Bayesian Methods for Machine Learning
|
|
|
- Collin O’Neal’
- 5 years ago
- Views:
Transcription
1 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial ( Zoubin Ghahramni ( Taha Bahadori (
2 Frequentist vs Bayesian Frequentist Data are a repeatable random sample (there is a frequency) Underlying parameters remain constant during repeatable process Parameters are fixed Prediction via the estimated parameter value Bayesian Data are observed from the realized sample Parameters are unknown and described probabilistically (random variables) Data are fixed Prediction is expectation over unknown parameters

3 The War in Comics
4 Classic Example: Binomial Experiment Given a sequence of coin tosses x1, x2,, xm, we want to estimate the (unknown) probability of heads P (H) = The instances are independent and identically distributed samples Note that x can take on many possible values potentially if we decide to use a multinomial distribution instead
5 Likelihood Function How good is a particular parameter? Ans: Depends on how likely it is to generate the data L( ; D) =P (D ) = Y m P (x m ) Example: Likelihood for the sequence H, T, T, H, H L(θ :D) L( ; D) = (1 )(1 ) = 3 (1 ) θ
6 Maximum Likelihood Estimate (MLE) Choose parameters that maximize the likelihood function Commonly used estimator in statistics Intuitively appealing In the binomial experiment, MLE for probability of heads ˆ = N H N H + N T Optimization problem approach
7 Is MLE the only option? Suppose that after 10 observations, MLE estimates the probability of a heads is 0.7, would you bet on heads for the next toss? How certain are you that the true parameter value is 0.7? Were there enough samples for you to be certain?
8 Bayesian Approach Formulate knowledge about situation probabilistically Define a model that expresses qualitative aspects of our knowledge (e.g., forms of distributions, independence assumptions) Specify a prior probability distribution for unknown parameters in the model that expresses our beliefs about which values are more or less likely Compute the posterior probability distribution for the parameters, given observed data Posterior distribution can be used for: Reaching conclusions while accounting for uncertainty Make predictions by averaging over posterior distribution
9 Posterior Distribution Posterior distribution for model parameters given the observed data combines the prior distribution with the likelihood function using Bayes' rule P ( D) = P ( )P (D ) P (D) Denominator is just a normalizing constant so you can write it proportionally as Posterior / Prior Likelihood Predictions can be made by integrating with respect to posterior P (new data D) = Z P (new data )P ( D)
10 Revisiting Binomial Experiment Prior distribution: uniform for in [0, 1] Posterior distribution: P ( x 1,x 2,,x M ) / P (x 1,x 2,,x M ) 1 Example: 5 coin tosses with 4 heads, 1 tail MLE estimate: P ( ) = 4 5 =0.8,P(x M+1 = H D) =0.8 Bayesian prediction: P (x M+1 = H D) = Z P( D)d =
11 Bayesian Inference and MLE MLE and Bayesian prediction differ However IF prior is well-behaved (i.e., does not assign 0 density to any feasible parameter value) THEN both MLE and Bayesian prediction converge to the same value as the number of training data increases
12 Features of the Bayesian Approach Probability is used to describe physical randomness and uncertainty regarding the true values of the parameters Prior and posterior probabilities represent degrees of belief, before and after seeing the data Model and prior are chosen based on the knowledge of the problem and not, in theory, by the amount of data collected or the question we are interested in answering
13 Priors Objective priors: noninformative priors that attempt to capture ignorance and have good frequentist properties Subjective priors: priors should capture our beliefs as well as possible. They are subjective but not arbitrary. Hierarchical priors: multiple levels of priors Empirical priors: learn some of the parameters of the prior from the data ( Empirical Bayes ) Robust, able to overcome limitations of mis-specification of prior Double counting of evidence / overfitting
14 Conjugate Prior If the posterior distribution are in the same family as prior probability distribution, the prior and posterior are called conjugate distributions All members of the exponential family of distributions have conjugate priors Likelihood Bernoulli Conjugate prior distribution Beta Prior hyperparameter, s Posterior hyperparameters + X x i, + n X xi Multinomial Dirichlet + X x i Poisson Gamma, + X x i, + n
15 Linear Regression (Classic Approach) y = w > x +, N(0, 2 ) P (y i w, x i, 2 )=N(w > x i, 2 ) P (y w, X, 2 )= Y i P (y i w, x i, 2 ) maximize log likelihood max ln(p (y w, x, 2 ) = max X i ln(n(y i w, x i, 2 )) 1 w MLE = argmin w 2 w =(X > X) 1 X > y X (y i x > i w) 2 i
16 Bayesian Linear Regression Prior is placed on either the weight, w, or the variance, sigma Conjugate prior for w is normal distribution P (w) N(µ 0,S 0 ) P (w y) N(µ, S) S 1 = S X> X µ = S(S 1 0 µ X> y) mean is weighted average of OLS estimate and prior mean, where weights reflect relative strengths of prior and data information
17 Computing the Posterior Distribution Analytical integration: works when conjugate prior distributions can be used, which combine nicely with the likelihood usually not the case Gaussian approximation: works well when there is sufficient data compared to model complexity posterior distribution is close to Gaussian (Central Limit Theorem) and can be handled by finding its mode Markov Chain Monte Carlo: simulate a Markov chain that eventually converges to the posterior distribution currently the dominant approach Variational approximation: cleverer way to approximate the posterior and maybe faster than MCMC but not as general and exact
18 Approximate Bayesian Inference Stochastic approximate inference (MCMC) Design an algorithm that draws sample from distribution Structural approximate inference (variational Bayes) Use an analytical proxy that is similar to original distribution Inspect sample statistics (Pros) Asymptotically exact (Cons) Computationally expensive (Cons) Tricky Engineering concerns Inspect distribution statistics of proxy (Pros) Often insightful & fast (Cons) Often hard work to derive (Cons) Requires validation via sampling
19 Marko Chain Monte Carlo (MCMC)
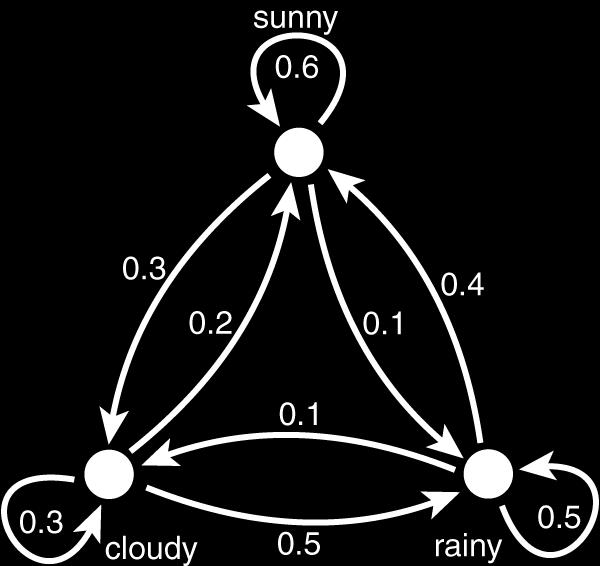
20 A Simple Markov Chain
21 Markov Chains Review A random process has Markov property if and only if: p(x t x t 1,X t 2,,X 1 )=p(x t x t 1 ) Finite-state Discrete Time Markov Chains can be completely specified by the transition matrix P P =[p ij ]; p ij = P [X t = j X t 1 = i] Stationarity: As t approaches infinity, the Markov chain converges in distribution to its stationary distribution (independent of starting position)
22 Markov Chains Review (2) Irreducible: any set of states can be reached from any other state in a finite number of moves Assuming a stationary distribution exists, it is unique if the chain is irreducible Aperiodicity: greatest common divisor of return times to any particular state i is 1 Ergodicity: if the Marko chain has station distribution, is aperiodic and irreducible then: E [h(x)] = 1 N X h(x (t) ) as N!1
23 MCMC Algorithms Posterior distribution is too complex to sample from directly, simulate a Markov chain that converge (asymptotically) to the posterior distribution Generating samples while exploring the state space using a Markov chain mechanism Constructed so the chain spends more time in the important regions Irreducible and aperiodic Markov chains with target distribution as the stationary distribution Can be very slow in some circumstances but is often the only viable approach to Bayesian inference using complex models
24 The Monte Carlo Principle General Problem: E [h(x)] = Z h(x) (x)dx Instead, draw samples from the target density to estimate the function X (1),X (2),,X (N) (x) E [h(x)] 1 X h(x (t) ) N
25 Metropolis-Hastings Algorithm Most popular MCMC (Metropolis, 1953; Hastings 1970) Main Idea: Create a Markov chain whose transition matrix does not depend on the normalization term Make sure the chain has a stationary distribution and is equal to the target distribution After sufficient number of iterations, the chain converges to the stationary distribution
26 Metropolis-Hasting Algorithm At each iteration t Step 1: Sample a candidate point from proposal distribution y q(y x (t) ) candidate point proposal distribution Step 2: Accept the next point with probability (x (t) p(y)q(x (t) y),y)=min 1, p(x (t) )q(y x (t) )

27 Illustration of Metropolis-Hasting Algorithm
28 Variations of Proposal Distribution Random-walk is when proposal is dependent on previous state y q(y x (t) ) Symmetric proposal originally proposed by Metropolis (e.g., Gaussian distribution) q(x y) q(y x) Independent sampler uses a proposal independent of x q(y x) q(y)
29 Metropolis-Hastings Notes Normalizing constant of the target distribution is not required Choice of proposal distribution is very important: too narrow > not enough mixing, too wide > high correlations Usually q is chosen so the proposal distribution is easily to sample with Easy to simulate several independent chains in parallel
30 Acceptance Rates Important to monitor the acceptance rate (fraction of candidate draws that are accepted) Too high means the chain is not mixing well and not moving around the parameter space quickly enough Too low means algorithm is too inefficient (too many candidate draws) General rules of thumb: Random walk: Somewhere between 0.25 and 0.50 Independent: Closer to 1 is preferred
31 Gibbs Sampling (Geman & Geman, 1984) Popular in statistics and graphical models Special form of Metropolis-Hastings where we always accept a candidate point and we know the full conditional distributions Easy to understand, easy to implement Open-source, black-box implementations available
32 Gibbs Sampling Sample or update in turn: X (t+1) 1 (x 1 x (t) 2,x(t) 3 X (t+1) 2 (x 2 x (t+1),x (t) 1 3 X (t+1) 3 (x 3 x (t+1) 1,x (t+1),,x(t) k ),,x(t) k ),x (t) 2 4,,x(t) k ) X (t+1) k (x k x (t+1) 1,x (t+1) 2,,x (t+1) k 1 )
33 Illustration of Gibbs Sampler
34 Practicalities: Burn-in Convergence usually occurs regardless of our starting point, so can pick any feasible starting point Chain convergence varies depending on the starting point As a matter of practice, most people throw out a certain number of the first draws, known as the burn-in The remaining draws are closer to the stationary distribution and less dependent on the starting point Plot the time series for each quantity of interest and the autocorrelation functions to see if the chain has converged
35 Practicalities: Number of Chains Suggestion: Experiment with different number of chains Several long runs (Gelman & Rubin, 1992) Gives indication of convergence Sense of statistical security One very long run (Geyer, 1992) Reaches parts other schemes cannot reach
36 Other Flavors of MC Auxiliary Variable Methods for MCMC Hybrid Monte Carlo (HMC) Slice Sampler Reversible jump MCMC Adaptive MCMC Sequential Monte Carlo (SMC) and Particle Filters
37 Variational Approximation

38 Bayesian Inference via Variational Approximation Related to mean field and other approximation methods from physics Idea: Find an approximate density that is maximally similar to the true posterior
39 The Mean-field Form A common way of restricting the class of approximate posterior is to consider those posteriors that factorize into independent partitions q( ) = Y i q i ( i ) Each q i ( i ) is the approximate posterior for the i th subset of parameters This implies a straightforward algorithm for inference by cycling over each set of parameters given current sets of others

40 Example: Variational Inference Figure 10.4 from Bishop PRML
41 Parametric vs. Nonparametric
42 Parametric vs Nonparametric Models Parametric models: finite fixed number of parameters, regardless of the size of the dataset (e.g., mixture of k Gaussians) Non-parametric models: number of parameters are allowed to grow with the data set size, or the predictions depend on the data size Doesn t limit the complexity of our model a priori More flexible and realistic model Better predictive performance
43 Nonparametric Overview Dirichlet Process / Chinese Restaurant Process Often used in clustering context and for latent class models Beta Process / Indian Buffet Process Latent feature models Gaussian Process Regression
44 Example: Number of Clusters?
45 Example: A Frequentist Approach Gaussian mixture model with K mixtures Distribution over the K classes Each cluster has a mean and covariance Use Expectation Maximization (EM) to maximize the likelihood with respect to distribution and cluster points
46 Example: Bayesian Parametric Approach Bayesian Gaussian mixture models with K mixtures Distribution over classes that is drawn from a Dirichlet Each cluster has a mean and covariance that is a Normal-Inverse-Wishart distribution Use sampling or variational inference to learn posterior
47 Example: Bayesian Parametric Approach
48 Example: Nonparametric Bayesian Approach Likelihood term looks identical to the parametric case Prior distribution uses the Dirichlet Process Flexible, non-parametric prior over infinite number of clusters and their parameters Distribution over distributions Use Gibbs sampling to find the right distributions
49 Example: Nonparametric Bayesian Approach
50 Limitations and Criticisms of Bayesian Methods It is hard to come up with a prior (subjective) and the assumptions may be wrong Closed world assumption: need to consider all possible hypotheses for the data before observing the data Computationally demanding (compared to frequentist approach) Use of approximations weakens coherence argument
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Part IV: Monte Carlo and nonparametric Bayes
 Part IV: Monte Carlo and nonparametric Bayes Outline Monte Carlo methods Nonparametric Bayesian models Outline Monte Carlo methods Nonparametric Bayesian models The Monte Carlo principle The expectation
Part IV: Monte Carlo and nonparametric Bayes Outline Monte Carlo methods Nonparametric Bayesian models Outline Monte Carlo methods Nonparametric Bayesian models The Monte Carlo principle The expectation
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Should all Machine Learning be Bayesian? Should all Bayesian models be non-parametric?
 Should all Machine Learning be Bayesian? Should all Bayesian models be non-parametric? Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/
Should all Machine Learning be Bayesian? Should all Bayesian models be non-parametric? Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
16 : Approximate Inference: Markov Chain Monte Carlo
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
27 : Distributed Monte Carlo Markov Chain. 1 Recap of MCMC and Naive Parallel Gibbs Sampling
 10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
Gentle Introduction to Infinite Gaussian Mixture Modeling
 Gentle Introduction to Infinite Gaussian Mixture Modeling with an application in neuroscience By Frank Wood Rasmussen, NIPS 1999 Neuroscience Application: Spike Sorting Important in neuroscience and for
Gentle Introduction to Infinite Gaussian Mixture Modeling with an application in neuroscience By Frank Wood Rasmussen, NIPS 1999 Neuroscience Application: Spike Sorting Important in neuroscience and for
Stat 451 Lecture Notes Markov Chain Monte Carlo. Ryan Martin UIC
 Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Computational statistics
 Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
Outline. Binomial, Multinomial, Normal, Beta, Dirichlet. Posterior mean, MAP, credible interval, posterior distribution
 Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Answers and expectations
 Answers and expectations For a function f(x) and distribution P(x), the expectation of f with respect to P is The expectation is the average of f, when x is drawn from the probability distribution P E
Answers and expectations For a function f(x) and distribution P(x), the expectation of f with respect to P is The expectation is the average of f, when x is drawn from the probability distribution P E
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
17 : Markov Chain Monte Carlo
 10-708: Probabilistic Graphical Models, Spring 2015 17 : Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Heran Lin, Bin Deng, Yun Huang 1 Review of Monte Carlo Methods 1.1 Overview Monte Carlo
10-708: Probabilistic Graphical Models, Spring 2015 17 : Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Heran Lin, Bin Deng, Yun Huang 1 Review of Monte Carlo Methods 1.1 Overview Monte Carlo
Bayesian Inference and MCMC
 Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
Bayesian inference. Fredrik Ronquist and Peter Beerli. October 3, 2007
 Bayesian inference Fredrik Ronquist and Peter Beerli October 3, 2007 1 Introduction The last few decades has seen a growing interest in Bayesian inference, an alternative approach to statistical inference.
Bayesian inference Fredrik Ronquist and Peter Beerli October 3, 2007 1 Introduction The last few decades has seen a growing interest in Bayesian inference, an alternative approach to statistical inference.
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
An overview of Bayesian analysis
 An overview of Bayesian analysis Benjamin Letham Operations Research Center, Massachusetts Institute of Technology, Cambridge, MA bletham@mit.edu May 2012 1 Introduction and Notation This work provides
An overview of Bayesian analysis Benjamin Letham Operations Research Center, Massachusetts Institute of Technology, Cambridge, MA bletham@mit.edu May 2012 1 Introduction and Notation This work provides
A Bayesian Approach to Phylogenetics
 A Bayesian Approach to Phylogenetics Niklas Wahlberg Based largely on slides by Paul Lewis (www.eeb.uconn.edu) An Introduction to Bayesian Phylogenetics Bayesian inference in general Markov chain Monte
A Bayesian Approach to Phylogenetics Niklas Wahlberg Based largely on slides by Paul Lewis (www.eeb.uconn.edu) An Introduction to Bayesian Phylogenetics Bayesian inference in general Markov chain Monte
Probabilistic Graphical Models Lecture 17: Markov chain Monte Carlo
 Probabilistic Graphical Models Lecture 17: Markov chain Monte Carlo Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 18, 2015 1 / 45 Resources and Attribution Image credits,
Probabilistic Graphical Models Lecture 17: Markov chain Monte Carlo Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 18, 2015 1 / 45 Resources and Attribution Image credits,
Markov Chain Monte Carlo methods
 Markov Chain Monte Carlo methods Tomas McKelvey and Lennart Svensson Signal Processing Group Department of Signals and Systems Chalmers University of Technology, Sweden November 26, 2012 Today s learning
Markov Chain Monte Carlo methods Tomas McKelvey and Lennart Svensson Signal Processing Group Department of Signals and Systems Chalmers University of Technology, Sweden November 26, 2012 Today s learning
Monte Carlo Methods. Leon Gu CSD, CMU
 Monte Carlo Methods Leon Gu CSD, CMU Approximate Inference EM: y-observed variables; x-hidden variables; θ-parameters; E-step: q(x) = p(x y, θ t 1 ) M-step: θ t = arg max E q(x) [log p(y, x θ)] θ Monte
Monte Carlo Methods Leon Gu CSD, CMU Approximate Inference EM: y-observed variables; x-hidden variables; θ-parameters; E-step: q(x) = p(x y, θ t 1 ) M-step: θ t = arg max E q(x) [log p(y, x θ)] θ Monte
CSC 2541: Bayesian Methods for Machine Learning
 CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 3 More Markov Chain Monte Carlo Methods The Metropolis algorithm isn t the only way to do MCMC. We ll
CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 3 More Markov Chain Monte Carlo Methods The Metropolis algorithm isn t the only way to do MCMC. We ll
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference
 COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
Tutorial on Probabilistic Programming with PyMC3
 185.A83 Machine Learning for Health Informatics 2017S, VU, 2.0 h, 3.0 ECTS Tutorial 02-04.04.2017 Tutorial on Probabilistic Programming with PyMC3 florian.endel@tuwien.ac.at http://hci-kdd.org/machine-learning-for-health-informatics-course
185.A83 Machine Learning for Health Informatics 2017S, VU, 2.0 h, 3.0 ECTS Tutorial 02-04.04.2017 Tutorial on Probabilistic Programming with PyMC3 florian.endel@tuwien.ac.at http://hci-kdd.org/machine-learning-for-health-informatics-course
Markov Chain Monte Carlo (MCMC)
") Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Contents. Part I: Fundamentals of Bayesian Inference 1
 Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
The Particle Filter. PD Dr. Rudolph Triebel Computer Vision Group. Machine Learning for Computer Vision
 The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
(5) Multi-parameter models - Gibbs sampling. ST440/540: Applied Bayesian Analysis
 Multi-parameter models - Gibbs sampling. ST440/540: Applied Bayesian Analysis") Summarizing a posterior Given the data and prior the posterior is determined Summarizing the posterior gives parameter estimates, intervals, and hypothesis tests Most of these computations are integrals
Summarizing a posterior Given the data and prior the posterior is determined Summarizing the posterior gives parameter estimates, intervals, and hypothesis tests Most of these computations are integrals
Statistical Machine Learning Lecture 8: Markov Chain Monte Carlo Sampling
 1 / 27 Statistical Machine Learning Lecture 8: Markov Chain Monte Carlo Sampling Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 27 Monte Carlo Integration The big question : Evaluate E p(z) [f(z)]
1 / 27 Statistical Machine Learning Lecture 8: Markov Chain Monte Carlo Sampling Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 27 Monte Carlo Integration The big question : Evaluate E p(z) [f(z)]
Markov Chain Monte Carlo methods
 Markov Chain Monte Carlo methods By Oleg Makhnin 1 Introduction a b c M = d e f g h i 0 f(x)dx 1.1 Motivation 1.1.1 Just here Supresses numbering 1.1.2 After this 1.2 Literature 2 Method 2.1 New math As
Markov Chain Monte Carlo methods By Oleg Makhnin 1 Introduction a b c M = d e f g h i 0 f(x)dx 1.1 Motivation 1.1.1 Just here Supresses numbering 1.1.2 After this 1.2 Literature 2 Method 2.1 New math As
28 : Approximate Inference - Distributed MCMC
 10-708: Probabilistic Graphical Models, Spring 2015 28 : Approximate Inference - Distributed MCMC Lecturer: Avinava Dubey Scribes: Hakim Sidahmed, Aman Gupta 1 Introduction For many interesting problems,
10-708: Probabilistic Graphical Models, Spring 2015 28 : Approximate Inference - Distributed MCMC Lecturer: Avinava Dubey Scribes: Hakim Sidahmed, Aman Gupta 1 Introduction For many interesting problems,
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
The Bayesian Choice. Christian P. Robert. From Decision-Theoretic Foundations to Computational Implementation. Second Edition.
 Christian P. Robert The Bayesian Choice From Decision-Theoretic Foundations to Computational Implementation Second Edition With 23 Illustrations ^Springer" Contents Preface to the Second Edition Preface
Christian P. Robert The Bayesian Choice From Decision-Theoretic Foundations to Computational Implementation Second Edition With 23 Illustrations ^Springer" Contents Preface to the Second Edition Preface
Bayesian Regression Linear and Logistic Regression
 When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
Probabilistic Graphical Models
 School of Computer Science Probabilistic Graphical Models Infinite Feature Models: The Indian Buffet Process Eric Xing Lecture 21, April 2, 214 Acknowledgement: slides first drafted by Sinead Williamson
School of Computer Science Probabilistic Graphical Models Infinite Feature Models: The Indian Buffet Process Eric Xing Lecture 21, April 2, 214 Acknowledgement: slides first drafted by Sinead Williamson
Bayesian Nonparametrics for Speech and Signal Processing
 Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Lecture 6: Markov Chain Monte Carlo
 Lecture 6: Markov Chain Monte Carlo D. Jason Koskinen koskinen@nbi.ku.dk Photo by Howard Jackman University of Copenhagen Advanced Methods in Applied Statistics Feb - Apr 2016 Niels Bohr Institute 2 Outline
Lecture 6: Markov Chain Monte Carlo D. Jason Koskinen koskinen@nbi.ku.dk Photo by Howard Jackman University of Copenhagen Advanced Methods in Applied Statistics Feb - Apr 2016 Niels Bohr Institute 2 Outline
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning
 Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Computer Vision Group Prof. Daniel Cremers. 11. Sampling Methods
 Prof. Daniel Cremers 11. Sampling Methods Sampling Methods Sampling Methods are widely used in Computer Science as an approximation of a deterministic algorithm to represent uncertainty without a parametric
Prof. Daniel Cremers 11. Sampling Methods Sampling Methods Sampling Methods are widely used in Computer Science as an approximation of a deterministic algorithm to represent uncertainty without a parametric
Stat 5101 Lecture Notes
 Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
I. Bayesian econometrics
 I. Bayesian econometrics A. Introduction B. Bayesian inference in the univariate regression model C. Statistical decision theory D. Large sample results E. Diffuse priors F. Numerical Bayesian methods
I. Bayesian econometrics A. Introduction B. Bayesian inference in the univariate regression model C. Statistical decision theory D. Large sample results E. Diffuse priors F. Numerical Bayesian methods
Computer Vision Group Prof. Daniel Cremers. 10a. Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Machine Learning using Bayesian Approaches
 Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures
 17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
Graphical Models and Kernel Methods
 Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Nonparametric Bayesian Methods - Lecture I
 Nonparametric Bayesian Methods - Lecture I Harry van Zanten Korteweg-de Vries Institute for Mathematics CRiSM Masterclass, April 4-6, 2016 Overview of the lectures I Intro to nonparametric Bayesian statistics
Nonparametric Bayesian Methods - Lecture I Harry van Zanten Korteweg-de Vries Institute for Mathematics CRiSM Masterclass, April 4-6, 2016 Overview of the lectures I Intro to nonparametric Bayesian statistics
Markov chain Monte Carlo
 Markov chain Monte Carlo Markov chain Monte Carlo (MCMC) Gibbs and Metropolis Hastings Slice sampling Practical details Iain Murray http://iainmurray.net/ Reminder Need to sample large, non-standard distributions:
Markov chain Monte Carlo Markov chain Monte Carlo (MCMC) Gibbs and Metropolis Hastings Slice sampling Practical details Iain Murray http://iainmurray.net/ Reminder Need to sample large, non-standard distributions:
MCMC: Markov Chain Monte Carlo
 I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
Bayesian nonparametrics
 Bayesian nonparametrics 1 Some preliminaries 1.1 de Finetti s theorem We will start our discussion with this foundational theorem. We will assume throughout all variables are defined on the probability
Bayesian nonparametrics 1 Some preliminaries 1.1 de Finetti s theorem We will start our discussion with this foundational theorem. We will assume throughout all variables are defined on the probability
CS242: Probabilistic Graphical Models Lecture 7B: Markov Chain Monte Carlo & Gibbs Sampling
 CS242: Probabilistic Graphical Models Lecture 7B: Markov Chain Monte Carlo & Gibbs Sampling Professor Erik Sudderth Brown University Computer Science October 27, 2016 Some figures and materials courtesy
CS242: Probabilistic Graphical Models Lecture 7B: Markov Chain Monte Carlo & Gibbs Sampling Professor Erik Sudderth Brown University Computer Science October 27, 2016 Some figures and materials courtesy
Brief introduction to Markov Chain Monte Carlo
 Brief introduction to Department of Probability and Mathematical Statistics seminar Stochastic modeling in economics and finance November 7, 2011 Brief introduction to Content 1 and motivation Classical
Brief introduction to Department of Probability and Mathematical Statistics seminar Stochastic modeling in economics and finance November 7, 2011 Brief introduction to Content 1 and motivation Classical
Lecture 7 and 8: Markov Chain Monte Carlo
 Lecture 7 and 8: Markov Chain Monte Carlo 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/ Ghahramani
Lecture 7 and 8: Markov Chain Monte Carlo 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/ Ghahramani
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Estimation of reliability parameters from Experimental data (Parte 2) Prof. Enrico Zio
 Prof. Enrico Zio") Estimation of reliability parameters from Experimental data (Parte 2) This lecture Life test (t 1,t 2,...,t n ) Estimate θ of f T t θ For example: λ of f T (t)= λe - λt Classical approach (frequentist
Estimation of reliability parameters from Experimental data (Parte 2) This lecture Life test (t 1,t 2,...,t n ) Estimate θ of f T t θ For example: λ of f T (t)= λe - λt Classical approach (frequentist
Simulation - Lectures - Part III Markov chain Monte Carlo
 Simulation - Lectures - Part III Markov chain Monte Carlo Julien Berestycki Part A Simulation and Statistical Programming Hilary Term 2018 Part A Simulation. HT 2018. J. Berestycki. 1 / 50 Outline Markov
Simulation - Lectures - Part III Markov chain Monte Carlo Julien Berestycki Part A Simulation and Statistical Programming Hilary Term 2018 Part A Simulation. HT 2018. J. Berestycki. 1 / 50 Outline Markov
Markov Chain Monte Carlo in Practice
 Markov Chain Monte Carlo in Practice Edited by W.R. Gilks Medical Research Council Biostatistics Unit Cambridge UK S. Richardson French National Institute for Health and Medical Research Vilejuif France
Markov Chain Monte Carlo in Practice Edited by W.R. Gilks Medical Research Council Biostatistics Unit Cambridge UK S. Richardson French National Institute for Health and Medical Research Vilejuif France
MCMC algorithms for fitting Bayesian models
 MCMC algorithms for fitting Bayesian models p. 1/1 MCMC algorithms for fitting Bayesian models Sudipto Banerjee sudiptob@biostat.umn.edu University of Minnesota MCMC algorithms for fitting Bayesian models
MCMC algorithms for fitting Bayesian models p. 1/1 MCMC algorithms for fitting Bayesian models Sudipto Banerjee sudiptob@biostat.umn.edu University of Minnesota MCMC algorithms for fitting Bayesian models
Pattern Recognition and Machine Learning. Bishop Chapter 11: Sampling Methods
 Pattern Recognition and Machine Learning Chapter 11: Sampling Methods Elise Arnaud Jakob Verbeek May 22, 2008 Outline of the chapter 11.1 Basic Sampling Algorithms 11.2 Markov Chain Monte Carlo 11.3 Gibbs
Pattern Recognition and Machine Learning Chapter 11: Sampling Methods Elise Arnaud Jakob Verbeek May 22, 2008 Outline of the chapter 11.1 Basic Sampling Algorithms 11.2 Markov Chain Monte Carlo 11.3 Gibbs
DAG models and Markov Chain Monte Carlo methods a short overview
 DAG models and Markov Chain Monte Carlo methods a short overview Søren Højsgaard Institute of Genetics and Biotechnology University of Aarhus August 18, 2008 Printed: August 18, 2008 File: DAGMC-Lecture.tex
DAG models and Markov Chain Monte Carlo methods a short overview Søren Højsgaard Institute of Genetics and Biotechnology University of Aarhus August 18, 2008 Printed: August 18, 2008 File: DAGMC-Lecture.tex
Hastings-within-Gibbs Algorithm: Introduction and Application on Hierarchical Model
 UNIVERSITY OF TEXAS AT SAN ANTONIO Hastings-within-Gibbs Algorithm: Introduction and Application on Hierarchical Model Liang Jing April 2010 1 1 ABSTRACT In this paper, common MCMC algorithms are introduced
UNIVERSITY OF TEXAS AT SAN ANTONIO Hastings-within-Gibbs Algorithm: Introduction and Application on Hierarchical Model Liang Jing April 2010 1 1 ABSTRACT In this paper, common MCMC algorithms are introduced
Pattern Recognition and Machine Learning. Bishop Chapter 2: Probability Distributions
 Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
The Metropolis-Hastings Algorithm. June 8, 2012
 The Metropolis-Hastings Algorithm June 8, 22 The Plan. Understand what a simulated distribution is 2. Understand why the Metropolis-Hastings algorithm works 3. Learn how to apply the Metropolis-Hastings
The Metropolis-Hastings Algorithm June 8, 22 The Plan. Understand what a simulated distribution is 2. Understand why the Metropolis-Hastings algorithm works 3. Learn how to apply the Metropolis-Hastings
Bayesian linear regression
 Bayesian linear regression Linear regression is the basis of most statistical modeling. The model is Y i = X T i β + ε i, where Y i is the continuous response X i = (X i1,..., X ip ) T is the corresponding
Bayesian linear regression Linear regression is the basis of most statistical modeling. The model is Y i = X T i β + ε i, where Y i is the continuous response X i = (X i1,..., X ip ) T is the corresponding
Computer Vision Group Prof. Daniel Cremers. 14. Sampling Methods
 Prof. Daniel Cremers 14. Sampling Methods Sampling Methods Sampling Methods are widely used in Computer Science as an approximation of a deterministic algorithm to represent uncertainty without a parametric
Prof. Daniel Cremers 14. Sampling Methods Sampling Methods Sampling Methods are widely used in Computer Science as an approximation of a deterministic algorithm to represent uncertainty without a parametric
Learning Bayesian network : Given structure and completely observed data
 Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Lecture 2: Priors and Conjugacy
 Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
Parameter Estimation. William H. Jefferys University of Texas at Austin Parameter Estimation 7/26/05 1
 Parameter Estimation William H. Jefferys University of Texas at Austin bill@bayesrules.net Parameter Estimation 7/26/05 1 Elements of Inference Inference problems contain two indispensable elements: Data
Parameter Estimation William H. Jefferys University of Texas at Austin bill@bayesrules.net Parameter Estimation 7/26/05 1 Elements of Inference Inference problems contain two indispensable elements: Data
Bagging During Markov Chain Monte Carlo for Smoother Predictions
 Bagging During Markov Chain Monte Carlo for Smoother Predictions Herbert K. H. Lee University of California, Santa Cruz Abstract: Making good predictions from noisy data is a challenging problem. Methods
Bagging During Markov Chain Monte Carlo for Smoother Predictions Herbert K. H. Lee University of California, Santa Cruz Abstract: Making good predictions from noisy data is a challenging problem. Methods
Markov Chain Monte Carlo
 Markov Chain Monte Carlo (and Bayesian Mixture Models) David M. Blei Columbia University October 14, 2014 We have discussed probabilistic modeling, and have seen how the posterior distribution is the critical
Markov Chain Monte Carlo (and Bayesian Mixture Models) David M. Blei Columbia University October 14, 2014 We have discussed probabilistic modeling, and have seen how the posterior distribution is the critical
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
CS 361: Probability & Statistics
 March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
an introduction to bayesian inference
 with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
MCMC and Gibbs Sampling. Kayhan Batmanghelich
 MCMC and Gibbs Sampling Kayhan Batmanghelich 1 Approaches to inference l Exact inference algorithms l l l The elimination algorithm Message-passing algorithm (sum-product, belief propagation) The junction
MCMC and Gibbs Sampling Kayhan Batmanghelich 1 Approaches to inference l Exact inference algorithms l l l The elimination algorithm Message-passing algorithm (sum-product, belief propagation) The junction
Time-Sensitive Dirichlet Process Mixture Models
 Time-Sensitive Dirichlet Process Mixture Models Xiaojin Zhu Zoubin Ghahramani John Lafferty May 25 CMU-CALD-5-4 School of Computer Science Carnegie Mellon University Pittsburgh, PA 523 Abstract We introduce
Time-Sensitive Dirichlet Process Mixture Models Xiaojin Zhu Zoubin Ghahramani John Lafferty May 25 CMU-CALD-5-4 School of Computer Science Carnegie Mellon University Pittsburgh, PA 523 Abstract We introduce
CS839: Probabilistic Graphical Models. Lecture 7: Learning Fully Observed BNs. Theo Rekatsinas
 CS839: Probabilistic Graphical Models Lecture 7: Learning Fully Observed BNs Theo Rekatsinas 1 Exponential family: a basic building block For a numeric random variable X p(x ) =h(x)exp T T (x) A( ) = 1
CS839: Probabilistic Graphical Models Lecture 7: Learning Fully Observed BNs Theo Rekatsinas 1 Exponential family: a basic building block For a numeric random variable X p(x ) =h(x)exp T T (x) A( ) = 1
MCMC Methods: Gibbs and Metropolis
 MCMC Methods: Gibbs and Metropolis Patrick Breheny February 28 Patrick Breheny BST 701: Bayesian Modeling in Biostatistics 1/30 Introduction As we have seen, the ability to sample from the posterior distribution
MCMC Methods: Gibbs and Metropolis Patrick Breheny February 28 Patrick Breheny BST 701: Bayesian Modeling in Biostatistics 1/30 Introduction As we have seen, the ability to sample from the posterior distribution
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
A Process over all Stationary Covariance Kernels
 A Process over all Stationary Covariance Kernels Andrew Gordon Wilson June 9, 0 Abstract I define a process over all stationary covariance kernels. I show how one might be able to perform inference that
A Process over all Stationary Covariance Kernels Andrew Gordon Wilson June 9, 0 Abstract I define a process over all stationary covariance kernels. I show how one might be able to perform inference that
MARKOV CHAIN MONTE CARLO
 MARKOV CHAIN MONTE CARLO RYAN WANG Abstract. This paper gives a brief introduction to Markov Chain Monte Carlo methods, which offer a general framework for calculating difficult integrals. We start with
MARKOV CHAIN MONTE CARLO RYAN WANG Abstract. This paper gives a brief introduction to Markov Chain Monte Carlo methods, which offer a general framework for calculating difficult integrals. We start with
Markov chain Monte Carlo Lecture 9
 Markov chain Monte Carlo Lecture 9 David Sontag New York University Slides adapted from Eric Xing and Qirong Ho (CMU) Limitations of Monte Carlo Direct (unconditional) sampling Hard to get rare events
Markov chain Monte Carlo Lecture 9 David Sontag New York University Slides adapted from Eric Xing and Qirong Ho (CMU) Limitations of Monte Carlo Direct (unconditional) sampling Hard to get rare events
SAMPLING ALGORITHMS. In general. Inference in Bayesian models
 SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
STAT 518 Intro Student Presentation
 STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
Machine Learning for Data Science (CS4786) Lecture 24
 Lecture 24") Machine Learning for Data Science (CS4786) Lecture 24 Graphical Models: Approximate Inference Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ BELIEF PROPAGATION OR MESSAGE PASSING Each
Machine Learning for Data Science (CS4786) Lecture 24 Graphical Models: Approximate Inference Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ BELIEF PROPAGATION OR MESSAGE PASSING Each
INTRODUCTION TO BAYESIAN STATISTICS
 INTRODUCTION TO BAYESIAN STATISTICS Sarat C. Dass Department of Statistics & Probability Department of Computer Science & Engineering Michigan State University TOPICS The Bayesian Framework Different Types
INTRODUCTION TO BAYESIAN STATISTICS Sarat C. Dass Department of Statistics & Probability Department of Computer Science & Engineering Michigan State University TOPICS The Bayesian Framework Different Types
DS-GA 1002 Lecture notes 11 Fall Bayesian statistics
 DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
A quick introduction to Markov chains and Markov chain Monte Carlo (revised version)
") A quick introduction to Markov chains and Markov chain Monte Carlo (revised version) Rasmus Waagepetersen Institute of Mathematical Sciences Aalborg University 1 Introduction These notes are intended to
A quick introduction to Markov chains and Markov chain Monte Carlo (revised version) Rasmus Waagepetersen Institute of Mathematical Sciences Aalborg University 1 Introduction These notes are intended to