Clustering. SVD and NMF
|
|
|
- Agnes Marsh
- 5 years ago
- Views:
Transcription
1 Clustering with the SVD and NMF Amy Langville Mathematics Department College of Charleston Dagstuhl 2/14/2007
2 Outline Fielder Method Extended Fielder Method and SVD Clustering with SVD vs. NMF Demos with vismatrix Tool
3 Fiedler Method
4 Fiedler Method s.p.d Laplacian matrix L = D A A must be symmetrix. Else, symmetrize by: A T A AA T A + A T Properties of L L is spd so all λ i 0. λ i = 0, connected component i If L is scc, then λ 1 = 0, λ i > 0, i = 2,...,n. The subdominant eigenvector v 2 gives info. on clustering.
5 Understanding Graph Theory Given this graph, there are no apparent clusters.
6 Understanding Graph Theory However, suppose we untangle the web.
7 Understanding Graph Theory However, suppose we untangle the web.
8 Understanding Graph Theory However, suppose we untangle the web.
9 Understanding Graph Theory However, suppose we untangle the web.
10 Understanding Graph Theory However, suppose we untangle the web.
11 Understanding Graph Theory However, suppose we untangle the web.
12 Understanding Graph Theory Although the clusters are now apparent, we need a better method
13 Using the Fiedler Vector Generally, v 2 is recursively used to partition the graph by separating the components into negative and positive values. sign(v 2 )=[-, -, -, +, +, +, -, -, -, +]
14 A Fiedler Clustering Example
15 Reminder: Problems With Laplacian The Laplacian method requires the use of: an undirected graph. a pictorially symmetric matrix. Square matrices. Zero may not always be the best choice for partitioning the eigenvector values of v 2. Recursive algorithms are expensive.
16 Why does Fiedler vector cluster? Two-way partition A = [ ] A1 A 2 A 3 A 4 D = [ D1 0 0 D 4 Assign each node to one of two clusters. Create decision variables x i x i = 1, if node i goes in cluster 1 x i = 1, if node i goes in cluster 2 Objective: minimize the number of between-cluster links maximize the number of in-cluster links min x x T Lx Suppose x = [ e e ]. Then min x x T Lx =(e T D 1 e + e T D 4 e)+(e T A 2 e + e T A 3 e) (e T A 1 e + e T A 4 e) for balancing between-cluster links in-cluster links ]
17 Why does Fiedler vector cluster? Optimization Problem min x T Lx is NP-hard. Relax from discrete to continuous values for x. By Rayleigh theorem, min x 2 =1 xt Lx = λ 1, with x as the eigenvector corresponding to λ 1. BUT, x = e, which is not helpful for clustering!
18 Optimization Solution Add constraint x T e = 0. By Courant-Fischer theorem, min x T Lx = λ 2, x 2 =1, x T e=0 with x = v 2 as the eigenvector corresponding to λ 2. v 2 is called the Fiedler vector.
19 Extended Fiedler
20 Other subdominant eigenvectors If v 2 gives approximate info. about clustering, what about the other subdominant eigenvectors v 3, v 4,...? Since L is symmetric, it has an orthogonal eigendecomposition. Thus, for i 1, v i v 1 = e. Thus, for i 1, v i sums to 0. Thus, for i 1, v i is centered about 0. This explains why, when bisecting a graph, a split about 0 makes sense.
21 Example Graph
22 Clustered Example Graph using eigenvectors v 2, v 3, v 4 Nodes 4 and 18 are saddle nodes that straddle a few clusters.
![Clustered Example Eigenvectors - - + - + - - + + 6 clusters, 6 [3,2 3 ] + + + + - + + - - Sign patterns in eigenvectors give clusters and saddle nodes.](/docs-images/90/102442814/images/23-0.jpg "Number of clusters found is not fixed, but lies in [j, 2 j ], where j is the number of eigenvectors used.")
23 Clustered Example Eigenvectors clusters, 6 [3,2 3 ] Sign patterns in eigenvectors give clusters and saddle nodes. Number of clusters found is not fixed, but lies in [j, 2 j ], where j is the number of eigenvectors used. takes a global view for clustering (whereas recursive Fiedler tunnels down, despite possible errors at initial iterations.)
24 Clustering with the SVD
25 Applying this to SVD A A k = U k Σ k V T k Left singular vectors in U k of term-by-document matrix A are eigenvectors of AA T. sign pattern in U k will cluster terms. Right singular vectors in V k of term-by-document matrix A are eigenvectors of A T A. sign pattern in V k will cluster documents.
26 Pseudocode For Term Clustering k = truncation point for SVD input U k (matrix of k left singular vectors of A) input j (user-defined scalar, # of clusters [j, 2 j ]. Note: j k.) create B = U(:, 1 : j) >= 0); binary matrix with sign patterns associate a number x(i) with each unique sign pattern x=zeros(n,1); for i=1:j x=x+(2 j i )*(B(:,i)); end reorder rows of A by indices in sorted vector x
27 vismatrix tool David Gleich
28 SVD Clustering of Reuters10 72K terms, 9K docs, 415K nonzeros j = 10 for terms produces 486 term clusters j = 4 for documents produces 8 document clusters
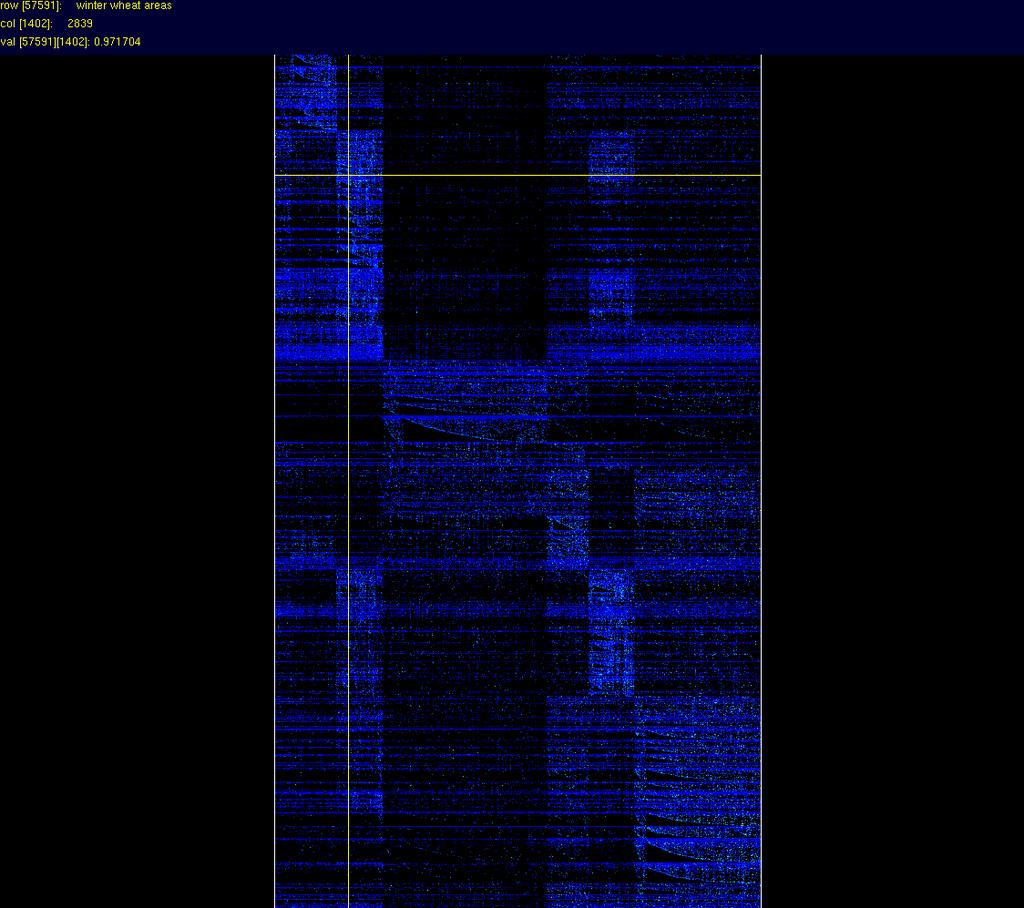
29
30 SVD Clustering of Reuters10 72K terms, 9K docs, 415K nonzeros j = 10 for terms produces 486 term clusters j = 4 for documents produces 8 document clusters j = 10 for terms produces 486 term clusters j = 10 for documents produces 391 document clusters

31
32 Summary of SVD Clustering + variable # of clusters returned between j and 2 j + sign pattern idea allows for natural division within clusters + clusters ordered so that similar clusters are nearby each other + less work than recursive Fiedler + can choose different # of clusters for terms and documents + can identify saddle terms and saddle documents only hard clustering is possible picture can be too refined with too many clusters as j increases, range for # of clusters becomes too wide EX: j=10, # of clusters is between 10 and 1024 In some sense, terms and docs are treated separately. (due to symmetry requirement)
33 Clustering with the NMF
34 Nonnegative Matrix Factorization (Lee and Seung 2000) Mean squared error objective function min A WH 2 F s.t. W, H 0 Nonlinear Optimization Problem convex in W or H, but not both tough to get global min huge # unknowns: mk for W and kn for H (EX: A 70K 10K and k=10 topics 800K unknowns) above objective is one of many possible convergence to local min NOT guaranteed for any algorithm
35 Multiplicative update rules Lee-Seung 2000 Hoyer 2002 NMF Algorithms Gradient Descent Hoyer 2004 Berry-Plemmons 2004 Lin 2007 Alternating Least Squares Paatero 1994 ACLS AHCLS
36 NMF Algorithm: Lee and Seung 2000 Mean Squared Error objective function min A WH 2 F s.t. W, H 0 W = abs(randn(m,k)); H = abs(randn(k,n)); for i = 1 : maxiter H = H.* (W T A)./(W T WH ); W = W.* (AH T )./(WHH T ); end (proof of convergence to fixed point based on E-M convergence proof) (objective function tails off after iterations)
37 NMF Algorithm: Lee and Seung 2000 Divergence objective function min i,j (A ij log A ij [WH] ij A ij +[WH] ij ) s.t. W, H 0 W = abs(randn(m,k)); H = abs(randn(k,n)); for i = 1 : maxiter H = H.* (W T (A./ (WH )))./ W T ee T ; W = W.* ((A./ (WH ))H T )./ee T H T ; end (proof of convergence to fixed point based on E-M convergence proof) (objective function tails off after iterations)
38 Multiplicative Update Summary Pros Cons + convergence theory: guaranteed to converge to fixed point + good initialization W (0), H (0) speeds convergence and gets to better fixed point fixed point may be local min or saddle point good initialization W (0), H (0) speeds convergence and gets to better fixed point slow: many M-M multiplications at each iteration hundreds/thousands of iterations until convergence no sparsity of W and H incorporated into mathematical setup 0 elements locked
39 Multiplicative Update and Locking During iterations of mult. update algorithms, once an element in W or H becomes 0, it can never become positive. Implications for W: In order to improve objective function, algorithm can only take terms out, not add terms, to topic vectors. Very inflexible: once algorithm starts down a path for a topic vector, it must continue in that vein. ALS-type algorithms do not lock elements, greater flexibility allows them to escape from path heading towards poor local min
40 Sparsity Measures Berry et al. x 2 2 Hoyer spar(x n 1 )= n x 1 / x 2 n 1 Diversity measure E (p) (x) = n i=1 x i p, 0 p 1 E (p) (x) = n i=1 x i p,p<0 Rao and Kreutz-Delgado: algorithms for minimizing E (p) (x) s.t. Ax = b, but expensive iterative procedure Ideal nnz(x) not continuous, NP-hard to use this in optim.
41 NMF Algorithm: Berry et al Gradient Descent Constrained Least Squares W = abs(randn(m,k)); (scale cols of W to unit norm) H = zeros(k,n); for i = 1 : maxiter CLS forj=1: #docs, solve min H j A j WH j λ H j 2 2 s.t. H j 0 GD W = W.* (AH T )./(WHH T ); (scale cols of W) end
42 NMF Algorithm: Berry et al Gradient Descent Constrained Least Squares W = abs(randn(m,k)); (scale cols of W to unit norm) H = zeros(k,n); for i = 1 : maxiter CLS forj=1: #docs, solve min H j A j WH j λ H j 2 2 s.t. H j 0 solve for H: (W T W + λ I) H = W T A; (small matrix solve) GD W = W.* (AH T )./(WHH T ); (scale cols of W) end (objective function tails off after iterations)
43 Berry et al Summary Pros Cons + fast: less work per iteration than most other NMF algorithms + fast: small # of iterations until convergence + sparsity parameter for H 0 elements in W are locked no sparsity parameter for W ad hoc nonnegativity: negative elements in H are set to 0, could run lsqnonneg or snnls instead no convergence theory
44 PMF Algorithm: Paatero & Tapper 1994 Mean Squared Error Alternating Least Squares min A WH 2 F s.t. W, H 0 W = abs(randn(m,k)); for i = 1 : maxiter LS for j = 1 : #docs, solve LS min H j A j WH j 2 2 s.t. H j 0 for j = 1 : #terms, solve min Wj A j W j H 2 2 s.t. W j 0 end
45 ALS Algorithm W = abs(randn(m,k)); for i = 1 : maxiter LS solve matrix equation W T WH = W T A for H nonneg H = H. (H >= 0) LS solve matrix equation HH T W T = HA T for W nonneg W = W. (W >= 0) end
46 ALS Summary Pros + fast + works well in practice + speedy convergence + only need to initialize W (0) + 0 elements not locked Cons no sparsity of W and H incorporated into mathematical setup ad hoc nonnegativity: negative elements are set to 0 ad hoc sparsity: negative elements are set to 0 no convergence theory
47 Alternating Constrained Least Squares If the very fast ALS works well in practice and no NMF algorithms guarantee convergence to local min, why not use ALS? W = abs(randn(m,k)); for i = 1 : maxiter CLS forj=1: #docs, solve CLS forj=1: #terms, solve min H j A j WH j λ H H j 2 2 s.t. H j 0 min Wj A j W j H λ W W j 2 2 s.t. W j 0 end
48 Alternating Constrained Least Squares If the very fast ALS works well in practice and no NMF algorithms guarantee convergence to local min, why not use ALS? W = abs(randn(m,k)); for i = 1 : maxiter cls solve for H: (W T W + λ H I) H = W T A nonneg H = H. (H >= 0) cls solve for W: (HH T + λ W I) W T = HA T nonneg W = W. (W >= 0) end
49 ACLS Summary Pros Cons + fast: 6.6 sec vs. 9.8 sec (gd-cls) + works well in practice + speedy convergence + only need to initialize W (0) + 0 elements not locked + allows for sparsity in both W and H ad hoc nonnegativity: after LS, negative elements set to 0, could run lsqnonneg or snnls instead (doesn t improve accuracy much) no convergence theory
50 ACLS + spar(x) Is there a better way to measure sparsity and still maintain speed of ACLS? spar(x n 1 )= n x 1 / x 2 n 1 ((1 spar(x)) n+spar(x)) x 2 x 1 =0 (spar(w j )=α W and spar(h j )=α H ) W = abs(randn(m,k)); for i = 1 : maxiter cls cls for j = 1 : #docs, solve min H j A j WH j λ H(((1 α H ) k + α H ) H j 2 2 H j 2 1 ) for j = 1 : #terms, solve s.t. H j 0 min Wj A j W j H λ W(((1 α W ) k + α W ) W j 2 2 W j 2 1 ) s.t. W j 0 end
51 AHCLS (spar(w j )=α W and spar(h j )=α H ) W = abs(randn(m,k)); β H =((1 α H ) k + α H ) 2 β W =((1 α W ) k + α W ) 2 for i = 1 : maxiter cls solve for H: (W T W + λ H β H I λ H E) H = W T A nonneg H = H. (H >= 0) cls solve for W: (HH T + λ W β W I λ W E) W T = HA T nonneg W = W. (W >= 0) end
52 AHCLS Summary 122 Convergence of GDCLS and AHCLS Algorithms on MED dataset Pros + fast: 6.8 vs. 9.8 sec (gd-cls) + works well in practice + speedy convergence + only need to initialize W (0) + 0 elements not locked Accuracy A -WH F AHCLS GDCLS SVD Error = number of iterations + allows for more explicit sparsity in both W and H Cons ad hoc nonnegativity: after LS, negative elements set to 0, could run lsqnonneg or snnls instead (doesn t improve accuracy much) convergence to stationary point only guaranteed when nonnegativity properly enforced.
53 Clustering with the NMF Clustering Terms use rows of W m k = cl.1 cl.2... cl.k term term Clustering Documents use cols of H k n = doc1 doc2... docn cl cl.k soft clustering is very natural
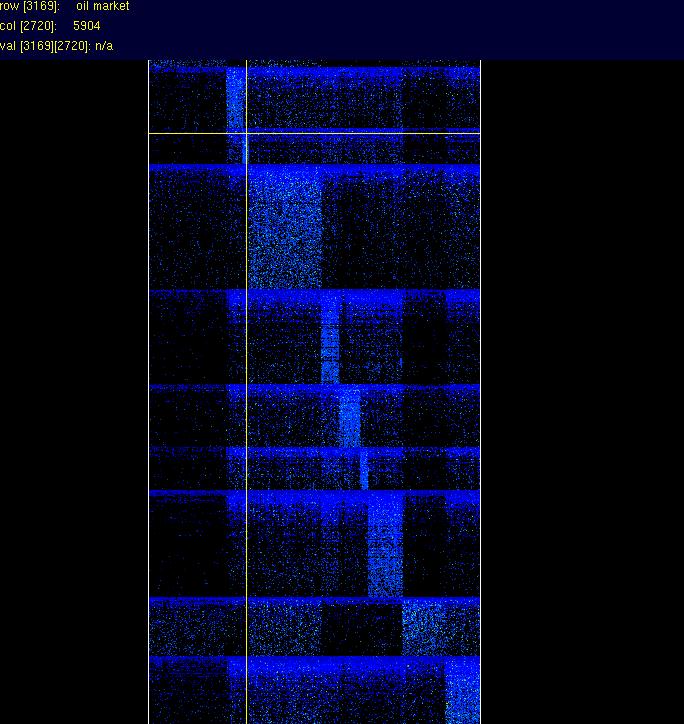
54

55
56 The Enron Dataset (SAS) PRIVATE collection of 150 Enron employees during ,000 terms and 65,000 messages Term-by-Message Matrix f astow1 f astow2 skilling subpoena dynegy
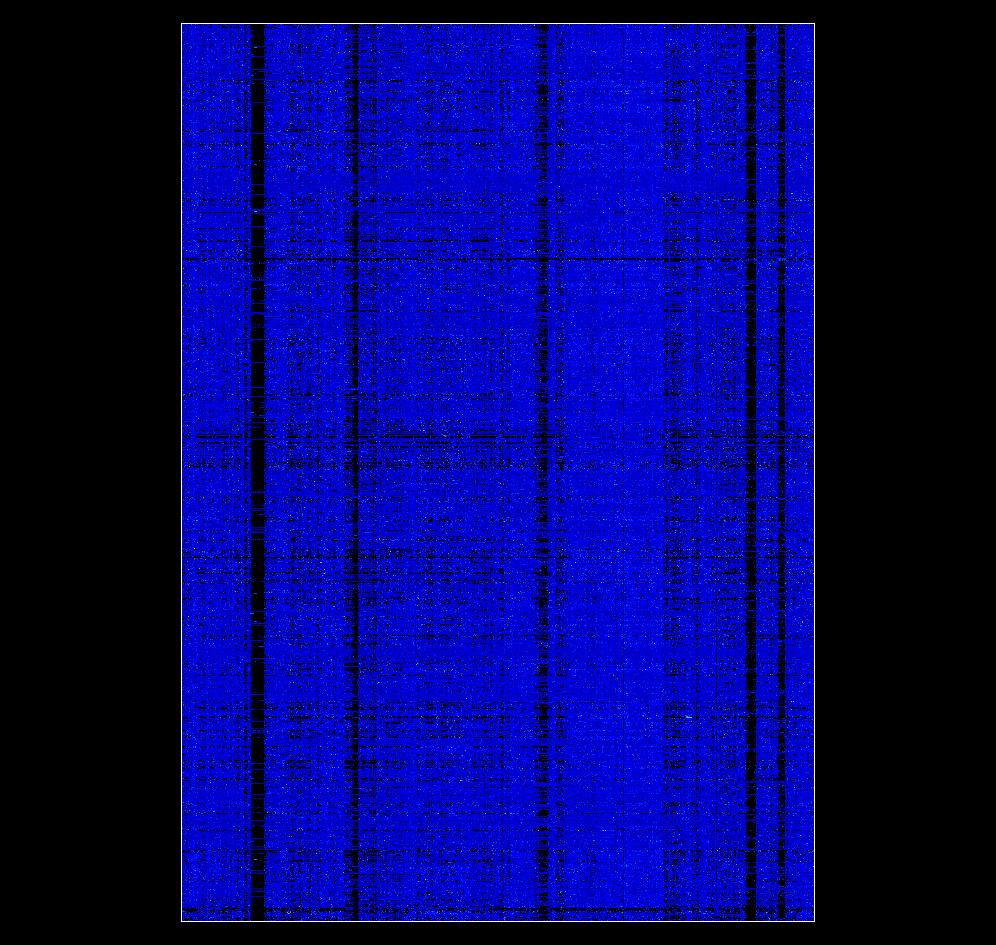
57

58
59 Summary of NMF Clustering + appealing picture of clusters + some NMF algorithms are faster than SVD + terms and docs are treated in integrated fashion + hard and soft clustering is possible user must choose k, a fixed # of clusters clusters have no particular order, similar clusters do not appear near each other
60 Conclusions SVD variable # of clusters returned clusters ordered so that similar clusters are nearby each other can choose different # of clusters for terms and documents can identify saddle terms and saddle documents NMF fast sparse factorization terms and docs are treated in integrated fashion hard and soft clustering is possible
Nonnegative Matrix Factorization. Data Mining
 The Nonnegative Matrix Factorization in Data Mining Amy Langville langvillea@cofc.edu Mathematics Department College of Charleston Charleston, SC Yahoo! Research 10/18/2005 Outline Part 1: Historical Developments
The Nonnegative Matrix Factorization in Data Mining Amy Langville langvillea@cofc.edu Mathematics Department College of Charleston Charleston, SC Yahoo! Research 10/18/2005 Outline Part 1: Historical Developments
Applications. Nonnegative Matrices: Ranking
 Applications of Nonnegative Matrices: Ranking and Clustering Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/7/2008 Collaborators Carl Meyer, N. C. State University David
Applications of Nonnegative Matrices: Ranking and Clustering Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/7/2008 Collaborators Carl Meyer, N. C. State University David
1 Matrix notation and preliminaries from spectral graph theory
 Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
1 Matrix notation and preliminaries from spectral graph theory
 Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Non-Negative Matrix Factorization
 Chapter 3 Non-Negative Matrix Factorization Part : Introduction & computation Motivating NMF Skillicorn chapter 8; Berry et al. (27) DMM, summer 27 2 Reminder A T U Σ V T T Σ, V U 2 Σ 2,2 V 2.8.6.6.3.6.5.3.6.3.6.4.3.6.4.3.3.4.5.3.5.8.3.8.3.3.5
Chapter 3 Non-Negative Matrix Factorization Part : Introduction & computation Motivating NMF Skillicorn chapter 8; Berry et al. (27) DMM, summer 27 2 Reminder A T U Σ V T T Σ, V U 2 Σ 2,2 V 2.8.6.6.3.6.5.3.6.3.6.4.3.6.4.3.3.4.5.3.5.8.3.8.3.3.5
1 Non-negative Matrix Factorization (NMF)
") 2018-06-21 1 Non-negative Matrix Factorization NMF) In the last lecture, we considered low rank approximations to data matrices. We started with the optimal rank k approximation to A R m n via the SVD,
2018-06-21 1 Non-negative Matrix Factorization NMF) In the last lecture, we considered low rank approximations to data matrices. We started with the optimal rank k approximation to A R m n via the SVD,
Non-Negative Matrix Factorization
 Chapter 3 Non-Negative Matrix Factorization Part 2: Variations & applications Geometry of NMF 2 Geometry of NMF 1 NMF factors.9.8 Data points.7.6 Convex cone.5.4 Projections.3.2.1 1.5 1.5 1.5.5 1 3 Sparsity
Chapter 3 Non-Negative Matrix Factorization Part 2: Variations & applications Geometry of NMF 2 Geometry of NMF 1 NMF factors.9.8 Data points.7.6 Convex cone.5.4 Projections.3.2.1 1.5 1.5 1.5.5 1 3 Sparsity
Lecture: Local Spectral Methods (1 of 4)
") Stat260/CS294: Spectral Graph Methods Lecture 18-03/31/2015 Lecture: Local Spectral Methods (1 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Stat260/CS294: Spectral Graph Methods Lecture 18-03/31/2015 Lecture: Local Spectral Methods (1 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Dimension Reduction and Iterative Consensus Clustering
 Dimension Reduction and Iterative Consensus Clustering Southeastern Clustering and Ranking Workshop August 24, 2009 Dimension Reduction and Iterative 1 Document Clustering Geometry of the SVD Centered
Dimension Reduction and Iterative Consensus Clustering Southeastern Clustering and Ranking Workshop August 24, 2009 Dimension Reduction and Iterative 1 Document Clustering Geometry of the SVD Centered
Communities, Spectral Clustering, and Random Walks
 Communities, Spectral Clustering, and Random Walks David Bindel Department of Computer Science Cornell University 3 Jul 202 Spectral clustering recipe Ingredients:. A subspace basis with useful information
Communities, Spectral Clustering, and Random Walks David Bindel Department of Computer Science Cornell University 3 Jul 202 Spectral clustering recipe Ingredients:. A subspace basis with useful information
Matrix Decomposition in Privacy-Preserving Data Mining JUN ZHANG DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF KENTUCKY
 Matrix Decomposition in Privacy-Preserving Data Mining JUN ZHANG DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF KENTUCKY OUTLINE Why We Need Matrix Decomposition SVD (Singular Value Decomposition) NMF (Nonnegative
Matrix Decomposition in Privacy-Preserving Data Mining JUN ZHANG DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF KENTUCKY OUTLINE Why We Need Matrix Decomposition SVD (Singular Value Decomposition) NMF (Nonnegative
Iterative Methods for Solving A x = b
 Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
A Least Squares Formulation for Canonical Correlation Analysis
 A Least Squares Formulation for Canonical Correlation Analysis Liang Sun, Shuiwang Ji, and Jieping Ye Department of Computer Science and Engineering Arizona State University Motivation Canonical Correlation
A Least Squares Formulation for Canonical Correlation Analysis Liang Sun, Shuiwang Ji, and Jieping Ye Department of Computer Science and Engineering Arizona State University Motivation Canonical Correlation
Eigenvalue problems and optimization
 Notes for 2016-04-27 Seeking structure For the past three weeks, we have discussed rather general-purpose optimization methods for nonlinear equation solving and optimization. In practice, of course, we
Notes for 2016-04-27 Seeking structure For the past three weeks, we have discussed rather general-purpose optimization methods for nonlinear equation solving and optimization. In practice, of course, we
Numerical Linear Algebra Primer. Ryan Tibshirani Convex Optimization /36-725
 Numerical Linear Algebra Primer Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: proximal gradient descent Consider the problem min g(x) + h(x) with g, h convex, g differentiable, and h simple
Numerical Linear Algebra Primer Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: proximal gradient descent Consider the problem min g(x) + h(x) with g, h convex, g differentiable, and h simple
ECS231: Spectral Partitioning. Based on Berkeley s CS267 lecture on graph partition
 ECS231: Spectral Partitioning Based on Berkeley s CS267 lecture on graph partition 1 Definition of graph partitioning Given a graph G = (N, E, W N, W E ) N = nodes (or vertices), E = edges W N = node weights
ECS231: Spectral Partitioning Based on Berkeley s CS267 lecture on graph partition 1 Definition of graph partitioning Given a graph G = (N, E, W N, W E ) N = nodes (or vertices), E = edges W N = node weights
Inverse Power Method for Non-linear Eigenproblems
 Inverse Power Method for Non-linear Eigenproblems Matthias Hein and Thomas Bühler Anubhav Dwivedi Department of Aerospace Engineering & Mechanics 7th March, 2017 1 / 30 OUTLINE Motivation Non-Linear Eigenproblems
Inverse Power Method for Non-linear Eigenproblems Matthias Hein and Thomas Bühler Anubhav Dwivedi Department of Aerospace Engineering & Mechanics 7th March, 2017 1 / 30 OUTLINE Motivation Non-Linear Eigenproblems
Applied Machine Learning for Biomedical Engineering. Enrico Grisan
 Applied Machine Learning for Biomedical Engineering Enrico Grisan enrico.grisan@dei.unipd.it Data representation To find a representation that approximates elements of a signal class with a linear combination
Applied Machine Learning for Biomedical Engineering Enrico Grisan enrico.grisan@dei.unipd.it Data representation To find a representation that approximates elements of a signal class with a linear combination
MULTIPLICATIVE ALGORITHM FOR CORRENTROPY-BASED NONNEGATIVE MATRIX FACTORIZATION
 MULTIPLICATIVE ALGORITHM FOR CORRENTROPY-BASED NONNEGATIVE MATRIX FACTORIZATION Ehsan Hosseini Asl 1, Jacek M. Zurada 1,2 1 Department of Electrical and Computer Engineering University of Louisville, Louisville,
MULTIPLICATIVE ALGORITHM FOR CORRENTROPY-BASED NONNEGATIVE MATRIX FACTORIZATION Ehsan Hosseini Asl 1, Jacek M. Zurada 1,2 1 Department of Electrical and Computer Engineering University of Louisville, Louisville,
SVD, Power method, and Planted Graph problems (+ eigenvalues of random matrices)
") Chapter 14 SVD, Power method, and Planted Graph problems (+ eigenvalues of random matrices) Today we continue the topic of low-dimensional approximation to datasets and matrices. Last time we saw the singular
Chapter 14 SVD, Power method, and Planted Graph problems (+ eigenvalues of random matrices) Today we continue the topic of low-dimensional approximation to datasets and matrices. Last time we saw the singular
Numerical Linear Algebra Primer. Ryan Tibshirani Convex Optimization
 Numerical Linear Algebra Primer Ryan Tibshirani Convex Optimization 10-725 Consider Last time: proximal Newton method min x g(x) + h(x) where g, h convex, g twice differentiable, and h simple. Proximal
Numerical Linear Algebra Primer Ryan Tibshirani Convex Optimization 10-725 Consider Last time: proximal Newton method min x g(x) + h(x) where g, h convex, g twice differentiable, and h simple. Proximal
Communities, Spectral Clustering, and Random Walks
 Communities, Spectral Clustering, and Random Walks David Bindel Department of Computer Science Cornell University 26 Sep 2011 20 21 19 16 22 28 17 18 29 26 27 30 23 1 25 5 8 24 2 4 14 3 9 13 15 11 10 12
Communities, Spectral Clustering, and Random Walks David Bindel Department of Computer Science Cornell University 26 Sep 2011 20 21 19 16 22 28 17 18 29 26 27 30 23 1 25 5 8 24 2 4 14 3 9 13 15 11 10 12
Quick Introduction to Nonnegative Matrix Factorization
 Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
Spectral Clustering on Handwritten Digits Database
 University of Maryland-College Park Advance Scientific Computing I,II Spectral Clustering on Handwritten Digits Database Author: Danielle Middlebrooks Dmiddle1@math.umd.edu Second year AMSC Student Advisor:
University of Maryland-College Park Advance Scientific Computing I,II Spectral Clustering on Handwritten Digits Database Author: Danielle Middlebrooks Dmiddle1@math.umd.edu Second year AMSC Student Advisor:
Chapter 11. Matrix Algorithms and Graph Partitioning. M. E. J. Newman. June 10, M. E. J. Newman Chapter 11 June 10, / 43
 Chapter 11 Matrix Algorithms and Graph Partitioning M. E. J. Newman June 10, 2016 M. E. J. Newman Chapter 11 June 10, 2016 1 / 43 Table of Contents 1 Eigenvalue and Eigenvector Eigenvector Centrality The
Chapter 11 Matrix Algorithms and Graph Partitioning M. E. J. Newman June 10, 2016 M. E. J. Newman Chapter 11 June 10, 2016 1 / 43 Table of Contents 1 Eigenvalue and Eigenvector Eigenvector Centrality The
CONVOLUTIVE NON-NEGATIVE MATRIX FACTORISATION WITH SPARSENESS CONSTRAINT
 CONOLUTIE NON-NEGATIE MATRIX FACTORISATION WITH SPARSENESS CONSTRAINT Paul D. O Grady Barak A. Pearlmutter Hamilton Institute National University of Ireland, Maynooth Co. Kildare, Ireland. ABSTRACT Discovering
CONOLUTIE NON-NEGATIE MATRIX FACTORISATION WITH SPARSENESS CONSTRAINT Paul D. O Grady Barak A. Pearlmutter Hamilton Institute National University of Ireland, Maynooth Co. Kildare, Ireland. ABSTRACT Discovering
Package sgpca. R topics documented: July 6, Type Package. Title Sparse Generalized Principal Component Analysis. Version 1.0.
 Package sgpca July 6, 2013 Type Package Title Sparse Generalized Principal Component Analysis Version 1.0 Date 2012-07-05 Author Frederick Campbell Maintainer Frederick Campbell
Package sgpca July 6, 2013 Type Package Title Sparse Generalized Principal Component Analysis Version 1.0 Date 2012-07-05 Author Frederick Campbell Maintainer Frederick Campbell
Rank Selection in Low-rank Matrix Approximations: A Study of Cross-Validation for NMFs
 Rank Selection in Low-rank Matrix Approximations: A Study of Cross-Validation for NMFs Bhargav Kanagal Department of Computer Science University of Maryland College Park, MD 277 bhargav@cs.umd.edu Vikas
Rank Selection in Low-rank Matrix Approximations: A Study of Cross-Validation for NMFs Bhargav Kanagal Department of Computer Science University of Maryland College Park, MD 277 bhargav@cs.umd.edu Vikas
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 12: Graph Clustering Cho-Jui Hsieh UC Davis May 29, 2018 Graph Clustering Given a graph G = (V, E, W ) V : nodes {v 1,, v n } E: edges
STA141C: Big Data & High Performance Statistical Computing Lecture 12: Graph Clustering Cho-Jui Hsieh UC Davis May 29, 2018 Graph Clustering Given a graph G = (V, E, W ) V : nodes {v 1,, v n } E: edges
Networks and Their Spectra
 Networks and Their Spectra Victor Amelkin University of California, Santa Barbara Department of Computer Science victor@cs.ucsb.edu December 4, 2017 1 / 18 Introduction Networks (= graphs) are everywhere.
Networks and Their Spectra Victor Amelkin University of California, Santa Barbara Department of Computer Science victor@cs.ucsb.edu December 4, 2017 1 / 18 Introduction Networks (= graphs) are everywhere.
Data Mining and Matrices
 Data Mining and Matrices 08 Boolean Matrix Factorization Rainer Gemulla, Pauli Miettinen June 13, 2013 Outline 1 Warm-Up 2 What is BMF 3 BMF vs. other three-letter abbreviations 4 Binary matrices, tiles,
Data Mining and Matrices 08 Boolean Matrix Factorization Rainer Gemulla, Pauli Miettinen June 13, 2013 Outline 1 Warm-Up 2 What is BMF 3 BMF vs. other three-letter abbreviations 4 Binary matrices, tiles,
Non-Negative Matrix Factorization with Quasi-Newton Optimization
 Non-Negative Matrix Factorization with Quasi-Newton Optimization Rafal ZDUNEK, Andrzej CICHOCKI Laboratory for Advanced Brain Signal Processing BSI, RIKEN, Wako-shi, JAPAN Abstract. Non-negative matrix
Non-Negative Matrix Factorization with Quasi-Newton Optimization Rafal ZDUNEK, Andrzej CICHOCKI Laboratory for Advanced Brain Signal Processing BSI, RIKEN, Wako-shi, JAPAN Abstract. Non-negative matrix
Lecture 3: Huge-scale optimization problems
 Liege University: Francqui Chair 2011-2012 Lecture 3: Huge-scale optimization problems Yurii Nesterov, CORE/INMA (UCL) March 9, 2012 Yu. Nesterov () Huge-scale optimization problems 1/32March 9, 2012 1
Liege University: Francqui Chair 2011-2012 Lecture 3: Huge-scale optimization problems Yurii Nesterov, CORE/INMA (UCL) March 9, 2012 Yu. Nesterov () Huge-scale optimization problems 1/32March 9, 2012 1
Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing
 Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing 1 Zhong-Yuan Zhang, 2 Chris Ding, 3 Jie Tang *1, Corresponding Author School of Statistics,
Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing 1 Zhong-Yuan Zhang, 2 Chris Ding, 3 Jie Tang *1, Corresponding Author School of Statistics,
Linear Algebra Methods for Data Mining
 Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 PCA, NMF Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki Summary: PCA PCA is SVD
Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 PCA, NMF Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki Summary: PCA PCA is SVD
8.1 Concentration inequality for Gaussian random matrix (cont d)
") MGMT 69: Topics in High-dimensional Data Analysis Falll 26 Lecture 8: Spectral clustering and Laplacian matrices Lecturer: Jiaming Xu Scribe: Hyun-Ju Oh and Taotao He, October 4, 26 Outline Concentration
MGMT 69: Topics in High-dimensional Data Analysis Falll 26 Lecture 8: Spectral clustering and Laplacian matrices Lecturer: Jiaming Xu Scribe: Hyun-Ju Oh and Taotao He, October 4, 26 Outline Concentration
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Matrix Factorization & Latent Semantic Analysis Review. Yize Li, Lanbo Zhang
 Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec Stanford University Jure Leskovec, Stanford University http://cs224w.stanford.edu Task: Find coalitions in signed networks Incentives: European
CS224W: Social and Information Network Analysis Jure Leskovec Stanford University Jure Leskovec, Stanford University http://cs224w.stanford.edu Task: Find coalitions in signed networks Incentives: European
Markov Chains and Spectral Clustering
 Markov Chains and Spectral Clustering Ning Liu 1,2 and William J. Stewart 1,3 1 Department of Computer Science North Carolina State University, Raleigh, NC 27695-8206, USA. 2 nliu@ncsu.edu, 3 billy@ncsu.edu
Markov Chains and Spectral Clustering Ning Liu 1,2 and William J. Stewart 1,3 1 Department of Computer Science North Carolina State University, Raleigh, NC 27695-8206, USA. 2 nliu@ncsu.edu, 3 billy@ncsu.edu
Gradient Descent. Dr. Xiaowei Huang
 Gradient Descent Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Three machine learning algorithms: decision tree learning k-nn linear regression only optimization objectives are discussed,
Gradient Descent Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Three machine learning algorithms: decision tree learning k-nn linear regression only optimization objectives are discussed,
Lecture 9: Numerical Linear Algebra Primer (February 11st)
") 10-725/36-725: Convex Optimization Spring 2015 Lecture 9: Numerical Linear Algebra Primer (February 11st) Lecturer: Ryan Tibshirani Scribes: Avinash Siravuru, Guofan Wu, Maosheng Liu Note: LaTeX template
10-725/36-725: Convex Optimization Spring 2015 Lecture 9: Numerical Linear Algebra Primer (February 11st) Lecturer: Ryan Tibshirani Scribes: Avinash Siravuru, Guofan Wu, Maosheng Liu Note: LaTeX template
A hybrid reordered Arnoldi method to accelerate PageRank computations
 A hybrid reordered Arnoldi method to accelerate PageRank computations Danielle Parker Final Presentation Background Modeling the Web The Web The Graph (A) Ranks of Web pages v = v 1... Dominant Eigenvector
A hybrid reordered Arnoldi method to accelerate PageRank computations Danielle Parker Final Presentation Background Modeling the Web The Web The Graph (A) Ranks of Web pages v = v 1... Dominant Eigenvector
Matrix Factorization with Applications to Clustering Problems: Formulation, Algorithms and Performance
 Date: Mar. 3rd, 2017 Matrix Factorization with Applications to Clustering Problems: Formulation, Algorithms and Performance Presenter: Songtao Lu Department of Electrical and Computer Engineering Iowa
Date: Mar. 3rd, 2017 Matrix Factorization with Applications to Clustering Problems: Formulation, Algorithms and Performance Presenter: Songtao Lu Department of Electrical and Computer Engineering Iowa
Dictionary Learning Using Tensor Methods
 Dictionary Learning Using Tensor Methods Anima Anandkumar U.C. Irvine Joint work with Rong Ge, Majid Janzamin and Furong Huang. Feature learning as cornerstone of ML ML Practice Feature learning as cornerstone
Dictionary Learning Using Tensor Methods Anima Anandkumar U.C. Irvine Joint work with Rong Ge, Majid Janzamin and Furong Huang. Feature learning as cornerstone of ML ML Practice Feature learning as cornerstone
Non-negative matrix factorization with fixed row and column sums
 Available online at www.sciencedirect.com Linear Algebra and its Applications 9 (8) 5 www.elsevier.com/locate/laa Non-negative matrix factorization with fixed row and column sums Ngoc-Diep Ho, Paul Van
Available online at www.sciencedirect.com Linear Algebra and its Applications 9 (8) 5 www.elsevier.com/locate/laa Non-negative matrix factorization with fixed row and column sums Ngoc-Diep Ho, Paul Van
Fast Nonnegative Matrix Factorization with Rank-one ADMM
 Fast Nonnegative Matrix Factorization with Rank-one Dongjin Song, David A. Meyer, Martin Renqiang Min, Department of ECE, UCSD, La Jolla, CA, 9093-0409 dosong@ucsd.edu Department of Mathematics, UCSD,
Fast Nonnegative Matrix Factorization with Rank-one Dongjin Song, David A. Meyer, Martin Renqiang Min, Department of ECE, UCSD, La Jolla, CA, 9093-0409 dosong@ucsd.edu Department of Mathematics, UCSD,
Compressive Sensing, Low Rank models, and Low Rank Submatrix
 Compressive Sensing,, and Low Rank Submatrix NICTA Short Course 2012 yi.li@nicta.com.au http://users.cecs.anu.edu.au/~yili Sep 12, 2012 ver. 1.8 http://tinyurl.com/brl89pk Outline Introduction 1 Introduction
Compressive Sensing,, and Low Rank Submatrix NICTA Short Course 2012 yi.li@nicta.com.au http://users.cecs.anu.edu.au/~yili Sep 12, 2012 ver. 1.8 http://tinyurl.com/brl89pk Outline Introduction 1 Introduction
Fast Coordinate Descent methods for Non-Negative Matrix Factorization
 Fast Coordinate Descent methods for Non-Negative Matrix Factorization Inderjit S. Dhillon University of Texas at Austin SIAM Conference on Applied Linear Algebra Valencia, Spain June 19, 2012 Joint work
Fast Coordinate Descent methods for Non-Negative Matrix Factorization Inderjit S. Dhillon University of Texas at Austin SIAM Conference on Applied Linear Algebra Valencia, Spain June 19, 2012 Joint work
Abstract. LANDI, AMANDA KIM. The Nonnegative Matrix Factorization: Methods and Applications. (Under the direction of Kazufumi Ito.
 Abstract LANDI, AMANDA KIM. The Nonnegative Matrix Factorization: Methods and Applications. (Under the direction of Kazufumi Ito.) In today s world, data continues to grow in size and complexity. Thus,
Abstract LANDI, AMANDA KIM. The Nonnegative Matrix Factorization: Methods and Applications. (Under the direction of Kazufumi Ito.) In today s world, data continues to grow in size and complexity. Thus,
 https://goo.gl/kfxweg KYOTO UNIVERSITY Statistical Machine Learning Theory Sparsity Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT OF INTELLIGENCE SCIENCE AND TECHNOLOGY 1 KYOTO UNIVERSITY Topics:
https://goo.gl/kfxweg KYOTO UNIVERSITY Statistical Machine Learning Theory Sparsity Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT OF INTELLIGENCE SCIENCE AND TECHNOLOGY 1 KYOTO UNIVERSITY Topics:
c Springer, Reprinted with permission.
 Zhijian Yuan and Erkki Oja. A FastICA Algorithm for Non-negative Independent Component Analysis. In Puntonet, Carlos G.; Prieto, Alberto (Eds.), Proceedings of the Fifth International Symposium on Independent
Zhijian Yuan and Erkki Oja. A FastICA Algorithm for Non-negative Independent Component Analysis. In Puntonet, Carlos G.; Prieto, Alberto (Eds.), Proceedings of the Fifth International Symposium on Independent
Factor Analysis (FA) Non-negative Matrix Factorization (NMF) CSE Artificial Intelligence Grad Project Dr. Debasis Mitra
 Non-negative Matrix Factorization (NMF) CSE Artificial Intelligence Grad Project Dr. Debasis Mitra") Factor Analysis (FA) Non-negative Matrix Factorization (NMF) CSE 5290 - Artificial Intelligence Grad Project Dr. Debasis Mitra Group 6 Taher Patanwala Zubin Kadva Factor Analysis (FA) 1. Introduction Factor
Factor Analysis (FA) Non-negative Matrix Factorization (NMF) CSE 5290 - Artificial Intelligence Grad Project Dr. Debasis Mitra Group 6 Taher Patanwala Zubin Kadva Factor Analysis (FA) 1. Introduction Factor
Using Matrix Decompositions in Formal Concept Analysis
 Using Matrix Decompositions in Formal Concept Analysis Vaclav Snasel 1, Petr Gajdos 1, Hussam M. Dahwa Abdulla 1, Martin Polovincak 1 1 Dept. of Computer Science, Faculty of Electrical Engineering and
Using Matrix Decompositions in Formal Concept Analysis Vaclav Snasel 1, Petr Gajdos 1, Hussam M. Dahwa Abdulla 1, Martin Polovincak 1 1 Dept. of Computer Science, Faculty of Electrical Engineering and
Link Analysis. Leonid E. Zhukov
 Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
Lecture: Local Spectral Methods (3 of 4) 20 An optimization perspective on local spectral methods
 20 An optimization perspective on local spectral methods") Stat260/CS294: Spectral Graph Methods Lecture 20-04/07/205 Lecture: Local Spectral Methods (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Stat260/CS294: Spectral Graph Methods Lecture 20-04/07/205 Lecture: Local Spectral Methods (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Algorithms and Applications for Approximate Nonnegative Matrix Factorization
 Algorithms and Applications for Approximate Nonnegative Matrix Factorization Michael W. Berry and Murray Browne Department of Computer Science, University of Tennessee, Knoxville, TN 37996-3450 Amy N.
Algorithms and Applications for Approximate Nonnegative Matrix Factorization Michael W. Berry and Murray Browne Department of Computer Science, University of Tennessee, Knoxville, TN 37996-3450 Amy N.
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Lecture 6 Positive Definite Matrices
 Linear Algebra Lecture 6 Positive Definite Matrices Prof. Chun-Hung Liu Dept. of Electrical and Computer Engineering National Chiao Tung University Spring 2017 2017/6/8 Lecture 6: Positive Definite Matrices
Linear Algebra Lecture 6 Positive Definite Matrices Prof. Chun-Hung Liu Dept. of Electrical and Computer Engineering National Chiao Tung University Spring 2017 2017/6/8 Lecture 6: Positive Definite Matrices
EE613 Machine Learning for Engineers. Kernel methods Support Vector Machines. jean-marc odobez 2015
 EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
Nonnegative matrix factorization for interactive topic modeling and document clustering
 Nonnegative matrix factorization for interactive topic modeling and document clustering Da Kuang and Jaegul Choo and Haesun Park Abstract Nonnegative matrix factorization (NMF) approximates a nonnegative
Nonnegative matrix factorization for interactive topic modeling and document clustering Da Kuang and Jaegul Choo and Haesun Park Abstract Nonnegative matrix factorization (NMF) approximates a nonnegative
Eigenvalue Problems Computation and Applications
 Eigenvalue ProblemsComputation and Applications p. 1/36 Eigenvalue Problems Computation and Applications Che-Rung Lee cherung@gmail.com National Tsing Hua University Eigenvalue ProblemsComputation and
Eigenvalue ProblemsComputation and Applications p. 1/36 Eigenvalue Problems Computation and Applications Che-Rung Lee cherung@gmail.com National Tsing Hua University Eigenvalue ProblemsComputation and
Block Coordinate Descent for Regularized Multi-convex Optimization
 Block Coordinate Descent for Regularized Multi-convex Optimization Yangyang Xu and Wotao Yin CAAM Department, Rice University February 15, 2013 Multi-convex optimization Model definition Applications Outline
Block Coordinate Descent for Regularized Multi-convex Optimization Yangyang Xu and Wotao Yin CAAM Department, Rice University February 15, 2013 Multi-convex optimization Model definition Applications Outline
Descent methods for Nonnegative Matrix Factorization
 Descent methods for Nonnegative Matrix Factorization Ngoc-Diep Ho, Paul Van Dooren and Vincent D. Blondel CESAME, Université catholique de Louvain, Av. Georges Lemaître 4, B-1348 Louvain-la-Neuve, Belgium.
Descent methods for Nonnegative Matrix Factorization Ngoc-Diep Ho, Paul Van Dooren and Vincent D. Blondel CESAME, Université catholique de Louvain, Av. Georges Lemaître 4, B-1348 Louvain-la-Neuve, Belgium.
Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering
 Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering Shuyang Ling Courant Institute of Mathematical Sciences, NYU Aug 13, 2018 Joint
Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering Shuyang Ling Courant Institute of Mathematical Sciences, NYU Aug 13, 2018 Joint
DATA MINING LECTURE 13. Link Analysis Ranking PageRank -- Random walks HITS
 DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
Data Exploration and Unsupervised Learning with Clustering
 Data Exploration and Unsupervised Learning with Clustering Paul F Rodriguez,PhD San Diego Supercomputer Center Predictive Analytic Center of Excellence Clustering Idea Given a set of data can we find a
Data Exploration and Unsupervised Learning with Clustering Paul F Rodriguez,PhD San Diego Supercomputer Center Predictive Analytic Center of Excellence Clustering Idea Given a set of data can we find a
Rank and Rating Aggregation. Amy Langville Mathematics Department College of Charleston
 Rank and Rating Aggregation Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/6/2008 Collaborators Carl Meyer, N. C. State University College of Charleston (current and former
Rank and Rating Aggregation Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/6/2008 Collaborators Carl Meyer, N. C. State University College of Charleston (current and former
CME342 Parallel Methods in Numerical Analysis. Matrix Computation: Iterative Methods II. Sparse Matrix-vector Multiplication.
 CME342 Parallel Methods in Numerical Analysis Matrix Computation: Iterative Methods II Outline: CG & its parallelization. Sparse Matrix-vector Multiplication. 1 Basic iterative methods: Ax = b r = b Ax
CME342 Parallel Methods in Numerical Analysis Matrix Computation: Iterative Methods II Outline: CG & its parallelization. Sparse Matrix-vector Multiplication. 1 Basic iterative methods: Ax = b r = b Ax
arxiv: v3 [cs.lg] 18 Mar 2013
![arxiv: v3 [cs.lg] 18 Mar 2013](/thumbs/72/67390553.jpg "arxiv: v3 [cs.lg] 18 Mar 2013") Hierarchical Data Representation Model - Multi-layer NMF arxiv:1301.6316v3 [cs.lg] 18 Mar 2013 Hyun Ah Song Department of Electrical Engineering KAIST Daejeon, 305-701 hyunahsong@kaist.ac.kr Abstract Soo-Young
Hierarchical Data Representation Model - Multi-layer NMF arxiv:1301.6316v3 [cs.lg] 18 Mar 2013 Hyun Ah Song Department of Electrical Engineering KAIST Daejeon, 305-701 hyunahsong@kaist.ac.kr Abstract Soo-Young
Gradient Descent. Ryan Tibshirani Convex Optimization /36-725
 Gradient Descent Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: canonical convex programs Linear program (LP): takes the form min x subject to c T x Gx h Ax = b Quadratic program (QP): like
Gradient Descent Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: canonical convex programs Linear program (LP): takes the form min x subject to c T x Gx h Ax = b Quadratic program (QP): like
Single-channel source separation using non-negative matrix factorization
 Single-channel source separation using non-negative matrix factorization Mikkel N. Schmidt Technical University of Denmark mns@imm.dtu.dk www.mikkelschmidt.dk DTU Informatics Department of Informatics
Single-channel source separation using non-negative matrix factorization Mikkel N. Schmidt Technical University of Denmark mns@imm.dtu.dk www.mikkelschmidt.dk DTU Informatics Department of Informatics
On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering
 On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering Chris Ding, Xiaofeng He, Horst D. Simon Published on SDM 05 Hongchang Gao Outline NMF NMF Kmeans NMF Spectral Clustering NMF
On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering Chris Ding, Xiaofeng He, Horst D. Simon Published on SDM 05 Hongchang Gao Outline NMF NMF Kmeans NMF Spectral Clustering NMF
Lecture 14: SVD, Power method, and Planted Graph problems (+ eigenvalues of random matrices) Lecturer: Sanjeev Arora
 Lecturer: Sanjeev Arora") princeton univ. F 13 cos 521: Advanced Algorithm Design Lecture 14: SVD, Power method, and Planted Graph problems (+ eigenvalues of random matrices) Lecturer: Sanjeev Arora Scribe: Today we continue the
princeton univ. F 13 cos 521: Advanced Algorithm Design Lecture 14: SVD, Power method, and Planted Graph problems (+ eigenvalues of random matrices) Lecturer: Sanjeev Arora Scribe: Today we continue the
Performance Evaluation of the Matlab PCT for Parallel Implementations of Nonnegative Tensor Factorization
 Performance Evaluation of the Matlab PCT for Parallel Implementations of Nonnegative Tensor Factorization Tabitha Samuel, Master s Candidate Dr. Michael W. Berry, Major Professor Abstract: Increasingly
Performance Evaluation of the Matlab PCT for Parallel Implementations of Nonnegative Tensor Factorization Tabitha Samuel, Master s Candidate Dr. Michael W. Berry, Major Professor Abstract: Increasingly
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017
 COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering
 On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering Chris Ding Xiaofeng He Horst D. Simon Abstract Current nonnegative matrix factorization (NMF) deals with X = FG T type. We
On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering Chris Ding Xiaofeng He Horst D. Simon Abstract Current nonnegative matrix factorization (NMF) deals with X = FG T type. We
Proximal Newton Method. Zico Kolter (notes by Ryan Tibshirani) Convex Optimization
 Convex Optimization") Proximal Newton Method Zico Kolter (notes by Ryan Tibshirani) Convex Optimization 10-725 Consider the problem Last time: quasi-newton methods min x f(x) with f convex, twice differentiable, dom(f) = R
Proximal Newton Method Zico Kolter (notes by Ryan Tibshirani) Convex Optimization 10-725 Consider the problem Last time: quasi-newton methods min x f(x) with f convex, twice differentiable, dom(f) = R
Data Mining and Matrices
 Data Mining and Matrices 6 Non-Negative Matrix Factorization Rainer Gemulla, Pauli Miettinen May 23, 23 Non-Negative Datasets Some datasets are intrinsically non-negative: Counters (e.g., no. occurrences
Data Mining and Matrices 6 Non-Negative Matrix Factorization Rainer Gemulla, Pauli Miettinen May 23, 23 Non-Negative Datasets Some datasets are intrinsically non-negative: Counters (e.g., no. occurrences
Matrices, Vector Spaces, and Information Retrieval
 Matrices, Vector Spaces, and Information Authors: M. W. Berry and Z. Drmac and E. R. Jessup SIAM 1999: Society for Industrial and Applied Mathematics Speaker: Mattia Parigiani 1 Introduction Large volumes
Matrices, Vector Spaces, and Information Authors: M. W. Berry and Z. Drmac and E. R. Jessup SIAM 1999: Society for Industrial and Applied Mathematics Speaker: Mattia Parigiani 1 Introduction Large volumes
Additional Exercises for Introduction to Nonlinear Optimization Amir Beck March 16, 2017
 Additional Exercises for Introduction to Nonlinear Optimization Amir Beck March 16, 2017 Chapter 1 - Mathematical Preliminaries 1.1 Let S R n. (a) Suppose that T is an open set satisfying T S. Prove that
Additional Exercises for Introduction to Nonlinear Optimization Amir Beck March 16, 2017 Chapter 1 - Mathematical Preliminaries 1.1 Let S R n. (a) Suppose that T is an open set satisfying T S. Prove that
Solving linear systems (6 lectures)
") Chapter 2 Solving linear systems (6 lectures) 2.1 Solving linear systems: LU factorization (1 lectures) Reference: [Trefethen, Bau III] Lecture 20, 21 How do you solve Ax = b? (2.1.1) In numerical linear
Chapter 2 Solving linear systems (6 lectures) 2.1 Solving linear systems: LU factorization (1 lectures) Reference: [Trefethen, Bau III] Lecture 20, 21 How do you solve Ax = b? (2.1.1) In numerical linear
Krylov Subspace Methods to Calculate PageRank
 Krylov Subspace Methods to Calculate PageRank B. Vadala-Roth REU Final Presentation August 1st, 2013 How does Google Rank Web Pages? The Web The Graph (A) Ranks of Web pages v = v 1... Dominant Eigenvector
Krylov Subspace Methods to Calculate PageRank B. Vadala-Roth REU Final Presentation August 1st, 2013 How does Google Rank Web Pages? The Web The Graph (A) Ranks of Web pages v = v 1... Dominant Eigenvector
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Subgradient methods for huge-scale optimization problems
 Subgradient methods for huge-scale optimization problems Yurii Nesterov, CORE/INMA (UCL) May 24, 2012 (Edinburgh, Scotland) Yu. Nesterov Subgradient methods for huge-scale problems 1/24 Outline 1 Problems
Subgradient methods for huge-scale optimization problems Yurii Nesterov, CORE/INMA (UCL) May 24, 2012 (Edinburgh, Scotland) Yu. Nesterov Subgradient methods for huge-scale problems 1/24 Outline 1 Problems
EE 381V: Large Scale Optimization Fall Lecture 24 April 11
 EE 381V: Large Scale Optimization Fall 2012 Lecture 24 April 11 Lecturer: Caramanis & Sanghavi Scribe: Tao Huang 24.1 Review In past classes, we studied the problem of sparsity. Sparsity problem is that
EE 381V: Large Scale Optimization Fall 2012 Lecture 24 April 11 Lecturer: Caramanis & Sanghavi Scribe: Tao Huang 24.1 Review In past classes, we studied the problem of sparsity. Sparsity problem is that
Low Rank Matrix Completion Formulation and Algorithm
 1 2 Low Rank Matrix Completion and Algorithm Jian Zhang Department of Computer Science, ETH Zurich zhangjianthu@gmail.com March 25, 2014 Movie Rating 1 2 Critic A 5 5 Critic B 6 5 Jian 9 8 Kind Guy B 9
1 2 Low Rank Matrix Completion and Algorithm Jian Zhang Department of Computer Science, ETH Zurich zhangjianthu@gmail.com March 25, 2014 Movie Rating 1 2 Critic A 5 5 Critic B 6 5 Jian 9 8 Kind Guy B 9
Regularized NNLS Algorithms for Nonnegative Matrix Factorization with Application to Text Document Clustering
 Regularized NNLS Algorithms for Nonnegative Matrix Factorization with Application to Text Document Clustering Rafal Zdunek Abstract. Nonnegative Matrix Factorization (NMF) has recently received much attention
Regularized NNLS Algorithms for Nonnegative Matrix Factorization with Application to Text Document Clustering Rafal Zdunek Abstract. Nonnegative Matrix Factorization (NMF) has recently received much attention
A Nearly Sublinear Approximation to exp{p}e i for Large Sparse Matrices from Social Networks
 A Nearly Sublinear Approximation to exp{p}e i for Large Sparse Matrices from Social Networks Kyle Kloster and David F. Gleich Purdue University December 14, 2013 Supported by NSF CAREER 1149756-CCF Kyle
A Nearly Sublinear Approximation to exp{p}e i for Large Sparse Matrices from Social Networks Kyle Kloster and David F. Gleich Purdue University December 14, 2013 Supported by NSF CAREER 1149756-CCF Kyle
7 Principal Component Analysis
 7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
Spectral Graph Theory and its Applications. Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale Unviersity
 Spectral Graph Theory and its Applications Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale Unviersity Outline Adjacency matrix and Laplacian Intuition, spectral graph drawing
Spectral Graph Theory and its Applications Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale Unviersity Outline Adjacency matrix and Laplacian Intuition, spectral graph drawing
Behavioral Data Mining. Lecture 7 Linear and Logistic Regression
 Behavioral Data Mining Lecture 7 Linear and Logistic Regression Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips Linear Regression
Behavioral Data Mining Lecture 7 Linear and Logistic Regression Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips Linear Regression
The Rectified Gaussian Distribution
 The Rectified Gaussian Distribution N. D. Socci, D. D. Lee and H. S. Seung Bell Laboratories, Lucent Technologies Murray Hill, NJ 07974 {ndslddleelseung}~bell-labs.com Abstract A simple but powerful modification
The Rectified Gaussian Distribution N. D. Socci, D. D. Lee and H. S. Seung Bell Laboratories, Lucent Technologies Murray Hill, NJ 07974 {ndslddleelseung}~bell-labs.com Abstract A simple but powerful modification
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering
 Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
ENGG5781 Matrix Analysis and Computations Lecture 10: Non-Negative Matrix Factorization and Tensor Decomposition
 ENGG5781 Matrix Analysis and Computations Lecture 10: Non-Negative Matrix Factorization and Tensor Decomposition Wing-Kin (Ken) Ma 2017 2018 Term 2 Department of Electronic Engineering The Chinese University
ENGG5781 Matrix Analysis and Computations Lecture 10: Non-Negative Matrix Factorization and Tensor Decomposition Wing-Kin (Ken) Ma 2017 2018 Term 2 Department of Electronic Engineering The Chinese University
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 21: Sensitivity of Eigenvalues and Eigenvectors; Conjugate Gradient Method Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 21: Sensitivity of Eigenvalues and Eigenvectors; Conjugate Gradient Method Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis
Singular Value Decomposition
 Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Projected Gradient Methods for Non-negative Matrix Factorization
 Projected Gradient Methods for Non-negative Matrix Factorization Chih-Jen Lin Department of Computer Science National Taiwan University, Taipei 106, Taiwan cjlin@csie.ntu.edu.tw Abstract Non-negative matrix
Projected Gradient Methods for Non-negative Matrix Factorization Chih-Jen Lin Department of Computer Science National Taiwan University, Taipei 106, Taiwan cjlin@csie.ntu.edu.tw Abstract Non-negative matrix
LINEAR SYSTEMS (11) Intensive Computation
 Intensive Computation") LINEAR SYSTEMS () Intensive Computation 27-8 prof. Annalisa Massini Viviana Arrigoni EXACT METHODS:. GAUSSIAN ELIMINATION. 2. CHOLESKY DECOMPOSITION. ITERATIVE METHODS:. JACOBI. 2. GAUSS-SEIDEL 2 CHOLESKY
LINEAR SYSTEMS () Intensive Computation 27-8 prof. Annalisa Massini Viviana Arrigoni EXACT METHODS:. GAUSSIAN ELIMINATION. 2. CHOLESKY DECOMPOSITION. ITERATIVE METHODS:. JACOBI. 2. GAUSS-SEIDEL 2 CHOLESKY
Constrained Optimization
 1 / 22 Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University March 30, 2015 2 / 22 1. Equality constraints only 1.1 Reduced gradient 1.2 Lagrange
1 / 22 Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University March 30, 2015 2 / 22 1. Equality constraints only 1.1 Reduced gradient 1.2 Lagrange