Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
|
|
|
- Beverly William Merritt
- 5 years ago
- Views:
Transcription
1 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas
2 Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian estimation Linear models Linear Regression, Logistic Regression, SVMs, Perceptron, Naïve Bayes under certain restrictions Non-linear models Decision trees, Neural networks, Kernels Non-parametric algorithms Nearest neighbor algorithms
3 Key Perspective on Learning Representation Evaluation or Loss Function Error + regularization Learning as Optimization Closed form Greedy search Gradient ascent 6
4 What you should know in Decision Tree Learning? Representation What it can represent and how Size/Complexity of the representation Heuristics for selecting the next attribute Information gain, one-step look ahead, gain ratio What makes the heuristic good? What are its cons? Complexity analysis Sample exam question: if I tweak the selection heuristic, how will that change the complexity and quality? Overfitting and Pruning Handling missing data Handling continuous attributes
5 Noise Small number of examples associated with each leaf What if only one example is associated with a leaf. Can you believe it? Coincidental regularities
6 Probability Theory Be able to apply and understand Axioms of probability Distribution vs density Conditional probability Sum-rule, chain-rule Bayes rule Sample question: If you know P(A B), do you have enough information to compute P(B A)?
7 Maximum Likelihood Estimation Data: Observed set D of α H Heads and α T Tails Hypothesis: Binomial distribution Learning: finding θ is an optimization problem What s the objective function? MLE: Choose θ to maximize probability of D
8 How to get a closed form solution? Set derivative to zero, and solve! d ln P (D ) d = d d [ln H (1 ) T ] = d d [ H ln + T ln(1 )] = H d d ln + = H T 1 T d d =0 ln(1 )
9 What if I have prior beliefs? Billionaire says: Wait, I know that the thumbtack is close to What can you do for me now? You say: I can learn it the Bayesian way Rather than estimating a single θ, we obtain a distribution over possible values of θ In the beginning Observe flips e.g.: {tails, tails} After observations


 1 P ( D)")
10 Bayesian Learning Use Bayes rule: Data Likelihood Prior Posterior Normalization Or equivalently: Also, for uniform priors: à reduces to MLE objective P ( ) 1 P ( D) P (D )
11 MAP: Maximum a Posteriori Approximation As more data is observed, Beta is more certain MAP: use most likely parameter to approximate the expectation
12 What you should know? MLE vs MAP and the relationship between the two MLE learning and Bayesian learning Thumbtack example Gaussians
13 The Naïve Bayes Classifier Given: Prior P(Y) Y n conditionally independent features X given the class Y For each X i, we have likelihood P(X i Y) X 1 X 2 X n Decision rule:
14 Subtleties of Naïve Bayes What is the hypothesis space? What kind of functions can it learn? When does it work and when it does not? Correlated features MLE vs Bayesian learning of Naïve Bayes Gaussian Naïve Bayes
15 Generative vs. Discriminative Classifiers Want to Learn: h:x! Y X features Y target classes Generative classifier, e.g., Naïve Bayes: Assume some functional form for P(X Y), P(Y) Estimate parameters of P(X Y), P(Y) directly from training data Use Bayes rule to calculate P(Y X= x) This is a generative model Indirect computation of P(Y X) through Bayes rule As a result, can also generate a sample of the data, P(X) = y P(y) P(X y) Discriminative classifiers, e.g., Logistic Regression: Assume some functional form for P(Y X) Estimate parameters of P(Y X) directly from training data This is the discriminative model Directly learn P(Y X) But cannot obtain a sample of the data, because P(X) is not available P(Y X) P(X Y) P(Y) 20
16 Linear Regression Argmin w Loss(h w ) h w (x) = w 1 x + w 0 w 1 = N Σ (x j y j ) ( Σ x j )( Σ y j ) N Σ (x j2 ) ( Σ x j ) 2 w 0 = ( Σ (y j ) w 1 ( Σ x j )/N
17 Logistic Regression n Learn P(Y X) directly! Assume a particular functional form Not differentiable P(Y)=0 P(Y)=1 22
18 Logistic Regression n Learn P(Y X) directly! Assume a particular functional form Logistic Function Aka Sigmoid 23
19 Issues in Linear and Logistic Regression Overfitting avoidance: Regularization L1 vs L2 regularization
20 What you should know about Logistic Regression (LR) Gaussian Naïve Bayes with class-independent variances representationally equivalent to LR Solution differs because of objective (loss) function In general, NB and LR make different assumptions NB: Features independent given class! assumption on P(X Y) LR: Functional form of P(Y X), no assumption on P(X Y) LR is a linear classifier decision rule is a hyperplane LR optimized by conditional likelihood no closed-form solution concave! global optimum with gradient ascent Maximum conditional a posteriori corresponds to regularization Convergence rates GNB (usually) needs less data LR (usually) gets to better solutions in the limit
21
22 From Logistic Regression to the Perceptron: 2 easy steps! Logistic Regression: (in vector notation): y is {0,1} Perceptron: y is {0,1}, y(x;w) is prediction given w Differences? w = w + j [yj p(yj x j,w)]f(x j ) w = w +[y y(x;w)]f(x) Drop the Σ j over training examples: online vs. batch learning Drop the dist n: probabilistic vs. error driven learning
23 Properties of Perceptrons Separability: some parameters get the training set perfectly correct Separable Convergence: if the training is separable, perceptron will eventually converge (binary case) Non-Separable
24 Problems with the Perceptron Noise: if the data isn t separable, weights might thrash Averaging weight vectors over time can help (averaged perceptron) Mediocre generalization: finds a barely separating solution Overtraining: test / validation accuracy usually rises, then falls Overtraining is a kind of overfitting
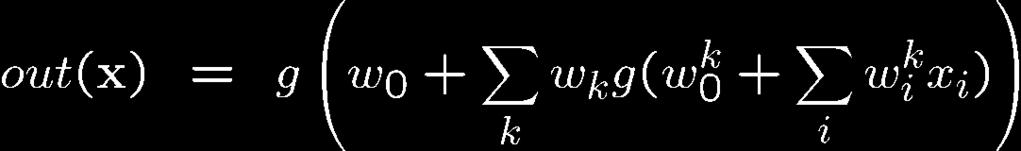
25
26
27 Neural networks: What you should know? How does it learn non-linear functions? Can it learn, for example an XOR function? Draw a neural network for it with appropriate weights Backprop Overfitting What kind of functions can it learn? Tradeoff number of hidden units number of layers
28 Linear SVM denotes +1 Aim: Learn a large margin classifier Mathematical Formulation: maximize 2 w x 2 x + x + denotes -1 Margin such that T For y =+ 1, wx+ b 1 i T For y = 1, wx+ b 1 i i i x - Common theme in machine learning: LEARNING IS OPTIMIZATION x 1
29 Solving the Optimization Problem n 1 2 minimize L ( w, b, α ) = w α y ( w x + b) 1 ( T ) p i i i i 2 i= 1 s.t. αi 0 Lagrangian Dual Problem maximize s.t. αi 0 1 n n n T αi αα i jyy i j i j i= 1 2 i= 1 j= 1 n xx, and i= 1 α y i i = 0
30 Non-linear SVMs: Feature Space n General idea: the original input space can be mapped to some higher-dimensional feature space where the training set is separable: Φ: x φ(x) This slide is courtesy of
31 Nonlinear SVMs: The Kernel Trick n With this mapping, our discriminant function is now: T T g( x) = w φ( x) + b= αφ i ( xi) φ( x) + b i SV n No need to know this mapping explicitly, because we only use the dot product of feature vectors in both the training and test. n A kernel function is defined as a function that corresponds to a dot product of two feature vectors in some expanded feature space: T K( x, x ) φ( x ) φ( x ) i j i j
32 Nonlinear SVMs: The Kernel Trick n Examples of commonly-used kernel functions: q q Linear kernel: Polynomial kernel: K ( x, x ) = x x T i j i j T K ( x, x ) = (1 + x x ) i j i j p q q Gaussian (Radial-Basis Function (RBF) ) kernel: Sigmoid: i j K( xi, xj) = exp( x x ) 2 2σ K( x, x ) = tanh( β x x + β ) T i j 0 i j 1 2 n In general, functions that satisfy Mercer s condition can be kernel functions: Kernel matrix should be positive semidefinite.
33 K-nearest Neighbor Distance measure Most common: Euclidean Choosing k Increasing k reduces variance, increases bias For high-dimensional space, problem that the nearest neighbor may not be very close at all! Memory-based technique. Must make a pass through the data for each classification. This can be prohibitive for large data sets.
34 Nearest Neighbor Advantages variable-sized hypothesis space Learning is extremely efficient however growing a good kd-tree can be expensive Very flexible decision boundaries Disadvantages distance function must be carefully chosen Irrelevant or correlated features must be eliminated Typically cannot handle more than 30 features Computational costs: Memory and classification-time computation
35 Locally Weighted Linear Regression: LWLR Idea: k-nn forms local approximation for each query point x q Why not form an explicit approximation f" for region surrounding x q Fit linear function to k nearest neighbors Fit quadratic,... Thus producing ``piecewise approximation'' to f" Minimize error over k nearest neighbors of x q Minimize error entire set of examples, weighting by distances Combine two above
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Logistic Regression. Vibhav Gogate The University of Texas at Dallas. Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld.
 Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES. Supervised Learning
 LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Generative v. Discriminative classifiers Intuition
 Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 1 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features
Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 1 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features
Last Time. Today. Bayesian Learning. The Distributions We Love. CSE 446 Gaussian Naïve Bayes & Logistic Regression
 CSE 446 Gaussian Naïve Bayes & Logistic Regression Winter 22 Dan Weld Learning Gaussians Naïve Bayes Last Time Gaussians Naïve Bayes Logistic Regression Today Some slides from Carlos Guestrin, Luke Zettlemoyer
CSE 446 Gaussian Naïve Bayes & Logistic Regression Winter 22 Dan Weld Learning Gaussians Naïve Bayes Last Time Gaussians Naïve Bayes Logistic Regression Today Some slides from Carlos Guestrin, Luke Zettlemoyer
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
Midterm: CS 6375 Spring 2018
 Midterm: CS 6375 Spring 2018 The exam is closed book (1 cheat sheet allowed). Answer the questions in the spaces provided on the question sheets. If you run out of room for an answer, use an additional
Midterm: CS 6375 Spring 2018 The exam is closed book (1 cheat sheet allowed). Answer the questions in the spaces provided on the question sheets. If you run out of room for an answer, use an additional
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
EE 511 Online Learning Perceptron
 Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Kevin Jamison EE 511 Online Learning Perceptron Instructor: Hanna Hajishirzi hannaneh@washington.edu
Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Kevin Jamison EE 511 Online Learning Perceptron Instructor: Hanna Hajishirzi hannaneh@washington.edu
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Classification: Logistic Regression NB & LR connections Readings: Barber 17.4 Dhruv Batra Virginia Tech Administrativia HW2 Due: Friday 3/6, 3/15, 11:55pm
ECE 5984: Introduction to Machine Learning Topics: Classification: Logistic Regression NB & LR connections Readings: Barber 17.4 Dhruv Batra Virginia Tech Administrativia HW2 Due: Friday 3/6, 3/15, 11:55pm
Machine Learning, Midterm Exam: Spring 2009 SOLUTION
 10-601 Machine Learning, Midterm Exam: Spring 2009 SOLUTION March 4, 2009 Please put your name at the top of the table below. If you need more room to work out your answer to a question, use the back of
10-601 Machine Learning, Midterm Exam: Spring 2009 SOLUTION March 4, 2009 Please put your name at the top of the table below. If you need more room to work out your answer to a question, use the back of
Week 5: Logistic Regression & Neural Networks
 Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Machine Learning Tom M. Mitchell Machine Learning Department Carnegie Mellon University. September 20, 2012
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 20, 2012 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 20, 2012 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Point Estimation. Vibhav Gogate The University of Texas at Dallas
 Point Estimation Vibhav Gogate The University of Texas at Dallas Some slides courtesy of Carlos Guestrin, Chris Bishop, Dan Weld and Luke Zettlemoyer. Basics: Expectation and Variance Binary Variables
Point Estimation Vibhav Gogate The University of Texas at Dallas Some slides courtesy of Carlos Guestrin, Chris Bishop, Dan Weld and Luke Zettlemoyer. Basics: Expectation and Variance Binary Variables
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Machine Learning Gaussian Naïve Bayes Big Picture
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 27, 2011 Today: Naïve Bayes Big Picture Logistic regression Gradient ascent Generative discriminative
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 27, 2011 Today: Naïve Bayes Big Picture Logistic regression Gradient ascent Generative discriminative
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Machine Learning
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Outline. Supervised Learning. Hong Chang. Institute of Computing Technology, Chinese Academy of Sciences. Machine Learning Methods (Fall 2012)
") Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Introduction to SVM and RVM
 Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Introduc)on to Bayesian methods (con)nued) - Lecture 16
on to Bayesian methods (con)nued) - Lecture 16") Introduc)on to Bayesian methods (con)nued) - Lecture 16 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Vibhav Gogate Outline of lectures Review of
Introduc)on to Bayesian methods (con)nued) - Lecture 16 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Vibhav Gogate Outline of lectures Review of
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 8 Feb. 12, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
Generative v. Discriminative classifiers Intuition
 Logistic Regression (Continued) Generative v. Discriminative Decision rees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University January 31 st, 2007 2005-2007 Carlos Guestrin 1 Generative
Logistic Regression (Continued) Generative v. Discriminative Decision rees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University January 31 st, 2007 2005-2007 Carlos Guestrin 1 Generative
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 2, 2015 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 2, 2015 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Generative v. Discriminative classifiers Intuition
 Logistic Regression Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features Y target
Logistic Regression Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features Y target
CS4495/6495 Introduction to Computer Vision. 8C-L3 Support Vector Machines
 CS4495/6495 Introduction to Computer Vision 8C-L3 Support Vector Machines Discriminative classifiers Discriminative classifiers find a division (surface) in feature space that separates the classes Several
CS4495/6495 Introduction to Computer Vision 8C-L3 Support Vector Machines Discriminative classifiers Discriminative classifiers find a division (surface) in feature space that separates the classes Several
Support Vector Machines. Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 4, 2015 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 4, 2015 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
Learning: Binary Perceptron. Examples: Perceptron. Separable Case. In the space of feature vectors
 Linear Classifiers CS 88 Artificial Intelligence Perceptrons and Logistic Regression Pieter Abbeel & Dan Klein University of California, Berkeley Feature Vectors Some (Simplified) Biology Very loose inspiration
Linear Classifiers CS 88 Artificial Intelligence Perceptrons and Logistic Regression Pieter Abbeel & Dan Klein University of California, Berkeley Feature Vectors Some (Simplified) Biology Very loose inspiration
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Artificial Intelligence Roman Barták
 Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
DEPARTMENT OF COMPUTER SCIENCE Autumn Semester MACHINE LEARNING AND ADAPTIVE INTELLIGENCE
 Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Introduction to Machine Learning Midterm Exam Solutions
 10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Nearest Neighbor. Machine Learning CSE546 Kevin Jamieson University of Washington. October 26, Kevin Jamieson 2
 Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
Naïve Bayes Introduction to Machine Learning. Matt Gormley Lecture 18 Oct. 31, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Machine Learning, Midterm Exam
 10-601 Machine Learning, Midterm Exam Instructors: Tom Mitchell, Ziv Bar-Joseph Wednesday 12 th December, 2012 There are 9 questions, for a total of 100 points. This exam has 20 pages, make sure you have
10-601 Machine Learning, Midterm Exam Instructors: Tom Mitchell, Ziv Bar-Joseph Wednesday 12 th December, 2012 There are 9 questions, for a total of 100 points. This exam has 20 pages, make sure you have
FINAL EXAM: FALL 2013 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 FINAL EXAM: FALL 2013 CS 6375 INSTRUCTOR: VIBHAV GOGATE You are allowed a two-page cheat sheet. You are also allowed to use a calculator. Answer the questions in the spaces provided on the question sheets.
FINAL EXAM: FALL 2013 CS 6375 INSTRUCTOR: VIBHAV GOGATE You are allowed a two-page cheat sheet. You are also allowed to use a calculator. Answer the questions in the spaces provided on the question sheets.
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
An Introduction to Statistical and Probabilistic Linear Models
 An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
Lecture 3: Pattern Classification
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machines
 Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Support Vector Machines
 Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
1 Machine Learning Concepts (16 points)
") CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Support Vector Machines and Kernel Methods
 2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
Day 5: Generative models, structured classification
 Day 5: Generative models, structured classification Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 22 June 2018 Linear regression
Day 5: Generative models, structured classification Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 22 June 2018 Linear regression
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
CS 188: Artificial Intelligence. Outline
 CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
Introduction to Machine Learning
 1, DATA11002 Introduction to Machine Learning Lecturer: Teemu Roos TAs: Ville Hyvönen and Janne Leppä-aho Department of Computer Science University of Helsinki (based in part on material by Patrik Hoyer
1, DATA11002 Introduction to Machine Learning Lecturer: Teemu Roos TAs: Ville Hyvönen and Janne Leppä-aho Department of Computer Science University of Helsinki (based in part on material by Patrik Hoyer
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, 2013
 Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
Introduction to Bayesian Learning. Machine Learning Fall 2018
 Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Machine Learning, Fall 2012 Homework 2
 0-60 Machine Learning, Fall 202 Homework 2 Instructors: Tom Mitchell, Ziv Bar-Joseph TA in charge: Selen Uguroglu email: sugurogl@cs.cmu.edu SOLUTIONS Naive Bayes, 20 points Problem. Basic concepts, 0
0-60 Machine Learning, Fall 202 Homework 2 Instructors: Tom Mitchell, Ziv Bar-Joseph TA in charge: Selen Uguroglu email: sugurogl@cs.cmu.edu SOLUTIONS Naive Bayes, 20 points Problem. Basic concepts, 0
Machine Learning (CSE 446): Neural Networks
: Neural Networks") Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
SVMs, Duality and the Kernel Trick
 SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Notes on Discriminant Functions and Optimal Classification
 Notes on Discriminant Functions and Optimal Classification Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Discriminant Functions Consider a classification problem
Notes on Discriminant Functions and Optimal Classification Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Discriminant Functions Consider a classification problem