Introduction to Econometrics. Multiple Regression (2016/2017)
|
|
|
- Rodger Rogers
- 5 years ago
- Views:
Transcription


1 Introduction to Econometrics STAT-S-301 Multiple Regression (016/017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1
2 OLS estimate of the TS/STR relation: OLS estimate of the Test Score/STR relation: Testscore_est = STR, R = 0.05, SER = 18.6 (10.4) (0.5) Is this a credible estimate of the causal effect on test scores of a change in the student-teacher ratio? No! There are omitted confounding factors (family income; whether the students are native English speakers) that bias the OLS estimator. The variable STR could be picking up the effect of these confounding factors.
3 Omitted Variable Bias The bias in the OLS estimator that occurs as a result of an omitted factor is called omitted variable bias. For omitted variable bias to occur, the omitted factor Z must be: 1. a determinant of Y. correlated with the regressor X Both conditions must hold for the omission of Z to result in omitted variable bias. 3
4 Omitted Variable Bias In the test score example: 1. English language ability (whether the student has English as a second language) plausibly affects standardized test scores: Z is a determinant of Y.. Immigrant communities tend to be less affluent and thus have smaller school budgets and higher STR: Z is correlated with X. Accordingly, ˆ 1 is biased. What is the direction of this bias? What does common sense suggest? If common sense fails you, there is a formula 4
5 5 A formula for omitted variable bias: 1 ˆ 1 = 1 1 ( ) ( ) n i i i n i i X X u X X = n i i X v n n s n where v i = (X i X )u i (X i X )u i. Under Least Squares Assumption #1, E[(X i X )u i ] = cov(x i,u i ) = 0. But what if E[(X i X )u i ] = cov(x i,u i ) = Xu 0?
6 6 Then 1 ˆ 1 = 1 1 ( ) ( ) n i i i n i i X X u X X = n i i X v n n s n so E( 1 ˆ ) 1 = 1 1 ( ) ( ) n i i i n i i X X u E X X Xu X = u Xu X X u where holds with equality when n is large; specifically, 1 ˆ p 1 + u Xu X, where Xu = corr(x,u).
7 If an omitted factor Z is both: (1) a determinant of Y (that is, it is contained in u); and () correlated with X, then Xu 0 and the OLS estimator ˆ 1 is biased. The mathematics makes precise the idea that districts with few ESL students (1) do better on standardized tests and () have smaller classes (bigger budgets), so ignoring the ESL factor results in overstating the class size effect. 7
 have smaller classes.")
8 Is this is actually going on in the CA data? Districts with fewer English Learners have higher test scores. Districts with lower percent EL (PctEL) have smaller classes. Among districts with comparable PctEL, the effect of class size is small (recall overall test score gap = 7.4). 8
9 Three ways to overcome omitted variable bias 1. Run a randomized controlled experiment in which treatment (STR) is randomly assigned: then PctEL is still a determinant of TestScore, but PctEL is uncorrelated with STR (but this is unrealistic in practice.).. Adopt the cross tabulation approach, with finer gradations of STR and PctEL (But soon we will run out of data, and what about other determinants like family income and parental education?). 3. Use a method in which the omitted variable (PctEL) is no longer omitted: include PctEL as an additional regressor in a multiple regression. 9
10 The Population Multiple Regression Model Consider the case of two regressors: Y i = X 1i + X i + u i, where i = 1,,n X 1, X are the two independent variables (regressors) (Y i, X 1i, X i ) denote the i th observation on Y, X 1, and X 0 = unknown population intercept 1 = effect on Y of a change in X 1, holding X constant = effect on Y of a change in X, holding X 1 constant u i = error term (omitted factors) 10
11 Interpretation of multiple regression coefficients Y i = X 1i + X i + u i, i = 1,,n Consider changing X 1 by X 1 while holding X constant: Before: Y = X 1 + X After: Y + Y = (X 1 + X 1 ) + X Difference: Y = 1 X 1 That is, 1 = also, = Y X Y X 1, holding X constant, holding X 1 constant and 0 = predicted value of Y when X 1 = X = 0. 11
12 The OLS Estimator in Multiple Regression With two regressors, the OLS estimator solves: n b0, b1, b Y i b0 b1 X1 i b X i. i1 min [ ( )] The OLS estimator minimizes the average squared difference between the actual values of Y i and the prediction (predicted value) based on the estimated line. This minimization problem is solved using calculus. The result is the OLS estimators of 0 and 1 and. 1
13 Example: the California test score data Regression of TestScore against STR: Testscore_est= STR. Now include percent English Learners in the district (PctEL): Testscore_est = STR 0.65PctEL. What happens to the coefficient on STR? Why? Note: corr(str, PctEL) =
14 Multiple regression in STATA reg testscr str pctel, robust; Regression with robust standard errors Number of obs = 40 F(, 417) = 3.8 Prob > F = R-squared = Root MSE = Robust testscr Coef. Std. Err. t P> t [95% Conf. Interval] str pctel _cons Testscore_est = STR 0.65PctEL What are the sampling distribution of ˆ 1 and ˆ? 14
15 The Least Squares Assumptions for Multiple Regression Y i = X 1i + X i + + k X ki + u i, i = 1,,n 1. The conditional distribution of u given the X s has mean zero, that is, E(u X 1 = x 1,, X k = x k ) = 0.. (X 1i,,X ki,y i ), i =1,,n, are i.i.d. 3. X 1,, X k, and u have four moments: 4 4 E( X 1i) <,, E( X ki) <, E( u 4 i ) <. 4. There is no multicollinearity. 15
16 Assumption #1: E(u X 1 = x 1,, X k = x k ) = 0. This has the same interpretation as in regression with a single regressor. If an omitted variable (1) belongs in the equation (so is in u) and () is correlated with an included X, then this condition fails. Failure of this condition leads to omitted variable bias. The solution if possible is to include the omitted variable in the regression. 16
17 Assumption #: (X 1i,,X ki,y i ), i =1,,n, are i.i.d. This is satisfied automatically if the data are collected by simple random sampling. Assumption #3: finite fourth moments This is technical assumption is satisfied automatically by variables with a bounded domain (test scores, PctEL, etc.). 17
18 Assumption #4: There is no perfect multicollinearity Perfect multicollinearity is when one of the regressors is an exact linear function of the other regressors. Usually it reflects a mistake in the definitions of the regressors, or an oddity in the data. Example: Suppose you accidentally include STR twice: regress testscr str str, robust Regression with robust standard errors Number of obs = 40 F( 1, 418) = 19.6 Prob > F = R-squared = Root MSE = Robust testscr Coef. Std. Err. t P> t [95% Conf. Interval] str str (dropped) _cons
19 Perfect multicollinearity In the previous regression, 1 is the effect on TestScore of a unit change in STR, holding STR constant (???). Second example: regress TestScore on a constant, D, and B, where: D i = 1 if STR 0, = 0 otherwise; B i = 1 if STR >0, = 0 otherwise, so B i = 1 D i and there is perfect multicollinearity. 19
20 The Sampling Distribution of the OLS Estimator Under the four Least Squares Assumptions: The exact (finite sample) distribution of 1 has mean 1, var( ˆ 1) is inversely proportional to n; so too for ˆ. Other than its mean and variance, the exact distribution of 1 is very complicated. ˆ 1 is consistent: ˆ 1 ˆ ˆ 1 E( 1) var( ˆ ) 1 So too for,, ˆk. ˆ p 1 (law of large numbers). is approximately distributed N(0,1) (CLT). ˆ ˆ 0
21 Hypothesis Tests and Confidence Intervals for a Single Coefficient in Multiple Regression ˆ ˆ 1 E( 1) var( ˆ ) 1 is approximately distributed N(0,1) (CLT). Thus, hypotheses on 1 can be tested using the usual t-statistic, and confidence intervals are constructed as [ SE( 1)]. ˆ ˆ So too for,, k. Note: ˆ 1 and ˆ are generally not independently distributed so neither are their t-statistics (more on this later). 1
22 Example: The California class size data (1) Testscore_est = STR (10.4) (0.5) () Testscore_est = STR 0.650PctEL (8.7) (0.43) (0.031) The coefficient on STR in () is the effect on TestScore of a unit change in STR, holding constant the percentage of English Learners in the district. Coefficient on STR falls by one-half. 95% confidence interval for coefficient on STR in () is [ ] = [ 1.95, 0.6].
23 Tests of Joint Hypotheses Let Expn = expenditures per pupil and consider the population regression model: TestScore i = STR i + Expn i + 3 PctEL i + u i. The null hypothesis that school resources don t matter, and the alternative that they do, corresponds to: H 0 : 1 = 0 and = 0 vs. H 1 : either 1 0 or 0 or both. 3
24 A joint hypothesis specifies a value for two or more coefficients, that is, it imposes a restriction on two or more coefficients. A common sense test is to reject if either of the individual t-statistics exceeds 1.96 in absolute value. But this common sense approach doesn t work! The resulting test doesn t have the right significance level! 4
25 Here s why: Calculation of the probability of incorrectly rejecting the null using the common sense test based on the two individual t-statistics. ˆ ˆ Suppose that 1 and are independently distributed. Let t 1 and t be the t-statistics: t 1 = ˆ 1 0 SE( ˆ ) 1 and t = ˆ 0 SE( ˆ ). The common sense test is: reject H 0 : 1 = = 0 if t 1 > 1.96 and/or t > 1.96 What is the probability that this common sense test rejects H 0, when H 0 is actually true? It should be 5%. 5
26 Probability of incorrectly rejecting the null = = = Pr H [ t 0 1 > 1.96 and/or t > 1.96] Pr H [ t 1 > 1.96, t > 1.96] Pr H [ t 1 > 1.96, t 1.96] 0 Pr H [ t , t > 1.96] 0 Pr H [ t 0 1 > 1.96] + Pr H [ t 1 > 1.96] + 0 Pr H [ t ] 0 Pr H [ t 0 > 1.96] Pr H [ t 1.96] 0 Pr H [ t > 1.96] 0 (disjoint events) (t 1, t are independent by assumption) = = = 9.75% which is not the desired 5%!! 6
27 The size of a test is the actual rejection rate under the null hypothesis. The size of the common sense test isn t 5%! Its size actually depends on the correlation between t 1 and t (and thus on the correlation between ˆ 1 and ˆ ). Two Solutions: Use a different critical value in this procedure not Use a different test statistic that test both 1 and at once: the F-statistic. 7
28 The F-statistic The F-statistic tests all parts of a joint hypothesis at once. Unpleasant formula for the special case of the joint hypothesis 1 = 1,0 and =,0 in a regression with two regressors: 1 t t ˆ t t 1 ˆ t 1, t 1 t, t 1 F = 1 where estimates the correlation between t 1 and t. ˆt, t 1 Reject when F is large. 8
29 The F-statistic testing 1 and (special case): 1 t t ˆ t 1 tt t F = 1 ˆ t 1, t 1, 1. The F-statistic is large when t 1 and/or t is large. The F-statistic corrects (in just the right way) for the correlation between t 1 and t. The formula for more than two s is really nasty unless you use matrix algebra. This gives the F-statistic a nice large-sample approximate distribution, which is 9
30 Large-sample distribution of the F-statistic Consider special case that t 1 and t are independent, so in large samples the formula becomes ˆt, t 1 p 0; 1 t t ˆ t t 1 ˆ t 1, t 1 t, t 1 F = 1 1 ( 1 ) t t. Under the null, t 1 and t have standard normal distributions that, in this special case, are independent. The large-sample distribution of the F-statistic is the distribution of the average of two independently distributed squared standard normal random variables. 30
31 In large samples, F is distributed as q /q. The chi-squared distribution with q degrees of freedom ( ) is defined to be the distribution of the sum of q independent squared standard normal random variables. q Selected large-sample critical values of q /q q 5% critical value (why?) 3.00 (the case q= above) p-value using the F-statistic: p-value = tail probability of the distribution beyond the F-statistic actually computed. q /q 31
32 Implementation in STATA Use the test command after the regression. Example: Test the joint hypothesis that the population coefficients on STR and expenditures per pupil (expn_stu) are both zero, against the alternative that at least one of the population coefficients is nonzero. 3
33 F-test example, California class size data: reg testscr str expn_stu pctel, r; Regression with robust standard errors Number of obs = 40 F( 3, 416) = Prob > F = R-squared = Root MSE = Robust testscr Coef. Std. Err. t P> t [95% Conf. Interval] str expn_stu pctel _cons NOTE test str expn_stu; The test command follows the regression ( 1) str = 0.0 There are q= restrictions being tested ( ) expn_stu = 0.0 F(, 416) = 5.43 The 5% critical value for q= is 3.00 Prob > F = Stata computes the p-value for you 33
34 Two (related) loose ends: 1. Homoskedasticity-only versions of the F-statistic.. The F distribution. The homoskedasticity-only ( rule-of-thumb ) F-statistic To compute the homoskedasticity-only F-statistic: Use the previous formulas, but using homoskedasticityonly standard errors; or Run two regressions, one under the null hypothesis (the restricted regression) and one under the alternative hypothesis (the unrestricted regression). The second method gives a simple formula. 34
35 The restricted and unrestricted regressions Example: are the coefficients on STR and Expn zero? Restricted population regression (that is, under H 0 ): TestScore i = PctEL i + u i (why?) Unrestricted population regression (under H 1 ): TestScore i = STR i + Expn i + 3 PctEL i + u i The number of restrictions under H 0 = q =. The fit will be better (R will be higher) in the unrestricted regression (why?). By how much must the R increase for the coefficients on Expn and PctEL to be judged statistically significant? 35
36 Simple formula for the homoskedasticityonly F-statistic: where: F = ( Runrestricted Rrestricted ) / q unrestricted unrestricted (1 R ) /( n k 1) R restricted = the R for the restricted regression R unrestricted = the R for the unrestricted regression q = the number of restrictions under the null k unrestricted = the number of regressors in the unrestricted regression 36
37 Example: Restricted regression: Testscore_est = PctEL, (1.0) (0.03) Unrestricted regression: R restricted = Testscore_est = STR Expn 0.656PctEL so: (15.5) (0.48) (1.59) (0.03) R unrestricted = , k unrestricted = 3, q = F = = ( Runrestricted Rrestricted ) / q unrestricted unrestricted (1 R ) /( n k 1) ( )/ (1.4366)/(40 3 1) =
38 The homoskedasticity-only F-statistic F = ( Runrestricted Rrestricted ) / q unrestricted unrestricted (1 R ) /( n k 1) The homoskedasticity-only F-statistic rejects when adding the two variables increased the R by enough that is, when adding the two variables improves the fit of the regression by enough. If the errors are homoskedastic, then the homoskedasticity-only F-statistic has a large-sample distribution that is q /q. But if the errors are heteroskedastic, the large-sample distribution is a mess and is not q /q. 38
39 The F distribution If: 1. u 1,,u n are normally distributed; and. X i is distributed independently of u i (so in particular u i is homoskedastic), then the homoskedasticity-only F-statistic has the F q,n-k 1 distribution, where q = the number of restrictions k = the number of regressors under the alternative (the unrestricted model). 39
40 The F q,n k 1 distribution: The F distribution is tabulated many places. When n gets large the F q,n-k 1 distribution asymptotes to the q /q distribution: F q, is another name for q /q. For q not too big and n 100, the F q,n k 1 distribution and the q /q distribution are essentially identical. Many regression packages compute p-values of F- statistics using the F distribution (which is OK if the sample size is 100. You will encounter the F-distribution in published empirical work. 40
41 Digression: A little history of statistics The theory of the homoskedasticity-only F-statistic and the F q,n k 1 distributions rests on implausibly strong assumptions (are earnings normally distributed?). These statistics dates to the early 0 th century, when computer was a job description and observations numbered in the dozens. The F-statistic and F q,n k 1 distribution were major breakthroughs: an easily computed formula; a single set of tables that could be published once, then applied in many settings; and a precise, mathematically elegant justification. 41
42 The strong assumptions seemed a minor price for this breakthrough. But with modern computers and large samples we can use the heteroskedasticity-robust F-statistic and the F q, distribution, which only require the four least squares assumptions. This historical legacy persists in modern software, in which homoskedasticity-only standard errors (and F- statistics) are the default, and in which p-values are computed using the F q,n k 1 distribution. 4
43 Summary: Homoskedasticity-only F-stat and the F distribution are justified only under very strong conditions stronger than are realistic in practice: Yet, they are widely used. You should use the heteroskedasticity-robust F-statistic, with q /q (that is, F q, ) critical values. For n 100, the F-distribution essentially is the distribution. q /q For small n, the F distribution isn t necessarily a better approximation to the sampling distribution of the F- statistic only if the strong conditions are true. 43
44 Summary: testing joint hypotheses The common-sense approach of rejecting if either of the t-statistics exceeds 1.96 rejects more than 5% of the time under the null, the size exceeds the desired significance level. The heteroskedasticity-robust F-statistic is built in to STATA ( test command); this tests all q restrictions at once. For n large, F is distributed as q /q (= F q, ). The homoskedasticity-only F-statistic is important historically (and thus in practice), and is intuitively appealing, but invalid when there is heteroscedasticity. 44
45 Testing Single Restrictions on Multiple Coefficients Y i = X 1i + X i + u i, i = 1,,n Consider the null and alternative hypothesis, H 0 : 1 = vs. H 1 : 1 This null imposes a single restriction (q = 1) on multiple coefficients it is not a joint hypothesis with multiple restrictions (compare with 1 = 0 and = 0). 45
46 Two methods: 1. Rearrange ( transform ) the regression Rearrange the regressors so that the restriction becomes a restriction on a single coefficient in an equivalent regression.. Perform the test directly Some software, including STATA, lets you test restrictions using multiple coefficients directly. 46
47 Method 1: Rearrange ( transform ) the regression Original system: Y i = X 1i + X i + u i H 0 : 1 = vs. H 1 : 1 Add and subtract X 1i : Y i = 0 + ( 1 ) X 1i + (X 1i + X i ) + u i or, Y i = X 1i + W i + u i where 1 = 1 and W i = X 1i + X i. Rearranged ( transformed ) system: Y i = X 1i + W i + u i H 0 : 1 = 0 vs. H 1 : 1 0 The testing problem is now a simple one: test whether 1 = 0 in the rearranged specification. 47
48 Method : Perform the test directly Y i = X 1i + X i + u i H 0 : 1 = vs. H 1 : 1 Example: TestScore i = STR i + Expn i + 3 PctEL i + u i To test, using STATA, whether 1 = : regress testscore str expn pctel, r test str=expn 48
49 Confidence Sets for Multiple Coefficients Y i = X 1i + X i + + k X ki + u i, i = 1,,n What is a joint confidence set for 1 and? A 95% confidence set is: A set-valued function of the data that contains the true parameter(s) in 95% of hypothetical repeated samples. The set of parameter values that cannot be rejected at the 5% significance level when taken as the null hypothesis. The coverage rate of a confidence set is the probability that the confidence set contains the true parameter values. 49
50 A common sense confidence set is the union of the 95% confidence intervals for 1 and, that is, the rectangle: [ ˆ SE( ˆ 1 ), ˆ 1.96 SE( ˆ )] What is the coverage rate of this confidence set? Des its coverage rate equal the desired confidence level of 95%? 50
51 Coverage rate of common sense confidence set: Pr[( 1, ) [ ˆ SE( ˆ 1 ), ˆ 1.96 SE( ˆ )]] = Pr[ ˆ SE( ˆ 1 ) 1 ˆ SE( ˆ 1 ), ˆ 1.96SE( ˆ ) ˆ SE( ˆ )] ˆ ˆ = Pr[ ˆ , ] SE( ) SE( ˆ ) = Pr[ t and t 1.96] 1 = 1 Pr[ t 1 > 1.96 and/or t > 1.96] 95%! Why? This confidence set inverts a test for which the size doesn t equal the significance level! 51
52 Recall: the probability of incorrectly rejecting the null = Pr H [ t 0 1 > 1.96 and/or t > 1.96] = Pr H [ t 0 1 > 1.96, t > 1.96] + Pr H [ t 0 1 > 1.96, t 1.96] + Pr H [ t , t > 1.96] (disjoint events) = Pr H [ t 0 1 > 1.96] Pr H [ t 0 > 1.96] + Pr H [ t 0 1 > 1.96] Pr H [ t ] + Pr H [ t ] Pr H [ t 0 > 1.96] = (if t 1, t are independent) = = 9.75% which is not the desired 5%!! 5
53 The confidence set based on the F-statistic Instead, use the acceptance region of a test that has size equal to its significance level ( invert a valid test). Let F( 1,0,,0 ) be the (heteroskedasticity-robust) F-statistic testing the hypothesis that 1 = 1, 0 and =,0 : 95% confidence set = [ 1,0,,0 : F( 1,0,,0 ) < 3.00] is the 5% critical value of the F, distribution. This set has coverage rate 95% because the test on which it is based (the test it inverts ) has size of 5%. 53
54 The confidence set based on the F-statistic is an ellipse F = 1 (1 ˆ ) 1 t t ˆ t 1 tt t [ 1, : F = 1 ˆ t 1, t t, t 1 1 (1 ˆ ) t, t 1 t t ˆ t t 1 1, 1 1 t, t ] ˆ ˆ,0 1 ˆ ˆ 1,0 1 1,0,0 ˆt 1, t ˆ ˆ SE( ˆ ˆ ) SE( 1) SE( 1) SE( ) This is a quadratic form in 1,0 and,0 thus the boundary of the set F = 3.00 is an ellipse. 54

55 Confidence set based on inverting the F-statistic 55
56 The R, SER, and R for Multiple Regression Actual = predicted + residual: Y i = Y ˆi + u ˆi As in regression with a single regressor, the SER (and the RMSE) is a measure of the spread of the Y s around the regression line: SER = 1 n uˆ i 1. i 1 n k 56
57 The R is the fraction of the variance explained: where ESS = R = ESS TSS = 1 n ˆ ˆ ( Yi Y), SSR = i1 just as for regression with one regressor. SSR TSS, n uˆ i, and TSS = i1 n ( Yi Y), i1 The R always increases when you add another regressor a bit of a problem for a measure of fit. The R corrects this problem by penalizing you for including another regressor: R = 1 n 1 SSR n k 1TSS so R < R. 57
58 How to interpret the R and R? A high R (or R ) means that the regressors explain the variation in Y. A high R (or omitted variable bias. R ) does not mean that you have eliminated A high R (or R ) does not mean that you have an unbiased estimator of a causal effect ( 1 ). A high R (or R ) does not mean that the included variables are statistically significant this must be determined using hypotheses tests. 58
59 Example: A Closer Look at the Test Score Data A general approach to variable selection and model specification: Specify a base or benchmark model. Specify a range of plausible alternative models, which include additional candidate variables. Does a candidate variable change the coefficient of interest ( 1 )? Is a candidate variable statistically significant? Use judgment, not a mechanical recipe 59
60 Variables we would like to see in the California data set: School characteristics: student-teacher ratio teacher quality computers (non-teaching resources) per student measures of curriculum design Student characteristics: English proficiency availability of extracurricular enrichment home learning environment parent s education level Variables actually in the California class size data set: student-teacher ratio (STR) percent English learners in the district (PctEL) percent eligible for subsidized/free lunch percent on public income assistance average district income 60
61 A look at more of the California data 61
62 Digression: presentation of regression results in a table Listing regressions in equation form can be cumbersome with many regressors and many regressions. Tables of regression results can present the key information compactly. Information to include: variables in the regression (dependent and independent) estimated coefficients standard errors results of F-tests of pertinent joint hypotheses some measure of fit number of observations. 6
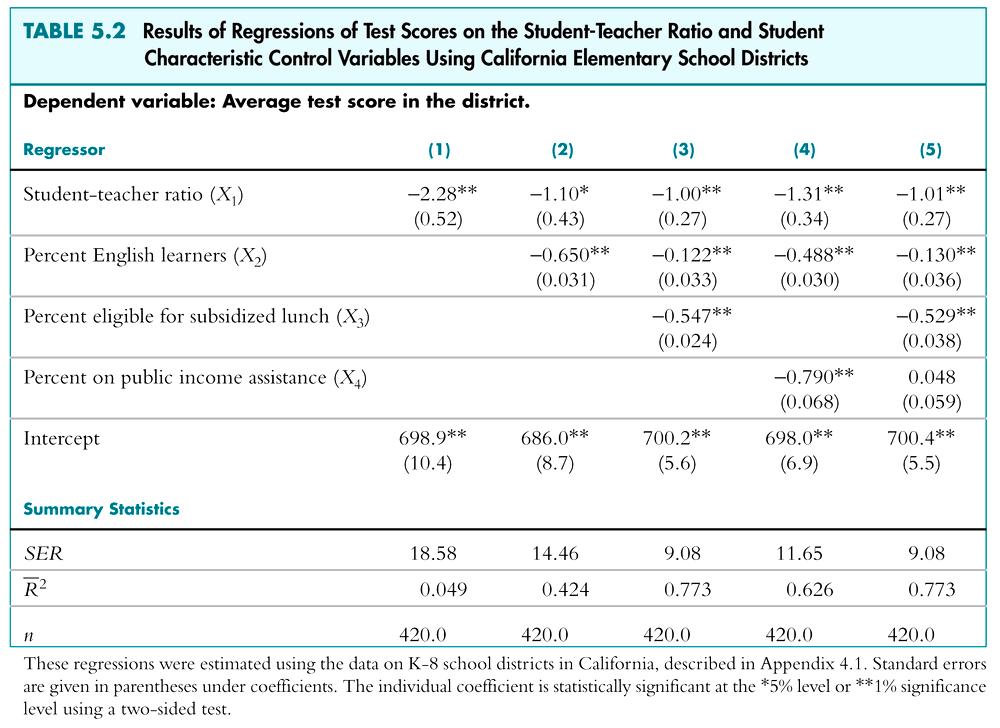
63 63
64 Summary: Multiple Regression Multiple regression allows you to estimate the effect on Y of a change in X1, holding X constant. If you can measure a variable, you can avoid omitted variable bias from that variable by including it. There is no simple recipe for deciding which variables belong in a regression you must exercise judgment. One approach is to specify a base model relying on a- priori reasoning then to explore the sensitivity of the key estimate(s) in alternative specifications. 64
Introduction to Econometrics. Multiple Regression
 Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Multiple Regression Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 OLS estimate of the TS/STR
Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Multiple Regression Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 OLS estimate of the TS/STR
Chapter 7. Hypothesis Tests and Confidence Intervals in Multiple Regression
 Chapter 7 Hypothesis Tests and Confidence Intervals in Multiple Regression Outline 1. Hypothesis tests and confidence intervals for a single coefficie. Joint hypothesis tests on multiple coefficients 3.
Chapter 7 Hypothesis Tests and Confidence Intervals in Multiple Regression Outline 1. Hypothesis tests and confidence intervals for a single coefficie. Joint hypothesis tests on multiple coefficients 3.
The F distribution. If: 1. u 1,,u n are normally distributed; and 2. X i is distributed independently of u i (so in particular u i is homoskedastic)
") The F distribution If: 1. u 1,,u n are normally distributed; and. X i is distributed independently of u i (so in particular u i is homoskedastic) then the homoskedasticity-only F-statistic has the F q,n-k
The F distribution If: 1. u 1,,u n are normally distributed; and. X i is distributed independently of u i (so in particular u i is homoskedastic) then the homoskedasticity-only F-statistic has the F q,n-k
Hypothesis Tests and Confidence Intervals in Multiple Regression
 Hypothesis Tests and Confidence Intervals in Multiple Regression (SW Chapter 7) Outline 1. Hypothesis tests and confidence intervals for one coefficient. Joint hypothesis tests on multiple coefficients
Hypothesis Tests and Confidence Intervals in Multiple Regression (SW Chapter 7) Outline 1. Hypothesis tests and confidence intervals for one coefficient. Joint hypothesis tests on multiple coefficients
Linear Regression with Multiple Regressors
 Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Hypothesis Tests and Confidence Intervals. in Multiple Regression
 ECON4135, LN6 Hypothesis Tests and Confidence Intervals Outline 1. Why multipple regression? in Multiple Regression (SW Chapter 7) 2. Simpson s paradox (omitted variables bias) 3. Hypothesis tests and
ECON4135, LN6 Hypothesis Tests and Confidence Intervals Outline 1. Why multipple regression? in Multiple Regression (SW Chapter 7) 2. Simpson s paradox (omitted variables bias) 3. Hypothesis tests and
Linear Regression with Multiple Regressors
 Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 6 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 53 Outline of Lecture 6 1 Omitted variable bias (SW 6.1) 2 Multiple
Applied Statistics and Econometrics Lecture 6 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 53 Outline of Lecture 6 1 Omitted variable bias (SW 6.1) 2 Multiple
Chapter 6: Linear Regression With Multiple Regressors
 Chapter 6: Linear Regression With Multiple Regressors 1-1 Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Chapter 6: Linear Regression With Multiple Regressors 1-1 Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 7 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 68 Outline of Lecture 7 1 Empirical example: Italian labor force
Applied Statistics and Econometrics Lecture 7 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 68 Outline of Lecture 7 1 Empirical example: Italian labor force
ECON Introductory Econometrics. Lecture 7: OLS with Multiple Regressors Hypotheses tests
 ECON4150 - Introductory Econometrics Lecture 7: OLS with Multiple Regressors Hypotheses tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 7 Lecture outline 2 Hypothesis test for single
ECON4150 - Introductory Econometrics Lecture 7: OLS with Multiple Regressors Hypotheses tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 7 Lecture outline 2 Hypothesis test for single
Regression with a Single Regressor: Hypothesis Tests and Confidence Intervals
 Regression with a Single Regressor: Hypothesis Tests and Confidence Intervals (SW Chapter 5) Outline. The standard error of ˆ. Hypothesis tests concerning β 3. Confidence intervals for β 4. Regression
Regression with a Single Regressor: Hypothesis Tests and Confidence Intervals (SW Chapter 5) Outline. The standard error of ˆ. Hypothesis tests concerning β 3. Confidence intervals for β 4. Regression
Nonlinear Regression Functions
 Nonlinear Regression Functions (SW Chapter 8) Outline 1. Nonlinear regression functions general comments 2. Nonlinear functions of one variable 3. Nonlinear functions of two variables: interactions 4.
Nonlinear Regression Functions (SW Chapter 8) Outline 1. Nonlinear regression functions general comments 2. Nonlinear functions of one variable 3. Nonlinear functions of two variables: interactions 4.
Lecture 5. In the last lecture, we covered. This lecture introduces you to
 Lecture 5 In the last lecture, we covered. homework 2. The linear regression model (4.) 3. Estimating the coefficients (4.2) This lecture introduces you to. Measures of Fit (4.3) 2. The Least Square Assumptions
Lecture 5 In the last lecture, we covered. homework 2. The linear regression model (4.) 3. Estimating the coefficients (4.2) This lecture introduces you to. Measures of Fit (4.3) 2. The Least Square Assumptions
Recall that a measure of fit is the sum of squared residuals: where. The F-test statistic may be written as:
 1 Joint hypotheses The null and alternative hypotheses can usually be interpreted as a restricted model ( ) and an model ( ). In our example: Note that if the model fits significantly better than the restricted
1 Joint hypotheses The null and alternative hypotheses can usually be interpreted as a restricted model ( ) and an model ( ). In our example: Note that if the model fits significantly better than the restricted
Introduction to Econometrics Third Edition James H. Stock Mark W. Watson The statistical analysis of economic (and related) data
 data") Introduction to Econometrics Third Edition James H. Stock Mark W. Watson The statistical analysis of economic (and related) data 1/2/3-1 1/2/3-2 Brief Overview of the Course Economics suggests important
Introduction to Econometrics Third Edition James H. Stock Mark W. Watson The statistical analysis of economic (and related) data 1/2/3-1 1/2/3-2 Brief Overview of the Course Economics suggests important
2. Linear regression with multiple regressors
 2. Linear regression with multiple regressors Aim of this section: Introduction of the multiple regression model OLS estimation in multiple regression Measures-of-fit in multiple regression Assumptions
2. Linear regression with multiple regressors Aim of this section: Introduction of the multiple regression model OLS estimation in multiple regression Measures-of-fit in multiple regression Assumptions
Econometrics Midterm Examination Answers
 Econometrics Midterm Examination Answers March 4, 204. Question (35 points) Answer the following short questions. (i) De ne what is an unbiased estimator. Show that X is an unbiased estimator for E(X i
Econometrics Midterm Examination Answers March 4, 204. Question (35 points) Answer the following short questions. (i) De ne what is an unbiased estimator. Show that X is an unbiased estimator for E(X i
ECON Introductory Econometrics. Lecture 6: OLS with Multiple Regressors
 ECON4150 - Introductory Econometrics Lecture 6: OLS with Multiple Regressors Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 6 Lecture outline 2 Violation of first Least Squares assumption
ECON4150 - Introductory Econometrics Lecture 6: OLS with Multiple Regressors Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 6 Lecture outline 2 Violation of first Least Squares assumption
ECON Introductory Econometrics. Lecture 5: OLS with One Regressor: Hypothesis Tests
 ECON4150 - Introductory Econometrics Lecture 5: OLS with One Regressor: Hypothesis Tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 5 Lecture outline 2 Testing Hypotheses about one
ECON4150 - Introductory Econometrics Lecture 5: OLS with One Regressor: Hypothesis Tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 5 Lecture outline 2 Testing Hypotheses about one
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 13 Nonlinearities Saul Lach October 2018 Saul Lach () Applied Statistics and Econometrics October 2018 1 / 91 Outline of Lecture 13 1 Nonlinear regression functions
Applied Statistics and Econometrics Lecture 13 Nonlinearities Saul Lach October 2018 Saul Lach () Applied Statistics and Econometrics October 2018 1 / 91 Outline of Lecture 13 1 Nonlinear regression functions
Introduction to Econometrics. Review of Probability & Statistics
 1 Introduction to Econometrics Review of Probability & Statistics Peerapat Wongchaiwat, Ph.D. wongchaiwat@hotmail.com Introduction 2 What is Econometrics? Econometrics consists of the application of mathematical
1 Introduction to Econometrics Review of Probability & Statistics Peerapat Wongchaiwat, Ph.D. wongchaiwat@hotmail.com Introduction 2 What is Econometrics? Econometrics consists of the application of mathematical
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 5 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 44 Outline of Lecture 5 Now that we know the sampling distribution
Applied Statistics and Econometrics Lecture 5 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 44 Outline of Lecture 5 Now that we know the sampling distribution
Multiple Regression Analysis: Estimation. Simple linear regression model: an intercept and one explanatory variable (regressor)
") 1 Multiple Regression Analysis: Estimation Simple linear regression model: an intercept and one explanatory variable (regressor) Y i = β 0 + β 1 X i + u i, i = 1,2,, n Multiple linear regression model:
1 Multiple Regression Analysis: Estimation Simple linear regression model: an intercept and one explanatory variable (regressor) Y i = β 0 + β 1 X i + u i, i = 1,2,, n Multiple linear regression model:
Linear Regression with 1 Regressor. Introduction to Econometrics Spring 2012 Ken Simons
 Linear Regression with 1 Regressor Introduction to Econometrics Spring 2012 Ken Simons Linear Regression with 1 Regressor 1. The regression equation 2. Estimating the equation 3. Assumptions required for
Linear Regression with 1 Regressor Introduction to Econometrics Spring 2012 Ken Simons Linear Regression with 1 Regressor 1. The regression equation 2. Estimating the equation 3. Assumptions required for
Introduction to Econometrics
 Introduction to Econometrics STAT-S-301 Panel Data (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Regression with Panel Data A panel dataset contains observations on multiple entities
Introduction to Econometrics STAT-S-301 Panel Data (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Regression with Panel Data A panel dataset contains observations on multiple entities
Review of Econometrics
 Review of Econometrics Zheng Tian June 5th, 2017 1 The Essence of the OLS Estimation Multiple regression model involves the models as follows Y i = β 0 + β 1 X 1i + β 2 X 2i + + β k X ki + u i, i = 1,...,
Review of Econometrics Zheng Tian June 5th, 2017 1 The Essence of the OLS Estimation Multiple regression model involves the models as follows Y i = β 0 + β 1 X 1i + β 2 X 2i + + β k X ki + u i, i = 1,...,
The Simple Linear Regression Model
 The Simple Linear Regression Model Lesson 3 Ryan Safner 1 1 Department of Economics Hood College ECON 480 - Econometrics Fall 2017 Ryan Safner (Hood College) ECON 480 - Lesson 3 Fall 2017 1 / 77 Bivariate
The Simple Linear Regression Model Lesson 3 Ryan Safner 1 1 Department of Economics Hood College ECON 480 - Econometrics Fall 2017 Ryan Safner (Hood College) ECON 480 - Lesson 3 Fall 2017 1 / 77 Bivariate
Contest Quiz 3. Question Sheet. In this quiz we will review concepts of linear regression covered in lecture 2.
 Updated: November 17, 2011 Lecturer: Thilo Klein Contact: tk375@cam.ac.uk Contest Quiz 3 Question Sheet In this quiz we will review concepts of linear regression covered in lecture 2. NOTE: Please round
Updated: November 17, 2011 Lecturer: Thilo Klein Contact: tk375@cam.ac.uk Contest Quiz 3 Question Sheet In this quiz we will review concepts of linear regression covered in lecture 2. NOTE: Please round
ECO321: Economic Statistics II
 ECO321: Economic Statistics II Chapter 6: Linear Regression a Hiroshi Morita hmorita@hunter.cuny.edu Department of Economics Hunter College, The City University of New York a c 2010 by Hiroshi Morita.
ECO321: Economic Statistics II Chapter 6: Linear Regression a Hiroshi Morita hmorita@hunter.cuny.edu Department of Economics Hunter College, The City University of New York a c 2010 by Hiroshi Morita.
Econometrics I KS. Module 2: Multivariate Linear Regression. Alexander Ahammer. This version: April 16, 2018
 Econometrics I KS Module 2: Multivariate Linear Regression Alexander Ahammer Department of Economics Johannes Kepler University of Linz This version: April 16, 2018 Alexander Ahammer (JKU) Module 2: Multivariate
Econometrics I KS Module 2: Multivariate Linear Regression Alexander Ahammer Department of Economics Johannes Kepler University of Linz This version: April 16, 2018 Alexander Ahammer (JKU) Module 2: Multivariate
Essential of Simple regression
 Essential of Simple regression We use simple regression when we are interested in the relationship between two variables (e.g., x is class size, and y is student s GPA). For simplicity we assume the relationship
Essential of Simple regression We use simple regression when we are interested in the relationship between two variables (e.g., x is class size, and y is student s GPA). For simplicity we assume the relationship
Econometrics 1. Lecture 8: Linear Regression (2) 黄嘉平
 黄嘉平") Econometrics 1 Lecture 8: Linear Regression (2) 黄嘉平 中国经济特区研究中 心讲师 办公室 : 文科楼 1726 E-mail: huangjp@szu.edu.cn Tel: (0755) 2695 0548 Office hour: Mon./Tue. 13:00-14:00 The linear regression model The linear
Econometrics 1 Lecture 8: Linear Regression (2) 黄嘉平 中国经济特区研究中 心讲师 办公室 : 文科楼 1726 E-mail: huangjp@szu.edu.cn Tel: (0755) 2695 0548 Office hour: Mon./Tue. 13:00-14:00 The linear regression model The linear
Assessing Studies Based on Multiple Regression
 Assessing Studies Based on Multiple Regression Outline 1. Internal and External Validity 2. Threats to Internal Validity a. Omitted variable bias b. Functional form misspecification c. Errors-in-variables
Assessing Studies Based on Multiple Regression Outline 1. Internal and External Validity 2. Threats to Internal Validity a. Omitted variable bias b. Functional form misspecification c. Errors-in-variables
ECON3150/4150 Spring 2015
 ECON3150/4150 Spring 2015 Lecture 3&4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo January 29, 2015 1 / 67 Chapter 4 in S&W Section 17.1 in S&W (extended OLS assumptions) 2
ECON3150/4150 Spring 2015 Lecture 3&4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo January 29, 2015 1 / 67 Chapter 4 in S&W Section 17.1 in S&W (extended OLS assumptions) 2
Multiple Regression Analysis
 Multiple Regression Analysis y = β 0 + β 1 x 1 + β 2 x 2 +... β k x k + u 2. Inference 0 Assumptions of the Classical Linear Model (CLM)! So far, we know: 1. The mean and variance of the OLS estimators
Multiple Regression Analysis y = β 0 + β 1 x 1 + β 2 x 2 +... β k x k + u 2. Inference 0 Assumptions of the Classical Linear Model (CLM)! So far, we know: 1. The mean and variance of the OLS estimators
ECO220Y Simple Regression: Testing the Slope
 ECO220Y Simple Regression: Testing the Slope Readings: Chapter 18 (Sections 18.3-18.5) Winter 2012 Lecture 19 (Winter 2012) Simple Regression Lecture 19 1 / 32 Simple Regression Model y i = β 0 + β 1 x
ECO220Y Simple Regression: Testing the Slope Readings: Chapter 18 (Sections 18.3-18.5) Winter 2012 Lecture 19 (Winter 2012) Simple Regression Lecture 19 1 / 32 Simple Regression Model y i = β 0 + β 1 x
ECON Introductory Econometrics. Lecture 17: Experiments
 ECON4150 - Introductory Econometrics Lecture 17: Experiments Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 13 Lecture outline 2 Why study experiments? The potential outcome framework.
ECON4150 - Introductory Econometrics Lecture 17: Experiments Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 13 Lecture outline 2 Why study experiments? The potential outcome framework.
Introduction to Econometrics
 Introduction to Econometrics STAT-S-301 Introduction to Time Series Regression and Forecasting (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Introduction to Time Series Regression
Introduction to Econometrics STAT-S-301 Introduction to Time Series Regression and Forecasting (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Introduction to Time Series Regression
ECON3150/4150 Spring 2016
 ECON3150/4150 Spring 2016 Lecture 4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo Last updated: January 26, 2016 1 / 49 Overview These lecture slides covers: The linear regression
ECON3150/4150 Spring 2016 Lecture 4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo Last updated: January 26, 2016 1 / 49 Overview These lecture slides covers: The linear regression
ECON Introductory Econometrics. Lecture 16: Instrumental variables
 ECON4150 - Introductory Econometrics Lecture 16: Instrumental variables Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 12 Lecture outline 2 OLS assumptions and when they are violated Instrumental
ECON4150 - Introductory Econometrics Lecture 16: Instrumental variables Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 12 Lecture outline 2 OLS assumptions and when they are violated Instrumental
Introduction to Econometrics. Regression with Panel Data
 Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Regression with Panel Data Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 Regression with Panel
Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Regression with Panel Data Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 Regression with Panel
2) For a normal distribution, the skewness and kurtosis measures are as follows: A) 1.96 and 4 B) 1 and 2 C) 0 and 3 D) 0 and 0
 For a normal distribution, the skewness and kurtosis measures are as follows: A) 1.96 and 4 B) 1 and 2 C) 0 and 3 D) 0 and 0") Introduction to Econometrics Midterm April 26, 2011 Name Student ID MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. (5,000 credit for each correct
Introduction to Econometrics Midterm April 26, 2011 Name Student ID MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. (5,000 credit for each correct
Econometrics -- Final Exam (Sample)
") Econometrics -- Final Exam (Sample) 1) The sample regression line estimated by OLS A) has an intercept that is equal to zero. B) is the same as the population regression line. C) cannot have negative and
Econometrics -- Final Exam (Sample) 1) The sample regression line estimated by OLS A) has an intercept that is equal to zero. B) is the same as the population regression line. C) cannot have negative and
Motivation for multiple regression
 Motivation for multiple regression 1. Simple regression puts all factors other than X in u, and treats them as unobserved. Effectively the simple regression does not account for other factors. 2. The slope
Motivation for multiple regression 1. Simple regression puts all factors other than X in u, and treats them as unobserved. Effectively the simple regression does not account for other factors. 2. The slope
THE MULTIVARIATE LINEAR REGRESSION MODEL
 THE MULTIVARIATE LINEAR REGRESSION MODEL Why multiple regression analysis? Model with more than 1 independent variable: y 0 1x1 2x2 u It allows : -Controlling for other factors, and get a ceteris paribus
THE MULTIVARIATE LINEAR REGRESSION MODEL Why multiple regression analysis? Model with more than 1 independent variable: y 0 1x1 2x2 u It allows : -Controlling for other factors, and get a ceteris paribus
Multivariate Regression: Part I
 Topic 1 Multivariate Regression: Part I ARE/ECN 240 A Graduate Econometrics Professor: Òscar Jordà Outline of this topic Statement of the objective: we want to explain the behavior of one variable as a
Topic 1 Multivariate Regression: Part I ARE/ECN 240 A Graduate Econometrics Professor: Òscar Jordà Outline of this topic Statement of the objective: we want to explain the behavior of one variable as a
Statistical Inference with Regression Analysis
 Introductory Applied Econometrics EEP/IAS 118 Spring 2015 Steven Buck Lecture #13 Statistical Inference with Regression Analysis Next we turn to calculating confidence intervals and hypothesis testing
Introductory Applied Econometrics EEP/IAS 118 Spring 2015 Steven Buck Lecture #13 Statistical Inference with Regression Analysis Next we turn to calculating confidence intervals and hypothesis testing
Introduction to Econometrics. Assessing Studies Based on Multiple Regression
 Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Assessing Studies Based on Multiple Regression Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1
Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Assessing Studies Based on Multiple Regression Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1
Introduction to Econometrics
 Introduction to Econometrics STAT-S-301 Experiments and Quasi-Experiments (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Why study experiments? Ideal randomized controlled experiments
Introduction to Econometrics STAT-S-301 Experiments and Quasi-Experiments (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Why study experiments? Ideal randomized controlled experiments
Chapter 11. Regression with a Binary Dependent Variable
 Chapter 11 Regression with a Binary Dependent Variable 2 Regression with a Binary Dependent Variable (SW Chapter 11) So far the dependent variable (Y) has been continuous: district-wide average test score
Chapter 11 Regression with a Binary Dependent Variable 2 Regression with a Binary Dependent Variable (SW Chapter 11) So far the dependent variable (Y) has been continuous: district-wide average test score
6. Assessing studies based on multiple regression
 6. Assessing studies based on multiple regression Questions of this section: What makes a study using multiple regression (un)reliable? When does multiple regression provide a useful estimate of the causal
6. Assessing studies based on multiple regression Questions of this section: What makes a study using multiple regression (un)reliable? When does multiple regression provide a useful estimate of the causal
WISE MA/PhD Programs Econometrics Instructor: Brett Graham Spring Semester, Academic Year Exam Version: A
 WISE MA/PhD Programs Econometrics Instructor: Brett Graham Spring Semester, 2016-17 Academic Year Exam Version: A INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This
WISE MA/PhD Programs Econometrics Instructor: Brett Graham Spring Semester, 2016-17 Academic Year Exam Version: A INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This
ECON Introductory Econometrics. Lecture 4: Linear Regression with One Regressor
 ECON4150 - Introductory Econometrics Lecture 4: Linear Regression with One Regressor Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 4 Lecture outline 2 The OLS estimators The effect of
ECON4150 - Introductory Econometrics Lecture 4: Linear Regression with One Regressor Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 4 Lecture outline 2 The OLS estimators The effect of
Empirical Application of Simple Regression (Chapter 2)
") Empirical Application of Simple Regression (Chapter 2) 1. The data file is House Data, which can be downloaded from my webpage. 2. Use stata menu File Import Excel Spreadsheet to read the data. Don t forget
Empirical Application of Simple Regression (Chapter 2) 1. The data file is House Data, which can be downloaded from my webpage. 2. Use stata menu File Import Excel Spreadsheet to read the data. Don t forget
Final Exam. Question 1 (20 points) 2 (25 points) 3 (30 points) 4 (25 points) 5 (10 points) 6 (40 points) Total (150 points) Bonus question (10)
 2 (25 points) 3 (30 points) 4 (25 points) 5 (10 points) 6 (40 points) Total (150 points) Bonus question (10)") Name Economics 170 Spring 2004 Honor pledge: I have neither given nor received aid on this exam including the preparation of my one page formula list and the preparation of the Stata assignment for the
Name Economics 170 Spring 2004 Honor pledge: I have neither given nor received aid on this exam including the preparation of my one page formula list and the preparation of the Stata assignment for the
Lecture #8 & #9 Multiple regression
 Lecture #8 & #9 Multiple regression Starting point: Y = f(x 1, X 2,, X k, u) Outcome variable of interest (movie ticket price) a function of several variables. Observables and unobservables. One or more
Lecture #8 & #9 Multiple regression Starting point: Y = f(x 1, X 2,, X k, u) Outcome variable of interest (movie ticket price) a function of several variables. Observables and unobservables. One or more
WISE MA/PhD Programs Econometrics Instructor: Brett Graham Spring Semester, Academic Year Exam Version: A
 WISE MA/PhD Programs Econometrics Instructor: Brett Graham Spring Semester, 2016-17 Academic Year Exam Version: A INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This
WISE MA/PhD Programs Econometrics Instructor: Brett Graham Spring Semester, 2016-17 Academic Year Exam Version: A INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This
8. Instrumental variables regression
 8. Instrumental variables regression Recall: In Section 5 we analyzed five sources of estimation bias arising because the regressor is correlated with the error term Violation of the first OLS assumption
8. Instrumental variables regression Recall: In Section 5 we analyzed five sources of estimation bias arising because the regressor is correlated with the error term Violation of the first OLS assumption
Exam ECON3150/4150: Introductory Econometrics. 18 May 2016; 09:00h-12.00h.
 Exam ECON3150/4150: Introductory Econometrics. 18 May 2016; 09:00h-12.00h. This is an open book examination where all printed and written resources, in addition to a calculator, are allowed. If you are
Exam ECON3150/4150: Introductory Econometrics. 18 May 2016; 09:00h-12.00h. This is an open book examination where all printed and written resources, in addition to a calculator, are allowed. If you are
Chapter 9: Assessing Studies Based on Multiple Regression. Copyright 2011 Pearson Addison-Wesley. All rights reserved.
 Chapter 9: Assessing Studies Based on Multiple Regression 1-1 9-1 Outline 1. Internal and External Validity 2. Threats to Internal Validity a) Omitted variable bias b) Functional form misspecification
Chapter 9: Assessing Studies Based on Multiple Regression 1-1 9-1 Outline 1. Internal and External Validity 2. Threats to Internal Validity a) Omitted variable bias b) Functional form misspecification
1: a b c d e 2: a b c d e 3: a b c d e 4: a b c d e 5: a b c d e. 6: a b c d e 7: a b c d e 8: a b c d e 9: a b c d e 10: a b c d e
 Economics 102: Analysis of Economic Data Cameron Spring 2016 Department of Economics, U.C.-Davis Final Exam (A) Tuesday June 7 Compulsory. Closed book. Total of 58 points and worth 45% of course grade.
Economics 102: Analysis of Economic Data Cameron Spring 2016 Department of Economics, U.C.-Davis Final Exam (A) Tuesday June 7 Compulsory. Closed book. Total of 58 points and worth 45% of course grade.
ECON2228 Notes 2. Christopher F Baum. Boston College Economics. cfb (BC Econ) ECON2228 Notes / 47
 ECON2228 Notes / 47") ECON2228 Notes 2 Christopher F Baum Boston College Economics 2014 2015 cfb (BC Econ) ECON2228 Notes 2 2014 2015 1 / 47 Chapter 2: The simple regression model Most of this course will be concerned with
ECON2228 Notes 2 Christopher F Baum Boston College Economics 2014 2015 cfb (BC Econ) ECON2228 Notes 2 2014 2015 1 / 47 Chapter 2: The simple regression model Most of this course will be concerned with
Multiple Linear Regression CIVL 7012/8012
 Multiple Linear Regression CIVL 7012/8012 2 Multiple Regression Analysis (MLR) Allows us to explicitly control for many factors those simultaneously affect the dependent variable This is important for
Multiple Linear Regression CIVL 7012/8012 2 Multiple Regression Analysis (MLR) Allows us to explicitly control for many factors those simultaneously affect the dependent variable This is important for
Business Statistics. Lecture 10: Course Review
 Business Statistics Lecture 10: Course Review 1 Descriptive Statistics for Continuous Data Numerical Summaries Location: mean, median Spread or variability: variance, standard deviation, range, percentiles,
Business Statistics Lecture 10: Course Review 1 Descriptive Statistics for Continuous Data Numerical Summaries Location: mean, median Spread or variability: variance, standard deviation, range, percentiles,
Lab 11 - Heteroskedasticity
 Lab 11 - Heteroskedasticity Spring 2017 Contents 1 Introduction 2 2 Heteroskedasticity 2 3 Addressing heteroskedasticity in Stata 3 4 Testing for heteroskedasticity 4 5 A simple example 5 1 1 Introduction
Lab 11 - Heteroskedasticity Spring 2017 Contents 1 Introduction 2 2 Heteroskedasticity 2 3 Addressing heteroskedasticity in Stata 3 4 Testing for heteroskedasticity 4 5 A simple example 5 1 1 Introduction
P1.T2. Stock & Watson Chapters 4 & 5. Bionic Turtle FRM Video Tutorials. By: David Harper CFA, FRM, CIPM
 P1.T2. Stock & Watson Chapters 4 & 5 Bionic Turtle FRM Video Tutorials By: David Harper CFA, FRM, CIPM Note: This tutorial is for paid members only. You know who you are. Anybody else is using an illegal
P1.T2. Stock & Watson Chapters 4 & 5 Bionic Turtle FRM Video Tutorials By: David Harper CFA, FRM, CIPM Note: This tutorial is for paid members only. You know who you are. Anybody else is using an illegal
Multiple Regression. Midterm results: AVG = 26.5 (88%) A = 27+ B = C =
 A = 27+ B = C =") Economics 130 Lecture 6 Midterm Review Next Steps for the Class Multiple Regression Review & Issues Model Specification Issues Launching the Projects!!!!! Midterm results: AVG = 26.5 (88%) A = 27+ B =
Economics 130 Lecture 6 Midterm Review Next Steps for the Class Multiple Regression Review & Issues Model Specification Issues Launching the Projects!!!!! Midterm results: AVG = 26.5 (88%) A = 27+ B =
Review of Statistics 101
 Review of Statistics 101 We review some important themes from the course 1. Introduction Statistics- Set of methods for collecting/analyzing data (the art and science of learning from data). Provides methods
Review of Statistics 101 We review some important themes from the course 1. Introduction Statistics- Set of methods for collecting/analyzing data (the art and science of learning from data). Provides methods
WISE International Masters
 WISE International Masters ECONOMETRICS Instructor: Brett Graham INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This examination paper contains 32 questions. You are
WISE International Masters ECONOMETRICS Instructor: Brett Graham INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This examination paper contains 32 questions. You are
(a) Briefly discuss the advantage of using panel data in this situation rather than pure crosssections
 Briefly discuss the advantage of using panel data in this situation rather than pure crosssections") Answer Key Fixed Effect and First Difference Models 1. See discussion in class.. David Neumark and William Wascher published a study in 199 of the effect of minimum wages on teenage employment using a
Answer Key Fixed Effect and First Difference Models 1. See discussion in class.. David Neumark and William Wascher published a study in 199 of the effect of minimum wages on teenage employment using a
Economics 326 Methods of Empirical Research in Economics. Lecture 14: Hypothesis testing in the multiple regression model, Part 2
 Economics 326 Methods of Empirical Research in Economics Lecture 14: Hypothesis testing in the multiple regression model, Part 2 Vadim Marmer University of British Columbia May 5, 2010 Multiple restrictions
Economics 326 Methods of Empirical Research in Economics Lecture 14: Hypothesis testing in the multiple regression model, Part 2 Vadim Marmer University of British Columbia May 5, 2010 Multiple restrictions
Econ 1123: Section 5. Review. Internal Validity. Panel Data. Clustered SE. STATA help for Problem Set 5. Econ 1123: Section 5.
 Outline 1 Elena Llaudet 2 3 4 October 6, 2010 5 based on Common Mistakes on P. Set 4 lnftmpop = -.72-2.84 higdppc -.25 lackpf +.65 higdppc * lackpf 2 lnftmpop = β 0 + β 1 higdppc + β 2 lackpf + β 3 lackpf
Outline 1 Elena Llaudet 2 3 4 October 6, 2010 5 based on Common Mistakes on P. Set 4 lnftmpop = -.72-2.84 higdppc -.25 lackpf +.65 higdppc * lackpf 2 lnftmpop = β 0 + β 1 higdppc + β 2 lackpf + β 3 lackpf
ECON3150/4150 Spring 2016
 ECON3150/4150 Spring 2016 Lecture 6 Multiple regression model Siv-Elisabeth Skjelbred University of Oslo February 5th Last updated: February 3, 2016 1 / 49 Outline Multiple linear regression model and
ECON3150/4150 Spring 2016 Lecture 6 Multiple regression model Siv-Elisabeth Skjelbred University of Oslo February 5th Last updated: February 3, 2016 1 / 49 Outline Multiple linear regression model and
LECTURE 10. Introduction to Econometrics. Multicollinearity & Heteroskedasticity
 LECTURE 10 Introduction to Econometrics Multicollinearity & Heteroskedasticity November 22, 2016 1 / 23 ON PREVIOUS LECTURES We discussed the specification of a regression equation Specification consists
LECTURE 10 Introduction to Econometrics Multicollinearity & Heteroskedasticity November 22, 2016 1 / 23 ON PREVIOUS LECTURES We discussed the specification of a regression equation Specification consists
Rewrap ECON November 18, () Rewrap ECON 4135 November 18, / 35
 Rewrap ECON 4135 November 18, / 35") Rewrap ECON 4135 November 18, 2011 () Rewrap ECON 4135 November 18, 2011 1 / 35 What should you now know? 1 What is econometrics? 2 Fundamental regression analysis 1 Bivariate regression 2 Multivariate
Rewrap ECON 4135 November 18, 2011 () Rewrap ECON 4135 November 18, 2011 1 / 35 What should you now know? 1 What is econometrics? 2 Fundamental regression analysis 1 Bivariate regression 2 Multivariate
1 Motivation for Instrumental Variable (IV) Regression
 Regression") ECON 370: IV & 2SLS 1 Instrumental Variables Estimation and Two Stage Least Squares Econometric Methods, ECON 370 Let s get back to the thiking in terms of cross sectional (or pooled cross sectional) data
ECON 370: IV & 2SLS 1 Instrumental Variables Estimation and Two Stage Least Squares Econometric Methods, ECON 370 Let s get back to the thiking in terms of cross sectional (or pooled cross sectional) data
Handout 12. Endogeneity & Simultaneous Equation Models
 Handout 12. Endogeneity & Simultaneous Equation Models In which you learn about another potential source of endogeneity caused by the simultaneous determination of economic variables, and learn how to
Handout 12. Endogeneity & Simultaneous Equation Models In which you learn about another potential source of endogeneity caused by the simultaneous determination of economic variables, and learn how to
1 Linear Regression Analysis The Mincer Wage Equation Data Econometric Model Estimation... 11
 Econ 495 - Econometric Review 1 Contents 1 Linear Regression Analysis 4 1.1 The Mincer Wage Equation................. 4 1.2 Data............................. 6 1.3 Econometric Model.....................
Econ 495 - Econometric Review 1 Contents 1 Linear Regression Analysis 4 1.1 The Mincer Wage Equation................. 4 1.2 Data............................. 6 1.3 Econometric Model.....................
An overview of applied econometrics
 An overview of applied econometrics Jo Thori Lind September 4, 2011 1 Introduction This note is intended as a brief overview of what is necessary to read and understand journal articles with empirical
An overview of applied econometrics Jo Thori Lind September 4, 2011 1 Introduction This note is intended as a brief overview of what is necessary to read and understand journal articles with empirical
Homoskedasticity. Var (u X) = σ 2. (23)
 = σ 2. (23)") Homoskedasticity How big is the difference between the OLS estimator and the true parameter? To answer this question, we make an additional assumption called homoskedasticity: Var (u X) = σ 2. (23) This
Homoskedasticity How big is the difference between the OLS estimator and the true parameter? To answer this question, we make an additional assumption called homoskedasticity: Var (u X) = σ 2. (23) This
Recent Advances in the Field of Trade Theory and Policy Analysis Using Micro-Level Data
 Recent Advances in the Field of Trade Theory and Policy Analysis Using Micro-Level Data July 2012 Bangkok, Thailand Cosimo Beverelli (World Trade Organization) 1 Content a) Classical regression model b)
Recent Advances in the Field of Trade Theory and Policy Analysis Using Micro-Level Data July 2012 Bangkok, Thailand Cosimo Beverelli (World Trade Organization) 1 Content a) Classical regression model b)
MGEC11H3Y L01 Introduction to Regression Analysis Term Test Friday July 5, PM Instructor: Victor Yu
 Last Name (Print): Solution First Name (Print): Student Number: MGECHY L Introduction to Regression Analysis Term Test Friday July, PM Instructor: Victor Yu Aids allowed: Time allowed: Calculator and one
Last Name (Print): Solution First Name (Print): Student Number: MGECHY L Introduction to Regression Analysis Term Test Friday July, PM Instructor: Victor Yu Aids allowed: Time allowed: Calculator and one
Linear Regression with one Regressor
 1 Linear Regression with one Regressor Covering Chapters 4.1 and 4.2. We ve seen the California test score data before. Now we will try to estimate the marginal effect of STR on SCORE. To motivate these
1 Linear Regression with one Regressor Covering Chapters 4.1 and 4.2. We ve seen the California test score data before. Now we will try to estimate the marginal effect of STR on SCORE. To motivate these
Economics 471: Econometrics Department of Economics, Finance and Legal Studies University of Alabama
 Economics 471: Econometrics Department of Economics, Finance and Legal Studies University of Alabama Course Packet The purpose of this packet is to show you one particular dataset and how it is used in
Economics 471: Econometrics Department of Economics, Finance and Legal Studies University of Alabama Course Packet The purpose of this packet is to show you one particular dataset and how it is used in
8. Nonstandard standard error issues 8.1. The bias of robust standard errors
 8.1. The bias of robust standard errors Bias Robust standard errors are now easily obtained using e.g. Stata option robust Robust standard errors are preferable to normal standard errors when residuals
8.1. The bias of robust standard errors Bias Robust standard errors are now easily obtained using e.g. Stata option robust Robust standard errors are preferable to normal standard errors when residuals
Econ 836 Final Exam. 2 w N 2 u N 2. 2 v N
 1) [4 points] Let Econ 836 Final Exam Y Xβ+ ε, X w+ u, w N w~ N(, σi ), u N u~ N(, σi ), ε N ε~ Nu ( γσ, I ), where X is a just one column. Let denote the OLS estimator, and define residuals e as e Y X.
1) [4 points] Let Econ 836 Final Exam Y Xβ+ ε, X w+ u, w N w~ N(, σi ), u N u~ N(, σi ), ε N ε~ Nu ( γσ, I ), where X is a just one column. Let denote the OLS estimator, and define residuals e as e Y X.
Gov 2000: 9. Regression with Two Independent Variables
 Gov 2000: 9. Regression with Two Independent Variables Matthew Blackwell Fall 2016 1 / 62 1. Why Add Variables to a Regression? 2. Adding a Binary Covariate 3. Adding a Continuous Covariate 4. OLS Mechanics
Gov 2000: 9. Regression with Two Independent Variables Matthew Blackwell Fall 2016 1 / 62 1. Why Add Variables to a Regression? 2. Adding a Binary Covariate 3. Adding a Continuous Covariate 4. OLS Mechanics
CHAPTER 6: SPECIFICATION VARIABLES
 Recall, we had the following six assumptions required for the Gauss-Markov Theorem: 1. The regression model is linear, correctly specified, and has an additive error term. 2. The error term has a zero
Recall, we had the following six assumptions required for the Gauss-Markov Theorem: 1. The regression model is linear, correctly specified, and has an additive error term. 2. The error term has a zero
Econometrics Homework 1
 Econometrics Homework Due Date: March, 24. by This problem set includes questions for Lecture -4 covered before midterm exam. Question Let z be a random column vector of size 3 : z = @ (a) Write out z
Econometrics Homework Due Date: March, 24. by This problem set includes questions for Lecture -4 covered before midterm exam. Question Let z be a random column vector of size 3 : z = @ (a) Write out z
Longitudinal Data Analysis Using Stata Paul D. Allison, Ph.D. Upcoming Seminar: May 18-19, 2017, Chicago, Illinois
 Longitudinal Data Analysis Using Stata Paul D. Allison, Ph.D. Upcoming Seminar: May 18-19, 217, Chicago, Illinois Outline 1. Opportunities and challenges of panel data. a. Data requirements b. Control
Longitudinal Data Analysis Using Stata Paul D. Allison, Ph.D. Upcoming Seminar: May 18-19, 217, Chicago, Illinois Outline 1. Opportunities and challenges of panel data. a. Data requirements b. Control
Final Exam - Solutions
 Ecn 102 - Analysis of Economic Data University of California - Davis March 19, 2010 Instructor: John Parman Final Exam - Solutions You have until 5:30pm to complete this exam. Please remember to put your
Ecn 102 - Analysis of Economic Data University of California - Davis March 19, 2010 Instructor: John Parman Final Exam - Solutions You have until 5:30pm to complete this exam. Please remember to put your
Econometrics I KS. Module 1: Bivariate Linear Regression. Alexander Ahammer. This version: March 12, 2018
 Econometrics I KS Module 1: Bivariate Linear Regression Alexander Ahammer Department of Economics Johannes Kepler University of Linz This version: March 12, 2018 Alexander Ahammer (JKU) Module 1: Bivariate
Econometrics I KS Module 1: Bivariate Linear Regression Alexander Ahammer Department of Economics Johannes Kepler University of Linz This version: March 12, 2018 Alexander Ahammer (JKU) Module 1: Bivariate
4. Nonlinear regression functions
 4. Nonlinear regression functions Up to now: Population regression function was assumed to be linear The slope(s) of the population regression function is (are) constant The effect on Y of a unit-change
4. Nonlinear regression functions Up to now: Population regression function was assumed to be linear The slope(s) of the population regression function is (are) constant The effect on Y of a unit-change
Lecture 5: Hypothesis testing with the classical linear model
 Lecture 5: Hypothesis testing with the classical linear model Assumption MLR6: Normality MLR6 is not one of the Gauss-Markov assumptions. It s not necessary to assume the error is normally distributed
Lecture 5: Hypothesis testing with the classical linear model Assumption MLR6: Normality MLR6 is not one of the Gauss-Markov assumptions. It s not necessary to assume the error is normally distributed
Lecture notes to Stock and Watson chapter 8
 Lecture notes to Stock and Watson chapter 8 Nonlinear regression Tore Schweder September 29 TS () LN7 9/9 1 / 2 Example: TestScore Income relation, linear or nonlinear? TS () LN7 9/9 2 / 2 General problem
Lecture notes to Stock and Watson chapter 8 Nonlinear regression Tore Schweder September 29 TS () LN7 9/9 1 / 2 Example: TestScore Income relation, linear or nonlinear? TS () LN7 9/9 2 / 2 General problem
Lab 07 Introduction to Econometrics
 Lab 07 Introduction to Econometrics Learning outcomes for this lab: Introduce the different typologies of data and the econometric models that can be used Understand the rationale behind econometrics Understand
Lab 07 Introduction to Econometrics Learning outcomes for this lab: Introduce the different typologies of data and the econometric models that can be used Understand the rationale behind econometrics Understand
Lecture 8: Instrumental Variables Estimation
 Lecture Notes on Advanced Econometrics Lecture 8: Instrumental Variables Estimation Endogenous Variables Consider a population model: y α y + β + β x + β x +... + β x + u i i i i k ik i Takashi Yamano
Lecture Notes on Advanced Econometrics Lecture 8: Instrumental Variables Estimation Endogenous Variables Consider a population model: y α y + β + β x + β x +... + β x + u i i i i k ik i Takashi Yamano
Chapter 8 Conclusion
 1 Chapter 8 Conclusion Three questions about test scores (score) and student-teacher ratio (str): a) After controlling for differences in economic characteristics of different districts, does the effect
1 Chapter 8 Conclusion Three questions about test scores (score) and student-teacher ratio (str): a) After controlling for differences in economic characteristics of different districts, does the effect
Problem Set #5-Key Sonoma State University Dr. Cuellar Economics 317- Introduction to Econometrics
 Problem Set #5-Key Sonoma State University Dr. Cuellar Economics 317- Introduction to Econometrics C1.1 Use the data set Wage1.dta to answer the following questions. Estimate regression equation wage =
Problem Set #5-Key Sonoma State University Dr. Cuellar Economics 317- Introduction to Econometrics C1.1 Use the data set Wage1.dta to answer the following questions. Estimate regression equation wage =