Lecture 9: Introduction to Kriging
|
|
|
- Denis Robbins
- 6 years ago
- Views:
Transcription
1 Lecture 9: Introduction to Kriging Math 586 Beginning remarks Kriging is a commonly used method of interpolation (prediction) for spatial data. The data are a set of observations of some variable(s) of interest, with some spatial correlation present. Usually, the result of kriging is the expected value ( kriging mean ) and variance ( kriging variance ) computed for every point within a region. Practically, this is done on a fine enough grid. Illustration: suppose we observe some variable Z along 1-dim space (X). There are 5 measurements made. We might ask ourselves, knowing the probabilistic behavior of the random field being observed, what are possible trajectories (realizations) of the random field, that agree with the data? This is answered by conditional simulation. In Fig. 1, you see two sets of 5 conditional simula- Conditional simulation: 5 realizations Other 5 realizations: higher krig. variance Z Z X X Figure 1: Conditional simulations, data given by dots tions for the same data. The one on the left is for one value of σ 2 = variance 1
2 of the random field, the one on the right is for another, higher, value. All the realizations are faithful to the data, but also faithful to the statistical model for the random field (i.e. mean and variogram) that we selected. Kriging mean for every location can be thought of as the average of the whole ensemble of possible realizations, conditioned on data. Kriging variance is the variance of that ensemble. (The ensemble is of course infinite, we only show 5 of its representatives.) You may see that the trajectories tend to diverge away from the observed data, that is, the kriging variance increases. Also, for the random field with higher variance (the one on the right in Fig. 1) We will observe similar qualitative behavior frequently in the future. Simple kriging (SK) Let us observe some stationary (WSS) random field V (x) at some points x j, j = 1,..., n. First, assume that the mean m and covariance function C( ) of this process are known. The case of prediction with the known mean is often called simple kriging. In order to better understand what happens and to devise an extendable approach, let s attack the question by directly trying to minimize MSE. We will seek an estimate ˆV 0 of the value of V at the point x 0. For simplicity, denote V j := V (x j ). Also, denote C(i, j) = Cov(V i, V j ). We may assume that the mean m = 0. Otherwise, subtract m from all of the V j values, estimate V 0, then add the mean back. Search for the estimate of the form ˆV 0 = n λ j V j, j=1 under the assumption of 0 mean, it is automatically unbiased. (Why?) We will find the kriging weights λ j that minimize MSE: [ ( MSE = E V 0 ) ] 2 λ j V j = V ar (V 0 ) λ j V j = (Why?) = V ar(v 0 ) 2 λ j Cov(V 0, V j ) + λ j λ i Cov(V i, V j ) That is, MSE = C(0, 0) 2 λ j C(0, j) + λ j λ i C(i, j) (1) 2
3 where C(i, j) = C V (x i x j ) might be interpreted as the elements of covariance matrix C. Note that the values C(0, j) depend on the location x 0. To minimize MSE, we take the derivatives with respect to λ k and equate to 0: MSE λ k = 2C(0, k) + 2λ k C(k, k) + 2 j k λ j C(k, j) = 0, k = 1,..., n That is, solve the system of equations 1 n λ j C(k, j) = C(0, k), k = 1,..., n (2) j=1 In matrix form, the above equations look like Cλ = b same as λ = C 1 b (3) If we denote the covariance matrix of the vector (V 0, V 1,..., V n ) as Σ, then [ ] σ 2 Σ = 0 b and MSE= σsk 2 = C(0, 0) 2λ b+λ Cλ = C(0, 0) λ b b C Now compare the equation (3) with the formula for conditional mean in Lecture 6, p. 4. It turns out that the above minimization argument is directly related to the BLUE theory for multivariate Normal! To avoid ambiguity, we will sometimes denote the optimal kriging weights λ SK. From the equations (1) and (2), the optimal kriging variance is σ 2 SK = C(0, 0) λ SK j C(0, j) (4) Compare this to the conditional variance formula from Lecture 6. What happens when you predict at one of the existing points x j? It is clear that the best choice is to just take V j, in which case the kriging variance is 0! If we use the covariance function such that C(h) C(0)σ 2 as h 0, that is, dealing with a continuous random field (no nugget!), then we should obtain lim ˆV (x0 ) = V j and σsk 2 0 x 0 x j 1 Note that we really did not use the assumption of WSS stationarity, since we allowed C(i, j) to vary with location x i. We don t have to assume a constant mean m, either, and can replace it by varying values m i, as long as these are known. 3
4 A simple case: Suppose that C(i, j) = 0, i j, only C(0, j) 0, j = 1,..., n. In this case, the kriging equations (2) are solved by λ j = σ 0 C(0, j) C(j, j) = ρ 0,j, σ j where ρ 0,j is the correlation coefficient. We obtain the prediction ˆV 0 σ 0 = ρ 0,j V j σ j That is, the weights reflect the strength of correlation. This reminds us of simple linear regression. Also, σ 2 SK = σ 2 0(1 ρ 2 0,j) where we recognize the quantity ρ 2 0,j as coefficient of determination R 2! (Question: why ρ 2 0,j 1?) Summary: Kriging is an exact interpolator (it preserves the observations) when there s no nugget effect. Kriging weights λ j depend only on locations and covariance function C, not on data. Kriging variance also depends on locations and C only. Kriging is a smooth predictor (if two points are close, then their kriging estimates are close). In MVN case, SK is the optimal predictor in the mean square sense (follows from MVN theory). Computationally, we only need to find the matrix C 1 once, then, as we vary the location, we will only vary vector b in (3) 4
 = 0.1144e h/10.")

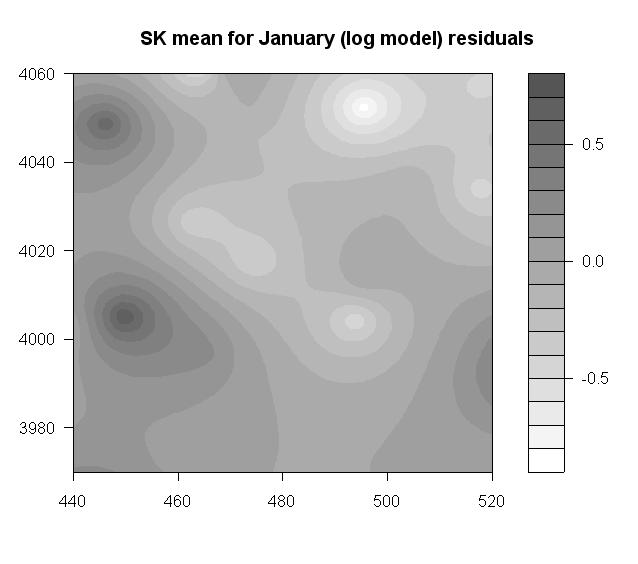
5 Example Northern NM precipitation, January log-model residuals The covariance function used in kriging is C(h) = e h/ , with the practical range of about 30. One look at the kriging st. dev. map tells us that we cannot reliably predict the precipitation (at least for January) in-between the stations. 5
6 Ordinary kriging (OK) The next issue will be estimating the mean m, which we assumed known in simple kriging. Option 1: first, estimate mean from the observations, then apply SK. Option 2: do both at the same time (Ordinary kriging). Option 1: We could try and estimate m by simply averaging the observations, but this does not take into account the correlations between V j. For example, if two locations are close together, and there is spatial continuity, then we have effectively one observation instead of two. This will require a Generalized least square approach, discussed later. Option 2: To keep the estimate unbiased, we need Thus, we need λ j = 1. m = E [V 0 ] = λ j E [V j ] = λ j m MSE is still expressed by (1), and we need to minimize it. We will apply Lagrange multiplier method of constrained optimization: minimize the function F (λ, µ) = MSE 2µ( λ j 1) where µ is the Lagrange multiplier. Taking partials with respect to λ k and µ and equating them to 0, we will get a system of equations { λ OK j C(k, j) µ = C(0, k), k = 1,..., n λ OK j = 1 In matrix form: C(1, 1)... C(1, n) 1 C(2, 1)... C(2, n) C(n, 1)... C(n, n) The kriging variance is, similarly to (4), λ 1 λ 2... λ n µ = σ 2 OK = C(0, 0) λ OK j C(0, j) + µ C(0, 1) C(0, 2)... C(0, n) 1 Overall, σ 2 OK is slightly higher than σ 2 SK because of higher uncertainty associated with estimating m. 6
 = 0.3382.")
7 Example continued Let s zoom in on a portion of NM precipitation map: the locations marked are stations close to the point x 0 = 470, y 0 = 4010, marked by. Comparing kriging st.dev. at that point, σ SK = , σ OK = , and maximum possible is σ = C(0, 0) = The kriging weights λ j were sorted according to their absolute values and the first 10 are: lambda_sk lambda_ok point no. [1,] [2,] [3,] [4,] [5,] [6,] [7,] [8,] [9,] [10,] Generally, closer points get higher weights. Notice, though, that 15 is masked by the presence of 14, and some stations get negative weights! 7
8 8
Point-Referenced Data Models
 Point-Referenced Data Models Jamie Monogan University of Georgia Spring 2013 Jamie Monogan (UGA) Point-Referenced Data Models Spring 2013 1 / 19 Objectives By the end of these meetings, participants should
Point-Referenced Data Models Jamie Monogan University of Georgia Spring 2013 Jamie Monogan (UGA) Point-Referenced Data Models Spring 2013 1 / 19 Objectives By the end of these meetings, participants should
Basics in Geostatistics 2 Geostatistical interpolation/estimation: Kriging methods. Hans Wackernagel. MINES ParisTech.
 Basics in Geostatistics 2 Geostatistical interpolation/estimation: Kriging methods Hans Wackernagel MINES ParisTech NERSC April 2013 http://hans.wackernagel.free.fr Basic concepts Geostatistics Hans Wackernagel
Basics in Geostatistics 2 Geostatistical interpolation/estimation: Kriging methods Hans Wackernagel MINES ParisTech NERSC April 2013 http://hans.wackernagel.free.fr Basic concepts Geostatistics Hans Wackernagel
Chapter 4 - Fundamentals of spatial processes Lecture notes
 TK4150 - Intro 1 Chapter 4 - Fundamentals of spatial processes Lecture notes Odd Kolbjørnsen and Geir Storvik January 30, 2017 STK4150 - Intro 2 Spatial processes Typically correlation between nearby sites
TK4150 - Intro 1 Chapter 4 - Fundamentals of spatial processes Lecture notes Odd Kolbjørnsen and Geir Storvik January 30, 2017 STK4150 - Intro 2 Spatial processes Typically correlation between nearby sites
Linear Model Under General Variance Structure: Autocorrelation
 Linear Model Under General Variance Structure: Autocorrelation A Definition of Autocorrelation In this section, we consider another special case of the model Y = X β + e, or y t = x t β + e t, t = 1,..,.
Linear Model Under General Variance Structure: Autocorrelation A Definition of Autocorrelation In this section, we consider another special case of the model Y = X β + e, or y t = x t β + e t, t = 1,..,.
Kriging Luc Anselin, All Rights Reserved
 Kriging Luc Anselin Spatial Analysis Laboratory Dept. Agricultural and Consumer Economics University of Illinois, Urbana-Champaign http://sal.agecon.uiuc.edu Outline Principles Kriging Models Spatial Interpolation
Kriging Luc Anselin Spatial Analysis Laboratory Dept. Agricultural and Consumer Economics University of Illinois, Urbana-Champaign http://sal.agecon.uiuc.edu Outline Principles Kriging Models Spatial Interpolation
PRODUCING PROBABILITY MAPS TO ASSESS RISK OF EXCEEDING CRITICAL THRESHOLD VALUE OF SOIL EC USING GEOSTATISTICAL APPROACH
 PRODUCING PROBABILITY MAPS TO ASSESS RISK OF EXCEEDING CRITICAL THRESHOLD VALUE OF SOIL EC USING GEOSTATISTICAL APPROACH SURESH TRIPATHI Geostatistical Society of India Assumptions and Geostatistical Variogram
PRODUCING PROBABILITY MAPS TO ASSESS RISK OF EXCEEDING CRITICAL THRESHOLD VALUE OF SOIL EC USING GEOSTATISTICAL APPROACH SURESH TRIPATHI Geostatistical Society of India Assumptions and Geostatistical Variogram
Geostatistics in Hydrology: Kriging interpolation
 Chapter Geostatistics in Hydrology: Kriging interpolation Hydrologic properties, such as rainfall, aquifer characteristics (porosity, hydraulic conductivity, transmissivity, storage coefficient, etc.),
Chapter Geostatistics in Hydrology: Kriging interpolation Hydrologic properties, such as rainfall, aquifer characteristics (porosity, hydraulic conductivity, transmissivity, storage coefficient, etc.),
Introduction. Semivariogram Cloud
 Introduction Data: set of n attribute measurements {z(s i ), i = 1,, n}, available at n sample locations {s i, i = 1,, n} Objectives: Slide 1 quantify spatial auto-correlation, or attribute dissimilarity
Introduction Data: set of n attribute measurements {z(s i ), i = 1,, n}, available at n sample locations {s i, i = 1,, n} Objectives: Slide 1 quantify spatial auto-correlation, or attribute dissimilarity
Basics of Point-Referenced Data Models
 Basics of Point-Referenced Data Models Basic tool is a spatial process, {Y (s), s D}, where D R r Chapter 2: Basics of Point-Referenced Data Models p. 1/45 Basics of Point-Referenced Data Models Basic
Basics of Point-Referenced Data Models Basic tool is a spatial process, {Y (s), s D}, where D R r Chapter 2: Basics of Point-Referenced Data Models p. 1/45 Basics of Point-Referenced Data Models Basic
Introduction to Spatial Data and Models
 Introduction to Spatial Data and Models Sudipto Banerjee 1 and Andrew O. Finley 2 1 Biostatistics, School of Public Health, University of Minnesota, Minneapolis, Minnesota, U.S.A. 2 Department of Forestry
Introduction to Spatial Data and Models Sudipto Banerjee 1 and Andrew O. Finley 2 1 Biostatistics, School of Public Health, University of Minnesota, Minneapolis, Minnesota, U.S.A. 2 Department of Forestry
A time series is called strictly stationary if the joint distribution of every collection (Y t
 5 Time series A time series is a set of observations recorded over time. You can think for example at the GDP of a country over the years (or quarters) or the hourly measurements of temperature over a
5 Time series A time series is a set of observations recorded over time. You can think for example at the GDP of a country over the years (or quarters) or the hourly measurements of temperature over a
University of California, Los Angeles Department of Statistics. Universal kriging
 University of California, Los Angeles Department of Statistics Statistics C173/C273 Instructor: Nicolas Christou Universal kriging The Ordinary Kriging (OK) that was discussed earlier is based on the constant
University of California, Los Angeles Department of Statistics Statistics C173/C273 Instructor: Nicolas Christou Universal kriging The Ordinary Kriging (OK) that was discussed earlier is based on the constant
Gridding of precipitation and air temperature observations in Belgium. Michel Journée Royal Meteorological Institute of Belgium (RMI)
") Gridding of precipitation and air temperature observations in Belgium Michel Journée Royal Meteorological Institute of Belgium (RMI) Gridding of meteorological data A variety of hydrologic, ecological,
Gridding of precipitation and air temperature observations in Belgium Michel Journée Royal Meteorological Institute of Belgium (RMI) Gridding of meteorological data A variety of hydrologic, ecological,
Introduction to Spatial Data and Models
 Introduction to Spatial Data and Models Sudipto Banerjee 1 and Andrew O. Finley 2 1 Department of Forestry & Department of Geography, Michigan State University, Lansing Michigan, U.S.A. 2 Biostatistics,
Introduction to Spatial Data and Models Sudipto Banerjee 1 and Andrew O. Finley 2 1 Department of Forestry & Department of Geography, Michigan State University, Lansing Michigan, U.S.A. 2 Biostatistics,
University of California, Los Angeles Department of Statistics. Effect of variogram parameters on kriging weights
 University of California, Los Angeles Department of Statistics Statistics C173/C273 Instructor: Nicolas Christou Effect of variogram parameters on kriging weights We will explore in this document how the
University of California, Los Angeles Department of Statistics Statistics C173/C273 Instructor: Nicolas Christou Effect of variogram parameters on kriging weights We will explore in this document how the
Geostatistics for Seismic Data Integration in Earth Models
 2003 Distinguished Instructor Short Course Distinguished Instructor Series, No. 6 sponsored by the Society of Exploration Geophysicists European Association of Geoscientists & Engineers SUB Gottingen 7
2003 Distinguished Instructor Short Course Distinguished Instructor Series, No. 6 sponsored by the Society of Exploration Geophysicists European Association of Geoscientists & Engineers SUB Gottingen 7
Lecture - 30 Stationary Processes
 Probability and Random Variables Prof. M. Chakraborty Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur Lecture - 30 Stationary Processes So,
Probability and Random Variables Prof. M. Chakraborty Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur Lecture - 30 Stationary Processes So,
Investigation of Monthly Pan Evaporation in Turkey with Geostatistical Technique
 Investigation of Monthly Pan Evaporation in Turkey with Geostatistical Technique Hatice Çitakoğlu 1, Murat Çobaner 1, Tefaruk Haktanir 1, 1 Department of Civil Engineering, Erciyes University, Kayseri,
Investigation of Monthly Pan Evaporation in Turkey with Geostatistical Technique Hatice Çitakoğlu 1, Murat Çobaner 1, Tefaruk Haktanir 1, 1 Department of Civil Engineering, Erciyes University, Kayseri,
ST505/S697R: Fall Homework 2 Solution.
 ST505/S69R: Fall 2012. Homework 2 Solution. 1. 1a; problem 1.22 Below is the summary information (edited) from the regression (using R output); code at end of solution as is code and output for SAS. a)
ST505/S69R: Fall 2012. Homework 2 Solution. 1. 1a; problem 1.22 Below is the summary information (edited) from the regression (using R output); code at end of solution as is code and output for SAS. a)
ENGRG Introduction to GIS
 ENGRG 59910 Introduction to GIS Michael Piasecki October 13, 2017 Lecture 06: Spatial Analysis Outline Today Concepts What is spatial interpolation Why is necessary Sample of interpolation (size and pattern)
ENGRG 59910 Introduction to GIS Michael Piasecki October 13, 2017 Lecture 06: Spatial Analysis Outline Today Concepts What is spatial interpolation Why is necessary Sample of interpolation (size and pattern)
Influence of parameter estimation uncertainty in Kriging: Part 2 Test and case study applications
 Hydrology and Earth System Influence Sciences, of 5(), parameter 5 3 estimation (1) uncertainty EGS in Kriging: Part Test and case study applications Influence of parameter estimation uncertainty in Kriging:
Hydrology and Earth System Influence Sciences, of 5(), parameter 5 3 estimation (1) uncertainty EGS in Kriging: Part Test and case study applications Influence of parameter estimation uncertainty in Kriging:
Some general observations.
 Modeling and analyzing data from computer experiments. Some general observations. 1. For simplicity, I assume that all factors (inputs) x1, x2,, xd are quantitative. 2. Because the code always produces
Modeling and analyzing data from computer experiments. Some general observations. 1. For simplicity, I assume that all factors (inputs) x1, x2,, xd are quantitative. 2. Because the code always produces
The Matrix Reloaded: Computations for large spatial data sets
 The Matrix Reloaded: Computations for large spatial data sets Doug Nychka National Center for Atmospheric Research The spatial model Solving linear systems Matrix multiplication Creating sparsity Sparsity,
The Matrix Reloaded: Computations for large spatial data sets Doug Nychka National Center for Atmospheric Research The spatial model Solving linear systems Matrix multiplication Creating sparsity Sparsity,
Statistics 203: Introduction to Regression and Analysis of Variance Penalized models
 Statistics 203: Introduction to Regression and Analysis of Variance Penalized models Jonathan Taylor - p. 1/15 Today s class Bias-Variance tradeoff. Penalized regression. Cross-validation. - p. 2/15 Bias-variance
Statistics 203: Introduction to Regression and Analysis of Variance Penalized models Jonathan Taylor - p. 1/15 Today s class Bias-Variance tradeoff. Penalized regression. Cross-validation. - p. 2/15 Bias-variance
MATH 1231 MATHEMATICS 1B CALCULUS. Section 5: - Power Series and Taylor Series.
 MATH 1231 MATHEMATICS 1B CALCULUS. Section 5: - Power Series and Taylor Series. The objective of this section is to become familiar with the theory and application of power series and Taylor series. By
MATH 1231 MATHEMATICS 1B CALCULUS. Section 5: - Power Series and Taylor Series. The objective of this section is to become familiar with the theory and application of power series and Taylor series. By
Empirical Bayesian Kriging
 Empirical Bayesian Kriging Implemented in ArcGIS Geostatistical Analyst By Konstantin Krivoruchko, Senior Research Associate, Software Development Team, Esri Obtaining reliable environmental measurements
Empirical Bayesian Kriging Implemented in ArcGIS Geostatistical Analyst By Konstantin Krivoruchko, Senior Research Associate, Software Development Team, Esri Obtaining reliable environmental measurements
7 Geostatistics. Figure 7.1 Focus of geostatistics
 7 Geostatistics 7.1 Introduction Geostatistics is the part of statistics that is concerned with geo-referenced data, i.e. data that are linked to spatial coordinates. To describe the spatial variation
7 Geostatistics 7.1 Introduction Geostatistics is the part of statistics that is concerned with geo-referenced data, i.e. data that are linked to spatial coordinates. To describe the spatial variation
Regression: Main Ideas Setting: Quantitative outcome with a quantitative explanatory variable. Example, cont.
 TCELL 9/4/205 36-309/749 Experimental Design for Behavioral and Social Sciences Simple Regression Example Male black wheatear birds carry stones to the nest as a form of sexual display. Soler et al. wanted
TCELL 9/4/205 36-309/749 Experimental Design for Behavioral and Social Sciences Simple Regression Example Male black wheatear birds carry stones to the nest as a form of sexual display. Soler et al. wanted
Regression with correlation for the Sales Data
 Regression with correlation for the Sales Data Scatter with Loess Curve Time Series Plot Sales 30 35 40 45 Sales 30 35 40 45 0 10 20 30 40 50 Week 0 10 20 30 40 50 Week Sales Data What is our goal with
Regression with correlation for the Sales Data Scatter with Loess Curve Time Series Plot Sales 30 35 40 45 Sales 30 35 40 45 0 10 20 30 40 50 Week 0 10 20 30 40 50 Week Sales Data What is our goal with
Correcting Variogram Reproduction of P-Field Simulation
 Correcting Variogram Reproduction of P-Field Simulation Julián M. Ortiz (jmo1@ualberta.ca) Department of Civil & Environmental Engineering University of Alberta Abstract Probability field simulation is
Correcting Variogram Reproduction of P-Field Simulation Julián M. Ortiz (jmo1@ualberta.ca) Department of Civil & Environmental Engineering University of Alberta Abstract Probability field simulation is
Spatial Data Mining. Regression and Classification Techniques
 Spatial Data Mining Regression and Classification Techniques 1 Spatial Regression and Classisfication Discrete class labels (left) vs. continues quantities (right) measured at locations (2D for geographic
Spatial Data Mining Regression and Classification Techniques 1 Spatial Regression and Classisfication Discrete class labels (left) vs. continues quantities (right) measured at locations (2D for geographic
Basic Probability Reference Sheet
 February 27, 2001 Basic Probability Reference Sheet 17.846, 2001 This is intended to be used in addition to, not as a substitute for, a textbook. X is a random variable. This means that X is a variable
February 27, 2001 Basic Probability Reference Sheet 17.846, 2001 This is intended to be used in addition to, not as a substitute for, a textbook. X is a random variable. This means that X is a variable
36-309/749 Experimental Design for Behavioral and Social Sciences. Sep. 22, 2015 Lecture 4: Linear Regression
 36-309/749 Experimental Design for Behavioral and Social Sciences Sep. 22, 2015 Lecture 4: Linear Regression TCELL Simple Regression Example Male black wheatear birds carry stones to the nest as a form
36-309/749 Experimental Design for Behavioral and Social Sciences Sep. 22, 2015 Lecture 4: Linear Regression TCELL Simple Regression Example Male black wheatear birds carry stones to the nest as a form
Econ 300/QAC 201: Quantitative Methods in Economics/Applied Data Analysis. 17th Class 7/1/10
 Econ 300/QAC 201: Quantitative Methods in Economics/Applied Data Analysis 17th Class 7/1/10 The only function of economic forecasting is to make astrology look respectable. --John Kenneth Galbraith show
Econ 300/QAC 201: Quantitative Methods in Economics/Applied Data Analysis 17th Class 7/1/10 The only function of economic forecasting is to make astrology look respectable. --John Kenneth Galbraith show
Multiple realizations using standard inversion techniques a
 Multiple realizations using standard inversion techniques a a Published in SEP report, 105, 67-78, (2000) Robert G Clapp 1 INTRODUCTION When solving a missing data problem, geophysicists and geostatisticians
Multiple realizations using standard inversion techniques a a Published in SEP report, 105, 67-78, (2000) Robert G Clapp 1 INTRODUCTION When solving a missing data problem, geophysicists and geostatisticians
1 Introduction to Generalized Least Squares
 ECONOMICS 7344, Spring 2017 Bent E. Sørensen April 12, 2017 1 Introduction to Generalized Least Squares Consider the model Y = Xβ + ɛ, where the N K matrix of regressors X is fixed, independent of the
ECONOMICS 7344, Spring 2017 Bent E. Sørensen April 12, 2017 1 Introduction to Generalized Least Squares Consider the model Y = Xβ + ɛ, where the N K matrix of regressors X is fixed, independent of the
Bayesian Transgaussian Kriging
 1 Bayesian Transgaussian Kriging Hannes Müller Institut für Statistik University of Klagenfurt 9020 Austria Keywords: Kriging, Bayesian statistics AMS: 62H11,60G90 Abstract In geostatistics a widely used
1 Bayesian Transgaussian Kriging Hannes Müller Institut für Statistik University of Klagenfurt 9020 Austria Keywords: Kriging, Bayesian statistics AMS: 62H11,60G90 Abstract In geostatistics a widely used
Lecture 15 Multiple regression I Chapter 6 Set 2 Least Square Estimation The quadratic form to be minimized is
 Lecture 15 Multiple regression I Chapter 6 Set 2 Least Square Estimation The quadratic form to be minimized is Q = (Y i β 0 β 1 X i1 β 2 X i2 β p 1 X i.p 1 ) 2, which in matrix notation is Q = (Y Xβ) (Y
Lecture 15 Multiple regression I Chapter 6 Set 2 Least Square Estimation The quadratic form to be minimized is Q = (Y i β 0 β 1 X i1 β 2 X i2 β p 1 X i.p 1 ) 2, which in matrix notation is Q = (Y Xβ) (Y
The Matrix Reloaded: Computations for large spatial data sets
 The Matrix Reloaded: Computations for large spatial data sets The spatial model Solving linear systems Matrix multiplication Creating sparsity Doug Nychka National Center for Atmospheric Research Sparsity,
The Matrix Reloaded: Computations for large spatial data sets The spatial model Solving linear systems Matrix multiplication Creating sparsity Doug Nychka National Center for Atmospheric Research Sparsity,
Time-lapse filtering and improved repeatability with automatic factorial co-kriging. Thierry Coléou CGG Reservoir Services Massy
 Time-lapse filtering and improved repeatability with automatic factorial co-kriging. Thierry Coléou CGG Reservoir Services Massy 1 Outline Introduction Variogram and Autocorrelation Factorial Kriging Factorial
Time-lapse filtering and improved repeatability with automatic factorial co-kriging. Thierry Coléou CGG Reservoir Services Massy 1 Outline Introduction Variogram and Autocorrelation Factorial Kriging Factorial
Chapter 4 - Fundamentals of spatial processes Lecture notes
 Chapter 4 - Fundamentals of spatial processes Lecture notes Geir Storvik January 21, 2013 STK4150 - Intro 2 Spatial processes Typically correlation between nearby sites Mostly positive correlation Negative
Chapter 4 - Fundamentals of spatial processes Lecture notes Geir Storvik January 21, 2013 STK4150 - Intro 2 Spatial processes Typically correlation between nearby sites Mostly positive correlation Negative
The General Linear Model. Monday, Lecture 2 Jeanette Mumford University of Wisconsin - Madison
 The General Linear Model Monday, Lecture 2 Jeanette Mumford University of Wisconsin - Madison How we re approaching the GLM Regression for behavioral data Without using matrices Understand least squares
The General Linear Model Monday, Lecture 2 Jeanette Mumford University of Wisconsin - Madison How we re approaching the GLM Regression for behavioral data Without using matrices Understand least squares
General Regression Model
 Scott S. Emerson, M.D., Ph.D. Department of Biostatistics, University of Washington, Seattle, WA 98195, USA January 5, 2015 Abstract Regression analysis can be viewed as an extension of two sample statistical
Scott S. Emerson, M.D., Ph.D. Department of Biostatistics, University of Washington, Seattle, WA 98195, USA January 5, 2015 Abstract Regression analysis can be viewed as an extension of two sample statistical
Comparison of rainfall distribution method
 Team 6 Comparison of rainfall distribution method In this section different methods of rainfall distribution are compared. METEO-France is the French meteorological agency, a public administrative institution
Team 6 Comparison of rainfall distribution method In this section different methods of rainfall distribution are compared. METEO-France is the French meteorological agency, a public administrative institution
Function Approximation
 1 Function Approximation This is page i Printer: Opaque this 1.1 Introduction In this chapter we discuss approximating functional forms. Both in econometric and in numerical problems, the need for an approximating
1 Function Approximation This is page i Printer: Opaque this 1.1 Introduction In this chapter we discuss approximating functional forms. Both in econometric and in numerical problems, the need for an approximating
Introduction to Geostatistics
 Introduction to Geostatistics Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public Health, Johns Hopkins University, Baltimore,
Introduction to Geostatistics Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public Health, Johns Hopkins University, Baltimore,
Stanford Exploration Project, Report 105, September 5, 2000, pages 41 53
 Stanford Exploration Project, Report 105, September 5, 2000, pages 41 53 40 Stanford Exploration Project, Report 105, September 5, 2000, pages 41 53 Short Note Multiple realizations using standard inversion
Stanford Exploration Project, Report 105, September 5, 2000, pages 41 53 40 Stanford Exploration Project, Report 105, September 5, 2000, pages 41 53 Short Note Multiple realizations using standard inversion
Long-Run Covariability
 Long-Run Covariability Ulrich K. Müller and Mark W. Watson Princeton University October 2016 Motivation Study the long-run covariability/relationship between economic variables great ratios, long-run Phillips
Long-Run Covariability Ulrich K. Müller and Mark W. Watson Princeton University October 2016 Motivation Study the long-run covariability/relationship between economic variables great ratios, long-run Phillips
Econometrics 2, Class 1
 Econometrics 2, Class Problem Set #2 September 9, 25 Remember! Send an email to let me know that you are following these classes: paul.sharp@econ.ku.dk That way I can contact you e.g. if I need to cancel
Econometrics 2, Class Problem Set #2 September 9, 25 Remember! Send an email to let me know that you are following these classes: paul.sharp@econ.ku.dk That way I can contact you e.g. if I need to cancel
Uncertainty in merged radar - rain gauge rainfall products
 Uncertainty in merged radar - rain gauge rainfall products Francesca Cecinati University of Bristol francesca.cecinati@bristol.ac.uk Supervisor: Miguel A. Rico-Ramirez This project has received funding
Uncertainty in merged radar - rain gauge rainfall products Francesca Cecinati University of Bristol francesca.cecinati@bristol.ac.uk Supervisor: Miguel A. Rico-Ramirez This project has received funding
Park Forest Math Team. Meet #3. Algebra. Self-study Packet
 Park Forest Math Team Meet #3 Self-study Packet Problem Categories for this Meet: 1. Mystery: Problem solving 2. Geometry: Angle measures in plane figures including supplements and complements 3. Number
Park Forest Math Team Meet #3 Self-study Packet Problem Categories for this Meet: 1. Mystery: Problem solving 2. Geometry: Angle measures in plane figures including supplements and complements 3. Number
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
df=degrees of freedom = n - 1
 One sample t-test test of the mean Assumptions: Independent, random samples Approximately normal distribution (from intro class: σ is unknown, need to calculate and use s (sample standard deviation)) Hypotheses:
One sample t-test test of the mean Assumptions: Independent, random samples Approximately normal distribution (from intro class: σ is unknown, need to calculate and use s (sample standard deviation)) Hypotheses:
Let V be a vector space, and let X be a subset. We say X is a Basis if it is both linearly independent and a generating set.
 Basis Let V be a vector space, and let X be a subset. We say X is a Basis if it is both linearly independent and a generating set. The first example of a basis is the standard basis for R n e 1 = (1, 0,...,
Basis Let V be a vector space, and let X be a subset. We say X is a Basis if it is both linearly independent and a generating set. The first example of a basis is the standard basis for R n e 1 = (1, 0,...,
Next is material on matrix rank. Please see the handout
 B90.330 / C.005 NOTES for Wednesday 0.APR.7 Suppose that the model is β + ε, but ε does not have the desired variance matrix. Say that ε is normal, but Var(ε) σ W. The form of W is W w 0 0 0 0 0 0 w 0
B90.330 / C.005 NOTES for Wednesday 0.APR.7 Suppose that the model is β + ε, but ε does not have the desired variance matrix. Say that ε is normal, but Var(ε) σ W. The form of W is W w 0 0 0 0 0 0 w 0
at least 50 and preferably 100 observations should be available to build a proper model
 III Box-Jenkins Methods 1. Pros and Cons of ARIMA Forecasting a) need for data at least 50 and preferably 100 observations should be available to build a proper model used most frequently for hourly or
III Box-Jenkins Methods 1. Pros and Cons of ARIMA Forecasting a) need for data at least 50 and preferably 100 observations should be available to build a proper model used most frequently for hourly or
1 Review of the dot product
 Any typographical or other corrections about these notes are welcome. Review of the dot product The dot product on R n is an operation that takes two vectors and returns a number. It is defined by n u
Any typographical or other corrections about these notes are welcome. Review of the dot product The dot product on R n is an operation that takes two vectors and returns a number. It is defined by n u
Series. richard/math230 These notes are taken from Calculus Vol I, by Tom M. Apostol,
 Series Professor Richard Blecksmith richard@math.niu.edu Dept. of Mathematical Sciences Northern Illinois University http://math.niu.edu/ richard/math230 These notes are taken from Calculus Vol I, by Tom
Series Professor Richard Blecksmith richard@math.niu.edu Dept. of Mathematical Sciences Northern Illinois University http://math.niu.edu/ richard/math230 These notes are taken from Calculus Vol I, by Tom
Handbook of Spatial Statistics Chapter 2: Continuous Parameter Stochastic Process Theory by Gneiting and Guttorp
 Handbook of Spatial Statistics Chapter 2: Continuous Parameter Stochastic Process Theory by Gneiting and Guttorp Marcela Alfaro Córdoba August 25, 2016 NCSU Department of Statistics Continuous Parameter
Handbook of Spatial Statistics Chapter 2: Continuous Parameter Stochastic Process Theory by Gneiting and Guttorp Marcela Alfaro Córdoba August 25, 2016 NCSU Department of Statistics Continuous Parameter
Spatial Backfitting of Roller Measurement Values from a Florida Test Bed
 Spatial Backfitting of Roller Measurement Values from a Florida Test Bed Daniel K. Heersink 1, Reinhard Furrer 1, and Mike A. Mooney 2 1 Institute of Mathematics, University of Zurich, CH-8057 Zurich 2
Spatial Backfitting of Roller Measurement Values from a Florida Test Bed Daniel K. Heersink 1, Reinhard Furrer 1, and Mike A. Mooney 2 1 Institute of Mathematics, University of Zurich, CH-8057 Zurich 2
MATH 1231 MATHEMATICS 1B Calculus Section 4.4: Taylor & Power series.
 MATH 1231 MATHEMATICS 1B 2010. For use in Dr Chris Tisdell s lectures. Calculus Section 4.4: Taylor & Power series. 1. What is a Taylor series? 2. Convergence of Taylor series 3. Common Maclaurin series
MATH 1231 MATHEMATICS 1B 2010. For use in Dr Chris Tisdell s lectures. Calculus Section 4.4: Taylor & Power series. 1. What is a Taylor series? 2. Convergence of Taylor series 3. Common Maclaurin series
1-Way ANOVA MATH 143. Spring Department of Mathematics and Statistics Calvin College
 1-Way ANOVA MATH 143 Department of Mathematics and Statistics Calvin College Spring 2010 The basic ANOVA situation Two variables: 1 Categorical, 1 Quantitative Main Question: Do the (means of) the quantitative
1-Way ANOVA MATH 143 Department of Mathematics and Statistics Calvin College Spring 2010 The basic ANOVA situation Two variables: 1 Categorical, 1 Quantitative Main Question: Do the (means of) the quantitative
Basics: Definitions and Notation. Stationarity. A More Formal Definition
 Basics: Definitions and Notation A Univariate is a sequence of measurements of the same variable collected over (usually regular intervals of) time. Usual assumption in many time series techniques is that
Basics: Definitions and Notation A Univariate is a sequence of measurements of the same variable collected over (usually regular intervals of) time. Usual assumption in many time series techniques is that
The ProbForecastGOP Package
 The ProbForecastGOP Package April 24, 2006 Title Probabilistic Weather Field Forecast using the GOP method Version 1.3 Author Yulia Gel, Adrian E. Raftery, Tilmann Gneiting, Veronica J. Berrocal Description
The ProbForecastGOP Package April 24, 2006 Title Probabilistic Weather Field Forecast using the GOP method Version 1.3 Author Yulia Gel, Adrian E. Raftery, Tilmann Gneiting, Veronica J. Berrocal Description
Interpolation {x,y} Data with Suavity. Peter K. Ott Forest Analysis & Inventory Branch BC Ministry of FLNRO Victoria, BC
 Interpolation {x,y} Data with Suavity Peter K. Ott Forest Analysis & Inventory Branch BC Ministry of FLNRO Victoria, BC Peter.Ott@gov.bc.ca 1 The Goal Given a set of points: x i, y i, i = 1,2,, n find
Interpolation {x,y} Data with Suavity Peter K. Ott Forest Analysis & Inventory Branch BC Ministry of FLNRO Victoria, BC Peter.Ott@gov.bc.ca 1 The Goal Given a set of points: x i, y i, i = 1,2,, n find
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
SIO 221B, Rudnick adapted from Davis 1. 1 x lim. N x 2 n = 1 N. { x} 1 N. N x = 1 N. N x = 1 ( N N x ) x = 0 (3) = 1 x N 2
 x = 0 (3) = 1 x N 2") SIO B, Rudnick adapted from Davis VII. Sampling errors We do not have access to the true statistics, so we must compute sample statistics. By this we mean that the number of realizations we average over
SIO B, Rudnick adapted from Davis VII. Sampling errors We do not have access to the true statistics, so we must compute sample statistics. By this we mean that the number of realizations we average over
If we want to analyze experimental or simulated data we might encounter the following tasks:
 Chapter 1 Introduction If we want to analyze experimental or simulated data we might encounter the following tasks: Characterization of the source of the signal and diagnosis Studying dependencies Prediction
Chapter 1 Introduction If we want to analyze experimental or simulated data we might encounter the following tasks: Characterization of the source of the signal and diagnosis Studying dependencies Prediction
2.6 Two-dimensional continuous interpolation 3: Kriging - introduction to geostatistics. References - geostatistics. References geostatistics (cntd.
 .6 Two-dimensional continuous interpolation 3: Kriging - introduction to geostatistics Spline interpolation was originally developed or image processing. In GIS, it is mainly used in visualization o spatial
.6 Two-dimensional continuous interpolation 3: Kriging - introduction to geostatistics Spline interpolation was originally developed or image processing. In GIS, it is mainly used in visualization o spatial
Improving Spatial Data Interoperability
 Improving Spatial Data Interoperability A Framework for Geostatistical Support-To To-Support Interpolation Michael F. Goodchild, Phaedon C. Kyriakidis, Philipp Schneider, Matt Rice, Qingfeng Guan, Jordan
Improving Spatial Data Interoperability A Framework for Geostatistical Support-To To-Support Interpolation Michael F. Goodchild, Phaedon C. Kyriakidis, Philipp Schneider, Matt Rice, Qingfeng Guan, Jordan
Spatial statistics, addition to Part I. Parameter estimation and kriging for Gaussian random fields
 Spatial statistics, addition to Part I. Parameter estimation and kriging for Gaussian random fields 1 Introduction Jo Eidsvik Department of Mathematical Sciences, NTNU, Norway. (joeid@math.ntnu.no) February
Spatial statistics, addition to Part I. Parameter estimation and kriging for Gaussian random fields 1 Introduction Jo Eidsvik Department of Mathematical Sciences, NTNU, Norway. (joeid@math.ntnu.no) February
Chapter 14 Stein-Rule Estimation
 Chapter 14 Stein-Rule Estimation The ordinary least squares estimation of regression coefficients in linear regression model provides the estimators having minimum variance in the class of linear and unbiased
Chapter 14 Stein-Rule Estimation The ordinary least squares estimation of regression coefficients in linear regression model provides the estimators having minimum variance in the class of linear and unbiased
Glossary. The ISI glossary of statistical terms provides definitions in a number of different languages:
 Glossary The ISI glossary of statistical terms provides definitions in a number of different languages: http://isi.cbs.nl/glossary/index.htm Adjusted r 2 Adjusted R squared measures the proportion of the
Glossary The ISI glossary of statistical terms provides definitions in a number of different languages: http://isi.cbs.nl/glossary/index.htm Adjusted r 2 Adjusted R squared measures the proportion of the
Anomaly Density Estimation from Strip Transect Data: Pueblo of Isleta Example
 Anomaly Density Estimation from Strip Transect Data: Pueblo of Isleta Example Sean A. McKenna, Sandia National Laboratories Brent Pulsipher, Pacific Northwest National Laboratory May 5 Distribution Statement
Anomaly Density Estimation from Strip Transect Data: Pueblo of Isleta Example Sean A. McKenna, Sandia National Laboratories Brent Pulsipher, Pacific Northwest National Laboratory May 5 Distribution Statement
Automatic Determination of Uncertainty versus Data Density
 Automatic Determination of Uncertainty versus Data Density Brandon Wilde and Clayton V. Deutsch It is useful to know how various measures of uncertainty respond to changes in data density. Calculating
Automatic Determination of Uncertainty versus Data Density Brandon Wilde and Clayton V. Deutsch It is useful to know how various measures of uncertainty respond to changes in data density. Calculating
Optimal Interpolation
 Optimal Interpolation Optimal Interpolation and/or kriging consist in determining the BEST LINEAR ESTIMATE in the least square sense for locations xi where you have no measurements: Example 1: Collected
Optimal Interpolation Optimal Interpolation and/or kriging consist in determining the BEST LINEAR ESTIMATE in the least square sense for locations xi where you have no measurements: Example 1: Collected
Last Update: April 7, 201 0
 M ath E S W inter Last Update: April 7, Introduction to Partial Differential Equations Disclaimer: his lecture note tries to provide an alternative approach to the material in Sections.. 5 in the textbook.
M ath E S W inter Last Update: April 7, Introduction to Partial Differential Equations Disclaimer: his lecture note tries to provide an alternative approach to the material in Sections.. 5 in the textbook.
Interpolation and 3D Visualization of Geodata
 Marek KULCZYCKI and Marcin LIGAS, Poland Key words: interpolation, kriging, real estate market analysis, property price index ABSRAC Data derived from property markets have spatial character, no doubt
Marek KULCZYCKI and Marcin LIGAS, Poland Key words: interpolation, kriging, real estate market analysis, property price index ABSRAC Data derived from property markets have spatial character, no doubt
Review of Multiple Regression
 Ronald H. Heck 1 Let s begin with a little review of multiple regression this week. Linear models [e.g., correlation, t-tests, analysis of variance (ANOVA), multiple regression, path analysis, multivariate
Ronald H. Heck 1 Let s begin with a little review of multiple regression this week. Linear models [e.g., correlation, t-tests, analysis of variance (ANOVA), multiple regression, path analysis, multivariate
Simple Linear Regression for the Climate Data
 Prediction Prediction Interval Temperature 0.2 0.0 0.2 0.4 0.6 0.8 320 340 360 380 CO 2 Simple Linear Regression for the Climate Data What do we do with the data? y i = Temperature of i th Year x i =CO
Prediction Prediction Interval Temperature 0.2 0.0 0.2 0.4 0.6 0.8 320 340 360 380 CO 2 Simple Linear Regression for the Climate Data What do we do with the data? y i = Temperature of i th Year x i =CO
Statistics 910, #5 1. Regression Methods
 Statistics 910, #5 1 Overview Regression Methods 1. Idea: effects of dependence 2. Examples of estimation (in R) 3. Review of regression 4. Comparisons and relative efficiencies Idea Decomposition Well-known
Statistics 910, #5 1 Overview Regression Methods 1. Idea: effects of dependence 2. Examples of estimation (in R) 3. Review of regression 4. Comparisons and relative efficiencies Idea Decomposition Well-known
Time series models in the Frequency domain. The power spectrum, Spectral analysis
 ime series models in the Frequency domain he power spectrum, Spectral analysis Relationship between the periodogram and the autocorrelations = + = ( ) ( ˆ α ˆ ) β I Yt cos t + Yt sin t t= t= ( ( ) ) cosλ
ime series models in the Frequency domain he power spectrum, Spectral analysis Relationship between the periodogram and the autocorrelations = + = ( ) ( ˆ α ˆ ) β I Yt cos t + Yt sin t t= t= ( ( ) ) cosλ
Vectors Part 1: Two Dimensions
 Vectors Part 1: Two Dimensions Last modified: 20/02/2018 Links Scalars Vectors Definition Notation Polar Form Compass Directions Basic Vector Maths Multiply a Vector by a Scalar Unit Vectors Example Vectors
Vectors Part 1: Two Dimensions Last modified: 20/02/2018 Links Scalars Vectors Definition Notation Polar Form Compass Directions Basic Vector Maths Multiply a Vector by a Scalar Unit Vectors Example Vectors
Regression Models - Introduction
 Regression Models - Introduction In regression models there are two types of variables that are studied: A dependent variable, Y, also called response variable. It is modeled as random. An independent
Regression Models - Introduction In regression models there are two types of variables that are studied: A dependent variable, Y, also called response variable. It is modeled as random. An independent
Detection ASTR ASTR509 Jasper Wall Fall term. William Sealey Gosset
 ASTR509-14 Detection William Sealey Gosset 1876-1937 Best known for his Student s t-test, devised for handling small samples for quality control in brewing. To many in the statistical world "Student" was
ASTR509-14 Detection William Sealey Gosset 1876-1937 Best known for his Student s t-test, devised for handling small samples for quality control in brewing. To many in the statistical world "Student" was
Propagation of Errors in Spatial Analysis
 Stephen F. Austin State University SFA ScholarWorks Faculty Presentations Spatial Science 2001 Propagation of Errors in Spatial Analysis Peter P. Siska I-Kuai Hung Arthur Temple College of Forestry and
Stephen F. Austin State University SFA ScholarWorks Faculty Presentations Spatial Science 2001 Propagation of Errors in Spatial Analysis Peter P. Siska I-Kuai Hung Arthur Temple College of Forestry and
AP Calculus Chapter 9: Infinite Series
 AP Calculus Chapter 9: Infinite Series 9. Sequences a, a 2, a 3, a 4, a 5,... Sequence: A function whose domain is the set of positive integers n = 2 3 4 a n = a a 2 a 3 a 4 terms of the sequence Begin
AP Calculus Chapter 9: Infinite Series 9. Sequences a, a 2, a 3, a 4, a 5,... Sequence: A function whose domain is the set of positive integers n = 2 3 4 a n = a a 2 a 3 a 4 terms of the sequence Begin
Multivariate Time Series: VAR(p) Processes and Models
 Processes and Models") Multivariate Time Series: VAR(p) Processes and Models A VAR(p) model, for p > 0 is X t = φ 0 + Φ 1 X t 1 + + Φ p X t p + A t, where X t, φ 0, and X t i are k-vectors, Φ 1,..., Φ p are k k matrices, with
Multivariate Time Series: VAR(p) Processes and Models A VAR(p) model, for p > 0 is X t = φ 0 + Φ 1 X t 1 + + Φ p X t p + A t, where X t, φ 0, and X t i are k-vectors, Φ 1,..., Φ p are k k matrices, with
Section 5.4. Ken Ueda
 Section 5.4 Ken Ueda Students seem to think that being graded on a curve is a positive thing. I took lasers 101 at Cornell and got a 92 on the exam. The average was a 93. I ended up with a C on the test.
Section 5.4 Ken Ueda Students seem to think that being graded on a curve is a positive thing. I took lasers 101 at Cornell and got a 92 on the exam. The average was a 93. I ended up with a C on the test.
On block bootstrapping areal data Introduction
 On block bootstrapping areal data Nicholas Nagle Department of Geography University of Colorado UCB 260 Boulder, CO 80309-0260 Telephone: 303-492-4794 Email: nicholas.nagle@colorado.edu Introduction Inference
On block bootstrapping areal data Nicholas Nagle Department of Geography University of Colorado UCB 260 Boulder, CO 80309-0260 Telephone: 303-492-4794 Email: nicholas.nagle@colorado.edu Introduction Inference
Your schedule of coming weeks. One-way ANOVA, II. Review from last time. Review from last time /22/2004. Create ANOVA table
 Your schedule of coming weeks One-way ANOVA, II 9.07 //00 Today: One-way ANOVA, part II Next week: Two-way ANOVA, parts I and II. One-way ANOVA HW due Thursday Week of May Teacher out of town all week
Your schedule of coming weeks One-way ANOVA, II 9.07 //00 Today: One-way ANOVA, part II Next week: Two-way ANOVA, parts I and II. One-way ANOVA HW due Thursday Week of May Teacher out of town all week
Multivariate Geostatistics
 Hans Wackernagel Multivariate Geostatistics An Introduction with Applications Third, completely revised edition with 117 Figures and 7 Tables Springer Contents 1 Introduction A From Statistics to Geostatistics
Hans Wackernagel Multivariate Geostatistics An Introduction with Applications Third, completely revised edition with 117 Figures and 7 Tables Springer Contents 1 Introduction A From Statistics to Geostatistics
Applied Regression Analysis
 Applied Regression Analysis Lecture 2 January 27, 2005 Lecture #2-1/27/2005 Slide 1 of 46 Today s Lecture Simple linear regression. Partitioning the sum of squares. Tests of significance.. Regression diagnostics
Applied Regression Analysis Lecture 2 January 27, 2005 Lecture #2-1/27/2005 Slide 1 of 46 Today s Lecture Simple linear regression. Partitioning the sum of squares. Tests of significance.. Regression diagnostics
ENSC327 Communications Systems 19: Random Processes. Jie Liang School of Engineering Science Simon Fraser University
 ENSC327 Communications Systems 19: Random Processes Jie Liang School of Engineering Science Simon Fraser University 1 Outline Random processes Stationary random processes Autocorrelation of random processes
ENSC327 Communications Systems 19: Random Processes Jie Liang School of Engineering Science Simon Fraser University 1 Outline Random processes Stationary random processes Autocorrelation of random processes
Some Review Problems for Exam 2: Solutions
 Math 5366 Fall 017 Some Review Problems for Exam : Solutions 1 Find the coefficient of x 15 in each of the following: 1 (a) (1 x) 6 Solution: 1 (1 x) = ( ) k + 5 x k 6 k ( ) ( ) 0 0 so the coefficient
Math 5366 Fall 017 Some Review Problems for Exam : Solutions 1 Find the coefficient of x 15 in each of the following: 1 (a) (1 x) 6 Solution: 1 (1 x) = ( ) k + 5 x k 6 k ( ) ( ) 0 0 so the coefficient
3E4: Modelling Choice. Introduction to nonlinear programming. Announcements
 3E4: Modelling Choice Lecture 7 Introduction to nonlinear programming 1 Announcements Solutions to Lecture 4-6 Homework will be available from http://www.eng.cam.ac.uk/~dr241/3e4 Looking ahead to Lecture
3E4: Modelling Choice Lecture 7 Introduction to nonlinear programming 1 Announcements Solutions to Lecture 4-6 Homework will be available from http://www.eng.cam.ac.uk/~dr241/3e4 Looking ahead to Lecture
COMS 4771 Introduction to Machine Learning. James McInerney Adapted from slides by Nakul Verma
 COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
1 What does the random effect η mean?
 Some thoughts on Hanks et al, Environmetrics, 2015, pp. 243-254. Jim Hodges Division of Biostatistics, University of Minnesota, Minneapolis, Minnesota USA 55414 email: hodge003@umn.edu October 13, 2015
Some thoughts on Hanks et al, Environmetrics, 2015, pp. 243-254. Jim Hodges Division of Biostatistics, University of Minnesota, Minneapolis, Minnesota USA 55414 email: hodge003@umn.edu October 13, 2015
ZONAL KRIGING. 5.1: Introduction and Previous Work CHAPTER 5
 CHAPTER 5 ZONAL KRIGING Kriging and conditional indicator simulation are valuable tools for evaluating uncertainty in the subsurface, but are limited by the assumption of stationarity (i.e. the mean and
CHAPTER 5 ZONAL KRIGING Kriging and conditional indicator simulation are valuable tools for evaluating uncertainty in the subsurface, but are limited by the assumption of stationarity (i.e. the mean and
Lecture 3: Statistical sampling uncertainty
 Lecture 3: Statistical sampling uncertainty c Christopher S. Bretherton Winter 2015 3.1 Central limit theorem (CLT) Let X 1,..., X N be a sequence of N independent identically-distributed (IID) random
Lecture 3: Statistical sampling uncertainty c Christopher S. Bretherton Winter 2015 3.1 Central limit theorem (CLT) Let X 1,..., X N be a sequence of N independent identically-distributed (IID) random