Computing with Distributed Distributional Codes Convergent Inference in Brains and Machines?
|
|
|
- Marcus Pope
- 5 years ago
- Views:
Transcription
1 Computing with Distributed Distributional Codes Convergent Inference in Brains and Machines? Maneesh Sahani Professor of Theoretical Neuroscience and Machine Learning Gatsby Computational Neuroscience Unit University College London October 26, 2018
 psychology, neuroscience, ML and")
2 AI and Biology Rosenblatt s Perceptron combined (rudimentary) psychology, neuroscience, ML and AI.
3 AI and Biology Rosenblatt s Perceptron combined (rudimentary) psychology, neuroscience, ML and AI.
4 Modern ML INPUT 32x32 C1: feature maps C3: f. maps S4: f. maps S2: f. maps C5: layer 120 F6: layer 84 OUTPUT 10 Convolutions Subsampling Convolutions Full connection Gaussian connections Subsampling Full connection ❼ ❾ r ❷ 6 P ❺ r ❻ r 6 ➎ ➂ 6 ❷ r 6❼ ❷ ❺ LeCun et al å➈ê è ç ï ëíï å➄è ÿ ä ï î➓å➄æ ê ø➑é è ç ï æ ä ï ú ø➀ì➈ÿ ê û➀å ï➊ä ð ã ç ï➓è ä❿å➄ø➀é å û➑ï ❶ì➇ï ➊ø➑ï é è å➄é ù➒ ø å➈ê ➊ì➈é è ä ì➈û è ç ï➓ï ï ❶è ì➄ë è ç ï ê ø ➈î ì➈ø ù é ì➈é û➀ø➑é ï å➄ä ø è ð➃➏6ë è ç ï➉ ❶ì➇ï ➊ø➑ï é è ø➀ê ê î➓å➄û➀û ➌ è ç ï➊é è ç ï ÿ é ø➑è➉ì➈æ ï➊ä❿å è ï ê ø➀é å ➍ ÿ å ê ø 6û➑ø➀é ï å➈ä î ì ù ï➎➌ å➄é ù è ç ï ê ÿ❼ ê å➈î æ û➑ø➀é❼ ➓û å ➈ï➊ä î ï➊ä ï➊û û➀ÿ ä❿ê è ç ï ø➑é æ ÿ è ð 20% ➏6ë è ç ï ❶ì➇ï ➊ø➑ï é è ø➀ê û➀å➈ä❺ ï ➌ ê ÿ❼ ê å➄î æ û➀ø➑é❼ ÿ é ø➑è ê4 ➊å➈é ï ê ï➊ï é å➈ê æ ï➊ä ëíì➈ä î ø➑é❼ å é ì ø➀ê❺ ý ì ä➉å é ì ø➀ê❺ ➉ñ4 ëíÿ é è ø➑ì é ù ï➊æ ï➊é ù ø➀é❼ ì➈é è ç ï úrå➈û➑ÿ ï ì➈ë è ç ï ø➀å ê➊ð þ➇ÿ ❶ï ê ê ø➑ú ï û å ➈ï ä ê ì➄ë ❶ì➈é➇ú ì➈û➀ÿ è ø➀ì➈é ê å➄é ù❺ê ÿ❼ ê å➈î æ û➑ø➀é❼ å➄ä ï è ➇æ ø ➊å➈û➑û å➄û➑è ï ä é å è ï ù ➌ ä ï ê ÿ û➑è ø➀é❼ ø➀é å ❺ ø 6æ ➇ä å➈î ø ù 10% å è ï å ❿ç û å ➈ï ä ➌ è ç ï é➇ÿ î➉ ï➊ä ì➄ë ëíï å è ÿ ä ï î➓å➄æ ê➉ø➀ê ø➑é ❶ä ï å➈ê ï ù å ê è ç ï ê æ å➄è ø å➄û ä ï ê ì û➑ÿ è ø➀ì➈é ø ê ù ï ❶ä ï å ê ï ù ð å ❿ç ÿ é ø è ø➀é è ç ï è ç ø➀ä❿ù ç ø ù ù ï é û å ➈ï ä ø➀é➑ ÿ ä ï î➓å ➉ç årú ï ø➑é æ ÿ è ➊ì➈é é ï è ø➑ì é ê ëíä ì➈î ê ï ú➈ï ä å➈ûrëíï å è ÿ ä ï➏î➓å➄æ ê ø➀é è ç ï æ ä ï➊ú➇ø➀ì➈ÿ ê û å ➈ï ä ð ã ç ï➓ ❶ì é➇ú➈ì➈û➀ÿ è ø➑ì é ê ÿ❼ ê å➈î æ û➑ø➀é❼ ❶ì➈î ø➀é å è ø➑ì é ➌ ø➀é ê æ ø➑ä ï ù õ ÿ ï û➏å➄é ù 2011 ø➑ï ê ï û 2012 ê➉é ì➄è ø➀ì➈é ê➉ì➈ë 2013 ê ø➑î æ û➀ï å➄é ù ❶ì î æ û➑ï ❶ï û➑û ê ➌➄ó å ê ø➑î æ û➀ï➊î ï é è ï ù ø➀é ÿ ô➇ÿ ê ç ø➑î➓å ê ñ ï ì ❶ì é ø➑è ä ì➈é ➌ è ç ì ÿ❼ ➈ç é ì ➈û➀ì å➈û➑û ê ÿ æ ï➊ä ú➇ø➀ê ï ù û➀ï å➈ä é ø➑é❼ æ ä ì ❶ï ù ÿ ä ï ê ÿ ❿ç å➈ê å ❿ô 6æ ä ì➈æ å å è ø➑ì é➓ó å ê årú å➄ø➀û➀å û➑ï è ç ï➊é ð❹ û å➄ä ➈ï ù ï ➈ä ï➊ï ì➈ë ø➀é ú å➈ä ø å➄é ➊ï è ì ➈ï ì➈î ï❶è ä ø è ä❿å➄é ê4ëíì ä î➓å è ø➑ì é ê ì➈ë XRCE AlexNet ZF ❺ ➑ ImageNet error rate (top 5) ã ç ø➀ê➉ê ï è ø➀ì➈é ù ï ê❺ ➊ä ø ï ê ø➀é î ì ä ï ù ï➊è å➈ø➑û è ç ï å➈ä ❿ç ø➑è ï è ÿ ä ï ì➈ë ï ñ ï➊è ➌ è ç ï1 ì é➇ú➈ì➈û➀ÿ è ø➑ì é å➄û ñ ï➊ÿ ä å➈û ñ ï➊è4ó ì ä ô ÿ ê ï ù ø➑é è ç ï ï æ ï➊ä ø➑î ï é è❿ê➊ð ï ñ ï➊è ➉ ➊ì➈î æ ä ø➀ê ï ê û➀å ï➊ä❿ê ➌ é ì➄è ❶ì ÿ é è ø➀é❼ è ç ï ø➀é æ ÿ è ➌ å➄û➀û ì➄ë ó ç ø ❿ç ➊ì➈é è å➈ø➑é è ä❿å➄ø➀é å û➑ï æ å➄ä❿å➄î ï➊è ï➊ä❿ê 9ó ï ø ç è ê ð ã ç ï➏ø➀é æ ÿ è ø➀ê å æ ø ï➊û➈ø➑î➓å ï➈ð ã ç ø➀ê ø➀ê ê ø ➈é ø ➊å➈é è û ➉û å➄ä ➈ï➊ä è ç å➄é è ç ï û➀å➈ä❺ ï ê è ❿ç å➄ä❿å ❶è ï ä ø➑é è ç ï ù å➄è å å➈ê ï 9å è î ì ê4è æ ø ï➊û ê➓ ❶ï é è ï➊ä ï ù❺ø➑é å ï➊û ù ❶ð ã ç ï➓ä ï å➈ê ì➈é ø ê è ç å➄è ø è ø ê ù ï ê ø➀ä å û➀ï è ç å➄è æ ì➄è ï➊é è ø å➄û ù ø ê4è ø➑é ❶è ø➀ú➈ï ëíï å è ÿ ä ï ê➉ê ÿ ❿ç å ê ê è ä ì➈ô ï ï➊é ù æ ì➈ø➀é è ê ì➈ä ❶ì ä é ï ä å➄é å➈æ æ ï å➄ä ❼ r ì➈ë è ç ï ä ï ➊ï➊æ è ø➀ú➈ï ï û➀ù ì➈ë è ç ï ç ø ç ï ê è 6û➀ï➊ú➈ï û ëíï å è ÿ ä ï ù ï❶è ï è ì➈ä❿ê➊ð ➏ é ï ñ ï❶è❺ VGG è ç ï ê ï❶è ì➈ë ❶ï➊é è ï➊ä❿ê➏ì➄ë è ç ï➉ä ï ➊ï➊æ è ø➑ú ï ï û➀ù ê ì➄ë è ç ï➉û å➈ê è ➊ì➈é➇ú➈ì û➑ÿ è ø➀ì➈é å➄û û å ➈ï➊ä ❼➌➈ê ï➊ï ï➊û➀ì ó ëíì➈ä î å å➄ä ï å ø➑é è ç ï ❶ï é è ï➊ä Human ì➄ë è ç ï ø➀é æ ÿ è ð ã ç ï ú å➄û➀ÿ ï ê ì➄ë è ç ï ø➀é æ ÿ è æ ø ï➊û ê å➄ä ï➉é ì ä î➓å➄û➀ø ï ù❺ê ì è ç å➄è è ç ï å➎ ❿ô ä ì ÿ é ù û➀ï➊ú ï➊û íó ç ø è ï t ❶ì ä ä ï ê æ ì➈é ù ê 2014 ResNet GoogLeNet-v4 è ì å ú å➄û➀ÿ ï ì➄ë➃ ð å➄é ù è ç ï ëíì ä ï ➈ä ì➈ÿ é ù û å ❿ô❼ ❶ì ä ä ï ê æ ì➈é ù ê è ì1 ð ð ã ç ø➀ê î➓å➈ô➈ï ê è ç ï➓î ï å➈é ø➀é æ ÿ è ä ì ÿ❼ ➈ç û ➌ å➈é ù❺è ç ï

5 Deep Learning and Biology Yamins & DiCarlo, 2016

6 Deep Learning and Biology Yamins & DiCarlo, 2016
7 Is this the whole story?
) x + ǫsign( x J(θ, x, y)) panda nematode")

8 Adversarial examples = x sign( x J(θ, x, y)) x + ǫsign( x J(θ, x, y)) panda nematode gibbon 57.7% confidence 8.2% confidence 99.3 % confidence Goodfellow et al ICLR Hints that recognition in deep convolutional nets depends on a conjunction of textural cues.

9 Vision isn t just object recognition Pixel decision contributions don t segment objects... Zintgraf et al. ICLR
10 Vision isn t just object recognition Pixel decision contributions don t segment objects and we can parse scenes like this: Fantastic Planet (1973) René Laloux
11 Vision isn t just object recognition Pixel decision contributions don t segment objects and we can parse scenes like this: Limited extrapolative generalisation. Fantastic Planet (1973) René Laloux

12 Vision isn t just object recognition Pixel decision contributions don t segment objects and we can parse scenes like this: Limited extrapolative generalisation. No sense of causal structure Fantastic Planet (1973) René Laloux
13 Inference and Bayes
14 Inference and Bayes A and B have the same physical luminance.
15 Inference and Bayes A and B have the same physical luminance. They appear different because we see by inference here we infer the likely reflectances of the squares.

16 Inference and Bayes A and B have the same physical luminance. They appear different because we see by inference here we infer the likely reflectances of the squares. Inferences depend on many cues, local and remote: optimal integration is usually probabilistic or Bayesian.
17 Can supervised (deep) learning be Bayesian? Yes if Bayes is optimal, then with enough supervision a network will learn to behave in a Bayesian way.
18 Can supervised (deep) learning be Bayesian? Yes if Bayes is optimal, then with enough supervision a network will learn to behave in a Bayesian way. No The specific Bayes-optimal function may look very different case-to-case. Bayesian reasoning involves beliefs about real but unobserved causal quantities. Basis of extrapolative generalisation. Usually derived by seeking conditional independence.
19 What about variational auto-encoders? ɛ ˆx1 ˆx2 ˆxD y (3) 1 y (3) y (3) 2 y1 yk K1 y (1) 1 y (1) y (1) 2 K1 x1 x2 xd VAEs (and GANs) can reproduce generative densities quite well (though with biases, as we ll see). Generate samples using deterministic transformations of external random variates (reparametrisation trick). By themselves, do not learn sensible causal components (but see Johnson et al. 2016). Require a simplified posterior representation need analytic expectations or samples. mostly Gaussian (or other tractable exponential family). generally neglect or severely simplify posterior correlations.
20 What about variational auto-encoders? ɛ ˆx1 ˆx2 ˆxD y (3) 1 y (3) y (3) 2 y1 yk K1 y (1) 1 y (1) y (1) 2 K1 x1 x2 xd VAEs (and GANs) can reproduce generative densities quite well (though with biases, as we ll see). Generate samples using deterministic transformations of external random variates (reparametrisation trick). By themselves, do not learn sensible causal components (but see Johnson et al. 2016). Require a simplified posterior representation need analytic expectations or samples. mostly Gaussian (or other tractable exponential family). generally neglect or severely simplify posterior correlations. If eventual goal is inference (for understanding, or for decisions) then this simplified posterior may miss the point.
21 Encoding uncertainty? Part of the difficulty is that we do not have efficient and accurate ways to represent uncertainty. Parameters of simple distributions (e.g. VAEs): σ For complex models the true posterior is very rarely simple. Biases learning towards parameters where posteriors look simpler than they should be. µ Sample of particles : Difficult to differentiate through general (non-reparametrisation) samplers: Importance resampling or MCMC.
22 An alternative Borrow from neural theory: Zemel et al. (1998); Sahani & Dayan (2003):
23 An alternative Borrow from neural theory: Zemel et al. (1998); Sahani & Dayan (2003): Represent distribution p(z) by expectations of encoding functions ψ i (z).
24 An alternative Borrow from neural theory: Zemel et al. (1998); Sahani & Dayan (2003): Represent distribution p(z) by expectations of encoding functions ψ i (z).
25 An alternative Borrow from neural theory: Zemel et al. (1998); Sahani & Dayan (2003): Represent distribution p(z) by expectations of encoding functions ψ i (z). For example: ψ i (z) = g(w i z + b i ).
26 An alternative Borrow from neural theory: Zemel et al. (1998); Sahani & Dayan (2003): Represent distribution p(z) by expectations of encoding functions ψ i (z). For example: ψ i (z) = g(w i z + b i ). Generalises the idea of moments
27 An alternative Borrow from neural theory: Zemel et al. (1998); Sahani & Dayan (2003): Represent distribution p(z) by expectations of encoding functions ψ i (z). For example: ψ i (z) = g(w i z + b i ). Generalises the idea of moments Each expectation r i = ψ i (z) places a constraint on the encoded distribution.
28 An alternative Borrow from neural theory: Zemel et al. (1998); Sahani & Dayan (2003): Represent distribution p(z) by expectations of encoding functions ψ i (z). For example: ψ i (z) = g(w i z + b i ). Generalises the idea of moments Each expectation r i = ψ i (z) places a constraint on the encoded distribution. Links to kernel-space mean embeddings, predictive state representations, and (as we ll see) information geometry.
29 Decoding a DDC If needed, we can transform a DDC representation into another form:
30 Decoding a DDC If needed, we can transform a DDC representation into another form: Simple parametric form method of moments or maximum likelihood.
31 Decoding a DDC If needed, we can transform a DDC representation into another form: Simple parametric form method of moments or maximum likelihood. Particles herding.
32 Decoding a DDC If needed, we can transform a DDC representation into another form: Simple parametric form method of moments or maximum likelihood. Particles herding. Maximum entropy: p(z) e i η i ψ i (z) although η i may be difficult to find. (Exponential-family distribution: in general described equally well by the natural parameters {η i } or by the mean parameters {r i } as in information geometry.) Data distribution Distribution decoded from DDC z 2 z 1 z 1
33 Decoding a DDC If needed, we can transform a DDC representation into another form: Simple parametric form method of moments or maximum likelihood. Particles herding. Maximum entropy: p(z) e i η i ψ i (z) although η i may be difficult to find. (Exponential-family distribution: in general described equally well by the natural parameters {η i } or by the mean parameters {r i } as in information geometry.) Data distribution Distribution decoded from DDC z 2 z 1 z 1 But perhaps we don t need to decode?
34 Computing with DDC mean parameters For a general exponential family distribution, the mean parameters do not provide easy evaluation of the density.
35 Computing with DDC mean parameters For a general exponential family distribution, the mean parameters do not provide easy evaluation of the density. But many computations are essentially evaluations of expected values: belief propagation expectation of conditional density decision making expected reward for action variational learning expected value of log-likehood / suff stats.
36 Computing with DDC mean parameters For a general exponential family distribution, the mean parameters do not provide easy evaluation of the density. But many computations are essentially evaluations of expected values: belief propagation expectation of conditional density decision making expected reward for action variational learning expected value of log-likehood / suff stats. With a flexible set of basis functions, such expectations can be approximated by linear combinations of DDC activations: f (x) = i α i ψ i (x) f (x) = i α i ψ i (x) = i α i r i where the r i are the learnt expected values.
37 Example: Bayesian filtering z t = f (z t 1 ) + dw z z 1 z 2 z 3 z T x t = g(z t ) + dw x x 1 x 2 x 3 x T Bayesian updating rule: p(z t x 1:t ) dz t 1 p(z t z t 1 )p(x t z t )p(z t 1 x 1:t 1 )
38 Example: Bayesian filtering z t = f (z t 1 ) + dw z z 1 z 2 z 3 z T x t = g(z t ) + dw x x 1 x 2 x 3 x T Bayesian updating rule: p(z t x 1:t ) dz t 1 p(z t z t 1 )p(x t z t )p(z t 1 x 1:t 1 ) Can be implemented by mapping the DDC representations ψ i (z t ) = σ(w ψ(z t 1 ), x t ) r i (t) = σ(w r(t 1), x t ) provided σ is linear in the first argument.
39 Example: Bayesian filtering z t = f (z t 1 ) + dw z z 1 z 2 z 3 z T x t = g(z t ) + dw x x 1 x 2 x 3 x T Bayesian updating rule: p(z t x 1:t ) dz t 1 p(z t z t 1 )p(x t z t )p(z t 1 x 1:t 1 ) Can be implemented by mapping the DDC representations ψ i (z t ) = σ(w ψ(z t 1 ), x t ) r i (t) = σ(w r(t 1), x t ) provided σ is linear in the first argument. So DDC-filtering is implemented by a form of RNN.
40 Supervised learning Expectations are easily learned from samples: {x (s), z (s) } p(x, z) target: ψ(z (s) ) W = argmin f (x (s) ; W ) ψ(z (s) ) 2 input: x (s) f (x) ψ(z) p(z s).
41 Unsupervised learning The Helmholtz Machine (Dayan et al. 1995). Approximate inference by recognition network. Learning: Generative or causal network A model of the data Recognition or inference network Reasons about causes of a datum Wake phase: estimate mean-field representation ẑ = q(z) = R(x; ρ). Update generative parameters θ. Sleep phase: sample from generative model. Update recognition parameters ρ.
42 Distributed Distributional Recognition for a Helmholtz Machine z L1 z LKL z 11 z 12 z 1K1 x 1 x 2 x D
43 Distributed Distributional Recognition for a Helmholtz Machine z L1 z LKL DDC z 11 z 12 z 1K1 ψ 1(z 1) ψ 2(z 1) ψ N(z 1) x 1 x 2 x D
44 Distributed Distributional Recognition for a Helmholtz Machine DDC z L1 z LKL ψ 1(z L) ψ 2(z L) ψ N(z L) DDC z 11 z 12 z 1K1 ψ 1(z 1) ψ 2(z 1) ψ N(z 1) x 1 x 2 x D
45 Wake phase learning the model Learning requires expected gradients of joint likelihood. DDC z L1 z LKL ψ 1(z) ψ 2(z) ψ N(z) DDC z 11 z 12 z 1K1 ψ 1(z) ψ 2(z) ψ N(z) x 1 x 2 x D θ F(z l, θ) i γ i l ψ i(z l) θ F(z l, θ) q i γ i l ψ i(z l)
46 Sleep phase learning to recognise and to learn Samples in the sleep phase are used to learn the recognition model and the gradients needed for learning. z L1 z LKL ψ 1(z) ψ 2(z) ψ N(z) samples z 11 z 12 z 1K1 ψ 1(z) ψ 2(z) ψ N(z) samples x 1 x 2 x D
47 Sleep phase learning to recognise and to learn Samples in the sleep phase are used to learn the recognition model and the gradients needed for learning. z L1 z LKL ψ 1(z) ψ 2(z) ψ N(z) samples z 11 z 12 z 1K1 ψ 1(z) ψ 2(z) ψ N(z) samples x 1 x 2 x D Train ρ 1 : φ(x (s) ) ψ(z (s) 1 ) and ρ l : ψ(z (s) l 1 ) ψ(z(s) l ) in wake phase: r l = ψ(z l ) x = ρ l ρ l 1... ρ 1 φ(x)
48 Sleep phase learning to recognise and to learn Samples in the sleep phase are used to learn the recognition model and the gradients needed for learning. z L1 z LKL ψ 1(z) ψ 2(z) ψ N(z) samples z 11 z 12 z 1K1 ψ 1(z) ψ 2(z) ψ N(z) samples x 1 x 2 x D Train ρ 1 : φ(x (s) ) ψ(z (s) 1 ) and ρ l : ψ(z (s) l 1 ) ψ(z(s) l ) in wake phase: r l = ψ(z l ) x = ρ l ρ l 1... ρ 1 φ(x) Train α l : ψ(z (s) l ) T (s) l θ g(z (s) l+1, θ ) and β l l : ψ(z (s) l ) T (s) l 1 θg(z (s) l, θ l 1 ) in wake phase: θl F x = α l r l β l+1 r l+1
49 Results Model: 2 latent-layer deep exponential network with Laplacian conditionals.




50 Results Model: 2 latent-layer deep exponential network with Laplacian conditionals. 8 VAE HM log MMD





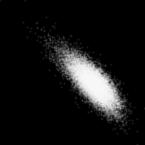











































51 Results Model: 2 latent-layer model of olfaction with Gamma latents. DDC HM True model MMD=0.002 x1 VAE True model MMD=0.02 x2 x3 x4 x5 x1 x2 x3 x4 x5 x1 x2 x3 x4 x5
52 Results 2-layer model on patches from natural images (van Hateren, 1998) z (1) z (1) 1 K1 z (2) 1 z (2) z (2) 2 K2 x1 x2 xd Model architecture MMD VAE MMD HM p-val (H 0 : VAE < HM) L 1 =10, L 2 = <10 10 L 1 =10, L 2 = <10 10 L 1 =50, L 2 = <10 10 L 1 =50, L 2 = <10 10 L 1 =100, L 2 = <10 10
53 Summary Machine learning systems have some way to go before they approach biological performance.
54 Summary Machine learning systems have some way to go before they approach biological performance. Part of the problem has to do with limited representations of probabilistic beliefs.
55 Summary Machine learning systems have some way to go before they approach biological performance. Part of the problem has to do with limited representations of probabilistic beliefs. Distributed distributional representations (DDCs):
56 Summary Machine learning systems have some way to go before they approach biological performance. Part of the problem has to do with limited representations of probabilistic beliefs. Distributed distributional representations (DDCs): carry the necessary uncertainty (in expectations, or the mean parameters of an exponential family code)
57 Summary Machine learning systems have some way to go before they approach biological performance. Part of the problem has to do with limited representations of probabilistic beliefs. Distributed distributional representations (DDCs): carry the necessary uncertainty (in expectations, or the mean parameters of an exponential family code) are well suited to learning from examples
58 Summary Machine learning systems have some way to go before they approach biological performance. Part of the problem has to do with limited representations of probabilistic beliefs. Distributed distributional representations (DDCs): carry the necessary uncertainty (in expectations, or the mean parameters of an exponential family code) are well suited to learning from examples and ease computation of expectations given a sufficiently rich family of encoding functionals
59 Summary Machine learning systems have some way to go before they approach biological performance. Part of the problem has to do with limited representations of probabilistic beliefs. Distributed distributional representations (DDCs): carry the necessary uncertainty (in expectations, or the mean parameters of an exponential family code) are well suited to learning from examples and ease computation of expectations given a sufficiently rich family of encoding functionals The DDC Helmholtz machine provides a local approach for learning, with a rich posterior (inferential) representation, which outperforms standard machine learning approaches.




60 Thanks Collaborators Eszter Vertes Kevin Li Peter Dayan Current Group Gergo Bohner Angus Chadwick Lea Duncker Kevin Li Kirsty McNaught Arne Meyer Virginia Rutten Joana Soldado-Magraner Eszter Vertes
Variational Autoencoders
 Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Probabilistic Reasoning in Deep Learning
 Probabilistic Reasoning in Deep Learning Dr Konstantina Palla, PhD palla@stats.ox.ac.uk September 2017 Deep Learning Indaba, Johannesburgh Konstantina Palla 1 / 39 OVERVIEW OF THE TALK Basics of Bayesian
Probabilistic Reasoning in Deep Learning Dr Konstantina Palla, PhD palla@stats.ox.ac.uk September 2017 Deep Learning Indaba, Johannesburgh Konstantina Palla 1 / 39 OVERVIEW OF THE TALK Basics of Bayesian
Auto-Encoding Variational Bayes
 Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Lecture 14: Deep Generative Learning
 Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Probabilistic & Unsupervised Learning
 Probabilistic & Unsupervised Learning Week 2: Latent Variable Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College
Probabilistic & Unsupervised Learning Week 2: Latent Variable Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College
Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning
 Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning Diederik (Durk) Kingma Danilo J. Rezende (*) Max Welling Shakir Mohamed (**) Stochastic Gradient Variational Inference Bayesian
Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning Diederik (Durk) Kingma Danilo J. Rezende (*) Max Welling Shakir Mohamed (**) Stochastic Gradient Variational Inference Bayesian
Variational Inference in TensorFlow. Danijar Hafner Stanford CS University College London, Google Brain
 Variational Inference in TensorFlow Danijar Hafner Stanford CS 20 2018-02-16 University College London, Google Brain Outline Variational Inference Tensorflow Distributions VAE in TensorFlow Variational
Variational Inference in TensorFlow Danijar Hafner Stanford CS 20 2018-02-16 University College London, Google Brain Outline Variational Inference Tensorflow Distributions VAE in TensorFlow Variational
Stochastic Variational Inference for Gaussian Process Latent Variable Models using Back Constraints
 Stochastic Variational Inference for Gaussian Process Latent Variable Models using Back Constraints Thang D. Bui Richard E. Turner tdb40@cam.ac.uk ret26@cam.ac.uk Computational and Biological Learning
Stochastic Variational Inference for Gaussian Process Latent Variable Models using Back Constraints Thang D. Bui Richard E. Turner tdb40@cam.ac.uk ret26@cam.ac.uk Computational and Biological Learning
Variational Inference via Stochastic Backpropagation
 Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation
Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation
Generative Adversarial Networks
 Generative Adversarial Networks Stefano Ermon, Aditya Grover Stanford University Lecture 10 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 10 1 / 17 Selected GANs https://github.com/hindupuravinash/the-gan-zoo
Generative Adversarial Networks Stefano Ermon, Aditya Grover Stanford University Lecture 10 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 10 1 / 17 Selected GANs https://github.com/hindupuravinash/the-gan-zoo
TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter Variational Autoencoders
 TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter 2018 Variational Autoencoders 1 The Latent Variable Cross-Entropy Objective We will now drop the negation and switch to argmax. Φ = argmax
TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter 2018 Variational Autoencoders 1 The Latent Variable Cross-Entropy Objective We will now drop the negation and switch to argmax. Φ = argmax
Probabilistic Graphical Models
 10-708 Probabilistic Graphical Models Homework 3 (v1.1.0) Due Apr 14, 7:00 PM Rules: 1. Homework is due on the due date at 7:00 PM. The homework should be submitted via Gradescope. Solution to each problem
10-708 Probabilistic Graphical Models Homework 3 (v1.1.0) Due Apr 14, 7:00 PM Rules: 1. Homework is due on the due date at 7:00 PM. The homework should be submitted via Gradescope. Solution to each problem
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Machine Learning: Logistic Regression. Lecture 04
 Machine Learning: Logistic Regression Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Supervised Learning Task = learn an (unkon function t : X T that maps input
Machine Learning: Logistic Regression Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Supervised Learning Task = learn an (unkon function t : X T that maps input
Variational Autoencoders. Presented by Alex Beatson Materials from Yann LeCun, Jaan Altosaar, Shakir Mohamed
 Variational Autoencoders Presented by Alex Beatson Materials from Yann LeCun, Jaan Altosaar, Shakir Mohamed Contents 1. Why unsupervised learning, and why generative models? (Selected slides from Yann
Variational Autoencoders Presented by Alex Beatson Materials from Yann LeCun, Jaan Altosaar, Shakir Mohamed Contents 1. Why unsupervised learning, and why generative models? (Selected slides from Yann
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Bayesian Deep Learning
 Bayesian Deep Learning Mohammad Emtiyaz Khan AIP (RIKEN), Tokyo http://emtiyaz.github.io emtiyaz.khan@riken.jp June 06, 2018 Mohammad Emtiyaz Khan 2018 1 What will you learn? Why is Bayesian inference
Bayesian Deep Learning Mohammad Emtiyaz Khan AIP (RIKEN), Tokyo http://emtiyaz.github.io emtiyaz.khan@riken.jp June 06, 2018 Mohammad Emtiyaz Khan 2018 1 What will you learn? Why is Bayesian inference
Generative models for missing value completion
 Generative models for missing value completion Kousuke Ariga Department of Computer Science and Engineering University of Washington Seattle, WA 98105 koar8470@cs.washington.edu Abstract Deep generative
Generative models for missing value completion Kousuke Ariga Department of Computer Science and Engineering University of Washington Seattle, WA 98105 koar8470@cs.washington.edu Abstract Deep generative
The Success of Deep Generative Models
 The Success of Deep Generative Models Jakub Tomczak AMLAB, University of Amsterdam CERN, 2018 What is AI about? What is AI about? Decision making: What is AI about? Decision making: new data High probability
The Success of Deep Generative Models Jakub Tomczak AMLAB, University of Amsterdam CERN, 2018 What is AI about? What is AI about? Decision making: What is AI about? Decision making: new data High probability
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Sandwiching the marginal likelihood using bidirectional Monte Carlo. Roger Grosse
 Sandwiching the marginal likelihood using bidirectional Monte Carlo Roger Grosse Ryan Adams Zoubin Ghahramani Introduction When comparing different statistical models, we d like a quantitative criterion
Sandwiching the marginal likelihood using bidirectional Monte Carlo Roger Grosse Ryan Adams Zoubin Ghahramani Introduction When comparing different statistical models, we d like a quantitative criterion
An Introduction to Statistical and Probabilistic Linear Models
 An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
arxiv: v1 [stat.ml] 6 Dec 2018
![arxiv: v1 [stat.ml] 6 Dec 2018](/thumbs/92/107935971.jpg "arxiv: v1 [stat.ml] 6 Dec 2018") missiwae: Deep Generative Modelling and Imputation of Incomplete Data arxiv:1812.02633v1 [stat.ml] 6 Dec 2018 Pierre-Alexandre Mattei Department of Computer Science IT University of Copenhagen pima@itu.dk
missiwae: Deep Generative Modelling and Imputation of Incomplete Data arxiv:1812.02633v1 [stat.ml] 6 Dec 2018 Pierre-Alexandre Mattei Department of Computer Science IT University of Copenhagen pima@itu.dk
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Deep latent variable models
 Deep latent variable models Pierre-Alexandre Mattei IT University of Copenhagen http://pamattei.github.io @pamattei 19 avril 2018 Séminaire de statistique du CNAM 1 Overview of talk A short introduction
Deep latent variable models Pierre-Alexandre Mattei IT University of Copenhagen http://pamattei.github.io @pamattei 19 avril 2018 Séminaire de statistique du CNAM 1 Overview of talk A short introduction
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Nonparametric Inference for Auto-Encoding Variational Bayes
 Nonparametric Inference for Auto-Encoding Variational Bayes Erik Bodin * Iman Malik * Carl Henrik Ek * Neill D. F. Campbell * University of Bristol University of Bath Variational approximations are an
Nonparametric Inference for Auto-Encoding Variational Bayes Erik Bodin * Iman Malik * Carl Henrik Ek * Neill D. F. Campbell * University of Bristol University of Bath Variational approximations are an
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
PILCO: A Model-Based and Data-Efficient Approach to Policy Search
 PILCO: A Model-Based and Data-Efficient Approach to Policy Search (M.P. Deisenroth and C.E. Rasmussen) CSC2541 November 4, 2016 PILCO Graphical Model PILCO Probabilistic Inference for Learning COntrol
PILCO: A Model-Based and Data-Efficient Approach to Policy Search (M.P. Deisenroth and C.E. Rasmussen) CSC2541 November 4, 2016 PILCO Graphical Model PILCO Probabilistic Inference for Learning COntrol
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2014
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Probabilistic & Unsupervised Learning
 Probabilistic & Unsupervised Learning Gaussian Processes Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College London
Probabilistic & Unsupervised Learning Gaussian Processes Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College London
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 8: Latent Variables, EM Yann LeCun
 Y. LeCun: Machine Learning and Pattern Recognition p. 1/? MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 8: Latent Variables, EM Yann LeCun The Courant Institute, New York University http://yann.lecun.com
Y. LeCun: Machine Learning and Pattern Recognition p. 1/? MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 8: Latent Variables, EM Yann LeCun The Courant Institute, New York University http://yann.lecun.com
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Efficient Likelihood-Free Inference
 Efficient Likelihood-Free Inference Michael Gutmann http://homepages.inf.ed.ac.uk/mgutmann Institute for Adaptive and Neural Computation School of Informatics, University of Edinburgh 8th November 2017
Efficient Likelihood-Free Inference Michael Gutmann http://homepages.inf.ed.ac.uk/mgutmann Institute for Adaptive and Neural Computation School of Informatics, University of Edinburgh 8th November 2017
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
A Unified View of Deep Generative Models
 SAILING LAB Laboratory for Statistical Artificial InteLigence & INtegreative Genomics A Unified View of Deep Generative Models Zhiting Hu and Eric Xing Petuum Inc. Carnegie Mellon University 1 Deep generative
SAILING LAB Laboratory for Statistical Artificial InteLigence & INtegreative Genomics A Unified View of Deep Generative Models Zhiting Hu and Eric Xing Petuum Inc. Carnegie Mellon University 1 Deep generative
Variational Autoencoders (VAEs)
") September 26 & October 3, 2017 Section 1 Preliminaries Kullback-Leibler divergence KL divergence (continuous case) p(x) andq(x) are two density distributions. Then the KL-divergence is defined as Z KL(p
September 26 & October 3, 2017 Section 1 Preliminaries Kullback-Leibler divergence KL divergence (continuous case) p(x) andq(x) are two density distributions. Then the KL-divergence is defined as Z KL(p
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
The Origin of Deep Learning. Lili Mou Jan, 2015
 The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
Ways to make neural networks generalize better
 Ways to make neural networks generalize better Seminar in Deep Learning University of Tartu 04 / 10 / 2014 Pihel Saatmann Topics Overview of ways to improve generalization Limiting the size of the weights
Ways to make neural networks generalize better Seminar in Deep Learning University of Tartu 04 / 10 / 2014 Pihel Saatmann Topics Overview of ways to improve generalization Limiting the size of the weights
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Part 4: Conditional Random Fields
 Part 4: Conditional Random Fields Sebastian Nowozin and Christoph H. Lampert Colorado Springs, 25th June 2011 1 / 39 Problem (Probabilistic Learning) Let d(y x) be the (unknown) true conditional distribution.
Part 4: Conditional Random Fields Sebastian Nowozin and Christoph H. Lampert Colorado Springs, 25th June 2011 1 / 39 Problem (Probabilistic Learning) Let d(y x) be the (unknown) true conditional distribution.
Deep Generative Models
 Deep Generative Models Durk Kingma Max Welling Deep Probabilistic Models Worksop Wednesday, 1st of Oct, 2014 D.P. Kingma Deep generative models Transformations between Bayes nets and Neural nets Transformation
Deep Generative Models Durk Kingma Max Welling Deep Probabilistic Models Worksop Wednesday, 1st of Oct, 2014 D.P. Kingma Deep generative models Transformations between Bayes nets and Neural nets Transformation
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Sequential Monte Carlo Methods for Bayesian Computation
 Sequential Monte Carlo Methods for Bayesian Computation A. Doucet Kyoto Sept. 2012 A. Doucet (MLSS Sept. 2012) Sept. 2012 1 / 136 Motivating Example 1: Generic Bayesian Model Let X be a vector parameter
Sequential Monte Carlo Methods for Bayesian Computation A. Doucet Kyoto Sept. 2012 A. Doucet (MLSS Sept. 2012) Sept. 2012 1 / 136 Motivating Example 1: Generic Bayesian Model Let X be a vector parameter
Variational Autoencoder
 Variational Autoencoder Göker Erdo gan August 8, 2017 The variational autoencoder (VA) [1] is a nonlinear latent variable model with an efficient gradient-based training procedure based on variational
Variational Autoencoder Göker Erdo gan August 8, 2017 The variational autoencoder (VA) [1] is a nonlinear latent variable model with an efficient gradient-based training procedure based on variational
Pattern Recognition and Machine Learning. Bishop Chapter 9: Mixture Models and EM
 Pattern Recognition and Machine Learning Chapter 9: Mixture Models and EM Thomas Mensink Jakob Verbeek October 11, 27 Le Menu 9.1 K-means clustering Getting the idea with a simple example 9.2 Mixtures
Pattern Recognition and Machine Learning Chapter 9: Mixture Models and EM Thomas Mensink Jakob Verbeek October 11, 27 Le Menu 9.1 K-means clustering Getting the idea with a simple example 9.2 Mixtures
PROBABILISTIC PROGRAMMING: BAYESIAN MODELLING MADE EASY
 PROBABILISTIC PROGRAMMING: BAYESIAN MODELLING MADE EASY Arto Klami Adapted from my talk in AIHelsinki seminar Dec 15, 2016 1 MOTIVATING INTRODUCTION Most of the artificial intelligence success stories
PROBABILISTIC PROGRAMMING: BAYESIAN MODELLING MADE EASY Arto Klami Adapted from my talk in AIHelsinki seminar Dec 15, 2016 1 MOTIVATING INTRODUCTION Most of the artificial intelligence success stories
FAST ADAPTATION IN GENERATIVE MODELS WITH GENERATIVE MATCHING NETWORKS
 FAST ADAPTATION IN GENERATIVE MODELS WITH GENERATIVE MATCHING NETWORKS Sergey Bartunov & Dmitry P. Vetrov National Research University Higher School of Economics (HSE), Yandex Moscow, Russia ABSTRACT We
FAST ADAPTATION IN GENERATIVE MODELS WITH GENERATIVE MATCHING NETWORKS Sergey Bartunov & Dmitry P. Vetrov National Research University Higher School of Economics (HSE), Yandex Moscow, Russia ABSTRACT We
Chapter 16. Structured Probabilistic Models for Deep Learning
 Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Latent Variable Models and EM Algorithm
 SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
Unsupervised Learning
 CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
Probabilistic Graphical Models for Image Analysis - Lecture 1
 Probabilistic Graphical Models for Image Analysis - Lecture 1 Alexey Gronskiy, Stefan Bauer 21 September 2018 Max Planck ETH Center for Learning Systems Overview 1. Motivation - Why Graphical Models 2.
Probabilistic Graphical Models for Image Analysis - Lecture 1 Alexey Gronskiy, Stefan Bauer 21 September 2018 Max Planck ETH Center for Learning Systems Overview 1. Motivation - Why Graphical Models 2.
Variational Auto Encoders
 Variational Auto Encoders 1 Recap Deep Neural Models consist of 2 primary components A feature extraction network Where important aspects of the data are amplified and projected into a linearly separable
Variational Auto Encoders 1 Recap Deep Neural Models consist of 2 primary components A feature extraction network Where important aspects of the data are amplified and projected into a linearly separable
Does the Wake-sleep Algorithm Produce Good Density Estimators?
 Does the Wake-sleep Algorithm Produce Good Density Estimators? Brendan J. Frey, Geoffrey E. Hinton Peter Dayan Department of Computer Science Department of Brain and Cognitive Sciences University of Toronto
Does the Wake-sleep Algorithm Produce Good Density Estimators? Brendan J. Frey, Geoffrey E. Hinton Peter Dayan Department of Computer Science Department of Brain and Cognitive Sciences University of Toronto
Parameter Estimation. Industrial AI Lab.
 Parameter Estimation Industrial AI Lab. Generative Model X Y w y = ω T x + ε ε~n(0, σ 2 ) σ 2 2 Maximum Likelihood Estimation (MLE) Estimate parameters θ ω, σ 2 given a generative model Given observed
Parameter Estimation Industrial AI Lab. Generative Model X Y w y = ω T x + ε ε~n(0, σ 2 ) σ 2 2 Maximum Likelihood Estimation (MLE) Estimate parameters θ ω, σ 2 given a generative model Given observed
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
MMD GAN 1 Fisher GAN 2
 MMD GAN 1 Fisher GAN 1 Chun-Liang Li, Wei-Cheng Chang, Yu Cheng, Yiming Yang, and Barnabás Póczos (CMU, IBM Research) Youssef Mroueh, and Tom Sercu (IBM Research) Presented by Rui-Yi(Roy) Zhang Decemeber
MMD GAN 1 Fisher GAN 1 Chun-Liang Li, Wei-Cheng Chang, Yu Cheng, Yiming Yang, and Barnabás Póczos (CMU, IBM Research) Youssef Mroueh, and Tom Sercu (IBM Research) Presented by Rui-Yi(Roy) Zhang Decemeber
Need for Sampling in Machine Learning. Sargur Srihari
 Need for Sampling in Machine Learning Sargur srihari@cedar.buffalo.edu 1 Rationale for Sampling 1. ML methods model data with probability distributions E.g., p(x,y; θ) 2. Models are used to answer queries,
Need for Sampling in Machine Learning Sargur srihari@cedar.buffalo.edu 1 Rationale for Sampling 1. ML methods model data with probability distributions E.g., p(x,y; θ) 2. Models are used to answer queries,
Unsupervised Discovery of Nonlinear Structure Using Contrastive Backpropagation
 Cognitive Science 30 (2006) 725 731 Copyright 2006 Cognitive Science Society, Inc. All rights reserved. Unsupervised Discovery of Nonlinear Structure Using Contrastive Backpropagation Geoffrey Hinton,
Cognitive Science 30 (2006) 725 731 Copyright 2006 Cognitive Science Society, Inc. All rights reserved. Unsupervised Discovery of Nonlinear Structure Using Contrastive Backpropagation Geoffrey Hinton,
Lecture 3: Pattern Classification
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Deep Variational Inference. FLARE Reading Group Presentation Wesley Tansey 9/28/2016
 Deep Variational Inference FLARE Reading Group Presentation Wesley Tansey 9/28/2016 What is Variational Inference? What is Variational Inference? Want to estimate some distribution, p*(x) p*(x) What is
Deep Variational Inference FLARE Reading Group Presentation Wesley Tansey 9/28/2016 What is Variational Inference? What is Variational Inference? Want to estimate some distribution, p*(x) p*(x) What is
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Probabilistic & Bayesian deep learning. Andreas Damianou
 Probabilistic & Bayesian deep learning Andreas Damianou Amazon Research Cambridge, UK Talk at University of Sheffield, 19 March 2019 In this talk Not in this talk: CRFs, Boltzmann machines,... In this
Probabilistic & Bayesian deep learning Andreas Damianou Amazon Research Cambridge, UK Talk at University of Sheffield, 19 March 2019 In this talk Not in this talk: CRFs, Boltzmann machines,... In this
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Denoising Criterion for Variational Auto-Encoding Framework
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Denoising Criterion for Variational Auto-Encoding Framework Daniel Jiwoong Im, Sungjin Ahn, Roland Memisevic, Yoshua
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Denoising Criterion for Variational Auto-Encoding Framework Daniel Jiwoong Im, Sungjin Ahn, Roland Memisevic, Yoshua
Deep Feedforward Networks. Lecture slides for Chapter 6 of Deep Learning Ian Goodfellow Last updated
 Deep Feedforward Networks Lecture slides for Chapter 6 of Deep Learning www.deeplearningbook.org Ian Goodfellow Last updated 2016-10-04 Roadmap Example: Learning XOR Gradient-Based Learning Hidden Units
Deep Feedforward Networks Lecture slides for Chapter 6 of Deep Learning www.deeplearningbook.org Ian Goodfellow Last updated 2016-10-04 Roadmap Example: Learning XOR Gradient-Based Learning Hidden Units
PROBABILISTIC PROGRAMMING: BAYESIAN MODELLING MADE EASY. Arto Klami
 PROBABILISTIC PROGRAMMING: BAYESIAN MODELLING MADE EASY Arto Klami 1 PROBABILISTIC PROGRAMMING Probabilistic programming is to probabilistic modelling as deep learning is to neural networks (Antti Honkela,
PROBABILISTIC PROGRAMMING: BAYESIAN MODELLING MADE EASY Arto Klami 1 PROBABILISTIC PROGRAMMING Probabilistic programming is to probabilistic modelling as deep learning is to neural networks (Antti Honkela,
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
Mathematical Formulation of Our Example
 Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Experiments on the Consciousness Prior
 Yoshua Bengio and William Fedus UNIVERSITÉ DE MONTRÉAL, MILA Abstract Experiments are proposed to explore a novel prior for representation learning, which can be combined with other priors in order to
Yoshua Bengio and William Fedus UNIVERSITÉ DE MONTRÉAL, MILA Abstract Experiments are proposed to explore a novel prior for representation learning, which can be combined with other priors in order to
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
Learning Deep Architectures
 Learning Deep Architectures Yoshua Bengio, U. Montreal Microsoft Cambridge, U.K. July 7th, 2009, Montreal Thanks to: Aaron Courville, Pascal Vincent, Dumitru Erhan, Olivier Delalleau, Olivier Breuleux,
Learning Deep Architectures Yoshua Bengio, U. Montreal Microsoft Cambridge, U.K. July 7th, 2009, Montreal Thanks to: Aaron Courville, Pascal Vincent, Dumitru Erhan, Olivier Delalleau, Olivier Breuleux,
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
6.867 Machine Learning
 6.867 Machine Learning Problem set 1 Due Thursday, September 19, in class What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
6.867 Machine Learning Problem set 1 Due Thursday, September 19, in class What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
Greedy Layer-Wise Training of Deep Networks
 Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
A Variance Modeling Framework Based on Variational Autoencoders for Speech Enhancement
 A Variance Modeling Framework Based on Variational Autoencoders for Speech Enhancement Simon Leglaive 1 Laurent Girin 1,2 Radu Horaud 1 1: Inria Grenoble Rhône-Alpes 2: Univ. Grenoble Alpes, Grenoble INP,
A Variance Modeling Framework Based on Variational Autoencoders for Speech Enhancement Simon Leglaive 1 Laurent Girin 1,2 Radu Horaud 1 1: Inria Grenoble Rhône-Alpes 2: Univ. Grenoble Alpes, Grenoble INP,
The Particle Filter. PD Dr. Rudolph Triebel Computer Vision Group. Machine Learning for Computer Vision
 The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts III-IV
 Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts III-IV Aapo Hyvärinen Gatsby Unit University College London Part III: Estimation of unnormalized models Often,
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts III-IV Aapo Hyvärinen Gatsby Unit University College London Part III: Estimation of unnormalized models Often,
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Notes on Adversarial Examples
 Notes on Adversarial Examples David Meyer dmm@{1-4-5.net,uoregon.edu,...} March 14, 2017 1 Introduction The surprising discovery of adversarial examples by Szegedy et al. [6] has led to new ways of thinking
Notes on Adversarial Examples David Meyer dmm@{1-4-5.net,uoregon.edu,...} March 14, 2017 1 Introduction The surprising discovery of adversarial examples by Szegedy et al. [6] has led to new ways of thinking