Probabilistic & Bayesian deep learning. Andreas Damianou
|
|
|
- Kevin Tyler
- 5 years ago
- Views:
Transcription

1 Probabilistic & Bayesian deep learning Andreas Damianou Amazon Research Cambridge, UK Talk at University of Sheffield, 19 March 2019

2 In this talk Not in this talk: CRFs, Boltzmann machines,...
3 In this talk Not in this talk: CRFs, Boltzmann machines,...
4 A standard neural network x 1 x 2 x 3... x q ϕ 1 w 1 ϕ 2 w2 ϕ 3 w3... w q ϕ q Y Define: φ j = φ(x j ) and f j = w j φ j (ignore bias for now) Once we ve defined all w s with back-prop, then f (and the whole network) becomes deterministic. What does that imply?
5 Trained neural network is deterministic. Implications? Generalization: Overfitting occurs. Need for ad-hoc invention of regularizers: dropout, early stopping... Data generation: A model which generalizes well, should also understand -or even be able to create ( imagine )- variations. No predictive uncertainty: Uncertainty needs to be propagated across the model to be reliable.

6 Need for uncertainty Reinforcement learning Critical predictive systems Active learning Semi-automatic systems Scarce data scenarios...
7 BNN with priors on its weights x 1 x 2 x 3... x q x 1 x 2 x 3... x q ϕ 1 ϕ 2 ϕ 3... ϕ q ϕ 1 ϕ 2 ϕ 3... ϕ q w1 w2 w3 w q q(w 1 ) q(w 2 ) q(w3) q(w q ) Y Y

8 BNN with priors on its weights x 1 x 2 x 3... x q x 1 x 2 x 3... x q ϕ 1 ϕ 2 ϕ 3... ϕ q ϕ 1 ϕ 2 ϕ 3... ϕ q Y Y
9 Probabilistic re-formulation DNN: y = g(w, x) = w 1 ϕ(w 2 ϕ(... x)) Training minimizing loss: arg min W 1 N (g(w, x i ) y i ) 2 + λ 2 i=1 i }{{} fit w i } {{ } regularizer Equivalent probabilistic view for regression, maximizing posterior probability: arg max W log p(y x, W) }{{} fit where p(y x, W) N and p(w) Laplace + log p(w) }{{} regularizer
10 Probabilistic re-formulation DNN: y = g(w, x) = w 1 ϕ(w 2 ϕ(... x)) Training minimizing loss: arg min W 1 N (g(w, x i ) y i ) 2 + λ 2 i=1 i }{{} fit w i } {{ } regularizer Equivalent probabilistic view for regression, maximizing posterior probability: arg max W log p(y x, W) }{{} fit where p(y x, W) N and p(w) Laplace + log p(w) }{{} regularizer
11 Probabilistic re-formulation DNN: y = g(w, x) = w 1 ϕ(w 2 ϕ(... x)) Training minimizing loss: arg min W 1 N (g(w, x i ) y i ) 2 + λ 2 i=1 i }{{} fit w i } {{ } regularizer Equivalent probabilistic view for regression, maximizing posterior probability: arg max W log p(y x, W) }{{} fit where p(y x, W) N and p(w) Laplace + log p(w) }{{} regularizer
12 Integrating out weights Define: D = (x, y) Remember Bayes rule: p(w D) = p(d w)p(w) p(d) = p(d w)p(w)dw For Bayesian inference, weights need to also be integrated out. This gives us a properly defined posterior on the parametres.
13 (Bayesian) Occam s Razor A plurality is not to be posited without necessity. W. of Ockham Everything should be made as simple as possible, but not simpler. A. Einstein Evidence is higher for the model that is not unnecessarily complex but still explains the data D.
14 Bayesian Inference Remember: Separation of Model and Inference
15 Inference p(d) (and hence p(w D)) is difficult to compute because of the nonlinear way in which w appears through g. Attempt at variational inference: where KL (q(w; θ) p(w D)) = log(p(d)) L(θ) }{{}}{{} minimize maximize L(θ) = E q(w;θ) [log p(d, w)] +H [q(w; θ)] }{{} F Term in red is still problematic. Solution: MC. Such approaches can be formulated as black-box inferences.
16 Inference p(d) (and hence p(w D)) is difficult to compute because of the nonlinear way in which w appears through g. Attempt at variational inference: where KL (q(w; θ) p(w D)) = log(p(d)) L(θ) }{{}}{{} minimize maximize L(θ) = E q(w;θ) [log p(d, w)] +H [q(w; θ)] }{{} F Term in red is still problematic. Solution: MC. Such approaches can be formulated as black-box inferences.
17 Inference p(d) (and hence p(w D)) is difficult to compute because of the nonlinear way in which w appears through g. Attempt at variational inference: where KL (q(w; θ) p(w D)) = log(p(d)) L(θ) }{{}}{{} minimize maximize L(θ) = E q(w;θ) [log p(d, w)] +H [q(w; θ)] }{{} F Term in red is still problematic. Solution: MC. Such approaches can be formulated as black-box inferences.

18 Credit: Tushar Tank
19 Credit: Tushar Tank
20 Credit: Tushar Tank
21 Credit: Tushar Tank
22 Inference: Score function method θ F = θ E q(w;θ) [log p(d, w)] = E q(w;θ) [p(d, w) θ log q(w; θ)] 1 K p(d, w (k) ) θ log q(w (k) ; θ), K i=1 w (k) iid q(w; θ) (Paisley et al., 2012; Ranganath et al., 2014; Mnih and Gregor, 2014, Ruiz et al. 2016)
23 Inference: Reparameterization gradient Reparametrize w as a transformation T of a simpler variable ɛ: w = T (ɛ; θ) q(ɛ) is now independent of θ θ F = θ E q(w;θ) [log p(d, w)] = E q(ɛ) [ w p(d, w) w=t (ɛ;θ) θ T (ɛ; θ) ] For example: w N (µ, σ) T w = µ + σ ɛ, ɛ N (0, 1) MC by sampling from q(ɛ) (thus obtaining samples from w through T ) (Salimans and Knowles, 2013; Kingma and Welling, 2014, Ruiz et al. 2016)
24 Inference: Reparameterization gradient Reparametrize w as a transformation T of a simpler variable ɛ: w = T (ɛ; θ) q(ɛ) is now independent of θ θ F = θ E q(w;θ) [log p(d, w)] = E q(ɛ) [ w p(d, w) w=t (ɛ;θ) θ T (ɛ; θ) ] For example: w N (µ, σ) T w = µ + σ ɛ, ɛ N (0, 1) MC by sampling from q(ɛ) (thus obtaining samples from w through T ) (Salimans and Knowles, 2013; Kingma and Welling, 2014, Ruiz et al. 2016)
25 Inference: Reparameterization gradient Reparametrize w as a transformation T of a simpler variable ɛ: w = T (ɛ; θ) q(ɛ) is now independent of θ θ F = θ E q(w;θ) [log p(d, w)] = E q(ɛ) [ w p(d, w) w=t (ɛ;θ) θ T (ɛ; θ) ] For example: w N (µ, σ) T w = µ + σ ɛ, ɛ N (0, 1) MC by sampling from q(ɛ) (thus obtaining samples from w through T ) (Salimans and Knowles, 2013; Kingma and Welling, 2014, Ruiz et al. 2016)
26 Inference: Reparameterization gradient Reparametrize w as a transformation T of a simpler variable ɛ: w = T (ɛ; θ) q(ɛ) is now independent of θ θ F = θ E q(w;θ) [log p(d, w)] = E q(ɛ) [ w p(d, w) w=t (ɛ;θ) θ T (ɛ; θ) ] For example: w N (µ, σ) T w = µ + σ ɛ, ɛ N (0, 1) MC by sampling from q(ɛ) (thus obtaining samples from w through T ) (Salimans and Knowles, 2013; Kingma and Welling, 2014, Ruiz et al. 2016)
27 Black-box VI
28 Black-box VI (github.com/blei-lab/edward)
29 Priors on weights (what we saw before) X ϕ ϕ... ϕ H. H ϕ ϕ... ϕ Y
30 From NN to GP X... ϕ ϕ... ϕ... H. H Y G G... ϕ ϕ... ϕ... NN: H 2 = W 2 φ(h 1 ) GP: φ is dimensional so: H 2 = f 2 (H 1 ; θ 2 ) + ɛ NN: p(w) GP: p(f( )) VAE can be seen as a special case of this
31 From NN to GP X... ϕ ϕ... ϕ... H. H Y G G... ϕ ϕ... ϕ... NN: H 2 = W 2 φ(h 1 ) GP: φ is dimensional so: H 2 = f 2 (H 1 ; θ 2 ) + ɛ NN: p(w) GP: p(f( )) VAE can be seen as a special case of this
32 From NN to GP X... ϕ ϕ... ϕ... H. H Y G G... ϕ ϕ... ϕ... NN: H 2 = W 2 φ(h 1 ) GP: φ is dimensional so: H 2 = f 2 (H 1 ; θ 2 ) + ɛ NN: p(w) GP: p(f( )) VAE can be seen as a special case of this
33 From NN to GP X... ϕ ϕ... ϕ... H. H Y G G... ϕ ϕ... ϕ... Real world perfectly described by unobserved latent variables: Ĥ But we only observe noisy high-dimensional data: Y We try to interpret the world and infer the latents: H Ĥ Inference: p(h Y) = p(y H)p(H) p(y)
34 Deep Gaussian processes Uncertainty about parameters: Check. Uncertainty about structure? Deep GP simultaneously brings in: prior on weights input/latent space is kernalized stochasticity in the warping
35 Introducing Gaussian Processes: A Gaussian distribution depends on a mean and a covariance matrix. A Gaussian process depends on a mean and a covariance function.
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56 Samples from a 1-D Gaussian
57 Samples from a 1-D Gaussian
58 Samples from a 1-D Gaussian
59 Samples from a 1-D Gaussian
60 Samples from a 1-D Gaussian
61 Samples from a 1-D Gaussian
62 Samples from a 1-D Gaussian
63 Samples from a 1-D Gaussian
64 How do GPs solve the overfitting problem (i.e. regularize)? Answer: Integrate over the function itself! So, we will average out all possible function forms, under a (GP) prior! Recap: MAP: Bayesian: θ are hyperparameters arg max p(y w, φ(x))p(w) e.g. y = φ(x) w + ɛ w arg max f p(y f) p(f x, θ) e.g. y = f(x, θ) + ɛ θ }{{} GP prior The Bayesian approach (GP) automatically balances the data-fitting with the complexity penalty.
65 How do GPs solve the overfitting problem (i.e. regularize)? Answer: Integrate over the function itself! So, we will average out all possible function forms, under a (GP) prior! Recap: MAP: Bayesian: θ are hyperparameters arg max p(y w, φ(x))p(w) e.g. y = φ(x) w + ɛ w arg max f p(y f) p(f x, θ) e.g. y = f(x, θ) + ɛ θ }{{} GP prior The Bayesian approach (GP) automatically balances the data-fitting with the complexity penalty.
66 Deep Gaussian processes x Define a recursive stacked construction h 1 f 1 f 2 f(x) GP f L (f L 1 (f L 2 f 1 (x)))) deep GP h 2 Compare to: y f 3 ϕ(x) w NN ϕ(ϕ(ϕ(x) w 1 )... w L 1 ) w L DNN

67 Two-layered DGP X Input f 1 H Unobserved f 2 Output Y
68 Inference in DGPs It s tricky. An additional difficulty comes from the fact that the kernel couples all points, so p(y x) is not factorized anymore. Indeed, p(y x, w) = f p(y f)p(f x, w) but w appears inside the non-linear kernel function: p(f x, w) = N(f 0, k(x, X w))
69 The resulting objective function By integrating over all unknowns: We obtain approximate posteriors q(h), q(f) over them We end up with a well regularized variational lower bound on the true marginal likelihood: F = Data Fit KL (q(h 1 ) p(h 1 )) + }{{} Regularisation Regularization achieved through uncertainty propagation. L H (q(h l )) }{{} Regularisation l=2
70 An example where uncertainty propagation matters: Recurrent learning.
71 Dynamics/memory: Deep Recurrent Gaussian Process
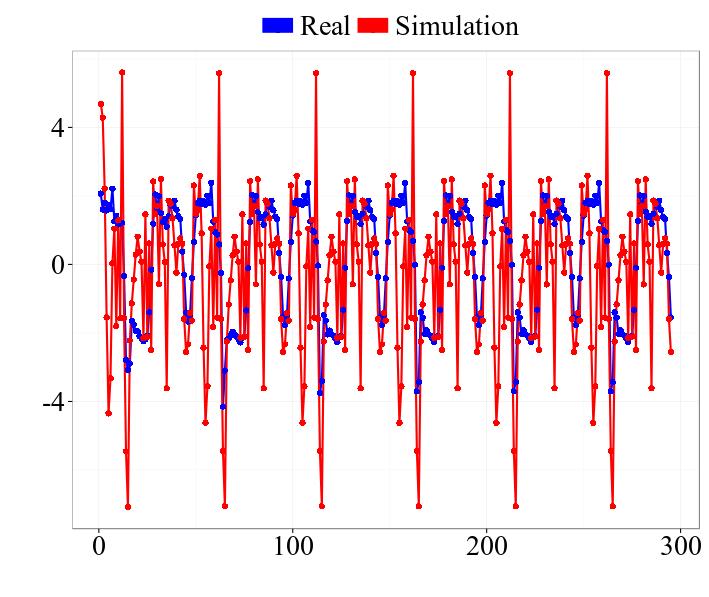
72 Avatar control Figure: The generated motion with a step function signal, starting with walking (blue), switching to running (red) and switching back to walking (blue) Videos: Switching between learned speeds Interpolating (un)seen speed Constant unseen speed


73 RGP GPNARX MLP-NARX LSTM


74 RGP GPNARX MLP-NARX LSTM
75 Stochastic warping X ϕ ϕ... ϕ H N (0, I) G. H N (0, I) G ϕ ϕ... ϕ Inference: Need to infer posteriors on H Define q(h) = N (µ, Σ) Amortize: {µ, Σ} = MLP (Y; θ) Y
76 Stochastic warping X ϕ ϕ... ϕ H N (0, I) G. H N (0, I) G ϕ ϕ... ϕ Inference: Need to infer posteriors on H Define q(h) = N (µ, Σ) Amortize: {µ, Σ} = MLP (Y; θ) Y
77 Amortized inference Solution: Reparameterization through recognition model g: µ n 1 = g 1 (y (n) ) = g l (µ (n) l 1 ) g l = MLP(θ l ) µ (n) l g l deterministic µ (n) l = g l (... g 1 (y (n) )) Dai, Damianou, Gonzalez, Lawrence, ICLR 2016
78 Bayesian approach recap Three ways of introducing uncertainty / noise in a NN: Treat weights w as distributions (BNNs) Stochasticity in the warping function φ (VAE) Bayesian non-parametrics applied to DNNs (DGP)
79 Connection between Bayesian and traditional approaches There s another view of Bayesian NNs. Namely that they can be used as a means of explaining / motivating DNN techniques (e.g. Dropout) in a more mathematically grounded way. Dropout as variational inference. (Kingma et al. 2015), (Gal and Ghahramani. 2016) Low-rank NN weight approximation and Deep Gaussian processes (Hensman and Lawrence 2014, Damianou 2015, Louizos and Welling 2016, Cutajar et al. 2016)...
80 Summary Motivation for probabilistic and Bayesian reasoning Three ways of incorporating uncertainty in DNNs Inference is more challenging when uncertainty has to be propagated Connection between Bayesian and traditional NN approaches
System identification and control with (deep) Gaussian processes. Andreas Damianou
 Gaussian processes. Andreas Damianou") System identification and control with (deep) Gaussian processes Andreas Damianou Department of Computer Science, University of Sheffield, UK MIT, 11 Feb. 2016 Outline Part 1: Introduction Part 2: Gaussian
System identification and control with (deep) Gaussian processes Andreas Damianou Department of Computer Science, University of Sheffield, UK MIT, 11 Feb. 2016 Outline Part 1: Introduction Part 2: Gaussian
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Dropout as a Bayesian Approximation: Insights and Applications
 Dropout as a Bayesian Approximation: Insights and Applications Yarin Gal and Zoubin Ghahramani Discussion by: Chunyuan Li Jan. 15, 2016 1 / 16 Main idea In the framework of variational inference, the authors
Dropout as a Bayesian Approximation: Insights and Applications Yarin Gal and Zoubin Ghahramani Discussion by: Chunyuan Li Jan. 15, 2016 1 / 16 Main idea In the framework of variational inference, the authors
Probabilistic Reasoning in Deep Learning
 Probabilistic Reasoning in Deep Learning Dr Konstantina Palla, PhD palla@stats.ox.ac.uk September 2017 Deep Learning Indaba, Johannesburgh Konstantina Palla 1 / 39 OVERVIEW OF THE TALK Basics of Bayesian
Probabilistic Reasoning in Deep Learning Dr Konstantina Palla, PhD palla@stats.ox.ac.uk September 2017 Deep Learning Indaba, Johannesburgh Konstantina Palla 1 / 39 OVERVIEW OF THE TALK Basics of Bayesian
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model
 Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
Probabilistic Graphical Models Lecture 20: Gaussian Processes
 Probabilistic Graphical Models Lecture 20: Gaussian Processes Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 30, 2015 1 / 53 What is Machine Learning? Machine learning algorithms
Probabilistic Graphical Models Lecture 20: Gaussian Processes Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 30, 2015 1 / 53 What is Machine Learning? Machine learning algorithms
Lecture: Gaussian Process Regression. STAT 6474 Instructor: Hongxiao Zhu
 Lecture: Gaussian Process Regression STAT 6474 Instructor: Hongxiao Zhu Motivation Reference: Marc Deisenroth s tutorial on Robot Learning. 2 Fast Learning for Autonomous Robots with Gaussian Processes
Lecture: Gaussian Process Regression STAT 6474 Instructor: Hongxiao Zhu Motivation Reference: Marc Deisenroth s tutorial on Robot Learning. 2 Fast Learning for Autonomous Robots with Gaussian Processes
GAUSSIAN PROCESS REGRESSION
 GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
Probabilistic Models for Learning Data Representations. Andreas Damianou
 Probabilistic Models for Learning Data Representations Andreas Damianou Department of Computer Science, University of Sheffield, UK IBM Research, Nairobi, Kenya, 23/06/2015 Sheffield SITraN Outline Part
Probabilistic Models for Learning Data Representations Andreas Damianou Department of Computer Science, University of Sheffield, UK IBM Research, Nairobi, Kenya, 23/06/2015 Sheffield SITraN Outline Part
CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes
 CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes Roger Grosse Roger Grosse CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes 1 / 55 Adminis-Trivia Did everyone get my e-mail
CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes Roger Grosse Roger Grosse CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes 1 / 55 Adminis-Trivia Did everyone get my e-mail
Variational Dropout via Empirical Bayes
 Variational Dropout via Empirical Bayes Valery Kharitonov 1 kharvd@gmail.com Dmitry Molchanov 1, dmolch111@gmail.com Dmitry Vetrov 1, vetrovd@yandex.ru 1 National Research University Higher School of Economics,
Variational Dropout via Empirical Bayes Valery Kharitonov 1 kharvd@gmail.com Dmitry Molchanov 1, dmolch111@gmail.com Dmitry Vetrov 1, vetrovd@yandex.ru 1 National Research University Higher School of Economics,
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 3 Stochastic Gradients, Bayesian Inference, and Occam s Razor https://people.orie.cornell.edu/andrew/orie6741 Cornell University August
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 3 Stochastic Gradients, Bayesian Inference, and Occam s Razor https://people.orie.cornell.edu/andrew/orie6741 Cornell University August
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Probabilistic & Unsupervised Learning
 Probabilistic & Unsupervised Learning Gaussian Processes Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College London
Probabilistic & Unsupervised Learning Gaussian Processes Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College London
CSci 8980: Advanced Topics in Graphical Models Gaussian Processes
 CSci 8980: Advanced Topics in Graphical Models Gaussian Processes Instructor: Arindam Banerjee November 15, 2007 Gaussian Processes Outline Gaussian Processes Outline Parametric Bayesian Regression Gaussian
CSci 8980: Advanced Topics in Graphical Models Gaussian Processes Instructor: Arindam Banerjee November 15, 2007 Gaussian Processes Outline Gaussian Processes Outline Parametric Bayesian Regression Gaussian
Reliability Monitoring Using Log Gaussian Process Regression
 COPYRIGHT 013, M. Modarres Reliability Monitoring Using Log Gaussian Process Regression Martin Wayne Mohammad Modarres PSA 013 Center for Risk and Reliability University of Maryland Department of Mechanical
COPYRIGHT 013, M. Modarres Reliability Monitoring Using Log Gaussian Process Regression Martin Wayne Mohammad Modarres PSA 013 Center for Risk and Reliability University of Maryland Department of Mechanical
Bayesian Deep Learning
 Bayesian Deep Learning Mohammad Emtiyaz Khan AIP (RIKEN), Tokyo http://emtiyaz.github.io emtiyaz.khan@riken.jp June 06, 2018 Mohammad Emtiyaz Khan 2018 1 What will you learn? Why is Bayesian inference
Bayesian Deep Learning Mohammad Emtiyaz Khan AIP (RIKEN), Tokyo http://emtiyaz.github.io emtiyaz.khan@riken.jp June 06, 2018 Mohammad Emtiyaz Khan 2018 1 What will you learn? Why is Bayesian inference
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
20: Gaussian Processes
 10-708: Probabilistic Graphical Models 10-708, Spring 2016 20: Gaussian Processes Lecturer: Andrew Gordon Wilson Scribes: Sai Ganesh Bandiatmakuri 1 Discussion about ML Here we discuss an introduction
10-708: Probabilistic Graphical Models 10-708, Spring 2016 20: Gaussian Processes Lecturer: Andrew Gordon Wilson Scribes: Sai Ganesh Bandiatmakuri 1 Discussion about ML Here we discuss an introduction
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Gaussian Processes. Le Song. Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012
 Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
COMP 551 Applied Machine Learning Lecture 20: Gaussian processes
 COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
Model Selection for Gaussian Processes
 Institute for Adaptive and Neural Computation School of Informatics,, UK December 26 Outline GP basics Model selection: covariance functions and parameterizations Criteria for model selection Marginal
Institute for Adaptive and Neural Computation School of Informatics,, UK December 26 Outline GP basics Model selection: covariance functions and parameterizations Criteria for model selection Marginal
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning
 Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning Diederik (Durk) Kingma Danilo J. Rezende (*) Max Welling Shakir Mohamed (**) Stochastic Gradient Variational Inference Bayesian
Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning Diederik (Durk) Kingma Danilo J. Rezende (*) Max Welling Shakir Mohamed (**) Stochastic Gradient Variational Inference Bayesian
Bayesian Semi-supervised Learning with Deep Generative Models
 Bayesian Semi-supervised Learning with Deep Generative Models Jonathan Gordon Department of Engineering Cambridge University jg801@cam.ac.uk José Miguel Hernández-Lobato Department of Engineering Cambridge
Bayesian Semi-supervised Learning with Deep Generative Models Jonathan Gordon Department of Engineering Cambridge University jg801@cam.ac.uk José Miguel Hernández-Lobato Department of Engineering Cambridge
Gaussian Process Regression
 Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Deep Variational Inference. FLARE Reading Group Presentation Wesley Tansey 9/28/2016
 Deep Variational Inference FLARE Reading Group Presentation Wesley Tansey 9/28/2016 What is Variational Inference? What is Variational Inference? Want to estimate some distribution, p*(x) p*(x) What is
Deep Variational Inference FLARE Reading Group Presentation Wesley Tansey 9/28/2016 What is Variational Inference? What is Variational Inference? Want to estimate some distribution, p*(x) p*(x) What is
Pattern Recognition and Machine Learning. Bishop Chapter 6: Kernel Methods
 Pattern Recognition and Machine Learning Chapter 6: Kernel Methods Vasil Khalidov Alex Kläser December 13, 2007 Training Data: Keep or Discard? Parametric methods (linear/nonlinear) so far: learn parameter
Pattern Recognition and Machine Learning Chapter 6: Kernel Methods Vasil Khalidov Alex Kläser December 13, 2007 Training Data: Keep or Discard? Parametric methods (linear/nonlinear) so far: learn parameter
Introduction to Machine Learning
 Introduction to Machine Learning Linear Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Introduction to Machine Learning Linear Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
The connection of dropout and Bayesian statistics
 The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
Lecture 5: GPs and Streaming regression
 Lecture 5: GPs and Streaming regression Gaussian Processes Information gain Confidence intervals COMP-652 and ECSE-608, Lecture 5 - September 19, 2017 1 Recall: Non-parametric regression Input space X
Lecture 5: GPs and Streaming regression Gaussian Processes Information gain Confidence intervals COMP-652 and ECSE-608, Lecture 5 - September 19, 2017 1 Recall: Non-parametric regression Input space X
Learning Gaussian Process Models from Uncertain Data
 Learning Gaussian Process Models from Uncertain Data Patrick Dallaire, Camille Besse, and Brahim Chaib-draa DAMAS Laboratory, Computer Science & Software Engineering Department, Laval University, Canada
Learning Gaussian Process Models from Uncertain Data Patrick Dallaire, Camille Besse, and Brahim Chaib-draa DAMAS Laboratory, Computer Science & Software Engineering Department, Laval University, Canada
Recurrent Latent Variable Networks for Session-Based Recommendation
 Recurrent Latent Variable Networks for Session-Based Recommendation Panayiotis Christodoulou Cyprus University of Technology paa.christodoulou@edu.cut.ac.cy 27/8/2017 Panayiotis Christodoulou (C.U.T.)
Recurrent Latent Variable Networks for Session-Based Recommendation Panayiotis Christodoulou Cyprus University of Technology paa.christodoulou@edu.cut.ac.cy 27/8/2017 Panayiotis Christodoulou (C.U.T.)
CS-E3210 Machine Learning: Basic Principles
 CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
Lecture 4: Probabilistic Learning
 DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
GWAS IV: Bayesian linear (variance component) models
 models") GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Variational Autoencoders
 Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
DEPARTMENT OF COMPUTER SCIENCE Autumn Semester MACHINE LEARNING AND ADAPTIVE INTELLIGENCE
 Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Deep Gaussian Processes
 Deep Gaussian Processes Neil D. Lawrence 8th April 2015 Mascot Num 2015 Outline Introduction Deep Gaussian Process Models Variational Methods Composition of GPs Results Outline Introduction Deep Gaussian
Deep Gaussian Processes Neil D. Lawrence 8th April 2015 Mascot Num 2015 Outline Introduction Deep Gaussian Process Models Variational Methods Composition of GPs Results Outline Introduction Deep Gaussian
Combine Monte Carlo with Exhaustive Search: Effective Variational Inference and Policy Gradient Reinforcement Learning
 Combine Monte Carlo with Exhaustive Search: Effective Variational Inference and Policy Gradient Reinforcement Learning Michalis K. Titsias Department of Informatics Athens University of Economics and Business
Combine Monte Carlo with Exhaustive Search: Effective Variational Inference and Policy Gradient Reinforcement Learning Michalis K. Titsias Department of Informatics Athens University of Economics and Business
Auto-Encoding Variational Bayes
 Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Introduction to Gaussian Process
 Introduction to Gaussian Process CS 778 Chris Tensmeyer CS 478 INTRODUCTION 1 What Topic? Machine Learning Regression Bayesian ML Bayesian Regression Bayesian Non-parametric Gaussian Process (GP) GP Regression
Introduction to Gaussian Process CS 778 Chris Tensmeyer CS 478 INTRODUCTION 1 What Topic? Machine Learning Regression Bayesian ML Bayesian Regression Bayesian Non-parametric Gaussian Process (GP) GP Regression
Computer Vision Group Prof. Daniel Cremers. 9. Gaussian Processes - Regression
 Group Prof. Daniel Cremers 9. Gaussian Processes - Regression Repetition: Regularized Regression Before, we solved for w using the pseudoinverse. But: we can kernelize this problem as well! First step:
Group Prof. Daniel Cremers 9. Gaussian Processes - Regression Repetition: Regularized Regression Before, we solved for w using the pseudoinverse. But: we can kernelize this problem as well! First step:
Introduction to Gaussian Processes
 Introduction to Gaussian Processes Neil D. Lawrence GPSS 10th June 2013 Book Rasmussen and Williams (2006) Outline The Gaussian Density Covariance from Basis Functions Basis Function Representations Constructing
Introduction to Gaussian Processes Neil D. Lawrence GPSS 10th June 2013 Book Rasmussen and Williams (2006) Outline The Gaussian Density Covariance from Basis Functions Basis Function Representations Constructing
Fully Bayesian Deep Gaussian Processes for Uncertainty Quantification
 Fully Bayesian Deep Gaussian Processes for Uncertainty Quantification N. Zabaras 1 S. Atkinson 1 Center for Informatics and Computational Science Department of Aerospace and Mechanical Engineering University
Fully Bayesian Deep Gaussian Processes for Uncertainty Quantification N. Zabaras 1 S. Atkinson 1 Center for Informatics and Computational Science Department of Aerospace and Mechanical Engineering University
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Gradient Estimation Using Stochastic Computation Graphs
 Gradient Estimation Using Stochastic Computation Graphs Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology May 9, 2017 Outline Stochastic Gradient Estimation
Gradient Estimation Using Stochastic Computation Graphs Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology May 9, 2017 Outline Stochastic Gradient Estimation
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Gaussian Processes in Machine Learning
 Gaussian Processes in Machine Learning November 17, 2011 CharmGil Hong Agenda Motivation GP : How does it make sense? Prior : Defining a GP More about Mean and Covariance Functions Posterior : Conditioning
Gaussian Processes in Machine Learning November 17, 2011 CharmGil Hong Agenda Motivation GP : How does it make sense? Prior : Defining a GP More about Mean and Covariance Functions Posterior : Conditioning
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
Bayesian RL Seminar. Chris Mansley September 9, 2008
 Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Expectation Propagation for Approximate Bayesian Inference
 Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
COMP 551 Applied Machine Learning Lecture 21: Bayesian optimisation
 COMP 55 Applied Machine Learning Lecture 2: Bayesian optimisation Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp55 Unless otherwise noted, all material posted
COMP 55 Applied Machine Learning Lecture 2: Bayesian optimisation Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp55 Unless otherwise noted, all material posted
Deep Gaussian Processes
 Deep Gaussian Processes Neil D. Lawrence 30th April 2015 KTH Royal Institute of Technology Outline Introduction Deep Gaussian Process Models Variational Approximation Samples and Results Outline Introduction
Deep Gaussian Processes Neil D. Lawrence 30th April 2015 KTH Royal Institute of Technology Outline Introduction Deep Gaussian Process Models Variational Approximation Samples and Results Outline Introduction
Machine Learning Basics: Maximum Likelihood Estimation
 Machine Learning Basics: Maximum Likelihood Estimation Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics 1. Learning
Machine Learning Basics: Maximum Likelihood Estimation Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics 1. Learning
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Variational Inference via Stochastic Backpropagation
 Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation
Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Outline Lecture 2 2(32)
") Outline Lecture (3), Lecture Linear Regression and Classification it is our firm belief that an understanding of linear models is essential for understanding nonlinear ones Thomas Schön Division of Automatic
Outline Lecture (3), Lecture Linear Regression and Classification it is our firm belief that an understanding of linear models is essential for understanding nonlinear ones Thomas Schön Division of Automatic
Doubly Stochastic Inference for Deep Gaussian Processes. Hugh Salimbeni Department of Computing Imperial College London
 Doubly Stochastic Inference for Deep Gaussian Processes Hugh Salimbeni Department of Computing Imperial College London 29/5/2017 Motivation DGPs promise much, but are difficult to train Doubly Stochastic
Doubly Stochastic Inference for Deep Gaussian Processes Hugh Salimbeni Department of Computing Imperial College London 29/5/2017 Motivation DGPs promise much, but are difficult to train Doubly Stochastic
Computer Vision Group Prof. Daniel Cremers. 4. Gaussian Processes - Regression
 Group Prof. Daniel Cremers 4. Gaussian Processes - Regression Definition (Rep.) Definition: A Gaussian process is a collection of random variables, any finite number of which have a joint Gaussian distribution.
Group Prof. Daniel Cremers 4. Gaussian Processes - Regression Definition (Rep.) Definition: A Gaussian process is a collection of random variables, any finite number of which have a joint Gaussian distribution.
Introduction to Machine Learning
 Introduction to Machine Learning Logistic Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Introduction to Machine Learning Logistic Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
σ(a) = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =
 = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =") Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Bayesian Support Vector Machines for Feature Ranking and Selection
 Bayesian Support Vector Machines for Feature Ranking and Selection written by Chu, Keerthi, Ong, Ghahramani Patrick Pletscher pat@student.ethz.ch ETH Zurich, Switzerland 12th January 2006 Overview 1 Introduction
Bayesian Support Vector Machines for Feature Ranking and Selection written by Chu, Keerthi, Ong, Ghahramani Patrick Pletscher pat@student.ethz.ch ETH Zurich, Switzerland 12th January 2006 Overview 1 Introduction
Deep learning with differential Gaussian process flows
 Deep learning with differential Gaussian process flows Pashupati Hegde Markus Heinonen Harri Lähdesmäki Samuel Kaski Helsinki Institute for Information Technology HIIT Department of Computer Science, Aalto
Deep learning with differential Gaussian process flows Pashupati Hegde Markus Heinonen Harri Lähdesmäki Samuel Kaski Helsinki Institute for Information Technology HIIT Department of Computer Science, Aalto
Gaussian Processes for Big Data. James Hensman
 Gaussian Processes for Big Data James Hensman Overview Motivation Sparse Gaussian Processes Stochastic Variational Inference Examples Overview Motivation Sparse Gaussian Processes Stochastic Variational
Gaussian Processes for Big Data James Hensman Overview Motivation Sparse Gaussian Processes Stochastic Variational Inference Examples Overview Motivation Sparse Gaussian Processes Stochastic Variational
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
PILCO: A Model-Based and Data-Efficient Approach to Policy Search
 PILCO: A Model-Based and Data-Efficient Approach to Policy Search (M.P. Deisenroth and C.E. Rasmussen) CSC2541 November 4, 2016 PILCO Graphical Model PILCO Probabilistic Inference for Learning COntrol
PILCO: A Model-Based and Data-Efficient Approach to Policy Search (M.P. Deisenroth and C.E. Rasmussen) CSC2541 November 4, 2016 PILCO Graphical Model PILCO Probabilistic Inference for Learning COntrol
Non-Gaussian likelihoods for Gaussian Processes
 Non-Gaussian likelihoods for Gaussian Processes Alan Saul University of Sheffield Outline Motivation Laplace approximation KL method Expectation Propagation Comparing approximations GP regression Model
Non-Gaussian likelihoods for Gaussian Processes Alan Saul University of Sheffield Outline Motivation Laplace approximation KL method Expectation Propagation Comparing approximations GP regression Model
Gaussian Processes for Machine Learning
 Gaussian Processes for Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics Tübingen, Germany carl@tuebingen.mpg.de Carlos III, Madrid, May 2006 The actual science of
Gaussian Processes for Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics Tübingen, Germany carl@tuebingen.mpg.de Carlos III, Madrid, May 2006 The actual science of
Machine Learning - MT & 5. Basis Expansion, Regularization, Validation
 Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Linear regression example Simple linear regression: f(x) = ϕ(x)t w w ~ N(0, ) The mean and covariance are given by E[f(x)] = ϕ(x)e[w] = 0.
![Linear regression example Simple linear regression: f(x) = ϕ(x)t w w ~ N(0, ) The mean and covariance are given by E[f(x)] = ϕ(x)e[w] = 0.](/thumbs/95/123587665.jpg "Linear regression example Simple linear regression: f(x) = ϕ(x)t w w ~ N(0, ) The mean and covariance are given by E[f(x)] = ϕ(x)e[w] = 0.") Gaussian Processes Gaussian Process Stochastic process: basically, a set of random variables. may be infinite. usually related in some way. Gaussian process: each variable has a Gaussian distribution every
Gaussian Processes Gaussian Process Stochastic process: basically, a set of random variables. may be infinite. usually related in some way. Gaussian process: each variable has a Gaussian distribution every
A Variance Modeling Framework Based on Variational Autoencoders for Speech Enhancement
 A Variance Modeling Framework Based on Variational Autoencoders for Speech Enhancement Simon Leglaive 1 Laurent Girin 1,2 Radu Horaud 1 1: Inria Grenoble Rhône-Alpes 2: Univ. Grenoble Alpes, Grenoble INP,
A Variance Modeling Framework Based on Variational Autoencoders for Speech Enhancement Simon Leglaive 1 Laurent Girin 1,2 Radu Horaud 1 1: Inria Grenoble Rhône-Alpes 2: Univ. Grenoble Alpes, Grenoble INP,
Nonparameteric Regression:
 Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
GWAS V: Gaussian processes
 GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
MTTTS16 Learning from Multiple Sources
 MTTTS16 Learning from Multiple Sources 5 ECTS credits Autumn 2018, University of Tampere Lecturer: Jaakko Peltonen Lecture 6: Multitask learning with kernel methods and nonparametric models On this lecture:
MTTTS16 Learning from Multiple Sources 5 ECTS credits Autumn 2018, University of Tampere Lecturer: Jaakko Peltonen Lecture 6: Multitask learning with kernel methods and nonparametric models On this lecture:
Overview. Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation
 Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Gaussian Processes (10/16/13)
") STA561: Probabilistic machine learning Gaussian Processes (10/16/13) Lecturer: Barbara Engelhardt Scribes: Changwei Hu, Di Jin, Mengdi Wang 1 Introduction In supervised learning, we observe some inputs
STA561: Probabilistic machine learning Gaussian Processes (10/16/13) Lecturer: Barbara Engelhardt Scribes: Changwei Hu, Di Jin, Mengdi Wang 1 Introduction In supervised learning, we observe some inputs
Linear Models for Regression
 Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Unsupervised Learning
 CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
Linear Models for Regression
 Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
Bayesian Inference: Principles and Practice 3. Sparse Bayesian Models and the Relevance Vector Machine
 Bayesian Inference: Principles and Practice 3. Sparse Bayesian Models and the Relevance Vector Machine Mike Tipping Gaussian prior Marginal prior: single α Independent α Cambridge, UK Lecture 3: Overview
Bayesian Inference: Principles and Practice 3. Sparse Bayesian Models and the Relevance Vector Machine Mike Tipping Gaussian prior Marginal prior: single α Independent α Cambridge, UK Lecture 3: Overview
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Bayesian Linear Regression [DRAFT - In Progress]
![Bayesian Linear Regression [DRAFT - In Progress]](/thumbs/92/109828713.jpg "Bayesian Linear Regression [DRAFT - In Progress]") Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Fast yet Simple Natural-Gradient Variational Inference in Complex Models
 Fast yet Simple Natural-Gradient Variational Inference in Complex Models Mohammad Emtiyaz Khan RIKEN Center for AI Project, Tokyo, Japan http://emtiyaz.github.io Joint work with Wu Lin (UBC) DidrikNielsen,
Fast yet Simple Natural-Gradient Variational Inference in Complex Models Mohammad Emtiyaz Khan RIKEN Center for AI Project, Tokyo, Japan http://emtiyaz.github.io Joint work with Wu Lin (UBC) DidrikNielsen,
ADVANCED MACHINE LEARNING ADVANCED MACHINE LEARNING. Non-linear regression techniques Part - II
 1 Non-linear regression techniques Part - II Regression Algorithms in this Course Support Vector Machine Relevance Vector Machine Support vector regression Boosting random projections Relevance vector
1 Non-linear regression techniques Part - II Regression Algorithms in this Course Support Vector Machine Relevance Vector Machine Support vector regression Boosting random projections Relevance vector
Deep Neural Networks as Gaussian Processes
 Deep Neural Networks as Gaussian Processes Jaehoon Lee, Yasaman Bahri, Roman Novak, Samuel S. Schoenholz, Jeffrey Pennington, Jascha Sohl-Dickstein Google Brain {jaehlee, yasamanb, romann, schsam, jpennin,
Deep Neural Networks as Gaussian Processes Jaehoon Lee, Yasaman Bahri, Roman Novak, Samuel S. Schoenholz, Jeffrey Pennington, Jascha Sohl-Dickstein Google Brain {jaehlee, yasamanb, romann, schsam, jpennin,
ECE521 Tutorial 2. Regression, GPs, Assignment 1. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel for the slides.
 ECE521 Tutorial 2 Regression, GPs, Assignment 1 ECE521 Winter 2016 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel for the slides. ECE521 Tutorial 2 ECE521 Winter 2016 Credits to Alireza / 3 Outline
ECE521 Tutorial 2 Regression, GPs, Assignment 1 ECE521 Winter 2016 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel for the slides. ECE521 Tutorial 2 ECE521 Winter 2016 Credits to Alireza / 3 Outline
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality