Linear Discrimination Functions
|
|
|
- Rudolph Mills
- 5 years ago
- Views:
Transcription
1 Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari November 4, 2009
2 Outline Linear models Gradient descent Perceptron Minimum square error approach Linear and logistic regression
3 Linear Discriminant Functions I A linear discriminant function can be written as g(x) = w 1 x w d x d + w 0 = w t x + w 0 where w is the weight vector w 0 is the bias or threshold A 2-class linear classifier implements the decision rule: Decide ω 1 if g(x) > 0 and ω 2 if g(x) < 0

4 Linear Discriminant Functions II The equation g(x) = 0 defines the decision surface that separates points assigned to ω 1 from points assigned to ω 2. When g(x) is linear, this decision surface is a hyperplane (H).
5 Linear Discriminant Functions III H divides the feature space into 2 half spaces: R 1 for 1, and R 2 for 2 If x 1 and x 2 are both on the decision surface w t x 1 + w 0 = w t x 2 + w 0 w t ( x 1 x 2 ) = 0 w is normal to any vector lying in the hyperplane
6 Linear Discriminant Functions IV If we express x as w x = x p + r w where x p is the normal projection of x onto H, and r is the algebraic distance from x to the hyperplane Since g( x p ) = 0, we have g( x) = w t x + w 0 = r w i.e. r = g( x) w r is signed distance: r > 0 if x falls in R 1, r < 0 if x falls in R 2 Distance from the origin to the hyperplane is w 0 w

7 Linear Discriminant Functions V
8 Multi-category Case I 2 approaches to extend the LDF approach to the multi-category case: ω i / not ω i ω i / ω j Reduce the problem to c 1 two-class problems: Problem #i: Find the functions that separates points assigned to ω i from those not assigned to ω i Find the c(c 1)/2 linear discriminants, one for every pair of classes Both approaches can lead to regions in which the classification is undefined
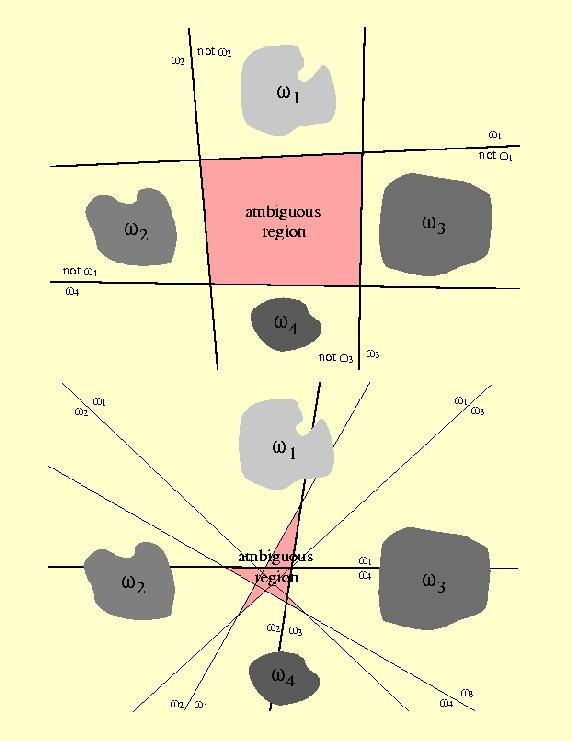
9 Multi-category Case II
10 Pairwise Classification Idea: build model for each pair of classes, using only training data from those classes Problem: solve c(c 1)/2 classification problems for c classes Turns out not to be a problem in many cases because training sets become small: Assume data evenly distributed, i.e. 2n/c per learning problem for n instances in total Suppose learning algorithm is linear in n Then runtime of pairwise classification is proportional to c(c 1) 2 2n c = (c 1)n
11 Linear Machine I Define c linear discriminant functions: g i ( x) = w t i x + w i0 i = 1,..., c Linear Machine classifier: x ω i if g i ( x) > g j ( x) for all i j In case of equal scores, the classification is undefined A LM divides the feature space into c decision regions, with g i ( x) the largest discriminant if x is in R i If R i and R j are contiguous, the boundary between them is a portion of the hyperplane H ij defined by: g i ( x) = g j ( x) or ( w i w j ) t x + (w i0 w j0 )
/2 3- and 5-class")
12 Linear Machine II It follows that w i w j is normal to H ij The signed distance from x to H ij is: g i ( x) g j ( x) w i w j There are c(c 1)/2 pairs of convex regions Not all regions are contiguous, and the total number of segments in the surfaces is often less than c(c 1)/2 3- and 5-class problems
13 Generalized LDF I The LDF is g( x) = w 0 + d i=1 w ix i Adding d(d + 1)/2 terms involving the products of pairs of components of x, quadratic discriminant function: g( x) = w 0 + d w i x i + i=1 d i=1 j=1 d w ij x i x j The separating surface defined by g( x) = 0 is a second-degree or hyperquadric surface Add more terms, such as w ijk x i x j x k, we obtain polynomial discriminant functions
14 Generalized LDF II The generalized LDF is defined g( x) = ˆd i=1 a i y i ( x) = a t y where: a is a ˆd-dimensional weight vector and y i ( x) are arbitrary functions of x The resulting discriminant function is not linear in x, but it is linear in y The functions y i ( x) map points in d-dimensional x-space to points in the ˆd-dimensional y-space

15 Generalized LDF III Example: Let the QDF be g( x) = a 1 + a 2 x + a 3 x 2 1 The 3-dimensional vector is then y = x x 2
16 2-class Linearly-Separable Case I g( x) = d w i x i = a t y i=0 where x 0 = 1 and y t = [1 x] = [1 x 1 x d ] is an augmented feature vector and a t = [w 0 w] = [w 0 w 1 w d ] is an augmented weight vector The hyperplane decision surface H defined a t y = 0 passes through the origin in y-space The distance from any point y to H is given by at y a = g( x) a Because a = (1 + w 2 ) this distance is less then the distance from x to H
17 2-class Linearly-Separable Case II Problem: find [w 0 w] = a Suppose that we have a set of n examples { y 1,..., y n } labeled ω 1 or ω 2 Look for a weight vector a that classifies all the examples correctly: a t y i > 0 and y i is labeled ω 1 or a t y i < 0 and y i is labeled ω 2 If a exists, the examples are linearly separable
18 2-class Linearly-Separable Case III Solutions Replacing all the examples labeled ω 2 by their negatives, one can look for a weight vector a such that a t y i > 0 for all the examples a a.k.a. separating vector or solution vector Each example y i places a constraint on the possible location of a solution vector a t y i = 0 defines a hyperplane through the origin having y i as a normal vector The solution vector (if it exists) must be on the positive side of every hyperplane Solution Region = intersection of the n half-spaces
 Seek a unit-length weight vector that maximizes the minimum distance from the examples to the hyperplane")
19 2-class Linearly-Separable Case IV Any vector that lies in the solution region is a solution vector: the solution vector (if it exists) is not unique Additional requirements to find a solution vector closer to the middle of the region (i.e. more likely to classify new examples correctly) Seek a unit-length weight vector that maximizes the minimum distance from the examples to the hyperplane

20 2-class Linearly-Separable Case V Seek the minimum-length weight vector satisfying a t y i b 0 The solution region shrinks by margin: b/ y i
21 Gradient Descent I Define a criterion function J( a) that is minimized when a is a solution vector: a t y i 0, i = 1,..., n Start with some arbitrary vector a(1) Compute the gradient vector J( a(1)) The next value a(2) is obtained by moving a distance from a(1) in the direction of steepest descent i.e. along the negative of the gradient In general, a(k + 1) is obtained from a(k) using a(k + 1) a(k) η(k) J( a(k)) where η(k) is the learning rate
22 Gradient Descent II
23 Gradient Descent & Delta Rule I To understand, consider a simpler linear machine (a.k.a. unit), where o = w 0 + w 1 x w n x n Let s learn w i s that minimize the squared error, i.e. J(w) = E[ w] where: E[ w] 1 ( t d o d ) 2 2 d D D is set of training examples x, t t is the target output value
24 Gradient Descent & Delta Rule II Gradient E[ w] [ E, E, E ] w 0 w 1 w n Training rule: i.e., w = η E[ w] w i = η E w i Note that η may be a constant
25 Gradient Descent & Delta Rule III E = 1 w i w i 2 = 1 2 = 1 2 d d (t d o d ) 2 d w i (t d o d ) 2 2(t d o d ) w i (t d o d ) = (t d o d ) (t d w x d ) w i d E w i = (t d o d )( x id ) d
26 Basic GRADIENT-DESCENT Algorithm GRADIENT-DESCENT(D, η) D: training set, η: learning rate (e.g..5) Initialize each w i to some small random value until the termination condition is met do Initialize each w i to zero. for each x, t D do Input the instance x to the unit and compute the output o for each w i do w i w i + η(t o)x i for each weight w i do w i w i + w i
27 Incremental (Stochastic) GRADIENT DESCENT I Approximation of the standard GRADIENT-DESCENT Batch GRADIENT-DESCENT: Do until satisfied 1 Compute the gradient E D [ w] 2 w w η E D [ w] Incremental GRADIENT-DESCENT: Do until satisfied For each training example d in D 1 Compute the gradient E d [ w] 2 w w η E d [ w]
28 Incremental (Stochastic) GRADIENT DESCENT II E D [ w] 1 (t d o d ) 2 2 d D E d [ w] 1 2 (t d o d ) 2 Training rule (delta rule): w i η(t o)x i similar to perceptron training rule, yet unthresholded convergence is only asymptotically guaranteed linear separability is no longer needed!
29 Standard vs. Stochastic GRADIENT-DESCENT Incremental-GD can approximate Batch-GD arbitrarily closely if η made small enough error summed over all examples before summing updated upon each example standard GD more costly per update step and can employ larger η stochastic GD may avoid falling in local minima because of using E d instead of E D
30 Newton s Algorithm J( a) J( a(k)) + J t ( a a(k)) ( a a(k)) t H( a a(k)) where H = 2 J a i a j is the Hessian matrix Choose a(k + 1) to minimize this function: a(k + 1) a(k) H 1 J( a) Greater improvement per step than GD but not applicable when H is singular Time complexity O(d 3 )
31 Perceptron I Assumption: data is linearly separable Hyperplane: d i=0 w ix i = 0 assuming that there is a constant attribute x 0 = 1 (bias) Algorithm for learning separating hyperplane: perceptron learning rule Classifier: If d i=0 w ix i > 0 then predict ω 1 (or +1), otherwise predict ω 2 (or 1)
32 Perceptron II Thresholded output { +1 if w0 + w o(x 1,..., x n ) = 1 x w d x d > 0 1 otherwise. { +1 if w x > 0 Simpler vector notation: o( x) = sgn( x) = 1 otherwise. Space of the hypotheses: { w w R n }
33 Decision Surface of a Perceptron Can represent some useful functions What weights represent g(x 1, x 2 ) = AND(x 1, x 2 )? But some functions not representable e.g., not linearly separable (XOR) Therefore, we ll want networks of these...
34 Perceptron Training Rule I Perceptron criterion function: J( a) = y Y ( a) ( a t y) where Y ( a) is the set of examples misclassified by a If no examples are misclassified, Y ( a) is empty and J( a) = 0 (i.e. a is a solution vector) J( a) 0, since a t y i 0 if y i is misclassified Geometrically, J( a) is proportional to the sum of the distances from the misclassified examples to the decision boundary Since J = y Y ( a) ( y) the update rule becomes a(k + 1) a(k) + η(k) y Y k ( a) where Y ( a) is the set of examples misclassified by a(k) y
35 Perceptron Training I Set all coefficient a i to zero do for each instance y in the training data if y is classified incorrectly by the perceptron if y belongs to ω 1 add it to a else subtract it from a until all instances in the training data are classified correctly return a
36 Perceptron Training II BATCH PERCEPTRON TRAINING Initialize a, η, θ, k 0 do k k + 1 a a + η(k) y Y k y until η(k) y Y k < θ return a Can prove it will converge If training data is linearly separable and η sufficiently small
37 Perceptron Training III Why does this work? Consider situation where an instance pertaining to the first class has been added: (a 0 + y 0 )y 0 + (a 1 + y 1 )y 1 + (a 2 + y 2 )y (a d + a d )y d This means output for a has increased by: y 0 y 0 + y 1 y 1 + y 2 y y d y d always positive, thus the hyperplane has moved into the correct direction (and output decreases for instances of other class)

38 Perceptron Training IV η = 1 and a(1) = 0. Sequence of misclassified instances: y 1 + y 2 + y 3, y 2, y 3, y 1, y 3 stop
39 Perceptron Simplification FIXED-INCREMENT SINGLE-EXAMPLE PERCEPTRON input: { y (k) } n k=1 training examples begin initialize a, k = 0 do k (k + 1) mod n if y (k) is misclassified by the model based on a then a a + y (k) until all examples properly classified return a end
40 Generalizations I VARIABLE-INCREMENT PERCEPTRON WITH MARGIN begin initialize a, θ, margin b, η, k 0 do k (k + 1) mod n if a t y (k) b then a a + y (k) until a t y (k) > b for all k return a end
41 Generalizations II BATCH VARIABLE-INCREMENT PERCEPTRON begin initialize a, η, k 0 do k (k + 1) mod n Y k j 0 do j j + 1 if y j misclassified then Y k Y k {y j } until j = n a a + y Y k y until Y k = return a end
42 Comments Perceptron adjusts the parameters only when it encounters an error, i.e. a misclassified training example Correctly classified examples can be ignored The learning rate η can be chosen arbitrarily, it will only impact on the norm of the final a (and the corresponding magnitude of a 0 ) The final weight vector a is a linear combination of training points
43 Nonseparable Case The Perceptron is an error correcting procedure converges when the examples are linearly separable Even if a separating vector is found for the training examples, it does not follow that the resulting classifier will perform well on independent test data To ensure that the performance on training and test data will be similar, many training examples should be used. Sufficiently large training examples are almost certainly non linearly separable No weight vector can correctly classify every example in a nonseparable set The corrections may never cease if set is nonseparable
44 Learning rate If we choose η(k) 0 as k then performance can be acceptable on non-separable problems while preserving the ability to find a solution on separable problems η(k) can be considered as a function of recent performance, decreasing it as performance improves: e.g. η(k) η/k The rate at which η(k) approaches zero is important: Too slow: result will be sensitive to those examples that render the set non-separable Too fast: may converge prematurely with sub-optimal results
45 Linear Models: WINNOW Another mistake-driven algorithm for finding a separating hyperplane Assumes binary attributes (i.e. propositional variables) Main difference: multiplicative instead of additive updates Weights are multiplied by a parameter α > 1 (or its inverse) Another difference: user-specified threshold parameter θ Predict first class if w 0 + w 1 x 1 + w 2 x w k x k > θ
46 The Algorithm I WINNOW initialize a, α while some instances are misclassified for each instance y in the training data classify y using the current model a if the predicted class is incorrect if y belongs to the target class for each attribute y i = 1, multiply a i by α (if y i = 0, a i is left unchanged) otherwise for each attribute y i = 1, divide a i by α (if y i = 0, a i is left unchanged)
47 The Algorithm II WINNOW is very effective in homing in on relevant features (it is attribute efficient) Can also be used in an on-line setting in which new instances arrive continuously (like the perceptron algorithm)
48 Balanced WINNOW I WINNOW doesn t allow negative weights and this can be a drawback in some applications BALANCED WINNOW maintains two weight vectors, one for each class: a + and a Instance is classified as belonging to the first class (of two classes) if: (a + 0 a 0 )+(a+ 1 a 1 )y 1+(a + 2 a 2 )y 2+ +(a + k a k )y k > θ
49 Balanced WINNOW II BALANCED WINNOW while some instances are misclassified for each instance a in the training data classify a using the current weights if the predicted class is incorrect if a belongs to the first class for each attribute y i = 1, multiply a + i by α and divide a i by α (if y i = 0, leave a + i and a i unchanged) otherwise for each attribute y i = 1, multiply a i by α and divide a + i by α (if y i = 0, leave a + i and a i unchanged)
50 Minimum Squared Error Approach I Minimum Squared Error (MSE) It trades the ability to obtain a separating vector for good performance on both separable and non-separable problems Previously, we sought a weight vector a making all of the inner products a t y 0 In the MSE procedure, one tries to make a t y i = b i, where b i are some arbitrarily specified positive constants Using matrix notation: Y a = b If Y is nonsingular, then a = Y 1 b Unfortunately Y is not a square matrix, usually with more rows than columns When there are more equations than unknowns, a is overdetermined, and ordinarily no exact solution exists.
51 Minimum Squared Error Approach II We can seek a weight vector a that minimizes some function of an error vector e = Y a b Minimizing the squared length of the error vector is equivalent to minimizing the sum-of-squared-error criterion function J( a) = Y a b 2 = n ( a t y i b i ) 2 i=1 whose gradient is n J = 2 ( a t y i b i ) y i = 2Y t (Y a b) i=1 Setting the gradient equal to zero, the following necessary condition holds: Y t Y a = Y t b
52 Minimum Squared Error Approach III Y t Y is a square matrix which is often nonsingular. Therefore, solving for a: a = (Y t Y ) 1 Y t b = Y + b where Y + = (Y t Y ) 1 Y t is the pseudo-inverse of Y Y + can be written also as lim ɛ 0 (Y t Y + ɛi) 1 Y t and it can be shown that this limit always exists, hence a = Y + b the MSE solution to the problem Y a = b
53 WIDROW-HOFF procedure a.k.a. LMS I The criterion function J( a) = Y a b 2 could be minimized by a gradient descent procedure Advantages: Avoids the problems that arise when Y t Y is singular Avoids the need for working with large matrices Since J = 2Y t (Y a b) a simple update rule would be { a(1) arbitrary a(k + 1) = a(k) + η(k)(y a b) or, if we consider the examples sequentially { a(1) arbitrary a(k + 1) = a(k) + η(k) [ b k a(k) t y(k) ] y(k)
54 WIDROW-HOFF procedure a.k.a. LMS II LMS({ y i } n i=1 ) input { y i } n i=1 : training examples begin Initialize a, b, θ, η( ), k 0 do k k + 1 mod n a a + η(k)(b k a(k) t y(k)) y(k) until η(k)(b k a(k) t y(k)) y(k) < θ return a end
55 Summary Perceptron training rule guaranteed to succeed if Training examples are linearly separable Sufficiently small learning rate η Linear unit training rule uses gradient descent Guaranteed to converge to hypothesis with MSE Given sufficiently small learning rate η Even when training data contains noise Even when training data not separable by H
56 Linear Regression Standard technique for numeric prediction Outcome is linear combination of attributes: x = w 0 + w 1 x 1 + w 2 x w d x d Weights are calculated from the training data standard math algorithms w Predicted value for first training instance x (1) w 0 + w 1 x (1) 1 + w 2 x (1) w d x (1) d = assuming extended vectors with x 0 = 1 d j=0 w j x (1) j
57 Probabilistic Classification Multiresponse Linear Regression (MLR) Any regression technique can be used for classification Training: perform a regression for each class g i linear compute each linear expression for each class, setting the output to 1 for training instances that belong to the class and 0 for those that don t Prediction: predict class corresponding to model with largest output value (membership value)
58 Logistic Regression I MLR drawbacks 1 membership values are not proper probabilities they can fall outside [0, 1] 2 least squares regression assumes that: the errors are not only statistically independent, but are also normally distributed with the same standard deviation Logit transformation does not suffer from these problems Builds a linear model for a transformed target variable Assume we have two classes
59 Logistic Regression II Logistic regression replaces the target Pr(1 x) that cannot be approximated well using a linear function with this target ( ) Pr(1 x) log 1 Pr(1 x) Transformation maps [0, 1] to (, + )
60 Logistic Regression III logit tranformation function
61 Example: Logistic Regression Model Resulting model: Pr(1 y) = 1/ ( 1 + e (a 0+a 1 y 1 +a 2 y 2 + +a d y d ) ) Example: Model with a 0 = 0.5 and a 1 = 1: Parameters induced from data using maximum likelihood
62 Maximum Likelihood Aim: maximize probability of training data with respect to the parameters Can use logarithms of probabilities and maximize log-likelihood of model and MSE: n i=1 ( 1 x (i)) ( ) ( ) log 1 Pr(1 y (i) ) +x (i) log 1 Pr(1 y (i) ) where the x (i) s are the responses (either 0 or 1) Weights a i need to be chosen to maximize log-likelihood relatively simple method: iteratively re-weighted least squares
63 Credits R. Duda, P. Hart, D. Stork: Pattern Classification, Wiley T. M. Mitchell: Machine Learning, McGraw Hill I. Witten & E. Frank: Data Mining: Practical Machine Learning Tools and Techniques, Morgan Kaufmann
Machine Learning 2017
 Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
A vector from the origin to H, V could be expressed using:
 Linear Discriminant Function: the linear discriminant function: g(x) = w t x + ω 0 x is the point, w is the weight vector, and ω 0 is the bias (t is the transpose). Two Category Case: In the two category
Linear Discriminant Function: the linear discriminant function: g(x) = w t x + ω 0 x is the point, w is the weight vector, and ω 0 is the bias (t is the transpose). Two Category Case: In the two category
The Perceptron Algorithm 1
 CS 64: Machine Learning Spring 5 College of Computer and Information Science Northeastern University Lecture 5 March, 6 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu Introduction The Perceptron
CS 64: Machine Learning Spring 5 College of Computer and Information Science Northeastern University Lecture 5 March, 6 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu Introduction The Perceptron
The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt.
 1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers
 Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Linear Classification. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
SGN (4 cr) Chapter 5
 Chapter 5") SGN-41006 (4 cr) Chapter 5 Linear Discriminant Analysis Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology January 21, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
SGN-41006 (4 cr) Chapter 5 Linear Discriminant Analysis Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology January 21, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Learning Methods for Linear Detectors
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2011/2012 Lesson 20 27 April 2012 Contents Learning Methods for Linear Detectors Learning Linear Detectors...2
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2011/2012 Lesson 20 27 April 2012 Contents Learning Methods for Linear Detectors Learning Linear Detectors...2
Linear discriminant functions
 Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Linear Discriminant Functions
 Linear Discriminant Functions Linear discriminant functions and decision surfaces Definition It is a function that is a linear combination of the components of g() = t + 0 () here is the eight vector and
Linear Discriminant Functions Linear discriminant functions and decision surfaces Definition It is a function that is a linear combination of the components of g() = t + 0 () here is the eight vector and
Single layer NN. Neuron Model
 Single layer NN We consider the simple architecture consisting of just one neuron. Generalization to a single layer with more neurons as illustrated below is easy because: M M The output units are independent
Single layer NN We consider the simple architecture consisting of just one neuron. Generalization to a single layer with more neurons as illustrated below is easy because: M M The output units are independent
Linear models: the perceptron and closest centroid algorithms. D = {(x i,y i )} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.
} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.") Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
COMP 652: Machine Learning. Lecture 12. COMP Lecture 12 1 / 37
 COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
The Perceptron algorithm
 The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Computational Learning Theory
 09s1: COMP9417 Machine Learning and Data Mining Computational Learning Theory May 20, 2009 Acknowledgement: Material derived from slides for the book Machine Learning, Tom M. Mitchell, McGraw-Hill, 1997
09s1: COMP9417 Machine Learning and Data Mining Computational Learning Theory May 20, 2009 Acknowledgement: Material derived from slides for the book Machine Learning, Tom M. Mitchell, McGraw-Hill, 1997
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Least Mean Squares Regression. Machine Learning Fall 2018
 Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
Optimization and Gradient Descent
 Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Multilayer Perceptron = FeedForward Neural Network
 Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Linear Classifiers as Pattern Detectors
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2014/2015 Lesson 16 8 April 2015 Contents Linear Classifiers as Pattern Detectors Notation...2 Linear
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2014/2015 Lesson 16 8 April 2015 Contents Linear Classifiers as Pattern Detectors Notation...2 Linear
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
In the Name of God. Lecture 11: Single Layer Perceptrons
 1 In the Name of God Lecture 11: Single Layer Perceptrons Perceptron: architecture We consider the architecture: feed-forward NN with one layer It is sufficient to study single layer perceptrons with just
1 In the Name of God Lecture 11: Single Layer Perceptrons Perceptron: architecture We consider the architecture: feed-forward NN with one layer It is sufficient to study single layer perceptrons with just
Chapter 2 Single Layer Feedforward Networks
 Chapter 2 Single Layer Feedforward Networks By Rosenblatt (1962) Perceptrons For modeling visual perception (retina) A feedforward network of three layers of units: Sensory, Association, and Response Learning
Chapter 2 Single Layer Feedforward Networks By Rosenblatt (1962) Perceptrons For modeling visual perception (retina) A feedforward network of three layers of units: Sensory, Association, and Response Learning
Lecture 6. Notes on Linear Algebra. Perceptron
 Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Chapter ML:VI. VI. Neural Networks. Perceptron Learning Gradient Descent Multilayer Perceptron Radial Basis Functions
 Chapter ML:VI VI. Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-1 Neural Networks STEIN 2005-2018 The iological Model Simplified model of a neuron:
Chapter ML:VI VI. Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-1 Neural Networks STEIN 2005-2018 The iological Model Simplified model of a neuron:
Machine Learning Linear Models
 Machine Learning Linear Models Outline II - Linear Models 1. Linear Regression (a) Linear regression: History (b) Linear regression with Least Squares (c) Matrix representation and Normal Equation Method
Machine Learning Linear Models Outline II - Linear Models 1. Linear Regression (a) Linear regression: History (b) Linear regression with Least Squares (c) Matrix representation and Normal Equation Method
Artificial Neural Networks
 Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
11 More Regression; Newton s Method; ROC Curves
 More Regression; Newton s Method; ROC Curves 59 11 More Regression; Newton s Method; ROC Curves LEAST-SQUARES POLYNOMIAL REGRESSION Replace each X i with feature vector e.g. (X i ) = [X 2 i1 X i1 X i2
More Regression; Newton s Method; ROC Curves 59 11 More Regression; Newton s Method; ROC Curves LEAST-SQUARES POLYNOMIAL REGRESSION Replace each X i with feature vector e.g. (X i ) = [X 2 i1 X i1 X i2
Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data
 Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data DD2424 March 23, 2017 Binary classification problem given labelled training data Have labelled training examples? Given
Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data DD2424 March 23, 2017 Binary classification problem given labelled training data Have labelled training examples? Given
Pattern Recognition and Machine Learning. Perceptrons and Support Vector machines
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Least Mean Squares Regression
 Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
Input layer. Weight matrix [ ] Output layer
![Input layer. Weight matrix [ ] Output layer](/thumbs/94/121286844.jpg "Input layer. Weight matrix [ ] Output layer") MASSACHUSETTS INSTITUTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2003 Recitation 10, November 4 th & 5 th 2003 Learning by perceptrons
MASSACHUSETTS INSTITUTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2003 Recitation 10, November 4 th & 5 th 2003 Learning by perceptrons
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Perceptron (Theory) + Linear Regression
 + Linear Regression") 10601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron (Theory) Linear Regression Matt Gormley Lecture 6 Feb. 5, 2018 1 Q&A
10601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron (Theory) Linear Regression Matt Gormley Lecture 6 Feb. 5, 2018 1 Q&A
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
6.867 Machine learning
 6.867 Machine learning Mid-term eam October 8, 6 ( points) Your name and MIT ID: .5.5 y.5 y.5 a).5.5 b).5.5.5.5 y.5 y.5 c).5.5 d).5.5 Figure : Plots of linear regression results with different types of
6.867 Machine learning Mid-term eam October 8, 6 ( points) Your name and MIT ID: .5.5 y.5 y.5 a).5.5 b).5.5.5.5 y.5 y.5 c).5.5 d).5.5 Figure : Plots of linear regression results with different types of
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
More about the Perceptron
 More about the Perceptron CMSC 422 MARINE CARPUAT marine@cs.umd.edu Credit: figures by Piyush Rai and Hal Daume III Recap: Perceptron for binary classification Classifier = hyperplane that separates positive
More about the Perceptron CMSC 422 MARINE CARPUAT marine@cs.umd.edu Credit: figures by Piyush Rai and Hal Daume III Recap: Perceptron for binary classification Classifier = hyperplane that separates positive
NEURAL NETWORKS and PATTERN RECOGNITION
 Anna Bartkowiak NEURAL NETWORKS and PATTERN RECOGNITION Lecture notes Fall 2004 Institute of Computer Science, University of Wroc law CONTENTS 2 Contents 2 Bayesian Decision theory 5 2.1 Setting Decision
Anna Bartkowiak NEURAL NETWORKS and PATTERN RECOGNITION Lecture notes Fall 2004 Institute of Computer Science, University of Wroc law CONTENTS 2 Contents 2 Bayesian Decision theory 5 2.1 Setting Decision
1 Newton s Method. Suppose we want to solve: x R. At x = x, f (x) can be approximated by:
 can be approximated by:") Newton s Method Suppose we want to solve: (P:) min f (x) At x = x, f (x) can be approximated by: n x R. f (x) h(x) := f ( x)+ f ( x) T (x x)+ (x x) t H ( x)(x x), 2 which is the quadratic Taylor expansion
Newton s Method Suppose we want to solve: (P:) min f (x) At x = x, f (x) can be approximated by: n x R. f (x) h(x) := f ( x)+ f ( x) T (x x)+ (x x) t H ( x)(x x), 2 which is the quadratic Taylor expansion
Linear Regression. S. Sumitra
 Linear Regression S Sumitra Notations: x i : ith data point; x T : transpose of x; x ij : ith data point s jth attribute Let {(x 1, y 1 ), (x, y )(x N, y N )} be the given data, x i D and y i Y Here D
Linear Regression S Sumitra Notations: x i : ith data point; x T : transpose of x; x ij : ith data point s jth attribute Let {(x 1, y 1 ), (x, y )(x N, y N )} be the given data, x i D and y i Y Here D
Simple Neural Nets For Pattern Classification
 CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Preliminaries. Definition: The Euclidean dot product between two vectors is the expression. i=1
 90 8 80 7 70 6 60 0 8/7/ Preliminaries Preliminaries Linear models and the perceptron algorithm Chapters, T x + b < 0 T x + b > 0 Definition: The Euclidean dot product beteen to vectors is the expression
90 8 80 7 70 6 60 0 8/7/ Preliminaries Preliminaries Linear models and the perceptron algorithm Chapters, T x + b < 0 T x + b > 0 Definition: The Euclidean dot product beteen to vectors is the expression
Introduction to Signal Detection and Classification. Phani Chavali
 Introduction to Signal Detection and Classification Phani Chavali Outline Detection Problem Performance Measures Receiver Operating Characteristics (ROC) F-Test - Test Linear Discriminant Analysis (LDA)
Introduction to Signal Detection and Classification Phani Chavali Outline Detection Problem Performance Measures Receiver Operating Characteristics (ROC) F-Test - Test Linear Discriminant Analysis (LDA)
PMR5406 Redes Neurais e Lógica Fuzzy Aula 3 Single Layer Percetron
 PMR5406 Redes Neurais e Aula 3 Single Layer Percetron Baseado em: Neural Networks, Simon Haykin, Prentice-Hall, 2 nd edition Slides do curso por Elena Marchiori, Vrije Unviersity Architecture We consider
PMR5406 Redes Neurais e Aula 3 Single Layer Percetron Baseado em: Neural Networks, Simon Haykin, Prentice-Hall, 2 nd edition Slides do curso por Elena Marchiori, Vrije Unviersity Architecture We consider
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Machine Learning for NLP
 Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning (CS 567) Lecture 3
 Lecture 3") Machine Learning (CS 567) Lecture 3 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 3 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Midterm. Introduction to Machine Learning. CS 189 Spring Please do not open the exam before you are instructed to do so.
 CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Minimax risk bounds for linear threshold functions
 CS281B/Stat241B (Spring 2008) Statistical Learning Theory Lecture: 3 Minimax risk bounds for linear threshold functions Lecturer: Peter Bartlett Scribe: Hao Zhang 1 Review We assume that there is a probability
CS281B/Stat241B (Spring 2008) Statistical Learning Theory Lecture: 3 Minimax risk bounds for linear threshold functions Lecturer: Peter Bartlett Scribe: Hao Zhang 1 Review We assume that there is a probability
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
Multilayer Neural Networks
 Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Introduction to Machine Learning
 Introduction to Machine Learning Logistic Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Introduction to Machine Learning Logistic Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Logistic Regression. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Artificial Neural Networks
 0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011!
 Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x))
 e.g. s ij = diag(l i (x))") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
The Perceptron Algorithm
 The Perceptron Algorithm Greg Grudic Greg Grudic Machine Learning Questions? Greg Grudic Machine Learning 2 Binary Classification A binary classifier is a mapping from a set of d inputs to a single output
The Perceptron Algorithm Greg Grudic Greg Grudic Machine Learning Questions? Greg Grudic Machine Learning 2 Binary Classification A binary classifier is a mapping from a set of d inputs to a single output
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Support Vector Machines. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Support Vector Machines CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Linear Classifier Naive Bayes Assume each attribute is drawn from Gaussian distribution with the same variance Generative model:
Support Vector Machines CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Linear Classifier Naive Bayes Assume each attribute is drawn from Gaussian distribution with the same variance Generative model:
Mark Gales October y (x) x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.
 x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.") University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x