TRACKING and DETECTION in COMPUTER VISION
|
|
|
- Fay Ball
- 5 years ago
- Views:
Transcription
1 Technischen Universität München Winter Semester 2013/2014 TRACKING and DETECTION in COMPUTER VISION Template tracking methods Slobodan Ilić
2 Template based-tracking Energy-based methods The Lucas-Kanade(LK) algorithm Compositional Algorithm Inverse Compositional Algorithm (IC) Efficient Second Order Method (ESM) Learning methods Learning linear predictors(hyperplane template matching of Jurie-Dhome) 2








3 Motivation template image Follow a template image in an image sequence by estimating the warp. 3
4 Template warping 4
5 Template warping Given the template T which we want to track: Template image T (x) 4
6 Template warping Given the template T which we want to track: Take all pixels x form the template and Template image T (x) 4
7 Template warping Given the template T which we want to track: Take all pixels x form the template and Warp them using the function W (x; p) parameterized in terms of parameters p to the input image I Template image Input image warp T (x) W (x; p) 4
8 Template warping Given the template T which we want to track: Take all pixels x form the template and Warp them using the function W (x; p) parameterized in terms of parameters p to the input image I Assign the pixel intensity values of the input image at the warped location to the template image I(W (x; p)) Template image Input image warp W (x; p) T (x) 4 I(W (x; p))
9 The tracking task The goal of template-based tracking is to find the parameters p such that: p by minimizing the norm of: I(W(x; p )) = T (x) Using a prediction as an approximation of the estimation p we can reformulate the goal: Find the parameter increments p p p + p such that: This is a non-linear minimization problem. (1) 5
10 Assumptions 6
11 Assumptions No errors in the template image boundaries: only the appearance of the object to be tracked appears in the template image. 6
12 Assumptions No errors in the template image boundaries: only the appearance of the object to be tracked appears in the template image. No large occlusions: the entire template is visible in the input image. 6
13 Assumptions No errors in the template image boundaries: only the appearance of the object to be tracked appears in the template image. No large occlusions: the entire template is visible in the input image. Brightness constancy assumption: the intensity of the object appearance is always the same. 6
14 The Lucas-Kanade Uses the Gauss-Newton method for minimization: Applies a first-order approximation Minimizes iteratively The warp has to be differentiable. 7
15 The derivation of Lucas-Kanade Linearize the error function of Eq. (1) on slide 5 by using a first-order Taylor series approximation of warped source image : = And minimize the following function: (2) 8
16 The derivation of Lucas-Kanade Linearize the error function of Eq. (1) on slide 5 by using a first-order Taylor series approximation of warped source image : = And minimize the following function: (2) Image gradient evaluated at W(x; p) 8
17 The derivation of Lucas-Kanade Linearize the error function of Eq. (1) on slide 5 by using a first-order Taylor series approximation of warped source image : = And minimize the following function: (2) Image gradient evaluated at W(x; p) Jacobian of the warp 8
18 Jacobian of the warp If warp is a function: then its Jacobian is: 9
19 Typical warps Translation, like in optical-flow: Affine, like in template tracking: 10
20 LK derivation Minimizing the Eq. 2 from slide 8 is a least-square problem and has a closed form solution. The partial derivatives of Eq.2 in respect with the parameter update p is: setting equation to zero gives closed-form solution: where H is nxn (Gauss-Newton) approximation of the Hessian matrix: 11


21 The LK alg. summary Iterate until p < 12
22 Alternative approaches Lucas-Kanade approximately minimizes: with respect to pand updates the parameters is step 9 like p p + p BUT, these are not the only ways to minimize this function, thus 3 other approaches are introduced: Compositional Image Alignment Inverse Compositional Image Alignment Inverse Additive Image Alignment 13
23 Compositional Image Alignment The warp is composed of two warps: which can be written as: and the solution is sought for the warp instead of additive update of the parameters p Thus the problem to minimize becomes: (3) 14
24 Compositional Affine Warp Affine warp: Compositional affine wrap: W(W(x; p); p)) = 1+p 1 p3 p5 p2 1+p4 p6 1+ p 1 p3 p5 p2 1+ p4 p x y 1 15
25 Derivation After applying first order Taylor approximation to I(W(x; p); p)) the Eq. 3 from slide 14 becomes: where I(W(x)) denotes the warped image and in order to proceed we assume that the warp W(x; 0) =x simplifies to: is identity warp, thus the above eq. I(W(x; p)) 16
26 Compositional vs. Additive Approach Forward additive approach: Compute image gradient and warp it with W(x; p) Compositional approach: Jacobian of the warp is evaluated at (x; p) Compute image gradient of the warped image I(W) Jacobian of the warp is evaluated at (x; 0) and is constant 17
27 Compositional vs. Additive Differences The gradient of I(W(x; p)) should be used in step (3) of the algorithm from slide 12. The Jacobian of the warp can be pre-computed because it is evaluated at (x;0) rather then being recomputed at each iteration in step (4). The warp is updated in step 9 and not warp parameters. 18
 Template image W(x; p) W(x; p) W(x; p) 1 Source image")
28 Inverse Compositional (IC) Approach (4) W(x; p) W(x; p) T(x) Template image W(x; p) W(x; p) W(x; p) 1 Source image 19
29 Derivation After first order Taylor expansion Eq. 4 becomes: and assuming that solution is: W(x; 0) =x is the identity warp the where the Hessian of image is replaced by the one of the template: since the there is nothing in H which depends on p it is constant and can be pre-computed 20
30 IC Algorithm 21
31 ESM (Efficient Second-order Method) (1) I = T + J p=0 dp + dp T H p=0 dp [second-order Taylor expansion] (2) J p=dp = J p=0 + 2dp T H p=0 [derivation of (1) wrt dp] (3) dp T H p=0 = ½(J p=dp - J p=0 ) [from Equation (2)] (4) I = T + J p=0 + ½(J p=dp - J p=0 )dp [by injecting (3) in (1)] (5) dp = [½(J p=0 + J p=dp )] + (I - T) [from Equation (4)] Like Gauss-Newton but replace J p=0 by ½(J p=0 + J p=dp ). Need to compute J p=dp at each iteration, and a pseudo-inverse at each iteration, but need much less iterations. 22

32 ESM Convergence Gauss-Newton ESM 23
33 Learning a Linear Predictor [Jurie&Dhome PAMI02] From the IC approach we had: Where we can denote J = T W to be p Jacobian of the error function we minimize Thus we can rewrite it: p =(J T (0)J (0)) 1 J T (0) or p = A 24
34 Hyperplane approximation If for each pixel we write an error function: y i ( p) =T(W(x i ; p)) I(W(x i ; p) and the total error function is with the solution being: we can rewrite it like: p = A E = i y i ( p) 2 we see that a 11,...,a ij...a nn are coefficients of n hyperplanes that can be estimated using linear least-squares N is a number of image sample points, e.g number of pixels in the template 25 p 1 p j p N
35 Training Can we learn A and make computation even faster? A is computed offline by regression: {(, ), (, ),...,(, )} p 0 p 1 y 1 (0) y 2 (0) image differences by minimizing: By writing N t k=1 ( p k Ay k (0)) 2 y Nt (0) p Nt H =(y i (0),...,y Nt (0)) Y =( p 1,..., p Nt ) and assuming N t >N= Y [n Nt ] = A h[nxn] H [N Nt ] A h = YH T (HH T ) 1 26
36 Advantages Can "jump" over local minimums. Handle faster motion. O p 27
37 Active Shape Models For deformable objects: p = x t u t v θ s with x = u i v i (u i, v i ) (t u, t v ): 2D translation; ϑ: 2D rotation; s: scale. 28
38 Dimensionality Reduction Training set: { } x i Covariance matrix of the training data: Cov = λ 1 λ SVD of the covariance matrix: Cov = U 2 Keep only the first columns of U : U = ( R x ). x = x + R x c 29 i ( x i x )( x i x ) T λ n U T U 2 c U 1
39 First Modes x = x + R x c Can be considered as a linear warp: W(x; c) = x + R x c Can constrain with c i < 3 λ i c are parameter of the warp we are searching 30
40 Fit Function min c,t u,t v,θ,s i dist( Tr ( tu,t v,θ,s x ),y ) i i Optimum can be found with linear algebra operations. 31
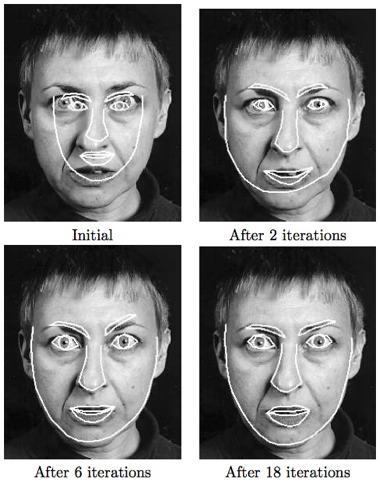
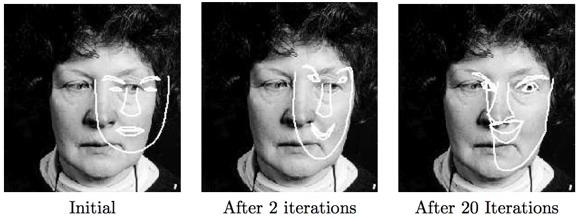
41 Convergence 32

42 Active Appearance Models g = g + R g c g 33
43 Fit Function min c,t u,t v,θ,s Tr ( tu,t v,θ,s g( c) ) I 2 = min c,t u,t v,θ,s ([ Tr ( tu,t v,θ,s g( c) )] I ) i i Non-linear least-squares. Optimization can be performed with the Gauss-Newton algorithm. i 2 34

44 Convergence 35

45 Example 36
Motion Estimation (I) Ce Liu Microsoft Research New England
 Ce Liu Microsoft Research New England") Motion Estimation (I) Ce Liu celiu@microsoft.com Microsoft Research New England We live in a moving world Perceiving, understanding and predicting motion is an important part of our daily lives Motion
Motion Estimation (I) Ce Liu celiu@microsoft.com Microsoft Research New England We live in a moving world Perceiving, understanding and predicting motion is an important part of our daily lives Motion
Motion Estimation (I)
") Motion Estimation (I) Ce Liu celiu@microsoft.com Microsoft Research New England We live in a moving world Perceiving, understanding and predicting motion is an important part of our daily lives Motion
Motion Estimation (I) Ce Liu celiu@microsoft.com Microsoft Research New England We live in a moving world Perceiving, understanding and predicting motion is an important part of our daily lives Motion
Image Alignment Computer Vision (Kris Kitani) Carnegie Mellon University
 Carnegie Mellon University") Lucas Kanade Image Alignment 16-385 Comuter Vision (Kris Kitani) Carnegie Mellon University htt://www.humansensing.cs.cmu.edu/intraface/ How can I find in the image? Idea #1: Temlate Matching Slow, combinatory,
Lucas Kanade Image Alignment 16-385 Comuter Vision (Kris Kitani) Carnegie Mellon University htt://www.humansensing.cs.cmu.edu/intraface/ How can I find in the image? Idea #1: Temlate Matching Slow, combinatory,
Efficient & Robust LK for Mobile Vision
 Efficient & Robust LK for Mobile Vision Instructor - Simon Lucey 16-623 - Designing Comuter Vision As Direct Method (ours) Indirect Method (ORB+RANSAC) H. Alismail, B. Browning, S. Lucey Bit-Planes: Dense
Efficient & Robust LK for Mobile Vision Instructor - Simon Lucey 16-623 - Designing Comuter Vision As Direct Method (ours) Indirect Method (ORB+RANSAC) H. Alismail, B. Browning, S. Lucey Bit-Planes: Dense
Iterative Image Registration: Lucas & Kanade Revisited. Kentaro Toyama Vision Technology Group Microsoft Research
 Iterative Image Registration: Lucas & Kanade Revisited Kentaro Toyama Vision Technology Group Microsoft Research Every writer creates his own precursors. His work modifies our conception of the past, as
Iterative Image Registration: Lucas & Kanade Revisited Kentaro Toyama Vision Technology Group Microsoft Research Every writer creates his own precursors. His work modifies our conception of the past, as
Motion estimation. Digital Visual Effects Yung-Yu Chuang. with slides by Michael Black and P. Anandan
 Motion estimation Digital Visual Effects Yung-Yu Chuang with slides b Michael Black and P. Anandan Motion estimation Parametric motion image alignment Tracking Optical flow Parametric motion direct method
Motion estimation Digital Visual Effects Yung-Yu Chuang with slides b Michael Black and P. Anandan Motion estimation Parametric motion image alignment Tracking Optical flow Parametric motion direct method
Method 1: Geometric Error Optimization
 Method 1: Geometric Error Optimization we need to encode the constraints ŷ i F ˆx i = 0, rank F = 2 idea: reconstruct 3D point via equivalent projection matrices and use reprojection error equivalent projection
Method 1: Geometric Error Optimization we need to encode the constraints ŷ i F ˆx i = 0, rank F = 2 idea: reconstruct 3D point via equivalent projection matrices and use reprojection error equivalent projection
Lucas-Kanade Optical Flow. Computer Vision Carnegie Mellon University (Kris Kitani)
") Lucas-Kanade Optical Flow Computer Vision 16-385 Carnegie Mellon University (Kris Kitani) I x u + I y v + I t =0 I x = @I @x I y = @I u = dx v = dy I @y t = @I dt dt @t spatial derivative optical flow
Lucas-Kanade Optical Flow Computer Vision 16-385 Carnegie Mellon University (Kris Kitani) I x u + I y v + I t =0 I x = @I @x I y = @I u = dx v = dy I @y t = @I dt dt @t spatial derivative optical flow
CPSC 540: Machine Learning
 CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
nonrobust estimation The n measurement vectors taken together give the vector X R N. The unknown parameter vector is P R M.
 Introduction to nonlinear LS estimation R. I. Hartley and A. Zisserman: Multiple View Geometry in Computer Vision. Cambridge University Press, 2ed., 2004. After Chapter 5 and Appendix 6. We will use x
Introduction to nonlinear LS estimation R. I. Hartley and A. Zisserman: Multiple View Geometry in Computer Vision. Cambridge University Press, 2ed., 2004. After Chapter 5 and Appendix 6. We will use x
Non-linear least squares
 Non-linear least squares Concept of non-linear least squares We have extensively studied linear least squares or linear regression. We see that there is a unique regression line that can be determined
Non-linear least squares Concept of non-linear least squares We have extensively studied linear least squares or linear regression. We see that there is a unique regression line that can be determined
Video and Motion Analysis Computer Vision Carnegie Mellon University (Kris Kitani)
") Video and Motion Analysis 16-385 Computer Vision Carnegie Mellon University (Kris Kitani) Optical flow used for feature tracking on a drone Interpolated optical flow used for super slow-mo optical flow
Video and Motion Analysis 16-385 Computer Vision Carnegie Mellon University (Kris Kitani) Optical flow used for feature tracking on a drone Interpolated optical flow used for super slow-mo optical flow
Image Alignment and Mosaicing Feature Tracking and the Kalman Filter
 Image Alignment and Mosaicing Feature Tracking and the Kalman Filter Image Alignment Applications Local alignment: Tracking Stereo Global alignment: Camera jitter elimination Image enhancement Panoramic
Image Alignment and Mosaicing Feature Tracking and the Kalman Filter Image Alignment Applications Local alignment: Tracking Stereo Global alignment: Camera jitter elimination Image enhancement Panoramic
Learning Task Grouping and Overlap in Multi-Task Learning
 Learning Task Grouping and Overlap in Multi-Task Learning Abhishek Kumar Hal Daumé III Department of Computer Science University of Mayland, College Park 20 May 2013 Proceedings of the 29 th International
Learning Task Grouping and Overlap in Multi-Task Learning Abhishek Kumar Hal Daumé III Department of Computer Science University of Mayland, College Park 20 May 2013 Proceedings of the 29 th International
Visual SLAM Tutorial: Bundle Adjustment
 Visual SLAM Tutorial: Bundle Adjustment Frank Dellaert June 27, 2014 1 Minimizing Re-projection Error in Two Views In a two-view setting, we are interested in finding the most likely camera poses T1 w
Visual SLAM Tutorial: Bundle Adjustment Frank Dellaert June 27, 2014 1 Minimizing Re-projection Error in Two Views In a two-view setting, we are interested in finding the most likely camera poses T1 w
Lecture 6: CS395T Numerical Optimization for Graphics and AI Line Search Applications
 Lecture 6: CS395T Numerical Optimization for Graphics and AI Line Search Applications Qixing Huang The University of Texas at Austin huangqx@cs.utexas.edu 1 Disclaimer This note is adapted from Section
Lecture 6: CS395T Numerical Optimization for Graphics and AI Line Search Applications Qixing Huang The University of Texas at Austin huangqx@cs.utexas.edu 1 Disclaimer This note is adapted from Section
Global parametric image alignment via high-order approximation
 Global parametric image alignment via high-order approximation Y. Keller, A. Averbuch 2 Electrical & Computer Engineering Department, Ben-Gurion University of the Negev. 2 School of Computer Science, Tel
Global parametric image alignment via high-order approximation Y. Keller, A. Averbuch 2 Electrical & Computer Engineering Department, Ben-Gurion University of the Negev. 2 School of Computer Science, Tel
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Gradient Descent. Dr. Xiaowei Huang
 Gradient Descent Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Three machine learning algorithms: decision tree learning k-nn linear regression only optimization objectives are discussed,
Gradient Descent Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Three machine learning algorithms: decision tree learning k-nn linear regression only optimization objectives are discussed,
Point Distribution Models
 Point Distribution Models Jan Kybic winter semester 2007 Point distribution models (Cootes et al., 1992) Shape description techniques A family of shapes = mean + eigenvectors (eigenshapes) Shapes described
Point Distribution Models Jan Kybic winter semester 2007 Point distribution models (Cootes et al., 1992) Shape description techniques A family of shapes = mean + eigenvectors (eigenshapes) Shapes described
Visual Tracking via Geometric Particle Filtering on the Affine Group with Optimal Importance Functions
 Monday, June 22 Visual Tracking via Geometric Particle Filtering on the Affine Group with Optimal Importance Functions Junghyun Kwon 1, Kyoung Mu Lee 1, and Frank C. Park 2 1 Department of EECS, 2 School
Monday, June 22 Visual Tracking via Geometric Particle Filtering on the Affine Group with Optimal Importance Functions Junghyun Kwon 1, Kyoung Mu Lee 1, and Frank C. Park 2 1 Department of EECS, 2 School
INTEREST POINTS AT DIFFERENT SCALES
 INTEREST POINTS AT DIFFERENT SCALES Thank you for the slides. They come mostly from the following sources. Dan Huttenlocher Cornell U David Lowe U. of British Columbia Martial Hebert CMU Intuitively, junctions
INTEREST POINTS AT DIFFERENT SCALES Thank you for the slides. They come mostly from the following sources. Dan Huttenlocher Cornell U David Lowe U. of British Columbia Martial Hebert CMU Intuitively, junctions
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Pose Tracking II! Gordon Wetzstein! Stanford University! EE 267 Virtual Reality! Lecture 12! stanford.edu/class/ee267/!
 Pose Tracking II! Gordon Wetzstein! Stanford University! EE 267 Virtual Reality! Lecture 12! stanford.edu/class/ee267/!! WARNING! this class will be dense! will learn how to use nonlinear optimization
Pose Tracking II! Gordon Wetzstein! Stanford University! EE 267 Virtual Reality! Lecture 12! stanford.edu/class/ee267/!! WARNING! this class will be dense! will learn how to use nonlinear optimization
Nonlinear Optimization for Optimal Control
 Nonlinear Optimization for Optimal Control Pieter Abbeel UC Berkeley EECS Many slides and figures adapted from Stephen Boyd [optional] Boyd and Vandenberghe, Convex Optimization, Chapters 9 11 [optional]
Nonlinear Optimization for Optimal Control Pieter Abbeel UC Berkeley EECS Many slides and figures adapted from Stephen Boyd [optional] Boyd and Vandenberghe, Convex Optimization, Chapters 9 11 [optional]
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Numerical optimization
 Numerical optimization Lecture 4 Alexander & Michael Bronstein tosca.cs.technion.ac.il/book Numerical geometry of non-rigid shapes Stanford University, Winter 2009 2 Longest Slowest Shortest Minimal Maximal
Numerical optimization Lecture 4 Alexander & Michael Bronstein tosca.cs.technion.ac.il/book Numerical geometry of non-rigid shapes Stanford University, Winter 2009 2 Longest Slowest Shortest Minimal Maximal
Numerical optimization. Numerical optimization. Longest Shortest where Maximal Minimal. Fastest. Largest. Optimization problems
 1 Numerical optimization Alexander & Michael Bronstein, 2006-2009 Michael Bronstein, 2010 tosca.cs.technion.ac.il/book Numerical optimization 048921 Advanced topics in vision Processing and Analysis of
1 Numerical optimization Alexander & Michael Bronstein, 2006-2009 Michael Bronstein, 2010 tosca.cs.technion.ac.il/book Numerical optimization 048921 Advanced topics in vision Processing and Analysis of
CS 4495 Computer Vision Principle Component Analysis
 CS 4495 Computer Vision Principle Component Analysis (and it s use in Computer Vision) Aaron Bobick School of Interactive Computing Administrivia PS6 is out. Due *** Sunday, Nov 24th at 11:55pm *** PS7
CS 4495 Computer Vision Principle Component Analysis (and it s use in Computer Vision) Aaron Bobick School of Interactive Computing Administrivia PS6 is out. Due *** Sunday, Nov 24th at 11:55pm *** PS7
COMP 558 lecture 18 Nov. 15, 2010
 Least squares We have seen several least squares problems thus far, and we will see more in the upcoming lectures. For this reason it is good to have a more general picture of these problems and how to
Least squares We have seen several least squares problems thus far, and we will see more in the upcoming lectures. For this reason it is good to have a more general picture of these problems and how to
Computer Vision Motion
 Computer Vision Motion Professor Hager http://www.cs.jhu.edu/~hager 12/1/12 CS 461, Copyright G.D. Hager Outline From Stereo to Motion The motion field and optical flow (2D motion) Factorization methods
Computer Vision Motion Professor Hager http://www.cs.jhu.edu/~hager 12/1/12 CS 461, Copyright G.D. Hager Outline From Stereo to Motion The motion field and optical flow (2D motion) Factorization methods
Introduction to gradient descent
 6-1: Introduction to gradient descent Prof. J.C. Kao, UCLA Introduction to gradient descent Derivation and intuitions Hessian 6-2: Introduction to gradient descent Prof. J.C. Kao, UCLA Introduction Our
6-1: Introduction to gradient descent Prof. J.C. Kao, UCLA Introduction to gradient descent Derivation and intuitions Hessian 6-2: Introduction to gradient descent Prof. J.C. Kao, UCLA Introduction Our
Machine Learning for Signal Processing Sparse and Overcomplete Representations
 Machine Learning for Signal Processing Sparse and Overcomplete Representations Abelino Jimenez (slides from Bhiksha Raj and Sourish Chaudhuri) Oct 1, 217 1 So far Weights Data Basis Data Independent ICA
Machine Learning for Signal Processing Sparse and Overcomplete Representations Abelino Jimenez (slides from Bhiksha Raj and Sourish Chaudhuri) Oct 1, 217 1 So far Weights Data Basis Data Independent ICA
CSC2515 Winter 2015 Introduction to Machine Learning. Lecture 2: Linear regression
 CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
17 Solution of Nonlinear Systems
 17 Solution of Nonlinear Systems We now discuss the solution of systems of nonlinear equations. An important ingredient will be the multivariate Taylor theorem. Theorem 17.1 Let D = {x 1, x 2,..., x m
17 Solution of Nonlinear Systems We now discuss the solution of systems of nonlinear equations. An important ingredient will be the multivariate Taylor theorem. Theorem 17.1 Let D = {x 1, x 2,..., x m
Linear Classifiers. Michael Collins. January 18, 2012
 Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
13. Nonlinear least squares
 L. Vandenberghe ECE133A (Fall 2018) 13. Nonlinear least squares definition and examples derivatives and optimality condition Gauss Newton method Levenberg Marquardt method 13.1 Nonlinear least squares
L. Vandenberghe ECE133A (Fall 2018) 13. Nonlinear least squares definition and examples derivatives and optimality condition Gauss Newton method Levenberg Marquardt method 13.1 Nonlinear least squares
BACKPROPAGATION. Neural network training optimization problem. Deriving backpropagation
 BACKPROPAGATION Neural network training optimization problem min J(w) w The application of gradient descent to this problem is called backpropagation. Backpropagation is gradient descent applied to J(w)
BACKPROPAGATION Neural network training optimization problem min J(w) w The application of gradient descent to this problem is called backpropagation. Backpropagation is gradient descent applied to J(w)
Regression with Numerical Optimization. Logistic
 CSG220 Machine Learning Fall 2008 Regression with Numerical Optimization. Logistic regression Regression with Numerical Optimization. Logistic regression based on a document by Andrew Ng October 3, 204
CSG220 Machine Learning Fall 2008 Regression with Numerical Optimization. Logistic regression Regression with Numerical Optimization. Logistic regression based on a document by Andrew Ng October 3, 204
Mobile Robotics 1. A Compact Course on Linear Algebra. Giorgio Grisetti
 Mobile Robotics 1 A Compact Course on Linear Algebra Giorgio Grisetti SA-1 Vectors Arrays of numbers They represent a point in a n dimensional space 2 Vectors: Scalar Product Scalar-Vector Product Changes
Mobile Robotics 1 A Compact Course on Linear Algebra Giorgio Grisetti SA-1 Vectors Arrays of numbers They represent a point in a n dimensional space 2 Vectors: Scalar Product Scalar-Vector Product Changes
KillingFusion: Non-rigid 3D Reconstruction without Correspondences. Supplementary Material
 KillingFusion: Non-rigid 3D Reconstruction without Correspondences Supplementary Material Miroslava Slavcheva 1, Maximilian Baust 1 Daniel Cremers 1 Slobodan Ilic 1, {mira.slavcheva,maximilian.baust,cremers}@tum.de,
KillingFusion: Non-rigid 3D Reconstruction without Correspondences Supplementary Material Miroslava Slavcheva 1, Maximilian Baust 1 Daniel Cremers 1 Slobodan Ilic 1, {mira.slavcheva,maximilian.baust,cremers}@tum.de,
Recap: edge detection. Source: D. Lowe, L. Fei-Fei
 Recap: edge detection Source: D. Lowe, L. Fei-Fei Canny edge detector 1. Filter image with x, y derivatives of Gaussian 2. Find magnitude and orientation of gradient 3. Non-maximum suppression: Thin multi-pixel
Recap: edge detection Source: D. Lowe, L. Fei-Fei Canny edge detector 1. Filter image with x, y derivatives of Gaussian 2. Find magnitude and orientation of gradient 3. Non-maximum suppression: Thin multi-pixel
Introduction to General and Generalized Linear Models
 Introduction to General and Generalized Linear Models Mixed effects models - Part IV Henrik Madsen Poul Thyregod Informatics and Mathematical Modelling Technical University of Denmark DK-2800 Kgs. Lyngby
Introduction to General and Generalized Linear Models Mixed effects models - Part IV Henrik Madsen Poul Thyregod Informatics and Mathematical Modelling Technical University of Denmark DK-2800 Kgs. Lyngby
1 Bayesian Linear Regression (BLR)
") Statistical Techniques in Robotics (STR, S15) Lecture#10 (Wednesday, February 11) Lecturer: Byron Boots Gaussian Properties, Bayesian Linear Regression 1 Bayesian Linear Regression (BLR) In linear regression,
Statistical Techniques in Robotics (STR, S15) Lecture#10 (Wednesday, February 11) Lecturer: Byron Boots Gaussian Properties, Bayesian Linear Regression 1 Bayesian Linear Regression (BLR) In linear regression,
Numerical Optimization Professor Horst Cerjak, Horst Bischof, Thomas Pock Mat Vis-Gra SS09
 Numerical Optimization 1 Working Horse in Computer Vision Variational Methods Shape Analysis Machine Learning Markov Random Fields Geometry Common denominator: optimization problems 2 Overview of Methods
Numerical Optimization 1 Working Horse in Computer Vision Variational Methods Shape Analysis Machine Learning Markov Random Fields Geometry Common denominator: optimization problems 2 Overview of Methods
Introduction to motion correspondence
 Introduction to motion correspondence 1 IPAM - UCLA July 24, 2013 Iasonas Kokkinos Center for Visual Computing Ecole Centrale Paris / INRIA Saclay Why estimate visual motion? 2 Tracking Segmentation Structure
Introduction to motion correspondence 1 IPAM - UCLA July 24, 2013 Iasonas Kokkinos Center for Visual Computing Ecole Centrale Paris / INRIA Saclay Why estimate visual motion? 2 Tracking Segmentation Structure
Methods in Computer Vision: Introduction to Optical Flow
 Methods in Computer Vision: Introduction to Optical Flow Oren Freifeld Computer Science, Ben-Gurion University March 22 and March 26, 2017 Mar 22, 2017 1 / 81 A Preliminary Discussion Example and Flow
Methods in Computer Vision: Introduction to Optical Flow Oren Freifeld Computer Science, Ben-Gurion University March 22 and March 26, 2017 Mar 22, 2017 1 / 81 A Preliminary Discussion Example and Flow
On prediction. Jussi Hakanen Post-doctoral researcher. TIES445 Data mining (guest lecture)
") On prediction Jussi Hakanen Post-doctoral researcher jussi.hakanen@jyu.fi Learning outcomes To understand the basic principles of prediction To understand linear regression in prediction To be aware of
On prediction Jussi Hakanen Post-doctoral researcher jussi.hakanen@jyu.fi Learning outcomes To understand the basic principles of prediction To understand linear regression in prediction To be aware of
CS229 Supplemental Lecture notes
 CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
Optimization Tutorial 1. Basic Gradient Descent
 E0 270 Machine Learning Jan 16, 2015 Optimization Tutorial 1 Basic Gradient Descent Lecture by Harikrishna Narasimhan Note: This tutorial shall assume background in elementary calculus and linear algebra.
E0 270 Machine Learning Jan 16, 2015 Optimization Tutorial 1 Basic Gradient Descent Lecture by Harikrishna Narasimhan Note: This tutorial shall assume background in elementary calculus and linear algebra.
Optical Flow, Motion Segmentation, Feature Tracking
 BIL 719 - Computer Vision May 21, 2014 Optical Flow, Motion Segmentation, Feature Tracking Aykut Erdem Dept. of Computer Engineering Hacettepe University Motion Optical Flow Motion Segmentation Feature
BIL 719 - Computer Vision May 21, 2014 Optical Flow, Motion Segmentation, Feature Tracking Aykut Erdem Dept. of Computer Engineering Hacettepe University Motion Optical Flow Motion Segmentation Feature
Linear Regression 1 / 25. Karl Stratos. June 18, 2018
 Linear Regression Karl Stratos June 18, 2018 1 / 25 The Regression Problem Problem. Find a desired input-output mapping f : X R where the output is a real value. x = = y = 0.1 How much should I turn my
Linear Regression Karl Stratos June 18, 2018 1 / 25 The Regression Problem Problem. Find a desired input-output mapping f : X R where the output is a real value. x = = y = 0.1 How much should I turn my
Generalized Gradient Descent Algorithms
 ECE 275AB Lecture 11 Fall 2008 V1.1 c K. Kreutz-Delgado, UC San Diego p. 1/1 Lecture 11 ECE 275A Generalized Gradient Descent Algorithms ECE 275AB Lecture 11 Fall 2008 V1.1 c K. Kreutz-Delgado, UC San
ECE 275AB Lecture 11 Fall 2008 V1.1 c K. Kreutz-Delgado, UC San Diego p. 1/1 Lecture 11 ECE 275A Generalized Gradient Descent Algorithms ECE 275AB Lecture 11 Fall 2008 V1.1 c K. Kreutz-Delgado, UC San
Normalization Techniques
 Normalization Techniques Devansh Arpit Normalization Techniques 1 / 39 Table of Contents 1 Introduction 2 Motivation 3 Batch Normalization 4 Normalization Propagation 5 Weight Normalization 6 Layer Normalization
Normalization Techniques Devansh Arpit Normalization Techniques 1 / 39 Table of Contents 1 Introduction 2 Motivation 3 Batch Normalization 4 Normalization Propagation 5 Weight Normalization 6 Layer Normalization
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Linear Classifiers. Blaine Nelson, Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
Presentation in Convex Optimization
 Dec 22, 2014 Introduction Sample size selection in optimization methods for machine learning Introduction Sample size selection in optimization methods for machine learning Main results: presents a methodology
Dec 22, 2014 Introduction Sample size selection in optimization methods for machine learning Introduction Sample size selection in optimization methods for machine learning Main results: presents a methodology
Introduction to Mobile Robotics Compact Course on Linear Algebra. Wolfram Burgard, Cyrill Stachniss, Kai Arras, Maren Bennewitz
 Introduction to Mobile Robotics Compact Course on Linear Algebra Wolfram Burgard, Cyrill Stachniss, Kai Arras, Maren Bennewitz Vectors Arrays of numbers Vectors represent a point in a n dimensional space
Introduction to Mobile Robotics Compact Course on Linear Algebra Wolfram Burgard, Cyrill Stachniss, Kai Arras, Maren Bennewitz Vectors Arrays of numbers Vectors represent a point in a n dimensional space
Iterative Reweighted Least Squares
 Iterative Reweighted Least Squares Sargur. University at Buffalo, State University of ew York USA Topics in Linear Classification using Probabilistic Discriminative Models Generative vs Discriminative
Iterative Reweighted Least Squares Sargur. University at Buffalo, State University of ew York USA Topics in Linear Classification using Probabilistic Discriminative Models Generative vs Discriminative
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Predictive Models Predictive Models 1 / 34 Outline
Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Predictive Models Predictive Models 1 / 34 Outline
Feature extraction: Corners and blobs
 Feature extraction: Corners and blobs Review: Linear filtering and edge detection Name two different kinds of image noise Name a non-linear smoothing filter What advantages does median filtering have over
Feature extraction: Corners and blobs Review: Linear filtering and edge detection Name two different kinds of image noise Name a non-linear smoothing filter What advantages does median filtering have over
Spatial Transformer Networks
 BIL722 - Deep Learning for Computer Vision Spatial Transformer Networks Max Jaderberg Andrew Zisserman Karen Simonyan Koray Kavukcuoglu Contents Introduction to Spatial Transformers Related Works Spatial
BIL722 - Deep Learning for Computer Vision Spatial Transformer Networks Max Jaderberg Andrew Zisserman Karen Simonyan Koray Kavukcuoglu Contents Introduction to Spatial Transformers Related Works Spatial
11 a 12 a 21 a 11 a 22 a 12 a 21. (C.11) A = The determinant of a product of two matrices is given by AB = A B 1 1 = (C.13) and similarly.
 A = The determinant of a product of two matrices is given by AB = A B 1 1 = (C.13) and similarly.") C PROPERTIES OF MATRICES 697 to whether the permutation i 1 i 2 i N is even or odd, respectively Note that I =1 Thus, for a 2 2 matrix, the determinant takes the form A = a 11 a 12 = a a 21 a 11 a 22 a
C PROPERTIES OF MATRICES 697 to whether the permutation i 1 i 2 i N is even or odd, respectively Note that I =1 Thus, for a 2 2 matrix, the determinant takes the form A = a 11 a 12 = a a 21 a 11 a 22 a
Ch6-Normalized Least Mean-Square Adaptive Filtering
 Ch6-Normalized Least Mean-Square Adaptive Filtering LMS Filtering The update equation for the LMS algorithm is wˆ wˆ u ( n 1) ( n) ( n) e ( n) Step size Filter input which is derived from SD as an approximation
Ch6-Normalized Least Mean-Square Adaptive Filtering LMS Filtering The update equation for the LMS algorithm is wˆ wˆ u ( n 1) ( n) ( n) e ( n) Step size Filter input which is derived from SD as an approximation
Lecture 6. Notes on Linear Algebra. Perceptron
 Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
DATA MINING AND MACHINE LEARNING. Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
Corners, Blobs & Descriptors. With slides from S. Lazebnik & S. Seitz, D. Lowe, A. Efros
 Corners, Blobs & Descriptors With slides from S. Lazebnik & S. Seitz, D. Lowe, A. Efros Motivation: Build a Panorama M. Brown and D. G. Lowe. Recognising Panoramas. ICCV 2003 How do we build panorama?
Corners, Blobs & Descriptors With slides from S. Lazebnik & S. Seitz, D. Lowe, A. Efros Motivation: Build a Panorama M. Brown and D. G. Lowe. Recognising Panoramas. ICCV 2003 How do we build panorama?
Machine Learning I Continuous Reinforcement Learning
 Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Visual meta-learning for planning and control
 Visual meta-learning for planning and control Seminar on Current Works in Computer Vision @ Chair of Pattern Recognition and Image Processing. Samuel Roth Winter Semester 2018/19 Albert-Ludwigs-Universität
Visual meta-learning for planning and control Seminar on Current Works in Computer Vision @ Chair of Pattern Recognition and Image Processing. Samuel Roth Winter Semester 2018/19 Albert-Ludwigs-Universität
Lecture 14: October 17
 1-725/36-725: Convex Optimization Fall 218 Lecture 14: October 17 Lecturer: Lecturer: Ryan Tibshirani Scribes: Pengsheng Guo, Xian Zhou Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer:
1-725/36-725: Convex Optimization Fall 218 Lecture 14: October 17 Lecturer: Lecturer: Ryan Tibshirani Scribes: Pengsheng Guo, Xian Zhou Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer:
Optimization and Root Finding. Kurt Hornik
 Optimization and Root Finding Kurt Hornik Basics Root finding and unconstrained smooth optimization are closely related: Solving ƒ () = 0 can be accomplished via minimizing ƒ () 2 Slide 2 Basics Root finding
Optimization and Root Finding Kurt Hornik Basics Root finding and unconstrained smooth optimization are closely related: Solving ƒ () = 0 can be accomplished via minimizing ƒ () 2 Slide 2 Basics Root finding
A STATISTICAL APPROACH TO IMAGE WARPING. Chris Glasbey. Biomathematics and Statistics Scotland
 A STATISTICAL APPROACH TO IMAGE WARPING Chris Glasbey Biomathematics and Statistics Scotland IMAGE ANALYSIS: the extraction of information from pictures Which line is longer? Who is this? 2 The human eye/brain
A STATISTICAL APPROACH TO IMAGE WARPING Chris Glasbey Biomathematics and Statistics Scotland IMAGE ANALYSIS: the extraction of information from pictures Which line is longer? Who is this? 2 The human eye/brain
Reconnaissance d objetsd et vision artificielle
 Reconnaissance d objetsd et vision artificielle http://www.di.ens.fr/willow/teaching/recvis09 Lecture 6 Face recognition Face detection Neural nets Attention! Troisième exercice de programmation du le
Reconnaissance d objetsd et vision artificielle http://www.di.ens.fr/willow/teaching/recvis09 Lecture 6 Face recognition Face detection Neural nets Attention! Troisième exercice de programmation du le
Sparse Levenberg-Marquardt algorithm.
 Sparse Levenberg-Marquardt algorithm. R. I. Hartley and A. Zisserman: Multiple View Geometry in Computer Vision. Cambridge University Press, second edition, 2004. Appendix 6 was used in part. The Levenberg-Marquardt
Sparse Levenberg-Marquardt algorithm. R. I. Hartley and A. Zisserman: Multiple View Geometry in Computer Vision. Cambridge University Press, second edition, 2004. Appendix 6 was used in part. The Levenberg-Marquardt
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Normalization Techniques in Training of Deep Neural Networks
 Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
On-line Support Vector Machine Regression
 Index On-line Support Vector Machine Regression Mario Martín Software Department KEML Group Universitat Politècnica de Catalunya Motivation and antecedents Formulation of SVM regression Characterization
Index On-line Support Vector Machine Regression Mario Martín Software Department KEML Group Universitat Politècnica de Catalunya Motivation and antecedents Formulation of SVM regression Characterization
A Generative Perspective on MRFs in Low-Level Vision Supplemental Material
 A Generative Perspective on MRFs in Low-Level Vision Supplemental Material Uwe Schmidt Qi Gao Stefan Roth Department of Computer Science, TU Darmstadt 1. Derivations 1.1. Sampling the Prior We first rewrite
A Generative Perspective on MRFs in Low-Level Vision Supplemental Material Uwe Schmidt Qi Gao Stefan Roth Department of Computer Science, TU Darmstadt 1. Derivations 1.1. Sampling the Prior We first rewrite
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Logistic Regression. Seungjin Choi
 Logistic Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Logistic Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Cox regression: Estimation
 Cox regression: Estimation Patrick Breheny October 27 Patrick Breheny Survival Data Analysis (BIOS 7210) 1/19 Introduction The Cox Partial Likelihood In our last lecture, we introduced the Cox partial
Cox regression: Estimation Patrick Breheny October 27 Patrick Breheny Survival Data Analysis (BIOS 7210) 1/19 Introduction The Cox Partial Likelihood In our last lecture, we introduced the Cox partial
Linear Methods for Regression. Lijun Zhang
 Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Differential Motion Analysis
 Differential Motion Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University, Evanston, IL 60208 yingwu@ece.northwestern.edu http://www.eecs.northwestern.edu/~yingwu July 19,
Differential Motion Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University, Evanston, IL 60208 yingwu@ece.northwestern.edu http://www.eecs.northwestern.edu/~yingwu July 19,
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Lecture 4: Linear predictors and the Perceptron
 Lecture 4: Linear predictors and the Perceptron Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 4 1 / 34 Inductive Bias Inductive bias is critical to prevent overfitting.
Lecture 4: Linear predictors and the Perceptron Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 4 1 / 34 Inductive Bias Inductive bias is critical to prevent overfitting.
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Optimization 2. CS5240 Theoretical Foundations in Multimedia. Leow Wee Kheng
 Optimization 2 CS5240 Theoretical Foundations in Multimedia Leow Wee Kheng Department of Computer Science School of Computing National University of Singapore Leow Wee Kheng (NUS) Optimization 2 1 / 38
Optimization 2 CS5240 Theoretical Foundations in Multimedia Leow Wee Kheng Department of Computer Science School of Computing National University of Singapore Leow Wee Kheng (NUS) Optimization 2 1 / 38
10-725/36-725: Convex Optimization Prerequisite Topics
 10-725/36-725: Convex Optimization Prerequisite Topics February 3, 2015 This is meant to be a brief, informal refresher of some topics that will form building blocks in this course. The content of the
10-725/36-725: Convex Optimization Prerequisite Topics February 3, 2015 This is meant to be a brief, informal refresher of some topics that will form building blocks in this course. The content of the
More Optimization. Optimization Methods. Methods
 More More Optimization Optimization Methods Methods Yann YannLeCun LeCun Courant CourantInstitute Institute http://yann.lecun.com http://yann.lecun.com (almost) (almost) everything everything you've you've
More More Optimization Optimization Methods Methods Yann YannLeCun LeCun Courant CourantInstitute Institute http://yann.lecun.com http://yann.lecun.com (almost) (almost) everything everything you've you've
Incremental and Decremental Training for Linear Classification
 Incremental and Decremental Training for Linear Classification Authors: Cheng-Hao Tsai, Chieh-Yen Lin, and Chih-Jen Lin Department of Computer Science National Taiwan University Presenter: Ching-Pei Lee
Incremental and Decremental Training for Linear Classification Authors: Cheng-Hao Tsai, Chieh-Yen Lin, and Chih-Jen Lin Department of Computer Science National Taiwan University Presenter: Ching-Pei Lee
Vasil Khalidov & Miles Hansard. C.M. Bishop s PRML: Chapter 5; Neural Networks
 C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
CSC321 Lecture 2: Linear Regression
 CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
j=1 r 1 x 1 x n. r m r j (x) r j r j (x) r j (x). r j x k
 r j r j (x) r j (x). r j x k") Maria Cameron Nonlinear Least Squares Problem The nonlinear least squares problem arises when one needs to find optimal set of parameters for a nonlinear model given a large set of data The variables x,,
Maria Cameron Nonlinear Least Squares Problem The nonlinear least squares problem arises when one needs to find optimal set of parameters for a nonlinear model given a large set of data The variables x,,
Learning gradients: prescriptive models
 Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Spatial Transformation
 Spatial Transformation Presented by Liqun Chen June 30, 2017 1 Overview 2 Spatial Transformer Networks 3 STN experiments 4 Recurrent Models of Visual Attention (RAM) 5 Recurrent Models of Visual Attention
Spatial Transformation Presented by Liqun Chen June 30, 2017 1 Overview 2 Spatial Transformer Networks 3 STN experiments 4 Recurrent Models of Visual Attention (RAM) 5 Recurrent Models of Visual Attention
Machine Learning. Regression. Manfred Huber
 Machine Learning Regression Manfred Huber 2015 1 Regression Regression refers to supervised learning problems where the target output is one or more continuous values Continuous output values imply that
Machine Learning Regression Manfred Huber 2015 1 Regression Regression refers to supervised learning problems where the target output is one or more continuous values Continuous output values imply that
5 Handling Constraints
 5 Handling Constraints Engineering design optimization problems are very rarely unconstrained. Moreover, the constraints that appear in these problems are typically nonlinear. This motivates our interest
5 Handling Constraints Engineering design optimization problems are very rarely unconstrained. Moreover, the constraints that appear in these problems are typically nonlinear. This motivates our interest
Numerical solution of Least Squares Problems 1/32
 Numerical solution of Least Squares Problems 1/32 Linear Least Squares Problems Suppose that we have a matrix A of the size m n and the vector b of the size m 1. The linear least square problem is to find
Numerical solution of Least Squares Problems 1/32 Linear Least Squares Problems Suppose that we have a matrix A of the size m n and the vector b of the size m 1. The linear least square problem is to find
Edges and Scale. Image Features. Detecting edges. Origin of Edges. Solution: smooth first. Effects of noise
 Edges and Scale Image Features From Sandlot Science Slides revised from S. Seitz, R. Szeliski, S. Lazebnik, etc. Origin of Edges surface normal discontinuity depth discontinuity surface color discontinuity
Edges and Scale Image Features From Sandlot Science Slides revised from S. Seitz, R. Szeliski, S. Lazebnik, etc. Origin of Edges surface normal discontinuity depth discontinuity surface color discontinuity