Antonio Torralba, Lecture 6 Pyramids. Learned feedforward visual processing
|
|
|
- Reginald Blake
- 5 years ago
- Views:
Transcription
1 Antonio Torralba, 2016 Lecture 6 Pyramids Learned feedforward visual processing
2 The Gaussian pyramid (original image) 2

3 Image down-sampling ê2 Blur Image up-sampling é2 3

4 Image up-sampling = Start by inserting zeros

5 Convolution and up-sampling as a matrix multiply (1D case) Insert zeros between pixels, then apply a low-pass filter, [ ]
6 The Laplacian Pyramid Synthesis Compute the difference between upsampled Gaussian pyramid level and Gaussian pyramid level. band pass filter - each level represents spatial frequencies (largely) unrepresented at other level. 6




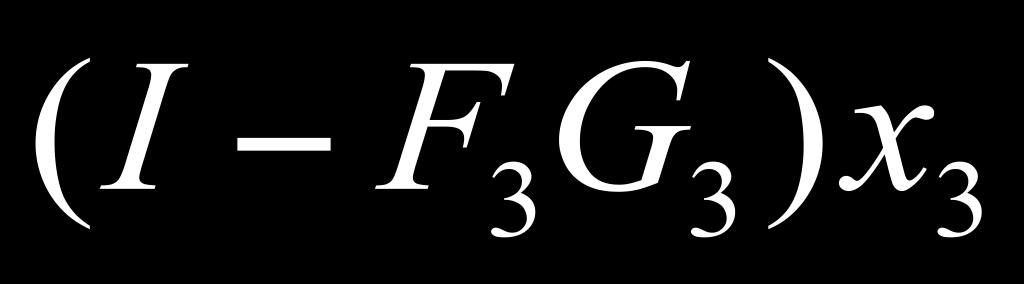
7 Laplacian pyramid algorithm 7
 pyramid. http://www-bcs.mit.edu/people/adelson/pub_pdfs/pyramid83.")
8 Showing, at full resolution, the information captured at each level of a Gaussian (top) and Laplacian (bottom) pyramid. 8
9 Laplacian pyramid reconstruction algorithm: recover x 1 from L 1, L 2, L 3 and x 4 G# is the blur-and-downsample operator at pyramid level # F# is the blur-and-upsample operator at pyramid level # Laplacian pyramid elements: L1 = (I F1 G1) x1 L2 = (I F2 G2) x2 L3 = (I F3 G3) x3 x2 = G1 x1 x3 = G2 x2 x4 = G3 x3 Reconstruction of original image (x1) from Laplacian pyramid elements: x3 = L3 + F3 x4 x2 = L2 + F2 x3 x1 = L1 + F1 x2 9

10 Laplacian pyramid reconstruction algorithm: recover x 1 from L 1, L 2, L 3 and g

11 Gaussian pyramid
")
12 (Low-pass residual) Laplacian pyramid
13 1-d Laplacian pyramid matrix, for [ ] low-pass filter high frequencies mid-band frequencies low frequencies 13
14 Laplacian pyramid applications Texture synthesis Image compression Noise removal Also related to SIFT 14
15 Image blending 15

16 Szeliski, Computer Vision,
17 Image blending Build Laplacian pyramid for both images: LA, LB Build Gaussian pyramid for mask: G Build a combined Laplacian pyramid: L(j) = G(j) LA(j) + (1-G(j)) LB(j) Collapse L to obtain the blended image 17
18 Image pyramids Gaussian Progressively blurred and subsampled versions of the image. Adds scale invariance to fixed-size algorithms. Laplacian Shows the information added in Gaussian pyramid at each spatial scale. Useful for noise reduction & coding. Those pyramids do not encode orientation 18
 = g(x, y) x = x x 2 +y 2 2πσ 4 e 2σ 2 g y (x, y) = g(x, y) y = y x 2 +y 2 2πσ")
19 Gaussian derivalves: Steerability. g x (x, y) = g(x, y) x = x x 2 +y 2 2πσ 4 e 2σ 2 g y (x, y) = g(x, y) y = y x 2 +y 2 2πσ 4 e 2σ 2 What about other orientations not axis aligned?





20 Gaussian derivalves: Steerability. g x (x,y) g y (x,y) g 60 (x,y) Input image g 60 (x,y) = ½g x (x,y) + 3/2g y (x,y)
21 Gaussian derivalves: Steerability. For the Gaussian derivatives, any orientation can be obtained as a linear combination of two basis functions: g α (x,y) = cos(α)g x (x,y) + sin(α)g y (x,y) In general, a kernel is steerable, if it can any rotation can be obtained as a linear combination of N basis functions. Steereability of gaussian derivatives, Freeman & Adelson 92
22 Steerable filters N-th order derivalves of Gaussians are steerable with N basis funclons. In general, if a funclon can be decomposed as a Fourier basis in polar coordinates with a finite number of polar terms, then the funclon is steerable. Steereability of gaussian derivatives, Freeman & Adelson 92
23 Steerable Pyramids We can extend the oriented filters into a multi-scale pyramid Simoncelli, Freeman, Adelson
24 Steerable Pyramids Simoncelli, Freeman, Adelson

25 Steerable Pyramid We may combine Steerability with Pyramids to get a Steerable Laplacian Pyramid as shown below Decomposition Images from:
26 Steerable Pyramid We may combine Steerability with Pyramids to get a Steerable Laplacian Pyramid as shown below Decomposition Images from:

27 Steerable Pyramid We may combine Steerability with Pyramids to get a Steerable Laplacian Pyramid as shown below Decomposition Reconstruction Images from:

28 There is also a high pass residual Shiftable MultiScale Transforms, by Simoncelli et al., IEEE Transactions on Information Theory, 1992
29 Steerable pyramid Multiple orientations at = one scale * Steerable pyramid Multiple orientations at the next scale the next scale pixel image Over-complete representation, but non-aliased subbands. 29


30 Image pyramids Gaussian Progressively blurred and subsampled versions of the image. Adds scale invariance to fixed-size algorithms. Laplacian Shows the information added in Gaussian pyramid at each spatial scale. Useful for noise reduction & coding. Steerable pyramid Shows components at each scale and orientation separately. Non-aliased subbands. Good for texture and feature analysis. But overcomplete and with HF residual.


31 Image transformalons DFT Gaussian pyramid Laplacian pyramid Steerable pyramid

32 Matlab resources for pyramids (with tutorial) 32

33 Matlab resources for pyramids (with tutorial) 33


34 Chapter 3: Image Processing
35 Why use these representalons? Handle real-world size varialons with a constant-size vision algorithm. Remove noise Analyze texture Recognize objects Label image features Image priors can be specified naturally in terms of wavelet pyramids. 35

36 Phase-based Pipeline (SIGGRAPH 13) Amplitude Phase Gains Complex steerable pyramid [Simoncelli and Freeman 1995] Temporal filtering on phases Pyramid inversion

37 input moaon magnified

38 input moaon magnified
39 Antonio Torralba, 2016 Lecture 6 Learned feedforward visual processing (Deep learning)
40 What is the best representation? All the previous representation are manually constructed. Could they be learnt from data?
41 Linear filtering pyramid architecture w1 w2 w3 + w4 w
42 Convolutional neural network architecture w1 w2 w3 + w4 w


43 Perceptrons, _Nagy_Pace_FR.pdf. Photo by George Nagy Perceptrons PDP book Minsky and Papert AI winter Krizhevsky, Sutskever, Hinton 43
44 Perceptrons,
45 Minsky and Papert pointed out many limitations of single-layer Perceptrons. Among them: very difficult to compute connectedness 45

46 Minsky and Papert, Perceptrons, 1972 Perceptrons PDP book Minsky and Papert AI winter Krizhevsky, Sutskever, Hinton 46

47 Parallel Distributed Processing (PDP), 1986 Perceptrons PDP book Minsky and Papert AI winter Krizhevsky, Sutskever, Hinton 47
48 XOR problem Inputs Output PDP authors pointed to the backpropagation algorithm as a breakthrough, allowing multi-layer neural networks to be trained. Among the functions that a multi-layer network can represent but a single-layer network cannot: the XOR function. 48

49 LeCun conv nets, 1998 Demos: 49

50 50
, 2009 IEEE 12th International.. http://pub.")
51 Neural networks to recognize handwritten digits? yes Neural networks for tougher problems? not really C Farabet, C Poulet, Y LeCun Computer Vision Workshops (ICCV Workshops), 2009 IEEE 12th International
52 Perceptrons NIPS 2000 NIPS, Neural Information Processing Systems, is the premier conference on machine learning. Evolved from an interdisciplinary conference to a machine learning conference. For the NIPS 2000 conference: title words predictive of paper acceptance: Belief Propagation and Gaussian. title words predictive of paper rejection: Minsky and Papert Neural Krizhevsky, and Network. PDP book AI winter Sutskever, Hinton 52
53 Krizhevsky, Sutskever, and Hinton, NIPS 2012 Perceptrons PDP book Minsky and Papert AI winter Krizhevsky, Sutskever, Hinton 53

54 Slide from Rob Fergus, NYU

55 Krizhevsky, Sutskever, and Hinton, NIPS

56 Test Nearby images, according to NN features Krizhevsky, Sutskever, and Hinton, NIPS
57 Research enthusiasm for artificial neural networks Perceptrons, years PDP book, 1986 Krizhevsky, Sutskever, Hinton, 2012 enthusiasm Minsky and Papert, 1972 AI winter, 2000 Geoff Hinton s citations time 57
58 Neural networks Neural nets composed of layers of artificial neurons. Each layer computes some function of layer beneath. Inputs mapped in feed-forward fashion to output. Consider only feed-forward neural models at the moment, i.e. no cycles
59 An individual neuron Input: x (n 1 vector) Parameters: weights w (n 1 vector), bias b (scalar) AcLvaLon: a = Pn i=1 x iwi + b. Note a is a scalar. MulLplicaLve interaclon between weights and input. Point-wise non-linear funclon: (: ), e.g. (: ) = tanh (: ). Output: y = f (a ) = ( Pn i=1 xiwi + b ) Can think of bias as weight w0, connected to constant input 1: y = f ( ~ wt [1; x ]).
60 An individual neuron (unit) Input: vector x (size n 1) x1 w1 Unit parameters: vector w (size n 1) bias b (scalar) Unit activation: a = Output: y = f (a) = f n i=1 x i w i + b ( n x i w i + b) i=1 x2 x3 xn 1 w2 w3 wn b + a y=f(a) f(.) is a point-wise non-linear function. E.g.: f (a) = tanh(a) = ea e a e a + e a Can think of bias as weight w 0, connected to constant input 1: y = f ([w 0, w] T [1; x ]).
61 Single layer network Input: column vector x (size n 1) Output: column vector y (size m 1) Layer parameters: weight matrix W (size n m) bias vector b (m 1) Units activation: ex. 4 inputs, 3 outputs a = Wx + b = + w1,m w1,1 wn,m Output: y = f (a) = f ( Wx + b)
62 f (a) = sigmoid(a) = Non-lineariLes: sigmoid 1 Interpretation as ring rate of neuron 1+ e a Bounded between [0,1] Saturation for large +ve,-ve inputs Gradients go to zero Outputs centered at 0.5 (poor conditioning) Not used in practice
63 Non-lineariLes: tanh f (a) = tanh(a) = ea e a e a + e a Bounded between [-1,+1] Saturation for large +ve,-ve inputs Gradients go to zero Outputs centered at 0 Preferable to sigmoid tanh(x) = 2 sigmoid(2x) 1
64 Non-lineariLes: reclfied linear (ReLU) f (a) = max(a,0) Unbounded output (on positive side) Efficient to implement: f '(a) = df da = 0 a < 0 1 a 0 Also seems to help convergence (see 6x speedup vs tanh in Krizhevsky et al.) Drawback: if strongly in negative region, unit is dead forever (no gradient). Default choice: widely used in current models.
65 Non-lineariLes: Leaky ReLU f (a) = max(0,a) a > 0 α min(0,a) a < 0 where α is small (e.g. 0.02) Efficient to implement: f '(a) = df da = α a < 0 1 a > 0 Also known as probabilistic ReLU (PReLU) Has non-zero gradients everywhere (unlike ReLU) α can also be learned (see Kaiming He et al. 2015).
66 Neural networks are composed of multiple layers of neurons. Acyclic structure. Basic model assumes full connections between layers. MulLple layers Layers between input and output are called hidden. Various names used: Articial Neural Nets (ANN) Multi-layer Perceptron (MLP) Fully-connected network Neurons typically called units.
67 Example: 3 layer MLP By convention, number of layers is hidden + output (i.e. does not include input). So 3-layer model has 2 hidden layers. Parameters: weight matrices W 1 ;W 2 ;W 3 bias vectors b 1 ; b 2 ; b 3.
68 MulLple layers Output layer n Hidden layer i (output) x n F n (x n-1, W n ) x n-1 x i F i (x i-1, W i ) x i-1 Hidden layer 1 x 1 F 1 (x 0, W 1 ) Input layer (input) x 0
69 Architecture seleclon How to pick number of layers and units/layer? AcLve area of research For fully connected models 2 or 3 layers seems the most that can be effeclvely trained (more later). Regarding number of units/layer: Parameters grows with (units/layer) 2. With large units/layer, can easily overt.


70 RepresentaLonal power of two-layer network 2 In bias Out 70
71 RepresentaLonal power 1 layer? Linear decision surface. 2+ layers? In theory, can represent any funclon. Assuming non-trivial non-linearity. Bengio 2009, hgp:// Bengio, Courville, Goodfellow book hgp:// Simple proof by M. Neilsen hgp://neuralnetworksanddeeplearning.com/chap4.html D. Mackay book hgp:// But issue is efficiency: very wide two layers vs narrow deep model? In praclce, more layers helps.
72 Training a model: overview Given dataset {x; y}, pick appropriate cost funclon C. Forward-pass (f-prop) training examples through the model to get network output. Get error using cost funclon C to compare output to targets y Use StochasLc Gradient Descent (SGD) to update weights adjuslng parameters to minimize loss/energy E (sum of the costs for each training example)
73 Cost funclon Consider model with N layers. Layer i has vector of weights Wi. Forward pass: takes input x and passes it through each layer F i : x i = F i (x i-1, W i ) Output of layer i is x i. Network output (top layer) is x n. (output) x n F n (x n-1, W n ) x n-1 x i F i (x i-1, W i ) x i-1 x 2 F 2 (x 1, W 2 ) x 1 F 1 (x 0, W 1 ) (input) x 0
74 Cost funclon Consider model with N layers. Layer i has vector of weights Wi. Forward pass: takes input x and passes it through each layer F i : x i = F i (x i-1, W i ) Output of layer i is x i. Network output (top layer) is x n. Cost funclon C compares x n to y Overall energy is the sum of the cost over all training examples: E = M C( x m n, y m ) m =1 (output) (input) F n (x n-1, W n ) x n-1 x i F i (x i-1, W i ) F 2 (x 1, W 2 ) F 1 (x 0, W 1 ) x 0 x n x i-1 x 2 x 1 E C(x n, y) y
75 StochasLc gradient descend Want to minimize overall loss funclon E. Loss is sum of individual losses over each example. In gradient descent, we start with some inilal set of parameters θ Update parameters: k is iteralon index, η is learning rate (scalar; set semi-manually). Gradients computed by b-prop. In StochasLc gradient descent, compute gradient on sub-set (batch) of data. If batchsize=1 then θ is updated aher each example. If batchsize=n (full set) then this is standard gradient descent. Gradient direclon is noisy, relalve to average over all examples (standard gradient descent). 75
76 StochasLc gradient descend We need to compute gradients of the cost with respect to model parameters w i Back-propagaLon is essenlally chain rule of derivalves back through the model. Each layer is differenlable with respect to parameters and input. 76
77 CompuLng gradients Training will be an iteralve procedure, and at each iteralon we will update the network parameters We want to compute the gradients Where θ = { w 1,w 2,,w } n 77
 = C F n F n 1 F 2 F 1 x m 0,w 1 E θ M m =1 ( ( ( ),w 2 ),w n 1 ),w n And then compute the partial derivatives instead, we can use the chain rule to derive a")
78 CompuLng gradients To compute the gradients, we could start by wring the full energy E as a funclon of the network parameters. ( ) = C F n F n 1 F 2 F 1 x m 0,w 1 E θ M m =1 ( ( ( ),w 2 ),w n 1 ),w n And then compute the partial derivatives instead, we can use the chain rule to derive a compact algorithm: back-propagation, y m 78
79 (
80 x column vector of size [n 1] Matrix calculus We now define a function on vector x: y = F(x) If y is a scalar, then [ ] The derivative of y is a row vector of size [1 n] y / x = y / x 1 y / x 2! y / x n If y is a vector [1 m], then (Jacobian formulation): y / x = x = x 1 x 2! x n y 1 / x 1 y 1 / x 2! y 1 / x n " " " y m / x 1 y m / x 2! y n / x m The derivative of y is a matrix of size [m n] (m rows and n columns)
81 Chain rule: Matrix calculus For the function: z = h(x) = f (g(x)) Its derivative is: h (x) = f (g(x)) g (x) and writing z=f(u), and u=g(x): dz = dz du dx x =a du u=g(a ) dx x =a [m n] [m p] [p n] with p = length vector u = u, m = z, and n = x Example, if z =1, u = 2, x =4 h (x) = =
82 Chain rule: Matrix calculus For the function: h(x) = f n (f n-1 ( (f 1 (x)) )) With u 1 = f 1 (x) u i = f i (u i-1 ) z = u n = f n (u n-1 ) The derivative becomes a product of matrices: dz dx x =a = dz du n 1 un 1 = f n 1 (u n 2 ) du n 1 du 2 du 1 du n 2 un 2 du = f n 2 (u n 3 ) 1 u1 dx = f 1 (a) x =a (exercise: check that all the matrix dimensions work fine)
83 )
84 CompuLng gradients The energy E is the sum of the costs associated to each training example x m, y m ( ) = C x n m, y m ;θ E θ M m =1 ( ) Its gradient with respect to the networks parameters is: E θ i = M m =1 C( x m n, y m ;θ) θ i is how much E varies when the parameter θ i is varied. 84
85 CompuLng gradients We could write the cost function to get the gradients: ( ) = C F n x n 1,w n C x n,y;θ with ( ), y ( ) [ ] θ = w 1,w 2,!,w n If we compute the gradient with respect to the parameters of the last layer (output layer) w n, using the chain rule: C = C x n w n x n w n = C x n F n ( x,w ) n 1 n w n (how much the cost changes when we change wn, is the product between how much the cost changes when we change the output of the last layer, times how much the output changes when we change the layer parameters.) 85
 n w n For example, for an Euclidean loss: C(x n,y) = 1 2 x n y 2 Will depend on the layer structure and non-linearity.")
86 CompuLng gradients: cost layer If we compute the gradient with respect to the parameters of the last layer (output layer) w n, using the chain rule: C = C x n w n x n w n = C x n F n ( x n 1,w ) n w n For example, for an Euclidean loss: C(x n,y) = 1 2 x n y 2 Will depend on the layer structure and non-linearity. The gradient is: C = x x n y n 86
87 CompuLng gradients: layer i We could write the full cost function to get the gradients: ( ) = C F n F n 1 F 2 F 1 x 0,w 1 C x n,y;θ ( ( ( ),w 2 ),w n 1 ),w n, y If we compute the gradient with respect to w i, using the chain rule: C = C w i x n x n x n 1 x i+1 x i x n 1 x n 2 x i w i C x i And this can be computed iteratively! F i ( ) x i 1,w i w i This is easy. 87
88 C = C w i x n If we have the value of layer bellow as: BackpropagaLon x n x n 1 x i+1 x i x n 1 x n 2 x i w i C F i x i 1,w i x i C w i x i ( ) we can compute the gradient at the C = C x i 1 x i x i x i 1 Gradient layer i-1 Gradient layer i F i ( ) x i 1,w i x i 1
89 BackpropagaLon: layer i F i+1 x i Hidden layer i F i (x i-1, W i ) x i-1 F i-1 Forward pass C x i C x i 1 Backward pass Layer i has two inputs (during training) x C i-1 x i For layer i, we need the derivatives: F i (x i 1,w i ) F i (x i 1,w i ) x i 1 w i We compute the outputs x i = F i (x i 1,w i ) C = C F (x,w ) i i 1 i x i 1 x i x i 1 The weight update equation is: C = C F (x,w ) i i 1 i w i x i w i w i k +1 w i k +η t E w i (sum over all training examples to get E)
90 BackpropagaLon: summary E Forward pass: for each training example. Compute the outputs for all layers x i = F i (x i 1,w i ) Backwards pass: compute cost derivalves iteralvely from top to bogom: C = C F (x,w ) i i 1 i x i 1 x i x i 1 Compute gradients and update weights. (output) C x n x n F n (x n-1, W n ) x n-1 x i F i (x i-1, W i ) x i-1 x 2 F 2 (x 1, W 2 ) x 1 F 1 (x 0, W 1 ) C(X n,y) C x i C x i 1 C x 2 C x 1 (input) x 0 y
6.869 Advances in Computer Vision. Bill Freeman, Antonio Torralba and Phillip Isola MIT Oct. 3, 2018
 6.869 Advances in Computer Vision Bill Freeman, Antonio Torralba and Phillip Isola MIT Oct. 3, 2018 1 Sampling Sampling Pixels Continuous world 3 Sampling 4 Sampling 5 Continuous image f (x, y) Sampling
6.869 Advances in Computer Vision Bill Freeman, Antonio Torralba and Phillip Isola MIT Oct. 3, 2018 1 Sampling Sampling Pixels Continuous world 3 Sampling 4 Sampling 5 Continuous image f (x, y) Sampling
Neural Networks. Lecture 2. Rob Fergus
 Neural Networks Lecture 2 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Neural Networks Lecture 2 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Neural Networks. Lecture 6. Rob Fergus
 Neural Networks Lecture 6 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Neural Networks Lecture 6 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Feedforward Networks. Sargur N. Srihari
 Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Deep Feedforward Networks
 Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN)
") EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Deep Learning (CNNs)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
BACKPROPAGATION. Neural network training optimization problem. Deriving backpropagation
 BACKPROPAGATION Neural network training optimization problem min J(w) w The application of gradient descent to this problem is called backpropagation. Backpropagation is gradient descent applied to J(w)
BACKPROPAGATION Neural network training optimization problem min J(w) w The application of gradient descent to this problem is called backpropagation. Backpropagation is gradient descent applied to J(w)
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 2 October 2018 http://www.inf.ed.ac.u/teaching/courses/mlp/ MLP Lecture 3 / 2 October 2018 Deep
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Lecture 14: Deep Generative Learning
 Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16 Slides adapted from Jordan Boyd-Graber, Justin Johnson, Andrej Karpathy, Chris Ketelsen, Fei-Fei Li, Mike Mozer, Michael Nielson
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 16 Slides adapted from Jordan Boyd-Graber, Justin Johnson, Andrej Karpathy, Chris Ketelsen, Fei-Fei Li, Mike Mozer, Michael Nielson
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Network Language Modeling
 Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Backpropagation Introduction to Machine Learning. Matt Gormley Lecture 12 Feb 23, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
The XOR problem. Machine learning for vision. The XOR problem. The XOR problem. x 1 x 2. x 2. x 1. Fall Roland Memisevic
 The XOR problem Fall 2013 x 2 Lecture 9, February 25, 2015 x 1 The XOR problem The XOR problem x 1 x 2 x 2 x 1 (picture adapted from Bishop 2006) It s the features, stupid It s the features, stupid The
The XOR problem Fall 2013 x 2 Lecture 9, February 25, 2015 x 1 The XOR problem The XOR problem x 1 x 2 x 2 x 1 (picture adapted from Bishop 2006) It s the features, stupid It s the features, stupid The
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Lecture 4 Backpropagation
 Lecture 4 Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 5, 2017 Things we will look at today More Backpropagation Still more backpropagation Quiz
Lecture 4 Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 5, 2017 Things we will look at today More Backpropagation Still more backpropagation Quiz
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Lecture 2: Modular Learning
 Lecture 2: Modular Learning Deep Learning @ UvA MODULAR LEARNING - PAGE 1 Announcement o C. Maddison is coming to the Deep Vision Seminars on the 21 st of Sep Author of concrete distribution, co-author
Lecture 2: Modular Learning Deep Learning @ UvA MODULAR LEARNING - PAGE 1 Announcement o C. Maddison is coming to the Deep Vision Seminars on the 21 st of Sep Author of concrete distribution, co-author
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville
 Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville Chapter 6 :Deep Feedforward Networks Benoit Massé Dionyssos Kounades-Bastian Benoit Massé, Dionyssos Kounades-Bastian Deep Feedforward
Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville Chapter 6 :Deep Feedforward Networks Benoit Massé Dionyssos Kounades-Bastian Benoit Massé, Dionyssos Kounades-Bastian Deep Feedforward
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Lecture 7 Convolutional Neural Networks
 Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 4.1 Gradient-Based Learning: Back-Propagation and Multi-Module Systems Yann LeCun
 Y. LeCun: Machine Learning and Pattern Recognition p. 1/2 MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 4.1 Gradient-Based Learning: Back-Propagation and Multi-Module Systems Yann LeCun The
Y. LeCun: Machine Learning and Pattern Recognition p. 1/2 MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 4.1 Gradient-Based Learning: Back-Propagation and Multi-Module Systems Yann LeCun The
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Feedforward Neural Networks
 Feedforward Neural Networks Michael Collins 1 Introduction In the previous notes, we introduced an important class of models, log-linear models. In this note, we describe feedforward neural networks, which
Feedforward Neural Networks Michael Collins 1 Introduction In the previous notes, we introduced an important class of models, log-linear models. In this note, we describe feedforward neural networks, which
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Sajid Anwar, Kyuyeon Hwang and Wonyong Sung
 Sajid Anwar, Kyuyeon Hwang and Wonyong Sung Department of Electrical and Computer Engineering Seoul National University Seoul, 08826 Korea Email: sajid@dsp.snu.ac.kr, khwang@dsp.snu.ac.kr, wysung@snu.ac.kr
Sajid Anwar, Kyuyeon Hwang and Wonyong Sung Department of Electrical and Computer Engineering Seoul National University Seoul, 08826 Korea Email: sajid@dsp.snu.ac.kr, khwang@dsp.snu.ac.kr, wysung@snu.ac.kr
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Machine Learning
 Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Feedforward Neural Networks. Michael Collins, Columbia University
 Feedforward Neural Networks Michael Collins, Columbia University Recap: Log-linear Models A log-linear model takes the following form: p(y x; v) = exp (v f(x, y)) y Y exp (v f(x, y )) f(x, y) is the representation
Feedforward Neural Networks Michael Collins, Columbia University Recap: Log-linear Models A log-linear model takes the following form: p(y x; v) = exp (v f(x, y)) y Y exp (v f(x, y )) f(x, y) is the representation
Introduction Biologically Motivated Crude Model Backpropagation
 Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Deep Learning: a gentle introduction
 Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Learning Deep Architectures for AI. Part I - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part I - Vijay Chakilam Chapter 0: Preliminaries Neural Network Models The basic idea behind the neural network approach is to model the response as a
Learning Deep Architectures for AI - Yoshua Bengio Part I - Vijay Chakilam Chapter 0: Preliminaries Neural Network Models The basic idea behind the neural network approach is to model the response as a
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Advanced Machine Learning
 Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Multiscale Image Transforms
 Multiscale Image Transforms Goal: Develop filter-based representations to decompose images into component parts, to extract features/structures of interest, and to attenuate noise. Motivation: extract
Multiscale Image Transforms Goal: Develop filter-based representations to decompose images into component parts, to extract features/structures of interest, and to attenuate noise. Motivation: extract
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Artificial Neuron (Perceptron)
") 9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
9/6/208 Gradient Descent (GD) Hantao Zhang Deep Learning with Python Reading: https://en.wikipedia.org/wiki/gradient_descent Artificial Neuron (Perceptron) = w T = w 0 0 + + w 2 2 + + w d d where
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
RegML 2018 Class 8 Deep learning
 RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
Lecture 2: Learning with neural networks
 Lecture 2: Learning with neural networks Deep Learning @ UvA LEARNING WITH NEURAL NETWORKS - PAGE 1 Lecture Overview o Machine Learning Paradigm for Neural Networks o The Backpropagation algorithm for
Lecture 2: Learning with neural networks Deep Learning @ UvA LEARNING WITH NEURAL NETWORKS - PAGE 1 Lecture Overview o Machine Learning Paradigm for Neural Networks o The Backpropagation algorithm for
Subsampling and image pyramids
 Subsampling and image pyramids http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 2018, Lecture 3 Course announcements Homework 0 and homework 1 will be posted tonight. - Homework 0 is not required
Subsampling and image pyramids http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 2018, Lecture 3 Course announcements Homework 0 and homework 1 will be posted tonight. - Homework 0 is not required
Machine Learning Lecture 12
 Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Lab 5: 16 th April Exercises on Neural Networks
 Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
Deep Feedforward Networks. Han Shao, Hou Pong Chan, and Hongyi Zhang
 Deep Feedforward Networks Han Shao, Hou Pong Chan, and Hongyi Zhang Deep Feedforward Networks Goal: approximate some function f e.g., a classifier, maps input to a class y = f (x) x y Defines a mapping
Deep Feedforward Networks Han Shao, Hou Pong Chan, and Hongyi Zhang Deep Feedforward Networks Goal: approximate some function f e.g., a classifier, maps input to a class y = f (x) x y Defines a mapping
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
Neural Networks: A Very Brief Tutorial
 Neural Networks: A Very Brief Tutorial Chloé-Agathe Azencott Machine Learning & Computational Biology MPIs for Developmental Biology & for Intelligent Systems Tübingen (Germany) cazencott@tue.mpg.de October
Neural Networks: A Very Brief Tutorial Chloé-Agathe Azencott Machine Learning & Computational Biology MPIs for Developmental Biology & for Intelligent Systems Tübingen (Germany) cazencott@tue.mpg.de October
Neural Networks. Learning and Computer Vision Prof. Olga Veksler CS9840. Lecture 10
 CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Deep Learning. Convolutional Neural Network (CNNs) Ali Ghodsi. October 30, Slides are partially based on Book in preparation, Deep Learning
 Ali Ghodsi. October 30, Slides are partially based on Book in preparation, Deep Learning") Convolutional Neural Network (CNNs) University of Waterloo October 30, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Convolutional Networks Convolutional
Convolutional Neural Network (CNNs) University of Waterloo October 30, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Convolutional Networks Convolutional
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
Supervised Learning. George Konidaris
 Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Statistical Machine Learning
 Statistical Machine Learning Lecture 9 Numerical optimization and deep learning Niklas Wahlström Division of Systems and Control Department of Information Technology Uppsala University niklas.wahlstrom@it.uu.se
Statistical Machine Learning Lecture 9 Numerical optimization and deep learning Niklas Wahlström Division of Systems and Control Department of Information Technology Uppsala University niklas.wahlstrom@it.uu.se
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Introduction to Deep Learning
 Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
100 inference steps doesn't seem like enough. Many neuron-like threshold switching units. Many weighted interconnections among units
 Connectionist Models Consider humans: Neuron switching time ~ :001 second Number of neurons ~ 10 10 Connections per neuron ~ 10 4 5 Scene recognition time ~ :1 second 100 inference steps doesn't seem like
Connectionist Models Consider humans: Neuron switching time ~ :001 second Number of neurons ~ 10 10 Connections per neuron ~ 10 4 5 Scene recognition time ~ :1 second 100 inference steps doesn't seem like
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Grundlagen der Künstlichen Intelligenz Neural networks Daniel Hennes 21.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Logistic regression Neural networks Perceptron
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Deep Feedforward Networks. Lecture slides for Chapter 6 of Deep Learning Ian Goodfellow Last updated
 Deep Feedforward Networks Lecture slides for Chapter 6 of Deep Learning www.deeplearningbook.org Ian Goodfellow Last updated 2016-10-04 Roadmap Example: Learning XOR Gradient-Based Learning Hidden Units
Deep Feedforward Networks Lecture slides for Chapter 6 of Deep Learning www.deeplearningbook.org Ian Goodfellow Last updated 2016-10-04 Roadmap Example: Learning XOR Gradient-Based Learning Hidden Units