Introduction to Machine Learning
|
|
|
- Miranda Linette Skinner
- 5 years ago
- Views:
Transcription
1 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s textbook, Machine Learning: A Probabilistic Perspective
2 Gaussian Mixture Models Mixture of 3 Gaussian Distributions in 2D Contour Plot of Joint Density, Marginalizing Cluster Assignments
3 Gaussian Mixture Models! Observed feature vectors: x i R d, i =1, 2,...,N! Hidden cluster labels: z i {1, 2,...,K}, i =1, 2,...,N! Hidden mixture means: µ k R d, k =1, 2,...,K! Hidden mixture covariances:! Hidden mixture probabilities:! Gaussian mixture marginal likelihood: p(x i π, µ, Σ) = Σ k R d d, k =1, 2,...,K π k, K π k =1 K z i =1 k=1 π zi N (x i µ zi, Σ zi ) p(x i z i, π, µ, Σ) =N (x i µ zi, Σ zi )
4 Clustering with Gaussian Mixtures 1 (a) 1 (b) Complete Data Labeled by True Cluster Assignments Incomplete Data: Points to be Clustered With complete data, learning is Gaussian discriminant analysis. C. Bishop, Pattern Recognition & Machine Learning
5 π Expectation Maximization (EM) y i π y t π z i θ x i N Supervised Training θ x t Supervised Testing θ x i N Unsupervised Learning π, θ parameters (define cluster location and shape) z 1,...,z N hidden data (group observations into clusters)! Initialization: Randomly select starting parameters! E-Step: Given parameters, find posterior of hidden data! Equivalent to test inference of full posterior distribution! M-Step: Given posterior distributions, find likely parameters! Distinct from supervised ML/MAP, but often still tractable! Iteration: Alternate E-step & M-step until convergence
6 EM Algorithm 2 0!2!2 0 (b) 2 C. Bishop, Pattern Recognition & Machine Learning
7 EM Algorithm 2 L =1 0!2!2 0 (c) 2 C. Bishop, Pattern Recognition & Machine Learning
8 EM Algorithm 2 L =5 0!2!2 0 (e) 2 C. Bishop, Pattern Recognition & Machine Learning
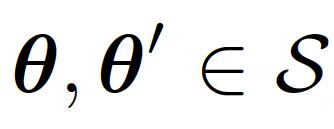
9 Convexity
10 Convexity & Jensen s Inequality f(e[x]) E[f(X)] f(x) chord a x! b
11 Concavity & Jensen s Inequality ln(e[x]) E[ln(X)]
12 EM as Lower Bound Maximization ( ) ln p(x θ) =ln p(x, z θ) ln p(x θ) z ( ) p(x, z θ) q(z) ln q(z) z ln p(x θ) z q(z) ln p(x, z θ) z q(z) ln q(z) L(q, θ)! Initialization: Randomly select starting parameters! E-Step: Given parameters, find posterior of hidden data q (t) = arg max q L(q, θ (t 1) )! M-Step: Given posterior distributions, find likely parameters θ (t) = arg max L(q (t), θ) θ! Iteration: Alternate E-step & M-step until convergence θ (0)
13 Lower Bounds on Marginal Likelihood KL(q p) L(q, θ) ln p(x θ) C. Bishop, Pattern Recognition & Machine Learning
14 EM: A Sequence of Lower Bounds ln p(x θ) L (q,θ) θ old θ new C. Bishop, Pattern Recognition & Machine Learning
15 Expectation Maximization Algorithm KL(q p) KL(q p) =0 L(q, θ old ) ln p(x θ old ) L(q, θ new ) ln p(x θ new ) E Step: Optimize distribution on hidden variables given parameters M Step: Optimize parameters given distribution on hidden variables C. Bishop, Pattern Recognition & Machine Learning
16 EM: Expectation Step ln p(x θ) z q(z) ln p(x, z θ) z q(z) ln q(z) L(q, θ) q (t) = arg max q L(q, θ (t 1) )! General solution, for any probabilistic model: q (t) (z) =p(z x, θ (t 1) ) posterior distribution given current parameters! Applying to probabilistic mixture models: p(z i π) = Cat(z i π) p(x i z i, θ) =p(x i θ ) zi π k p(x i θ k ) K l=1 π lp(x i θ l ) r ik = p(z i = k x i, π, θ) = π θ z i x i N
17 E-Step for Gaussian Mixtures 1 (c) 1 (b) Posterior Probabilities of Assignment to Each Cluster r ik = p(z i = k x i, π, θ) = Incomplete Data: Points to be Clustered π k p(x i θ k ) K l=1 π lp(x i θ l )
18 Reminder: Exponential Families φ(x) R d θ Θ Z(θ) > 0 h(x) > 0 fixed vector of sufficient statistics (features), specifying the family of distributions unknown vector of natural parameters, determine particular distribution in this family normalization constant or partition function, ensuring this is a valid probability distribution reference measure independent of parameters (for many models, we simply have ) h(x) =1! Examples: Multinomial, Dirichlet, Gaussian, Poisson,!! ML estimation via moment matching: E θ [φ(x)] = 1 N φ(x i ) N i=1

19 Reminder: Constrained Optimization! Solution: ˆθ = arg max θ K k=1 θ k =1 ˆθ k = a k K k=1 subject to a 0 a 0 = a k log θ k a k 0 θ k 0 K k=1! Proof for K=2: Change of variables to unconstrained problem! Proof for general K: Lagrange multipliers (see textbook) a k
20 EM: Maximization Step ln p(x θ) q(z) ln p(x, z θ) z z θ (t) = arg max L(q (t), θ) = arg max θ θ! Unlike E-step, no simplified general solution! Applying to mixtures of exponential families: p(z i π) = Cat(z i π) p(x i z i, θ) = exp(θ T z i φ(x i ) A(θ zi )) ˆπ k = N k N Eˆθk [φ(x)] = 1 N k N i=1 r ik φ(x i ) q(z) ln q(z) L(q, θ) q(z) ln p(x, z θ) z weighted moment matching π θ N k = N i=1 z i x i N r ik

21 Binary Features: Mixtures of Bernoullis 10 Clusters Identified via EM Algorithm from Binarized MNIST Digits
 1 1 0 0 1 1 2 2 3 3 4 4 5 5")

22 Density Shape Matters 2 21 errors using gauss (red=error) 2 4 errors using student (red=error) Bankrupt Solvent Mixture of Gaussians 6 Bankrupt Solvent Mixture of Student t Densities
23 Real Clusters may not be Round Ng, Jordan, & Weiss, NIPS02
24 Dimensionality Reduction Supervised Learning Unsupervised Learning Discrete classification or categorization clustering Continuous regression dimensionality reduction!goal: Infer label/response y given only features x!classical: Find latent variables y good for compression of x!probabilistic learning: Estimate parameters of joint distribution p(x,y) which maximize marginal probability p(x)
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Pattern Recognition and Machine Learning. Bishop Chapter 9: Mixture Models and EM
 Pattern Recognition and Machine Learning Chapter 9: Mixture Models and EM Thomas Mensink Jakob Verbeek October 11, 27 Le Menu 9.1 K-means clustering Getting the idea with a simple example 9.2 Mixtures
Pattern Recognition and Machine Learning Chapter 9: Mixture Models and EM Thomas Mensink Jakob Verbeek October 11, 27 Le Menu 9.1 K-means clustering Getting the idea with a simple example 9.2 Mixtures
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
The Expectation-Maximization Algorithm
 1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Cheng Soon Ong & Christian Walder. Canberra February June 2017
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2017 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 679 Part XIX
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2017 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 679 Part XIX
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Computer Vision Group Prof. Daniel Cremers. 6. Mixture Models and Expectation-Maximization
 Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
STATS 306B: Unsupervised Learning Spring Lecture 3 April 7th
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 3 April 7th Lecturer: Lester Mackey Scribe: Jordan Bryan, Dangna Li 3.1 Recap: Gaussian Mixture Modeling In the last lecture, we discussed the Gaussian
STATS 306B: Unsupervised Learning Spring 2014 Lecture 3 April 7th Lecturer: Lester Mackey Scribe: Jordan Bryan, Dangna Li 3.1 Recap: Gaussian Mixture Modeling In the last lecture, we discussed the Gaussian
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
Clustering and Gaussian Mixture Models
 Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
IEOR E4570: Machine Learning for OR&FE Spring 2015 c 2015 by Martin Haugh. The EM Algorithm
 IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Lecture 10. Announcement. Mixture Models II. Topics of This Lecture. This Lecture: Advanced Machine Learning. Recap: GMMs as Latent Variable Models
 Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Series 6, May 14th, 2018 (EM Algorithm and Semi-Supervised Learning)
") Exercises Introduction to Machine Learning SS 2018 Series 6, May 14th, 2018 (EM Algorithm and Semi-Supervised Learning) LAS Group, Institute for Machine Learning Dept of Computer Science, ETH Zürich Prof
Exercises Introduction to Machine Learning SS 2018 Series 6, May 14th, 2018 (EM Algorithm and Semi-Supervised Learning) LAS Group, Institute for Machine Learning Dept of Computer Science, ETH Zürich Prof
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 6 Jan-Willem van de Meent (credit: Yijun Zhao, Chris Bishop, Andrew Moore, Hastie et al.) Project Project Deadlines 3 Feb: Form teams of
Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 6 Jan-Willem van de Meent (credit: Yijun Zhao, Chris Bishop, Andrew Moore, Hastie et al.) Project Project Deadlines 3 Feb: Form teams of
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Clustering, K-Means, EM Tutorial
 Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
Clustering K-means. Machine Learning CSE546. Sham Kakade University of Washington. November 15, Review: PCA Start: unsupervised learning
 Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
K-Means and Gaussian Mixture Models
 K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
CS242: Probabilistic Graphical Models Lecture 4A: MAP Estimation & Graph Structure Learning
 CS242: Probabilistic Graphical Models Lecture 4A: MAP Estimation & Graph Structure Learning Professor Erik Sudderth Brown University Computer Science October 4, 2016 Some figures and materials courtesy
CS242: Probabilistic Graphical Models Lecture 4A: MAP Estimation & Graph Structure Learning Professor Erik Sudderth Brown University Computer Science October 4, 2016 Some figures and materials courtesy
Posterior Regularization
 Posterior Regularization 1 Introduction One of the key challenges in probabilistic structured learning, is the intractability of the posterior distribution, for fast inference. There are numerous methods
Posterior Regularization 1 Introduction One of the key challenges in probabilistic structured learning, is the intractability of the posterior distribution, for fast inference. There are numerous methods
Probabilistic Time Series Classification
 Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Another Walkthrough of Variational Bayes. Bevan Jones Machine Learning Reading Group Macquarie University
 Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Latent Variable Models and EM Algorithm
 SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
Lecture 6: April 19, 2002
 EE596 Pat. Recog. II: Introduction to Graphical Models Spring 2002 Lecturer: Jeff Bilmes Lecture 6: April 19, 2002 University of Washington Dept. of Electrical Engineering Scribe: Huaning Niu,Özgür Çetin
EE596 Pat. Recog. II: Introduction to Graphical Models Spring 2002 Lecturer: Jeff Bilmes Lecture 6: April 19, 2002 University of Washington Dept. of Electrical Engineering Scribe: Huaning Niu,Özgür Çetin
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
Technical Details about the Expectation Maximization (EM) Algorithm
 Algorithm") Technical Details about the Expectation Maximization (EM Algorithm Dawen Liang Columbia University dliang@ee.columbia.edu February 25, 2015 1 Introduction Maximum Lielihood Estimation (MLE is widely used
Technical Details about the Expectation Maximization (EM Algorithm Dawen Liang Columbia University dliang@ee.columbia.edu February 25, 2015 1 Introduction Maximum Lielihood Estimation (MLE is widely used
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Expectation Maximization Mark Schmidt University of British Columbia Winter 2018 Last Time: Learning with MAR Values We discussed learning with missing at random values in data:
CPSC 540: Machine Learning Expectation Maximization Mark Schmidt University of British Columbia Winter 2018 Last Time: Learning with MAR Values We discussed learning with missing at random values in data:
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
Lecture 14. Clustering, K-means, and EM
 Lecture 14. Clustering, K-means, and EM Prof. Alan Yuille Spring 2014 Outline 1. Clustering 2. K-means 3. EM 1 Clustering Task: Given a set of unlabeled data D = {x 1,..., x n }, we do the following: 1.
Lecture 14. Clustering, K-means, and EM Prof. Alan Yuille Spring 2014 Outline 1. Clustering 2. K-means 3. EM 1 Clustering Task: Given a set of unlabeled data D = {x 1,..., x n }, we do the following: 1.
Expectation maximization tutorial
 Expectation maximization tutorial Octavian Ganea November 18, 2016 1/1 Today Expectation - maximization algorithm Topic modelling 2/1 ML & MAP Observed data: X = {x 1, x 2... x N } 3/1 ML & MAP Observed
Expectation maximization tutorial Octavian Ganea November 18, 2016 1/1 Today Expectation - maximization algorithm Topic modelling 2/1 ML & MAP Observed data: X = {x 1, x 2... x N } 3/1 ML & MAP Observed
Note 1: Varitional Methods for Latent Dirichlet Allocation
 Technical Note Series Spring 2013 Note 1: Varitional Methods for Latent Dirichlet Allocation Version 1.0 Wayne Xin Zhao batmanfly@gmail.com Disclaimer: The focus of this note was to reorganie the content
Technical Note Series Spring 2013 Note 1: Varitional Methods for Latent Dirichlet Allocation Version 1.0 Wayne Xin Zhao batmanfly@gmail.com Disclaimer: The focus of this note was to reorganie the content
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Variational Inference (11/04/13)
") STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
Expectation Maximization
 Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
An Introduction to Statistical and Probabilistic Linear Models
 An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
Hidden Markov Models
 CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
CSC411 Fall 2018 Homework 5
 Homework 5 Deadline: Wednesday, Nov. 4, at :59pm. Submission: You need to submit two files:. Your solutions to Questions and 2 as a PDF file, hw5_writeup.pdf, through MarkUs. (If you submit answers to
Homework 5 Deadline: Wednesday, Nov. 4, at :59pm. Submission: You need to submit two files:. Your solutions to Questions and 2 as a PDF file, hw5_writeup.pdf, through MarkUs. (If you submit answers to
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Latent Variable View of EM. Sargur Srihari
 Latent Variable View of EM Sargur srihari@cedar.buffalo.edu 1 Examples of latent variables 1. Mixture Model Joint distribution is p(x,z) We don t have values for z 2. Hidden Markov Model A single time
Latent Variable View of EM Sargur srihari@cedar.buffalo.edu 1 Examples of latent variables 1. Mixture Model Joint distribution is p(x,z) We don t have values for z 2. Hidden Markov Model A single time
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
CS839: Probabilistic Graphical Models. Lecture 7: Learning Fully Observed BNs. Theo Rekatsinas
 CS839: Probabilistic Graphical Models Lecture 7: Learning Fully Observed BNs Theo Rekatsinas 1 Exponential family: a basic building block For a numeric random variable X p(x ) =h(x)exp T T (x) A( ) = 1
CS839: Probabilistic Graphical Models Lecture 7: Learning Fully Observed BNs Theo Rekatsinas 1 Exponential family: a basic building block For a numeric random variable X p(x ) =h(x)exp T T (x) A( ) = 1
Lecture 8: Graphical models for Text
 Lecture 8: Graphical models for Text 4F13: Machine Learning Joaquin Quiñonero-Candela and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/
Lecture 8: Graphical models for Text 4F13: Machine Learning Joaquin Quiñonero-Candela and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/
Latent Variable Models and EM algorithm
 Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Gaussian Mixture Models, Expectation Maximization
 Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Expectation maximization
 Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
GWAS V: Gaussian processes
 GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Lecture 4: Probabilistic Learning
 DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
STATS 306B: Unsupervised Learning Spring Lecture 2 April 2
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 2 April 2 Lecturer: Lester Mackey Scribe: Junyang Qian, Minzhe Wang 2.1 Recap In the last lecture, we formulated our working definition of unsupervised
STATS 306B: Unsupervised Learning Spring 2014 Lecture 2 April 2 Lecturer: Lester Mackey Scribe: Junyang Qian, Minzhe Wang 2.1 Recap In the last lecture, we formulated our working definition of unsupervised
PROBABILITY DISTRIBUTIONS. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
Mathematical Formulation of Our Example
 Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
1 EM algorithm: updating the mixing proportions {π k } ik are the posterior probabilities at the qth iteration of EM.
 Université du Sud Toulon - Var Master Informatique Probabilistic Learning and Data Analysis TD: Model-based clustering by Faicel CHAMROUKHI Solution The aim of this practical wor is to show how the Classification
Université du Sud Toulon - Var Master Informatique Probabilistic Learning and Data Analysis TD: Model-based clustering by Faicel CHAMROUKHI Solution The aim of this practical wor is to show how the Classification
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Expectation Maximization Algorithm
 Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 19 Nov. 5, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 19 Nov. 5, 2018 1 Reminders Homework
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017
 COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
Lecture 2: GMM and EM
 2: GMM and EM-1 Machine Learning Lecture 2: GMM and EM Lecturer: Haim Permuter Scribe: Ron Shoham I. INTRODUCTION This lecture comprises introduction to the Gaussian Mixture Model (GMM) and the Expectation-Maximization
2: GMM and EM-1 Machine Learning Lecture 2: GMM and EM Lecturer: Haim Permuter Scribe: Ron Shoham I. INTRODUCTION This lecture comprises introduction to the Gaussian Mixture Model (GMM) and the Expectation-Maximization
Gaussian Mixture Models
 Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Probabilistic Graphical Models for Image Analysis - Lecture 4
 Probabilistic Graphical Models for Image Analysis - Lecture 4 Stefan Bauer 12 October 2018 Max Planck ETH Center for Learning Systems Overview 1. Repetition 2. α-divergence 3. Variational Inference 4.
Probabilistic Graphical Models for Image Analysis - Lecture 4 Stefan Bauer 12 October 2018 Max Planck ETH Center for Learning Systems Overview 1. Repetition 2. α-divergence 3. Variational Inference 4.
Naïve Bayes Introduction to Machine Learning. Matt Gormley Lecture 18 Oct. 31, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning