } n i=1 x i = features X y i = labels / responses
12. Structural Risk Minimization ECE 830 & CS 761, Spring 2016 1 / 23 General setup for statistical learning theory We observe training examples {x i, y i } n i=1 x i = features X y i = labels / responses