Introduction to Econometrics. Review of Probability & Statistics
|
|
|
- Laurence Williamson
- 5 years ago
- Views:
Transcription
1 1 Introduction to Econometrics Review of Probability & Statistics Peerapat Wongchaiwat, Ph.D.
2 Introduction 2 What is Econometrics? Econometrics consists of the application of mathematical statistics to economic data to lend empirical support to the models constructed by mathematical economics and to obtain numerical results. Econometrics may be defined as the quantitative analysis of actual economic phenomena based on the concurrent development of theory and observation, related by appropriate methods of inference.
3 What is Econometrics? 3 Economics Econometrics Statistics Mathematics
4 Why do we study econometrics? 4 Rare in economics (and many other areas without labs!) to have experimental data Need to use nonexperimental, or observational data to make inferences Important to be able to apply economic theory to real world data
5 Why it is so important? 5 An empirical analysis uses data to test a theory or to estimate a relationship A formal economic model can be tested Theory may be ambiguous as to the effect of some policy change can use econometrics to evaluate the program
6 The Question of Causality 6 Simply establishing a relationship between variables is rarely sufficient Want to get the effect to be considered causal If we ve truly controlled for enough other variables, then the estimated effect can often be considered to be causal
7 Purpose of Econometrics 7 Structural Analysis Policy Evaluation Economical Prediction Empirical Analysis
8 Methodology of Econometrics 8 1. Statement of theory or hypothesis. 2. Specification of the mathematical model of the theory. 3. Specification of the statistical, or econometric model. 4. Obtaining the data. 5. Estimation of the parameters of the econometric model. 6. Hypothesis testing. 7. Forecasting or prediction.
9 9 Example:Kynesian theory of consumption 1. Statement of theory or hypothesis. Keynes stated: The fundamental psychological law is that men/women are disposed, as a rule and on average, to increase their consumption as their income increases, but not as much as the increase in their income. In short, Keynes postulated that the marginal propensity to consume (MPC), the rate of change of consumption for a unit change in income, is greater than zero but less than 1
10 2.Specification of the mathematical model of the theory A mathematical economist might suggest the following form of the Keynesian consumption function: Consumption expenditure 0 1X Income
11 3. Specification of the statistical, or econometric model. To allow for the inexact relationships between economic variables, the econometrician would modify the deterministic consumption function as follows: 1 0 X u U, known as disturbance, or error term This is called an econometric model. 11
12 4. Obtaining the data. 12 year X Source: Data on (Personal Consumption Expenditure) and X (Gross Domestic Product), ) all in 1992 billions of dollars
13 13 5. Estimation of the parameters of the econometric model. reg y x Source SS df MS Number of obs = F( 1, 13) = Model Prob > F = Residual R-squared = Adj R-squared = Total Root MSE = y Coef. Std. Err. t P> t [95% Conf. Interval] x _cons
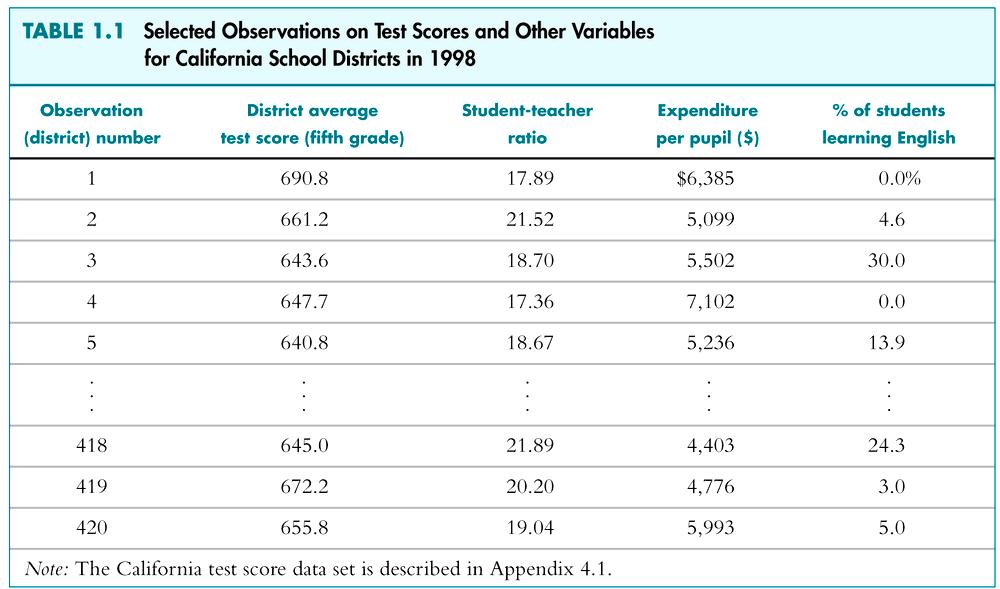
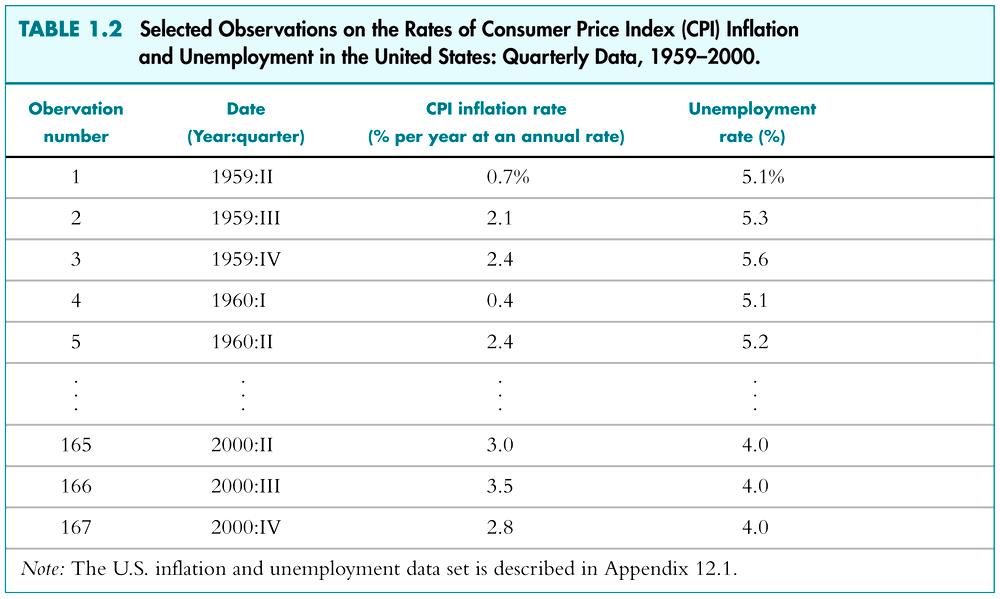
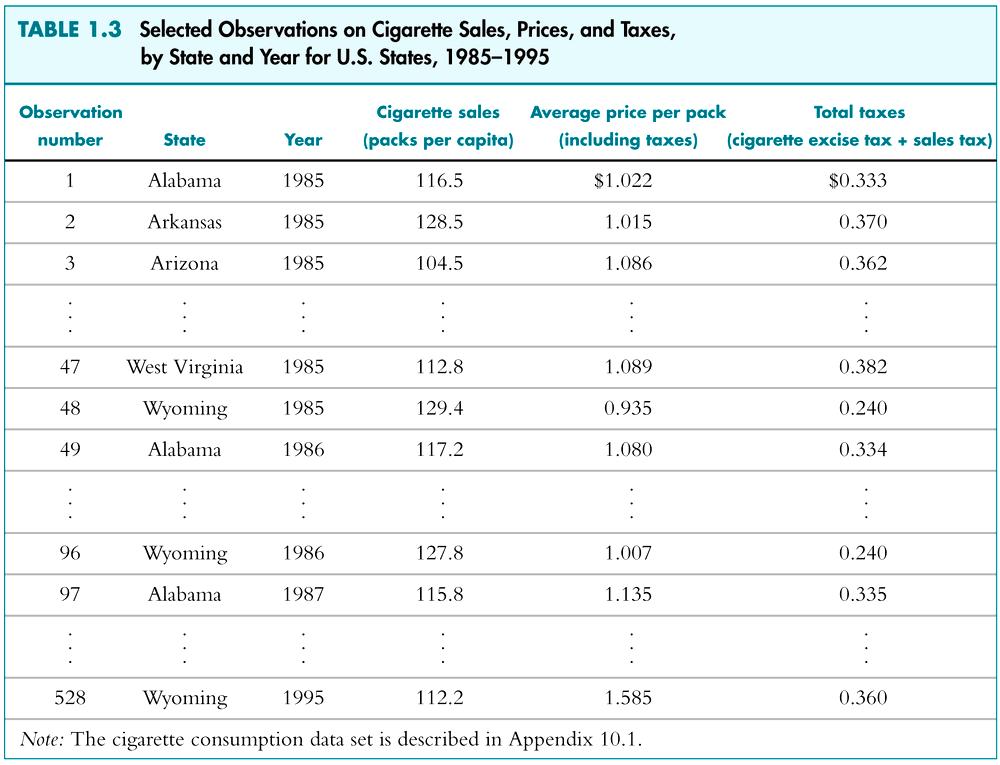
14 6. Hypothesis testing. 14 As noted earlier, Keynes expected the MPC to be positive but less than 1. In our example we found it is about Then, is 0.70 statistically less than 1? If it is, it may support Keynes s theory. Such confirmation or refutation of econometric theories on the basis of sample evidence is based on a branch of statistical theory know as statistical inference (hypothesis testing)
15 7.Forecasting or prediction. 15 To illustrate, suppose we want to predict the mean consumption expenditure for The GDP value for 1997 was billion dollars. Putting this value on the right-hand of the model, we obtain billion dollars. But the actual value of the consumption expenditure reported in 1997 was billion dollars. The estimated model thus overpredicted. The forecast error is about billion dollars.

16 16 Types of Data Sets
17 17
18 18
19 19
20 Review of Probability and Statistics 20 Empirical problem: Class size and educational output Policy question: What is the effect on test scores (or some other outcome measure) of reducing class size by one student per class? By 8 students/class? We must use data to find out (is there any way to answer this without data?)
21 The California Test Score Data Set 21 All K-6 and K-8 California school districts (n = 420) Variables: 5 th grade test scores (Stanford-9 achievement test, combined math and reading), district average Student-teacher ratio (STR) = no. of students in the district divided by no. full-time equivalent teachers

22 Initial look at the data: 22 This table doesn t tell us anything about the relationship between test scores and the STR.
23 23 Question: Do districts with smaller classes have higher test scores? Scatterplot of test score v. student-teacher ratio What does this figure show?
24 24 We need to get some numerical evidence on whether districts with low STRs have higher test scores but how? 1. Compare average test scores in districts with low STRs to those with high STRs ( estimation ) 2. Test the null hypothesis that the mean test scores in the two types of districts are the same, against the alternative hypothesis that they differ ( hypothesis testing ) 3. Estimate an interval for the difference in the mean test scores, high v. low STR districts ( confidence interval )
25 Initial data analysis: Compare districts with small (STR < 20) and large (STR 20) class sizes: 25 Class Size Average score ( ) Standard deviation (sb B ) n Small Large Estimation of = difference between group means 2. Test the hypothesis that = 0 3. Construct a confidence interval for
26 1. Estimation 26 small - = large small 1 n i n small i= 1 å = = 7.4 large 1 n i å n large i= 1 Is this a large difference in a real-world sense? Standard deviation across districts = 19.1 Difference between 60 th and 75 th percentiles of test score distribution is = 8.2 This is a big enough difference to be important for school reform discussions, for parents, or for a school committee?
27 2. Hypothesis testing 27 Difference-in-means test: compute the t-statistic, t s l s l 2 2 ss sl SE( s l) n s n l where SE( s l ) is the standard error of s l, the subscripts s and l refer to small and large STR districts, and n 1 s s ( ) (etc.) 2 2 s i s ns 1 i1
28 28 Compute the difference-of-means t-statistic: Size sb B n small large t s l ss sl n s n l = 4.05 t > 1.96, so reject (at the 5% significance level) the null hypothesis that the two means are the same.
29 3. Confidence interval 29 A 95% confidence interval for the difference between the means is, ( s l ) 1.96 SE( s l ) Two equivalent statements: = = (3.8, 11.0) 1. The 95% confidence interval for doesn t include 0; 2. The hypothesis that = 0 is rejected at the 5% level.
30 What comes next 30 The mechanics of estimation, hypothesis testing, and confidence intervals should be familiar These concepts extend directly to regression and its variants Before turning to regression, however, we will review some of the underlying theory of estimation, hypothesis testing, and confidence intervals: Why do these procedures work, and why use these rather than others? So we will review the intellectual foundations of statistics and econometrics
31 Review of Statistical Theory The probability framework for statistical inference 2. Estimation 3. Testing 4. Confidence Intervals The probability framework for statistical inference (a) Population, random variable, and distribution (b) Moments of a distribution (mean, variance, standard deviation, covariance, correlation) (c) Conditional distributions and conditional means (d) Distribution of a sample of data drawn randomly from a population: 1,, n
32 (a) Population, random variable, and 32 distribution Population The group or collection of all possible entities of interest (school districts) We will think of populations as infinitely large (N is an approximation to very big ) Random variable Numerical summary of a random outcome (district average test score, district STR)
33 Population distribution of 33 The probabilities of different values of that occur in the population, for ex. Pr[ = 650] (when is discrete) or: The probabilities of sets of these values, for ex. Pr[640 < < 660] (when is continuous).
34 (b) Moments of a population distribution: mean, variance, standard deviation, covariance, correlation 34 mean = expected value (expectation) of = E() = m = long-run average value of over repeated realizations of variance = E( m ) 2 = 2 s = measure of the squared spread of the distribution standard deviation = variance = s
35 Moments, ctd. 35 skewness = 3 E 3 = measure of asymmetry of a distribution skewness = 0: distribution is symmetric skewness > (<) 0: distribution has long right (left) tail kurtosis = 4 E 4 = measure of mass in tails = measure of probability of large values kurtosis = 3: normal distribution skewness > 3: heavy tails ( leptokurtotic )
36 36
37 37 Random variables: joint distributions and covariance Random variables X and Z have a joint distribution The covariance between X and Z is cov(x,z) = E[(X m X )(Z m Z )] = s XZ The covariance is a measure of the linear association between X and Z; its units are units of X units of Z cov(x,z) > 0 means a positive relation between X and Z If X and Z are independently distributed, then cov(x,z) = 0 (but not vice versa!!) The covariance of a r.v. with itself is its variance: cov(x,x) = E[(X m X )(X m X )] = E[(X m X ) 2 ] = s 2 X
38 38 The covariance between Test Score and STR is negative: so is the correlation
39 The correlation coefficient is defined in terms of the covariance: 39 corr(x,z) = cov( X, Z) var( X) var( Z) s s s XZ = = r XZ X Z 1 < corr(x,z) < 1 corr(x,z) = 1 mean perfect positive linear association corr(x,z) = 1 means perfect negative linear association corr(x,z) = 0 means no linear association
40 40 The correlation coefficient measures linear association
41 41 (c) Conditional distributions and conditional means Conditional distributions The distribution of, given value(s) of some other random variable, X Ex: the distribution of test scores, given that STR < 20 Conditional expectations and conditional moments conditional mean = mean of conditional distribution = E( X = x) (important concept and notation) conditional variance = variance of conditional distribution Example: E(Test scores STR < 20) = the mean of test scores among districts with small class sizes The difference in means is the difference between the means of two conditional distributions:
42 Conditional mean, ctd. 42 = E(Test scores STR < 20) E(Test scores STR 20) Other examples of conditional means: Wages of all female workers ( = wages, X = gender) Mortality rate of those given an experimental treatment ( = live/die; X = treated/not treated) If E(X Z) = const, then corr(x,z) = 0 (not necessarily vice versa however) The conditional mean is a (possibly new) term for the familiar idea of the group mean
43 (d) Distribution of a sample of data drawn randomly from a population: 1,, n 43 We will assume simple random sampling Choose and individual (district, entity) at random from the population Randomness and data Prior to sample selection, the value of is random because the individual selected is random Once the individual is selected and the value of is observed, then is just a number not random The data set is ( 1, 2,, n ), where i = value of for the i th individual (district, entity) sampled
44 44 Distribution of 1,, n under simple random sampling Because individuals #1 and #2 are selected at random, the value of 1 has no information content for 2. Thus: 1 and 2 are independently distributed 1 and 2 come from the same distribution, that is, B 1, 2 are identically distributed That is, under simple random sampling, 1 and 2 are independently and identically distributed (i.i.d.). More generally, under simple random sampling, { i }, i = 1,, n, are i.i.d. This framework allows rigorous statistical inferences about moments of population distributions using a sample of data from that population
45 1. The probability framework for statistical inference 2. Estimation 3. Testing 4. Confidence Intervals Estimation is the natural estimator of the mean. But: (a) What are the properties of? (b) Why should we use rather than some other estimator? 1 (the first observation) maybe unequal weights not simple average 45 median( 1,, n ) The starting point is the sampling distribution of
46 (a) The sampling distribution of 46 is a random variable, and its properties are determined by the sampling distribution of The individuals in the sample are drawn at random. Thus the values of ( 1,, n ) are random Thus functions of ( 1,, n ), such as, are random: had a different sample been drawn, they would have taken on a different value The distribution of over different possible samples of size n is called the sampling distribution of. The mean and variance of are the mean and variance of its sampling distribution, E( ) and var( ). The concept of the sampling distribution underpins all of econometrics.
47 The sampling distribution of, ctd. 47 Example: Suppose takes on 0 or 1 (a Bernoulli random variable) with the probability distribution, Pr[ = 0] =0.22, Pr( =1) = 0.78 Then E() = p 1 + (1 p) 0 = p = 0.78 s = E[ E()] 2 = p(1 p) [remember this?] 2 = 0.78(1 0.78) = The sampling distribution of depends on n. Consider n = 2. The sampling distribution of is, Pr( = 0) = = Pr( = ½) = = Pr( = 1) = =
48 48 The sampling distribution of (p =.78): when is Bernoulli
49 49 Things we want to know about the sampling distribution: What is the mean of? If E( ) = true = 0.78, then is an unbiased estimator of What is the variance of? How does var( ) depend on n (famous 1/n formula) Does become close to when n is large? Law of large numbers: is a consistent estimator of appears bell shaped for n large is this generally true? In fact, is approximately normally distributed for n large (Central Limit Theorem)
50 The mean and variance of the sampling distribution of 50 General case that is, for i i.i.d. from any distribution, not just Bernoulli: 1 n n 1 1 n mean: E( ) = E( i ) = E ( i ) = = n n n Variance: var( ) = E[ E( )] 2 i 1 i 1 = E[ ] 2 = E 1 = E n 1 n i n i1 n i1 ( i ) 2 2 i1
51 so 1 var( ) = E n n i1 ( i ) 2 n n 1 1 = E ( i ) ( j ) n i1 n j1 1 = 2 n 1 n n i1 j1 n n = 2 n i 1 j 1 E ( i )( j ) cov(, ) i j 51 = = 1 n 2 2 i1 n 2 n
52 52 Mean and variance of sampling distribution of, ctd. E( ) = var( ) = 2 n Implications: 1. is an unbiased estimator of (that is, E( ) = ) 2. var( ) is inversely proportional to n the spread of the sampling distribution is proportional to 1/ n Thus the sampling uncertainty associated with is proportional to 1/ n (larger samples, less uncertainty, but square-root law)
53 53 The sampling distribution of is large when n For small sample sizes, the distribution of is complicated, but if n is large, the sampling distribution is simple! 1. As n increases, the distribution of becomes more tightly centered around (the Law of Large Numbers) 2. Moreover, the distribution of becomes normal (the Central Limit Theorem)
54 The Law of Large Numbers: 54 An estimator is consistent if the probability that its falls within an interval of the true population value tends to one as the sample size increases. 2 If ( 1,, n ) are i.i.d. and <, then is a consistent estimator of, that is, Pr[ < ] 1 as n which can be written, p ( p means converges in probability to ). 2 (the math: as n, var( ) = 0, which implies that Pr[ < ] 1.) n
55 55 The Central Limit Theorem (CLT): 2 If ( 1,, n ) are i.i.d. and 0 < <, then when n is large the distribution of is well approximated by a normal distribution. 2 is approximately distributed N(, ) ( normal n 2 distribution with mean and variance /n ) n ( )/ is approximately distributed N(0,1) (standard normal) E( ) That is, standardized = = is var( ) / n approximately distributed as N(0,1) The larger is n, the better is the approximation.
56 56 Sampling distribution of Bernoulli, p = 0.78: when is
57 57 E( ) Same example: sampling distribution of : var( )
58 Summary: The Sampling Distribution of 58 2 For 1,, n i.i.d. with 0 < <, The exact (finite sample) sampling distribution of has mean ( is an unbiased estimator of ) and variance 2 /n Other than its mean and variance, the exact distribution of is complicated and depends on the distribution of (the population distribution) When n is large, the sampling distribution simplifies: p (Law of large numbers) E( ) var( ) is approximately N(0,1) (CLT)
59 (b) Why Use To Estimate? 59 is unbiased: E( ) = is consistent: p is the least squares estimator of ; solves, n min ( m) m i1 i 2 so, minimizes the sum of squared residuals optional derivation n n n d 2 d ( i m) = 2 ( i m ) = 2 ( i m) dm i 1 i1 dm i1 Set derivative to zero and denote optimal value of m by ˆm: n = i1 n mˆ = i1 ˆ nm or ˆm = 1 n i i 1 n =
60 Why Use To Estimate?, ctd. 60 has a smaller variance than all other linear unbiased estimators: consider the estimator, ˆ n 1 a, where i i n i1 {a i } are such that ˆ is unbiased; then var( ) var( ˆ ) isn t the only estimator of can you think of a time you might want to use the median instead?
61 1. The probability framework for statistical inference 2. Estimation 3. Hypothesis Testing 4. Confidence intervals Hypothesis Testing The hypothesis testing problem (for the mean): make a provisional decision, based on the evidence at hand, whether a null hypothesis is true, or instead that some alternative hypothesis is true. That is, test H 0 : E() =,0 vs. H 1 : E() >,0 (1-sided, >) H 0 : E() =,0 vs. H 1 : E() <,0 (1-sided, <) H 0 : E() =,0 vs. H 1 : E(),0 (2-sided) 61
62 Some terminology for testing statistical hypotheses: p-value = probability of drawing a statistic (e.g. ) at least as 62 adverse to the null as the value actually computed with your data, assuming that the null hypothesis is true. The significance level of a test is a pre-specified probability of incorrectly rejecting the null, when the null is true. Calculating the p-value based on : p-value = Pr [ ] act H0,0,0 where act is the value of actually observed (nonrandom)
63 Calculating the p-value, ctd. 63 To compute the p-value, you need the to know the sampling distribution of, which is complicated if n is small. If n is large, you can use the normal approximation (CLT): p-value = Pr [ ], = = act H0,0,0 act,0,0 Pr H [ ] 0 / n / act,0,0 Pr H [ ] 0 n probability under left+right N(0,1) tails where = std. dev. of the distribution of = / n.
64 Calculating the p-value with known: 64 For large n, p-value = the probability that a N(0,1) random variable falls outside ( act,0 )/ In practice, is unknown it must be estimated
65 Estimator of the variance of : 65 Fact: 2 s = 1 n n 2 ( i ) 1 = sample variance of i1 If ( 1,, n ) are i.i.d. and E( 4 ) <, then 2 s p 2 Why does the law of large numbers apply? Because 2 s is a sample average; see Appendix 3.3 Technical note: we assume E( 4 ) < because here the average is not of i, but of its square; see App. 3.3
66 Computing the p-value with 2 estimated: 66 so p-value = = Pr [ ], act H0,0,0 act,0,0 Pr H [ ] 0 0 p-value = / n / (large n) s / n s / n act,0,0 Pr H [ ] 0 act Pr H [ t t ] ( estimated) n 2 probability under normal tails outside t act where t = s,0 / n (the usual t-statistic)
67 What is the link between the p-value 67 and the significance level? The significance level is prespecified. For example, if the prespecified significance level is 5%, you reject the null hypothesis if t 1.96 equivalently, you reject if p The p-value is sometimes called the marginal significance level. Often, it is better to communicate the p-value than simply whether a test rejects or not the p-value contains more information than the yes/no statement about whether the test rejects.
68 At this point, you might be wondering, What happened to the t-table and the degrees of freedom? Digression: the Student t distribution If i, i = 1,, n is i.i.d. N(, ), then the t-statistic has the Student t-distribution with n 1 degrees of freedom. 2 The critical values of the Student t-distribution is tabulated in the back of all statistics books. Remember the recipe? 1. Compute the t-statistic 2. Compute the degrees of freedom, which is n 1 3. Look up the 5% critical value 4. If the t-statistic exceeds (in absolute value) this critical value, reject the null hypothesis.
69 Comments on this recipe and the Student t-distribution The theory of the t-distribution was one of the early triumphs of mathematical statistics. It is astounding, really: if is i.i.d. normal, then you can know the exact, finite-sample distribution of the t-statistic it is the Student t. So, you can construct confidence intervals (using the Student t critical value) that have exactly the right coverage rate, no matter what the sample size. This result was really useful in times when computer was a job title, data collection was expensive, and the number of observations was perhaps a dozen. It is also a conceptually beautiful result, and the math is beautiful too which is probably why stats profs love to teach the t-distribution. But.
70 Comments on Student t distribution, ctd If the sample size is moderate (several dozen) or large (hundreds or more), the difference between the t-distribution and N(0,1) critical values are negligible. Here are some 5% critical values for 2-sided tests: degrees of freedom (n 1) 5% t-distribution critical value
71 Comments on Student t distribution, ctd So, the Student-t distribution is only relevant when the sample size is very small; but in that case, for it to be correct, you must be sure that the population distribution of is normal. In economic data, the normality assumption is rarely credible. Here are the distributions of some economic data. Do you think earnings are normally distributed? Suppose you have a sample of n = 10 observations from one of these distributions would you feel comfortable using the Student t distribution?
72 72
73 Comments on Student t distribution, ctd ou might not know this. Consider the t-statistic testing the hypothesis that two means (groups s, l) are equal: s l s l t 2 2 ss sl SE( s l) n s n l Even if the population distribution of in the two groups is normal, this statistic doesn t have a Student t distribution! There is a statistic testing this hypothesis that has a normal distribution, the pooled variance t-statistic however the pooled variance t-statistic is only valid if the variances of the normal distributions are the same in the two groups. Would you expect this to be true, say, for men s v. women s wages?
74 The Student-t distribution summary 74 The assumption that is distributed N(, ) is rarely plausible in practice (income? number of children?) For n > 30, the t-distribution and N(0,1) are very close (as n grows large, the t n 1 distribution converges to N(0,1)) The t-distribution is an artifact from days when sample sizes were small and computers were people For historical reasons, statistical software typically uses the t-distribution to compute p-values but this is irrelevant when the sample size is moderate or large. For these reasons, in this class we will focus on the large-n approximation given by the CLT 2
75 1. The probability framework for statistical inference 2. Estimation 3. Testing 4. Confidence intervals Confidence Intervals A 95% confidence interval for is an interval that contains the true value of in 95% of repeated samples. 75 Digression: What is random here? The values of 1,, n and thus any functions of them including the confidence interval. The confidence interval it will differ from one sample to the next. The population parameter,, is not random, we just don t know it.
76 Confidence intervals, ctd. 76 A 95% confidence interval can always be constructed as the set of values of not rejected by a hypothesis test with a 5% significance level. { : s / n 1.96} = { : 1.96 s = { : 1.96 sn s 1.96 n } = { ( 1.96 sn, s n )} / n 1.96} This confidence interval relies on the large-n results that is approximately normally distributed and 2 s p 2.
77 Summary: 77 From the two assumptions of: (1) simple random sampling of a population, that is, { i, i =1,,n} are i.i.d. (2) 0 < E( 4 ) < we developed, for large samples (large n): Theory of estimation (sampling distribution of ) Theory of hypothesis testing (large-n distribution of t- statistic and computation of the p-value) Theory of confidence intervals (constructed by inverting test statistic) Are assumptions (1) & (2) plausible in practice? es
Introduction to Econometrics Third Edition James H. Stock Mark W. Watson The statistical analysis of economic (and related) data
 data") Introduction to Econometrics Third Edition James H. Stock Mark W. Watson The statistical analysis of economic (and related) data 1/2/3-1 1/2/3-2 Brief Overview of the Course Economics suggests important
Introduction to Econometrics Third Edition James H. Stock Mark W. Watson The statistical analysis of economic (and related) data 1/2/3-1 1/2/3-2 Brief Overview of the Course Economics suggests important
Regression with a Single Regressor: Hypothesis Tests and Confidence Intervals
 Regression with a Single Regressor: Hypothesis Tests and Confidence Intervals (SW Chapter 5) Outline. The standard error of ˆ. Hypothesis tests concerning β 3. Confidence intervals for β 4. Regression
Regression with a Single Regressor: Hypothesis Tests and Confidence Intervals (SW Chapter 5) Outline. The standard error of ˆ. Hypothesis tests concerning β 3. Confidence intervals for β 4. Regression
Chapter 7. Hypothesis Tests and Confidence Intervals in Multiple Regression
 Chapter 7 Hypothesis Tests and Confidence Intervals in Multiple Regression Outline 1. Hypothesis tests and confidence intervals for a single coefficie. Joint hypothesis tests on multiple coefficients 3.
Chapter 7 Hypothesis Tests and Confidence Intervals in Multiple Regression Outline 1. Hypothesis tests and confidence intervals for a single coefficie. Joint hypothesis tests on multiple coefficients 3.
Introduction to Econometrics. Multiple Regression (2016/2017)
") Introduction to Econometrics STAT-S-301 Multiple Regression (016/017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 OLS estimate of the TS/STR relation: OLS estimate of the Test Score/STR relation:
Introduction to Econometrics STAT-S-301 Multiple Regression (016/017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 OLS estimate of the TS/STR relation: OLS estimate of the Test Score/STR relation:
ECON3150/4150 Spring 2015
 ECON3150/4150 Spring 2015 Lecture 3&4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo January 29, 2015 1 / 67 Chapter 4 in S&W Section 17.1 in S&W (extended OLS assumptions) 2
ECON3150/4150 Spring 2015 Lecture 3&4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo January 29, 2015 1 / 67 Chapter 4 in S&W Section 17.1 in S&W (extended OLS assumptions) 2
Lab 07 Introduction to Econometrics
 Lab 07 Introduction to Econometrics Learning outcomes for this lab: Introduce the different typologies of data and the econometric models that can be used Understand the rationale behind econometrics Understand
Lab 07 Introduction to Econometrics Learning outcomes for this lab: Introduce the different typologies of data and the econometric models that can be used Understand the rationale behind econometrics Understand
Hypothesis Tests and Confidence Intervals in Multiple Regression
 Hypothesis Tests and Confidence Intervals in Multiple Regression (SW Chapter 7) Outline 1. Hypothesis tests and confidence intervals for one coefficient. Joint hypothesis tests on multiple coefficients
Hypothesis Tests and Confidence Intervals in Multiple Regression (SW Chapter 7) Outline 1. Hypothesis tests and confidence intervals for one coefficient. Joint hypothesis tests on multiple coefficients
Linear Regression with Multiple Regressors
 Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
ECON Introductory Econometrics. Lecture 5: OLS with One Regressor: Hypothesis Tests
 ECON4150 - Introductory Econometrics Lecture 5: OLS with One Regressor: Hypothesis Tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 5 Lecture outline 2 Testing Hypotheses about one
ECON4150 - Introductory Econometrics Lecture 5: OLS with One Regressor: Hypothesis Tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 5 Lecture outline 2 Testing Hypotheses about one
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 6 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 53 Outline of Lecture 6 1 Omitted variable bias (SW 6.1) 2 Multiple
Applied Statistics and Econometrics Lecture 6 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 53 Outline of Lecture 6 1 Omitted variable bias (SW 6.1) 2 Multiple
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 7 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 68 Outline of Lecture 7 1 Empirical example: Italian labor force
Applied Statistics and Econometrics Lecture 7 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 68 Outline of Lecture 7 1 Empirical example: Italian labor force
Introduction to Econometrics. Multiple Regression
 Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Multiple Regression Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 OLS estimate of the TS/STR
Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Multiple Regression Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 OLS estimate of the TS/STR
Statistical Inference with Regression Analysis
 Introductory Applied Econometrics EEP/IAS 118 Spring 2015 Steven Buck Lecture #13 Statistical Inference with Regression Analysis Next we turn to calculating confidence intervals and hypothesis testing
Introductory Applied Econometrics EEP/IAS 118 Spring 2015 Steven Buck Lecture #13 Statistical Inference with Regression Analysis Next we turn to calculating confidence intervals and hypothesis testing
Business Statistics. Lecture 10: Course Review
 Business Statistics Lecture 10: Course Review 1 Descriptive Statistics for Continuous Data Numerical Summaries Location: mean, median Spread or variability: variance, standard deviation, range, percentiles,
Business Statistics Lecture 10: Course Review 1 Descriptive Statistics for Continuous Data Numerical Summaries Location: mean, median Spread or variability: variance, standard deviation, range, percentiles,
Linear Regression with Multiple Regressors
 Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
ECON Introductory Econometrics. Lecture 17: Experiments
 ECON4150 - Introductory Econometrics Lecture 17: Experiments Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 13 Lecture outline 2 Why study experiments? The potential outcome framework.
ECON4150 - Introductory Econometrics Lecture 17: Experiments Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 13 Lecture outline 2 Why study experiments? The potential outcome framework.
1 Independent Practice: Hypothesis tests for one parameter:
 1 Independent Practice: Hypothesis tests for one parameter: Data from the Indian DHS survey from 2006 includes a measure of autonomy of the women surveyed (a scale from 0-10, 10 being the most autonomous)
1 Independent Practice: Hypothesis tests for one parameter: Data from the Indian DHS survey from 2006 includes a measure of autonomy of the women surveyed (a scale from 0-10, 10 being the most autonomous)
Econometrics Midterm Examination Answers
 Econometrics Midterm Examination Answers March 4, 204. Question (35 points) Answer the following short questions. (i) De ne what is an unbiased estimator. Show that X is an unbiased estimator for E(X i
Econometrics Midterm Examination Answers March 4, 204. Question (35 points) Answer the following short questions. (i) De ne what is an unbiased estimator. Show that X is an unbiased estimator for E(X i
ECON3150/4150 Spring 2016
 ECON3150/4150 Spring 2016 Lecture 4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo Last updated: January 26, 2016 1 / 49 Overview These lecture slides covers: The linear regression
ECON3150/4150 Spring 2016 Lecture 4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo Last updated: January 26, 2016 1 / 49 Overview These lecture slides covers: The linear regression
Hypothesis Tests and Confidence Intervals. in Multiple Regression
 ECON4135, LN6 Hypothesis Tests and Confidence Intervals Outline 1. Why multipple regression? in Multiple Regression (SW Chapter 7) 2. Simpson s paradox (omitted variables bias) 3. Hypothesis tests and
ECON4135, LN6 Hypothesis Tests and Confidence Intervals Outline 1. Why multipple regression? in Multiple Regression (SW Chapter 7) 2. Simpson s paradox (omitted variables bias) 3. Hypothesis tests and
ECO220Y Simple Regression: Testing the Slope
 ECO220Y Simple Regression: Testing the Slope Readings: Chapter 18 (Sections 18.3-18.5) Winter 2012 Lecture 19 (Winter 2012) Simple Regression Lecture 19 1 / 32 Simple Regression Model y i = β 0 + β 1 x
ECO220Y Simple Regression: Testing the Slope Readings: Chapter 18 (Sections 18.3-18.5) Winter 2012 Lecture 19 (Winter 2012) Simple Regression Lecture 19 1 / 32 Simple Regression Model y i = β 0 + β 1 x
Nonlinear Regression Functions
 Nonlinear Regression Functions (SW Chapter 8) Outline 1. Nonlinear regression functions general comments 2. Nonlinear functions of one variable 3. Nonlinear functions of two variables: interactions 4.
Nonlinear Regression Functions (SW Chapter 8) Outline 1. Nonlinear regression functions general comments 2. Nonlinear functions of one variable 3. Nonlinear functions of two variables: interactions 4.
Problem Set #3-Key. wage Coef. Std. Err. t P> t [95% Conf. Interval]
![Problem Set #3-Key. wage Coef. Std. Err. t P> t [95% Conf. Interval]](/thumbs/84/90891969.jpg "Problem Set #3-Key. wage Coef. Std. Err. t P> t [95% Conf. Interval]") Problem Set #3-Key Sonoma State University Economics 317- Introduction to Econometrics Dr. Cuellar 1. Use the data set Wage1.dta to answer the following questions. a. For the regression model Wage i =
Problem Set #3-Key Sonoma State University Economics 317- Introduction to Econometrics Dr. Cuellar 1. Use the data set Wage1.dta to answer the following questions. a. For the regression model Wage i =
ECON Introductory Econometrics. Lecture 7: OLS with Multiple Regressors Hypotheses tests
 ECON4150 - Introductory Econometrics Lecture 7: OLS with Multiple Regressors Hypotheses tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 7 Lecture outline 2 Hypothesis test for single
ECON4150 - Introductory Econometrics Lecture 7: OLS with Multiple Regressors Hypotheses tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 7 Lecture outline 2 Hypothesis test for single
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 5 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 44 Outline of Lecture 5 Now that we know the sampling distribution
Applied Statistics and Econometrics Lecture 5 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 44 Outline of Lecture 5 Now that we know the sampling distribution
Multivariate Regression: Part I
 Topic 1 Multivariate Regression: Part I ARE/ECN 240 A Graduate Econometrics Professor: Òscar Jordà Outline of this topic Statement of the objective: we want to explain the behavior of one variable as a
Topic 1 Multivariate Regression: Part I ARE/ECN 240 A Graduate Econometrics Professor: Òscar Jordà Outline of this topic Statement of the objective: we want to explain the behavior of one variable as a
9. Linear Regression and Correlation
 9. Linear Regression and Correlation Data: y a quantitative response variable x a quantitative explanatory variable (Chap. 8: Recall that both variables were categorical) For example, y = annual income,
9. Linear Regression and Correlation Data: y a quantitative response variable x a quantitative explanatory variable (Chap. 8: Recall that both variables were categorical) For example, y = annual income,
Problem Set 1 ANSWERS
 Economics 20 Prof. Patricia M. Anderson Problem Set 1 ANSWERS Part I. Multiple Choice Problems 1. If X and Z are two random variables, then E[X-Z] is d. E[X] E[Z] This is just a simple application of one
Economics 20 Prof. Patricia M. Anderson Problem Set 1 ANSWERS Part I. Multiple Choice Problems 1. If X and Z are two random variables, then E[X-Z] is d. E[X] E[Z] This is just a simple application of one
ECON Introductory Econometrics. Lecture 2: Review of Statistics
 ECON415 - Introductory Econometrics Lecture 2: Review of Statistics Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 2-3 Lecture outline 2 Simple random sampling Distribution of the sample
ECON415 - Introductory Econometrics Lecture 2: Review of Statistics Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 2-3 Lecture outline 2 Simple random sampling Distribution of the sample
Review of Statistics 101
 Review of Statistics 101 We review some important themes from the course 1. Introduction Statistics- Set of methods for collecting/analyzing data (the art and science of learning from data). Provides methods
Review of Statistics 101 We review some important themes from the course 1. Introduction Statistics- Set of methods for collecting/analyzing data (the art and science of learning from data). Provides methods
The Simple Linear Regression Model
 The Simple Linear Regression Model Lesson 3 Ryan Safner 1 1 Department of Economics Hood College ECON 480 - Econometrics Fall 2017 Ryan Safner (Hood College) ECON 480 - Lesson 3 Fall 2017 1 / 77 Bivariate
The Simple Linear Regression Model Lesson 3 Ryan Safner 1 1 Department of Economics Hood College ECON 480 - Econometrics Fall 2017 Ryan Safner (Hood College) ECON 480 - Lesson 3 Fall 2017 1 / 77 Bivariate
General Linear Model (Chapter 4)
") General Linear Model (Chapter 4) Outcome variable is considered continuous Simple linear regression Scatterplots OLS is BLUE under basic assumptions MSE estimates residual variance testing regression coefficients
General Linear Model (Chapter 4) Outcome variable is considered continuous Simple linear regression Scatterplots OLS is BLUE under basic assumptions MSE estimates residual variance testing regression coefficients
Econometrics Homework 1
 Econometrics Homework Due Date: March, 24. by This problem set includes questions for Lecture -4 covered before midterm exam. Question Let z be a random column vector of size 3 : z = @ (a) Write out z
Econometrics Homework Due Date: March, 24. by This problem set includes questions for Lecture -4 covered before midterm exam. Question Let z be a random column vector of size 3 : z = @ (a) Write out z
Review of probability and statistics 1 / 31
 Review of probability and statistics 1 / 31 2 / 31 Why? This chapter follows Stock and Watson (all graphs are from Stock and Watson). You may as well refer to the appendix in Wooldridge or any other introduction
Review of probability and statistics 1 / 31 2 / 31 Why? This chapter follows Stock and Watson (all graphs are from Stock and Watson). You may as well refer to the appendix in Wooldridge or any other introduction
Review of Statistics
 Review of Statistics Topics Descriptive Statistics Mean, Variance Probability Union event, joint event Random Variables Discrete and Continuous Distributions, Moments Two Random Variables Covariance and
Review of Statistics Topics Descriptive Statistics Mean, Variance Probability Union event, joint event Random Variables Discrete and Continuous Distributions, Moments Two Random Variables Covariance and
The F distribution. If: 1. u 1,,u n are normally distributed; and 2. X i is distributed independently of u i (so in particular u i is homoskedastic)
") The F distribution If: 1. u 1,,u n are normally distributed; and. X i is distributed independently of u i (so in particular u i is homoskedastic) then the homoskedasticity-only F-statistic has the F q,n-k
The F distribution If: 1. u 1,,u n are normally distributed; and. X i is distributed independently of u i (so in particular u i is homoskedastic) then the homoskedasticity-only F-statistic has the F q,n-k
Question 1 carries a weight of 25%; Question 2 carries 20%; Question 3 carries 20%; Question 4 carries 35%.
 UNIVERSITY OF EAST ANGLIA School of Economics Main Series PGT Examination 017-18 ECONOMETRIC METHODS ECO-7000A Time allowed: hours Answer ALL FOUR Questions. Question 1 carries a weight of 5%; Question
UNIVERSITY OF EAST ANGLIA School of Economics Main Series PGT Examination 017-18 ECONOMETRIC METHODS ECO-7000A Time allowed: hours Answer ALL FOUR Questions. Question 1 carries a weight of 5%; Question
2) For a normal distribution, the skewness and kurtosis measures are as follows: A) 1.96 and 4 B) 1 and 2 C) 0 and 3 D) 0 and 0
 For a normal distribution, the skewness and kurtosis measures are as follows: A) 1.96 and 4 B) 1 and 2 C) 0 and 3 D) 0 and 0") Introduction to Econometrics Midterm April 26, 2011 Name Student ID MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. (5,000 credit for each correct
Introduction to Econometrics Midterm April 26, 2011 Name Student ID MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. (5,000 credit for each correct
Chapter 6: Linear Regression With Multiple Regressors
 Chapter 6: Linear Regression With Multiple Regressors 1-1 Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Chapter 6: Linear Regression With Multiple Regressors 1-1 Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
The t-test: A z-score for a sample mean tells us where in the distribution the particular mean lies
 The t-test: So Far: Sampling distribution benefit is that even if the original population is not normal, a sampling distribution based on this population will be normal (for sample size > 30). Benefit
The t-test: So Far: Sampling distribution benefit is that even if the original population is not normal, a sampling distribution based on this population will be normal (for sample size > 30). Benefit
ES103 Introduction to Econometrics
 Anita Staneva May 16, ES103 2015Introduction to Econometrics.. Lecture 1 ES103 Introduction to Econometrics Lecture 1: Basic Data Handling and Anita Staneva Egypt Scholars Economic Society Outline Introduction
Anita Staneva May 16, ES103 2015Introduction to Econometrics.. Lecture 1 ES103 Introduction to Econometrics Lecture 1: Basic Data Handling and Anita Staneva Egypt Scholars Economic Society Outline Introduction
Problem Set #5-Key Sonoma State University Dr. Cuellar Economics 317- Introduction to Econometrics
 Problem Set #5-Key Sonoma State University Dr. Cuellar Economics 317- Introduction to Econometrics C1.1 Use the data set Wage1.dta to answer the following questions. Estimate regression equation wage =
Problem Set #5-Key Sonoma State University Dr. Cuellar Economics 317- Introduction to Econometrics C1.1 Use the data set Wage1.dta to answer the following questions. Estimate regression equation wage =
Multiple Regression: Inference
 Multiple Regression: Inference The t-test: is ˆ j big and precise enough? We test the null hypothesis: H 0 : β j =0; i.e. test that x j has no effect on y once the other explanatory variables are controlled
Multiple Regression: Inference The t-test: is ˆ j big and precise enough? We test the null hypothesis: H 0 : β j =0; i.e. test that x j has no effect on y once the other explanatory variables are controlled
Linear Regression with one Regressor
 1 Linear Regression with one Regressor Covering Chapters 4.1 and 4.2. We ve seen the California test score data before. Now we will try to estimate the marginal effect of STR on SCORE. To motivate these
1 Linear Regression with one Regressor Covering Chapters 4.1 and 4.2. We ve seen the California test score data before. Now we will try to estimate the marginal effect of STR on SCORE. To motivate these
Answer all questions from part I. Answer two question from part II.a, and one question from part II.b.
 B203: Quantitative Methods Answer all questions from part I. Answer two question from part II.a, and one question from part II.b. Part I: Compulsory Questions. Answer all questions. Each question carries
B203: Quantitative Methods Answer all questions from part I. Answer two question from part II.a, and one question from part II.b. Part I: Compulsory Questions. Answer all questions. Each question carries
Section 3: Simple Linear Regression
 Section 3: Simple Linear Regression Carlos M. Carvalho The University of Texas at Austin McCombs School of Business http://faculty.mccombs.utexas.edu/carlos.carvalho/teaching/ 1 Regression: General Introduction
Section 3: Simple Linear Regression Carlos M. Carvalho The University of Texas at Austin McCombs School of Business http://faculty.mccombs.utexas.edu/carlos.carvalho/teaching/ 1 Regression: General Introduction
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 13 Nonlinearities Saul Lach October 2018 Saul Lach () Applied Statistics and Econometrics October 2018 1 / 91 Outline of Lecture 13 1 Nonlinear regression functions
Applied Statistics and Econometrics Lecture 13 Nonlinearities Saul Lach October 2018 Saul Lach () Applied Statistics and Econometrics October 2018 1 / 91 Outline of Lecture 13 1 Nonlinear regression functions
Mathematics for Economics MA course
 Mathematics for Economics MA course Simple Linear Regression Dr. Seetha Bandara Simple Regression Simple linear regression is a statistical method that allows us to summarize and study relationships between
Mathematics for Economics MA course Simple Linear Regression Dr. Seetha Bandara Simple Regression Simple linear regression is a statistical method that allows us to summarize and study relationships between
Sociology 593 Exam 2 Answer Key March 28, 2002
 Sociology 59 Exam Answer Key March 8, 00 I. True-False. (0 points) Indicate whether the following statements are true or false. If false, briefly explain why.. A variable is called CATHOLIC. This probably
Sociology 59 Exam Answer Key March 8, 00 I. True-False. (0 points) Indicate whether the following statements are true or false. If false, briefly explain why.. A variable is called CATHOLIC. This probably
Statistics for IT Managers
 Statistics for IT Managers 95-796, Fall 2012 Module 2: Hypothesis Testing and Statistical Inference (5 lectures) Reading: Statistics for Business and Economics, Ch. 5-7 Confidence intervals Given the sample
Statistics for IT Managers 95-796, Fall 2012 Module 2: Hypothesis Testing and Statistical Inference (5 lectures) Reading: Statistics for Business and Economics, Ch. 5-7 Confidence intervals Given the sample
Ordinary Least Squares Regression Explained: Vartanian
 Ordinary Least Squares Regression Explained: Vartanian When to Use Ordinary Least Squares Regression Analysis A. Variable types. When you have an interval/ratio scale dependent variable.. When your independent
Ordinary Least Squares Regression Explained: Vartanian When to Use Ordinary Least Squares Regression Analysis A. Variable types. When you have an interval/ratio scale dependent variable.. When your independent
M(t) = 1 t. (1 t), 6 M (0) = 20 P (95. X i 110) i=1
 = 1 t. (1 t), 6 M (0) = 20 P (95. X i 110) i=1") Math 66/566 - Midterm Solutions NOTE: These solutions are for both the 66 and 566 exam. The problems are the same until questions and 5. 1. The moment generating function of a random variable X is M(t)
Math 66/566 - Midterm Solutions NOTE: These solutions are for both the 66 and 566 exam. The problems are the same until questions and 5. 1. The moment generating function of a random variable X is M(t)
Practice exam questions
 Practice exam questions Nathaniel Higgins nhiggins@jhu.edu, nhiggins@ers.usda.gov 1. The following question is based on the model y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 + u. Discuss the following two hypotheses.
Practice exam questions Nathaniel Higgins nhiggins@jhu.edu, nhiggins@ers.usda.gov 1. The following question is based on the model y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 + u. Discuss the following two hypotheses.
Empirical Application of Simple Regression (Chapter 2)
") Empirical Application of Simple Regression (Chapter 2) 1. The data file is House Data, which can be downloaded from my webpage. 2. Use stata menu File Import Excel Spreadsheet to read the data. Don t forget
Empirical Application of Simple Regression (Chapter 2) 1. The data file is House Data, which can be downloaded from my webpage. 2. Use stata menu File Import Excel Spreadsheet to read the data. Don t forget
Harvard University. Rigorous Research in Engineering Education
 Statistical Inference Kari Lock Harvard University Department of Statistics Rigorous Research in Engineering Education 12/3/09 Statistical Inference You have a sample and want to use the data collected
Statistical Inference Kari Lock Harvard University Department of Statistics Rigorous Research in Engineering Education 12/3/09 Statistical Inference You have a sample and want to use the data collected
L6: Regression II. JJ Chen. July 2, 2015
 L6: Regression II JJ Chen July 2, 2015 Today s Plan Review basic inference based on Sample average Difference in sample average Extrapolate the knowledge to sample regression coefficients Standard error,
L6: Regression II JJ Chen July 2, 2015 Today s Plan Review basic inference based on Sample average Difference in sample average Extrapolate the knowledge to sample regression coefficients Standard error,
University of California at Berkeley Fall Introductory Applied Econometrics Final examination. Scores add up to 125 points
 EEP 118 / IAS 118 Elisabeth Sadoulet and Kelly Jones University of California at Berkeley Fall 2008 Introductory Applied Econometrics Final examination Scores add up to 125 points Your name: SID: 1 1.
EEP 118 / IAS 118 Elisabeth Sadoulet and Kelly Jones University of California at Berkeley Fall 2008 Introductory Applied Econometrics Final examination Scores add up to 125 points Your name: SID: 1 1.
ECON Introductory Econometrics. Lecture 4: Linear Regression with One Regressor
 ECON4150 - Introductory Econometrics Lecture 4: Linear Regression with One Regressor Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 4 Lecture outline 2 The OLS estimators The effect of
ECON4150 - Introductory Econometrics Lecture 4: Linear Regression with One Regressor Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 4 Lecture outline 2 The OLS estimators The effect of
EC212: Introduction to Econometrics Review Materials (Wooldridge, Appendix)
") 1 EC212: Introduction to Econometrics Review Materials (Wooldridge, Appendix) Taisuke Otsu London School of Economics Summer 2018 A.1. Summation operator (Wooldridge, App. A.1) 2 3 Summation operator For
1 EC212: Introduction to Econometrics Review Materials (Wooldridge, Appendix) Taisuke Otsu London School of Economics Summer 2018 A.1. Summation operator (Wooldridge, App. A.1) 2 3 Summation operator For
Statistical inference
 Statistical inference Contents 1. Main definitions 2. Estimation 3. Testing L. Trapani MSc Induction - Statistical inference 1 1 Introduction: definition and preliminary theory In this chapter, we shall
Statistical inference Contents 1. Main definitions 2. Estimation 3. Testing L. Trapani MSc Induction - Statistical inference 1 1 Introduction: definition and preliminary theory In this chapter, we shall
Multiple Regression Analysis
 Multiple Regression Analysis y = β 0 + β 1 x 1 + β 2 x 2 +... β k x k + u 2. Inference 0 Assumptions of the Classical Linear Model (CLM)! So far, we know: 1. The mean and variance of the OLS estimators
Multiple Regression Analysis y = β 0 + β 1 x 1 + β 2 x 2 +... β k x k + u 2. Inference 0 Assumptions of the Classical Linear Model (CLM)! So far, we know: 1. The mean and variance of the OLS estimators
Inferences for Regression
 Inferences for Regression An Example: Body Fat and Waist Size Looking at the relationship between % body fat and waist size (in inches). Here is a scatterplot of our data set: Remembering Regression In
Inferences for Regression An Example: Body Fat and Waist Size Looking at the relationship between % body fat and waist size (in inches). Here is a scatterplot of our data set: Remembering Regression In
) The cumulative probability distribution shows the probability
 The cumulative probability distribution shows the probability") Problem Set ECONOMETRICS Prof Òscar Jordà Due Date: Thursday, April 0 STUDENT S NAME: Multiple Choice Questions [0 pts] Please provide your answers to this section below: 3 4 5 6 7 8 9 0 ) The cumulative
Problem Set ECONOMETRICS Prof Òscar Jordà Due Date: Thursday, April 0 STUDENT S NAME: Multiple Choice Questions [0 pts] Please provide your answers to this section below: 3 4 5 6 7 8 9 0 ) The cumulative
Introduction to Econometrics
 Introduction to Econometrics STAT-S-301 Experiments and Quasi-Experiments (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Why study experiments? Ideal randomized controlled experiments
Introduction to Econometrics STAT-S-301 Experiments and Quasi-Experiments (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Why study experiments? Ideal randomized controlled experiments
y = a + bx 12.1: Inference for Linear Regression Review: General Form of Linear Regression Equation Review: Interpreting Computer Regression Output
 12.1: Inference for Linear Regression Review: General Form of Linear Regression Equation y = a + bx y = dependent variable a = intercept b = slope x = independent variable Section 12.1 Inference for Linear
12.1: Inference for Linear Regression Review: General Form of Linear Regression Equation y = a + bx y = dependent variable a = intercept b = slope x = independent variable Section 12.1 Inference for Linear
Lab 10 - Binary Variables
 Lab 10 - Binary Variables Spring 2017 Contents 1 Introduction 1 2 SLR on a Dummy 2 3 MLR with binary independent variables 3 3.1 MLR with a Dummy: different intercepts, same slope................. 4 3.2
Lab 10 - Binary Variables Spring 2017 Contents 1 Introduction 1 2 SLR on a Dummy 2 3 MLR with binary independent variables 3 3.1 MLR with a Dummy: different intercepts, same slope................. 4 3.2
Econometrics I KS. Module 2: Multivariate Linear Regression. Alexander Ahammer. This version: April 16, 2018
 Econometrics I KS Module 2: Multivariate Linear Regression Alexander Ahammer Department of Economics Johannes Kepler University of Linz This version: April 16, 2018 Alexander Ahammer (JKU) Module 2: Multivariate
Econometrics I KS Module 2: Multivariate Linear Regression Alexander Ahammer Department of Economics Johannes Kepler University of Linz This version: April 16, 2018 Alexander Ahammer (JKU) Module 2: Multivariate
Sociology Exam 2 Answer Key March 30, 2012
 Sociology 63993 Exam 2 Answer Key March 30, 2012 I. True-False. (20 points) Indicate whether the following statements are true or false. If false, briefly explain why. 1. A researcher has constructed scales
Sociology 63993 Exam 2 Answer Key March 30, 2012 I. True-False. (20 points) Indicate whether the following statements are true or false. If false, briefly explain why. 1. A researcher has constructed scales
At this point, if you ve done everything correctly, you should have data that looks something like:
 This homework is due on July 19 th. Economics 375: Introduction to Econometrics Homework #4 1. One tool to aid in understanding econometrics is the Monte Carlo experiment. A Monte Carlo experiment allows
This homework is due on July 19 th. Economics 375: Introduction to Econometrics Homework #4 1. One tool to aid in understanding econometrics is the Monte Carlo experiment. A Monte Carlo experiment allows
Group Comparisons: Differences in Composition Versus Differences in Models and Effects
 Group Comparisons: Differences in Composition Versus Differences in Models and Effects Richard Williams, University of Notre Dame, https://www3.nd.edu/~rwilliam/ Last revised February 15, 2015 Overview.
Group Comparisons: Differences in Composition Versus Differences in Models and Effects Richard Williams, University of Notre Dame, https://www3.nd.edu/~rwilliam/ Last revised February 15, 2015 Overview.
5. Let W follow a normal distribution with mean of μ and the variance of 1. Then, the pdf of W is
 Practice Final Exam Last Name:, First Name:. Please write LEGIBLY. Answer all questions on this exam in the space provided (you may use the back of any page if you need more space). Show all work but do
Practice Final Exam Last Name:, First Name:. Please write LEGIBLY. Answer all questions on this exam in the space provided (you may use the back of any page if you need more space). Show all work but do
The Difference in Proportions Test
 Overview The Difference in Proportions Test Dr Tom Ilvento Department of Food and Resource Economics A Difference of Proportions test is based on large sample only Same strategy as for the mean We calculate
Overview The Difference in Proportions Test Dr Tom Ilvento Department of Food and Resource Economics A Difference of Proportions test is based on large sample only Same strategy as for the mean We calculate
ECON 497 Final Exam Page 1 of 12
 ECON 497 Final Exam Page of 2 ECON 497: Economic Research and Forecasting Name: Spring 2008 Bellas Final Exam Return this exam to me by 4:00 on Wednesday, April 23. It may be e-mailed to me. It may be
ECON 497 Final Exam Page of 2 ECON 497: Economic Research and Forecasting Name: Spring 2008 Bellas Final Exam Return this exam to me by 4:00 on Wednesday, April 23. It may be e-mailed to me. It may be
Lecture 3: Multiple Regression. Prof. Sharyn O Halloran Sustainable Development U9611 Econometrics II
 Lecture 3: Multiple Regression Prof. Sharyn O Halloran Sustainable Development Econometrics II Outline Basics of Multiple Regression Dummy Variables Interactive terms Curvilinear models Review Strategies
Lecture 3: Multiple Regression Prof. Sharyn O Halloran Sustainable Development Econometrics II Outline Basics of Multiple Regression Dummy Variables Interactive terms Curvilinear models Review Strategies
Assessing Studies Based on Multiple Regression
 Assessing Studies Based on Multiple Regression Outline 1. Internal and External Validity 2. Threats to Internal Validity a. Omitted variable bias b. Functional form misspecification c. Errors-in-variables
Assessing Studies Based on Multiple Regression Outline 1. Internal and External Validity 2. Threats to Internal Validity a. Omitted variable bias b. Functional form misspecification c. Errors-in-variables
2.1. Consider the following production function, known in the literature as the transcendental production function (TPF).
.") CHAPTER Functional Forms of Regression Models.1. Consider the following production function, known in the literature as the transcendental production function (TPF). Q i B 1 L B i K i B 3 e B L B K 4 i
CHAPTER Functional Forms of Regression Models.1. Consider the following production function, known in the literature as the transcendental production function (TPF). Q i B 1 L B i K i B 3 e B L B K 4 i
Hypothesis testing. Data to decisions
 Hypothesis testing Data to decisions The idea Null hypothesis: H 0 : the DGP/population has property P Under the null, a sample statistic has a known distribution If, under that that distribution, the
Hypothesis testing Data to decisions The idea Null hypothesis: H 0 : the DGP/population has property P Under the null, a sample statistic has a known distribution If, under that that distribution, the
Chapter 11. Regression with a Binary Dependent Variable
 Chapter 11 Regression with a Binary Dependent Variable 2 Regression with a Binary Dependent Variable (SW Chapter 11) So far the dependent variable (Y) has been continuous: district-wide average test score
Chapter 11 Regression with a Binary Dependent Variable 2 Regression with a Binary Dependent Variable (SW Chapter 11) So far the dependent variable (Y) has been continuous: district-wide average test score
S o c i o l o g y E x a m 2 A n s w e r K e y - D R A F T M a r c h 2 7,
 S o c i o l o g y 63993 E x a m 2 A n s w e r K e y - D R A F T M a r c h 2 7, 2 0 0 9 I. True-False. (20 points) Indicate whether the following statements are true or false. If false, briefly explain
S o c i o l o g y 63993 E x a m 2 A n s w e r K e y - D R A F T M a r c h 2 7, 2 0 0 9 I. True-False. (20 points) Indicate whether the following statements are true or false. If false, briefly explain
1. The shoe size of five randomly selected men in the class is 7, 7.5, 6, 6.5 the shoe size of 4 randomly selected women is 6, 5.
 Economics 3 Introduction to Econometrics Winter 2004 Professor Dobkin Name Final Exam (Sample) You must answer all the questions. The exam is closed book and closed notes you may use calculators. You must
Economics 3 Introduction to Econometrics Winter 2004 Professor Dobkin Name Final Exam (Sample) You must answer all the questions. The exam is closed book and closed notes you may use calculators. You must
Can you tell the relationship between students SAT scores and their college grades?
 Correlation One Challenge Can you tell the relationship between students SAT scores and their college grades? A: The higher SAT scores are, the better GPA may be. B: The higher SAT scores are, the lower
Correlation One Challenge Can you tell the relationship between students SAT scores and their college grades? A: The higher SAT scores are, the better GPA may be. B: The higher SAT scores are, the lower
EC2001 Econometrics 1 Dr. Jose Olmo Room D309
 EC2001 Econometrics 1 Dr. Jose Olmo Room D309 J.Olmo@City.ac.uk 1 Revision of Statistical Inference 1.1 Sample, observations, population A sample is a number of observations drawn from a population. Population:
EC2001 Econometrics 1 Dr. Jose Olmo Room D309 J.Olmo@City.ac.uk 1 Revision of Statistical Inference 1.1 Sample, observations, population A sample is a number of observations drawn from a population. Population:
Lecture 12: Interactions and Splines
 Lecture 12: Interactions and Splines Sandy Eckel seckel@jhsph.edu 12 May 2007 1 Definition Effect Modification The phenomenon in which the relationship between the primary predictor and outcome varies
Lecture 12: Interactions and Splines Sandy Eckel seckel@jhsph.edu 12 May 2007 1 Definition Effect Modification The phenomenon in which the relationship between the primary predictor and outcome varies
Handout 12. Endogeneity & Simultaneous Equation Models
 Handout 12. Endogeneity & Simultaneous Equation Models In which you learn about another potential source of endogeneity caused by the simultaneous determination of economic variables, and learn how to
Handout 12. Endogeneity & Simultaneous Equation Models In which you learn about another potential source of endogeneity caused by the simultaneous determination of economic variables, and learn how to
Empirical approaches in public economics
 Empirical approaches in public economics ECON4624 Empirical Public Economics Fall 2016 Gaute Torsvik Outline for today The canonical problem Basic concepts of causal inference Randomized experiments Non-experimental
Empirical approaches in public economics ECON4624 Empirical Public Economics Fall 2016 Gaute Torsvik Outline for today The canonical problem Basic concepts of causal inference Randomized experiments Non-experimental
MS&E 226: Small Data
 MS&E 226: Small Data Lecture 15: Examples of hypothesis tests (v5) Ramesh Johari ramesh.johari@stanford.edu 1 / 32 The recipe 2 / 32 The hypothesis testing recipe In this lecture we repeatedly apply the
MS&E 226: Small Data Lecture 15: Examples of hypothesis tests (v5) Ramesh Johari ramesh.johari@stanford.edu 1 / 32 The recipe 2 / 32 The hypothesis testing recipe In this lecture we repeatedly apply the
ANOVA - analysis of variance - used to compare the means of several populations.
 12.1 One-Way Analysis of Variance ANOVA - analysis of variance - used to compare the means of several populations. Assumptions for One-Way ANOVA: 1. Independent samples are taken using a randomized design.
12.1 One-Way Analysis of Variance ANOVA - analysis of variance - used to compare the means of several populations. Assumptions for One-Way ANOVA: 1. Independent samples are taken using a randomized design.
Introduction to Econometrics
 Introduction to Econometrics STAT-S-301 Introduction to Time Series Regression and Forecasting (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Introduction to Time Series Regression
Introduction to Econometrics STAT-S-301 Introduction to Time Series Regression and Forecasting (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Introduction to Time Series Regression
Sampling Distributions: Central Limit Theorem
 Review for Exam 2 Sampling Distributions: Central Limit Theorem Conceptually, we can break up the theorem into three parts: 1. The mean (µ M ) of a population of sample means (M) is equal to the mean (µ)
Review for Exam 2 Sampling Distributions: Central Limit Theorem Conceptually, we can break up the theorem into three parts: 1. The mean (µ M ) of a population of sample means (M) is equal to the mean (µ)
THE MULTIVARIATE LINEAR REGRESSION MODEL
 THE MULTIVARIATE LINEAR REGRESSION MODEL Why multiple regression analysis? Model with more than 1 independent variable: y 0 1x1 2x2 u It allows : -Controlling for other factors, and get a ceteris paribus
THE MULTIVARIATE LINEAR REGRESSION MODEL Why multiple regression analysis? Model with more than 1 independent variable: y 0 1x1 2x2 u It allows : -Controlling for other factors, and get a ceteris paribus
Education Production Functions. April 7, 2009
 Education Production Functions April 7, 2009 Outline I Production Functions for Education Hanushek Paper Card and Krueger Tennesee Star Experiment Maimonides Rule What do I mean by Production Function?
Education Production Functions April 7, 2009 Outline I Production Functions for Education Hanushek Paper Card and Krueger Tennesee Star Experiment Maimonides Rule What do I mean by Production Function?
Regression #8: Loose Ends
 Regression #8: Loose Ends Econ 671 Purdue University Justin L. Tobias (Purdue) Regression #8 1 / 30 In this lecture we investigate a variety of topics that you are probably familiar with, but need to touch
Regression #8: Loose Ends Econ 671 Purdue University Justin L. Tobias (Purdue) Regression #8 1 / 30 In this lecture we investigate a variety of topics that you are probably familiar with, but need to touch
Hypothesis testing I. - In particular, we are talking about statistical hypotheses. [get everyone s finger length!] n =
![Hypothesis testing I. - In particular, we are talking about statistical hypotheses. [get everyone s finger length!] n =](/thumbs/86/94764601.jpg "Hypothesis testing I. - In particular, we are talking about statistical hypotheses. [get everyone s finger length!] n =") Hypothesis testing I I. What is hypothesis testing? [Note we re temporarily bouncing around in the book a lot! Things will settle down again in a week or so] - Exactly what it says. We develop a hypothesis,
Hypothesis testing I I. What is hypothesis testing? [Note we re temporarily bouncing around in the book a lot! Things will settle down again in a week or so] - Exactly what it says. We develop a hypothesis,
Functional Form. So far considered models written in linear form. Y = b 0 + b 1 X + u (1) Implies a straight line relationship between y and X
 Implies a straight line relationship between y and X") Functional Form So far considered models written in linear form Y = b 0 + b 1 X + u (1) Implies a straight line relationship between y and X Functional Form So far considered models written in linear form
Functional Form So far considered models written in linear form Y = b 0 + b 1 X + u (1) Implies a straight line relationship between y and X Functional Form So far considered models written in linear form
Longitudinal Data Analysis Using Stata Paul D. Allison, Ph.D. Upcoming Seminar: May 18-19, 2017, Chicago, Illinois
 Longitudinal Data Analysis Using Stata Paul D. Allison, Ph.D. Upcoming Seminar: May 18-19, 217, Chicago, Illinois Outline 1. Opportunities and challenges of panel data. a. Data requirements b. Control
Longitudinal Data Analysis Using Stata Paul D. Allison, Ph.D. Upcoming Seminar: May 18-19, 217, Chicago, Illinois Outline 1. Opportunities and challenges of panel data. a. Data requirements b. Control
Introduction to Regression Analysis. Dr. Devlina Chatterjee 11 th August, 2017
 Introduction to Regression Analysis Dr. Devlina Chatterjee 11 th August, 2017 What is regression analysis? Regression analysis is a statistical technique for studying linear relationships. One dependent
Introduction to Regression Analysis Dr. Devlina Chatterjee 11 th August, 2017 What is regression analysis? Regression analysis is a statistical technique for studying linear relationships. One dependent
Difference between means - t-test /25
 Difference between means - t-test 1 Discussion Question p492 Ex 9-4 p492 1-3, 6-8, 12 Assume all variances are not equal. Ignore the test for variance. 2 Students will perform hypothesis tests for two
Difference between means - t-test 1 Discussion Question p492 Ex 9-4 p492 1-3, 6-8, 12 Assume all variances are not equal. Ignore the test for variance. 2 Students will perform hypothesis tests for two
Multiple Regression. Midterm results: AVG = 26.5 (88%) A = 27+ B = C =
 A = 27+ B = C =") Economics 130 Lecture 6 Midterm Review Next Steps for the Class Multiple Regression Review & Issues Model Specification Issues Launching the Projects!!!!! Midterm results: AVG = 26.5 (88%) A = 27+ B =
Economics 130 Lecture 6 Midterm Review Next Steps for the Class Multiple Regression Review & Issues Model Specification Issues Launching the Projects!!!!! Midterm results: AVG = 26.5 (88%) A = 27+ B =
Lectures 5 & 6: Hypothesis Testing
 Lectures 5 & 6: Hypothesis Testing in which you learn to apply the concept of statistical significance to OLS estimates, learn the concept of t values, how to use them in regression work and come across
Lectures 5 & 6: Hypothesis Testing in which you learn to apply the concept of statistical significance to OLS estimates, learn the concept of t values, how to use them in regression work and come across
Basic econometrics. Tutorial 3. Dipl.Kfm. Johannes Metzler
 Basic econometrics Tutorial 3 Dipl.Kfm. Introduction Some of you were asking about material to revise/prepare econometrics fundamentals. First of all, be aware that I will not be too technical, only as
Basic econometrics Tutorial 3 Dipl.Kfm. Introduction Some of you were asking about material to revise/prepare econometrics fundamentals. First of all, be aware that I will not be too technical, only as