Quantifying Fingerprint Evidence using Bayesian Alignment
|
|
|
- Nickolas Hodge
- 5 years ago
- Views:
Transcription
1 Quantifying Fingerprint Evidence using Bayesian Alignment Peter Forbes Joint work with Steffen Lauritzen and Jesper Møller Department of Statistics University of Oxford UCL CSML Lunch Talk 14 February 2014
2 History of fingerprints Fingerprints have been used to authenticate legal documents in China since 300 BC Scottish missionary Henry Faulds first used fingerprints for forensic identification in 1880 Sir Francis Galton established in 1892 that fingerprints are invariant over time and crudely estimated that Probability two fingerprints are identical = 1/68 billion Yet crime scene prints are often partial and blurry
3 Strength of evidence For its entire history, fingerprint evidence has been presented categorically Of all the methods of identification, fingerprinting alone has proved to be both infallible and feasible (FBI training manual, 1963) From a statistical viewpoint, the scientific foundation for fingerprint individuality is incredibly weak... there has been much speculation and little data. None of the models has been subjected to testing, which is of course the basic element of the scientific approach (Stoney, 2001)
4 Motivation Fingerprint evidence is forensic acme: UK has 330,000 crime scene prints collected each year and 34,000 identifications Recent push to follow DNA evidence and quantify the uncertainty (Neumann et al., 2012) My model attempts this by computing the likelihood ratio between two competing models: H p : A and B originate from the same finger H d : A and B originate from independent fingers. Test using a public dataset from the NIST-FBI (Garris and McCabe, 2000)



5 Fingerprints as minutia sets Figure: An example fingerprint with minutiae labelled Minutiae are points where epidermal ridges end or bifurcate Represent with m = (r C, s S 1, t {0, 1}), where S 1 is the unit circle embedded in C Most fingers have around 135 minutiae
6 Preliminaries Define the complex Normal distribution on C n as Z CN n (µ, Σ) Re(Z µ), Im(Z µ) iid N n(0, Σ/2) with density ϕ n (z; µ, Σ) Define the root von Mises distribution on S 1 as X, Y iid rvm(κ) Pr(XY ) = exp{κre(x Ȳ )}/{2πI 0 (κ)} A set of points A V form a marked Poisson point process with rate ρ and mark distribution g (denoted MPPP(ρ, g)) iff Number of points in any two disjoint regions are independent Number of points in v V Poisson( v ρ(r)dr) Each point has a mark, and marks are iid with density g Conditional on A, Pr(A) r A ρ(r)g(mark(r))
7 Model for latent finger Like Green and Mardia (2006), we view the observed point sets as partial, distorted copies of a latent true point set Latent minutiae are distributed as MPPP(ρ, g) on C with ρ(r) = ρ 0 ϕ 1 (r; 0, σ 2 ) and g(s, t) = p t (1 p) 1 t /(2π) for ρ 0 > 0, σ > 0 and p (0, 1)
8 Model for observed minutia sets m l observed w.p. q A {m a = (r a, s a, t a )} r a r a + CN(0, ω 2 ) s a s a + rvm(κ) Latent finger {m l = (r l, s l, t l )} Independent Binomial Thinning q A, q B (0, 1) Independent Observation Errors ω, κ > 0 m l observed w.p. q B {m b = (r b, s b, t b )} r b r b + CN(0, ω 2 ) s b s b + rvm(κ) r a ψ A (r a + τ A ) s b ψ A s b Rigid motion τ A, τ B C 2 ψ A, ψ B S 1 r a ψ B (r a + τ B ) s b ψ B s b Fingerprint Fingermark A = {(r a, s a, t a )} Observed minutia sets B = {(r b, s b, t b )}

9 Introduction Model Example fingerprint Algorithm Results Future work References

10 Example high-quality fingermark

11 Introduction Model Algorithm Example overlaid with a rigid motion Results Future work References
12 Finding the densities Desire the likelihood ratio LR = Pr(A, B H p) Pr(A, B H d ) First we need to find the densities under H d and H p These will depend on the constants ρ 0, p, ω, κ Will also depend on the variables θ = (q A, q B, τ A, τ B, ψ, σ)
13 Finding the densities Under H d, A and B are from independent latent fingers. By integrating over the latent minutia, we have Pr(A, B θ, H d ) ρ A (r a )g(s a, t a ) (r a,s a,t a) A ρ B (r b )g(s b, t b ) where ρ A and ρ B are given by (r b,s b,t b ) B ρ A (r a ) = ρ 0 q A ϕ 1 (r a ; τ A, σ 2 + ω 2 ) ρ B (r b ) = ρ 0 q B ϕ 1 (r b ; τ B, σ 2 + ω 2 ) This can be integrated analytically over θ
14 Finding the densities Under H p we observe A = M 10 {m a : (m a, m b ) M 11 } and B = M 01 {m b : (m a, m b ) M 11 } where M 10 MPPP((1 q B )ρ A ( ), g) are the points observed in A not B M 01 MPPP((1 q A )ρ B ( ), g) are the points observed in B not A M 11 MPPP(ρ 11, g 11 ) are the points observed in both A and B Note M 11 is a MPPP on C 2. Integrating over the latent true minutia (r, s, t), we have (( ) ra ρ 11 (r a, r b ) = ρ 0 q A q B ϕ 2 ; r b ( τa τ B ) ( σ, 2 + ω 2 σ 2 )) ψ σ 2 ψ σ 2 + ω 2 g 11 (s a, t a, s b, t b ) = I(t a = t b ) pta (1 p) 1 ta 4π 2 exp{κre(s a s b ψ)} I 0 (κ) where ψ = ψ A ψb is the rotation between A and B
15 Finding the densities The density under H p is thus Pr(A, B θ, H p ) (1 q B )ρ A (r a )g(s a, t a ) (r a,s a,t a) M 01 (1 q A )ρ B (r b )g(s b, t b ) (r b,s b,t b ) M 10 (r a,s a,t a) (r b,s b,t b ) M 11 ρ 11 (r a, r b )g 11 (s a, t a, s b, t b ) but we only observe A = M 10 {m a : (m a, m b ) M 11 } and B = M 01 {m b : (m a, m b ) M 11 }! Need to treat the matching ξ between A and B as an unknown variable and sum over its possible values
16 Computing the likelihood ratio τ A, τ B, ψ, σ are assigned (improper) flat priors π, which ensures LR is invariant under similarity transformations q A has a conjugate Beta prior with hyperparameters α, β q B has a flat prior ρ 0, p, ω, κ, α, β are constants to be estimated by MLE Find LR by marginalizing over θ and ξ ξ Pr(A, B, ξ θ, Hp )π(θ)dθ LR = Pr(A, B θ, Hd )π(θ)dθ Sum in numerator contains many terms min( A, B ) n=0 Use MCMC to approximate the LR A! B! n!( A n)!( B n)! 10100
17 An estimate for LR Define the joint distribution of (θ, ξ, H) by { p 0 Pr(A, B, ξ θ, H p )π(θ) if H = H p, Pr(θ, ξ, H, A, B) = (1 p 0 )Pr(A, B H d )q(ξ θ)q(θ) if H = H d. where p 0 (0, 1) and the densities q are chosen to promote good mixing of our MCMC over the model space By sampling from this, we can approximate LR by replacing the below expectation with its sample average: LR = Pr(A, B H p) Pr(A, B H d ) = p 0 1 p 0 E θ,ξ,h A,B [I (H = H p )] E θ,ξ,h A,B [I (H = H d )].
18 Tuning the sampler To accurately estimate LR we must switch models often, i.e. p 0 Pr(A, B, ξ θ, H p )π(θ) (1 p 0 )Pr(A, B H d )q(ξ θ)q(θ) We have severe problems with local modes under H p due to the high dimensionality of ξ Attempting to tune q(θ) often resulted in tuning to the current local mode, so we use a fixed diffuse distribution We choose q(ξ θ) to approximate Pr(θ, ξ A, B, H p ) Put some arbitrary ordering on A and let ξ α = {(a, b) ξ : a < α}, B α = {b B : (a, b) ξ α } q(ξ θ) = A α=1 Pr(θ, ξ α+1, H p, A, B) b (B\B Pr(θ, ξ α) α (α, b), H p, A, B)
19 A better estimate for LR We want to choose p 0 so that p 0 Pr(A, B, ξ θ, H p )π(θ) (1 p 0 )Pr(A, B H d )q(ξ θ)q(θ) over a large portion of the state space (θ, ξ) This is very difficult, so we tune p 0 to ensure good mixing based on our previous samples Letting l(θ, ξ, A, B) = Pr(θ, ξ, A, B H p )/Pr(θ, ξ, A, B H d ), [ E θ,ξ A,B {1 p 0 + p 0 /l(θ, ξ, A, B)} 1] LR = [ E θ,ξ A,B {p 0 + (1 p 0 )l(θ, ξ, A, B)} 1]. Can show that replacing the expectations with sample averages leads to an valid estimator of LR even if we change p 0 each iteration! p0 n n m=n p0 n = {1 + 1/l(θm, ξ m, A, B)} 1 n m=n 100 {1 + l(θm, ξ m, A, B)} 1
20 Gibbs sampler Algorithm 1 Gibbs sampler for joint posterior of (θ, ξ, H) Require: θ 0, ξ 0 set to some initial value. Set H 0 = H p. for n = 1,..., N do if H = H p then (qa n, qn B ) Sample ( q A, q B A, B, τ n 1 A, τ n 1 B, σ n 1, ψ n 1, ξ n 1, H n 1) (τa n, τ B n) Sample ( τ A, τ B A, B, qa n, qn B, σn 1, ψ n 1, ξ n 1, H n 1) σ n Sample ( σ A, B, qa n, qn B, τ A n, τ B n, ψn 1, ξ n 1, H n 1) ψ n Sample ( ψ A, B, qa n, qn B, τ A n, τ B n, σn, ξ n 1, H n 1) ξ n ξ n 1 for j = 1,..., n A do do repeatedly to reduce autocorrelation ξ n Sample ( ξ A, B, qa n, qn B, τ A n, τ B n, σn, ψ n, ξ n, H n 1) end for end if p0 n adaptive value to increase mixing in H H n Sample (H A, B, qa n, qn B, τ A n, τ B n, σn, ψ n, ξ n ) end for Not quite reversible jump: we don t change states under H d This approach provides better model mixing when the proposal distributions q(θ, ξ) are far from the posterior distributions
21 ξ sampler Basic Metropolis Hastings algorithm like (Green and Mardia, 2006) has accept rates less than 10 5 infeasibly slow Instead we sample directly by reducing the adjacent states with an auxiliary variable α which takes values uniformly on A There are B + 1 states adjacent to any (α, ξ), obtained by matching α to each b B or leaving α unmatched α b α b α α b α b (a) Add (b) Swap b (c) Remove (d) Swap a (e) Swap Figure: Matches ξ which are adjacent to (α, ξ 0 ).
 based on fingermark quality Figure: Example fingermarks from Garris and McCabe")
22 NIST-FBI dataset NIST-FBI dataset of 258 fingerprint/fingermark pairs All images have their minutiae labelled by expert examiners Split into three subsets (good, bad, and ugly) based on fingermark quality Figure: Example fingermarks from Garris and McCabe (2000).
23 Simulated dataset Generated 258 fingerprint/fingermark pairs based on model assumptions Split into three sets (good, bad, and ugly) in order of decreasing B Computed all pairwise likelihood ratios Computed LRs are almost entirely determined by B

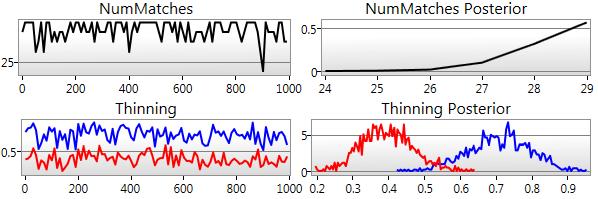
24 MCMC behavior

25 MCMC behavior
26 Results: simulated data 0.15 G B U Histogram of the log 10 -likelihood ratios for good, bad and ugly simulated fingermarks. Inset ROC curve has false
27 Results: NIST-FBI data 0.15 G B U Histogram of the log 10 -likelihood ratios for good, bad and ugly NIST-FBI fingermarks. Inset ROC curve has false

28 Better model for latent minutiae The intensity for the latent finger MPPP is inaccurate, since most minutiae occur in areas of high minutia curvature Figure: Minutia density over various fingerprints from Chen and Jain (2009)

29 Better distortion model Basic model assumes observed minutiae vary from true minutiae by a rigid motion and iid noise Actually, nearby minutiae have spatially correlated distortions Account for this using a smoothing thin plate spline model, which leads to a Gaussian process for the distortions Figure: Example smoothing thin plate spline from Chui and Rangarajan (2000)
30 Conclusion We have developed a simple model to quantify the strength of evidence for forensic fingerprints Better latent distributions and distortion models will increase discrimination between true and false matches Must manage trade off between model complexity and computational efficiency Computed likelihood ratios should be calibrated against ground-truth database
31 Conclusion Chen, Y. and A. K. Jain (2009). Beyond minutiae: A fingerprint individuality model with pattern, ridge and pore features. Chui, H. and A. Rangarajan (2000). A new algorithm for non-rigid point matching. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp Garris, M. and R. McCabe (2000). NIST special database 27: Fingerprint minutiae from latent and matching tenprint images. Technical report, NIST, Gaithersburg, MD, USA. Green, P. J. and K. V. Mardia (2006). Bayesian alignment using hierarchical models, with applications in protein bioinformatics. Biometrika 93(2), Neumann, C., I. W. Evett, and J. E. Skerrett (2012). Quantifying the weight of evidence from a forensic fingerprint comparison: a new paradigm (with discussion). Journal of the Royal Statistical Society: Series A 175(2),
AALBORG UNIVERSITY. Fingerprint analysis with marked point processes. Peter G. M. Forbes, Steffen Lauritzen and Jesper Møller
 AALBORG UNIVERSITY Fingerprint analysis with marked point processes by Peter G. M. Forbes, Steffen Lauritzen and Jesper Møller R-214-6 July 214 Department of Mathematical Sciences Aalborg University Fredrik
AALBORG UNIVERSITY Fingerprint analysis with marked point processes by Peter G. M. Forbes, Steffen Lauritzen and Jesper Møller R-214-6 July 214 Department of Mathematical Sciences Aalborg University Fredrik
Markov Chain Monte Carlo methods
 Markov Chain Monte Carlo methods Tomas McKelvey and Lennart Svensson Signal Processing Group Department of Signals and Systems Chalmers University of Technology, Sweden November 26, 2012 Today s learning
Markov Chain Monte Carlo methods Tomas McKelvey and Lennart Svensson Signal Processing Group Department of Signals and Systems Chalmers University of Technology, Sweden November 26, 2012 Today s learning
Bayesian model selection for computer model validation via mixture model estimation
 Bayesian model selection for computer model validation via mixture model estimation Kaniav Kamary ATER, CNAM Joint work with É. Parent, P. Barbillon, M. Keller and N. Bousquet Outline Computer model validation
Bayesian model selection for computer model validation via mixture model estimation Kaniav Kamary ATER, CNAM Joint work with É. Parent, P. Barbillon, M. Keller and N. Bousquet Outline Computer model validation
On the Individuality of Fingerprints: Models and Methods
 On the Individuality of Fingerprints: Models and Methods Dass, S., Pankanti, S., Prabhakar, S., and Zhu, Y. Abstract Fingerprint individuality is the study of the extent of uniqueness of fingerprints and
On the Individuality of Fingerprints: Models and Methods Dass, S., Pankanti, S., Prabhakar, S., and Zhu, Y. Abstract Fingerprint individuality is the study of the extent of uniqueness of fingerprints and
Metropolis-Hastings Algorithm
 Strength of the Gibbs sampler Metropolis-Hastings Algorithm Easy algorithm to think about. Exploits the factorization properties of the joint probability distribution. No difficult choices to be made to
Strength of the Gibbs sampler Metropolis-Hastings Algorithm Easy algorithm to think about. Exploits the factorization properties of the joint probability distribution. No difficult choices to be made to
Bayesian model selection in graphs by using BDgraph package
 Bayesian model selection in graphs by using BDgraph package A. Mohammadi and E. Wit March 26, 2013 MOTIVATION Flow cytometry data with 11 proteins from Sachs et al. (2005) RESULT FOR CELL SIGNALING DATA
Bayesian model selection in graphs by using BDgraph package A. Mohammadi and E. Wit March 26, 2013 MOTIVATION Flow cytometry data with 11 proteins from Sachs et al. (2005) RESULT FOR CELL SIGNALING DATA
Adaptive HMC via the Infinite Exponential Family
 Adaptive HMC via the Infinite Exponential Family Arthur Gretton Gatsby Unit, CSML, University College London RegML, 2017 Arthur Gretton (Gatsby Unit, UCL) Adaptive HMC via the Infinite Exponential Family
Adaptive HMC via the Infinite Exponential Family Arthur Gretton Gatsby Unit, CSML, University College London RegML, 2017 Arthur Gretton (Gatsby Unit, UCL) Adaptive HMC via the Infinite Exponential Family
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Markov Chain Monte Carlo (MCMC)
") Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
A Review of Pseudo-Marginal Markov Chain Monte Carlo
 A Review of Pseudo-Marginal Markov Chain Monte Carlo Discussed by: Yizhe Zhang October 21, 2016 Outline 1 Overview 2 Paper review 3 experiment 4 conclusion Motivation & overview Notation: θ denotes the
A Review of Pseudo-Marginal Markov Chain Monte Carlo Discussed by: Yizhe Zhang October 21, 2016 Outline 1 Overview 2 Paper review 3 experiment 4 conclusion Motivation & overview Notation: θ denotes the
Creating Non-Gaussian Processes from Gaussian Processes by the Log-Sum-Exp Approach. Radford M. Neal, 28 February 2005
 Creating Non-Gaussian Processes from Gaussian Processes by the Log-Sum-Exp Approach Radford M. Neal, 28 February 2005 A Very Brief Review of Gaussian Processes A Gaussian process is a distribution over
Creating Non-Gaussian Processes from Gaussian Processes by the Log-Sum-Exp Approach Radford M. Neal, 28 February 2005 A Very Brief Review of Gaussian Processes A Gaussian process is a distribution over
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Deblurring Jupiter (sampling in GLIP faster than regularized inversion) Colin Fox Richard A. Norton, J.
 Colin Fox Richard A. Norton, J.") Deblurring Jupiter (sampling in GLIP faster than regularized inversion) Colin Fox fox@physics.otago.ac.nz Richard A. Norton, J. Andrés Christen Topics... Backstory (?) Sampling in linear-gaussian hierarchical
Deblurring Jupiter (sampling in GLIP faster than regularized inversion) Colin Fox fox@physics.otago.ac.nz Richard A. Norton, J. Andrés Christen Topics... Backstory (?) Sampling in linear-gaussian hierarchical
On the Evidential Value of Fingerprints
 On the Evidential Value of Fingerprints Heeseung Choi, Abhishek Nagar and Anil K. Jain Dept. of Computer Science and Engineering Michigan State University East Lansing, MI, U.S.A. {hschoi,nagarabh,jain}@cse.msu.edu
On the Evidential Value of Fingerprints Heeseung Choi, Abhishek Nagar and Anil K. Jain Dept. of Computer Science and Engineering Michigan State University East Lansing, MI, U.S.A. {hschoi,nagarabh,jain}@cse.msu.edu
Monte Carlo in Bayesian Statistics
 Monte Carlo in Bayesian Statistics Matthew Thomas SAMBa - University of Bath m.l.thomas@bath.ac.uk December 4, 2014 Matthew Thomas (SAMBa) Monte Carlo in Bayesian Statistics December 4, 2014 1 / 16 Overview
Monte Carlo in Bayesian Statistics Matthew Thomas SAMBa - University of Bath m.l.thomas@bath.ac.uk December 4, 2014 Matthew Thomas (SAMBa) Monte Carlo in Bayesian Statistics December 4, 2014 1 / 16 Overview
Bayesian Estimation of DSGE Models 1 Chapter 3: A Crash Course in Bayesian Inference
 1 The views expressed in this paper are those of the authors and do not necessarily reflect the views of the Federal Reserve Board of Governors or the Federal Reserve System. Bayesian Estimation of DSGE
1 The views expressed in this paper are those of the authors and do not necessarily reflect the views of the Federal Reserve Board of Governors or the Federal Reserve System. Bayesian Estimation of DSGE
Likelihood-free MCMC
 Bayesian inference for stable distributions with applications in finance Department of Mathematics University of Leicester September 2, 2011 MSc project final presentation Outline 1 2 3 4 Classical Monte
Bayesian inference for stable distributions with applications in finance Department of Mathematics University of Leicester September 2, 2011 MSc project final presentation Outline 1 2 3 4 Classical Monte
Bayesian Image Segmentation Using MRF s Combined with Hierarchical Prior Models
 Bayesian Image Segmentation Using MRF s Combined with Hierarchical Prior Models Kohta Aoki 1 and Hiroshi Nagahashi 2 1 Interdisciplinary Graduate School of Science and Engineering, Tokyo Institute of Technology
Bayesian Image Segmentation Using MRF s Combined with Hierarchical Prior Models Kohta Aoki 1 and Hiroshi Nagahashi 2 1 Interdisciplinary Graduate School of Science and Engineering, Tokyo Institute of Technology
Computational statistics
 Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
BAYESIAN METHODS FOR VARIABLE SELECTION WITH APPLICATIONS TO HIGH-DIMENSIONAL DATA
 BAYESIAN METHODS FOR VARIABLE SELECTION WITH APPLICATIONS TO HIGH-DIMENSIONAL DATA Intro: Course Outline and Brief Intro to Marina Vannucci Rice University, USA PASI-CIMAT 04/28-30/2010 Marina Vannucci
BAYESIAN METHODS FOR VARIABLE SELECTION WITH APPLICATIONS TO HIGH-DIMENSIONAL DATA Intro: Course Outline and Brief Intro to Marina Vannucci Rice University, USA PASI-CIMAT 04/28-30/2010 Marina Vannucci
Machine Learning Srihari. Gaussian Processes. Sargur Srihari
 Gaussian Processes Sargur Srihari 1 Topics in Gaussian Processes 1. Examples of use of GP 2. Duality: From Basis Functions to Kernel Functions 3. GP Definition and Intuition 4. Linear regression revisited
Gaussian Processes Sargur Srihari 1 Topics in Gaussian Processes 1. Examples of use of GP 2. Duality: From Basis Functions to Kernel Functions 3. GP Definition and Intuition 4. Linear regression revisited
A Minutiae-based Fingerprint Individuality Model
 A Minutiae-based Fingerprint Individuality Model Jiansheng Chen Yiu-Sang Moon Department of Computer Science and Engineering, The Chinese University of Hong Kong, Shatin N.T., Hong Kong {jschen, ysmoon}@cse.cuhk.edu.hk
A Minutiae-based Fingerprint Individuality Model Jiansheng Chen Yiu-Sang Moon Department of Computer Science and Engineering, The Chinese University of Hong Kong, Shatin N.T., Hong Kong {jschen, ysmoon}@cse.cuhk.edu.hk
MONTE CARLO METHODS. Hedibert Freitas Lopes
 MONTE CARLO METHODS Hedibert Freitas Lopes The University of Chicago Booth School of Business 5807 South Woodlawn Avenue, Chicago, IL 60637 http://faculty.chicagobooth.edu/hedibert.lopes hlopes@chicagobooth.edu
MONTE CARLO METHODS Hedibert Freitas Lopes The University of Chicago Booth School of Business 5807 South Woodlawn Avenue, Chicago, IL 60637 http://faculty.chicagobooth.edu/hedibert.lopes hlopes@chicagobooth.edu
Introduction to Bayesian methods in inverse problems
 Introduction to Bayesian methods in inverse problems Ville Kolehmainen 1 1 Department of Applied Physics, University of Eastern Finland, Kuopio, Finland March 4 2013 Manchester, UK. Contents Introduction
Introduction to Bayesian methods in inverse problems Ville Kolehmainen 1 1 Department of Applied Physics, University of Eastern Finland, Kuopio, Finland March 4 2013 Manchester, UK. Contents Introduction
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Fitting Narrow Emission Lines in X-ray Spectra
 Outline Fitting Narrow Emission Lines in X-ray Spectra Taeyoung Park Department of Statistics, University of Pittsburgh October 11, 2007 Outline of Presentation Outline This talk has three components:
Outline Fitting Narrow Emission Lines in X-ray Spectra Taeyoung Park Department of Statistics, University of Pittsburgh October 11, 2007 Outline of Presentation Outline This talk has three components:
MCMC Sampling for Bayesian Inference using L1-type Priors
 MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
Computer Vision Group Prof. Daniel Cremers. 10a. Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
A BAYESIAN ANALYSIS OF HIERARCHICAL MIXTURES WITH APPLICATION TO CLUSTERING FINGERPRINTS. By Sarat C. Dass and Mingfei Li Michigan State University
 Technical Report RM669, Department of Statistics & Probability, Michigan State University A BAYESIAN ANALYSIS OF HIERARCHICAL MIXTURES WITH APPLICATION TO CLUSTERING FINGERPRINTS By Sarat C. Dass and Mingfei
Technical Report RM669, Department of Statistics & Probability, Michigan State University A BAYESIAN ANALYSIS OF HIERARCHICAL MIXTURES WITH APPLICATION TO CLUSTERING FINGERPRINTS By Sarat C. Dass and Mingfei
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
Bayesian Inference for Clustered Extremes
 Newcastle University, Newcastle-upon-Tyne, U.K. lee.fawcett@ncl.ac.uk 20th TIES Conference: Bologna, Italy, July 2009 Structure of this talk 1. Motivation and background 2. Review of existing methods Limitations/difficulties
Newcastle University, Newcastle-upon-Tyne, U.K. lee.fawcett@ncl.ac.uk 20th TIES Conference: Bologna, Italy, July 2009 Structure of this talk 1. Motivation and background 2. Review of existing methods Limitations/difficulties
Learning the hyper-parameters. Luca Martino
 Learning the hyper-parameters Luca Martino 2017 2017 1 / 28 Parameters and hyper-parameters 1. All the described methods depend on some choice of hyper-parameters... 2. For instance, do you recall λ (bandwidth
Learning the hyper-parameters Luca Martino 2017 2017 1 / 28 Parameters and hyper-parameters 1. All the described methods depend on some choice of hyper-parameters... 2. For instance, do you recall λ (bandwidth
The Minimum Message Length Principle for Inductive Inference
 The Principle for Inductive Inference Centre for Molecular, Environmental, Genetic & Analytic (MEGA) Epidemiology School of Population Health University of Melbourne University of Helsinki, August 25,
The Principle for Inductive Inference Centre for Molecular, Environmental, Genetic & Analytic (MEGA) Epidemiology School of Population Health University of Melbourne University of Helsinki, August 25,
Bayesian Inference of Multiple Gaussian Graphical Models
 Bayesian Inference of Multiple Gaussian Graphical Models Christine Peterson,, Francesco Stingo, and Marina Vannucci February 18, 2014 Abstract In this paper, we propose a Bayesian approach to inference
Bayesian Inference of Multiple Gaussian Graphical Models Christine Peterson,, Francesco Stingo, and Marina Vannucci February 18, 2014 Abstract In this paper, we propose a Bayesian approach to inference
Bayesian inference J. Daunizeau
 Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
Foundations of Statistical Inference
 Foundations of Statistical Inference Julien Berestycki Department of Statistics University of Oxford MT 2016 Julien Berestycki (University of Oxford) SB2a MT 2016 1 / 32 Lecture 14 : Variational Bayes
Foundations of Statistical Inference Julien Berestycki Department of Statistics University of Oxford MT 2016 Julien Berestycki (University of Oxford) SB2a MT 2016 1 / 32 Lecture 14 : Variational Bayes
Fingerprint Individuality
 Fingerprint Individuality On the Individuality of Fingerprints, Sharat Pankanti, Anil Jain and Salil Prabhakar, IEEE Transactions on PAMI, 2002 US DOJ, Office of the Inspector General, A Review of the
Fingerprint Individuality On the Individuality of Fingerprints, Sharat Pankanti, Anil Jain and Salil Prabhakar, IEEE Transactions on PAMI, 2002 US DOJ, Office of the Inspector General, A Review of the
STAT 425: Introduction to Bayesian Analysis
 STAT 425: Introduction to Bayesian Analysis Marina Vannucci Rice University, USA Fall 2017 Marina Vannucci (Rice University, USA) Bayesian Analysis (Part 1) Fall 2017 1 / 10 Lecture 7: Prior Types Subjective
STAT 425: Introduction to Bayesian Analysis Marina Vannucci Rice University, USA Fall 2017 Marina Vannucci (Rice University, USA) Bayesian Analysis (Part 1) Fall 2017 1 / 10 Lecture 7: Prior Types Subjective
Stat 516, Homework 1
 Stat 516, Homework 1 Due date: October 7 1. Consider an urn with n distinct balls numbered 1,..., n. We sample balls from the urn with replacement. Let N be the number of draws until we encounter a ball
Stat 516, Homework 1 Due date: October 7 1. Consider an urn with n distinct balls numbered 1,..., n. We sample balls from the urn with replacement. Let N be the number of draws until we encounter a ball
Introduction to Markov Chain Monte Carlo & Gibbs Sampling
 Introduction to Markov Chain Monte Carlo & Gibbs Sampling Prof. Nicholas Zabaras Sibley School of Mechanical and Aerospace Engineering 101 Frank H. T. Rhodes Hall Ithaca, NY 14853-3801 Email: zabaras@cornell.edu
Introduction to Markov Chain Monte Carlo & Gibbs Sampling Prof. Nicholas Zabaras Sibley School of Mechanical and Aerospace Engineering 101 Frank H. T. Rhodes Hall Ithaca, NY 14853-3801 Email: zabaras@cornell.edu
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Announcement. HW4 has been assigned. Finger Print Recognition using Minutiae. Biometrics CSE 190 Lecture 16. CSE190, Winter CSE190, Winter 2011
 Announcement HW4 has been assigned Finger Print Recognition using Minutiae Biometrics CSE 190 Lecture 16 1 Fingerprints Biological Principles of Fingerprints Individual epidermal ridges and valleys have
Announcement HW4 has been assigned Finger Print Recognition using Minutiae Biometrics CSE 190 Lecture 16 1 Fingerprints Biological Principles of Fingerprints Individual epidermal ridges and valleys have
Riemann Manifold Methods in Bayesian Statistics
 Ricardo Ehlers ehlers@icmc.usp.br Applied Maths and Stats University of São Paulo, Brazil Working Group in Statistical Learning University College Dublin September 2015 Bayesian inference is based on Bayes
Ricardo Ehlers ehlers@icmc.usp.br Applied Maths and Stats University of São Paulo, Brazil Working Group in Statistical Learning University College Dublin September 2015 Bayesian inference is based on Bayes
Hastings-within-Gibbs Algorithm: Introduction and Application on Hierarchical Model
 UNIVERSITY OF TEXAS AT SAN ANTONIO Hastings-within-Gibbs Algorithm: Introduction and Application on Hierarchical Model Liang Jing April 2010 1 1 ABSTRACT In this paper, common MCMC algorithms are introduced
UNIVERSITY OF TEXAS AT SAN ANTONIO Hastings-within-Gibbs Algorithm: Introduction and Application on Hierarchical Model Liang Jing April 2010 1 1 ABSTRACT In this paper, common MCMC algorithms are introduced
Bayesian inference for multivariate skew-normal and skew-t distributions
 Bayesian inference for multivariate skew-normal and skew-t distributions Brunero Liseo Sapienza Università di Roma Banff, May 2013 Outline Joint research with Antonio Parisi (Roma Tor Vergata) 1. Inferential
Bayesian inference for multivariate skew-normal and skew-t distributions Brunero Liseo Sapienza Università di Roma Banff, May 2013 Outline Joint research with Antonio Parisi (Roma Tor Vergata) 1. Inferential
Default Priors and Effcient Posterior Computation in Bayesian
 Default Priors and Effcient Posterior Computation in Bayesian Factor Analysis January 16, 2010 Presented by Eric Wang, Duke University Background and Motivation A Brief Review of Parameter Expansion Literature
Default Priors and Effcient Posterior Computation in Bayesian Factor Analysis January 16, 2010 Presented by Eric Wang, Duke University Background and Motivation A Brief Review of Parameter Expansion Literature
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
7. Estimation and hypothesis testing. Objective. Recommended reading
 7. Estimation and hypothesis testing Objective In this chapter, we show how the election of estimators can be represented as a decision problem. Secondly, we consider the problem of hypothesis testing
7. Estimation and hypothesis testing Objective In this chapter, we show how the election of estimators can be represented as a decision problem. Secondly, we consider the problem of hypothesis testing
Bayesian time series classification
 Bayesian time series classification Peter Sykacek Department of Engineering Science University of Oxford Oxford, OX 3PJ, UK psyk@robots.ox.ac.uk Stephen Roberts Department of Engineering Science University
Bayesian time series classification Peter Sykacek Department of Engineering Science University of Oxford Oxford, OX 3PJ, UK psyk@robots.ox.ac.uk Stephen Roberts Department of Engineering Science University
Bayesian Classification and Regression Trees
 Bayesian Classification and Regression Trees James Cussens York Centre for Complex Systems Analysis & Dept of Computer Science University of York, UK 1 Outline Problems for Lessons from Bayesian phylogeny
Bayesian Classification and Regression Trees James Cussens York Centre for Complex Systems Analysis & Dept of Computer Science University of York, UK 1 Outline Problems for Lessons from Bayesian phylogeny
Bayesian spatial hierarchical modeling for temperature extremes
 Bayesian spatial hierarchical modeling for temperature extremes Indriati Bisono Dr. Andrew Robinson Dr. Aloke Phatak Mathematics and Statistics Department The University of Melbourne Maths, Informatics
Bayesian spatial hierarchical modeling for temperature extremes Indriati Bisono Dr. Andrew Robinson Dr. Aloke Phatak Mathematics and Statistics Department The University of Melbourne Maths, Informatics
Monte Carlo integration
 Monte Carlo integration Eample of a Monte Carlo sampler in D: imagine a circle radius L/ within a square of LL. If points are randoml generated over the square, what s the probabilit to hit within circle?
Monte Carlo integration Eample of a Monte Carlo sampler in D: imagine a circle radius L/ within a square of LL. If points are randoml generated over the square, what s the probabilit to hit within circle?
Ages of stellar populations from color-magnitude diagrams. Paul Baines. September 30, 2008
 Ages of stellar populations from color-magnitude diagrams Paul Baines Department of Statistics Harvard University September 30, 2008 Context & Example Welcome! Today we will look at using hierarchical
Ages of stellar populations from color-magnitude diagrams Paul Baines Department of Statistics Harvard University September 30, 2008 Context & Example Welcome! Today we will look at using hierarchical
Markov Chain Monte Carlo, Numerical Integration
 Markov Chain Monte Carlo, Numerical Integration (See Statistics) Trevor Gallen Fall 2015 1 / 1 Agenda Numerical Integration: MCMC methods Estimating Markov Chains Estimating latent variables 2 / 1 Numerical
Markov Chain Monte Carlo, Numerical Integration (See Statistics) Trevor Gallen Fall 2015 1 / 1 Agenda Numerical Integration: MCMC methods Estimating Markov Chains Estimating latent variables 2 / 1 Numerical
Dynamic models. Dependent data The AR(p) model The MA(q) model Hidden Markov models. 6 Dynamic models
 model The MA(q) model Hidden Markov models. 6 Dynamic models") 6 Dependent data The AR(p) model The MA(q) model Hidden Markov models Dependent data Dependent data Huge portion of real-life data involving dependent datapoints Example (Capture-recapture) capture histories
6 Dependent data The AR(p) model The MA(q) model Hidden Markov models Dependent data Dependent data Huge portion of real-life data involving dependent datapoints Example (Capture-recapture) capture histories
Bayesian Inference for Discretely Sampled Diffusion Processes: A New MCMC Based Approach to Inference
 Bayesian Inference for Discretely Sampled Diffusion Processes: A New MCMC Based Approach to Inference Osnat Stramer 1 and Matthew Bognar 1 Department of Statistics and Actuarial Science, University of
Bayesian Inference for Discretely Sampled Diffusion Processes: A New MCMC Based Approach to Inference Osnat Stramer 1 and Matthew Bognar 1 Department of Statistics and Actuarial Science, University of
A = {(x, u) : 0 u f(x)},
 : 0 u f(x)},") Draw x uniformly from the region {x : f(x) u }. Markov Chain Monte Carlo Lecture 5 Slice sampler: Suppose that one is interested in sampling from a density f(x), x X. Recall that sampling x f(x) is equivalent
Draw x uniformly from the region {x : f(x) u }. Markov Chain Monte Carlo Lecture 5 Slice sampler: Suppose that one is interested in sampling from a density f(x), x X. Recall that sampling x f(x) is equivalent
Bayesian non-parametric model to longitudinally predict churn
 Bayesian non-parametric model to longitudinally predict churn Bruno Scarpa Università di Padova Conference of European Statistics Stakeholders Methodologists, Producers and Users of European Statistics
Bayesian non-parametric model to longitudinally predict churn Bruno Scarpa Università di Padova Conference of European Statistics Stakeholders Methodologists, Producers and Users of European Statistics
Probabilistic Time Series Classification
 Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Basic math for biology
 Basic math for biology Lei Li Florida State University, Feb 6, 2002 The EM algorithm: setup Parametric models: {P θ }. Data: full data (Y, X); partial data Y. Missing data: X. Likelihood and maximum likelihood
Basic math for biology Lei Li Florida State University, Feb 6, 2002 The EM algorithm: setup Parametric models: {P θ }. Data: full data (Y, X); partial data Y. Missing data: X. Likelihood and maximum likelihood
Supplement to A Hierarchical Approach for Fitting Curves to Response Time Measurements
 Supplement to A Hierarchical Approach for Fitting Curves to Response Time Measurements Jeffrey N. Rouder Francis Tuerlinckx Paul L. Speckman Jun Lu & Pablo Gomez May 4 008 1 The Weibull regression model
Supplement to A Hierarchical Approach for Fitting Curves to Response Time Measurements Jeffrey N. Rouder Francis Tuerlinckx Paul L. Speckman Jun Lu & Pablo Gomez May 4 008 1 The Weibull regression model
MCMC for non-linear state space models using ensembles of latent sequences
 MCMC for non-linear state space models using ensembles of latent sequences Alexander Y. Shestopaloff Department of Statistical Sciences University of Toronto alexander@utstat.utoronto.ca Radford M. Neal
MCMC for non-linear state space models using ensembles of latent sequences Alexander Y. Shestopaloff Department of Statistical Sciences University of Toronto alexander@utstat.utoronto.ca Radford M. Neal
Pseudo-marginal MCMC methods for inference in latent variable models
 Pseudo-marginal MCMC methods for inference in latent variable models Arnaud Doucet Department of Statistics, Oxford University Joint work with George Deligiannidis (Oxford) & Mike Pitt (Kings) MCQMC, 19/08/2016
Pseudo-marginal MCMC methods for inference in latent variable models Arnaud Doucet Department of Statistics, Oxford University Joint work with George Deligiannidis (Oxford) & Mike Pitt (Kings) MCQMC, 19/08/2016
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Hierarchical Modeling for Univariate Spatial Data
 Hierarchical Modeling for Univariate Spatial Data Geography 890, Hierarchical Bayesian Models for Environmental Spatial Data Analysis February 15, 2011 1 Spatial Domain 2 Geography 890 Spatial Domain This
Hierarchical Modeling for Univariate Spatial Data Geography 890, Hierarchical Bayesian Models for Environmental Spatial Data Analysis February 15, 2011 1 Spatial Domain 2 Geography 890 Spatial Domain This
Contents. Part I: Fundamentals of Bayesian Inference 1
 Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
Parameter Estimation. William H. Jefferys University of Texas at Austin Parameter Estimation 7/26/05 1
 Parameter Estimation William H. Jefferys University of Texas at Austin bill@bayesrules.net Parameter Estimation 7/26/05 1 Elements of Inference Inference problems contain two indispensable elements: Data
Parameter Estimation William H. Jefferys University of Texas at Austin bill@bayesrules.net Parameter Estimation 7/26/05 1 Elements of Inference Inference problems contain two indispensable elements: Data
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Stat 451 Lecture Notes Markov Chain Monte Carlo. Ryan Martin UIC
 Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Web Appendix for Hierarchical Adaptive Regression Kernels for Regression with Functional Predictors by D. B. Woodard, C. Crainiceanu, and D.
 Web Appendix for Hierarchical Adaptive Regression Kernels for Regression with Functional Predictors by D. B. Woodard, C. Crainiceanu, and D. Ruppert A. EMPIRICAL ESTIMATE OF THE KERNEL MIXTURE Here we
Web Appendix for Hierarchical Adaptive Regression Kernels for Regression with Functional Predictors by D. B. Woodard, C. Crainiceanu, and D. Ruppert A. EMPIRICAL ESTIMATE OF THE KERNEL MIXTURE Here we
Hierarchical Nearest-Neighbor Gaussian Process Models for Large Geo-statistical Datasets
 Hierarchical Nearest-Neighbor Gaussian Process Models for Large Geo-statistical Datasets Abhirup Datta 1 Sudipto Banerjee 1 Andrew O. Finley 2 Alan E. Gelfand 3 1 University of Minnesota, Minneapolis,
Hierarchical Nearest-Neighbor Gaussian Process Models for Large Geo-statistical Datasets Abhirup Datta 1 Sudipto Banerjee 1 Andrew O. Finley 2 Alan E. Gelfand 3 1 University of Minnesota, Minneapolis,
PSEUDO-MARGINAL METROPOLIS-HASTINGS APPROACH AND ITS APPLICATION TO BAYESIAN COPULA MODEL
 PSEUDO-MARGINAL METROPOLIS-HASTINGS APPROACH AND ITS APPLICATION TO BAYESIAN COPULA MODEL Xuebin Zheng Supervisor: Associate Professor Josef Dick Co-Supervisor: Dr. David Gunawan School of Mathematics
PSEUDO-MARGINAL METROPOLIS-HASTINGS APPROACH AND ITS APPLICATION TO BAYESIAN COPULA MODEL Xuebin Zheng Supervisor: Associate Professor Josef Dick Co-Supervisor: Dr. David Gunawan School of Mathematics
MCMC for big data. Geir Storvik. BigInsight lunch - May Geir Storvik MCMC for big data BigInsight lunch - May / 17
 MCMC for big data Geir Storvik BigInsight lunch - May 2 2018 Geir Storvik MCMC for big data BigInsight lunch - May 2 2018 1 / 17 Outline Why ordinary MCMC is not scalable Different approaches for making
MCMC for big data Geir Storvik BigInsight lunch - May 2 2018 Geir Storvik MCMC for big data BigInsight lunch - May 2 2018 1 / 17 Outline Why ordinary MCMC is not scalable Different approaches for making
Chapter 6 Fingerprints By the end of this chapter you will be able to:
 Chapter 6 Fingerprints By the end of this chapter you will be able to: discuss the history of fingerprinting describe the characteristics of fingerprints and fingerprinting minutiae explain when and how
Chapter 6 Fingerprints By the end of this chapter you will be able to: discuss the history of fingerprinting describe the characteristics of fingerprints and fingerprinting minutiae explain when and how
A Bayesian perspective on GMM and IV
 A Bayesian perspective on GMM and IV Christopher A. Sims Princeton University sims@princeton.edu November 26, 2013 What is a Bayesian perspective? A Bayesian perspective on scientific reporting views all
A Bayesian perspective on GMM and IV Christopher A. Sims Princeton University sims@princeton.edu November 26, 2013 What is a Bayesian perspective? A Bayesian perspective on scientific reporting views all
Making rating curves - the Bayesian approach
 Making rating curves - the Bayesian approach Rating curves what is wanted? A best estimate of the relationship between stage and discharge at a given place in a river. The relationship should be on the
Making rating curves - the Bayesian approach Rating curves what is wanted? A best estimate of the relationship between stage and discharge at a given place in a river. The relationship should be on the
Sub-kilometer-scale space-time stochastic rainfall simulation
 Picture: Huw Alexander Ogilvie Sub-kilometer-scale space-time stochastic rainfall simulation Lionel Benoit (University of Lausanne) Gregoire Mariethoz (University of Lausanne) Denis Allard (INRA Avignon)
Picture: Huw Alexander Ogilvie Sub-kilometer-scale space-time stochastic rainfall simulation Lionel Benoit (University of Lausanne) Gregoire Mariethoz (University of Lausanne) Denis Allard (INRA Avignon)
Statistical Methods in Particle Physics Lecture 1: Bayesian methods
 Statistical Methods in Particle Physics Lecture 1: Bayesian methods SUSSP65 St Andrews 16 29 August 2009 Glen Cowan Physics Department Royal Holloway, University of London g.cowan@rhul.ac.uk www.pp.rhul.ac.uk/~cowan
Statistical Methods in Particle Physics Lecture 1: Bayesian methods SUSSP65 St Andrews 16 29 August 2009 Glen Cowan Physics Department Royal Holloway, University of London g.cowan@rhul.ac.uk www.pp.rhul.ac.uk/~cowan
Bayesian learning of sparse factor loadings
 Magnus Rattray School of Computer Science, University of Manchester Bayesian Research Kitchen, Ambleside, September 6th 2008 Talk Outline Brief overview of popular sparsity priors Example application:
Magnus Rattray School of Computer Science, University of Manchester Bayesian Research Kitchen, Ambleside, September 6th 2008 Talk Outline Brief overview of popular sparsity priors Example application:
Calibration of Stochastic Volatility Models using Particle Markov Chain Monte Carlo Methods
 Calibration of Stochastic Volatility Models using Particle Markov Chain Monte Carlo Methods Jonas Hallgren 1 1 Department of Mathematics KTH Royal Institute of Technology Stockholm, Sweden BFS 2012 June
Calibration of Stochastic Volatility Models using Particle Markov Chain Monte Carlo Methods Jonas Hallgren 1 1 Department of Mathematics KTH Royal Institute of Technology Stockholm, Sweden BFS 2012 June
Generative Models and Stochastic Algorithms for Population Average Estimation and Image Analysis
 Generative Models and Stochastic Algorithms for Population Average Estimation and Image Analysis Stéphanie Allassonnière CIS, JHU July, 15th 28 Context : Computational Anatomy Context and motivations :
Generative Models and Stochastic Algorithms for Population Average Estimation and Image Analysis Stéphanie Allassonnière CIS, JHU July, 15th 28 Context : Computational Anatomy Context and motivations :
The Jackknife-Like Method for Assessing Uncertainty of Point Estimates for Bayesian Estimation in a Finite Gaussian Mixture Model
 Thai Journal of Mathematics : 45 58 Special Issue: Annual Meeting in Mathematics 207 http://thaijmath.in.cmu.ac.th ISSN 686-0209 The Jackknife-Like Method for Assessing Uncertainty of Point Estimates for
Thai Journal of Mathematics : 45 58 Special Issue: Annual Meeting in Mathematics 207 http://thaijmath.in.cmu.ac.th ISSN 686-0209 The Jackknife-Like Method for Assessing Uncertainty of Point Estimates for
Overall Objective Priors
 Overall Objective Priors Jim Berger, Jose Bernardo and Dongchu Sun Duke University, University of Valencia and University of Missouri Recent advances in statistical inference: theory and case studies University
Overall Objective Priors Jim Berger, Jose Bernardo and Dongchu Sun Duke University, University of Valencia and University of Missouri Recent advances in statistical inference: theory and case studies University
ComputationalToolsforComparing AsymmetricGARCHModelsviaBayes Factors. RicardoS.Ehlers
 ComputationalToolsforComparing AsymmetricGARCHModelsviaBayes Factors RicardoS.Ehlers Laboratório de Estatística e Geoinformação- UFPR http://leg.ufpr.br/ ehlers ehlers@leg.ufpr.br II Workshop on Statistical
ComputationalToolsforComparing AsymmetricGARCHModelsviaBayes Factors RicardoS.Ehlers Laboratório de Estatística e Geoinformação- UFPR http://leg.ufpr.br/ ehlers ehlers@leg.ufpr.br II Workshop on Statistical
Empirical Bayes Unfolding of Elementary Particle Spectra at the Large Hadron Collider
 Empirical Bayes Unfolding of Elementary Particle Spectra at the Large Hadron Collider Mikael Kuusela Institute of Mathematics, EPFL Statistics Seminar, University of Bristol June 13, 2014 Joint work with
Empirical Bayes Unfolding of Elementary Particle Spectra at the Large Hadron Collider Mikael Kuusela Institute of Mathematics, EPFL Statistics Seminar, University of Bristol June 13, 2014 Joint work with
Principles of Bayesian Inference
 Principles of Bayesian Inference Sudipto Banerjee University of Minnesota July 20th, 2008 1 Bayesian Principles Classical statistics: model parameters are fixed and unknown. A Bayesian thinks of parameters
Principles of Bayesian Inference Sudipto Banerjee University of Minnesota July 20th, 2008 1 Bayesian Principles Classical statistics: model parameters are fixed and unknown. A Bayesian thinks of parameters
!) + log(t) # n i. The last two terms on the right hand side (RHS) are clearly independent of θ and can be
 + log(t) # n i. The last two terms on the right hand side (RHS) are clearly independent of θ and can be") Supplementary Materials General case: computing log likelihood We first describe the general case of computing the log likelihood of a sensory parameter θ that is encoded by the activity of neurons. Each
Supplementary Materials General case: computing log likelihood We first describe the general case of computing the log likelihood of a sensory parameter θ that is encoded by the activity of neurons. Each
Mixture models. Mixture models MCMC approaches Label switching MCMC for variable dimension models. 5 Mixture models
 5 MCMC approaches Label switching MCMC for variable dimension models 291/459 Missing variable models Complexity of a model may originate from the fact that some piece of information is missing Example
5 MCMC approaches Label switching MCMC for variable dimension models 291/459 Missing variable models Complexity of a model may originate from the fact that some piece of information is missing Example
SAMPLING ALGORITHMS. In general. Inference in Bayesian models
 SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
Brief introduction to Markov Chain Monte Carlo
 Brief introduction to Department of Probability and Mathematical Statistics seminar Stochastic modeling in economics and finance November 7, 2011 Brief introduction to Content 1 and motivation Classical
Brief introduction to Department of Probability and Mathematical Statistics seminar Stochastic modeling in economics and finance November 7, 2011 Brief introduction to Content 1 and motivation Classical
A short introduction to INLA and R-INLA
 A short introduction to INLA and R-INLA Integrated Nested Laplace Approximation Thomas Opitz, BioSP, INRA Avignon Workshop: Theory and practice of INLA and SPDE November 7, 2018 2/21 Plan for this talk
A short introduction to INLA and R-INLA Integrated Nested Laplace Approximation Thomas Opitz, BioSP, INRA Avignon Workshop: Theory and practice of INLA and SPDE November 7, 2018 2/21 Plan for this talk
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
On Markov chain Monte Carlo methods for tall data
 On Markov chain Monte Carlo methods for tall data Remi Bardenet, Arnaud Doucet, Chris Holmes Paper review by: David Carlson October 29, 2016 Introduction Many data sets in machine learning and computational
On Markov chain Monte Carlo methods for tall data Remi Bardenet, Arnaud Doucet, Chris Holmes Paper review by: David Carlson October 29, 2016 Introduction Many data sets in machine learning and computational
Statistics & Data Sciences: First Year Prelim Exam May 2018
 Statistics & Data Sciences: First Year Prelim Exam May 2018 Instructions: 1. Do not turn this page until instructed to do so. 2. Start each new question on a new sheet of paper. 3. This is a closed book
Statistics & Data Sciences: First Year Prelim Exam May 2018 Instructions: 1. Do not turn this page until instructed to do so. 2. Start each new question on a new sheet of paper. 3. This is a closed book
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Bayesian Nonparametric Regression for Diabetes Deaths
 Bayesian Nonparametric Regression for Diabetes Deaths Brian M. Hartman PhD Student, 2010 Texas A&M University College Station, TX, USA David B. Dahl Assistant Professor Texas A&M University College Station,
Bayesian Nonparametric Regression for Diabetes Deaths Brian M. Hartman PhD Student, 2010 Texas A&M University College Station, TX, USA David B. Dahl Assistant Professor Texas A&M University College Station,
Hmms with variable dimension structures and extensions
 Hmm days/enst/january 21, 2002 1 Hmms with variable dimension structures and extensions Christian P. Robert Université Paris Dauphine www.ceremade.dauphine.fr/ xian Hmm days/enst/january 21, 2002 2 1 Estimating
Hmm days/enst/january 21, 2002 1 Hmms with variable dimension structures and extensions Christian P. Robert Université Paris Dauphine www.ceremade.dauphine.fr/ xian Hmm days/enst/january 21, 2002 2 1 Estimating
The Bayesian Choice. Christian P. Robert. From Decision-Theoretic Foundations to Computational Implementation. Second Edition.
 Christian P. Robert The Bayesian Choice From Decision-Theoretic Foundations to Computational Implementation Second Edition With 23 Illustrations ^Springer" Contents Preface to the Second Edition Preface
Christian P. Robert The Bayesian Choice From Decision-Theoretic Foundations to Computational Implementation Second Edition With 23 Illustrations ^Springer" Contents Preface to the Second Edition Preface
Bayesian Methods and Uncertainty Quantification for Nonlinear Inverse Problems
 Bayesian Methods and Uncertainty Quantification for Nonlinear Inverse Problems John Bardsley, University of Montana Collaborators: H. Haario, J. Kaipio, M. Laine, Y. Marzouk, A. Seppänen, A. Solonen, Z.
Bayesian Methods and Uncertainty Quantification for Nonlinear Inverse Problems John Bardsley, University of Montana Collaborators: H. Haario, J. Kaipio, M. Laine, Y. Marzouk, A. Seppänen, A. Solonen, Z.
Sequential Monte Carlo Methods
 University of Pennsylvania Bradley Visitor Lectures October 23, 2017 Introduction Unfortunately, standard MCMC can be inaccurate, especially in medium and large-scale DSGE models: disentangling importance
University of Pennsylvania Bradley Visitor Lectures October 23, 2017 Introduction Unfortunately, standard MCMC can be inaccurate, especially in medium and large-scale DSGE models: disentangling importance