Applications. Nonnegative Matrices: Ranking
|
|
|
- Earl Rodney Jackson
- 5 years ago
- Views:
Transcription
1 Applications of Nonnegative Matrices: Ranking and Clustering Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/7/2008
2 Collaborators Carl Meyer, N. C. State University David Gleich, Stanford University Michael Berry, University of Tennessee-Knoxville College of Charleston (current and former students) Luke Ingram Ibai Basabe Kathryn Pedings Neil Goodson Colin Stephenson Emmie Douglas
3 Nonnegative Matrices Ranking webpages Ranking sports teams Recommendation systems Meta-algorithms Rank and rating aggregation Cluster aggregation
4 Ranking webpages

5


6 1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg
7 Web Information Retrieval IR before the Web = traditional IR IR on the Web = web IR
8 Web Information Retrieval IR before the Web = traditional IR IR on the Web = web IR How is the Web different from other document collections?
9 Web Information Retrieval IR before the Web = traditional IR IR on the Web = web IR How is the Web different from other document collections? It s huge. over 10 billion pages, average page size of 500KB 20 times size of Library of Congress print collection Deep Web X bigger than Surface Web
10 Web Information Retrieval IR before the Web = traditional IR IR on the Web = web IR How is the Web different from other document collections? It s huge. over 10 billion pages, average page size of 500KB 20 times size of Library of Congress print collection Deep Web X bigger than Surface Web It s dynamic. content changes: 40% of pages change in a week, 23% of.com change daily size changes: billions of pages added each year
11 Web Information Retrieval IR before the Web = traditional IR IR on the Web = web IR How is the Web different from other document collections? It s huge. over 10 billion pages, average page size of 500KB 20 times size of Library of Congress print collection Deep Web X bigger than Surface Web It s dynamic. content changes: 40% of pages change in a week, 23% of.com change daily size changes: billions of pages added each year It s self-organized. no standards, review process, formats errors, falsehoods, link rot, and spammers!
12 Web Information Retrieval IR before the Web = traditional IR IR on the Web = web IR How is the Web different from other document collections? It s huge. over 10 billion pages, average page size of 500KB 20 times size of Library of Congress print collection Deep Web X bigger than Surface Web It s dynamic. content changes: 40% of pages change in a week, 23% of.com change daily size changes: billions of pages added each year It s self-organized. no standards, review process, formats errors, falsehoods, link rot, and spammers! A Herculean Task!

13 Web Information Retrieval IR before the Web = traditional IR IR on the Web = web IR How is the Web different from other document collections? It s huge. over 10 billion pages, each about 500KB 20 times size of Library of Congress print collection Deep Web X bigger than Surface Web It s dynamic. content changes: 40% of pages change in a week, 23% of.com change daily size changes: billions of pages added each year It s self-organized. no standards, review process, formats errors, falsehoods, link rot, and spammers! Ah, but it s hyperlinked! Vannevar Bush s 1945 memex
14 Elements of a Web Search Engine WWW Crawler Module Page Repository User Indexing Module Results Queries query-independent Indexes Ranking Module Query Module Special-purpose indexes Content Index Structure Index
15 The Ranking Module (generates popularity scores) Measure the importance of each page
16 The Ranking Module (generates popularity scores) Measure the importance of each page The measure should be Independent of any query Primarily determined by the link structure of the Web Tempered by some content considerations
17 The Ranking Module (generates popularity scores) Measure the importance of each page The measure should be Independent of any query Primarily determined by the link structure of the Web Tempered by some content considerations Compute these measures off-line long before any queries are processed
18 The Ranking Module (generates popularity scores) Measure the importance of each page The measure should be Independent of any query Primarily determined by the link structure of the Web Tempered by some content considerations Compute these measures off-line long before any queries are processed Google s PageRank c technology distinguishes it from all competitors
19 The Ranking Module (generates popularity scores) Measure the importance of each page The measure should be Independent of any query Primarily determined by the link structure of the Web Tempered by some content considerations Compute these measures off-line long before any queries are processed Google s PageRank c technology distinguishes it from all competitors Google s PageRank = Google s $$$$$
20
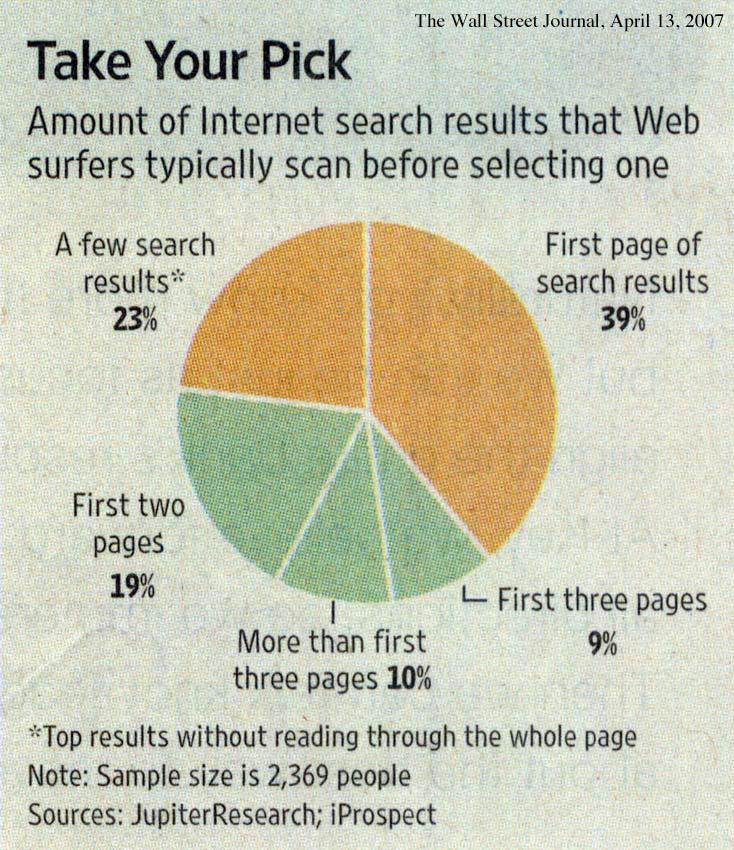
21
22
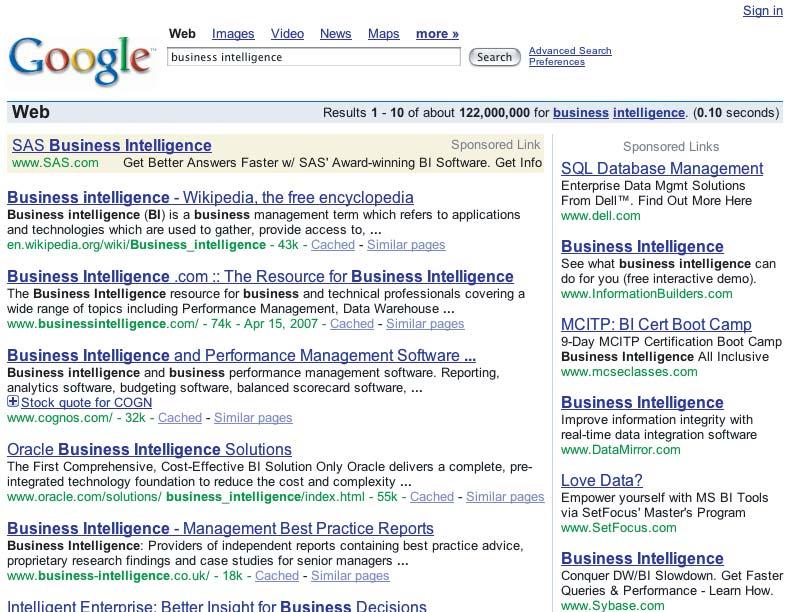
23

24
25 Google s PageRank (Lawrence Page & Sergey Brin 1998) The Google Goals Create a PageRank r(p ) that is not query dependent Off-line calculations No query time computation Let the Web vote with in-links But not by simple link counts One link to P from Yahoo! is important Many links to P from me is not Share The Vote Yahoo! casts many votes value of vote from Y ahoo! is diluted If Yahoo! votes for n pages Then P receives only r(y )/n credit from Y
26 Google s PageRank (Lawrence Page & Sergey Brin 1998) The Google Goals Create a PageRank r(p ) that is not query dependent Off-line calculations No query time computation Let the Web vote with in-links But not by simple link counts One link to P from Yahoo! is important Many links to P from me is not Share The Vote Yahoo! casts many votes value of vote from Y ahoo! is diluted If Yahoo! votes for n pages Then P receives only r(y )/n credit from Y
27 Google s PageRank (Lawrence Page & Sergey Brin 1998) The Google Goals Create a PageRank r(p ) that is not query dependent Off-line calculations No query time computation Let the Web vote with in-links But not by simple link counts One link to P from Yahoo! is important Many links to P from me is not Share The Vote Yahoo! casts many votes value of vote from Y ahoo! is diluted If Yahoo! votes for n pages Then P receives only r(y )/n credit from Y
28 Google s PageRank (Lawrence Page & Sergey Brin 1998) The Google Goals Create a PageRank r(p ) that is not query dependent Off-line calculations No query time computation Let the Web vote with in-links But not by simple link counts One link to P from Yahoo! is important Many links to P from me is not Share The Vote Yahoo! casts many votes value of vote from Y ahoo! is diluted If Yahoo! votes for n pages Then P receives only r(y )/n credit from Y
29 The Definition r(p )= r(p ) P P B P PageRank B P = {all pages pointing to P } P = number of out links from P
30 The Definition r(p )= r(p ) P P B P PageRank B P = {all pages pointing to P } P = number of out links from P Successive Refinement Start with r 0 (P i )=1/n for all pages P 1,P 2,...,P n
31 The Definition r(p )= r(p ) P P B P Successive Refinement Start with r 0 (P i )=1/n PageRank B P = {all pages pointing to P } P = number of out links from P for all pages P 1,P 2,...,P n Iteratively refine rankings for each page r 1 (P i )= r 0 (P ) P P B Pi
32 The Definition r(p )= r(p ) P P B P Successive Refinement Start with r 0 (P i )=1/n PageRank B P = {all pages pointing to P } P = number of out links from P for all pages P 1,P 2,...,P n Iteratively refine rankings for each page r 1 (P i )= r 0 (P ) P P B Pi r 2 (P i )= r 1 (P ) P P B Pi
33 The Definition r(p )= r(p ) P P B P Successive Refinement Start with r 0 (P i )=1/n PageRank B P = {all pages pointing to P } P = number of out links from P for all pages P 1,P 2,...,P n Iteratively refine rankings for each page r 1 (P i )= r 0 (P ) P P B Pi r 2 (P i )= r 1 (P ) P P B Pi... r j+1 (P i )= r j (P ) P P B Pi
34 In Matrix Notation After Step k π T k = [r k(p 1 ),r k (P 2 ),...,r k (P n )]
35 In Matrix Notation After Step k π T k = [r k(p 1 ),r k (P 2 ),...,r k (P n )] π T k+1 = πt k H where h ij = { 1/ Pi if i j 0 otherwise
36 In Matrix Notation After Step k π T k = [r k(p 1 ),r k (P 2 ),...,r k (P n )] π T k+1 = πt k H where h ij = { 1/ Pi if i j 0 otherwise PageRank vector = π T = lim k π T k = eigenvector for H Provided that the limit exists
37 Tiny Web 1 2 P 1 P 2 P 3 P 4 P 5 P H = P 1 P 2 P 3 P 4 P 5 P 6 4
38 H = Tiny Web P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P 2 P 3 P 4 P 5 P 6 4
39 H = Tiny Web P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P P 3 P 4 P 5 P 6 4
40 H = Tiny Web P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P P 3 1/3 1/ /3 0 P 4 P 5 P 6 4
41 Tiny Web H = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P P 3 1/3 1/ /3 0 P /2 1/2 P 5 P 6 4
42 Tiny Web H = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P 6 4
43 Tiny Web H = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P
44 Tiny Web H = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P A random walk on the Web Graph
45 Tiny Web H = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P A random walk on the Web Graph PageRank = π i = amount of time spent at P i
46 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote 2 3 Markov chain 6 5 4
47 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote
48 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote
49 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote
50 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote
51 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote
52 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote
53 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote
54 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote
55 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote
56 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote 2 page 2 is a dangling node
57 Tiny Web H = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P A random walk on the Web Graph PageRank = π i = amount of time spent at P i Dead end page (nothing to click on) a dangling node
58 Tiny Web H = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P A random walk on the Web Graph PageRank = π i = amount of time spent at P i Dead end page (nothing to click on) a dangling node π T =(0, 1, 0, 0, 0, 0) = e-vector = Page P 2 is a rank sink
59 The Fix Allow Web Surfers To Make Random Jumps
60 Ranking with a Random Surfer Rank each page corresponding to a search term by number and quality of votes cast for that page. Hyperlink as vote 2 surfer teleports
61 The Fix Allow Web Surfers To Make Random Jumps ( 1 Replace zero rows with et n = n, 1 n,..., 1 ) n S = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P 2 1/6 1/6 1/6 1/6 1/6 1/6 P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P
62 The Fix Allow Web Surfers To Make Random Jumps ( 1 Replace zero rows with et n = n, 1 n,..., 1 ) n S = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P 2 1/6 1/6 1/6 1/6 1/6 1/6 P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P S = H + aet 6 is now row stochastic = ρ(s) = 1
63 The Fix Allow Web Surfers To Make Random Jumps ( 1 Replace zero rows with et n = n, 1 n,..., 1 ) n S = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P 2 1/6 1/6 1/6 1/6 1/6 1/6 P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P S = H + aet 6 is now row stochastic = ρ(s) = 1 Perron says π T 0 s.t. π T = π T S with i π i = 1
64 Nasty Problem The Web Is Not Strongly Connected
65 Nasty Problem The Web Is Not Strongly Connected S is reducible S = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P 2 1/6 1/6 1/6 1/6 1/6 1/6 P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P
66 Nasty Problem The Web Is Not Strongly Connected S is reducible S = P 1 P 2 P 3 P 4 P 5 P 6 P 1 0 1/2 1/ P 2 1/6 1/6 1/6 1/6 1/6 1/6 P 3 1/3 1/ /3 0 P /2 1/2 P /2 0 1/2 P Reducible = PageRank vector is not well defined Frobenius says S needs to be irreducible to ensure a unique π T > 0 s.t. π T = π T S with i π i = 1
67 Irreducibility Is Not Enough Could Get Trapped Into A Cycle (P i P j P i )
68 Irreducibility Is Not Enough Could Get Trapped Into A Cycle (P i P j P i ) The powers S k fail to converge
69 Irreducibility Is Not Enough Could Get Trapped Into A Cycle (P i P j P i ) The powers S k fail to converge π T k+1 = πt k S fails to convergence
70 Irreducibility Is Not Enough Could Get Trapped Into A Cycle (P i P j P i ) The powers S k fail to converge π T k+1 = πt k S fails to convergence Convergence Requirement Perron Frobenius requires S to be primitive
71 Irreducibility Is Not Enough Could Get Trapped Into A Cycle (P i P j P i ) The powers S k fail to converge π T k+1 = πt k S fails to convergence Convergence Requirement Perron Frobenius requires S to be primitive No eigenvalues other than λ = 1 on unit circle
72 Irreducibility Is Not Enough Could Get Trapped Into A Cycle (P i P j P i ) The powers S k fail to converge π T k+1 = πt k S fails to convergence Convergence Requirement Perron Frobenius requires S to be primitive No eigenvalues other than λ = 1 on unit circle Frobenius proved S is primitive S k > 0 for some k
73 The Google Fix Allow A Random Jump From Any Page G = αs +(1 α)e > 0, E = ee T /n, 0 <α<1
74 The Google Fix Allow A Random Jump From Any Page G = αs +(1 α)e > 0, E = ee T /n, 0 <α<1 G = αh + uv T > 0 u = αa +(1 α)e, v T = e T /n
75 The Google Fix Allow A Random Jump From Any Page G = αs +(1 α)e > 0, E = ee T /n, 0 <α<1 G = αh + uv T > 0 u = αa +(1 α)e, v T = e T /n PageRank vector π T = left-hand Perron vector of G
76 Ranking with a Random Surfer If a page is important, it gets lots of votes from other important pages, which means the random surfer visits it often. Simply count the number of times, or proportion of time, the surfer spends on each page to create ranking of webpages.
77 Ranking with a Random Surfer If a page is important, it gets lots of votes from other important pages, which means the random surfer visits it often. Simply count the number of times, or proportion of time, the surfer spends on each page to create ranking of webpages. Proportion of Time Page 1 =.04 Page 2 =.05 Page 3 =.04 Page 4 =.38 Page 5 =.20 Page 6 = Ranked List of Pages Page 4 Page 6 Page 5 Page 2 Page 1 Page 3
78 The Google Fix Allow A Random Jump From Any Page G = αs +(1 α)e > 0, E = ee T /n, 0 <α<1 G = αh + uv T > 0 u = αa +(1 α)e, v T = e T /n PageRank vector π T = left-hand Perron vector of G Some Happy Accidents x T G = αx T H + βv T Sparse computations with the original link structure
79 The Google Fix Allow A Random Jump From Any Page G = αs +(1 α)e > 0, E = ee T /n, 0 <α<1 G = αh + uv T > 0 u = αa +(1 α)e, v T = e T /n PageRank vector π T = left-hand Perron vector of G Some Happy Accidents x T G = αx T H + βv T Sparse computations with the original link structure λ 2 (G) =α Convergence rate controllable by Google engineers
80 The Google Fix Allow A Random Jump From Any Page G = αs +(1 α)e > 0, E = ee T /n, 0 <α<1 G = αh + uv T > 0 u = αa +(1 α)e, v T = e T /n PageRank vector π T = left-hand Perron vector of G Some Happy Accidents x T G = αx T H + βv T Sparse computations with the original link structure λ 2 (G) =α Convergence rate controllable by Google engineers v T can be any positive probability vector in G = αh + uv T
81 The Google Fix Allow A Random Jump From Any Page G = αs +(1 α)e > 0, E = ee T /n, 0 <α<1 G = αh + uv T > 0 u = αa +(1 α)e, v T = e T /n PageRank vector π T = left-hand Perron vector of G Some Happy Accidents x T G = αx T H + βv T Sparse computations with the original link structure λ 2 (G) =α Convergence rate controllable by Google engineers v T can be any positive probability vector in G = αh + uv T The choice of v T allows for personalization
82 Google matrix G > 0 Perron-Frobenius guarantees existence of π uniqueness of π convergence of algorithm rate of convergence: 2 (G) = α
83 Ranking Sports Teams
84 PageRank applied to Sports (joint work with Carl Meyer) webpages vote with hyperlinks losing teams vote with point differentials 45 Duke 45 Miami 20 VT UNC 2 UVA not as successful at ranking and predicting winners as mhits
85 mhits each team i gets both offensive rating o i and defensive rating d i mhits Thesis: A team is a good defensive team (i.e., deserves a high defensive rating d j ) when it holds its opponents (particularly strong offensive teams) to low scores. A team is a good offensive team (i.e., deserves a high offensive rating o i ) when it scores many points against its opponents (particularly opponents with high defensive ratings). Miami 17 UNC Duke VT UVA P= Duke Miami UNC UVA VT Duke Miami UNC UVA VT Graph Point Matrix P 0
86 Summation Notation mhits Equations d j = X i I j p ij 1 o i and o i = X j L i p ij 1 d j Matrix Notation: iterative procedure d (k) = P T 1 o (k) and o (k) = P 1 d (k 1) related to the Sinkhorn-Knopp algorithm for matrix balancing (uses successive row and column scaling to transform P 0 into doubly stochastic matrix S) P. Knight uses Sinkhorn-Knopp algorithm to rank webpages


87 mhits Results: tiny NCAA (data from Luke Ingram) Duke Miami 38 VT UNC 7 UVA 5
88 Weighted mhits Weighted Point Matrix P 0 p ij = w ij p ij (w ij = weight of matchup between teams i and j) possible weightings w ij w Linear w Logarithmic t 0 tf t t 0 tf t w Exponential w Step Function t 0 tf t t 0 t s tf t


89 mhits Results: full NCAA (image from Neil Goodson and Colin Stephenson)

90 mhits Results: full NCAA weightings can easily be applied to all ranking methods interesting possibilities for weighted webpage ranking
91 mhits Point Matrix P 0 Perron-Frobenius guarantees (for irreducible P with total support) existence of o and d uniqueness of o and d convergence of mhits algorithm rate of convergence of mhits algorithm σ2 2 (S), where S = D (1/o) P D (1/d)
92 Recommendation Systems
93 Recommendation Systems A 0 purchase history matrix A = Item Item Item m User 1 User 2... User n Find similar users Find similar items Cluster users into classes EX: use NMF so that A m n W m k H k n
94 NMF Algorithm: Lee and Seung 2000 Mean Squared Error objective function min ka WHk 2 F s.t. W, H 0 W = abs(randn(m,k)); H = abs(randn(k,n)); for i = 1 : maxiter H = H.* (W T A)./ (W T WH ); W = W.* (AH T )./ (WHH T ); end Many parameters affect performance (k, obj. function, sparsity constraints, algorithm, etc.). NMF is not unique! (proof of convergence to fixed point based on E-M convergence proof)
95 Interpretation with NMF columns of W are the underlying basis vectors, i.e., each of the n columns of A m n can be built from k columns of W m k. columns of H give the weights associated with each basis vector.... A 2 = A 1 WH 1 = item 1 5 item 2 0 item 3 0 item 4 11 item 5 1 w 1. WH 1 = h w 2. h w k. h k W, H 0 immediate interpretation (additive parts-based rep.)
96 user rating matrix A = Netflix movies,.5 million users movie movie movie m User 1 User 2... User n Find similar users Find similar movies Cluster users and movies into classes Rank users Rank movies
")

97 (vismatrix tool - David Gleich) Clustering Netflix (movie-movie matrix; x 17770)
98 user rating matrix A = Netflix movies,.5 million users movie movie movie m User 1 User 2... User n Find similar users Find similar movies Cluster users and movies into classes Rank users Rank movies
99 mhits on Netflix each movie i gets a rating m i and each user gets a rating u j mhits Thesis: A movie is a good (i.e., deserves a high rating m i ) if it gets high ratings from good (i.e., discriminating) users. A user is good (i.e., deserves a high rating u j ) when his or her ratings match the true rating of a movie. mhits Netflix Algorithm u = e; for i = 1 : maxiter m = A u; m = 5(m min(m)) max(m) min(m) ; u = 1 ((R (R>0). (em T )). 2 )e ; end
100 Netflix mhits results subset: 1500 super users 1 st Raiders of the Lost Ark 2 nd Silence of the Lambs 3 rd The Sixth Sense 4 th Shawshank Redemption 5 th LOR: Fellowship of the Ring 6 th The Matrix 7 th LOR: The Two Towers 8 th Pulp Fiction 9 th LOR: The Return of the King 10 th Forrest Gump 11 th The Usual Suspects 12 th American Beauty (rate 1000 movies) 13 th Pirates of the Carribbean: Black Pearl 14 th The Godfather 15 th Braveheart
101 The Enron Dataset (data from Mike Berry) PRIVATE collection of 150 Enron employees during ,000 terms and 65,000 messages Term-by-Message Matrix f astow1 f astow2 skilling subpoena dynegy
102 Text Mining Applications Data compression Find similar terms Find similar documents Cluster documents Cluster terms Topic detection and tracking
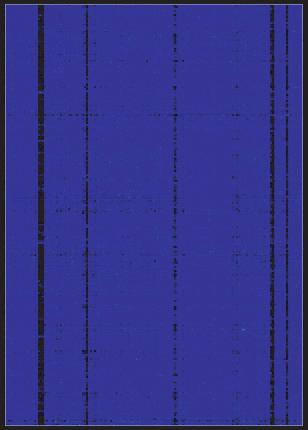
103 Unclustered Enron A
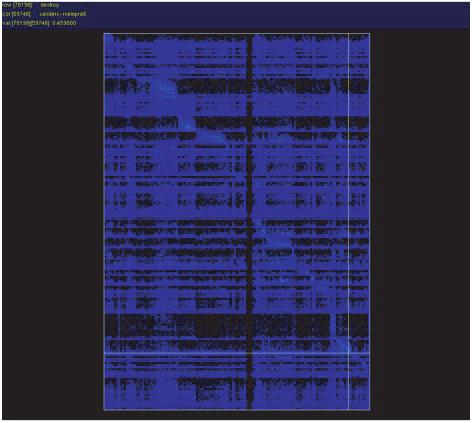
104 NMF-clustered Enron A
105 Clustering the Enron Dataset (image from Mike Berry)
106 Tracking Enron clusters over time (image from Mike Berry)
107 Meta-Algorithms
108 Rank Aggregation
109 Rank Aggregation average rank Borda count simulated data graph theory
110 Average Rank
111 Borda Count for each ranked list, each item receives a score equal to the number of items it outranks.

112 Simulated Data 3 ranked lists mhits VT beats Miami by 1 point, UVA by 2 points,... Miami beats UVA by 1 point, UNC by 2 points,... UVA beats UNC by 1 point, Duke by 2 points UNC beats Duke by 1 point repeat for each ranked list generates game scores for teams Simulated Game Data
113 Simulated Data
114 Graph Theory more voting ranked lists are used to form weighted graph possible weights * w ij = # of ranked lists having i below j * w ij = sum of rank differences of lists having i below j run algorithm (e.g., Markov, PageRank, HITS) to determine most important nodes
115 Aggregation Rating Aggregation
116 Rating Aggregation rating vectors form rating differential matrix R for each rating vector
117 Rating Aggregation rating differential matrices R 0 differing scales normalize
118 Rating Aggregation rating differential matrices
119 Rating Aggregation rating differential matrices combine into one matrix average
120 Rating Aggregation rating differential matrices combine into one matrix average
121 Rating Aggregation average rating differential matrix R average 0 run ranking method * Markov method on R T average * row sums of R average / col sums of R average * Perron vector of R average

122 Rating Aggregation average rating differential matrix R average 0 run ranking method * Markov method on R T average * row sums of R average / col sums of R average * Perron vector of R average
123 Cluster Aggregation many clustering algorithms = many clustering results Can we combine many results to make one super result? Cluster Aggregation Algorithm 1. Create aggregation matrix F 0 f ij = # of methods having items i and j in the same cluster 2. Run favorite clustering method on F
124 Cluster Aggregation Example Method 1 Method 2 Method 3 item cluster assignment item cluster assignment item cluster assignment Cluster Aggregated Graph Cluster Aggregated Results Fiedler using just one eigenvector Fiedler using two eigenvectors
125 Conclusions Applied problems often have nonnegative data. This nonnegativity is exploitable structure. proofs for convergence and rates of convergence proofs for existence and uniqueness Nonnegativity is easily interpretable. Often it pays to maintain nonnegativity throughout the modeling process. nonnegative matrix factorizations nonnegative rating vectors
1998: enter Link Analysis
 1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
Rank and Rating Aggregation. Amy Langville Mathematics Department College of Charleston
 Rank and Rating Aggregation Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/6/2008 Collaborators Carl Meyer, N. C. State University College of Charleston (current and former
Rank and Rating Aggregation Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/6/2008 Collaborators Carl Meyer, N. C. State University College of Charleston (current and former
How does Google rank webpages?
 Linear Algebra Spring 016 How does Google rank webpages? Dept. of Internet and Multimedia Eng. Konkuk University leehw@konkuk.ac.kr 1 Background on search engines Outline HITS algorithm (Jon Kleinberg)
Linear Algebra Spring 016 How does Google rank webpages? Dept. of Internet and Multimedia Eng. Konkuk University leehw@konkuk.ac.kr 1 Background on search engines Outline HITS algorithm (Jon Kleinberg)
Link Analysis. Leonid E. Zhukov
 Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
Clustering. SVD and NMF
 Clustering with the SVD and NMF Amy Langville Mathematics Department College of Charleston Dagstuhl 2/14/2007 Outline Fielder Method Extended Fielder Method and SVD Clustering with SVD vs. NMF Demos with
Clustering with the SVD and NMF Amy Langville Mathematics Department College of Charleston Dagstuhl 2/14/2007 Outline Fielder Method Extended Fielder Method and SVD Clustering with SVD vs. NMF Demos with
Updating PageRank. Amy Langville Carl Meyer
 Updating PageRank Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC SCCM 11/17/2003 Indexing Google Must index key terms on each page Robots crawl the web software
Updating PageRank Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC SCCM 11/17/2003 Indexing Google Must index key terms on each page Robots crawl the web software
Calculating Web Page Authority Using the PageRank Algorithm
 Jacob Miles Prystowsky and Levi Gill Math 45, Fall 2005 1 Introduction 1.1 Abstract In this document, we examine how the Google Internet search engine uses the PageRank algorithm to assign quantitatively
Jacob Miles Prystowsky and Levi Gill Math 45, Fall 2005 1 Introduction 1.1 Abstract In this document, we examine how the Google Internet search engine uses the PageRank algorithm to assign quantitatively
Uncertainty and Randomization
 Uncertainty and Randomization The PageRank Computation in Google Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it 1993: Robustness of Linear Systems 1993: Robustness of Linear Systems 16 Years
Uncertainty and Randomization The PageRank Computation in Google Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it 1993: Robustness of Linear Systems 1993: Robustness of Linear Systems 16 Years
PageRank. Ryan Tibshirani /36-662: Data Mining. January Optional reading: ESL 14.10
 PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize/navigate it? First try: Human curated Web directories Yahoo, DMOZ, LookSmart
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize/navigate it? First try: Human curated Web directories Yahoo, DMOZ, LookSmart
A Note on Google s PageRank
 A Note on Google s PageRank According to Google, google-search on a given topic results in a listing of most relevant web pages related to the topic. Google ranks the importance of webpages according to
A Note on Google s PageRank According to Google, google-search on a given topic results in a listing of most relevant web pages related to the topic. Google ranks the importance of webpages according to
Ranking using Matrices.
 Anjela Govan, Amy Langville, Carl D. Meyer Northrop Grumman, College of Charleston, North Carolina State University June 2009 Outline Introduction Offense-Defense Model Generalized Markov Model Data Game
Anjela Govan, Amy Langville, Carl D. Meyer Northrop Grumman, College of Charleston, North Carolina State University June 2009 Outline Introduction Offense-Defense Model Generalized Markov Model Data Game
Introduction to Search Engine Technology Introduction to Link Structure Analysis. Ronny Lempel Yahoo Labs, Haifa
 Introduction to Search Engine Technology Introduction to Link Structure Analysis Ronny Lempel Yahoo Labs, Haifa Outline Anchor-text indexing Mathematical Background Motivation for link structure analysis
Introduction to Search Engine Technology Introduction to Link Structure Analysis Ronny Lempel Yahoo Labs, Haifa Outline Anchor-text indexing Mathematical Background Motivation for link structure analysis
Link Mining PageRank. From Stanford C246
 Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/7/2012 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Web pages are not equally important www.joe-schmoe.com
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/7/2012 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Web pages are not equally important www.joe-schmoe.com
Lecture 7 Mathematics behind Internet Search
 CCST907 Hidden Order in Daily Life: A Mathematical Perspective Lecture 7 Mathematics behind Internet Search Dr. S. P. Yung (907A) Dr. Z. Hua (907B) Department of Mathematics, HKU Outline Google is the
CCST907 Hidden Order in Daily Life: A Mathematical Perspective Lecture 7 Mathematics behind Internet Search Dr. S. P. Yung (907A) Dr. Z. Hua (907B) Department of Mathematics, HKU Outline Google is the
MultiRank and HAR for Ranking Multi-relational Data, Transition Probability Tensors, and Multi-Stochastic Tensors
 MultiRank and HAR for Ranking Multi-relational Data, Transition Probability Tensors, and Multi-Stochastic Tensors Michael K. Ng Centre for Mathematical Imaging and Vision and Department of Mathematics
MultiRank and HAR for Ranking Multi-relational Data, Transition Probability Tensors, and Multi-Stochastic Tensors Michael K. Ng Centre for Mathematical Imaging and Vision and Department of Mathematics
Nonnegative Matrix Factorization. Data Mining
 The Nonnegative Matrix Factorization in Data Mining Amy Langville langvillea@cofc.edu Mathematics Department College of Charleston Charleston, SC Yahoo! Research 10/18/2005 Outline Part 1: Historical Developments
The Nonnegative Matrix Factorization in Data Mining Amy Langville langvillea@cofc.edu Mathematics Department College of Charleston Charleston, SC Yahoo! Research 10/18/2005 Outline Part 1: Historical Developments
CS 277: Data Mining. Mining Web Link Structure. CS 277: Data Mining Lectures Analyzing Web Link Structure Padhraic Smyth, UC Irvine
 CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Data Mining Recitation Notes Week 3
 Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Link Analysis Ranking
 Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
Google PageRank. Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano
 Google PageRank Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano fricci@unibz.it 1 Content p Linear Algebra p Matrices p Eigenvalues and eigenvectors p Markov chains p Google
Google PageRank Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano fricci@unibz.it 1 Content p Linear Algebra p Matrices p Eigenvalues and eigenvectors p Markov chains p Google
Graph Models The PageRank Algorithm
 Graph Models The PageRank Algorithm Anna-Karin Tornberg Mathematical Models, Analysis and Simulation Fall semester, 2013 The PageRank Algorithm I Invented by Larry Page and Sergey Brin around 1998 and
Graph Models The PageRank Algorithm Anna-Karin Tornberg Mathematical Models, Analysis and Simulation Fall semester, 2013 The PageRank Algorithm I Invented by Larry Page and Sergey Brin around 1998 and
Link Analysis Information Retrieval and Data Mining. Prof. Matteo Matteucci
 Link Analysis Information Retrieval and Data Mining Prof. Matteo Matteucci Hyperlinks for Indexing and Ranking 2 Page A Hyperlink Page B Intuitions The anchor text might describe the target page B Anchor
Link Analysis Information Retrieval and Data Mining Prof. Matteo Matteucci Hyperlinks for Indexing and Ranking 2 Page A Hyperlink Page B Intuitions The anchor text might describe the target page B Anchor
DATA MINING LECTURE 13. Link Analysis Ranking PageRank -- Random walks HITS
 DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
How works. or How linear algebra powers the search engine. M. Ram Murty, FRSC Queen s Research Chair Queen s University
 How works or How linear algebra powers the search engine M. Ram Murty, FRSC Queen s Research Chair Queen s University From: gomath.com/geometry/ellipse.php Metric mishap causes loss of Mars orbiter
How works or How linear algebra powers the search engine M. Ram Murty, FRSC Queen s Research Chair Queen s University From: gomath.com/geometry/ellipse.php Metric mishap causes loss of Mars orbiter
Link Analysis. Stony Brook University CSE545, Fall 2016
 Link Analysis Stony Brook University CSE545, Fall 2016 The Web, circa 1998 The Web, circa 1998 The Web, circa 1998 Match keywords, language (information retrieval) Explore directory The Web, circa 1998
Link Analysis Stony Brook University CSE545, Fall 2016 The Web, circa 1998 The Web, circa 1998 The Web, circa 1998 Match keywords, language (information retrieval) Explore directory The Web, circa 1998
Google Page Rank Project Linear Algebra Summer 2012
 Google Page Rank Project Linear Algebra Summer 2012 How does an internet search engine, like Google, work? In this project you will discover how the Page Rank algorithm works to give the most relevant
Google Page Rank Project Linear Algebra Summer 2012 How does an internet search engine, like Google, work? In this project you will discover how the Page Rank algorithm works to give the most relevant
Node Centrality and Ranking on Networks
 Node Centrality and Ranking on Networks Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Social
Node Centrality and Ranking on Networks Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Social
Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University.
 Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org #1: C4.5 Decision Tree - Classification (61 votes) #2: K-Means - Clustering
Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org #1: C4.5 Decision Tree - Classification (61 votes) #2: K-Means - Clustering
ECEN 689 Special Topics in Data Science for Communications Networks
 ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 8 Random Walks, Matrices and PageRank Graphs
ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 8 Random Walks, Matrices and PageRank Graphs
Lab 8: Measuring Graph Centrality - PageRank. Monday, November 5 CompSci 531, Fall 2018
 Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
IR: Information Retrieval
 / 44 IR: Information Retrieval FIB, Master in Innovation and Research in Informatics Slides by Marta Arias, José Luis Balcázar, Ramon Ferrer-i-Cancho, Ricard Gavaldá Department of Computer Science, UPC
/ 44 IR: Information Retrieval FIB, Master in Innovation and Research in Informatics Slides by Marta Arias, José Luis Balcázar, Ramon Ferrer-i-Cancho, Ricard Gavaldá Department of Computer Science, UPC
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Data Mining and Matrices
 Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
Page rank computation HPC course project a.y
 Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
CS246: Mining Massive Datasets Jure Leskovec, Stanford University.
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu What is the structure of the Web? How is it organized? 2/7/2011 Jure Leskovec, Stanford C246: Mining Massive
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu What is the structure of the Web? How is it organized? 2/7/2011 Jure Leskovec, Stanford C246: Mining Massive
Computing PageRank using Power Extrapolation
 Computing PageRank using Power Extrapolation Taher Haveliwala, Sepandar Kamvar, Dan Klein, Chris Manning, and Gene Golub Stanford University Abstract. We present a novel technique for speeding up the computation
Computing PageRank using Power Extrapolation Taher Haveliwala, Sepandar Kamvar, Dan Klein, Chris Manning, and Gene Golub Stanford University Abstract. We present a novel technique for speeding up the computation
Math 304 Handout: Linear algebra, graphs, and networks.
 Math 30 Handout: Linear algebra, graphs, and networks. December, 006. GRAPHS AND ADJACENCY MATRICES. Definition. A graph is a collection of vertices connected by edges. A directed graph is a graph all
Math 30 Handout: Linear algebra, graphs, and networks. December, 006. GRAPHS AND ADJACENCY MATRICES. Definition. A graph is a collection of vertices connected by edges. A directed graph is a graph all
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
Data and Algorithms of the Web
 Data and Algorithms of the Web Link Analysis Algorithms Page Rank some slides from: Anand Rajaraman, Jeffrey D. Ullman InfoLab (Stanford University) Link Analysis Algorithms Page Rank Hubs and Authorities
Data and Algorithms of the Web Link Analysis Algorithms Page Rank some slides from: Anand Rajaraman, Jeffrey D. Ullman InfoLab (Stanford University) Link Analysis Algorithms Page Rank Hubs and Authorities
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
PageRank algorithm Hubs and Authorities. Data mining. Web Data Mining PageRank, Hubs and Authorities. University of Szeged.
 Web Data Mining PageRank, University of Szeged Why ranking web pages is useful? We are starving for knowledge It earns Google a bunch of money. How? How does the Web looks like? Big strongly connected
Web Data Mining PageRank, University of Szeged Why ranking web pages is useful? We are starving for knowledge It earns Google a bunch of money. How? How does the Web looks like? Big strongly connected
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides
 Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Chapter 10. Finite-State Markov Chains. Introductory Example: Googling Markov Chains
 Chapter 0 Finite-State Markov Chains Introductory Example: Googling Markov Chains Google means many things: it is an Internet search engine, the company that produces the search engine, and a verb meaning
Chapter 0 Finite-State Markov Chains Introductory Example: Googling Markov Chains Google means many things: it is an Internet search engine, the company that produces the search engine, and a verb meaning
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides
 Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Application. Stochastic Matrices and PageRank
 Application Stochastic Matrices and PageRank Stochastic Matrices Definition A square matrix A is stochastic if all of its entries are nonnegative, and the sum of the entries of each column is. We say A
Application Stochastic Matrices and PageRank Stochastic Matrices Definition A square matrix A is stochastic if all of its entries are nonnegative, and the sum of the entries of each column is. We say A
6.207/14.15: Networks Lecture 7: Search on Networks: Navigation and Web Search
 6.207/14.15: Networks Lecture 7: Search on Networks: Navigation and Web Search Daron Acemoglu and Asu Ozdaglar MIT September 30, 2009 1 Networks: Lecture 7 Outline Navigation (or decentralized search)
6.207/14.15: Networks Lecture 7: Search on Networks: Navigation and Web Search Daron Acemoglu and Asu Ozdaglar MIT September 30, 2009 1 Networks: Lecture 7 Outline Navigation (or decentralized search)
Inf 2B: Ranking Queries on the WWW
 Inf B: Ranking Queries on the WWW Kyriakos Kalorkoti School of Informatics University of Edinburgh Queries Suppose we have an Inverted Index for a set of webpages. Disclaimer Not really the scenario of
Inf B: Ranking Queries on the WWW Kyriakos Kalorkoti School of Informatics University of Edinburgh Queries Suppose we have an Inverted Index for a set of webpages. Disclaimer Not really the scenario of
Web Ranking. Classification (manual, automatic) Link Analysis (today s lesson)
 Link Analysis (today s lesson)") Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Link Analysis. Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze
 Link Analysis Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages
Link Analysis Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
eigenvalues, markov matrices, and the power method
 eigenvalues, markov matrices, and the power method Slides by Olson. Some taken loosely from Jeff Jauregui, Some from Semeraro L. Olson Department of Computer Science University of Illinois at Urbana-Champaign
eigenvalues, markov matrices, and the power method Slides by Olson. Some taken loosely from Jeff Jauregui, Some from Semeraro L. Olson Department of Computer Science University of Illinois at Urbana-Champaign
MATH36001 Perron Frobenius Theory 2015
 MATH361 Perron Frobenius Theory 215 In addition to saying something useful, the Perron Frobenius theory is elegant. It is a testament to the fact that beautiful mathematics eventually tends to be useful,
MATH361 Perron Frobenius Theory 215 In addition to saying something useful, the Perron Frobenius theory is elegant. It is a testament to the fact that beautiful mathematics eventually tends to be useful,
Pseudocode for calculating Eigenfactor TM Score and Article Influence TM Score using data from Thomson-Reuters Journal Citations Reports
 Pseudocode for calculating Eigenfactor TM Score and Article Influence TM Score using data from Thomson-Reuters Journal Citations Reports Jevin West and Carl T. Bergstrom November 25, 2008 1 Overview There
Pseudocode for calculating Eigenfactor TM Score and Article Influence TM Score using data from Thomson-Reuters Journal Citations Reports Jevin West and Carl T. Bergstrom November 25, 2008 1 Overview There
SUPPLEMENTARY MATERIALS TO THE PAPER: ON THE LIMITING BEHAVIOR OF PARAMETER-DEPENDENT NETWORK CENTRALITY MEASURES
 SUPPLEMENTARY MATERIALS TO THE PAPER: ON THE LIMITING BEHAVIOR OF PARAMETER-DEPENDENT NETWORK CENTRALITY MEASURES MICHELE BENZI AND CHRISTINE KLYMKO Abstract This document contains details of numerical
SUPPLEMENTARY MATERIALS TO THE PAPER: ON THE LIMITING BEHAVIOR OF PARAMETER-DEPENDENT NETWORK CENTRALITY MEASURES MICHELE BENZI AND CHRISTINE KLYMKO Abstract This document contains details of numerical
Random Surfing on Multipartite Graphs
 Random Surfing on Multipartite Graphs Athanasios N. Nikolakopoulos, Antonia Korba and John D. Garofalakis Department of Computer Engineering and Informatics, University of Patras December 07, 2016 IEEE
Random Surfing on Multipartite Graphs Athanasios N. Nikolakopoulos, Antonia Korba and John D. Garofalakis Department of Computer Engineering and Informatics, University of Patras December 07, 2016 IEEE
Multiple Relational Ranking in Tensor: Theory, Algorithms and Applications
 Multiple Relational Ranking in Tensor: Theory, Algorithms and Applications Michael K. Ng Centre for Mathematical Imaging and Vision and Department of Mathematics Hong Kong Baptist University Email: mng@math.hkbu.edu.hk
Multiple Relational Ranking in Tensor: Theory, Algorithms and Applications Michael K. Ng Centre for Mathematical Imaging and Vision and Department of Mathematics Hong Kong Baptist University Email: mng@math.hkbu.edu.hk
1 Searching the World Wide Web
 Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
On the mathematical background of Google PageRank algorithm
 Working Paper Series Department of Economics University of Verona On the mathematical background of Google PageRank algorithm Alberto Peretti, Alberto Roveda WP Number: 25 December 2014 ISSN: 2036-2919
Working Paper Series Department of Economics University of Verona On the mathematical background of Google PageRank algorithm Alberto Peretti, Alberto Roveda WP Number: 25 December 2014 ISSN: 2036-2919
Complex Social System, Elections. Introduction to Network Analysis 1
 Complex Social System, Elections Introduction to Network Analysis 1 Complex Social System, Network I person A voted for B A is more central than B if more people voted for A In-degree centrality index
Complex Social System, Elections Introduction to Network Analysis 1 Complex Social System, Network I person A voted for B A is more central than B if more people voted for A In-degree centrality index
Information Retrieval and Search. Web Linkage Mining. Miłosz Kadziński
 Web Linkage Analysis D24 D4 : Web Linkage Mining Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Web mining: Web Mining Discovery
Web Linkage Analysis D24 D4 : Web Linkage Mining Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Web mining: Web Mining Discovery
UpdatingtheStationary VectorofaMarkovChain. Amy Langville Carl Meyer
 UpdatingtheStationary VectorofaMarkovChain Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC NSMC 9/4/2003 Outline Updating and Pagerank Aggregation Partitioning
UpdatingtheStationary VectorofaMarkovChain Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC NSMC 9/4/2003 Outline Updating and Pagerank Aggregation Partitioning
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
Pr[positive test virus] Pr[virus] Pr[positive test] = Pr[positive test] = Pr[positive test]
![Pr[positive test virus] Pr[virus] Pr[positive test] = Pr[positive test] = Pr[positive test]](/thumbs/77/74699650.jpg "Pr[positive test virus] Pr[virus] Pr[positive test] = Pr[positive test] = Pr[positive test]") 146 Probability Pr[virus] = 0.00001 Pr[no virus] = 0.99999 Pr[positive test virus] = 0.99 Pr[positive test no virus] = 0.01 Pr[virus positive test] = Pr[positive test virus] Pr[virus] = 0.99 0.00001 =
146 Probability Pr[virus] = 0.00001 Pr[no virus] = 0.99999 Pr[positive test virus] = 0.99 Pr[positive test no virus] = 0.01 Pr[virus positive test] = Pr[positive test virus] Pr[virus] = 0.99 0.00001 =
Lecture 12: Link Analysis for Web Retrieval
 Lecture 12: Link Analysis for Web Retrieval Trevor Cohn COMP90042, 2015, Semester 1 What we ll learn in this lecture The web as a graph Page-rank method for deriving the importance of pages Hubs and authorities
Lecture 12: Link Analysis for Web Retrieval Trevor Cohn COMP90042, 2015, Semester 1 What we ll learn in this lecture The web as a graph Page-rank method for deriving the importance of pages Hubs and authorities
Krylov Subspace Methods to Calculate PageRank
 Krylov Subspace Methods to Calculate PageRank B. Vadala-Roth REU Final Presentation August 1st, 2013 How does Google Rank Web Pages? The Web The Graph (A) Ranks of Web pages v = v 1... Dominant Eigenvector
Krylov Subspace Methods to Calculate PageRank B. Vadala-Roth REU Final Presentation August 1st, 2013 How does Google Rank Web Pages? The Web The Graph (A) Ranks of Web pages v = v 1... Dominant Eigenvector
Lesson Plan. AM 121: Introduction to Optimization Models and Methods. Lecture 17: Markov Chains. Yiling Chen SEAS. Stochastic process Markov Chains
 AM : Introduction to Optimization Models and Methods Lecture 7: Markov Chains Yiling Chen SEAS Lesson Plan Stochastic process Markov Chains n-step probabilities Communicating states, irreducibility Recurrent
AM : Introduction to Optimization Models and Methods Lecture 7: Markov Chains Yiling Chen SEAS Lesson Plan Stochastic process Markov Chains n-step probabilities Communicating states, irreducibility Recurrent
0.1 Naive formulation of PageRank
 PageRank is a ranking system designed to find the best pages on the web. A webpage is considered good if it is endorsed (i.e. linked to) by other good webpages. The more webpages link to it, and the more
PageRank is a ranking system designed to find the best pages on the web. A webpage is considered good if it is endorsed (i.e. linked to) by other good webpages. The more webpages link to it, and the more
Lecture: Local Spectral Methods (1 of 4)
") Stat260/CS294: Spectral Graph Methods Lecture 18-03/31/2015 Lecture: Local Spectral Methods (1 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Stat260/CS294: Spectral Graph Methods Lecture 18-03/31/2015 Lecture: Local Spectral Methods (1 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Mathematical Properties & Analysis of Google s PageRank
 Mathematical Properties & Analysis of Google s PageRank Ilse Ipsen North Carolina State University, USA Joint work with Rebecca M. Wills Cedya p.1 PageRank An objective measure of the citation importance
Mathematical Properties & Analysis of Google s PageRank Ilse Ipsen North Carolina State University, USA Joint work with Rebecca M. Wills Cedya p.1 PageRank An objective measure of the citation importance
Coding the Matrix! Divya Padmanabhan. Intelligent Systems Lab, Dept. of CSA, Indian Institute of Science, Bangalore. June 28, 2013
 Coding the Matrix! Divya Padmanabhan Intelligent Systems Lab, Dept. of CSA, Indian Institute of Science, Bangalore June 28, 203 Divya Padmanabhan Coding the Matrix! June 28, 203 How does the most popular
Coding the Matrix! Divya Padmanabhan Intelligent Systems Lab, Dept. of CSA, Indian Institute of Science, Bangalore June 28, 203 Divya Padmanabhan Coding the Matrix! June 28, 203 How does the most popular
Updating Markov Chains Carl Meyer Amy Langville
 Updating Markov Chains Carl Meyer Amy Langville Department of Mathematics North Carolina State University Raleigh, NC A. A. Markov Anniversary Meeting June 13, 2006 Intro Assumptions Very large irreducible
Updating Markov Chains Carl Meyer Amy Langville Department of Mathematics North Carolina State University Raleigh, NC A. A. Markov Anniversary Meeting June 13, 2006 Intro Assumptions Very large irreducible
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University We ve had our first HC cases. Please, please, please, before you do anything that might violate the HC, talk to me or a TA to make sure it is legitimate. It is much
Jeffrey D. Ullman Stanford University We ve had our first HC cases. Please, please, please, before you do anything that might violate the HC, talk to me or a TA to make sure it is legitimate. It is much
Hub, Authority and Relevance Scores in Multi-Relational Data for Query Search
 Hub, Authority and Relevance Scores in Multi-Relational Data for Query Search Xutao Li 1 Michael Ng 2 Yunming Ye 1 1 Department of Computer Science, Shenzhen Graduate School, Harbin Institute of Technology,
Hub, Authority and Relevance Scores in Multi-Relational Data for Query Search Xutao Li 1 Michael Ng 2 Yunming Ye 1 1 Department of Computer Science, Shenzhen Graduate School, Harbin Institute of Technology,
THEORY OF SEARCH ENGINES. CONTENTS 1. INTRODUCTION 1 2. RANKING OF PAGES 2 3. TWO EXAMPLES 4 4. CONCLUSION 5 References 5
 THEORY OF SEARCH ENGINES K. K. NAMBIAR ABSTRACT. Four different stochastic matrices, useful for ranking the pages of the Web are defined. The theory is illustrated with examples. Keywords Search engines,
THEORY OF SEARCH ENGINES K. K. NAMBIAR ABSTRACT. Four different stochastic matrices, useful for ranking the pages of the Web are defined. The theory is illustrated with examples. Keywords Search engines,
Intelligent Data Analysis. PageRank. School of Computer Science University of Birmingham
 Intelligent Data Analysis PageRank Peter Tiňo School of Computer Science University of Birmingham Information Retrieval on the Web Most scoring methods on the Web have been derived in the context of Information
Intelligent Data Analysis PageRank Peter Tiňo School of Computer Science University of Birmingham Information Retrieval on the Web Most scoring methods on the Web have been derived in the context of Information
Web Ranking. Classification (manual, automatic) Link Analysis (today s lesson)
 Link Analysis (today s lesson)") Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
How Does Google?! A journey into the wondrous mathematics behind your favorite websites. David F. Gleich! Computer Science! Purdue University!
 ! How Does Google?! A journey into the wondrous mathematics behind your favorite websites David F. Gleich! Computer Science! Purdue University! 1 Mathematics underlies an enormous number of the websites
! How Does Google?! A journey into the wondrous mathematics behind your favorite websites David F. Gleich! Computer Science! Purdue University! 1 Mathematics underlies an enormous number of the websites
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 2 Web pages are important if people visit them a lot. But we can t watch everybody using the Web. A good surrogate for visiting pages is to assume people follow links
Jeffrey D. Ullman Stanford University 2 Web pages are important if people visit them a lot. But we can t watch everybody using the Web. A good surrogate for visiting pages is to assume people follow links
Google and Biosequence searches with Markov Chains
 Google and Biosequence searches with Markov Chains Nigel Buttimore Trinity College Dublin 3 June 2010 UCD-TCD Mathematics Summer School Frontiers of Maths and Applications Summary A brief history of Andrei
Google and Biosequence searches with Markov Chains Nigel Buttimore Trinity College Dublin 3 June 2010 UCD-TCD Mathematics Summer School Frontiers of Maths and Applications Summary A brief history of Andrei
Applications to network analysis: Eigenvector centrality indices Lecture notes
 Applications to network analysis: Eigenvector centrality indices Lecture notes Dario Fasino, University of Udine (Italy) Lecture notes for the second part of the course Nonnegative and spectral matrix
Applications to network analysis: Eigenvector centrality indices Lecture notes Dario Fasino, University of Udine (Italy) Lecture notes for the second part of the course Nonnegative and spectral matrix
Introduction to Data Mining
 Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
Announcements: Warm-up Exercise:
 Fri Mar 30 5.6 Discrete dynamical systems: Google page rank, using some notes I wrote a while ago. I'll probably also bring a handout to class. There are other documents on the internet about this subject.
Fri Mar 30 5.6 Discrete dynamical systems: Google page rank, using some notes I wrote a while ago. I'll probably also bring a handout to class. There are other documents on the internet about this subject.
arxiv:cond-mat/ v1 3 Sep 2004
 Effects of Community Structure on Search and Ranking in Information Networks Huafeng Xie 1,3, Koon-Kiu Yan 2,3, Sergei Maslov 3 1 New Media Lab, The Graduate Center, CUNY New York, NY 10016, USA 2 Department
Effects of Community Structure on Search and Ranking in Information Networks Huafeng Xie 1,3, Koon-Kiu Yan 2,3, Sergei Maslov 3 1 New Media Lab, The Graduate Center, CUNY New York, NY 10016, USA 2 Department
How to optimize the personalization vector to combat link spamming
 Delft University of Technology Faculty of Electrical Engineering, Mathematics and Computer Science Delft Institute of Applied Mathematics How to optimize the personalization vector to combat link spamming
Delft University of Technology Faculty of Electrical Engineering, Mathematics and Computer Science Delft Institute of Applied Mathematics How to optimize the personalization vector to combat link spamming
Monte Carlo methods in PageRank computation: When one iteration is sufficient
 Monte Carlo methods in PageRank computation: When one iteration is sufficient Nelly Litvak (University of Twente, The Netherlands) e-mail: n.litvak@ewi.utwente.nl Konstantin Avrachenkov (INRIA Sophia Antipolis,
Monte Carlo methods in PageRank computation: When one iteration is sufficient Nelly Litvak (University of Twente, The Netherlands) e-mail: n.litvak@ewi.utwente.nl Konstantin Avrachenkov (INRIA Sophia Antipolis,
Ranking and Hillside Form
 Ranking and Hillside Form Marthe Fallang Master s Thesis, Spring 2015 Acknowledgements First and foremost I would like to thank my advisor, Geir Dahl, for suggesting the topic and the article that has
Ranking and Hillside Form Marthe Fallang Master s Thesis, Spring 2015 Acknowledgements First and foremost I would like to thank my advisor, Geir Dahl, for suggesting the topic and the article that has
Node and Link Analysis
 Node and Link Analysis Leonid E. Zhukov School of Applied Mathematics and Information Science National Research University Higher School of Economics 10.02.2014 Leonid E. Zhukov (HSE) Lecture 5 10.02.2014
Node and Link Analysis Leonid E. Zhukov School of Applied Mathematics and Information Science National Research University Higher School of Economics 10.02.2014 Leonid E. Zhukov (HSE) Lecture 5 10.02.2014
Analysis of Google s PageRank
 Analysis of Google s PageRank Ilse Ipsen North Carolina State University Joint work with Rebecca M. Wills AN05 p.1 PageRank An objective measure of the citation importance of a web page [Brin & Page 1998]
Analysis of Google s PageRank Ilse Ipsen North Carolina State University Joint work with Rebecca M. Wills AN05 p.1 PageRank An objective measure of the citation importance of a web page [Brin & Page 1998]
Applications of The Perron-Frobenius Theorem
 Applications of The Perron-Frobenius Theorem Nate Iverson The University of Toledo Toledo, Ohio Motivation In a finite discrete linear dynamical system x n+1 = Ax n What are sufficient conditions for x
Applications of The Perron-Frobenius Theorem Nate Iverson The University of Toledo Toledo, Ohio Motivation In a finite discrete linear dynamical system x n+1 = Ax n What are sufficient conditions for x
Markov Chains for Biosequences and Google searches
 Markov Chains for Biosequences and Google searches Nigel Buttimore Trinity College Dublin 21 January 2008 Bell Labs Ireland Alcatel-Lucent Summary A brief history of Andrei Andreyevich Markov and his work
Markov Chains for Biosequences and Google searches Nigel Buttimore Trinity College Dublin 21 January 2008 Bell Labs Ireland Alcatel-Lucent Summary A brief history of Andrei Andreyevich Markov and his work
COMPSCI 514: Algorithms for Data Science
 COMPSCI 514: Algorithms for Data Science Arya Mazumdar University of Massachusetts at Amherst Fall 2018 Lecture 4 Markov Chain & Pagerank Homework Announcement Show your work in the homework Write the
COMPSCI 514: Algorithms for Data Science Arya Mazumdar University of Massachusetts at Amherst Fall 2018 Lecture 4 Markov Chain & Pagerank Homework Announcement Show your work in the homework Write the
The Giving Game: Google Page Rank
 The Giving Game: Google Page Rank University of Utah Teachers Math Circle Nick Korevaar March, 009 Stage 1: The Game Imagine a game in which you repeatedly distribute something desirable to your friends,
The Giving Game: Google Page Rank University of Utah Teachers Math Circle Nick Korevaar March, 009 Stage 1: The Game Imagine a game in which you repeatedly distribute something desirable to your friends,
MAE 298, Lecture 8 Feb 4, Web search and decentralized search on small-worlds
 MAE 298, Lecture 8 Feb 4, 2008 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in a file-sharing
MAE 298, Lecture 8 Feb 4, 2008 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in a file-sharing