CS6375: Machine Learning Gautam Kunapuli. Support Vector Machines
|
|
|
- Samson Stanley
- 5 years ago
- Views:
Transcription

1 Gautam Kunapuli
2 Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this data set text across all documents in the corpus is represented as a bag (multiset) of its words captures the multiplicity/frequency of words and terms does not capture semantics, sentiment, grammar, or even word order vector space model, where each document is simply represented as a vector of word statistics such as counts more advanced statistics such as term-frequency/inverse document frequency (tf-idf) can be used corpus of documents document 1 document 2 document category sports politics politics document n sports 2
.")


3 SVM for Linearly Separable Data Problem: Find a linear classifier f x = w x + b such that sign f x = +1, when positive example sign f x = 1, when negative example w w w The data set is linearly separable, that is separable by a linear classifier (hyperplane). There exist many different classifiers! Which one is the best? Prefer hyperplanes that achieve maximum separation between the two data sets the separation between the two data sets achieved by a classifier is called the margin of the classifier Bias: select a classifier with the largest margin Linearly separability is a simplifying assumption we make in order to derive a maximum-margin model; it assumes that there is no noise in the data set, and hence, the resulting model does not require a loss function. This is not a realistic assumption for real-world data sets. 3
4 Maximizing the Margin of a Classifier distance of a point x to the hyperplane w x + α = 0 is w x + α w Problem: Find a linear classifier f x = w x + b with the largest margin such that sign f x = +1, when positive example sign f x = 1, when negative example Let the margin be defined by two (parallel) hyperplanes and. The margin ( ) of the classifier is the distance between the two hyperplanes that form the boundaries of the separation Without loss of generality, we can set and (why?) and the margin is distance of a point x to the hyperplane w x + β = 0 is w x + β w 4
5 Maximizing the Margin of a Classifier distance of a point x to the hyperplane w x + α = 0 is w x + α w Problem: Find a linear classifier f x = w x + b with the largest margin such that sign f x = +1, when positive example sign f x = 1, when negative example Problem Formulation Given a linearly-separable data set, learn a linear classifier such that all the training examples with lie above the margin, that is all the training examples with lie below the margin the margin is maximized distance of a point x to the hyperplane w x + β = 0 is w x + β w Note that max w min w min w min w 2 w w 2 w 2 2 w w 2 5
6 Hard-Margin Support Vector Machine Problem: Find a linear classifier f x = w x + b with the largest margin such that sign f x = +1, when positive example sign f x = 1, when negative example Constrained optimization problem w, This model is called the hard-margin SVM as it is rigid and does not allow flexibility for misclassifications by the model; only feasible when data set is linearly separable. Convex, quadratic minimization problem called the primal problem. Guaranteed to have a global minimum The problem is no longer unconstrained; need additional optimization tools to ensure feasibility of solutions (that solutions satisfy the constraints) Further properties of the formulation can be studied by deriving the Lagrangian and the dual problem 6
7 Hard-Margin SVM: Primal Problem Primal problem for hard-margin SVM w, for each constraint, which corresponds to each training example ( introduce new variables called dual variables or Lagrange multipliers, (the Lagrange multipliers will give us a mechanism to ensure feasibility, that is, ensure that the optimal solutions (w and b) indeed achieve linear separation of the two classes) ), we Lagrangian function for hard-margin SVM the Lagrangian function is a function of the primal variables ( and ) and the dual variables ( ); (the Lagrangian function converts a constrained optimization problem into an unconstrained optimization problem) If we can find a minimization of the Lagrangian function with the resulting solution will also be the solution to our original constrained problem. for each training example ( ), the following must hold for the optimal solution: (primal feasibility) (dual feasibility) (complementarity) 7
 These are the first-order optimality conditions. We can now eliminate the primal variables by substituting the optimality conditions into the Lagrangian.")
8 Hard-Margin SVM: First-Order Conditions Differentiate the Lagrangian with respect to the primal variables ( and ) the classifier is a linear combination of training examples ( ) These are the first-order optimality conditions. We can now eliminate the primal variables by substituting the optimality conditions into the Lagrangian. 8
 between each pair of training examples Why bother with the dual?")
 dual has fewer")
9 Hard-Margin SVM: Dual Problem the dual problem depends only on the dual variables ( ) and the inner products ( ) between each pair of training examples Why bother with the dual? both primal and dual problems are convex (quadratic) optimization problems. No duality gap (that is, the primal solution and dual solution will be exactly the same) dual has fewer constraints. Easier to solve dual solution is sparse. Easier to represent 9
10 Hard-Margin SVM: Support Vectors Recall that for each training example ( ), the following must hold for the final classifier (optimal solution) (primal feasibility) (dual feasibility) (complementarity) Case 3: and (degenerate case; not shown in figure) Case 1a: and (training example is not on the margin) Case 2: and (training example is on the margin) Case 1b: and (training example is not on the margin) 10
 are called the support vectors because they support the classifier.")
11 Hard-Margin SVM: Support Vectors Recall that for each training example ( ), the following must hold (primal feasibility) (dual feasibility) (complementarity) The first order condition that showed that the classifier was a linear combination of the training data: the training examples with (non-zero) are called the support vectors because they support the classifier. All other training examples have, and this makes the solution sparse. Only a small number of training examples will have and a large number of training examples will have. The optimal classifier is a sparse linear combination of the training examples, that is, the classifier depends only on the support vectors. This means that if we removed all other training examples except the support vectors, the solution would remain unchanged. 11
12 Soft-Margin SVM: Loss Function So far, assumed that the data is linearly separable, which is not valid in real-world applications. correctly classified points must not be penalized Problem: Find a linear classifier f x = w x + b with the largest margin such that sign f x = +1, when positive example sign f x = 1, when negative example and misclassifications are minimized. misclassified points inside the margin, or on the wrong side of the margin must be penalized Measure the misclassification error for each training example Penalize each misclassification by the size of the violation, using the hinge loss (contrast with the loss function of the Perceptron) correctly classified points must not be penalized 12

13 Soft-Margin SVM: Formulation Maximize the margin (contrast with the regularization function of Ridge Regression) misclassified points inside the margin, or on the wrong side of the margin must be penalized Optimization problem w, Problem: Find a linear classifier f x = w x + b with the largest margin such that sign f x = +1, when positive example sign f x = 1, when negative example and misclassifications are minimized. Regularization parameter (C > 0), sometimes also denoted λ, trades-off between margin maximization and loss minimization Penalize each misclassification by the size of the violation, using the hinge loss (contrast with the loss function of the Perceptron) 13

 and allows flexibility for")
14 Soft-Margin SVM: Primal Problem Problem: Find a linear classifier f x = w x + b with the largest margin such that sign f x = +1, when positive example sign f x = 1, when negative example and misclassifications are minimized. n misclassified points inside the margin, or on the wrong side of the margin must be penalized This model is called the soft-margin SVM as it is softens the classification constraints with slack variables (ξ ) and allows flexibility for misclassifications by the model 14
 are upperbounded by the regularization parameter (0 α C) hard-margin svm dual 15")
15 Soft-Margin SVM: Dual Problem misclassified points inside the margin, or on the wrong side of the margin must be penalized the only difference between the soft-margin and hardmargin SVM dual problems is that the Lagrange multipliers ( training example weights) are upperbounded by the regularization parameter (0 α C) hard-margin svm dual 15

16 Soft-Margin SVM: Dual Problem the regularization constant is set by the user; this parameter trades off between the regularization term (bias) and the loss term (variance) the dual solution depends only on the inner products of the training data; this is an important property that allows us to extend linear SVMs to learn nonlinear classification functions without explicit transformation n 16

17 Nonlinear SVM Classifiers transform data to a higher dimensional feature space Solution Approach 1 (Explicit Transformation) transform data to a higher dimensional feature space train linear SVM classifier in the high-dim. space transform high-dimensional linear classifier back to the original space to obtain a nonlinear classifier train a linear SVM classifier in the higher dimensional space using linear SVMs transform the learned high-dimensional linear classifier back to the original space to obtain a nonlinear classifier 17
18 Nonlinear SVM Classifiers transform data to a higher dimensional feature space Solution Approach 1 (Explicit Transformation) transform data to a higher dimensional feature space train linear SVM classifier in the high-dim. space transform high-dimensional linear classifier back to the original space to obtain a nonlinear classifier if we have training features, the size of the transformation grows very fast; explicit transformations can become very expensive 18

19 The Kernel Trick data in higher-dimensional space when learning a linear SVM, recall that the dual solution depends only on the inner products of the training data, so we only need to compute inner products in the higher-dimensional space: the function is an example of a kernel function the kernel function relates the inner-products in the original and transformed spaces; with a kernel, we can avoid explicit transformation 19
 between all")

20 Kernel SVMs n n n n n Solution Approach 2 (Kernel SVMs) instead of inner-products x x, compute the kernel function κ x, x = (x x ) between all pairs of training examples use the formulation and algorithm of the linear SVM directly, simply replacing the inner-product matrix with a kernel matrix n n n n 20


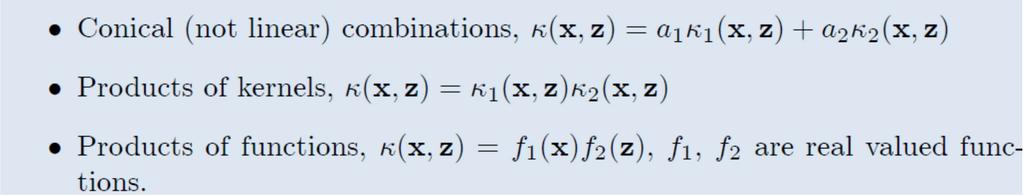
21 Examples of Kernel Functions 21


22 Some Popular Kernels polynomial kernel Gaussian kernel 22
 exp z exp x z σ using the Taylor expansion for, we have Gaussian kernels can represent")
 helps learn robust models; selection of kernel parameter ( ) is also")
23 Overfitting with Kernels observe that the Gaussian kernel can be written as exp x z 2σ = exp x + 2x z z 2σ = exp( x ) exp z exp x z σ using the Taylor expansion for, we have Gaussian kernels can represent polynomials of every degree, which means they can overfit, especially when features spaces are larger margin maximization (regularization) helps learn robust models; selection of kernel parameter ( ) is also critical 23
24 Regularization and Overfitting The regularization parameter, C, is chosen a priori, and defines the relative trade-off between norm (bias/complexity) and loss (error/variance) We want to find classifiers that minimize (regularization + C loss) Regularization introduces inductive bias over solutions controls the complexity of the solution imposes smoothness restriction on solutions As C increases, the effect of the regularization decreases and the SVM tends to overfit the data 24
25 The Effect of C on Classification C = small values of C (low complexity, high error) C = 0.01 C = 0.1 C = 1 C = 10 C = 100 large values of C (high complexity, low error) 25
26 SVM Modeling Choices 26
27 SVM Implementations Over The Years Earliest solution approaches: Quadratic Programming Solvers (CPLEX, LOQO, Matlab QP, SeDuMi) Decomposition methods: SVM chunking (Osuna et. al., 1997); SVMlight (Joachims, 1999) Sequential Minimization Optimization (Platt, 1999); implementation: LIBSVM (Chang et. al., 2000) Interior Point Methods (Munson and Ferris, 2006), Successive Over-relaxation (Mangasarian, 2004) Co-ordinate Descent Algorithms (Keerthi et. al., 2009), Bundle Methods (Teo et. al., 2010) Present: scikit-learn s Stochastic Gradient Descent can learn linear SVMs; also has a dedicated SVM package that can handle binary and multi-class classification, regression, one-class classification and kernels 27
28 28
Support Vector Machine (continued)
") Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machines: Maximum Margin Classifiers
 Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machines
 Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Indirect Rule Learning: Support Vector Machines. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
Pattern Recognition 2018 Support Vector Machines
 Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Kernel Machines. Pradeep Ravikumar Co-instructor: Manuela Veloso. Machine Learning
 Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Machine Learning. Lecture 6: Support Vector Machine. Feng Li.
 Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
SVMs, Duality and the Kernel Trick
 SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support Vector Machine
 Andrea Passerini passerini@disi.unitn.it Machine Learning Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
Andrea Passerini passerini@disi.unitn.it Machine Learning Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Support Vector Machines
 EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
Statistical Pattern Recognition
 Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
CSC 411 Lecture 17: Support Vector Machine
 CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
Support Vector Machines. Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Lecture 10: A brief introduction to Support Vector Machine
 Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
L5 Support Vector Classification
 L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Lecture Notes on Support Vector Machine
 Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Machine Learning And Applications: Supervised Learning-SVM
 Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Machine Learning. Support Vector Machines. Manfred Huber
 Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Topics we covered. Machine Learning. Statistics. Optimization. Systems! Basics of probability Tail bounds Density Estimation Exponential Families
 Midterm Review Topics we covered Machine Learning Optimization Basics of optimization Convexity Unconstrained: GD, SGD Constrained: Lagrange, KKT Duality Linear Methods Perceptrons Support Vector Machines
Midterm Review Topics we covered Machine Learning Optimization Basics of optimization Convexity Unconstrained: GD, SGD Constrained: Lagrange, KKT Duality Linear Methods Perceptrons Support Vector Machines
Support Vector Machines Explained
 December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
Support Vector Machines
 Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Support Vector Machines
 Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machine. Industrial AI Lab.
 Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
SVM May 2007 DOE-PI Dianne P. O Leary c 2007
 SVM May 2007 DOE-PI Dianne P. O Leary c 2007 1 Speeding the Training of Support Vector Machines and Solution of Quadratic Programs Dianne P. O Leary Computer Science Dept. and Institute for Advanced Computer
SVM May 2007 DOE-PI Dianne P. O Leary c 2007 1 Speeding the Training of Support Vector Machines and Solution of Quadratic Programs Dianne P. O Leary Computer Science Dept. and Institute for Advanced Computer
Linear, threshold units. Linear Discriminant Functions and Support Vector Machines. Biometrics CSE 190 Lecture 11. X i : inputs W i : weights
 Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
Stat542 (F11) Statistical Learning. First consider the scenario where the two classes of points are separable.
 Statistical Learning. First consider the scenario where the two classes of points are separable.") Linear SVM (separable case) First consider the scenario where the two classes of points are separable. It s desirable to have the width (called margin) between the two dashed lines to be large, i.e., have
Linear SVM (separable case) First consider the scenario where the two classes of points are separable. It s desirable to have the width (called margin) between the two dashed lines to be large, i.e., have
Support Vector Machines
 Support Vector Machines Ryan M. Rifkin Google, Inc. 2008 Plan Regularization derivation of SVMs Geometric derivation of SVMs Optimality, Duality and Large Scale SVMs The Regularization Setting (Again)
Support Vector Machines Ryan M. Rifkin Google, Inc. 2008 Plan Regularization derivation of SVMs Geometric derivation of SVMs Optimality, Duality and Large Scale SVMs The Regularization Setting (Again)
Lecture 10: Support Vector Machine and Large Margin Classifier
 Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
Support'Vector'Machines. Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan
 Support'Vector'Machines Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan kasthuri.kannan@nyumc.org Overview Support Vector Machines for Classification Linear Discrimination Nonlinear Discrimination
Support'Vector'Machines Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan kasthuri.kannan@nyumc.org Overview Support Vector Machines for Classification Linear Discrimination Nonlinear Discrimination
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie
 A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
Support Vector Machine & Its Applications
 Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
Kernelized Perceptron Support Vector Machines
 Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Convex Optimization and Support Vector Machine
 Convex Optimization and Support Vector Machine Problem 0. Consider a two-class classification problem. The training data is L n = {(x 1, t 1 ),..., (x n, t n )}, where each t i { 1, 1} and x i R p. We
Convex Optimization and Support Vector Machine Problem 0. Consider a two-class classification problem. The training data is L n = {(x 1, t 1 ),..., (x n, t n )}, where each t i { 1, 1} and x i R p. We
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Support Vector Machines for Classification and Regression. 1 Linearly Separable Data: Hard Margin SVMs
 E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
Support Vector Machine. Industrial AI Lab. Prof. Seungchul Lee
 Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Sequential Minimal Optimization (SMO)
") Data Science and Machine Intelligence Lab National Chiao Tung University May, 07 The SMO algorithm was proposed by John C. Platt in 998 and became the fastest quadratic programming optimization algorithm,
Data Science and Machine Intelligence Lab National Chiao Tung University May, 07 The SMO algorithm was proposed by John C. Platt in 998 and became the fastest quadratic programming optimization algorithm,
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
COMP 652: Machine Learning. Lecture 12. COMP Lecture 12 1 / 37
 COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Linear Classification and SVM. Dr. Xin Zhang
 Linear Classification and SVM Dr. Xin Zhang Email: eexinzhang@scut.edu.cn What is linear classification? Classification is intrinsically non-linear It puts non-identical things in the same class, so a
Linear Classification and SVM Dr. Xin Zhang Email: eexinzhang@scut.edu.cn What is linear classification? Classification is intrinsically non-linear It puts non-identical things in the same class, so a
Machine Learning and Data Mining. Support Vector Machines. Kalev Kask
 Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Review: Support vector machines. Machine learning techniques and image analysis
 Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
LECTURE 7 Support vector machines
 LECTURE 7 Support vector machines SVMs have been used in a multitude of applications and are one of the most popular machine learning algorithms. We will derive the SVM algorithm from two perspectives:
LECTURE 7 Support vector machines SVMs have been used in a multitude of applications and are one of the most popular machine learning algorithms. We will derive the SVM algorithm from two perspectives:
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support Vector Machines
 Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Support Vector Machines II. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Support Vector Machines II CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Outline Linear SVM hard margin Linear SVM soft margin Non-linear SVM Application Linear Support Vector Machine An optimization
Support Vector Machines II CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Outline Linear SVM hard margin Linear SVM soft margin Non-linear SVM Application Linear Support Vector Machine An optimization
Data Mining. Linear & nonlinear classifiers. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Support Vector Machines for Classification and Regression
 CIS 520: Machine Learning Oct 04, 207 Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may
CIS 520: Machine Learning Oct 04, 207 Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may
Support Vector Machines and Kernel Methods
 Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
Support Vector Machines, Kernel SVM
 Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support vector machines
 Support vector machines Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 SVM, kernel methods and multiclass 1/23 Outline 1 Constrained optimization, Lagrangian duality and KKT 2 Support
Support vector machines Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 SVM, kernel methods and multiclass 1/23 Outline 1 Constrained optimization, Lagrangian duality and KKT 2 Support
Introduction to SVM and RVM
 Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012
 CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Andreas Maletti Technische Universität Dresden Fakultät Informatik June 15, 2006 1 The Problem 2 The Basics 3 The Proposed Solution Learning by Machines Learning
Introduction to Support Vector Machines Andreas Maletti Technische Universität Dresden Fakultät Informatik June 15, 2006 1 The Problem 2 The Basics 3 The Proposed Solution Learning by Machines Learning
Lecture 18: Kernels Risk and Loss Support Vector Regression. Aykut Erdem December 2016 Hacettepe University
 Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Support Vector and Kernel Methods
 SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
Support Vector Machine
 Support Vector Machine Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Linear Support Vector Machine Kernelized SVM Kernels 2 From ERM to RLM Empirical Risk Minimization in the binary
Support Vector Machine Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Linear Support Vector Machine Kernelized SVM Kernels 2 From ERM to RLM Empirical Risk Minimization in the binary
Support Vector Machines and Speaker Verification
 1 Support Vector Machines and Speaker Verification David Cinciruk March 6, 2013 2 Table of Contents Review of Speaker Verification Introduction to Support Vector Machines Derivation of SVM Equations Soft
1 Support Vector Machines and Speaker Verification David Cinciruk March 6, 2013 2 Table of Contents Review of Speaker Verification Introduction to Support Vector Machines Derivation of SVM Equations Soft
10/05/2016. Computational Methods for Data Analysis. Massimo Poesio SUPPORT VECTOR MACHINES. Support Vector Machines Linear classifiers
 Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Support Vector Machine via Nonlinear Rescaling Method
 Manuscript Click here to download Manuscript: svm-nrm_3.tex Support Vector Machine via Nonlinear Rescaling Method Roman Polyak Department of SEOR and Department of Mathematical Sciences George Mason University
Manuscript Click here to download Manuscript: svm-nrm_3.tex Support Vector Machine via Nonlinear Rescaling Method Roman Polyak Department of SEOR and Department of Mathematical Sciences George Mason University
ICS-E4030 Kernel Methods in Machine Learning
 ICS-E4030 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 28. September, 2016 Juho Rousu 28. September, 2016 1 / 38 Convex optimization Convex optimisation This
ICS-E4030 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 28. September, 2016 Juho Rousu 28. September, 2016 1 / 38 Convex optimization Convex optimisation This
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels
 SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
SVM optimization and Kernel methods
 Announcements SVM optimization and Kernel methods w 4 is up. Due in a week. Kaggle is up 4/13/17 1 4/13/17 2 Outline Review SVM optimization Non-linear transformations in SVM Soft-margin SVM Goal: Find
Announcements SVM optimization and Kernel methods w 4 is up. Due in a week. Kaggle is up 4/13/17 1 4/13/17 2 Outline Review SVM optimization Non-linear transformations in SVM Soft-margin SVM Goal: Find
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
A GENERAL FORMULATION FOR SUPPORT VECTOR MACHINES. Wei Chu, S. Sathiya Keerthi, Chong Jin Ong
 A GENERAL FORMULATION FOR SUPPORT VECTOR MACHINES Wei Chu, S. Sathiya Keerthi, Chong Jin Ong Control Division, Department of Mechanical Engineering, National University of Singapore 0 Kent Ridge Crescent,
A GENERAL FORMULATION FOR SUPPORT VECTOR MACHINES Wei Chu, S. Sathiya Keerthi, Chong Jin Ong Control Division, Department of Mechanical Engineering, National University of Singapore 0 Kent Ridge Crescent,
Introduction to Machine Learning
 1, DATA11002 Introduction to Machine Learning Lecturer: Teemu Roos TAs: Ville Hyvönen and Janne Leppä-aho Department of Computer Science University of Helsinki (based in part on material by Patrik Hoyer
1, DATA11002 Introduction to Machine Learning Lecturer: Teemu Roos TAs: Ville Hyvönen and Janne Leppä-aho Department of Computer Science University of Helsinki (based in part on material by Patrik Hoyer
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
Statistical Methods for Data Mining
 Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Support Vector Machines Here we approach the two-class classification problem in a direct way: We try and find
Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Support Vector Machines Here we approach the two-class classification problem in a direct way: We try and find