Behavioral Data Mining. Lecture 7 Linear and Logistic Regression
|
|
|
- Claribel Copeland
- 6 years ago
- Views:
Transcription
1 Behavioral Data Mining Lecture 7 Linear and Logistic Regression
2 Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips
3 Linear Regression Predict a response variable Y from a vector of inputs X T ( X, X 2,..., X 1 p using a linear model: ˆ 0 Yˆ ˆ ) p 0 X j j 1 ˆ j is called the intercept or bias of the model. If we add a constant to every X, then the formula simplifies to: X 0 1 Yˆ p j 0 X ˆ j X j T ˆ
4 Least Squares The residual sum of squares (RSS) for N points is given by: RSS( ) or in matrix form (boldface for matrices/vectors, uppercase for matrices): RSS ( ) N i 1 ( y i x i ( y X ) T T ) 2 ( y X ) This is a quadratic function of, so its global minimum can be found by differentiating w.r.t. : X T ( y X ) 0 the solution satisfies X T X X T y
5 Solving Regression Problems This has a unique solution if ˆ ( X X T X) T 1 is non-singular, which is This is often true if N > p (more points than X dimensions), but there is no guarantee. On the other hand if p < N, the matrix is guaranteed to be singular, and we need to constrain the solution somehow. X X T y
6 Example Y X

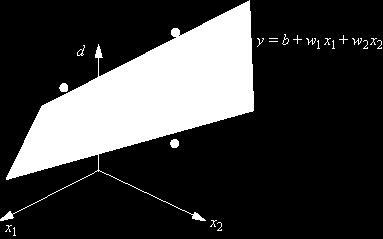
7 Example in 2D
8 Probabilistic Formulation We take X p to be a random variable, Y another real-valued random variable dependent on X. These variables have a joint distribution Pr(X,Y). In general, we make a prediction of Y using some function (so far a linear function) f(x). To choose the best model (f) we define a loss function L(Y, f(x)) and try to minimize the expected loss across the joint distribution Pr(X,Y). The squared-error loss is EPE(f) = E(Y-f(X)) 2 and we want to minimize: EPE( f ) E( Y f ( X 2 ))
9 Minimizing Expected Loss f ( x) E( Y X x) This is called the regression function. If we assume that f() has the form f(x) = x T, then the optimal solution is similar to the previous sample solution: ˆ T 1 [E( X X )] E( X Replacing expected values with the sums we computed before gives the same result. T y)
10 Other Loss Functions The L 1 loss is defined as L(Y, f(x)) = E Y-f(X) The solution is the conditional median: f(x) = median(y X=x) which is often a more robust estimator. The L 1 loss has a discontinuous derivative and no simple closed form. On the other hand, it can be formulated as a linear program. It is also practical to solve it using stochastic gradient methods that are less sensitive to gradient discontinuities.
11 Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips
12 Regularizers Ridge and Lasso In practice the regression solution may be singular: ˆ ( X X) T 1 This is likely for example, with dependent features (trigrams and bigrams). The system still has a solution, in fact a linear space of solutions. We can make the solution unique by imposing additional conditions, e.g. Ridge regression: minimize L 2 norm of. The solution is ˆ ( X The matrix in parentheses is generically non-singular. X X I) T y T 1 X T y
13 Regularizers Regularization can be viewed as adding a probability distribution on X (independent of Y). Minimizing the L 2 norm of X is equivalent to using a mean-zero Normal distribution for Pr(X). The regression problem can be formulated as a Bayesian estimation problem with Pr(X) as a prior. The effect is to make the estimate conservative smaller values for are favored, and more evidence is needed to produce large coefficients for. Can choose the regularizer weight ( ) by observing the empirical distribution of after solving many regression problems, or simply by optimizing it during cross-validation.
14 Lasso Lasso regression: minimize L 1 norm of. Typically generates a sparse model since the L 1 norm drives many coefficients to zero. The function to minimize is and its derivative is T ( y X ) ( y X ) X T ( y X ) sign( ) An efficient solution is Least-Angle Regression (LARS) due to Hastie (see reading). Another option is stochastic gradient.
15 Coefficient tests Regularization helps avoid over-fitting, but many coefficients will still carry noise values that will be different on different samples from the same population. To remove coefficients that are not almost surely non-zero, we can add a significance test. The statistic is: z j ˆ ˆ where j is the j th diagonal element of, and 2 is an estimate of the error variance (mean squared difference between Y and X ). j j ( X T X) 1
16 Significant Coefficients The z value has a t-distribution under the null hypothesis ( j = 0) but in most cases (due to many degrees-of-freedom) it is well-approximated as a normal distribution. Using the normal CDF, we can test whether a given coefficient is significantly different from zero, at say a significance of 0.05 The weakness of this approach is that regression coefficients depend on each other dependence may change as other features are added or removed. E.g. highly dependent features share their influence.
17 Stepwise Selection We can select features in greedy fashion, at each step adding the next feature that most improves the error. By maintaining a QR decomposition of X T X and pivoting on the next best feature, stepwise selection is asymptotically as efficient as the standard solution method.
18 Regression and n-grams Unlike naïve Bayes, regression does not suffer from bias when features are dependent. On the other hand, regression has insufficient degrees of freedom to model dependencies. e.g., page and turn(er) vs. page turner A unigram model distributes this influence between the two words, increasing the error when each occurs alone. The strongest dependencies between words occur over short distances. Adding n-grams allows the strongest dependent combinations to receive an independent weight.
19 An example Dataset: Reviews from amazon.com, about 1M book reviews. Includes text and numerical score from 1 to 5. Each review (X) is represented as a bag-of-words (or n-grams) with counts. The responses Y are the numerical scores. Each X is normalized by dividing by its sum. 10-fold cross-validation is used for training/testing. Final cross-validation RMSE = 0.84
20 'productive' 'not disappointed' 'covering' 'be disappointed' 'two stars' 'five stars' 'not recommend' 'no nonsense' 'calling' '5 stars' 'online' 'points out' 'at best' 'no better' 'track' 'only problem' Strongest negatives 'travels' 'comprehend' 'ashamed' 'worthwhile' Strongest positives 'negative reviews' 'not only' 'the negative' 'a try' 'stern' 'not agree' 'parody' 'of print' 'evaluate' 'adulthood' 'web' 'even better' 'exposes' 'literary' 'covers' 'instead of' 'secret' 'not put' 'foster' 'be it' 'not buy' 'i wasnt' 'frederick' 'to avoid'
21 Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips
22 Logistic Regression Goal: use linear classifier functions and derive smooth [0,1] probabilities from them, Or: extend naïve Bayes to model dependence between features as in linear regression. The following probability derives from X 1 p = n 1 + exp ( j=1 X j β j ) And satisfies logit p = ln n p 1 p = X j j=1 β j
23 Logistic Regression Logistic regression generalizes naïve Bayes in the following sense: For independent features X, the maximum-likelihood logistic coefficients are the naïve Bayes classifier coefficients. And the probability computed using the logistic function is the same as the Bayes posterior probability.
24 Logistic Regression The log likelihood for a model on N data vectors is: l β = N i=1 y i β T x i log (1 + exp β T x i ) Where we assume every x has a zeroth coefficient = 1. The derivative dl/d is dl dβ = N i=1 x i y ix i 1 + exp β T = x x i (y i p i ) i This is a non-linear optimization, but the function is convex. It can be solved with Newton s method if the model dimension is small. Otherwise, we can use stochastic gradient. N i=1
25 Regularization Just as with linear regression, Logistic regression can easily overfit data unless the model is regularized. Once again we can do this either with L 1 or L 2 measures on the coefficients. The gradients are then: L 2 : dl dβ = i=1 x i y i p i + 2λβ L 1 : dl dβ = i=1 x i y i p i + λ sign β As with linear regression, the L 1 norm tends to drive weak coefficients to zero. This helps both to reduce model variance, and also to limit model size (and improve evaluation speed).
26 Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips
27 Stochastic Gradient With behavioral data, many learning algorithms rely on gradient descent where the gradient is expressible as a sum over contributions from each user. e.g. the gradient of Logistic Regression is: dl dβ = N i=1 x i (y i p i ) where the sum is taken over N users. In classical gradient descent, we would take a step directly in the gradient direction dl/d.

28 Gradient Descent y = x 2-1/(2 ) dy/dx = -x For a well-behaved (locally quadratic) minimum in 1 dimension, gradient descent is an efficient optimization procedure. But things are normally much more difficult in high dimensions. Quadratic minima can be highly eccentric.
29 Gradient Descent
30 Newton s Method The Hessian matrix: d 2 l H ij = dβ i dβ j Together with the local gradient dl/d exactly characterizes a quadratic minimum. If these derivatives can be computed, the Newton step is β n+1 = β n dl 1 H dβ Which converges quadratically (quadratically decreasing error) to the minimum.
31 Newton s method
32 Newton s Method If the model has p coefficients, the Hessian has p 2. It will often be impractical to compute all these coefficients, either because of time or memory limits. But a typical quadratic minimum has a few strong dimensions and many weak ones. Finding these and optimizing along them can be fast and is the basis of many more efficient optimization algorithms.
33 Stochastic Gradient Its safer to take many small steps in gradient than few large steps. Stochastic gradient uses the approximate gradient from one or a few samples to incrementally update the model. back to Logistic Regression, we compute: dl dβ x i (y i p i ) i block where the sum is taken over a small block of values, and add a multiple of this gradient to at each step. These small steps avoid overshooting and oscillation near eccentric minima.
34 Convergence Rate Stochastic gradient is often orders of magnitude faster than traditional gradient methods, but may still be slow for highdimensional models. e.g. Linear regression on 1M Amazon reviews. model size = 20,000-30,000, stochastic gradient block size = 1000 RMSE Number of complete passes over the dataset (~ 1M local updates)
35 Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips
36 Improved Stochastic Gradient Based on incremental estimation of natural gradient, several methods have appeared recently. They infer second-order information from gradient steps and use this to approximate Newton steps.
37 Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips
38 Sparse Matrices The term counts X can be stored as an NxM sparse matrix, where N is the number of terms, M the number of docs. Sparse matrices contain only the non-zero values. Formats are: Coordinate: store all tuples of (row, col, value), usually sorted in lexicographic (row, col) or (col, row) order. CSC, Compressed Sparse Column: rows, values, compress(cols) CSR, Compressed Sparse Row: cols, values, compress(rows) CSC especially is a widely-used format in scientific computing, for sparse BLAS and Matlab. CSC supports efficient slicing by columns this is useful for permutations, blocking and cross-validation by docids.
 to the start and end+1 of the elements in each column.")
39 CSC format Elements are sorted in (col, row) order, i.e. column-major order. Value and row are the same as for coordinate format. Instead of storing every column value, CSC stores a matrix of M+1 column pointers (colptr) to the start and end+1 of the elements in each column. N row N colptr M+1
40 CSC format Because of memory grain and caching (next time), its much faster to traverse the columns of a CSC sparse matrix than rows for matrix operations. Additional techniques (autotuned blocking) may be used inside sparse matrix-vector multiply operators to improve performance you don t need to implement this, but you should use it when available. N row N colptr M+1
41 Other tips Use binary files + compression speeds up reads. Should be less than 10 secs for 0.5 GB. Use blocking for datasets that wont fit in main memory. Seek to start address of a block of data in the binary file no need to explicitly split the file. Data is available in binary form already tokenized, with dictionary, if you need it.
42 Summary Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips
Behavioral Data Mining. Lecture 3 Naïve Bayes Classifier and Generalized Linear Models
 Behavioral Data Mining Lecture 3 Naïve Bayes Classifier and Generalized Linear Models Outline Naïve Bayes Classifier Regularization in Linear Regression Generalized Linear Models Assignment Tips: Matrix
Behavioral Data Mining Lecture 3 Naïve Bayes Classifier and Generalized Linear Models Outline Naïve Bayes Classifier Regularization in Linear Regression Generalized Linear Models Assignment Tips: Matrix
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Linear Methods for Regression. Lijun Zhang
 Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Least Squares Regression
 CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
Machine Learning Linear Classification. Prof. Matteo Matteucci
 Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Introduction to Machine Learning. Regression. Computer Science, Tel-Aviv University,
 1 Introduction to Machine Learning Regression Computer Science, Tel-Aviv University, 2013-14 Classification Input: X Real valued, vectors over real. Discrete values (0,1,2,...) Other structures (e.g.,
1 Introduction to Machine Learning Regression Computer Science, Tel-Aviv University, 2013-14 Classification Input: X Real valued, vectors over real. Discrete values (0,1,2,...) Other structures (e.g.,
Least Squares Regression
 E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Machine Learning for OR & FE
 Machine Learning for OR & FE Regression II: Regularization and Shrinkage Methods Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com
Machine Learning for OR & FE Regression II: Regularization and Shrinkage Methods Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com
Linear Discrimination Functions
 Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari November 4, 2009 Outline Linear models Gradient descent Perceptron Minimum square error approach
Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari November 4, 2009 Outline Linear models Gradient descent Perceptron Minimum square error approach
CSC2515 Winter 2015 Introduction to Machine Learning. Lecture 2: Linear regression
 CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
CS242: Probabilistic Graphical Models Lecture 4A: MAP Estimation & Graph Structure Learning
 CS242: Probabilistic Graphical Models Lecture 4A: MAP Estimation & Graph Structure Learning Professor Erik Sudderth Brown University Computer Science October 4, 2016 Some figures and materials courtesy
CS242: Probabilistic Graphical Models Lecture 4A: MAP Estimation & Graph Structure Learning Professor Erik Sudderth Brown University Computer Science October 4, 2016 Some figures and materials courtesy
Final Overview. Introduction to ML. Marek Petrik 4/25/2017
 Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Linear Regression. CSL603 - Fall 2017 Narayanan C Krishnan
 Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Machine Learning for NLP
 Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
CPSC 540: Machine Learning
 CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
CPSC 540: Machine Learning First-Order Methods, L1-Regularization, Coordinate Descent Winter 2016 Some images from this lecture are taken from Google Image Search. Admin Room: We ll count final numbers
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
This model of the conditional expectation is linear in the parameters. A more practical and relaxed attitude towards linear regression is to say that
 Linear Regression For (X, Y ) a pair of random variables with values in R p R we assume that E(Y X) = β 0 + with β R p+1. p X j β j = (1, X T )β j=1 This model of the conditional expectation is linear
Linear Regression For (X, Y ) a pair of random variables with values in R p R we assume that E(Y X) = β 0 + with β R p+1. p X j β j = (1, X T )β j=1 This model of the conditional expectation is linear
Machine Learning for Biomedical Engineering. Enrico Grisan
 Machine Learning for Biomedical Engineering Enrico Grisan enrico.grisan@dei.unipd.it Curse of dimensionality Why are more features bad? Redundant features (useless or confounding) Hard to interpret and
Machine Learning for Biomedical Engineering Enrico Grisan enrico.grisan@dei.unipd.it Curse of dimensionality Why are more features bad? Redundant features (useless or confounding) Hard to interpret and
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d)
") COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d) Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless
COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d) Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless
Linear Models for Regression CS534
 Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Sparse Linear Models (10/7/13)
") STA56: Probabilistic machine learning Sparse Linear Models (0/7/) Lecturer: Barbara Engelhardt Scribes: Jiaji Huang, Xin Jiang, Albert Oh Sparsity Sparsity has been a hot topic in statistics and machine
STA56: Probabilistic machine learning Sparse Linear Models (0/7/) Lecturer: Barbara Engelhardt Scribes: Jiaji Huang, Xin Jiang, Albert Oh Sparsity Sparsity has been a hot topic in statistics and machine
Behavioral Data Mining. Lecture 2
 Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
COS513: FOUNDATIONS OF PROBABILISTIC MODELS LECTURE 10
 COS53: FOUNDATIONS OF PROBABILISTIC MODELS LECTURE 0 MELISSA CARROLL, LINJIE LUO. BIAS-VARIANCE TRADE-OFF (CONTINUED FROM LAST LECTURE) If V = (X n, Y n )} are observed data, the linear regression problem
COS53: FOUNDATIONS OF PROBABILISTIC MODELS LECTURE 0 MELISSA CARROLL, LINJIE LUO. BIAS-VARIANCE TRADE-OFF (CONTINUED FROM LAST LECTURE) If V = (X n, Y n )} are observed data, the linear regression problem
Homework 1 Solutions Probability, Maximum Likelihood Estimation (MLE), Bayes Rule, knn
, Bayes Rule, knn") Homework 1 Solutions Probability, Maximum Likelihood Estimation (MLE), Bayes Rule, knn CMU 10-701: Machine Learning (Fall 2016) https://piazza.com/class/is95mzbrvpn63d OUT: September 13th DUE: September
Homework 1 Solutions Probability, Maximum Likelihood Estimation (MLE), Bayes Rule, knn CMU 10-701: Machine Learning (Fall 2016) https://piazza.com/class/is95mzbrvpn63d OUT: September 13th DUE: September
CSE546 Machine Learning, Autumn 2016: Homework 1
 CSE546 Machine Learning, Autumn 2016: Homework 1 Due: Friday, October 14 th, 5pm 0 Policies Writing: Please submit your HW as a typed pdf document (not handwritten). It is encouraged you latex all your
CSE546 Machine Learning, Autumn 2016: Homework 1 Due: Friday, October 14 th, 5pm 0 Policies Writing: Please submit your HW as a typed pdf document (not handwritten). It is encouraged you latex all your
Lecture 3. Linear Regression II Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
CS598 Machine Learning in Computational Biology (Lecture 5: Matrix - part 2) Professor Jian Peng Teaching Assistant: Rongda Zhu
 Professor Jian Peng Teaching Assistant: Rongda Zhu") CS598 Machine Learning in Computational Biology (Lecture 5: Matrix - part 2) Professor Jian Peng Teaching Assistant: Rongda Zhu Feature engineering is hard 1. Extract informative features from domain knowledge
CS598 Machine Learning in Computational Biology (Lecture 5: Matrix - part 2) Professor Jian Peng Teaching Assistant: Rongda Zhu Feature engineering is hard 1. Extract informative features from domain knowledge
CSC2515 Assignment #2
 CSC2515 Assignment #2 Due: Nov.4, 2pm at the START of class Worth: 18% Late assignments not accepted. 1 Pseudo-Bayesian Linear Regression (3%) In this question you will dabble in Bayesian statistics and
CSC2515 Assignment #2 Due: Nov.4, 2pm at the START of class Worth: 18% Late assignments not accepted. 1 Pseudo-Bayesian Linear Regression (3%) In this question you will dabble in Bayesian statistics and
Outline. Supervised Learning. Hong Chang. Institute of Computing Technology, Chinese Academy of Sciences. Machine Learning Methods (Fall 2012)
") Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Bindel, Fall 2016 Matrix Computations (CS 6210) Notes for
 Notes for") 1 A cautionary tale Notes for 2016-10-05 You have been dropped on a desert island with a laptop with a magic battery of infinite life, a MATLAB license, and a complete lack of knowledge of basic geometry.
1 A cautionary tale Notes for 2016-10-05 You have been dropped on a desert island with a laptop with a magic battery of infinite life, a MATLAB license, and a complete lack of knowledge of basic geometry.
Lecture 4: Types of errors. Bayesian regression models. Logistic regression
 Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
The classifier. Theorem. where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know
 The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The classifier. Linear discriminant analysis (LDA) Example. Challenges for LDA
 Example. Challenges for LDA") The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
COMP 551 Applied Machine Learning Lecture 20: Gaussian processes
 COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
Data Mining 2018 Logistic Regression Text Classification
 Data Mining 2018 Logistic Regression Text Classification Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Data Mining 1 / 50 Two types of approaches to classification In (probabilistic)
Data Mining 2018 Logistic Regression Text Classification Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Data Mining 1 / 50 Two types of approaches to classification In (probabilistic)
Linear Models for Regression
 Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
CS-E3210 Machine Learning: Basic Principles
 CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
COMP 551 Applied Machine Learning Lecture 2: Linear regression
 COMP 551 Applied Machine Learning Lecture 2: Linear regression Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted for this
COMP 551 Applied Machine Learning Lecture 2: Linear regression Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted for this
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Overview. Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation
 Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Online Learning With Kernel
 CS 446 Machine Learning Fall 2016 SEP 27, 2016 Online Learning With Kernel Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes Overview Stochastic Gradient Descent Algorithms Regularization Algorithm Issues
CS 446 Machine Learning Fall 2016 SEP 27, 2016 Online Learning With Kernel Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes Overview Stochastic Gradient Descent Algorithms Regularization Algorithm Issues
Introduction to Machine Learning Midterm Exam Solutions
 10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
COMS 4771 Regression. Nakul Verma
 COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
II. Linear Models (pp.47-70)
") Notation: Means pencil-and-paper QUIZ Means coding QUIZ Agree or disagree: Regression can be always reduced to classification. Explain, either way! A certain classifier scores 98% on the training set,
Notation: Means pencil-and-paper QUIZ Means coding QUIZ Agree or disagree: Regression can be always reduced to classification. Explain, either way! A certain classifier scores 98% on the training set,
Algorithms for NLP. Language Modeling III. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
Modeling Data with Linear Combinations of Basis Functions. Read Chapter 3 in the text by Bishop
 Modeling Data with Linear Combinations of Basis Functions Read Chapter 3 in the text by Bishop A Type of Supervised Learning Problem We want to model data (x 1, t 1 ),..., (x N, t N ), where x i is a vector
Modeling Data with Linear Combinations of Basis Functions Read Chapter 3 in the text by Bishop A Type of Supervised Learning Problem We want to model data (x 1, t 1 ),..., (x N, t N ), where x i is a vector
Classification. Chapter Introduction. 6.2 The Bayes classifier
 Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Introduction to Logistic Regression
 Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Linear Regression Models. Based on Chapter 3 of Hastie, Tibshirani and Friedman
 Linear Regression Models Based on Chapter 3 of Hastie, ibshirani and Friedman Linear Regression Models Here the X s might be: p f ( X = " + " 0 j= 1 X j Raw predictor variables (continuous or coded-categorical
Linear Regression Models Based on Chapter 3 of Hastie, ibshirani and Friedman Linear Regression Models Here the X s might be: p f ( X = " + " 0 j= 1 X j Raw predictor variables (continuous or coded-categorical
Generalized Boosted Models: A guide to the gbm package
 Generalized Boosted Models: A guide to the gbm package Greg Ridgeway April 15, 2006 Boosting takes on various forms with different programs using different loss functions, different base models, and different
Generalized Boosted Models: A guide to the gbm package Greg Ridgeway April 15, 2006 Boosting takes on various forms with different programs using different loss functions, different base models, and different
Direct Learning: Linear Regression. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Direct Learning: Linear Regression Parametric learning We consider the core function in the prediction rule to be a parametric function. The most commonly used function is a linear function: squared loss:
Direct Learning: Linear Regression Parametric learning We consider the core function in the prediction rule to be a parametric function. The most commonly used function is a linear function: squared loss:
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task
 Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Lecture 14: Shrinkage
 Lecture 14: Shrinkage Reading: Section 6.2 STATS 202: Data mining and analysis October 27, 2017 1 / 19 Shrinkage methods The idea is to perform a linear regression, while regularizing or shrinking the
Lecture 14: Shrinkage Reading: Section 6.2 STATS 202: Data mining and analysis October 27, 2017 1 / 19 Shrinkage methods The idea is to perform a linear regression, while regularizing or shrinking the
Logistic Regression. William Cohen
 Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Data Analysis and Machine Learning Lecture 12: Multicollinearity, Bias-Variance Trade-off, Cross-validation and Shrinkage Methods.
 TheThalesians Itiseasyforphilosopherstoberichiftheychoose Data Analysis and Machine Learning Lecture 12: Multicollinearity, Bias-Variance Trade-off, Cross-validation and Shrinkage Methods Ivan Zhdankin
TheThalesians Itiseasyforphilosopherstoberichiftheychoose Data Analysis and Machine Learning Lecture 12: Multicollinearity, Bias-Variance Trade-off, Cross-validation and Shrinkage Methods Ivan Zhdankin
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Bayesian Learning. Tobias Scheffer, Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Machine Learning and Computational Statistics, Spring 2017 Homework 2: Lasso Regression
 Machine Learning and Computational Statistics, Spring 2017 Homework 2: Lasso Regression Due: Monday, February 13, 2017, at 10pm (Submit via Gradescope) Instructions: Your answers to the questions below,
Machine Learning and Computational Statistics, Spring 2017 Homework 2: Lasso Regression Due: Monday, February 13, 2017, at 10pm (Submit via Gradescope) Instructions: Your answers to the questions below,
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
GWAS IV: Bayesian linear (variance component) models
 models") GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
CS6375: Machine Learning Gautam Kunapuli. Support Vector Machines
 Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
A Survey of L 1. Regression. Céline Cunen, 20/10/2014. Vidaurre, Bielza and Larranaga (2013)
") A Survey of L 1 Regression Vidaurre, Bielza and Larranaga (2013) Céline Cunen, 20/10/2014 Outline of article 1.Introduction 2.The Lasso for Linear Regression a) Notation and Main Concepts b) Statistical
A Survey of L 1 Regression Vidaurre, Bielza and Larranaga (2013) Céline Cunen, 20/10/2014 Outline of article 1.Introduction 2.The Lasso for Linear Regression a) Notation and Main Concepts b) Statistical
Learning Task Grouping and Overlap in Multi-Task Learning
 Learning Task Grouping and Overlap in Multi-Task Learning Abhishek Kumar Hal Daumé III Department of Computer Science University of Mayland, College Park 20 May 2013 Proceedings of the 29 th International
Learning Task Grouping and Overlap in Multi-Task Learning Abhishek Kumar Hal Daumé III Department of Computer Science University of Mayland, College Park 20 May 2013 Proceedings of the 29 th International
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Andriy Mnih and Ruslan Salakhutdinov
 MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
Homework 4. Convex Optimization /36-725
 Homework 4 Convex Optimization 10-725/36-725 Due Friday November 4 at 5:30pm submitted to Christoph Dann in Gates 8013 (Remember to a submit separate writeup for each problem, with your name at the top)
Homework 4 Convex Optimization 10-725/36-725 Due Friday November 4 at 5:30pm submitted to Christoph Dann in Gates 8013 (Remember to a submit separate writeup for each problem, with your name at the top)
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning
 Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
DATA MINING AND MACHINE LEARNING. Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
Gradient Boosting (Continued)
") Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
An Introduction to Statistical and Probabilistic Linear Models
 An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
ECE521 lecture 4: 19 January Optimization, MLE, regularization
 ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
The connection of dropout and Bayesian statistics
 The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
Midterm exam CS 189/289, Fall 2015
 Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning
 SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
Linear Model Selection and Regularization
 Linear Model Selection and Regularization Recall the linear model Y = β 0 + β 1 X 1 + + β p X p + ɛ. In the lectures that follow, we consider some approaches for extending the linear model framework. In
Linear Model Selection and Regularization Recall the linear model Y = β 0 + β 1 X 1 + + β p X p + ɛ. In the lectures that follow, we consider some approaches for extending the linear model framework. In