Matrix Decomposition in Privacy-Preserving Data Mining JUN ZHANG DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF KENTUCKY
|
|
|
- Thomasina Preston
- 6 years ago
- Views:
Transcription

1 Matrix Decomposition in Privacy-Preserving Data Mining JUN ZHANG DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF KENTUCKY
2 OUTLINE Why We Need Matrix Decomposition SVD (Singular Value Decomposition) NMF (Nonnegative Matrix Factorization) Applications in Privacy-Preserving Data Mining


3 A TYPICAL TERM-BY-DOCUMENT MATRIX 1. All entries are nonnegative 2. Most entries are zeros 3. Large dimensions 4. Disorganized 5. Lots of noise

4 A SUPERMARKET TRANSCATION MATRIX 1. All entries are nonnegative 2. Most entries are zeros 3. Large dimensions 4. Disorganized 5. Lots of noise
5 WHY WE NEED MATRIX DECOMPOSITION? Compact representation of data in the form of matrix Original matrix == Factor matrix * * Factor matrix Original matrix: sparse, no ordered Factor matrix: compact, ordered. Easy to find hidden relationships in data, e.g., orthogonal, correlation, etc.
6 COMPACT REPRESENTATION OF ORIGINAL DATA Column clustering = x x Row clustering


7 REDUCE 2-D DATA TO 1-D DATA 1-D data 2-D data Reference:Faloutsos et. al., Large Graph Mining, KDD09
8 OUTLINE Why We Need Matrix Decomposition? SVD (Singular Value Decomposition) NMF (Nonnegative Matrix Factorization) Applications in Privacy-Preserving Data Mining
9 SINGULAR VALUE DECOMPOSITION(SVD) A [n x m] = U [n x r] r x r] (V [m x r] ) T A: n * m matrix (E.g., n documents*m words, or n pages*m links) U: n x r matrix (e.g., n documents, r topics) : r x r diagonal matrix (strength of each topics) (r is rank of matrix A), Sometimes the diagonal matrix is denoted as V: m x r matrix (e.g., m words, r topics) P1-9
10 SVD A = U V T -example:


11 Gene H. Golub (February 29, 1932 November 16, 2007) American Mathematician and Computer Scientist 11
12 SVD - PROPERTIES Theorem [Press,92]: Any numerical matrix A can be decomposed in the form of A = U V T, U, V: unique (*) U, V: column orthogonal (i.e., Any column vectors of U and V matrices have unit norm, and they are mutually orthogonal) U T U = I; V T V = I (I: identity matrix) : diagonal matrix, diagonal entries are nonnegative, and in descending order
13 SVD EXAMPLE A = U V T -example: Eng Med data infṛetrieval brain lung = x x
14 SVD EXAMPLE A = U V T -example: data infṛetrieval Eng Topics Med Topics Eng Med = brain lung x x
15 Faloutsos, Miller, Tsourakakis KDD'09 SVD EXAMPLE A = U V T -example: Document-to-Topics Similarity Matrix data infṛetrieval Eng Topics Med Topics Eng Med = brain lung x x P1-15
16 SVD EXAMPLE A = U V T -example: data infṛetrieval brain lung Strength of Eng Topics Eng Med = x x
17 SVD EXAMPLE A = U V T -example: Eng Med data infṛetrieval brain lung = x Word-to-Topics Similarity Matrix x
18 SVD PROPERTIES Documents, Words and Concepts /Topics : U: Document-to-Topic Similarity Matrix V: Word-to-Topic Similarity Matrix : Strength of Every Topics
19 SVD PROPERTIES Documents, Words and Topics : Q: If A is document-to-word similarity matrix, then what can be said about A T A? A: Q: How about AA T? A:
20 SVD PROPERTIES Documents, Words and Topics : Q: If A is document-to-word similarity matrix, what can be said about A T A? A: Word-to-word similarity matrix Q: How about AA T? A: Document-to-document similarity matrix
21 PROPERTIES OF SVD The columns of V are the eigenvectors of the covariance matrix of A T A
22 PROPERTIES OF SVD The columns of V are the eigenvectors of the covariance matrix of A T A

23 PROPERTIES OF SVD The columns of U are the eigenvectors of the inner-product matrix of AA T
24 PROPERTIES OF SVD The columns of U are the eigenvectors of the inner-product matrix of AA T


25 PROPERTIES OF SVD SVD: best Projection coordinates First eigenvector v1 Best :min sum of squares of projection errors


26 SVD DIMENSION REDUCTION Original matrix
27 SVD DIMENSION REDUCTION A = U V T 分解 = x x v
28 SVD REDUCTION A = U V T : = v 1 covariance of coordinate x x
29 SVD DIMENSION REDUCTION A = U V T : U :The value of the data projected onto the projection axis = x x
30 SVD DIMENSION REDUCTION Remove small singular values and the corresponding singular vectors (setting them to zero): = x x
31 SVD DIMENSION REDUCTION Why is it called dimension reduction Original matrix: rank = x x
32 SVD DIMENSION REDUCTION Why is it called dimension reduction? Modified data: rank = x 9.64 x
33 SVD = x x u 1 u v 1 v 2
34 SVD = x x u 1 u v 1 v 2 = 1 u 1 v T u 2 v T
35 SVD n m r topics = 1 u 1 v T u 2 v T n x 1 1 x m
36 SVD Data approximation/dimension reduction n m = 1 u 1 v T u 2 v T >= 2 >=...
37 SVD A k = U k V T k Or, m n = 1 u 1 v T u k 1 >= 2 >=... v T k
38 SVD A k = U k V T k n or, m Eckart-Young-Misky Theorem: A k is the best rank-k matrix that minimizes A k A F = 1 u 1 v T u k 1 >= 2 >=... v T k
39 TRUNCATED SVD
40 OUTLINE Why Do We Need Matrix Decomposition? SVD (Singular Value Decomposition) NMF (Nonnegative Matrix Factorization) Applications in Privacy-Preserving Data Mining
41 NONNEGATIVE MATRIX FACTORIZATION (NMF) Given a nonnegative matrix V, decompose it into the product or two (or more) nonnegative matrices W and H. V = n x m W = n x r H = r x m V WH (n+m)r < nm, original matrix is compressed/rank reduced
42 DIFFERENCE BETWEEN NMF AND SVD There is no negative value in NMF. NMF is additive combinations, and can be easily understood and linked to physical meanings SVD is unique, NMF is not unique. The nonuniqueness of NMF is both advantageous and disadvantageous Advantages: Better for privacy protection Disadvantages: How to find the optimal solution?
43 OBJECTIVE FUNCTIONS Quality of NMF:
 nonnegativity; 2)Elements of W and H do not")
44 FACTORIZATION:ITERATIVE UPDATES (OBJECTIVE FUNCTION 1) The following iterative updates guarantee 1) nonnegativity; 2)Elements of W and H do not increase
45 FACTORIZATION: ITERATIVE UPDATES (OBJECTIVE FUNCTION 2) The following iterative updates guarantee 1)Nonnegativity; 2)Elements of W and H doe not increase
46 INITIALIZATION OF NMF The final nonnegative matrices W and H depend on the initial choices of W and H. Different initial values will result in different NMF, even the iterative update rules are the same. (How to optimize the initial matrices, can use SVD approximations)
47 PROPERTIES OF NMF The final nonnegative matrices W and H depend on the initial choices of W and H. Differential initial values will result in different NMF, even the iterative update rules are the same. The update rules of NMF can only guarantee to converge to a local optimum. Why?
48 WHY ONLY LOCAL OPTIMUM The solution space of W is a convex set, that of H is also a convex set But the solution space of WH may not be a convex set There does not seem to have global optimum for an optimization problem on a non-convex set

49 NMF EXAMPLE
50 OUTLINE Why Do We Need Matrix Decomposition? SVD (Singular Value Decomposition) NMF (Nonnegative Matrix Factorization) Applications in Privacy-Preserving Data Mining

51 DATA VALUE PERTURBATION SVD or NMF Perturbation


52 Objective: Balance privacy preservation and data utility
53 NMF DATA PERTURBATION
54 EXPERIMENTAL RESULTS OF NMF DATA PERTURBATION Upper left: Original data (3 clusters). Upper right: NMF perturbed data (large perturbation, good clusters). Lower left: Additive noise with Gauss distribution. Lower right: Additive noise with normal distribution (small perturbation, bad clusters)
55 SUPPORT VECTOR MACHINE CLASSIFICATION Top: SVM with original data (98% correct rate) Middle: SVM with NMF perturbed data (98% correct rate) Bottom: SVM with normal distribution noise added data (54% correct rate)
56 SVD DATA PERTURBATION
57 EXPERIMENTAL RESULTS (COMPLEXITY)
58 DATA PATTERN HIDING Data pattern: Records A and B are in the same cluster In original data, if A and B are in the same cluster, then A B, otherwise A B In privacy-preserving data mining, sometimes, data owner does not want to disclose the same cluster relationship (or not same cluster relationship)
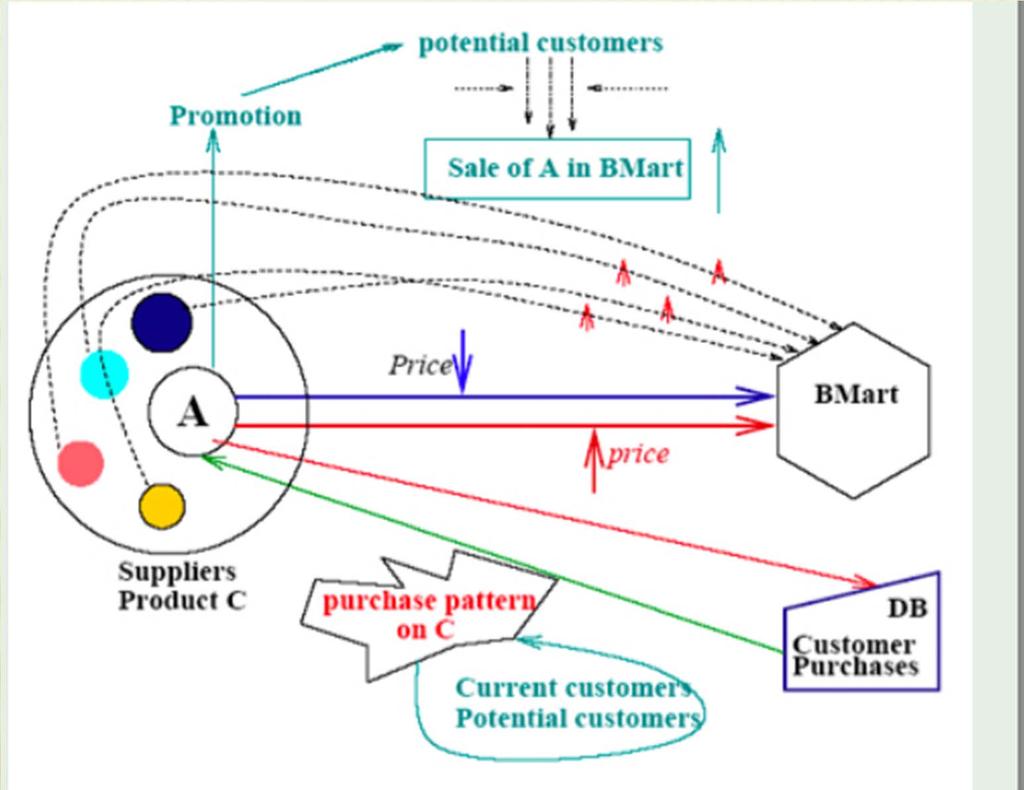
59 EXAMPLE
60 METHOD Perform MNF on A (n*m): A WH W(n*r):Cluster basis: Assume there are r clusters H(r*m):coefficients for clusters Record A i is in cluster j,if j=arg max H it, t=1,,m
61 METHOD Perform NMF on A(n*m): A WH W(n*r): Cluster basis, assume r clusters H(r*m):Cluster coefficients Record A i is in cluster j, if j=arg max H it, t=1,,m Assume that A i and A j are in different clusters in the original data, but A i and A t are in the same cluster, i.e., A i A j, A i A t.
62 CHANGE CLUSTER MEMBERSHIP Assume that A i and A j are in different clusters in the original data, but A i and A t are in the same cluster, i.e., A i A j, A i A t. If the data owner wants to hide these data patterns, what can we do?
63 CHANGE CLUSTER MEMBERSHIP Remember: Record A i is in cluster j, if j=arg max H it, t=1,,m Method: To hide A i A j, Adjust the locations of the maximum values of H i and H j, and make them in the same column Method: To hide A i A t, adjust the positions of the maximum values of H i and H t, so that they are in different columns
64 MAXIMUM AND MINIMUM EXCHANGE In original data, data x is in cluster j, we want to hide this information H x =(H x1,, H xi,, H xj,,h xm ) Obviously, H xj >= H xt, t<>j We assume that H xi <= H xt, t<>i
65 MAXIMUM AND MINIMUM EXCHANGE In original data, data x is in cluster j, we want to hide this information H x =(H x1,, H xi,, H xj,,h xm ) Obviously, H xj >= H xt, t<>j We assume that H xi <= H xt, t<>i The modified data is H * x=(h x1,, H xj,, H xi,,h xm )
66 INDEX EXCHANGE METHOD If we have records x and y, after NMF Assume
67 INDEX EXCHANGE METHOD If we have records x and y, after NMF Assume If x y, i.e., x and y are not in same cluster (IdX max IdY max ), and this information should be hidden
68 INDEX EXCHANGE METHOD If we have records x and y, after NMF Assume If x y, i.e., x and yare in same the cluster, (IdX max =IdY max ), this information should be hidden 1 t k, t IdX max
69 ALL EXCHANGE METHOD For records x and y Assume Modify H x and H y to be
70 EXAMPLE After NMF, we have H 50 H 80 (The largest coefficients and are in the 2 nd row) To hide H 50 H 80, modify H 80
71 PRACTICAL PROBLEMS The clustering from NMF is not accurate Membership exchange based on NMF may not be accurate However, we know the correct clustering results, we can modify data until the desired membership changes are achieved We may incorporate the clustering information into the NMF process
72 ANY QUESTION?
Jun Zhang Department of Computer Science University of Kentucky
 Jun Zhang Department of Computer Science University of Kentucky Background on Privacy Attacks General Data Perturbation Model SVD and Its Properties Data Privacy Attacks Experimental Results Summary 2
Jun Zhang Department of Computer Science University of Kentucky Background on Privacy Attacks General Data Perturbation Model SVD and Its Properties Data Privacy Attacks Experimental Results Summary 2
Dimension Reduction and Iterative Consensus Clustering
 Dimension Reduction and Iterative Consensus Clustering Southeastern Clustering and Ranking Workshop August 24, 2009 Dimension Reduction and Iterative 1 Document Clustering Geometry of the SVD Centered
Dimension Reduction and Iterative Consensus Clustering Southeastern Clustering and Ranking Workshop August 24, 2009 Dimension Reduction and Iterative 1 Document Clustering Geometry of the SVD Centered
Introduction to Data Mining
 Introduction to Data Mining Lecture #21: Dimensionality Reduction Seoul National University 1 In This Lecture Understand the motivation and applications of dimensionality reduction Learn the definition
Introduction to Data Mining Lecture #21: Dimensionality Reduction Seoul National University 1 In This Lecture Understand the motivation and applications of dimensionality reduction Learn the definition
Faloutsos, Tong ICDE, 2009
 Large Graph Mining: Patterns, Tools and Case Studies Christos Faloutsos Hanghang Tong CMU Copyright: Faloutsos, Tong (29) 2-1 Outline Part 1: Patterns Part 2: Matrix and Tensor Tools Part 3: Proximity
Large Graph Mining: Patterns, Tools and Case Studies Christos Faloutsos Hanghang Tong CMU Copyright: Faloutsos, Tong (29) 2-1 Outline Part 1: Patterns Part 2: Matrix and Tensor Tools Part 3: Proximity
The Singular Value Decomposition
 The Singular Value Decomposition Philippe B. Laval KSU Fall 2015 Philippe B. Laval (KSU) SVD Fall 2015 1 / 13 Review of Key Concepts We review some key definitions and results about matrices that will
The Singular Value Decomposition Philippe B. Laval KSU Fall 2015 Philippe B. Laval (KSU) SVD Fall 2015 1 / 13 Review of Key Concepts We review some key definitions and results about matrices that will
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Properties of Matrices and Operations on Matrices
 Properties of Matrices and Operations on Matrices A common data structure for statistical analysis is a rectangular array or matris. Rows represent individual observational units, or just observations,
Properties of Matrices and Operations on Matrices A common data structure for statistical analysis is a rectangular array or matris. Rows represent individual observational units, or just observations,
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Prof. Chris Clifton 6 September 2017 Material adapted from course created by Dr. Luo Si, now leading Alibaba research group 1 Vector Space Model Disadvantages:
CS47300: Web Information Search and Management Prof. Chris Clifton 6 September 2017 Material adapted from course created by Dr. Luo Si, now leading Alibaba research group 1 Vector Space Model Disadvantages:
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
Foundations of Computer Vision
 Foundations of Computer Vision Wesley. E. Snyder North Carolina State University Hairong Qi University of Tennessee, Knoxville Last Edited February 8, 2017 1 3.2. A BRIEF REVIEW OF LINEAR ALGEBRA Apply
Foundations of Computer Vision Wesley. E. Snyder North Carolina State University Hairong Qi University of Tennessee, Knoxville Last Edited February 8, 2017 1 3.2. A BRIEF REVIEW OF LINEAR ALGEBRA Apply
Parallel Singular Value Decomposition. Jiaxing Tan
 Parallel Singular Value Decomposition Jiaxing Tan Outline What is SVD? How to calculate SVD? How to parallelize SVD? Future Work What is SVD? Matrix Decomposition Eigen Decomposition A (non-zero) vector
Parallel Singular Value Decomposition Jiaxing Tan Outline What is SVD? How to calculate SVD? How to parallelize SVD? Future Work What is SVD? Matrix Decomposition Eigen Decomposition A (non-zero) vector
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Numerical Linear Algebra Background Cho-Jui Hsieh UC Davis May 15, 2018 Linear Algebra Background Vectors A vector has a direction and a magnitude
STA141C: Big Data & High Performance Statistical Computing Numerical Linear Algebra Background Cho-Jui Hsieh UC Davis May 15, 2018 Linear Algebra Background Vectors A vector has a direction and a magnitude
Jun Zhang Department of Computer Science University of Kentucky
 Application i of Wavelets in Privacy-preserving Data Mining Jun Zhang Department of Computer Science University of Kentucky Outline Privacy-preserving in Collaborative Data Analysis Advantages of Wavelets
Application i of Wavelets in Privacy-preserving Data Mining Jun Zhang Department of Computer Science University of Kentucky Outline Privacy-preserving in Collaborative Data Analysis Advantages of Wavelets
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 22 1 / 21 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 22 1 / 21 Overview
Dimensionality Reduction: PCA. Nicholas Ruozzi University of Texas at Dallas
 Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Singular Value Decomposition and Polar Form
 Chapter 12 Singular Value Decomposition and Polar Form 12.1 Singular Value Decomposition for Square Matrices Let f : E! E be any linear map, where E is a Euclidean space. In general, it may not be possible
Chapter 12 Singular Value Decomposition and Polar Form 12.1 Singular Value Decomposition for Square Matrices Let f : E! E be any linear map, where E is a Euclidean space. In general, it may not be possible
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Singular Value Decomposition and Polar Form
 Chapter 14 Singular Value Decomposition and Polar Form 14.1 Singular Value Decomposition for Square Matrices Let f : E! E be any linear map, where E is a Euclidean space. In general, it may not be possible
Chapter 14 Singular Value Decomposition and Polar Form 14.1 Singular Value Decomposition for Square Matrices Let f : E! E be any linear map, where E is a Euclidean space. In general, it may not be possible
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 5: Numerical Linear Algebra Cho-Jui Hsieh UC Davis April 20, 2017 Linear Algebra Background Vectors A vector has a direction and a magnitude
STA141C: Big Data & High Performance Statistical Computing Lecture 5: Numerical Linear Algebra Cho-Jui Hsieh UC Davis April 20, 2017 Linear Algebra Background Vectors A vector has a direction and a magnitude
Eigenvalues and diagonalization
 Eigenvalues and diagonalization Patrick Breheny November 15 Patrick Breheny BST 764: Applied Statistical Modeling 1/20 Introduction The next topic in our course, principal components analysis, revolves
Eigenvalues and diagonalization Patrick Breheny November 15 Patrick Breheny BST 764: Applied Statistical Modeling 1/20 Introduction The next topic in our course, principal components analysis, revolves
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017
 COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
Clustering. SVD and NMF
 Clustering with the SVD and NMF Amy Langville Mathematics Department College of Charleston Dagstuhl 2/14/2007 Outline Fielder Method Extended Fielder Method and SVD Clustering with SVD vs. NMF Demos with
Clustering with the SVD and NMF Amy Langville Mathematics Department College of Charleston Dagstuhl 2/14/2007 Outline Fielder Method Extended Fielder Method and SVD Clustering with SVD vs. NMF Demos with
Lecture 02 Linear Algebra Basics
 Introduction to Computational Data Analysis CX4240, 2019 Spring Lecture 02 Linear Algebra Basics Chao Zhang College of Computing Georgia Tech These slides are based on slides from Le Song and Andres Mendez-Vazquez.
Introduction to Computational Data Analysis CX4240, 2019 Spring Lecture 02 Linear Algebra Basics Chao Zhang College of Computing Georgia Tech These slides are based on slides from Le Song and Andres Mendez-Vazquez.
Preserving Privacy in Data Mining using Data Distortion Approach
 Preserving Privacy in Data Mining using Data Distortion Approach Mrs. Prachi Karandikar #, Prof. Sachin Deshpande * # M.E. Comp,VIT, Wadala, University of Mumbai * VIT Wadala,University of Mumbai 1. prachiv21@yahoo.co.in
Preserving Privacy in Data Mining using Data Distortion Approach Mrs. Prachi Karandikar #, Prof. Sachin Deshpande * # M.E. Comp,VIT, Wadala, University of Mumbai * VIT Wadala,University of Mumbai 1. prachiv21@yahoo.co.in
Computational Methods. Eigenvalues and Singular Values
 Computational Methods Eigenvalues and Singular Values Manfred Huber 2010 1 Eigenvalues and Singular Values Eigenvalues and singular values describe important aspects of transformations and of data relations
Computational Methods Eigenvalues and Singular Values Manfred Huber 2010 1 Eigenvalues and Singular Values Eigenvalues and singular values describe important aspects of transformations and of data relations
Preprocessing & dimensionality reduction
 Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Manning & Schuetze, FSNLP, (c)
") page 554 554 15 Topics in Information Retrieval co-occurrence Latent Semantic Indexing Term 1 Term 2 Term 3 Term 4 Query user interface Document 1 user interface HCI interaction Document 2 HCI interaction
page 554 554 15 Topics in Information Retrieval co-occurrence Latent Semantic Indexing Term 1 Term 2 Term 3 Term 4 Query user interface Document 1 user interface HCI interaction Document 2 HCI interaction
Summary of Week 9 B = then A A =
 Summary of Week 9 Finding the square root of a positive operator Last time we saw that positive operators have a unique positive square root We now briefly look at how one would go about calculating the
Summary of Week 9 Finding the square root of a positive operator Last time we saw that positive operators have a unique positive square root We now briefly look at how one would go about calculating the
Proposition 42. Let M be an m n matrix. Then (32) N (M M)=N (M) (33) R(MM )=R(M)
 N (M M)=N (M) (33) R(MM )=R(M)") RODICA D. COSTIN. Singular Value Decomposition.1. Rectangular matrices. For rectangular matrices M the notions of eigenvalue/vector cannot be defined. However, the products MM and/or M M (which are square,
RODICA D. COSTIN. Singular Value Decomposition.1. Rectangular matrices. For rectangular matrices M the notions of eigenvalue/vector cannot be defined. However, the products MM and/or M M (which are square,
Linear Algebra (Review) Volker Tresp 2017
 Volker Tresp 2017") Linear Algebra (Review) Volker Tresp 2017 1 Vectors k is a scalar (a number) c is a column vector. Thus in two dimensions, c = ( c1 c 2 ) (Advanced: More precisely, a vector is defined in a vector space.
Linear Algebra (Review) Volker Tresp 2017 1 Vectors k is a scalar (a number) c is a column vector. Thus in two dimensions, c = ( c1 c 2 ) (Advanced: More precisely, a vector is defined in a vector space.
Chapter XII: Data Pre and Post Processing
 Chapter XII: Data Pre and Post Processing Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 XII.1 4-1 Chapter XII: Data Pre and Post Processing 1. Data
Chapter XII: Data Pre and Post Processing Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 XII.1 4-1 Chapter XII: Data Pre and Post Processing 1. Data
Linear Algebra - Part II
 Linear Algebra - Part II Projection, Eigendecomposition, SVD (Adapted from Sargur Srihari s slides) Brief Review from Part 1 Symmetric Matrix: A = A T Orthogonal Matrix: A T A = AA T = I and A 1 = A T
Linear Algebra - Part II Projection, Eigendecomposition, SVD (Adapted from Sargur Srihari s slides) Brief Review from Part 1 Symmetric Matrix: A = A T Orthogonal Matrix: A T A = AA T = I and A 1 = A T
Parallel Numerical Algorithms
 Parallel Numerical Algorithms Chapter 6 Matrix Models Section 6.2 Low Rank Approximation Edgar Solomonik Department of Computer Science University of Illinois at Urbana-Champaign CS 554 / CSE 512 Edgar
Parallel Numerical Algorithms Chapter 6 Matrix Models Section 6.2 Low Rank Approximation Edgar Solomonik Department of Computer Science University of Illinois at Urbana-Champaign CS 554 / CSE 512 Edgar
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
Data Mining Lecture 4: Covariance, EVD, PCA & SVD
 Data Mining Lecture 4: Covariance, EVD, PCA & SVD Jo Houghton ECS Southampton February 25, 2019 1 / 28 Variance and Covariance - Expectation A random variable takes on different values due to chance The
Data Mining Lecture 4: Covariance, EVD, PCA & SVD Jo Houghton ECS Southampton February 25, 2019 1 / 28 Variance and Covariance - Expectation A random variable takes on different values due to chance The
Dimensionality Reduction
 Dimensionality Reduction Given N vectors in n dims, find the k most important axes to project them k is user defined (k < n) Applications: information retrieval & indexing identify the k most important
Dimensionality Reduction Given N vectors in n dims, find the k most important axes to project them k is user defined (k < n) Applications: information retrieval & indexing identify the k most important
1 Singular Value Decomposition and Principal Component
 Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
Tensor Analysis. Topics in Data Mining Fall Bruno Ribeiro
 Tensor Analysis Topics in Data Mining Fall 2015 Bruno Ribeiro Tensor Basics But First 2 Mining Matrices 3 Singular Value Decomposition (SVD) } X(i,j) = value of user i for property j i 2 j 5 X(Alice, cholesterol)
Tensor Analysis Topics in Data Mining Fall 2015 Bruno Ribeiro Tensor Basics But First 2 Mining Matrices 3 Singular Value Decomposition (SVD) } X(i,j) = value of user i for property j i 2 j 5 X(Alice, cholesterol)
CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization
 CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization Tim Roughgarden February 28, 2017 1 Preamble This lecture fulfills a promise made back in Lecture #1,
CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization Tim Roughgarden February 28, 2017 1 Preamble This lecture fulfills a promise made back in Lecture #1,
Image Registration Lecture 2: Vectors and Matrices
 Image Registration Lecture 2: Vectors and Matrices Prof. Charlene Tsai Lecture Overview Vectors Matrices Basics Orthogonal matrices Singular Value Decomposition (SVD) 2 1 Preliminary Comments Some of this
Image Registration Lecture 2: Vectors and Matrices Prof. Charlene Tsai Lecture Overview Vectors Matrices Basics Orthogonal matrices Singular Value Decomposition (SVD) 2 1 Preliminary Comments Some of this
Study Notes on Matrices & Determinants for GATE 2017
 Study Notes on Matrices & Determinants for GATE 2017 Matrices and Determinates are undoubtedly one of the most scoring and high yielding topics in GATE. At least 3-4 questions are always anticipated from
Study Notes on Matrices & Determinants for GATE 2017 Matrices and Determinates are undoubtedly one of the most scoring and high yielding topics in GATE. At least 3-4 questions are always anticipated from
Singular value decomposition
 Singular value decomposition The eigenvalue decomposition (EVD) for a square matrix A gives AU = UD. Let A be rectangular (m n, m > n). A singular value σ and corresponding pair of singular vectors u (m
Singular value decomposition The eigenvalue decomposition (EVD) for a square matrix A gives AU = UD. Let A be rectangular (m n, m > n). A singular value σ and corresponding pair of singular vectors u (m
The Singular Value Decomposition
 The Singular Value Decomposition An Important topic in NLA Radu Tiberiu Trîmbiţaş Babeş-Bolyai University February 23, 2009 Radu Tiberiu Trîmbiţaş ( Babeş-Bolyai University)The Singular Value Decomposition
The Singular Value Decomposition An Important topic in NLA Radu Tiberiu Trîmbiţaş Babeş-Bolyai University February 23, 2009 Radu Tiberiu Trîmbiţaş ( Babeş-Bolyai University)The Singular Value Decomposition
Structure in Data. A major objective in data analysis is to identify interesting features or structure in the data.
 Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Linear Algebra (Review) Volker Tresp 2018
 Volker Tresp 2018") Linear Algebra (Review) Volker Tresp 2018 1 Vectors k, M, N are scalars A one-dimensional array c is a column vector. Thus in two dimensions, ( ) c1 c = c 2 c i is the i-th component of c c T = (c 1, c
Linear Algebra (Review) Volker Tresp 2018 1 Vectors k, M, N are scalars A one-dimensional array c is a column vector. Thus in two dimensions, ( ) c1 c = c 2 c i is the i-th component of c c T = (c 1, c
Functional Analysis Review
 Outline 9.520: Statistical Learning Theory and Applications February 8, 2010 Outline 1 2 3 4 Vector Space Outline A vector space is a set V with binary operations +: V V V and : R V V such that for all
Outline 9.520: Statistical Learning Theory and Applications February 8, 2010 Outline 1 2 3 4 Vector Space Outline A vector space is a set V with binary operations +: V V V and : R V V such that for all
Singular Value Decomposition
 Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
CS 572: Information Retrieval
 CS 572: Information Retrieval Lecture 11: Topic Models Acknowledgments: Some slides were adapted from Chris Manning, and from Thomas Hoffman 1 Plan for next few weeks Project 1: done (submit by Friday).
CS 572: Information Retrieval Lecture 11: Topic Models Acknowledgments: Some slides were adapted from Chris Manning, and from Thomas Hoffman 1 Plan for next few weeks Project 1: done (submit by Friday).
Quick Introduction to Nonnegative Matrix Factorization
 Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
2.3. Clustering or vector quantization 57
 Multivariate Statistics non-negative matrix factorisation and sparse dictionary learning The PCA decomposition is by construction optimal solution to argmin A R n q,h R q p X AH 2 2 under constraint :
Multivariate Statistics non-negative matrix factorisation and sparse dictionary learning The PCA decomposition is by construction optimal solution to argmin A R n q,h R q p X AH 2 2 under constraint :
Singular Value Decomposition
 Singular Value Decomposition Motivatation The diagonalization theorem play a part in many interesting applications. Unfortunately not all matrices can be factored as A = PDP However a factorization A =
Singular Value Decomposition Motivatation The diagonalization theorem play a part in many interesting applications. Unfortunately not all matrices can be factored as A = PDP However a factorization A =
Manning & Schuetze, FSNLP (c) 1999,2000
 1999,2000") 558 15 Topics in Information Retrieval (15.10) y 4 3 2 1 0 0 1 2 3 4 5 6 7 8 Figure 15.7 An example of linear regression. The line y = 0.25x + 1 is the best least-squares fit for the four points (1,1),
558 15 Topics in Information Retrieval (15.10) y 4 3 2 1 0 0 1 2 3 4 5 6 7 8 Figure 15.7 An example of linear regression. The line y = 0.25x + 1 is the best least-squares fit for the four points (1,1),
Linear Algebra Methods for Data Mining
 Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 The Singular Value Decomposition (SVD) continued Linear Algebra Methods for Data Mining, Spring 2007, University
Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 The Singular Value Decomposition (SVD) continued Linear Algebra Methods for Data Mining, Spring 2007, University
Review problems for MA 54, Fall 2004.
 Review problems for MA 54, Fall 2004. Below are the review problems for the final. They are mostly homework problems, or very similar. If you are comfortable doing these problems, you should be fine on
Review problems for MA 54, Fall 2004. Below are the review problems for the final. They are mostly homework problems, or very similar. If you are comfortable doing these problems, you should be fine on
COMP 558 lecture 18 Nov. 15, 2010
 Least squares We have seen several least squares problems thus far, and we will see more in the upcoming lectures. For this reason it is good to have a more general picture of these problems and how to
Least squares We have seen several least squares problems thus far, and we will see more in the upcoming lectures. For this reason it is good to have a more general picture of these problems and how to
UNIT 6: The singular value decomposition.
 UNIT 6: The singular value decomposition. María Barbero Liñán Universidad Carlos III de Madrid Bachelor in Statistics and Business Mathematical methods II 2011-2012 A square matrix is symmetric if A T
UNIT 6: The singular value decomposition. María Barbero Liñán Universidad Carlos III de Madrid Bachelor in Statistics and Business Mathematical methods II 2011-2012 A square matrix is symmetric if A T
Deep Learning Book Notes Chapter 2: Linear Algebra
 Deep Learning Book Notes Chapter 2: Linear Algebra Compiled By: Abhinaba Bala, Dakshit Agrawal, Mohit Jain Section 2.1: Scalars, Vectors, Matrices and Tensors Scalar Single Number Lowercase names in italic
Deep Learning Book Notes Chapter 2: Linear Algebra Compiled By: Abhinaba Bala, Dakshit Agrawal, Mohit Jain Section 2.1: Scalars, Vectors, Matrices and Tensors Scalar Single Number Lowercase names in italic
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
CS598 Machine Learning in Computational Biology (Lecture 5: Matrix - part 2) Professor Jian Peng Teaching Assistant: Rongda Zhu
 Professor Jian Peng Teaching Assistant: Rongda Zhu") CS598 Machine Learning in Computational Biology (Lecture 5: Matrix - part 2) Professor Jian Peng Teaching Assistant: Rongda Zhu Feature engineering is hard 1. Extract informative features from domain knowledge
CS598 Machine Learning in Computational Biology (Lecture 5: Matrix - part 2) Professor Jian Peng Teaching Assistant: Rongda Zhu Feature engineering is hard 1. Extract informative features from domain knowledge
Chapter 3 Transformations
 Chapter 3 Transformations An Introduction to Optimization Spring, 2014 Wei-Ta Chu 1 Linear Transformations A function is called a linear transformation if 1. for every and 2. for every If we fix the bases
Chapter 3 Transformations An Introduction to Optimization Spring, 2014 Wei-Ta Chu 1 Linear Transformations A function is called a linear transformation if 1. for every and 2. for every If we fix the bases
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Linear Algebra. Session 12
 Linear Algebra. Session 12 Dr. Marco A Roque Sol 08/01/2017 Example 12.1 Find the constant function that is the least squares fit to the following data x 0 1 2 3 f(x) 1 0 1 2 Solution c = 1 c = 0 f (x)
Linear Algebra. Session 12 Dr. Marco A Roque Sol 08/01/2017 Example 12.1 Find the constant function that is the least squares fit to the following data x 0 1 2 3 f(x) 1 0 1 2 Solution c = 1 c = 0 f (x)
Linear Methods for Regression. Lijun Zhang
 Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Privacy-Preserving Data Mining
 CS 380S Privacy-Preserving Data Mining Vitaly Shmatikov slide 1 Reading Assignment Evfimievski, Gehrke, Srikant. Limiting Privacy Breaches in Privacy-Preserving Data Mining (PODS 2003). Blum, Dwork, McSherry,
CS 380S Privacy-Preserving Data Mining Vitaly Shmatikov slide 1 Reading Assignment Evfimievski, Gehrke, Srikant. Limiting Privacy Breaches in Privacy-Preserving Data Mining (PODS 2003). Blum, Dwork, McSherry,
The Singular Value Decomposition (SVD) and Principal Component Analysis (PCA)
 and Principal Component Analysis (PCA)") Chapter 5 The Singular Value Decomposition (SVD) and Principal Component Analysis (PCA) 5.1 Basics of SVD 5.1.1 Review of Key Concepts We review some key definitions and results about matrices that will
Chapter 5 The Singular Value Decomposition (SVD) and Principal Component Analysis (PCA) 5.1 Basics of SVD 5.1.1 Review of Key Concepts We review some key definitions and results about matrices that will
Matrix Factorization & Latent Semantic Analysis Review. Yize Li, Lanbo Zhang
 Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
MATH 350: Introduction to Computational Mathematics
 MATH 350: Introduction to Computational Mathematics Chapter V: Least Squares Problems Greg Fasshauer Department of Applied Mathematics Illinois Institute of Technology Spring 2011 fasshauer@iit.edu MATH
MATH 350: Introduction to Computational Mathematics Chapter V: Least Squares Problems Greg Fasshauer Department of Applied Mathematics Illinois Institute of Technology Spring 2011 fasshauer@iit.edu MATH
CS60021: Scalable Data Mining. Dimensionality Reduction
 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 CS60021: Scalable Data Mining Dimensionality Reduction Sourangshu Bhattacharya Assumption: Data lies on or near a
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 CS60021: Scalable Data Mining Dimensionality Reduction Sourangshu Bhattacharya Assumption: Data lies on or near a
IV. Matrix Approximation using Least-Squares
 IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
Principal Component Analysis and Singular Value Decomposition. Volker Tresp, Clemens Otte Summer 2014
 Principal Component Analysis and Singular Value Decomposition Volker Tresp, Clemens Otte Summer 2014 1 Motivation So far we always argued for a high-dimensional feature space Still, in some cases it makes
Principal Component Analysis and Singular Value Decomposition Volker Tresp, Clemens Otte Summer 2014 1 Motivation So far we always argued for a high-dimensional feature space Still, in some cases it makes
CS 143 Linear Algebra Review
 CS 143 Linear Algebra Review Stefan Roth September 29, 2003 Introductory Remarks This review does not aim at mathematical rigor very much, but instead at ease of understanding and conciseness. Please see
CS 143 Linear Algebra Review Stefan Roth September 29, 2003 Introductory Remarks This review does not aim at mathematical rigor very much, but instead at ease of understanding and conciseness. Please see
Machine Learning. B. Unsupervised Learning B.2 Dimensionality Reduction. Lars Schmidt-Thieme, Nicolas Schilling
 Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
7. Symmetric Matrices and Quadratic Forms
 Linear Algebra 7. Symmetric Matrices and Quadratic Forms CSIE NCU 1 7. Symmetric Matrices and Quadratic Forms 7.1 Diagonalization of symmetric matrices 2 7.2 Quadratic forms.. 9 7.4 The singular value
Linear Algebra 7. Symmetric Matrices and Quadratic Forms CSIE NCU 1 7. Symmetric Matrices and Quadratic Forms 7.1 Diagonalization of symmetric matrices 2 7.2 Quadratic forms.. 9 7.4 The singular value
Lecture 8: Linear Algebra Background
 CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 8: Linear Algebra Background Lecturer: Shayan Oveis Gharan 2/1/2017 Scribe: Swati Padmanabhan Disclaimer: These notes have not been subjected
CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 8: Linear Algebra Background Lecturer: Shayan Oveis Gharan 2/1/2017 Scribe: Swati Padmanabhan Disclaimer: These notes have not been subjected
One Picture and a Thousand Words Using Matrix Approximtions October 2017 Oak Ridge National Lab Dianne P. O Leary c 2017
 One Picture and a Thousand Words Using Matrix Approximtions October 2017 Oak Ridge National Lab Dianne P. O Leary c 2017 1 One Picture and a Thousand Words Using Matrix Approximations Dianne P. O Leary
One Picture and a Thousand Words Using Matrix Approximtions October 2017 Oak Ridge National Lab Dianne P. O Leary c 2017 1 One Picture and a Thousand Words Using Matrix Approximations Dianne P. O Leary
More Linear Algebra. Edps/Soc 584, Psych 594. Carolyn J. Anderson
 More Linear Algebra Edps/Soc 584, Psych 594 Carolyn J. Anderson Department of Educational Psychology I L L I N O I S university of illinois at urbana-champaign c Board of Trustees, University of Illinois
More Linear Algebra Edps/Soc 584, Psych 594 Carolyn J. Anderson Department of Educational Psychology I L L I N O I S university of illinois at urbana-champaign c Board of Trustees, University of Illinois
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Numerical Linear Algebra Primer. Ryan Tibshirani Convex Optimization /36-725
 Numerical Linear Algebra Primer Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: proximal gradient descent Consider the problem min g(x) + h(x) with g, h convex, g differentiable, and h simple
Numerical Linear Algebra Primer Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: proximal gradient descent Consider the problem min g(x) + h(x) with g, h convex, g differentiable, and h simple
Spectral Clustering. by HU Pili. June 16, 2013
 Spectral Clustering by HU Pili June 16, 2013 Outline Clustering Problem Spectral Clustering Demo Preliminaries Clustering: K-means Algorithm Dimensionality Reduction: PCA, KPCA. Spectral Clustering Framework
Spectral Clustering by HU Pili June 16, 2013 Outline Clustering Problem Spectral Clustering Demo Preliminaries Clustering: K-means Algorithm Dimensionality Reduction: PCA, KPCA. Spectral Clustering Framework
Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing
 Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing 1 Zhong-Yuan Zhang, 2 Chris Ding, 3 Jie Tang *1, Corresponding Author School of Statistics,
Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing 1 Zhong-Yuan Zhang, 2 Chris Ding, 3 Jie Tang *1, Corresponding Author School of Statistics,
1 Non-negative Matrix Factorization (NMF)
") 2018-06-21 1 Non-negative Matrix Factorization NMF) In the last lecture, we considered low rank approximations to data matrices. We started with the optimal rank k approximation to A R m n via the SVD,
2018-06-21 1 Non-negative Matrix Factorization NMF) In the last lecture, we considered low rank approximations to data matrices. We started with the optimal rank k approximation to A R m n via the SVD,
CHAPTER 11. A Revision. 1. The Computers and Numbers therein
 CHAPTER A Revision. The Computers and Numbers therein Traditional computer science begins with a finite alphabet. By stringing elements of the alphabet one after another, one obtains strings. A set of
CHAPTER A Revision. The Computers and Numbers therein Traditional computer science begins with a finite alphabet. By stringing elements of the alphabet one after another, one obtains strings. A set of
Non-negative matrix factorization with fixed row and column sums
 Available online at www.sciencedirect.com Linear Algebra and its Applications 9 (8) 5 www.elsevier.com/locate/laa Non-negative matrix factorization with fixed row and column sums Ngoc-Diep Ho, Paul Van
Available online at www.sciencedirect.com Linear Algebra and its Applications 9 (8) 5 www.elsevier.com/locate/laa Non-negative matrix factorization with fixed row and column sums Ngoc-Diep Ho, Paul Van
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis. Massimiliano Pontil
 2. Least Squares and Principal Components Analysis. Massimiliano Pontil") GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
Non-Negative Matrix Factorization
 Chapter 3 Non-Negative Matrix Factorization Part : Introduction & computation Motivating NMF Skillicorn chapter 8; Berry et al. (27) DMM, summer 27 2 Reminder A T U Σ V T T Σ, V U 2 Σ 2,2 V 2.8.6.6.3.6.5.3.6.3.6.4.3.6.4.3.3.4.5.3.5.8.3.8.3.3.5
Chapter 3 Non-Negative Matrix Factorization Part : Introduction & computation Motivating NMF Skillicorn chapter 8; Berry et al. (27) DMM, summer 27 2 Reminder A T U Σ V T T Σ, V U 2 Σ 2,2 V 2.8.6.6.3.6.5.3.6.3.6.4.3.6.4.3.3.4.5.3.5.8.3.8.3.3.5
Matrices, Vector Spaces, and Information Retrieval
 Matrices, Vector Spaces, and Information Authors: M. W. Berry and Z. Drmac and E. R. Jessup SIAM 1999: Society for Industrial and Applied Mathematics Speaker: Mattia Parigiani 1 Introduction Large volumes
Matrices, Vector Spaces, and Information Authors: M. W. Berry and Z. Drmac and E. R. Jessup SIAM 1999: Society for Industrial and Applied Mathematics Speaker: Mattia Parigiani 1 Introduction Large volumes
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Review of Linear Algebra Denis Helic KTI, TU Graz Oct 9, 2014 Denis Helic (KTI, TU Graz) KDDM1 Oct 9, 2014 1 / 74 Big picture: KDDM Probability Theory
Knowledge Discovery and Data Mining 1 (VO) (707.003) Review of Linear Algebra Denis Helic KTI, TU Graz Oct 9, 2014 Denis Helic (KTI, TU Graz) KDDM1 Oct 9, 2014 1 / 74 Big picture: KDDM Probability Theory
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
EUSIPCO
 EUSIPCO 2013 1569741067 CLUSERING BY NON-NEGAIVE MARIX FACORIZAION WIH INDEPENDEN PRINCIPAL COMPONEN INIIALIZAION Liyun Gong 1, Asoke K. Nandi 2,3 1 Department of Electrical Engineering and Electronics,
EUSIPCO 2013 1569741067 CLUSERING BY NON-NEGAIVE MARIX FACORIZAION WIH INDEPENDEN PRINCIPAL COMPONEN INIIALIZAION Liyun Gong 1, Asoke K. Nandi 2,3 1 Department of Electrical Engineering and Electronics,
Machine Learning - MT & 14. PCA and MDS
 Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)